基于改進(jìn)MobileFaceNet的羊臉識(shí)別方法
2022-06-21 08:21:46張宏鳴周利香李永恒郝靳曄李書琴
農(nóng)業(yè)機(jī)械學(xué)報(bào) 2022年5期
張宏鳴 周利香 李永恒 郝靳曄 孫 揚(yáng) 李書琴
(西北農(nóng)林科技大學(xué)信息工程學(xué)院, 陜西楊凌 712100)
0 引言
現(xiàn)階段中國大多數(shù)羊場采用耳標(biāo)識(shí)別、射頻識(shí)別[1]的方式對(duì)動(dòng)物進(jìn)行身份識(shí)別,該類方法的身份識(shí)別標(biāo)識(shí)容易丟失。目前,監(jiān)控設(shè)備已成為羊場的基本設(shè)施。基于計(jì)算機(jī)視覺技術(shù)對(duì)羊臉進(jìn)行檢測,進(jìn)而識(shí)別不同羊只,成為智慧養(yǎng)殖領(lǐng)域智能識(shí)別的解決方案之一。
已有學(xué)者使用計(jì)算機(jī)視覺技術(shù)進(jìn)行動(dòng)物身份識(shí)別的研究[2-5]。在傳統(tǒng)機(jī)器學(xué)習(xí)方面,部分學(xué)者應(yīng)用傳統(tǒng)特征提取方法進(jìn)行牛的分類識(shí)別[6]、豬只個(gè)體識(shí)別。然而數(shù)據(jù)采集工作量較大,數(shù)據(jù)處理后的灰度圖像的訓(xùn)練失去了較多顏色信息,對(duì)單色臉部識(shí)別效果不理想。在深度學(xué)習(xí)方面,HANSEN等[7]、WANG等[8]用遷移學(xué)習(xí)技術(shù),使用VGG網(wǎng)絡(luò)人臉預(yù)訓(xùn)練模型,分別實(shí)現(xiàn)了豬和牛的非接觸式臉部識(shí)別。GUO等[9]使用改進(jìn)的卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)實(shí)現(xiàn)金絲猴非接觸式面部識(shí)別。SALAMA等[10]實(shí)現(xiàn)了綿羊的識(shí)別。何東健等[11]使用改進(jìn)YOLO v3實(shí)現(xiàn)擠奶奶牛個(gè)體的身份識(shí)別,劉月峰等[12]提出了一種基于幅值迭代剪枝算法的網(wǎng)絡(luò)篩選方法實(shí)現(xiàn)奶牛的進(jìn)食行為識(shí)別。但基于YOLO網(wǎng)絡(luò)的識(shí)別模型參數(shù)量大,對(duì)于面部特征相似的個(gè)體識(shí)別精度仍有待提高。現(xiàn)有的動(dòng)物面部識(shí)別數(shù)據(jù)多為近距離拍攝數(shù)據(jù),在閉集訓(xùn)練集上達(dá)到了很好的識(shí)別效果,但處理增量數(shù)據(jù)需要重新進(jìn)行分類器訓(xùn)練,且遠(yuǎn)距離場景下錯(cuò)誤分類概率更高。面部識(shí)別算法應(yīng)用推廣中人臉識(shí)別占據(jù)主導(dǎo)地位,主要算法有DeepID[13-14]系列算法、FaceNet[15]、InsightFace[16]算法,DeepID系列算法使用Softmax損失函數(shù),模型識(shí)別率與人臉類別數(shù)成反比。FaceNet算法中采用三元組損失函數(shù)監(jiān)督學(xué)習(xí)人臉特征提升了識(shí)別率,但模型計(jì)算耗時(shí)長。InsightFace算法中使用MobileFaceNet[17]作為主干特征提取網(wǎng)絡(luò),Arcface[18]損失函數(shù)加大類間距,相比于MobileNet,VGG及其他識(shí)別網(wǎng)絡(luò)在人臉識(shí)別領(lǐng)域模型規(guī)模小,識(shí)別率高。故本文選擇MobileFaceNet,并針對(duì)羊只體型較小、面部相似性大、奶山羊顏色單一且花色區(qū)別不大的問題,對(duì)MobileFaceNet進(jìn)行改進(jìn)與優(yōu)化。目標(biāo)檢測算法[19-24]中YOLO v4的檢測速度快,可進(jìn)行大規(guī)模的羊臉識(shí)別數(shù)據(jù)采集,降低人工采集數(shù)據(jù)集成本,具有現(xiàn)實(shí)場景下羊臉識(shí)別的潛力。
因此,本文采用單級(jí)式目標(biāo)檢測方法中的YOLO v4算法構(gòu)建羊臉檢測器,以批量獲取羊臉,構(gòu)建識(shí)別數(shù)據(jù)集。針對(duì)遠(yuǎn)距離下羊只個(gè)體識(shí)別率不高的問題,提出一種基于融合空間信息的高效通道注意力(Efficient channel coalesce spatial information attention,ECCSA)MobileFaceNet的輕量級(jí)羊臉識(shí)別模型(ECCSA-MFC),以期為非接觸式羊臉識(shí)別提供參考方法。
1 識(shí)別方法
1.1 視頻與圖像采集
因采集單一樣本會(huì)使得檢測器的穩(wěn)定性和復(fù)雜場景下的適應(yīng)性較差,試驗(yàn)選擇灘羊和關(guān)中奶山羊兩類羊作為研究對(duì)象,分距離對(duì)室內(nèi)室外不同光照、不同高度、不同角度的羊臉進(jìn)行拍攝和錄像,對(duì)所有采集的羊只進(jìn)行人工干預(yù)驅(qū)趕,并增加攝像機(jī)抖動(dòng)情形,以采集存在抖動(dòng)情況的單羊過道現(xiàn)實(shí)應(yīng)用場景。共采集遠(yuǎn)距離羊臉視頻42段,近距離羊臉視頻89段,共計(jì)131段視頻數(shù)據(jù),奶山羊個(gè)體62只,灘羊個(gè)體57只,共計(jì)119只羊。處理后的分辨率調(diào)整為1 920像素×1 080像素,部分場景如圖1所示。

圖1 羊臉原始數(shù)據(jù)樣例Fig.1 Original examples of sheep face
1.2 技術(shù)路線
本研究使用深度學(xué)習(xí)的方法實(shí)現(xiàn)非接觸式的羊面部識(shí)別,技術(shù)路線如圖2所示。

圖2 技術(shù)路線圖Fig.2 Technology roadmap
主要包括4個(gè)步驟:
(1)數(shù)據(jù)集構(gòu)建:使用FFMpeg處理原始視頻數(shù)據(jù),將視頻轉(zhuǎn)化成圖像,對(duì)圖像進(jìn)行羊臉區(qū)域標(biāo)注,根據(jù)羊臉檢測數(shù)據(jù)集和羊臉識(shí)別數(shù)據(jù)集構(gòu)建要求,進(jìn)行數(shù)據(jù)集準(zhǔn)備。
(2)羊臉檢測:利用羊臉檢測數(shù)據(jù)集訓(xùn)練基于YOLO v4模型的羊臉檢測模型,用于現(xiàn)實(shí)應(yīng)用中羊臉識(shí)別數(shù)據(jù)集自動(dòng)式構(gòu)建,同時(shí)作為實(shí)際應(yīng)用場景下的羊臉檢測器。
(3)羊臉識(shí)別:利用調(diào)用羊臉檢測器生成的羊臉識(shí)別數(shù)據(jù)集,訓(xùn)練本文提出的ECCSA-MFC羊臉識(shí)別模型。
(4)結(jié)果輸出:準(zhǔn)備測試視頻數(shù)據(jù),調(diào)用羊臉檢測器與羊臉識(shí)別模型,計(jì)算特征向量,對(duì)比特征向量的最佳閾值,輸出試驗(yàn)結(jié)果。
1.3 數(shù)據(jù)集構(gòu)建
由于采集的羊臉視頻數(shù)據(jù)的前后幀之間相似性很高,首先對(duì)采集的視頻數(shù)據(jù)使用FFMpeg處理成圖像,每12幀提取1幀,為了避免后期訓(xùn)練的識(shí)別模型出現(xiàn)過擬合情況,使用結(jié)構(gòu)相似度方法(Structural similarity, SSIM)[25]對(duì)圖像進(jìn)行檢查,刪減相似性高的前后幀圖像。共獲得原始圖像4 836幅,試驗(yàn)共構(gòu)建兩個(gè)數(shù)據(jù)集。對(duì)羊臉檢測數(shù)據(jù)集中的所有圖像進(jìn)行人工手動(dòng)羊臉框定。通過高斯噪聲、水平翻轉(zhuǎn)、隨機(jī)裁剪等數(shù)據(jù)增強(qiáng)方法對(duì)羊臉檢測數(shù)據(jù)進(jìn)行擴(kuò)充。部分羊臉檢測原始數(shù)據(jù)及標(biāo)注數(shù)據(jù)如圖3a所示。對(duì)于羊臉識(shí)別數(shù)據(jù)集,將檢測器檢測出的羊臉按照不同個(gè)體進(jìn)行人工分類,為了保證后續(xù)識(shí)別模型的準(zhǔn)確性,對(duì)每一文件夾下的羊臉圖像進(jìn)行人工篩選,剔除模糊、側(cè)臉、誤檢測、不屬于此類的其他類別羊臉,保證每個(gè)文件夾下的羊臉清晰、正臉、尺寸為112像素×112像素。圖3b為羊臉識(shí)別數(shù)據(jù)集樣例。

圖3 羊臉數(shù)據(jù)集樣例Fig.3 Samples of sheep face data
為了驗(yàn)證識(shí)別模型在實(shí)際場景應(yīng)用中的魯棒性和準(zhǔn)確性,試驗(yàn)將這119只羊的臉部數(shù)據(jù)按照開集識(shí)別[26]和閉集識(shí)別[27]對(duì)訓(xùn)練集和驗(yàn)證集進(jìn)行隨機(jī)分類,其具體處理結(jié)果如表1所示。
1.4 羊臉檢測
1.4.1基于YOLO v4的羊臉檢測方法
YOLO v4算法改進(jìn)了原有YOLO目標(biāo)檢測架構(gòu),主干網(wǎng)絡(luò)采用CSPDarknet53,頸部采用空間金字塔和最大池化進(jìn)行多尺度融合增大感受野,采用路徑聚合網(wǎng)絡(luò)對(duì)不同的輸出層進(jìn)行特征融合。滿足羊臉實(shí)時(shí)檢測的需求,故本試驗(yàn)采用YOLO v4進(jìn)行羊臉檢測。

表1 羊臉數(shù)據(jù)集處理結(jié)果Tab.1 Sheep face dataset processing results
1.4.2羊臉檢測試驗(yàn)設(shè)置
在Darknet深度學(xué)習(xí)框架下搭建YOLO v4算法。根據(jù)本試驗(yàn)所需類別對(duì)自定義的數(shù)據(jù)集進(jìn)行相關(guān)參數(shù)設(shè)置,通過K-means++聚類方法重新計(jì)算出錨框大小,采用3通道處理策略,輸入檢測框尺寸為608像素×608像素,設(shè)置動(dòng)量為0.949,權(quán)重衰減正則系數(shù)為1×10-5,調(diào)整學(xué)習(xí)率為1×10-3,采取學(xué)習(xí)率10倍衰減方式進(jìn)行模型迭代,將迭代輪次設(shè)置為2 000次,在每一輪迭代訓(xùn)練時(shí)進(jìn)行Mosaic數(shù)據(jù)增強(qiáng),損失函數(shù)采用完美交并比方法(Complete intersection over union,CIOU),進(jìn)行非極大值抑制。
1.4.3羊臉檢測評(píng)價(jià)指標(biāo)
通過計(jì)算羊臉對(duì)象真實(shí)框和預(yù)測框之間的交并比(Intersection over union,IoU)、準(zhǔn)確率及F1值進(jìn)行檢測模型評(píng)估。
1.5 羊臉識(shí)別
1.5.1MobileFaceNet網(wǎng)絡(luò)結(jié)構(gòu)
MobileFaceNet源于MobileNetV2[28],擁有工業(yè)級(jí)精度和運(yùn)算速度,相比于大型網(wǎng)絡(luò),該模型參數(shù)少且所占內(nèi)存小,降低了訓(xùn)練過擬合風(fēng)險(xiǎn)。MobileFaceNet使用512×7×7(通道數(shù)×長×寬)可分離卷積代替平均池化層。將激活函數(shù)ReLU替換為PReLU,訓(xùn)練過程中采用Arcface損失函數(shù)增大類間分類距離,通過歸一化層加快模型收斂速度,防止模型過擬合。
1.5.2ECCSA融合空間信息的通道注意力
ECA是一種針對(duì)深度CNN的高效通道注意模塊,去除了SE[29]模塊中的全連接層(Fully connected layers,F(xiàn)C)。ECA在全局池化層(Global average pooling,GAP)之后的特征上通過一個(gè)可以權(quán)重共享的1維卷積進(jìn)行學(xué)習(xí),自適應(yīng)地確定核尺寸k,通過執(zhí)行1維卷積,保證了模型效率和計(jì)算效果,通過Sigmoid函數(shù)來學(xué)習(xí)通道注意力。本文提出的ECCSA模塊如圖4所示,其中C、W、H分別表示圖像的通道數(shù)、長、寬。在ECA基礎(chǔ)上并行增加空間注意力[30]進(jìn)行空間分類像素域的學(xué)習(xí),提高特征提取能力。
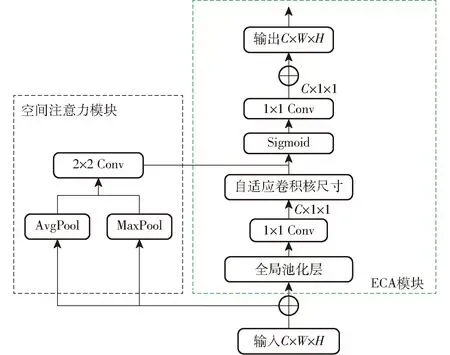
圖4 ECCSA模塊Fig.4 ECCSA module
1.5.3融合空間通道注意力的ECCSA-MFC
由于不同個(gè)體羊外觀相似,臉部類間差異更小,羊臉易受異物遮蓋,MobileFaceNet算法對(duì)羊臉識(shí)別效果并不理想,識(shí)別準(zhǔn)確率不高。為了提高模型的魯棒性和全局性,本文提出ECCSA-MFC模型,該模型針對(duì)MobileFaceNet主干網(wǎng)絡(luò)做了3處改進(jìn)。
(1)融合ECCSA模塊的特征提取層

圖5 改進(jìn)的MobileFaceNet網(wǎng)絡(luò)結(jié)構(gòu)Fig.5 Improved MobileFaceNet network structure
為了增加主干特征的接受范圍,在特征提取層中加入ECCSA,保證模型低復(fù)雜度的同時(shí),提高神經(jīng)網(wǎng)絡(luò)提取特征的跨通道交互和空間分類像素域?qū)W習(xí)的能力。對(duì)原有MobileFaceNet網(wǎng)絡(luò)的網(wǎng)絡(luò)頸部進(jìn)行改進(jìn),融合了空間信息的高效通道注意力識(shí)別模型ECCSA-MFC網(wǎng)絡(luò)結(jié)構(gòu)如圖5所示。網(wǎng)絡(luò)輸入羊臉圖像的尺寸為112×112×3,通過兩層CBP進(jìn)行特征融合,該層由2×2卷積(Conv)、批量歸一化(BN)、PReLU激活函數(shù)構(gòu)成。運(yùn)用帶有ECCSA模塊的深度可分離卷積層(DW層)對(duì)上層提取特征進(jìn)行處理,再經(jīng)過倒殘差層(DWRes層)對(duì)低維特征進(jìn)行學(xué)習(xí)。其中DWRes層包含多個(gè)DW層,再通過Flatten層進(jìn)行數(shù)據(jù)壓平得到512×1的特征向量。
(2)學(xué)習(xí)率動(dòng)態(tài)調(diào)優(yōu)
為了避免模型訓(xùn)練過程中陷入局部最優(yōu)解,使用余弦退火算法對(duì)學(xué)習(xí)率進(jìn)行動(dòng)態(tài)調(diào)優(yōu)。
(3)ImageNet數(shù)據(jù)集上的預(yù)訓(xùn)練模型
在羊臉識(shí)別模型訓(xùn)練前對(duì)輸入圖像進(jìn)行預(yù)處理后,使用人臉數(shù)據(jù)集上的預(yù)訓(xùn)練模型初始化ECCSA-MFC的均值和方差,對(duì)圖像按照通道進(jìn)行標(biāo)準(zhǔn)化,加快模型的收斂深度,提高模型性能。
1.5.4羊臉識(shí)別試驗(yàn)設(shè)置
(1)圖像預(yù)處理
在羊臉識(shí)別模型訓(xùn)練前需對(duì)輸入圖像進(jìn)行預(yù)處理,使用在ImageNet數(shù)據(jù)集上計(jì)算得到的均值和方差,對(duì)圖像按照通道進(jìn)行標(biāo)準(zhǔn)化,加快模型的收斂深度。
(2)數(shù)據(jù)增強(qiáng)
為了增加訓(xùn)練圖像的數(shù)量并使網(wǎng)絡(luò)對(duì)某些變換更加魯棒,在訓(xùn)練圖像上隨機(jī)執(zhí)行了4個(gè)操作:隨機(jī)翻轉(zhuǎn)30°;圖像尺寸變換至112像素×112像素;數(shù)據(jù)形式轉(zhuǎn)換為張量形式(tensor),并進(jìn)行歸一化;在羊臉上添加隨機(jī)遮蓋以模擬現(xiàn)實(shí)場景下的遮蓋情況。
(3)參數(shù)設(shè)置
試驗(yàn)使用Arcface損失函數(shù),設(shè)置動(dòng)態(tài)初始化學(xué)習(xí)率為1×10-3,加入余弦退火進(jìn)行學(xué)習(xí)率動(dòng)態(tài)調(diào)優(yōu)。為了防止訓(xùn)練模型過擬合,設(shè)置dropout為0.6,學(xué)習(xí)動(dòng)量為5×10-4,迭代周期(Epoch)為50,批量大小(Batch size)為32。
1.5.5羊臉識(shí)別模型評(píng)價(jià)指標(biāo)
(1)拒識(shí)率和誤識(shí)率
拒識(shí)率(False reject rate,F(xiàn)RR)決定了模型的易用程度,誤識(shí)率(False accept rate,F(xiàn)AR)決定了模型的安全性。通過FRR和FAR可確定識(shí)別模型的最佳閾值,在羊臉識(shí)別系統(tǒng)中,將FAR設(shè)置為千分之一,在FAR固定的條件下,若FRR低于5%,則模型效果較優(yōu)。
(1)
(2)
式中NFR——錯(cuò)誤拒絕次數(shù)
FRR——拒識(shí)率,%FAR——誤識(shí)率,%
NFA——錯(cuò)誤接受次數(shù)
NGRA——類內(nèi)測試總數(shù)
NIRA——類間測試總數(shù)
(2)識(shí)別率
采用十折交叉驗(yàn)證的方式,計(jì)算每一輪檢測的識(shí)別率(Detection and identification rate,DIR),DIR的計(jì)算公式為
DIR(T,1)=
(3)
式中Pg——羊臉識(shí)別庫中的羊臉圖像
DIR——準(zhǔn)確識(shí)別率
Pj——待識(shí)別的羊臉圖像
Rank——識(shí)別結(jié)果標(biāo)記函數(shù),識(shí)別錯(cuò)誤賦值為0,識(shí)別正確賦值為1
Pj*——待識(shí)別羊與識(shí)別庫中羊匹配的第j*幅圖像的計(jì)算閾值
T——采用InsightFace中的閾值計(jì)算方式得到的最佳閾值
2 試驗(yàn)與結(jié)果分析
2.1 羊臉檢測
通過YOLO v4目標(biāo)檢測方法訓(xùn)練羊臉檢測模型,使用OpenCV讀取視頻流,進(jìn)行羊臉檢測并保存檢測框中的羊臉信息。最終YOLO v4羊臉檢測模型的平均交并比(IOU)為76.68%、準(zhǔn)確率為97.91%、F1值為93.84%。實(shí)現(xiàn)了對(duì)羊臉數(shù)據(jù)的實(shí)時(shí)檢測,同時(shí)為羊臉視頻識(shí)別奠定基礎(chǔ)。
羊臉檢測訓(xùn)練數(shù)據(jù)中包含不同光照條件、遮擋及鏡頭抖動(dòng)情況,圖6a表明該模型能夠檢測出室內(nèi)近距離下的羊臉。圖6b表明在鏡頭抖動(dòng)情況下,該模型能夠精準(zhǔn)檢測到遠(yuǎn)距離模糊羊臉,滿足羊臉檢測需求。

圖6 羊臉檢測結(jié)果Fig.6 Results of sheep face detection
2.2 羊臉識(shí)別
2.2.1模型識(shí)別結(jié)果對(duì)比
對(duì)MobileFaceNet使用余弦退火改變學(xué)習(xí)率計(jì)算方式,并初始化均值和方差,進(jìn)行模型初步精度優(yōu)化,如表2所示。進(jìn)行動(dòng)態(tài)學(xué)習(xí)率調(diào)優(yōu)得到的C-MFC模型識(shí)別率相比原有模型,在閉集上提升了0.67個(gè)百分點(diǎn),開集上提升了4.38個(gè)百分點(diǎn),且誤識(shí)率和拒識(shí)率均有所降低。
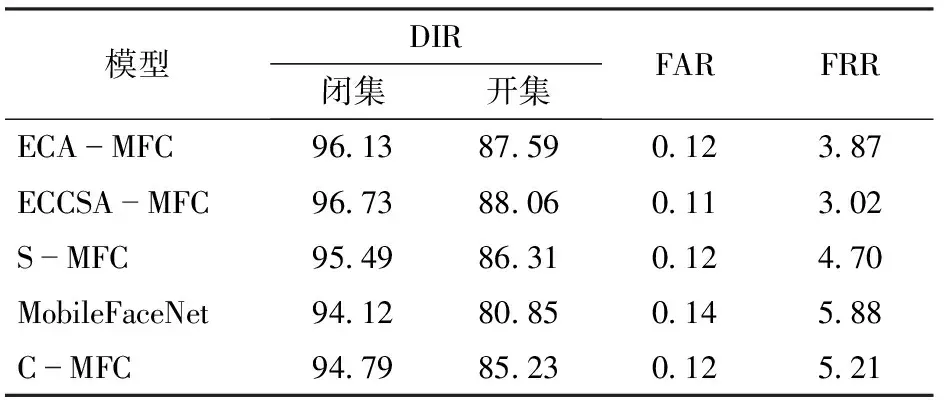
表2 不同模型效果對(duì)比Tab.2 Effect comparison of different models %

圖7 羊臉識(shí)別模型訓(xùn)練過程Fig.7 Training process of sheep face recognition model
本研究目的是在模型得到初步優(yōu)化的基礎(chǔ)上,構(gòu)建空間信息的高效通道注意力識(shí)別模型(ECCSA-MFC),提高遠(yuǎn)距離下的羊臉識(shí)別率。首先對(duì)MobileFaceNet的DW結(jié)構(gòu)進(jìn)行改進(jìn),對(duì)空間注意力模塊(S-MFC)、ECA模塊(ECA-MFC)以及ECCSA模塊融合DW的模型(ECCSA-MFC)進(jìn)行試驗(yàn)與結(jié)果分析。羊臉識(shí)別模型訓(xùn)練過程中在驗(yàn)證集上的識(shí)別率(DIR)、損失值(Loss)和最佳閾值(Threshord)的變化曲線如圖7所示。可以看出本文提出的ECCSA-MFC比S-MFC、ECA-MFC模塊的羊臉識(shí)別率高,在50輪迭代計(jì)算中,DIR曲線均穩(wěn)定高于ECA-MFC和S-MFC模型,并且在固定范圍內(nèi)振蕩;損失值處于逐漸穩(wěn)步收斂狀態(tài),且收斂效果優(yōu)于ECA-MFC和S-MFC,而單獨(dú)使用空間注意力模塊進(jìn)行改進(jìn)的S-MFC可能會(huì)出現(xiàn)梯度爆炸的情況;從閾值的變化情況看,本文提出的ECCSA-MFC模型閾值穩(wěn)定在1.6左右,與正常推理閾值波動(dòng)范圍一致,證明了ECCSA-MFC模型效果比ECA-MFC、S-MFC更加優(yōu)越。
將3種方法得到的收斂后模型進(jìn)行保存計(jì)算,得到不同模型的DIR、FAR和FRR。由表2可見,僅使用ECA模塊的ECA-MFC模型的效果,在閉集識(shí)別中相比于C-MFC提升了1.34個(gè)百分點(diǎn),在開集識(shí)別中相比于C-MFC提升了2.36個(gè)百分點(diǎn)。S-MFC模型雖然在閉集識(shí)別率上比C-MFC提升了0.7個(gè)百分點(diǎn),但在開集識(shí)別中的提升效果略低于ECA-MFC模型。ECCSA-MFC模型在開集和閉集中均取得最好的識(shí)別效果,閉集識(shí)別率達(dá)到96.73%,比C-MFC提升了1.94個(gè)百分點(diǎn);開集識(shí)別率達(dá)到88.06%,比C-MFC提升了2.83個(gè)百分點(diǎn)。
由表3可得,ECCSA-MFC在實(shí)現(xiàn)模型更加輕量化的同時(shí),能夠穩(wěn)定提升識(shí)別率,模型所占內(nèi)存僅為4.8 MB,相比MobileFaceNet減小了0.3 MB。
2.2.2實(shí)際場景下結(jié)果對(duì)比
為了驗(yàn)證本文模型在實(shí)際場景下的效果,分別使用奶山羊和灘羊的開集驗(yàn)證集進(jìn)行分類識(shí)別試驗(yàn)。奶山羊的驗(yàn)證集數(shù)據(jù)中前6只來自遠(yuǎn)景下采集的數(shù)據(jù),后6只來自近景下采集的數(shù)據(jù),11只灘羊的驗(yàn)證數(shù)據(jù)均為近景數(shù)據(jù)。制作奶山羊和灘羊的分類識(shí)別混淆矩陣用以直觀展示模型在驗(yàn)證集上的分類結(jié)果,如圖8所示,從左到右依次是C-MFC、ECA-MFC、S-MFC、ECCSA-MFC模型分類結(jié)果。原有的MFC結(jié)構(gòu)擁有近距離識(shí)別能力,在近距離羊只身份識(shí)別中,能夠做到準(zhǔn)確識(shí)別。ECA-MFC和S-MFC對(duì)近距離花色差異較大的灘羊的識(shí)別效果尚可,但識(shí)別顏色單一且距離較遠(yuǎn)的奶山羊仍然存在誤識(shí)別的可能。ECCSA-MFC模型能夠很好地改善C-MFC在遠(yuǎn)距離下對(duì)奶山羊的識(shí)別效果,并且在近距離的識(shí)別中不僅能夠準(zhǔn)確地識(shí)別花色差異較大的灘羊,在顏色單一的奶山羊遠(yuǎn)距離下仍然能夠正確識(shí)別羊只真實(shí)身份。這更加充分證明了ECCSA-MFC模型擁有對(duì)不同距離下羊臉正確分類識(shí)別的能力。圖9為使用1.2節(jié)中灘羊遠(yuǎn)距離模擬單過道現(xiàn)實(shí)場景視頻中視頻幀識(shí)別結(jié)果。

表3 不同網(wǎng)絡(luò)復(fù)雜度對(duì)比Tab.3 Complexity evaluation of different networks

圖8 驗(yàn)證集識(shí)別結(jié)果對(duì)比Fig.8 Comparison of verification set identification results

圖9 視頻幀識(shí)別結(jié)果Fig.9 Video frame recognition result
3 結(jié)論
(1)基于YOLO v4算法的羊臉檢測方法的檢測準(zhǔn)確率為97.91%,為羊臉數(shù)據(jù)采集工作減輕了負(fù)擔(dān),為視頻監(jiān)控下進(jìn)行羊臉識(shí)別提供了技術(shù)支撐。
(2)提出了一種引入融合空間信息的高效通道注意力的ECCSA-MFC模型,能夠有效增加主干特征的提取范圍。相比于原有MFC模型帶來的性能增益明顯,模型所占內(nèi)存比MobileFaceNet減小了0.3 MB,模型識(shí)別率得到有效提升,其中模型的閉集識(shí)別率比C-MFC提升了1.94個(gè)百分點(diǎn),開集識(shí)別率比C-MFC提升了2.83個(gè)百分點(diǎn)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
