融合多環境參數的雞糞氨氣排放預測模型研究
2022-06-21 08:22:12丁露雨李奇峰王朝元余禮根宗偉勛
農業機械學報 2022年5期
丁露雨 呂 陽 李奇峰, 王朝元 余禮根 宗偉勛
(1.清遠市智慧農業農村研究院, 清遠 511500; 2.國家農業信息化工程技術研究中心, 北京 100097;3.中國農業大學水利與土木工程學院, 北京 100083; 4.清遠市農業科學研究所, 清遠 511500)
0 引言
氨氣(NH3)是密閉雞舍主要的有害氣體,生產中由于通風不足或通風不及時,常出現有害氣體濃度累積、空氣質量差的問題,嚴重制約了畜禽健康生產[1-4]。隨著我國畜牧業的不斷發展,數字化、福利化養殖成為了畜牧業升級轉型的發展方向[5],有效預測舍內NH3濃度可輔助通風量需求計算、評估舍內空氣質量,及時、合理地調控舍內NH3水平,對畜禽健康生產具有重要意義。
目前,畜禽舍NH3預測模型的研究大致包括兩類,第一類是直接預測舍內NH3濃度的模型。例如,文獻[6]結合長短時記憶神經網絡(LSTM),使用隨機森林(RF)對影響NH3濃度的環境變量進行重要性排序,然后構建雞舍NH3濃度預測模型。文獻[7]提出基于粒子群算法-優化深度神經網絡算法(PSO-DNN)預測冬季平養雞舍NH3濃度,并證明該模型的預測精度高于現有的隨機森林模型。舍內NH3濃度受其排放量和舍內通風量的影響,現有研究中建立的NH3濃度預測模型大都沒有考慮環境調控設備運行狀態和氣體排放量水平,且數據量有限,所建立的模型泛化能力和魯棒性較差,無法直接對設備運行狀態予以調控指導和決策指令。第二類是預測NH3產生量或排放量的模型[8-11]。這類模型通過排放機理或統計分析預測NH3排放水平,結合動物環境需求可以獲得環境調控參數(如通風量),指導設備進行環境調控。然而,現有模型存在參數數量多或沒有考慮動物個體及環境因素不確定性對NH3排放影響的問題,不同生產條件下的預測誤差大。
NH3排放過程中常伴隨著其他氣體的釋放,相同條件下,畜禽生產中各類氣體的排放具有相關性,可以考慮結合氣體產生與釋放的機理過程,引入其他易測氣體的排放量,用于預測NH3排放[12-14],這有利于代替部分不確定因素的影響,使得預測結果更具有可靠性。本文選取相對易于測量且能代表動物及環境變化不確定性影響的變量參數(溫度、相對濕度、H2O排放量、CO2排放量)作為輸入特征,利用機器學習方法建立肉雞糞NH3排放預測模型,對比不同模型類別對NH3排放的預測效果,以期為日常畜禽舍環境管理提供模型參考。
1 材料與方法
地面墊料平養是國內常見的一種肉雞飼養方式,該模式投資少、成本低、易于管理,但糞便在舍內堆積時間長,舍內NH3濃度較高,尤其是冬季通風量較小時,易誘發呼吸道疾病。本文在實驗室條件下模擬平養肉雞舍冬季NH3排放過程,測試糞便發酵過程中NH3、CO2、H2O濃度及排放量,用于建立NH3排放估計模型的數據集,利用不同的輸入參數和模型開展對比研究,構建NH3排放量估計模型,試驗流程如圖1所示。

圖1 試驗流程圖Fig.1 Flow chart of experiment
1.1 氣體排放測試與數據采集
1.1.1試驗裝置
肉雞舍氣體排放試驗裝置如圖2所示。該試驗裝置尺寸(長×寬×高)為0.86 m×0.45 m×0.65 m,參照動態箱原理設計,由亞克力材料制成,內部設置有直徑0.34 m、高0.2 m圓柱型雞糞容器以及雞糞攪動耙、手工操作窗口等設施,便于模擬肉雞對雞糞的踩踏及雞糞與墊料的混合。箱體兩側各設9個進出氣孔,一側為進氣面,對側作為出氣面連接氣泵模擬機械通風,通氣量為0.618 m3/h,出氣口管路中接流量計監測箱內通氣量。為防止出氣孔氣體影響模擬環境各項參數數值,氣泵出氣口設置延長管將廢氣排至室外。

圖2 試驗裝置實物圖Fig.2 Demonstration of experimental setup
1.1.2數據采集與計算
肉雞舍氣體排放模擬試驗地點位于中國農業大學上莊試驗站內,試驗共計12 d。試驗初始時,裝置內鋪加墊料并放置3 000 g雞糞,之后每日向試驗箱內添加雞糞150 g,每日采集進、出氣口NH3、CO2、H2O等氣體濃度(質量比)。箱內設置溫濕度自動記錄儀(艾普瑞(上海)精密光電有限公司)記錄箱內溫度T及相對濕度,采集頻率2次/min。試驗裝置進、出氣口設有氣體采樣點,通過INNOVA 1403型多路器(LumaSense Technologies公司,美國)及INNOVA 1512i型光聲譜多氣檢測儀(LumaSense Technologies公司,美國)進行氣體連續、循環采樣及濃度檢測。每次測量約1 min,前20 s為管道沖洗,后40 s為氣體濃度分析,每個點測3次,進、出口采樣點交替采集,去掉第1次測量結果,取后2次平均值為該采樣點當前氣體濃度。
每日開蓋添加雞糞對排放系統有一定影響,取到達穩態時的相同時間階段(每日15:30至次日09:25)進行數據分析,共444組數據計算氣體排放量。排放量計算公式[15]為
(1)
式中E——目標氣體排放量,mg/(kg·h)
Co——試驗裝置出氣口采樣點氣體濃度,mg/m3
Ci——試驗裝置進氣口采樣點氣體濃度,mg/m3
V——通氣量,m3/h
M——每日雞糞量,kg
1.2 NH3排放預測模型
1.2.1參數選擇
(1)CO2和H2O
從NH3產生機理考慮,雞糞的尿酸分解是雞舍內NH3產生的主要途徑,因為家禽的肝臟中沒有精氨酸酶和氨甲酰磷酸合成酶,不能通過尿素循環把體內代謝產生的氨合成尿素,只能在肝臟和腎臟中合成嘌呤,并在黃嘌呤氧化酶的作用下生成尿酸[16]。尿酸在多種微生物酶的作用下水解成尿素和乙醛酸,最后尿素在脲酶的作用下產生NH3和CO2,尿酸生成NH3的反應式如圖3所示[17-18]。

圖3 尿酸分解變成氨氣的過程Fig.3 Decomposition of uric acid into ammonia
分析雞糞產生NH3的機理及其產生后排放的機理可以看出,NH3的產生伴隨著CO2的生成,而NH3揮發與H2O揮發密不可分。相比于NH3濃度,CO2濃度和相對濕度更容易實現低成本和高精度的測量,且傳感器壽命相對于傳統的NH3濃度電化學傳感器長,維護成本更低。因此,選取H2O排放量(EH2O)及CO2排放量(ECO2)作為環境參數參與模型構建。
(2)溫度T和相對濕度H
溫度、相對濕度是影響畜禽糞便NH3產生與揮發的關鍵環境參數。大量研究冬季畜禽舍內溫濕度與有害氣體分布規律的結果表明,NH3濃度與溫、濕度具有顯著相關性[20-21]。當處于冬季低溫條件時,雞舍的保溫需求會與通風形成較為明顯的矛盾,通風不足時舍內的NH3濃度和相對濕度會產生相互影響。文獻[21]研究冬季溫、濕度對平養雞舍NH3濃度影響時發現:NH3濃度與T有較強的正線性關系,當舍內環境溫度上升時,大部分情況下NH3濃度也會上升;當處于不通風階段時,舍內NH3濃度會與相對濕度形成負線性相關,隨相對濕度的下降而升高,這可能是由于NH3易溶于水[22],濕度較大時,會有部分NH3隨之溶解。
1.2.2模型選擇
機器學習以數據為研究對象,監督學習作為機器學習的重要組成部分,可以從標簽數據中學習模型。標簽數據表示輸入、輸出的對應關系,預測模型對給定的輸入產生相應的輸出,監督學習的本質是學習輸入到輸出的映射規律統計[23]。
以與雞糞NH3排放相關的環境參數為特征數據,以 NH3作為標簽數據,目的是從T、H、EH2O、ECO2等特征數據中學習對應關系,使其能夠預測標簽數據,該種模型是典型的監督學習模型。其中,輸入變量(T、H、EH2O、ECO2)和輸出變量(氨氣排放量ENH3)均為連續變量,這類預測問題成為回歸問題,對應模型為非概率模型。因此,采用監督學習的方法建模,考慮到數據量只有444條,不適用于大規模的參數訓練,所以使用統計學習——即統計機器學習的方法進行模型構建。
雞糞NH3排放預測模型由數據直接學習決策函數,所以屬于監督學習中的判別模型。依據模型特點,選擇較為常用的判別模型對雞糞NH3排放進行預測,包括廣義線性回歸模型、內核嶺回歸、決策樹及集成方法(隨機森林、極限隨機樹、AdaBoost回歸、梯度提升回歸)8個模型,對比各個模型在雞糞NH3排放預測中的決定系數R2。
1.2.3模型訓練
采用Python語言sklearn庫進行模型訓練,訓練過程中的數據集劃分方式、超參數選擇對模型訓練結果至關重要。
(1)數據集劃分
模型訓練采取10折隨機排列交叉驗證的方法進行數據集劃分,即對數據集隨機抽樣選出訓練集和測試集,進行10次的評估和測試,最終對10次的結果取均值,得到最終的模型評價結果。該方法可以增強模型結果的可信度、減少數據集劃分對模型訓練的影響[24]。
(2)超參數
訓練模型中,決策樹及集成模型的訓練涉及超參數選擇問題。超參數的選擇關系到預測結果的優劣,好的模型參數會提升模型的效果,所以模型參數的選擇至關重要。超參數不能在模型中自動學習,需要在訓練過程中結合多種評價指標進行選擇。使用網格追蹤法尋找超參數的最優值,并結合所采用的學習機方法進行微調,選擇一組最優超參數。本文涉及到的主要超參數如表1所示。

表1 本文模型中涉及的主要超參數Tab.1 Hyperparameters involved in different models
1.3 模型評價指標
使用預測模型的決定系數R2、均方根誤差(RMSE)、平均絕對百分比誤差(MAPE)作為評價指標[10],測試不同模型對雞糞NH3排放量的預測效果。
2 結果與討論
2.1 氣體排放測試數據

圖4 雞糞氣體排放測試數據Fig.4 Chicken manure gas emission test data
氣體排放測試期間,動態箱內平均溫度、相對濕度分別為(6.1±1.1)℃、(69.9±5.4)%,期間的平均NH3、CO2及H2O排放量分別為(3.2±0.9)mg/(kg·h)、(147.5±61.6)mg/(kg·h)、(184.1±43.9)mg/(kg·h)。測試期間,T、相對濕度、ENH3、ECO2和EH2O的變化趨勢如圖4所示。試驗開始時,雞糞進行發酵反應,前4 d時NH3排放量隨時間上升并達到最高點,然后大幅下降,之后每日隨雞糞不斷添加,重復以上趨勢。同時,通過與其它環境參數曲線進行對比觀察發現,NH3排放量的數量級遠小于CO2和H2O,但3種氣體排放量的變化趨勢幾乎一致,這說明EH2O、ECO2比ENH3相對更容易實現準確檢測,研究中選擇的T、H、EH2O、ECO2這4個自變量對ENH3預測有較好的可解釋性和代表性。
2.2 不同預測模型對比
結合已有超參數的選擇方法、各模型超參數的數量及范圍,在確保準確度的前提下,使用網格追蹤法尋找左右超參數并進行微調。不同模型最佳超參數選擇后的結果如表2所示。

表2 不同樹模型選用的超參數值Tab.2 Hyperparameter values selected by different tree models
在最佳超參數選擇的基礎上,分析各模型以T、H、EH2O、ECO2為自變量預測ENH3的評價指標(表3)發現,嶺回歸、彈性網絡、內核嶺回歸預測氨氣排放量的效果很差,決定系數均不足0.2,預測誤差大,而樹模型和同質集成的樹模型的結果較好,其中極限隨機樹模型表現最優。

表3 不同模型評價指標Tab.3 Evaluation indexes of different models
極限隨機樹也是一種集成方法,使用多個樹來預測樣本,圖5為集成模型中的一顆子樹。該子樹是一顆關于所選參數的決策樹,該樹只顯示了前4層,記錄著分割的特征和對應的分割點。計算分割點的方法中,進一步增強了分割點的隨機性,利用的特征是候選特征的隨機集合。根據所有候選特征任意生成分割點,在生成的分割值中選擇最佳的點進行分割。這種方法通常可以減小模型的離散度,所以極限隨機樹在多個模型中表現最好。
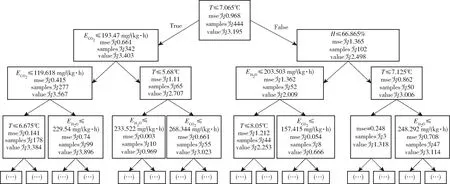
圖5 樹模型結構圖Fig.5 Structure diagram of tree model
選擇表3中性能較好的樹模型作為預測模型對測試集數據進行驗證分析,預測結果與實測結果對比如圖6所示。使用T、H、EH2O、ECO2作為影響因子參與建模時,決策樹、隨機森林、極限隨機樹、AdaBoost回歸、梯度提升回歸的平均殘差百分比分別為(3±4.6)%、(4±3.7)%、(3±3.5)%、(6±4.8)%、(5±4.5)%。可見,各模型預測NH3排放量時多表現為高估,其中決策樹和極限隨機樹平均殘差百分比最低,但決策樹模型的殘差百分比標準差更高,故而模型的穩定性不如極限隨機樹,極限隨機樹模型的預測效果最佳。

圖6 各類樹模型預測結果對比Fig.6 Comparison of prediction results of various tree models
2.3 參數
2.3.1參數重要性
特征重要性和排列重要性分析可以判別各參數對模型的重要程度。特征重要性是指特征(即輸入參數)對預測結果的影響,是模型對每個特征重要程度的描述。排列重要性是隨機打亂某個特征之后,衡量該特征對模型的影響,從而得出特征的重要性。
選取表現最好的極限隨機樹作為分析對象,利用排列重要性和特征重要性分析T、H、EH2O、ECO2在建模過程中的重要程度,探究NH3排放量預測的機理知識與模型重要性的聯系。

圖7 特征重要性和排列重要性圖Fig.7 Feature importance and permutation importance charts
從圖7可以看出,EH2O在NH3排放預測中起著重要作用,這可能是因為NH3易溶于水,在今后的研究中可以重點關注EH2O與ENH3之間的相互作用關系。T和ECO2在特征重要性和排列重要性兩方面評價中,影響程度并不對應相同,雖然排名有所變化,但不能一定說明ECO2比T的影響程度大。因為測試時環境溫度相對比較穩定,變化幅度較小(變異系數18.0%),而ECO2的變化相對更大(變異系數41.8%),因此,隨機打亂T和ECO2兩個特征后預測的結果變化幅度不同。此外,糞便發酵過程中CO2的產生具有溫度依賴性,T變化后,EH2O也會隨之變化。
綜上所述,如果同一個特征在不同的評價方法中都重要,那么該特征就應該重點關注。在本次試驗中,兩種評價方法中EH2O的得分都很高,因此,不同參數組合時,模型中都需要考慮EH2O。
2.3.2模型對特征變量的依賴性
通過個體條件期望圖(Individual conditional expectation,ICE)和部分依賴圖進行依賴性分析,即某一特征變量的值變化對NH3排放量預測值的影響。
個體條件期望圖是用來可視化分析目標響應和一組輸入特征變量之間的交互作用,可以分析目標函數與輸入的特征變量之間的依賴性。設xs為輸入特征集合(即特征參數),xc為其補集。響應f在xs處的部分依賴性定義為
(2)

圖8所示分別為T、H、EH2O、ECO2為研究對象的條件期望圖,即變化其中一個環境參數的取值,保留其他參數取值不變,運用訓練完成的極限隨機樹模型預測ENH3的結果。圖中,測試數據集樣本為50個樣本,細線代表每條數據,粗線代表所有細線的均值。曲線越陡峭,說明該參數對于模型越重要,反之,對模型重要性越低。

圖8 個體條件期望圖(ICE)Fig.8 Individual conditional expectation graph
從圖8中可以看出,當T<6.5℃時,T的ICE曲線變化平緩,說明T變化,其余值不變的情況下,ENH3的預測值幾乎不變,即T的變化對ENH3的預測結果影響不大;當T>6.5℃時,T與ENH3大致呈線性的負相關關系。EH2O的變化最陡峭,說明EH2O在預測ENH3的過程中貢獻度最大。
部分依賴圖與個體條件期望圖相似,區別在于研究對象的抽取方式不同,個體條件期望圖抽取數據的方式符合數據分布特征,部分依賴圖是按照等間隔方式抽取數據并計算。這能夠展現出兩個特征變量對模型預測影響的函數關系:近似線性關系、單調關系或者更復雜的關系。為了更加形象地觀察特征組合與模型之間的交互作用,在三維空間內用兩個特征的相互作用繪制部分依賴圖。
由圖9可以看出,相比于單個變量,同時考慮兩個變量的影響時,變量與模型之間的交互變得更為復雜。以EH2O和ECO2為例,在EH2O小于200 mg/(kg·h)時,ECO2對ENH3的作用與單變量時的趨勢大致相同,但是當EH2O大于200 mg/(kg·h)時,EH2O的影響占據主導地位,ECO2在該段的影響幾乎可以忽略。這也體現出變量影響之間的一個原則:模型中表現強的變量會掩蓋掉表現弱的變量。

圖9 三維空間內的部分依賴圖Fig.9 Partial dependence diagram in three dimensional space
2.4 環境參數融合對模型的影響
2.4.1水汽壓差
T和H度二者間存在互作關系,當空氣中H不變時,T升高會使得H降低。NH3排放研究中,常使用水汽壓差(VPD)來表征T和H二者對NH3排放的共同影響[25]。因此,將模型參數進一步簡化,利用VPD代替T和H,探索模型的預測效果。
VPD是空氣中水汽分壓力與飽和水汽壓之間的差值,可通過T和H計算獲得[26],公式為
(3)
式中V——水汽壓差,kPa
計算后,氣體排放測試時的VPD變化曲線如 圖10所示。
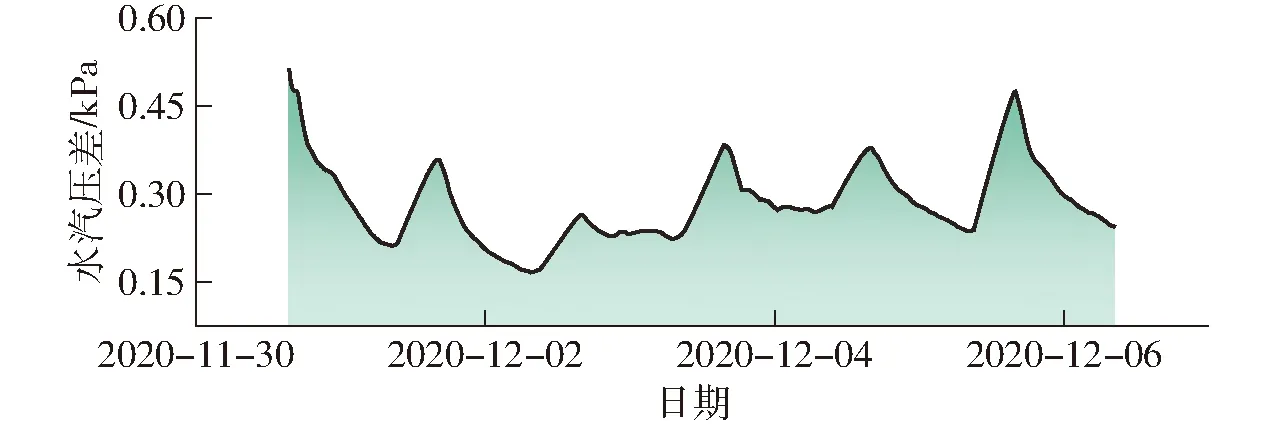
圖10 雞糞氣體排放測試期間的VPD變化曲線Fig.10 VPD during experiment of gaseous emissions from chicken manure
2.4.2水汽壓差對模型的影響
為了探索衍生參數對模型準確率的影響,選用VPD、EH2O、ECO2等3個自變量的不同組合進行建模嘗試,具體組合方式為:VPD、EH2O、ECO2;VPD、EH2O;VPD、ECO2。
對比包含VPD的參數組合與T、H、EH2O、ECO2的參數組合,不同特征變量利用極限隨機樹模型預測ENH3的決定系數R2如圖11所示。

圖11 不同參數組合特征輸入時模型的決定系數Fig.11 R2 of model when different parameter combination features were input
從參數數量上看,相同模型隨著參數數量的變少,模型的R2呈降低的趨勢。各模型的預測效果并沒有隨著引入VPD而有所提升,甚至有所降低。這可能是因為本研究中所選用的模型參數較少,樹模型可選的參數較為單一,最后構建出的樹模型差異性不大,影響了樹的多樣性,進而導致了參數數量與評價指標得分之間成正比的結果。從最優模型的選擇角度來看,不同參數組合時,仍然是各類樹模型的擬合效果更好,最佳模型仍然是極限隨機樹模型,也體現了極限隨機樹模型的預測準確性。
綜合不同模型種類和參數組合的建模效果可知,采用極限隨機樹模型且以T、H、EH2O、ECO2為模型特征變量輸入時,ENH3的預測效果最好。
2.5 模型應用
(1)模型應用條件
應用中,上述模型的特征參數EH2O、ECO2為糞便揮發所產生[27-28],因此,該模型不同條件的應用方式不同。當模型應用場景的氣體排放源僅為糞便時可直接使用模型估計NH3排放量,如糞便貯存、堆肥過程中NH3排放量估計、缺失值填充等。當模型應用場景的氣體排放源包含糞便和動物時,需對測得的EH2O、ECO2進行校正,扣除肉雞自身產生的CO2和水汽后再輸入模型進行測算,如肉雞舍氨氣排放量預測、以改善空氣質量為目標的通風量測算等。根據國際農業工程學會國際農業工程委員會(CIGR),肉雞生產中排放的CO2和水汽量可通過肉雞產生的顯熱、潛熱和總熱量,利用已有模型進行計算[29-30]。
(2)模型應用優化
本文中參與模型構建的數據量及各參數變化范圍有限,模型應用中可能會存在一些局限。由2.3.1節可知,當EH2O大于200 mg/(kg·h)時,ENH3預測值與EH2O之間有很強的依賴性。本研究中EH2O的范圍在110~270 mg/(kg·h)之間,當EH2O大于270 mg/(kg·h)時模型的準確度可能會有所變化。T是影響CO2、NH3、H2O排放的重要環境參數,本研究中T的變化范圍相對較小(4~8℃),進而出現了模型對T依賴性最弱的結果。從機理上看,T是影響氣體排放最主要的環境因素之一,作用程度遠大于相對濕度;當T從10℃以內上升到20℃以上后養殖場的氣體排放會增加數十倍[31-32]。當T大于10℃,如果直接使用前述模型可能會出現較大的誤差。
本研究構建的模型具有一定的自適應能力,鑒于上述局限的存在,應用中可通過增加數據量進行優化訓練,提高模型普適性。數據量的增加包括兩方面:一是擴大數據分布的范圍,二是增加各范圍數據的數量。文獻[33]在分類模型泛化能力的研究中發現,樣本數量的增加和樣本分布范圍的擴大,可以有效提升模型普適性,而且數據分布范圍的影響大于數據增量的影響[34]。因此,未來應用中優先考慮擴大數據分布范圍。例如,可以增加T大于10℃以上的環境數據和氣體排放數據,與原始數據混合訓練極限隨機樹模型,提高模型的普適性。
3 結論
(1)考慮到畜禽生產及糞便發酵過程中,NH3濃度及排放量存在數值小、傳感器腐蝕性高、不易采集的情況,本文結合NH3產生的機理和機器學習建模技術,利用相對較易采集的環境參數作為影響因子,對比了8種不同模型的預測效果,建立了墊料飼養條件下肉雞糞NH3排放量預測模型,為墊料飼養肉雞舍通風調控奠定模型基礎,也為糞便管理中肉雞糞NH3排放量預測提供模型支撐。
(2)通過預測模型結果對比發現,使用T、H、EH2O、ECO2作為特征輸入,以極限隨機樹為預測模型時,肉雞糞NH3排放量的預測效果最優,R2為0.916 7,ENH3預測的平均殘差百分比為(3±3.5)%。各特征參數中,EH2O對模型的影響最為重要。引入VPD代替T和H并不能得到更好的模型效果,甚至會降低模型預測的準確度。應用中,當排放源同時包括糞便和動物時,應當扣除肉雞自身產生的CO2和H2O,對EH2O、ECO2校正后再輸入模型中進行預測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
