基于GC-Cascade R-CNN的梨葉病斑計數(shù)方法
2022-06-21 08:21:36程潤華康亞龍黃新忠徐陽春董彩霞
農(nóng)業(yè)機械學報 2022年5期
薛 衛(wèi) 程潤華 康亞龍 黃新忠 徐陽春 董彩霞
(1.南京農(nóng)業(yè)大學人工智能學院, 南京 210095; 2.南京農(nóng)業(yè)大學資源與環(huán)境科學學院, 南京 210095;3.福建農(nóng)業(yè)科學院果樹研究所, 福州 350013)
0 引言
中國的梨種植面積和產(chǎn)量均居世界首位[1]。梨樹病害是影響產(chǎn)量的主要因素,及時準確地進行病害發(fā)生程度診斷,有利于提前做出預測預報和采取防控措施,對梨生產(chǎn)具有重要現(xiàn)實意義。梨樹病害早期癥狀,多由近圓形斑點區(qū)域組成,病斑尺寸微小,顏色不均勻,紋理不顯著;后期多個病斑常融合成明顯且不規(guī)則形狀的深色斑塊。因此病害早期是防治的最佳時期。梨樹葉片病害發(fā)生程度主要通過人工統(tǒng)計葉面病斑數(shù)來評價分析[2-3]。此過程費時費力,誤差較大。
傳統(tǒng)圖像處理和機器學習廣泛應用于農(nóng)作物病害診斷領域[4]。研究者利用閾值分割[5]、邊緣檢測[6]、OTSU算法[7]、支持向量機[8](Support vector machine, SVM)、K-均值聚類算法[9]等方法進行病害檢測研究,取得了一定的進展。然而,傳統(tǒng)圖像處理方法依賴于人工設定特征模式,特征提取不穩(wěn)定,受環(huán)境影響較大;在圖像檢測上魯棒性較低,難適用于復雜的農(nóng)業(yè)生產(chǎn)環(huán)境。
近年來,隨著深度學習在計算機視覺領域的發(fā)展,目標檢測在作物檢測[4]、自動導航[10]、人臉識別[11]、行人檢測[12]等諸多領域廣泛應用。當前主流目標檢測算法,如經(jīng)典的兩階段檢測算法Faster R-CNN[13]、單階段檢測算法YOLO[14]系列和SSD[15]系列,大都針對分布稀疏、尺寸較大的目標。在檢測小目標方面識別效果不佳。小目標在MS COCO數(shù)據(jù)集中被定義為尺寸小于32像素×32像素的物體。梨葉早期病害產(chǎn)生的病斑個體在采樣圖像中的面積遠小于32像素×32像素,直接應用經(jīng)典目標檢測算法,經(jīng)卷積神經(jīng)網(wǎng)絡(Convolutional neural network,CNN)下采樣后的特征信息保留較少,檢測難度較大。
現(xiàn)有的小目標檢測算法一般是在經(jīng)典目標檢測方法的基礎上提出一些改進或優(yōu)化策略[16],如改進特征融合技巧、結(jié)合上下文信息和引入注意力模塊等[17-20]。目前這些基于深度學習的小目標檢測算法仍有一定的提升空間。
為有效解決自然環(huán)境下梨葉病斑計數(shù)成本高、誤差大等問題,本文提出基于全局上下文級聯(lián)R-CNN網(wǎng)絡(Global context Cascade R-CNN,GC-Cascade R-CNN)的高效梨葉病斑自動計數(shù)方法。以Cascade R-CNN[21]為基本網(wǎng)絡模型,引入全局上下文模塊(Global context feature model,GC-Model),通過建立長距離依賴和通道依賴增強目標特征信息。將各層特征經(jīng)特征金字塔網(wǎng)絡[22](Feature pyramid network,F(xiàn)PN)融合,送入級聯(lián)網(wǎng)絡中檢測,最終統(tǒng)計相關病斑數(shù)量。并通過實驗驗證提出模型的有效性和實時性。
1 病害數(shù)據(jù)集
1.1 數(shù)據(jù)采集
梨樹葉片病害圖像取自福建省西北內(nèi)陸山區(qū)的建寧縣試驗站。試驗站屬山地果園,管理水平中等,地處亞熱帶季風氣候,年平均氣溫約16.9℃,年平均日照時數(shù)1 720 h,無霜期230~280 d,年降水量1 850 mm。在試驗園區(qū)進行梨葉采摘,采摘后在實驗室通過相機進行圖像采集。攝像頭正對葉片表面,鏡頭距離葉片表面約10 cm。樣本圖像格式為JPG,分辨率為4 752像素×3 168像素。
梨葉其他幾類病害圖像收集于公開數(shù)據(jù)集,如Kaggle競賽中的plant pathology 2020數(shù)據(jù)集、AI Challenger 2018農(nóng)作物病害檢測數(shù)據(jù)集等。部分梨葉圖像如圖1所示,因為采集樣本圖像分辨率較高,故挑選原圖中病斑顯著局部區(qū)域作為數(shù)據(jù)集。數(shù)據(jù)集共收集550幅梨葉片圖像,包括銹病150幅、黑星病100幅、炭疽病200幅和褐斑病100幅。其中,黑星病病斑尺寸較大,特征較為明顯。銹病與褐斑病顏色特征顯著。而炭疽病病斑尺寸較小,各項特征不突出,檢測難度最大。

圖1 數(shù)據(jù)采集樣本圖Fig.1 Samples of data acquisition
1.2 數(shù)據(jù)增強
針對小目標分辨率低、數(shù)據(jù)集少及分布不均勻等問題。通常對數(shù)據(jù)集中樣本進行數(shù)據(jù)增強以擴充數(shù)據(jù)集的數(shù)量,實現(xiàn)更復雜的數(shù)據(jù)描述,提高目標檢測算法的擬合能力。
常見的數(shù)據(jù)擴充方式有旋轉(zhuǎn)、剪裁、縮放、水平翻轉(zhuǎn)等[23]。本文數(shù)據(jù)增強策略采用數(shù)據(jù)集圖像順時針旋轉(zhuǎn)120°、150°、210°、240°、300°,水平鏡像翻轉(zhuǎn)和垂直鏡像翻轉(zhuǎn)的方式。增強后的擴展數(shù)據(jù)集包含銹病圖像1 050幅、黑星病圖像700幅、炭疽病圖像1 400幅和褐斑病圖像700幅。
在病斑數(shù)據(jù)標注方面,使用標注工具LabelImg進行標注。標注結(jié)果中梨炭疽病的樣本數(shù)為6 234個,梨銹病的樣本數(shù)為2 522個,梨黑星病的樣本數(shù)為2 211個,梨褐斑病的樣本數(shù)為2 132個。訓練時將樣本混合,按照比例4∶1劃分訓練集和測試集。
2 基于GC-Cascade R-CNN的病斑計數(shù)模型
本文提出的算法基于Cascade R-CNN目標檢測模型,主要分訓練階段和測試階段。基本檢測流程如下:首先輸入圖像,進行圖像分區(qū),得到一系列分區(qū)圖像。后逐一對分區(qū)圖像進行特征提取,使用FPN特征融合,提取圖像中更有效的特征信息。然后輸入到級聯(lián)網(wǎng)絡檢測,統(tǒng)計圖像病斑計數(shù)值。具體流程如圖2所示。

圖2 病斑計數(shù)流程圖Fig.2 Flow chart of disease spot counting
2.1 圖像分區(qū)
梨樹葉片病害樣本圖像原始分辨率較高,如炭疽病樣本圖像的分辨率為4 752像素×3 168像素。目前基于深度學習網(wǎng)絡的目標檢測算法一般使用分辨率在512像素×512像素以下的圖像進行訓練和測試。若直接將樣本圖像輸入到網(wǎng)絡中會被強制縮小到較低的分辨率,導致目標特征信息丟失,檢測精度大大降低[24]。
參照文獻[25]中的處理方法,通過滑動窗口算法將圖像分成與目標網(wǎng)絡輸入尺寸一致的區(qū)塊。滑動窗口分區(qū)尺寸設置為N像素×N像素,區(qū)塊間重疊百分比設置為15%,可保存分區(qū)圖像在原始圖像中的全局位置。若圖像邊緣部分不足以進行分區(qū),需向相反方向截取圖像。
對于每一個圖像分區(qū),根據(jù)該分區(qū)的全局位置坐標返回在原圖的邊界框位置預測,最終將所有圖像分區(qū)結(jié)果整合到原圖中。對邊界框預測的全局矩陣應用非極大值抑制算法(Non-maximum suppression,NMS),以避免分區(qū)邊界區(qū)域的重疊檢測。
2.2 級聯(lián)R-CNN網(wǎng)絡
Cascade R-CNN[21]是級聯(lián)R-CNN網(wǎng)絡,它聯(lián)合多級網(wǎng)絡結(jié)構(gòu)為每個R-CNN設置不同的重疊度(Intersection over union,IoU)閾值,平衡每個網(wǎng)絡中正負樣本的分布,提取到的正負樣本用于下一個網(wǎng)絡的輸入,由此對檢測結(jié)果不斷優(yōu)化。網(wǎng)絡結(jié)構(gòu)默認具有3個R-CNN網(wǎng)絡結(jié)構(gòu),具體結(jié)構(gòu)如圖3所示。

圖3 Cascade R-CNN結(jié)構(gòu)框圖Fig.3 Framework diagram of Cascade R-CNN
IoU閾值通常被用來界定正負樣本。低IoU閾值通常伴隨無關噪聲,檢測結(jié)果中會包含較多的背景區(qū)域。隨著IoU閾值的逐漸增加,檢測性能也會逐漸提升。但當其提升到一定程度,繼續(xù)增加會使得檢測性能趨于下降。這是因為樣本不平衡的影響,正樣本在高IoU閾值下不斷減少,訓練容易過擬合。同時區(qū)域生成網(wǎng)絡(Region proposal network,RPN)篩選的候選框與標注框出現(xiàn)偏差,邊界框回歸損失會顯著增加。
級聯(lián)網(wǎng)絡采用逐級上升IoU閾值方式,重采樣正負樣本,可以克服訓練過程中的過擬合問題。每個階段都能得到質(zhì)量更好的候選框,穩(wěn)定提升訓練效果。
此外,本文使用ROI Align[26]替換傳統(tǒng)R-CNN網(wǎng)絡中默認的ROI Pooling作為網(wǎng)絡中區(qū)域特征聚集層。ROI Align使用雙線性插值算法替換原來的最近鄰插法,有效地解決了ROI Pooling操作中2次量化造成區(qū)域不匹配的問題,更準確地定位目標位置,可以提升檢測模型的準確率。ROI Align的反向傳播公式為
(1)
式中L——損失函數(shù)
xa——池化前特征圖上的像素點a
ytb——池化后的第t個候選區(qū)域的第b個像素點
a*(t,b)——前向傳播時計算出來的采樣點位置
d(~)——兩點的距離函數(shù)
Δh、Δw——a與a*(t,b)橫縱坐標的差值,作為雙線性插值算法的系數(shù)參與原始梯度的計算
2.3 全局上下文模塊(GC-Model)
非局部神經(jīng)網(wǎng)絡(Non-local neural network,NLNet)[27]是一種基于自注意力機制的長距離依賴模型。它采用非局部操作建立查詢位置(Query position)和所有位置的成對關系,計算相關性得到注意力圖(Attention map)。后通過加權和的方式聚合所有位置的相關性特征,得到查詢位置的全局上下文特征。將全局上下文特征與原始特征結(jié)合,完成長距離依賴的建立。但其對每一個位置獲取的注意力圖不受位置依賴,存在較大的計算冗余。
非局部神經(jīng)網(wǎng)絡基于非局部操作塊(Non-local block),其對查詢位置的非局部操作可表達為
(2)
式中xi——查詢位置的輸入矩陣
xj——其他位置的輸入矩陣
zi——查詢位置的輸出矩陣
Wz、Wk——線性轉(zhuǎn)換矩陣
Np——特征圖中的位置數(shù)
C(x)——歸一化函數(shù)
f——2個位置的相似性函數(shù)
具體網(wǎng)絡結(jié)構(gòu)如圖4a所示,其中C、H、W分別為特征圖的通道數(shù)、高度及寬度。C×H×W是特征提取得到的三維特征圖,而C×HW是經(jīng)過線性轉(zhuǎn)換過后的二維特征矩陣,后續(xù)的結(jié)果均是經(jīng)過處理的特征矩陣。

圖4 長距離依賴和通道依賴模型圖Fig.4 Long-range dependency and channel dependency model diagram
擠壓和激勵網(wǎng)絡[28](Squeeze and excitation networks,SENet)是基于通道注意力機制的經(jīng)典網(wǎng)絡。它聚焦于通道維度,通過學習的方式對通道間的依賴關系進行建模,獲取各特征通道的重要程度,自適應調(diào)整各通道的特征響應。具體結(jié)構(gòu)如圖4b所示,主要由3個操作構(gòu)成:首先,通過全局池化層(Global average pooling)進行特征壓縮,得到特征通道上響應全局特征的分布,獲取全局感受野。然后,根據(jù)特征通道間的相關性生成每個通道的特征權重。最后將特征權重看作特征選擇后每個特征通道的重要程度,通過對應元素相乘加權到原始特征上,完成通道維度上對原始特征的重新標定。
GC-Model[29]是結(jié)合NLNet全局上下文建模能力和SENet計算量小等優(yōu)點的非局部操作網(wǎng)絡,其計算量相對較小,只需計算一個所有位置共享的全局注意力圖。同時結(jié)合長距離依賴和通道依賴,能夠更好地融合全局信息,增強視覺場景的全局理解,在一定程度上提升了目標檢測精度。
GC-Model中非局部操作可分為3個步驟:首先采用1×1卷積核和Softmax函數(shù)得到注意力權重,然后通過矩陣乘法執(zhí)行全局注意力池化,獲取全局上下文特征。然后采用1×1卷積核特征轉(zhuǎn)換獲取通道依賴性,計算每個通道的重要程度。將線性整流函數(shù)(Rectified linear unit, ReLU)和通道歸一化(Layer normalization,LN)用于降低轉(zhuǎn)換難度。最后采用對應元素逐個相加操作將全局上下文特征與原始特征融合,完成原始特征的重新標定。
具體結(jié)構(gòu)如圖5所示,其中r為瓶頸比率(Ratio of channels of transform bottleneck),用于降低模塊參數(shù)量。GC-Model可表示為

圖5 全局上下文模塊結(jié)構(gòu)框圖Fig.5 Framework diagram of GC-Model
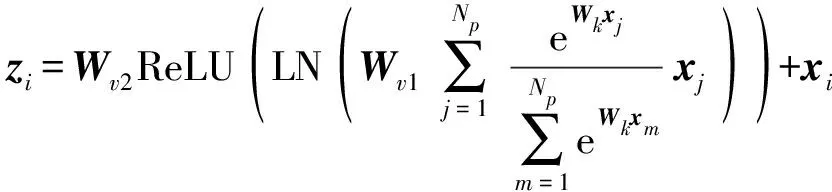
(3)
式中xm——注意力位置的輸入矩陣
Wv1、Wv2——線性轉(zhuǎn)換矩陣

Wv2ReLU(LN())——特征轉(zhuǎn)換函數(shù)
GC-Model是輕量級的特征增強模塊,能夠獲取全局上下文特征,且能靈活地嵌入到任何一個現(xiàn)有的網(wǎng)絡結(jié)構(gòu)當中,適用性較好。本文將GC-Model與級聯(lián)目標檢測網(wǎng)絡結(jié)合,用于提升網(wǎng)絡模型的檢測性能。
2.4 GC-Cascade R-CNN
GC-Cascade R-CNN目標檢測模型如圖6所示。GC-Cascade R-CNN使用深度殘差網(wǎng)絡[30](Residual neural network,ResNet)作為特征提取網(wǎng)絡,在Conv3、Conv4和Conv5階段嵌入GC-Model;構(gòu)建長距離依賴和通道依賴,增強原始特征信息。輸出特征圖經(jīng)特征金字塔融合后輸入到RPN當中。

圖6 GC-Cascade R-CNN結(jié)構(gòu)框圖Fig.6 Framework diagram of GC-Cascade R-CNN
經(jīng)過RPN篩選候選區(qū)域后,將映射到原圖的感興趣區(qū)域(Regions of interest,ROI)通過ROI Align[26]層進行區(qū)域特征聚集轉(zhuǎn)換為固定尺寸,最終輸入到全連接層進行分類和邊框回歸。推理時通過前一個檢測器輸出的邊框回歸對候選區(qū)域進行重采樣,逐步提升IoU閾值,提升樣本采樣質(zhì)量和網(wǎng)絡訓練結(jié)果。得到檢測結(jié)果后,統(tǒng)計圖像中相關病斑計數(shù)值。
主干特征提取網(wǎng)絡結(jié)構(gòu)具體如表1所示。其中,瓶頸結(jié)構(gòu)(Bottleneck)是一種用來減少參數(shù)數(shù)量的殘差網(wǎng)絡結(jié)構(gòu),由2個1×1卷積、1個3×3卷積和1個殘差連接組成。

表1 主干特征提取網(wǎng)絡結(jié)構(gòu)Tab.1 Backbone network structure
3 實驗與結(jié)果分析
3.1 實驗設置
實驗操作平臺為高性能服務器,運行環(huán)境Windows 10。處理器為Intel Xeon E5-2650 v4,主頻 2.20 GHz。32 GB內(nèi)存,顯卡為NVIDIA GeForce GTX 1080Ti,運行顯存為11 GB,使用GPU加速。在Python 3.7編程環(huán)境下使用Pytorch深度學習框架,版本為1.3.0。

圖7 損失函數(shù)曲線Fig.7 Loss function curve
模型訓練時,損失函數(shù)采用隨機梯度下降法(Stochastic gradient descent,SGD)。初始學習率(Learning rate)設置為0.002 5,權重衰減系數(shù)(Weight decay)為0.000 1,動量因子(Momentum)為0.9,迭代次數(shù)為60 000。當?shù)螖?shù)為40 000、50 000時,將學習率調(diào)整為0.000 25和0.000 025。訓練在前500次迭代時采用預熱(warmup)策略,在初始使用較小學習率而后期切換為較大學習率,提升模型訓練的穩(wěn)定性。梨葉病害病斑數(shù)據(jù)集上GC-Cascade R-CNN損失收斂情況如圖7所示。模型訓練時收斂速度較快,在迭代次數(shù)不到10 000已達到損失最低點,后續(xù)曲線進入振蕩階段,但幅度不大,最后趨于平穩(wěn)收斂。
3.2 病斑計數(shù)實驗
3.2.1梨葉病斑檢測實驗
為了驗證GC-Cascade R-CNN模型對于梨葉片病害病斑檢測的效果,分別使用RetinaNet[31]、Faster R-CNN[13]、Libra R-CNN[32]和Cascade R-CNN[21]等目標檢測算法進行梨葉病斑檢測實驗對比,驗證本文目標檢測模型的有效性和實時性。基本網(wǎng)絡IoU閾值設置為0.5,級聯(lián)網(wǎng)絡中IoU閾值則設置為0.5~0.7。使用Soft-NMS[33]算法,默認重疊閾值為0.5。模型使用平均精確率(Average precision,AP)作為本次實驗目標檢測結(jié)果的評價指標,梨葉病害數(shù)據(jù)集上的檢測結(jié)果如表2所示。

表2 不同目標檢測網(wǎng)絡檢測結(jié)果對比Tab.2 Comparison of detection results of different target detection networks
骨干網(wǎng)絡R50-FPN表示主干特征提取網(wǎng)絡使用ResNet-50網(wǎng)絡,并使用FPN進行特征融合。對于不同種類的病斑,GC-Cascade R-CNN的平均精確率均高于其他算法,平均精確率均值達89.4%。與Faster R-CNN相比,銹病的平均精確率提升了3.7個百分點,黑星病平均精確率提升了4.5個百分點,褐斑病平均精確率提升了3.9個百分點,炭疽病平均精確率提升了4.5個百分點。與Cascade R-CNN相比,除炭疽病平均精確率提升了2.3個百分點,其他3類病斑平均精確率提升均不到1個百分點。由此可知,當網(wǎng)絡復雜達到一定程度時,全局上下文特征模塊對小目標檢測的提升幅度大于一般目標檢測。
隨著模型復雜度的提升,平均檢測時間相應會有所增加。GC-Cascade R-CNN模型對每幅圖像的平均檢測時間為0.347 s,雖然略慢于之前的網(wǎng)絡模型,但基本保持了檢測實時性。

圖8 梨葉病害病斑檢測結(jié)果Fig.8 Detection results of pear disease spot
梨樹葉片病害病斑檢測結(jié)果如圖8所示。因為原圖的尺寸較大,未標明各類病斑標簽信息,僅用不同顏色區(qū)分。炭疽病斑尺寸較小,在原圖里肉眼可能無法完全分辨,特征提取時深層的特征信息較少,經(jīng)全局上下文模塊增強特征后,檢測性能提升最為明顯。銹病、黑星病和褐斑病相對炭疽病的尺寸較大,特征信息較豐富,檢測性能提升較小。

圖9 梨葉斑點炭疽病斑檢測對比Fig.9 Comparison of pear anthrax spot detection
為了便于觀察炭疽病斑的檢測效果,測試集中某幅圖像的檢測結(jié)果如圖9所示。RetinaNet算法忽略了大部分的病斑,檢測性能較差。Faster R-CNN算法雖檢測出了葉片上的大部分病斑,但依舊存在漏檢現(xiàn)象。Cascade R-CNN算法和GC-Cascade R-CNN算法的檢測結(jié)果基本一致,完全檢測出了所有病斑。仔細觀察,Cascade R-CNN存在多個重疊病斑重復檢測的情況,影響病斑計數(shù)結(jié)果。以上結(jié)果表明GC-Cascade R-CNN的檢測結(jié)果更精確,更適合病斑計數(shù)任務。
3.2.2GC-Model消融實驗
本文針對梨葉數(shù)據(jù)集中的斑點炭疽病這一類小目標數(shù)據(jù),進行GC-Model消融實驗,來驗證該模塊的影響。將它以相同的方式插入到RetinaNet、Faster R-CNN和Libra R-CNN中,探究其對檢測結(jié)果的影響。
表3比較了嵌入GC-Model前后的檢測性能。結(jié)果顯示,嵌入模塊后的平均精確率顯著提升,達到2.5個百分點左右。說明全局上下文特征模塊在特征增強方面存在明顯優(yōu)勢。

表3 不同網(wǎng)絡結(jié)構(gòu)檢測性能對比Tab.3 Comparison of detection performance of different network structures
為了驗證GC-Model在主干特征提取網(wǎng)絡不同階段嵌入的影響,在ResNet-50的Conv3、Conv4、Conv5階段分別單獨嵌入和組合嵌入,以Cascade R-CNN為基準網(wǎng)絡進行實驗對比,骨干網(wǎng)絡使用R50-FPN。
表4為不同嵌入階段的檢測性能。得益于全局上下文模塊的使用,平均精確率都有一定的提升,在Conv4階段和Conv5階段嵌入實現(xiàn)了比Conv3階段更好的性能,表明深層次的高度語義特征可以從全局上下文特征中增強更多。雖然平均檢測時間略有增加,但本文算法將GC-Model組合嵌入Conv3、Conv4、Conv5階段比只嵌入單個階段具有更高的檢測性能。

表4 不同嵌入階段檢測性能對比Tab.4 Comparison of detection performance at different embedding stages
3.2.3多尺度訓練實驗
為了模擬多尺度訓練對炭疽病斑檢測的影響,對單尺度輸入圖像和多尺度輸入圖像進行了實驗[30]。對于單尺度尺寸,使用400像素×400像素、500像素×500像素和600像素×600像素。多尺度尺寸采用單尺度尺寸的相關組合,從指定的比例尺搭配中選擇任何可重復項來進行訓練。檢測結(jié)果見表5。

表5 不同尺度尺寸訓練后檢測結(jié)果對比Tab.5 Comparison of test results after training with different scales
從表5可看出,在單尺度模式下,500像素×500像素圖像尺寸下訓練的模型平均精確率最高。本文模型是單尺度模式訓練模型。為了達到最佳檢測性能,將圖像分區(qū)中滑動窗口分區(qū)尺寸的N設置為500,即網(wǎng)絡輸入尺寸設置為500像素×500像素。多尺度模式訓練模型平均精確率達87.8%,高于所有單尺度模式訓練模型的性能表現(xiàn)。這表明多尺度訓練方法可以有效地增加檢測目標的覆蓋范圍,從而提高檢測性能。
3.2.4不同種類病斑計數(shù)結(jié)果
基于目標檢測結(jié)果得到梨葉樣本圖像上相關病斑的個數(shù)。將數(shù)據(jù)集中各類梨葉病害的單幅病斑計數(shù)值與真實值進行對比,采用線性回歸對結(jié)果進行分析。各類病害單幅圖像計數(shù)值與真實值的擬合結(jié)果如圖10所示。

圖10 病斑計數(shù)預測值與真實值的比較Fig.10 Comparisons of pear disease spot counting results between measured and calculated values
從擬合結(jié)果看,決定系數(shù)R2均大于0.92,表明本文方法對各類梨葉病斑的計數(shù)值與真實值具有顯著的線性相關性,計數(shù)準確度較高,適用于果園實拍梨葉病害圖像的病斑計數(shù)任務,有利于實現(xiàn)自動化病害診斷,精準農(nóng)藥噴灑,保障梨樹果實的質(zhì)量和產(chǎn)量。
4 結(jié)論
(1)針對梨樹病斑計數(shù)誤差較大、效率較低的問題,提出一種快速準確的梨葉片病害病斑計數(shù)網(wǎng)絡GC-Cascade R-CNN。實驗結(jié)果表明,模型的平均精度均值達89.4%,高于流行目標檢測模型。模型病斑計數(shù)值與真實值回歸擬合的決定系數(shù)均大于0.92,說明該模型能夠有效改善梨葉片病害病斑計數(shù)難題,實現(xiàn)梨葉病害發(fā)生程度的準確診斷。
(2)GC-Cascade R-CNN具有較快的推理速度,單幅圖像平均檢測時間僅為0.347 s,可滿足實時診斷的需求,實現(xiàn)梨葉病害發(fā)生程度的高效評估,具有一定的應用價值。
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
