基于深度神經網絡的豬咳嗽聲識別方法
2022-06-21 08:21:42沈明霞王夢雨劉龍申
農業機械學報 2022年5期
沈明霞 王夢雨 劉龍申 陳 佳 太 猛 張 偉
(1.南京農業大學工學院, 南京 210031; 2.江蘇智慧牧業裝備科技創新中心, 南京 210031)
0 引言
養豬業是畜牧業的重要組成部分[1],豬養殖生產中,對豬呼吸道疾病診療是主要工作基礎[2-3]。咳嗽是豬呼吸道疾病的主要早期癥狀[4],因此通過識別咳嗽聲進行豬早期呼吸道疾病預警成為當前關注點[5]。
國內外科研人員在識別豬只咳嗽聲方面的研究主要分為3類:一是基于一般聲學分析算法的咳嗽聲識別,GUARINO等[6]使用濾波器組結合振幅解調進行特征提取,通過動態時間規整算法(DTW)將這些特征向量與參考集進行比較,咳嗽聲識別正確率為85.5%。EXADAKTYLOS等[7]利用功率譜密度(PSD)研究病豬咳嗽聲的頻率特征,利用模糊C均值聚類算法對咳嗽和其它聲音分類,咳嗽聲識別正確率為82%。徐亞妮等[8]提取梅山母豬聲音信號的功率譜密度作為特征,提出了模糊C均值聚類算法的改進方法,對梅山豬的咳嗽聲與尖叫聲進行聚類分析,取到了較好的分類效果。二是基于傳統機器學習的咳嗽聲識別算法研究,原始的信號輸入往往只經過一層處理,模型結構簡單、易于學習,但對于較為復雜的信號處理能力具有局限性[9-12]。文獻[13-15]分別構建基于不同特征提取(LPCC、MFCC)的隱馬爾可夫(HMM)模型和矢量量化(VQ)模型對豬咳嗽聲進行識別,都取得了一定成果。三是基于深度學習技術的豬咳嗽聲識別,深層神經網絡被廣泛應用于醫學影像分析、農作物識別、人臉識別等各個領域[16-19]。YIN等[20]提出了一種基于AlexNet模型和譜圖特征的分類算法,總體識別準確率達到96.8%,F1值達到96.2%。SHEN等[2]通過將MFCC與多層CNN融合得到MFCC-CNN特征,總體識別準確率為96.6%,使用softmax和線性支持向量機(SVM)分類器進行分類后,咳嗽識別準確率分別提高了7.21%和3.86%,F1值分別提高了10.37%和5.21%。黎煊等[1]提出了基于雙向長短時記憶網絡-連接時序分類的聲學模型(BLSVM-CTC),利用五折交叉驗證試驗,豬咳嗽聲識別率為92.40%,誤識別率為3.55%,總識別率為93.77%。
現有研究成果表明將聲音信號轉換成聲譜圖,利用神經網絡進行識別,可有效提高識別精度[21-23]。本文通過譜減法對截取的豬只有效聲音段進行去噪,從而消除環境中的干擾噪聲,利用將聲音信號的短時能量和短時過零率作為特征參量的雙門限端點檢測法進行豬只有效聲音信號獲取,分別提取豬只咳嗽、鳴叫、噴嚏以及呼嚕聲的logFBank以及MFCC兩種聲音特征后,輸入CNNs和DFSMN兩類神經網絡模型進行豬咳嗽聲識別訓練,比較兩種特征提取方法對模型效果的影響,以及不同迭代次數的影響,最后進行4種聲音信號的四分類模型訓練。
1 數據采集與預處理
1.1 實驗對象
實驗數據采集自江蘇省鎮江市句容江蘇農博園梅山豬育種中心,采集時間為2018年6月,采集對象為10只2—3月齡、體質量(50±5)kg的梅山豬,其中5只體溫升高至40.5℃,表現為連續性咳嗽,呼吸增快,經專業飼養人員診斷為患病。另外5只為健康豬只,無咳嗽癥狀。
1.2 實驗設備
錄音設備為韓國現代數字E66型智能錄音筆,最大內存16 GB,音頻儲存格式為wav,采樣精度為16位,采樣頻率為48 kHz,每2 h保存為一個錄音文件,以年-月-日-時-分-秒格式命名。
1.3 數據采集
分別將患病豬只及健康豬只放置在2個相鄰豬舍內,將2支錄音筆分別懸掛于豬舍內距離地面高度約1.6 m處,共采集到有效錄音數據57 h。圖1為實驗數據采集現場圖。

圖1 實驗數據采集現場圖Fig.1 Pig house of experimental data collection
1.4 數據預處理與數據集劃分
本次實驗中豬舍采集到的音頻包含豬只的咳嗽、鳴叫、噴嚏、呼嚕聲等可用數據以及人聲、金屬器皿碰撞等其它環境噪聲,利用音頻處理軟件Adobe Audition(AU)進行有聲段截取,共截取有效聲音(咳嗽聲、呼嚕聲、鳴叫聲及噴嚏聲)536段。
譜減法是聲音信號處理過程中常用的去噪方法之一,將聲音信號類比為目標信號與噪聲信號的疊加,獲取聲音信號的前幾幀或靜默段作為噪聲信號,獲取平均噪聲能量,實現聲音信號的去噪處理。圖2為譜減法處理前后時長為10 s的連續咳嗽聲降噪效果波形對比圖,由圖2b可知,豬連續聲音信號噪聲得到明顯削減,并通過人耳試聽進一步驗證,豬聲音樣本沒有失真。

圖2 譜減法去噪前后豬咳嗽聲波形圖Fig.2 Sound waveform of pig cough before and after spectral subtraction denoising
利用將聲音信號的短時能量和短時過零率作為特征參量的雙門限端點檢測法對去噪后的536段錄音信號進行端點檢測,共得到咳嗽聲1 058個,其它聲音樣本420個,其中噴嚏聲184個,鳴叫聲121個,呼嚕聲115個。驗證集和測試集的數目分別設置為本類聲音樣本個數的10%,每次實驗進行隨機選取,剩余樣本設置為訓練集。表1為數據集劃分結果。
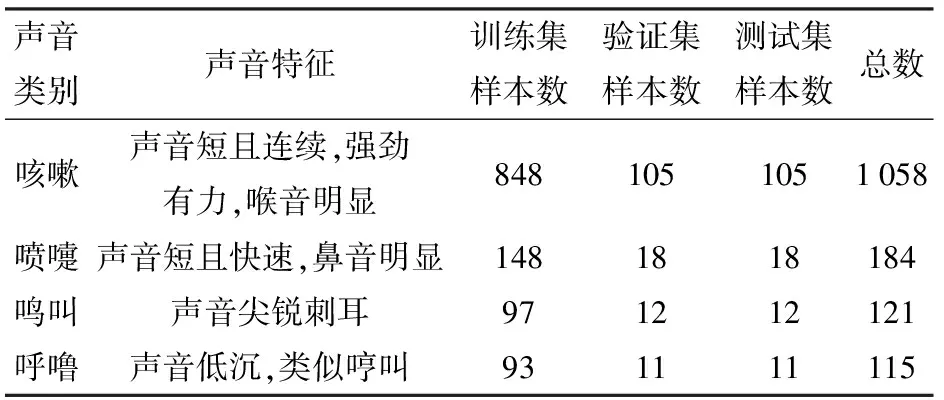
表1 數據集劃分結果Tab.1 Data set partitioning results 個
2 豬咳嗽聲識別
2.1 豬聲音特征參數提取
濾波器組(FBank)特征由于相鄰濾波器組有重疊,相鄰的特征高度相關,MFCC特征是在logFBank(FBank取對數)特征的基礎上再進行離散余弦變換(DCT)得到,具有更好的判別度。分別提取上述得到的聲音信號的logFBank和MFCC兩種音頻特征。通過實驗分析比較這兩種聲學特征對咳嗽聲識別模型效果的影響,提取的特征存儲為npy文件。圖3為算法整體流程圖,檢測樣本格式等信息正確后逐個提取特征并保存,否則跳過此樣本。

圖3 豬只聲音特征提取算法流程圖Fig.3 Flow chart of pig sound feature extraction algorithm
為了補償聲音信號中被壓抑的高頻部分,突出高頻的共振峰,需要在頻域上面乘以一個系數,預加重系數設置為0.97。預加重對噪聲無影響,提高了輸出信噪比,公式為
s′n=sn-ksn-1
(1)
式中s′n——預加重后的聲音信號
sn——n時刻聲音采樣值
sn-1——n-1時刻聲音采樣值
k——預加重系數
由于原始音頻樣本時間長度不固定,但具有微觀上的短時平穩性,為了便于傅里葉變換,加窗切分為固定長度的小片段。為了保證信號不失真,根據奈奎斯特采樣定律,采樣頻率設置為48 kHz,幀長設置為25 ms。為了避免窗邊界對信號的遺漏,幀與幀之間設置一部分重疊區域,即幀移設置為10 ms。采用漢明窗消除每一幀信號在其兩端出現的信號不連續問題,從而使傅里葉變換之后取得更高質量的頻譜。漢明窗計算公式為
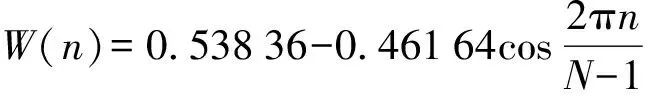
(2)
式中W(n)——漢明窗函數
N——信號總的采樣點個數
n——采樣點序號
加窗過程為漢明窗函數與原信號作乘積變換,公式為
S′(n)=W(n)S(n)
(3)
式中S(n)——原始幀信號
S′(n)——加窗后信號
為了方便深度神經網絡學習,需要將時域信號轉換到頻域,本實驗在每一幀進行2 048點短時傅里葉變換(Short time Fourier transform, STFT),計算公式為
(4)
式中Xn(W)——短時傅里葉變換頻域值
x(n)——第n個采樣點的采樣值
m——漢明窗長度ω——角頻率
R——窗口隨時間滑動的距離
W——漢明窗函數
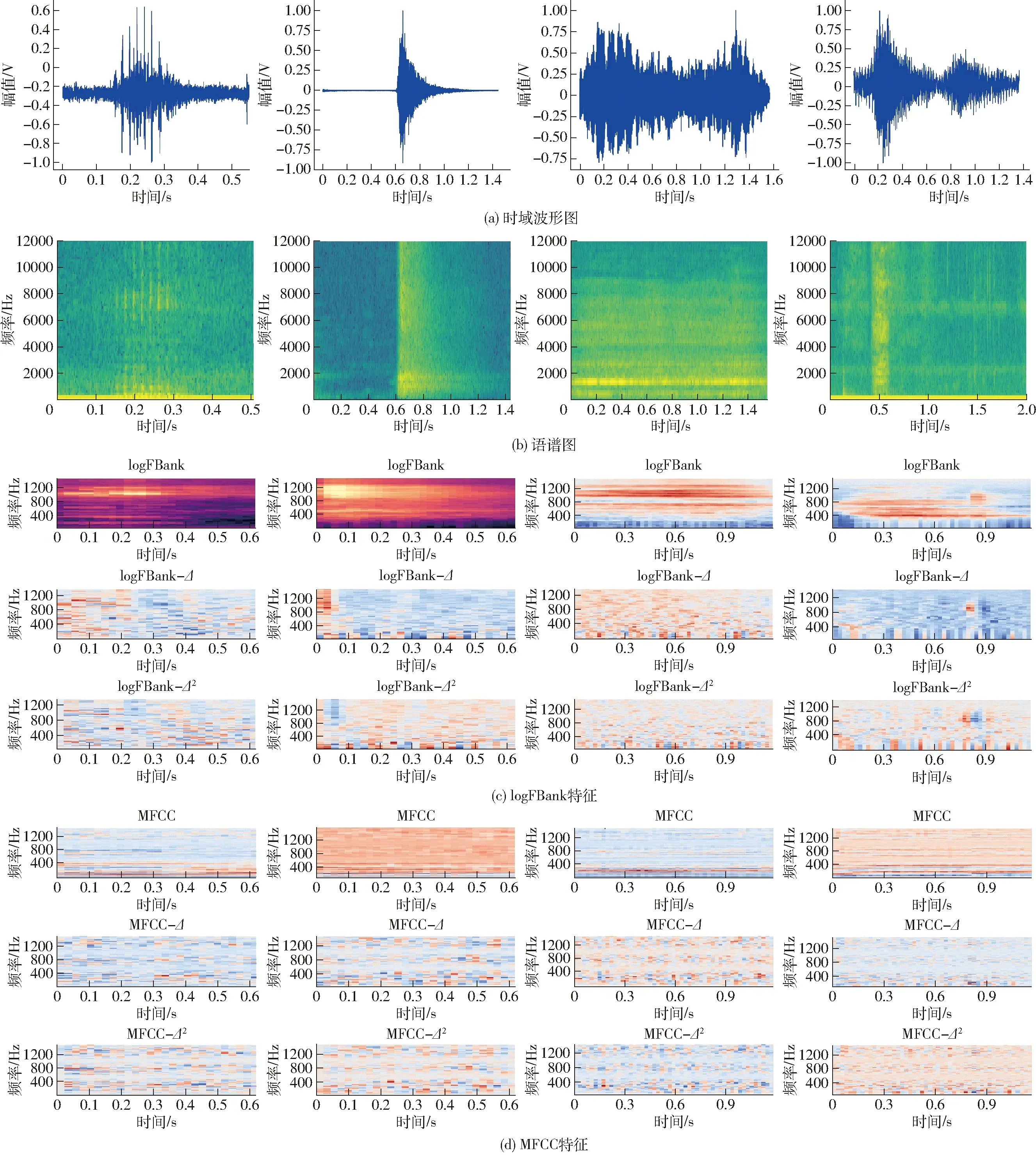
圖4 豬聲音時頻域特征轉換Fig.4 Feature conversion of pig sound in time-frequency domain
短時傅里葉變換后得到的幅度譜與每一個梅爾刻度濾波器進行頻率相乘累加,濾波器組個數設置為64。為了更接近人耳聽聲原理,濾波后取對數,最終得到logFBank特征。MFCC特征梅爾刻度濾波器組個數設置為128,離散余弦變換(DCT)后,返回倒譜數64個。最終將時域特征轉換到頻域,得到4種聲音信號的各兩種聲音特征,分別再對其求一階差分和二階差分,得到3個特征進行零-均值標準化(z-score)處理,轉換成三維數組作為咳嗽聲識別模型的輸入。
圖4為時頻域轉換結果,從左到右依次為呼嚕聲、噴嚏聲、鳴叫聲、咳嗽聲,圖中Δ為一階差分。通過對比分析4種聲音各自的時域和頻域特征圖可發現,不同聲音信號的語譜圖存在明顯差異,4種聲音信號的logFBank及MFCC特征也存在差異,這是本實驗進行分類識別的基礎。
2.2 豬咳嗽聲識別模型
采用提取的logFBank和MFCC及其一階、二階差分組合作為特征參數,分別經過CNNs和DFSMN兩種深度學習模型訓練后比較總體精確度、咳嗽聲和非咳嗽聲識別精確度、召回率及F1值等指標,綜合判定模型性能。圖5為深度神經網絡模型整體訓練流程圖。

圖5 模型訓練整體流程圖Fig.5 Overall process of model training
2.2.1基于CNNs的豬咳嗽聲識別模型
卷積神經網絡是目前比較流行的一種深度學習算法,在圖像特征提取、語音處理等領域效果優異。一個深層CNNs模型通常包含卷積層、激活層、池化層和全連接層。卷積層是用若干個卷積核進行卷積運算,即卷積核在二維特征數據上按特定步長滑動計算權重矩陣和掃描所得的數據矩陣的乘積,得到一個輸出,一層所有卷積核的個數即為本層卷積輸出通道數。激活層通常使用ReLU函數,用于非線性運算,使得神經網絡能更好地解決更加復雜的問題。
池化層通常在各個卷積層之間,降低各個特征的維度,減少過擬合,通常有最大池化(Max pooling)和平均池化(Average pooling)兩種形式,最大池化即把上層結果特征元素的最大值作為輸出,平均池化即將特征平均值作為下層輸入,本文選擇最大池化層。全連接層通常在模型尾部,所有神經元都有權重連接,用于特征分類。圖6為基于CNNs的豬只咳嗽聲識別模型的整體結構,包括3層卷積加最大池化層以及3層全連接層。
本文使用的CNNs模型包括3層卷積層,輸入通道數分別為3、32、32,輸出通道數分別為32、32、32,卷積核(kernel-size)均為3,步長(stride)默認為1,無填充(padding-mode)。激活層均采用ReLU函數,利用最大池化層(MaxPool2d)提取重要信息,減少計算量,kernel-size和stride均為2。全連接層輸入輸出通道數分別為576×256、256×256、256×2。模型具體參數結構如表2所示。
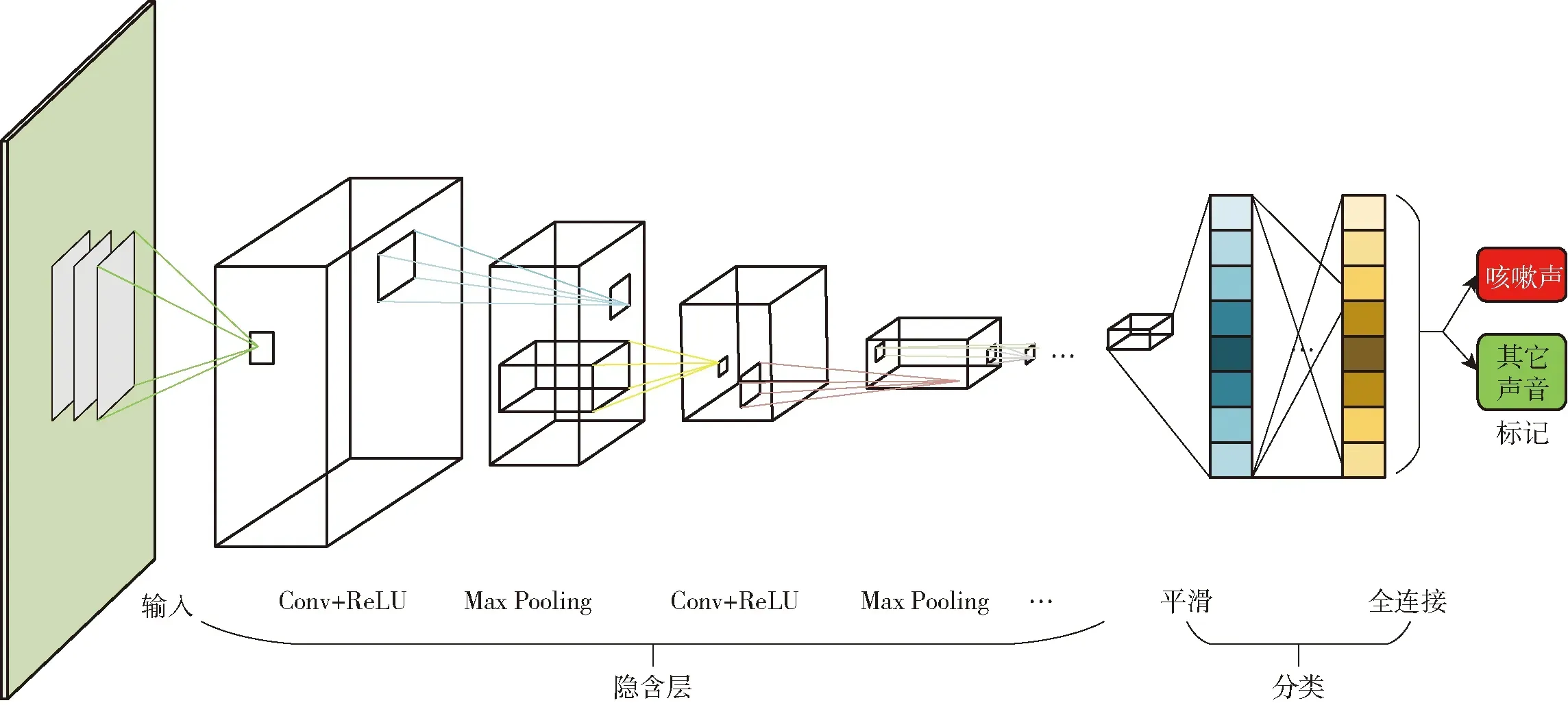
圖6 基于CNNs的咳嗽聲識別模型結構Fig.6 Structure of cough recognition model based on CNNs
2.2.2基于DFSMN的豬咳嗽聲識別模型
前饋序列記憶神經網絡(DFSMN)通過進一步在cFSMN的記憶模塊之間添加跳轉連接(Skip connection),從而可以將低層記憶模塊的輸出直接累加到高層記憶模塊里,有利于解決網絡深度造成的梯度消失問題。DFSMN記憶單元公式為
(5)
其中
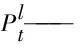
Vl——第l個隱含層和第l個線性投影層的權值
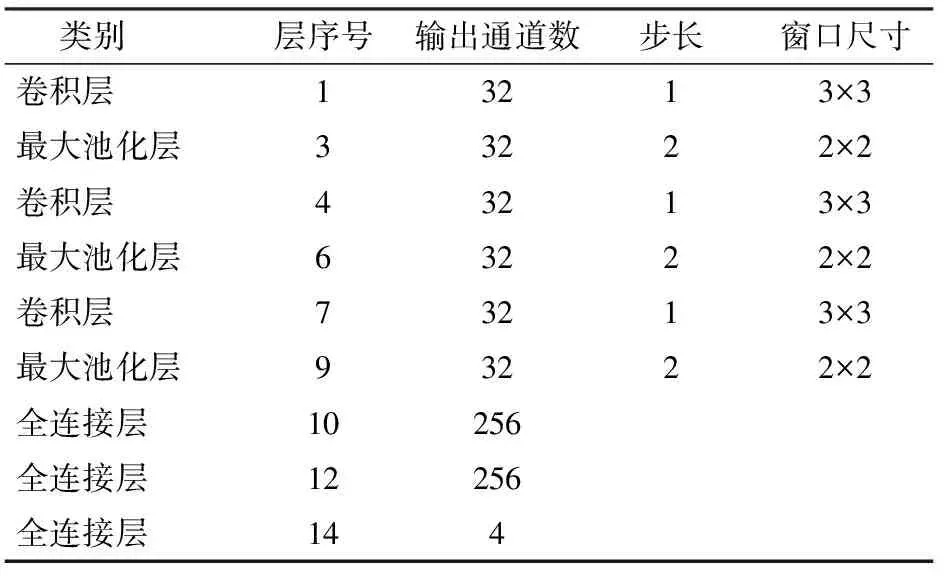
表2 CNNs模型結構參數Tab.2 Model structure parameters of CNNs

bl——第l個隱含層和第l個線性投影層的偏置

H(·)——記憶模塊之間的跳轉連接函數
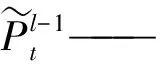

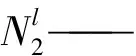



圖7 DFSMN結構Fig.7 Structure of DFSMN


s1——反向濾波器的編碼步幅因子
s2——前向濾波器的編碼步幅因子
在聲音信號預處理中,相鄰幀信息由于重疊而具有很強的冗余性,DFSMN將步長因子添加到記憶塊中,以消除這種冗余。總延遲與每個記憶塊中的步長和前向過濾器順序有關,計算公式為
(6)
式中τ——記憶模塊的延遲
L——記憶模塊總數
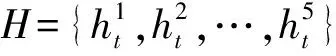
咳嗽聲識別模型輸入層接著一層卷積網絡,DFSMN部分由3層DFSMN組成,緊接著3個ReLU激活函數層和3層全連接層,最后是輸出部分。卷積層輸入通道數為每種特征及其一階和二階差分組合,設置為3,輸出通道數依據經驗值即卷積核個數,設置為2的倍數32,卷積核通道數依據輸入通道數設置為3;DFSMN層模型輸入特征維度由上層卷積運算后進行數組重新組合得到,具體輸入分別為1 984、256、256個單元,輸出特征維度與下一層矩陣維度匹配,可進行矩陣運算,輸出均為256個單元;全連接層同理,輸入分別為9 728、256、256個單元,輸出為256、256、4個單元。圖8為基于DFSMN的咳嗽聲識別模型框架,圖中InF、OutF分別表示輸入、輸出特征,In-Conv、L-Conv、R-Conv分別表示輸入、左半部分、右半部分網絡的一維卷積層。
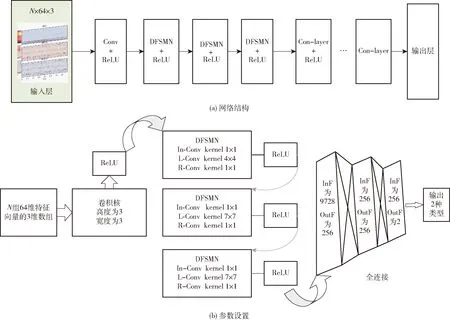
圖8 基于DFSMN的咳嗽聲識別模型Fig.8 Cough recognition model based on DFSMN
2.2.3模型訓練步驟與參數設置
深度神經網絡模型訓練步驟通常隨機生成初始模型參數,算法代入設定好的學習率和迭代次數N;由損失函數獲得損失值(loss);計算導數后由優化函數(optimizer)得到下一次迭代的優化參數;不斷迭代直至迭代N次。
本文的神經網絡具體操作步驟如下:①整體網絡框架構建,包括訓練集、驗證集、測試集樣本數據加載。由于原始音頻時長不一,特征提取后幀數不同,在輸入模型之前需要對數據進行長度統一,本文取最大長度40幀為閾值,不足40部分由零填充,超過40強制截取最大長度。創建以時間為名的文件夾,用來存儲模型結果。②超參數初始化,每輪模型訓練中,利用shuffle函數打亂樣本順序。訓練一次取出樣本數據64個,全部數據參與訓練完成一次迭代周期,初始輪數設置為100輪。設定隨機梯度下降(Stochastie gradient descent, SGD)為優化器,學習率初始化為0.001,動量設置為0.9,學習衰減率為0.98。優化器公式為
(7)
Δθt=-ηgt
(8)
式中θt-1——模型參數
η——學習率
gt——損失值關于參數的梯度


(9)
式中H——損失函數值
p——樣本真實分布
q——模型預測的樣本分布
p(x)——期望輸出
q(x)——實際輸出
③開始訓練后每次迭代完成計算損失并更新參數,每50個迭代周期降低一次學習率。④訓練結束對比驗證集和測試集的訓練效果,手動調整相對應的超參數,當訓練集和驗證集的損失值、精確率浮動誤差不超過2%時,停止訓練。
3 實驗結果與分析
本實驗均在一臺配置為1塊GTX1080Ti顯卡、有效內存31.1 GB、2塊Xeon Gold 5118CPU的工作站進行訓練,所涉及算法均基于pytorch深度學習開發庫。
3.1 模型評價指標
通過混淆矩陣形式清楚表示分類識別結果的咳嗽聲正確識別個數、咳嗽聲誤識別個數、其它聲音正確識別個數與誤識別個數,并通過準確率(Accuarcy)、精確率(Precision)、召回率(Recall)和F1值來衡量豬咳嗽聲識別模型的性能。
3.2 不同迭代次數和特征提取方法對模型效果的影響
3.2.1不同迭代次數
影響深度學習模型性能的因素通常包括學習率、迭代次數、初始化參數等,數據集數量、迭代次數、模型深度對模型效果的影響尚未發現普遍規律。
實驗設置從100輪開始每次增加50輪直至250輪,MFCC-CNNs模型測試集準確率在100~200輪之間不斷上升,在訓練輪數200時咳嗽聲精確率達到97%,其它聲音精確率為93%,召回率咳嗽聲為96%,其它聲音為93%,F1值咳嗽聲為98%,其它聲音為93%,總體識別準確率為96.71%。隨著訓練輪數繼續增加,模型準確率并不會繼續提高,識別準確率穩定在91%以上。logFBank-CNNs模型性能較穩定,測試集的準確率基本穩定在94%左右。MFCC-DFSMN模型最高準確率在200輪時達到92.46%,總體識別率較低,模型總體性能較差。logFBank-DFSMN模型咳嗽聲識別準確率穩定在90%以上,最高達到95.89%。
表3為不同迭代次數對不同模型在驗證集和測試集上咳嗽聲和其它聲音的識別效果對比,表中P1、P2、R1、R2、F1、F2、A分別表示咳嗽聲和其它聲音的精確率、召回率、F1值以及總體識別準確率。綜上分析在訓練輪數為200時,MFCC-CNNs模型對咳嗽聲的識別效果最好。不同特征與神經網絡的組合隨訓練次數不同,識別準確率存在上下波動情況,波動幅度不超過4%,總體穩定性較好。
3.2.2不同特征提取方法
表4、5為兩種神經網絡模型訓練次數為200時不同特征輸入下咳嗽聲和其它聲音的精確率、召回率、F1值和總體識別準確率的比較。模型在兩種特征輸入下,測試集和驗證集的結果基本相同。
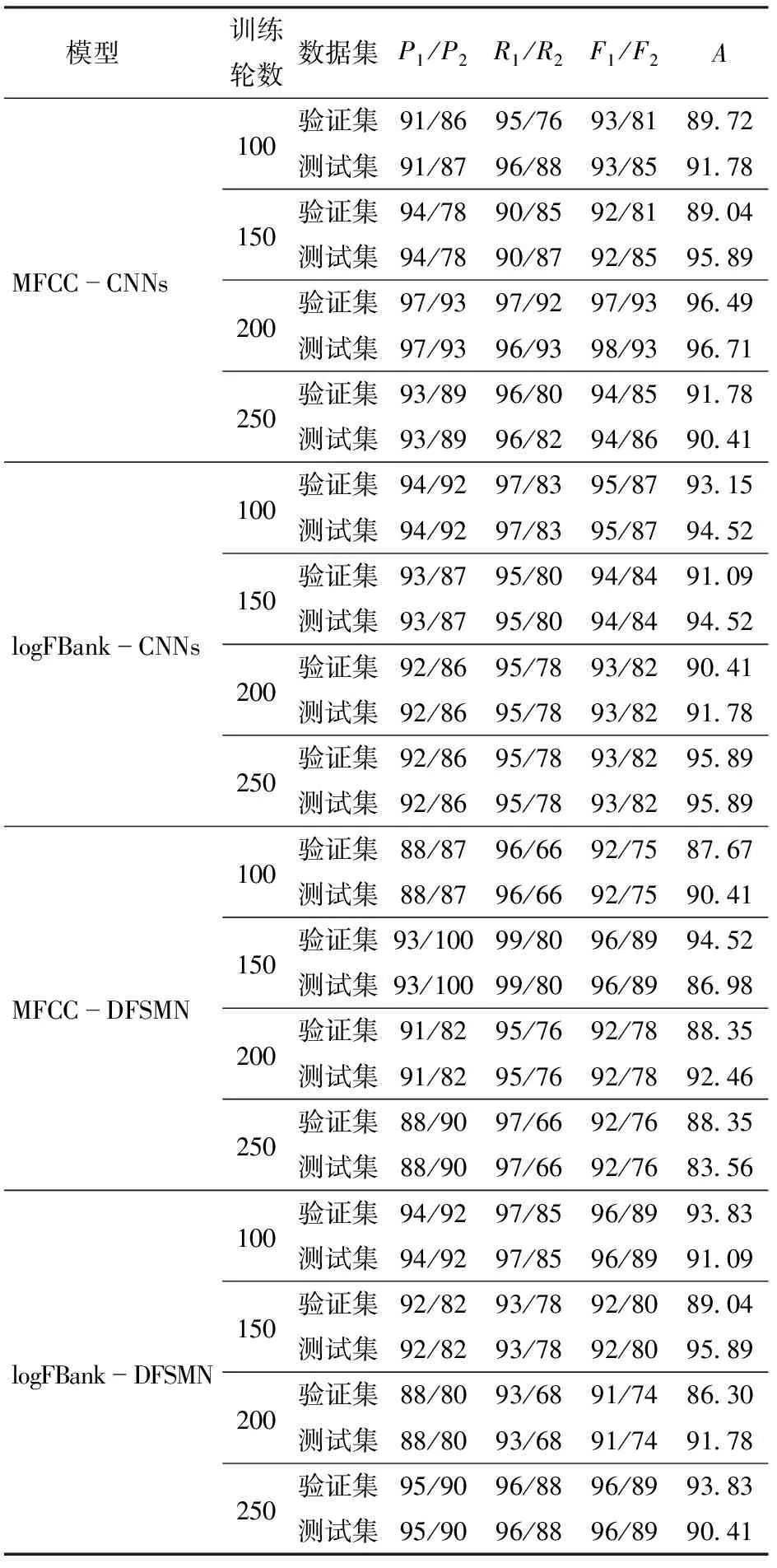
表3 不同迭代次數識別效果Tab.3 Experiment results of different iteration times %
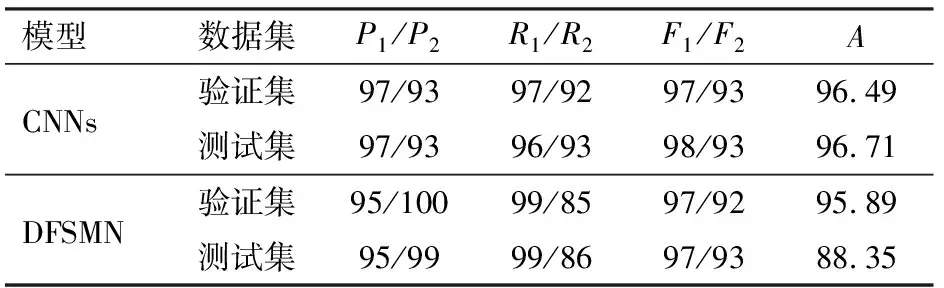
表4 MFCC特征識別效果Tab.4 Recognition effect of MFCC %

表5 logFBank特征識別效果Tab.5 Recognition effect of logFBank %
由圖9a可以明顯發現,以MFCC為特征的兩種模型準確率均高于以logFBank為特征的模型,且MFCC-CNNs的準確率最高。由圖9可以看出,CNNs模型在迭代周期數為25時,準確率還處于上升階段,此時損失值曲線處于不斷下降狀態,波動較小,而后逐漸平穩,模型收斂。DFSMN模型準確率與損失值趨于平穩狀態要早于CNNs模型,最終logFBank-CNNs、logFBank-DFSMN、MFCC-CNNs、MFCC-DFSMN 4種模型驗證集訓練損失值分別為0.032、0.044、0.025、0.028。
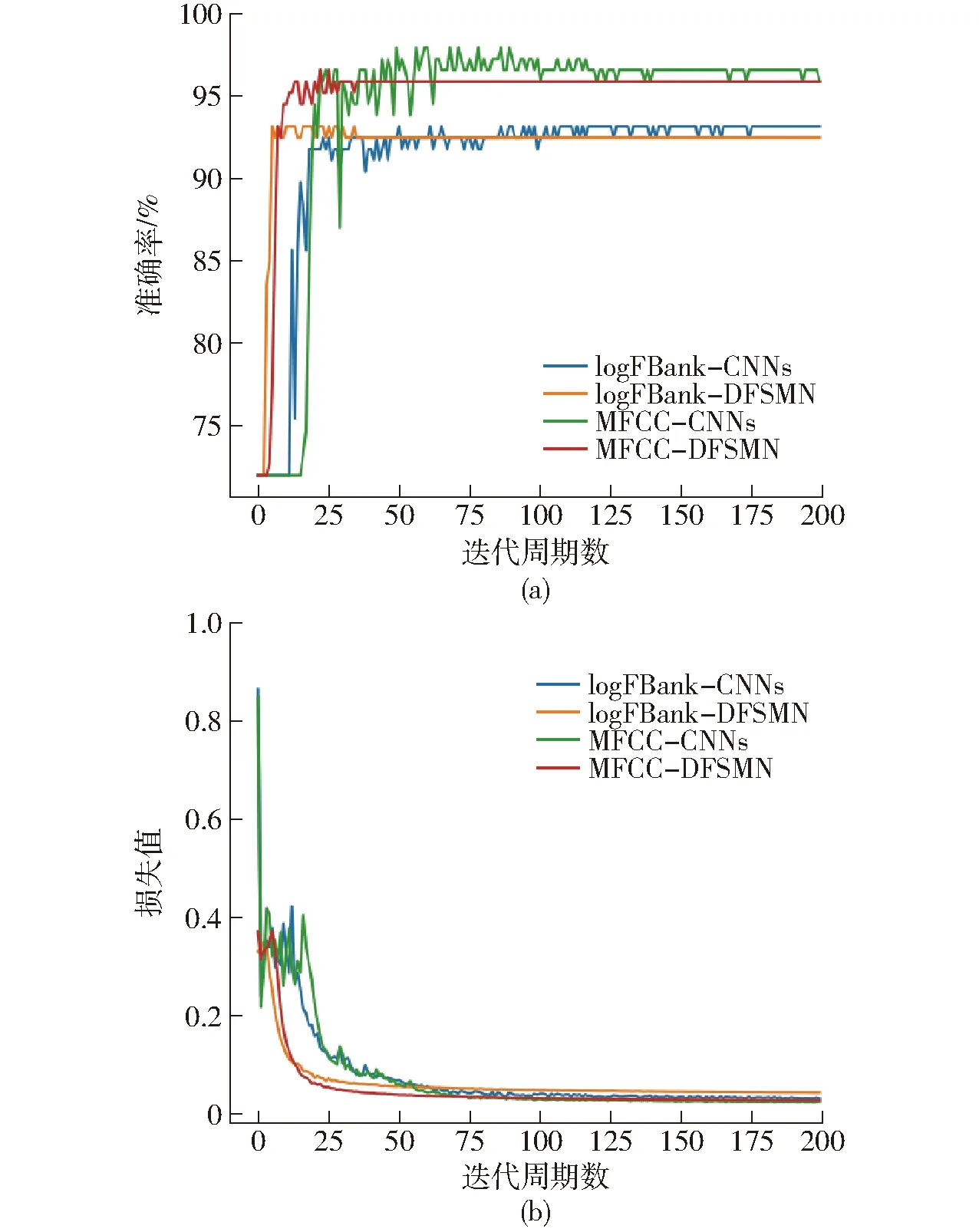
圖9 4種模型驗證集準確率、損失值變化曲線Fig.9 Accuracy and loss curves of four models
3.3 MFCC-CNNs對4種聲音的分類效果
豬只的咳嗽聲和噴嚏聲由人耳試聽存在一定相似度,為了更加準確地對豬只的不同聲音進行區分,在二分類的基礎上將標簽數增加至4個,檢驗MFCC-CNNs模型對4種聲音分類識別的效果。表6為訓練100輪后測試集上的模型評價指標結果。由測試集結果可知,總體識別準確率為92.47%。相較咳嗽聲,其它3種聲音召回率和F1值都比較低,考慮原因是樣本數量不均衡或者樣本數量較少導致。圖10為MFCC-CNNs模型訓練過程,圖10a表明驗證集準確率尚未達到訓練集水平,圖10b表明損失值均隨著網絡迭代周期數逐步下降,最終趨于穩定,損失值分別為0.009、0.052。
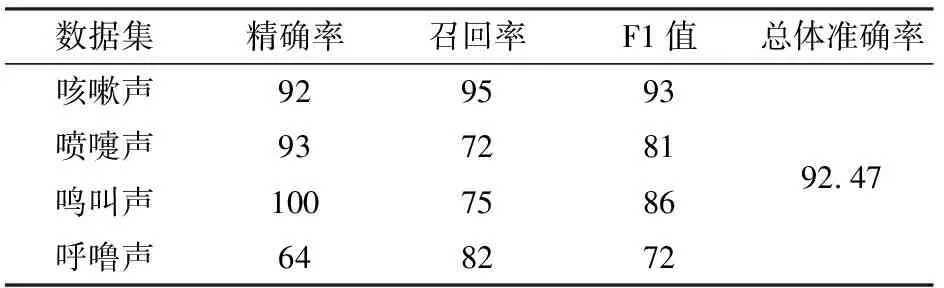
表6 MFCC-CNNs四分類效果對比Tab.6 Comparison of four classification effects of MFCC-CNNs %
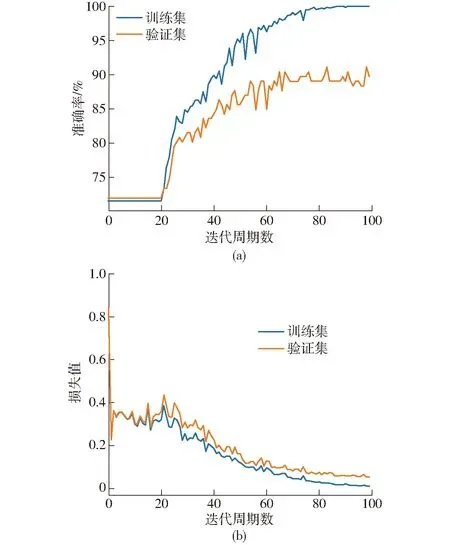
圖10 MFCC-CNNs訓練過程Fig.10 MFCC-CNNs training process
4 結論
(1)提出了一種基于MFCC-CNNs的深度神經網絡豬咳嗽聲識別方法。通過傳統譜減法處理后原始聲音噪聲明顯減小,利用雙門限端點檢測法得到有效聲音信號后分別提取logFBank和MFCC特征,結果顯示以MFCC為特征的CNNs咳嗽聲識別模型準確率最高,咳嗽聲識別精確率為97%,召回率為96%,F1值為98%,總體識別準確率為96.71%。
(2)將深層卷積神經網絡與前饋序列記憶神經網絡引入豬咳嗽聲識別領域,通過設置不同迭代次數的對比實驗可知,不同迭代次數對二分類模型結果的影響最大誤差不超過4%,且以MFCC為特征輸入的模型準確率普遍高于以logFBank為特征輸入的模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
