基于環(huán)境變量和機器學習的土壤水分反演模型研究
2022-06-21 08:22:00王思楠李瑞平吳英杰趙水霞王秀青
農業(yè)機械學報 2022年5期
關鍵詞:模型
王思楠 李瑞平,2 吳英杰 趙水霞 王秀青
(1.內蒙古農業(yè)大學水利與土木建筑工程學院, 呼和浩特 010018;2.內蒙古自治區(qū)農牧業(yè)大數據研究與應用重點實驗室, 呼和浩特 010018;3.中國水利水電科學研究院牧區(qū)水利科學研究所, 呼和浩特 010020;4.內蒙古自治區(qū)測繪地理信息中心, 呼和浩特 010050)
0 引言
土壤含水率是地表能量平衡的重要決定參數,在全球水循環(huán)中起著重要作用[1]。同時在農業(yè)應用中,土壤水分含量不僅是作物生長發(fā)育的基本條件,也是作物產量估算、干旱監(jiān)測的關鍵參數[2]。因此,準確、及時地反演土壤水分具有重要意義。
土壤水分的分布受多個相互作用的因素影響,如土壤特性、植被覆蓋和氣候條件[3]。因此,用傳統(tǒng)的單點測量方法,如烘干法、數字探頭等,相對難以有效地獲得大規(guī)模的土壤水分信息[4]。與地面單點測量方法相比,遙感技術因其覆蓋面廣、時效性強、成本低,逐漸得到應用[5-6]。光學遙感作為最早和最成熟的地球觀測技術,一直發(fā)揮著重要的作用。學者們通過地物反射輻射特征變化來模擬地表覆蓋類型、地表溫度、土壤熱慣量及地表蒸散發(fā)與土壤含水量的經驗關系,從而實現(xiàn)土壤水分的反演[7-9]。然而,上述大多數方法都是經驗性的,對于回歸分析需要做出的一些統(tǒng)計假設可能會導致使用受限,如離群數據、非線性、異方差和多共線性,不能對土壤水分進行強有力的預測。機器學習方法能夠發(fā)現(xiàn)數據之間有意義的關聯(lián)、模式和規(guī)則,可以克服上述問題,如人工神經網絡[10]、卷積神經網絡[11]、支持向量機[12]、極限學習機(Extreme learning machine,ELM)[13]、隨機森林(Random forest,RF)[14],已經成功地應用于干旱半干旱地區(qū)土壤水分反演。研究證明基于機器學習方法能夠構建綜合多特征變量的土壤水分反演模型,可以提高土壤水分反演的時空分辨率以及反演精度[15-17]。研究表明,偏最小二乘回歸法、極限學習機和隨機森林是定量反演的可行方法[18-19]。總體而言,上述模型方法各具優(yōu)缺點,對不同研究區(qū)域有其不同的要素要求和適用范圍,有的土壤水分反演方法雖精度較高,但所需測定要素容量大,有的模型雖解決了大范圍應用的難題,卻在參數獲取和模型建立方面要求很高。
本文以內蒙古自治區(qū)烏審旗作為研究區(qū),對不同環(huán)境變量與表層土壤含水率進行相關分析,利用最優(yōu)子集篩選環(huán)境變量作為模型輸入變量,利用偏最小二乘(Partial least squares regression,PLSR)、極限學習機和隨機森林等方法構建不同的土壤含水率反演模型,通過比較,探索毛烏素沙地腹部土壤含水率的高效反演模型及方法,在此基礎上,反演研究區(qū)不同月份土壤水分并分析其時空變化。
1 數據與方法
1.1 研究區(qū)概況
烏審旗位于鄂爾多斯市西南部(圖1),地處毛烏素沙地腹部(37°38′~39°23′N、108°17′~109°40′E),地勢由西北向東南傾斜,平均海拔1 305 m。年平均降雨量350~400 mm,年平均氣溫6.8℃。主要土壤類型有栗鈣土、草甸土、鹽堿土、沼澤潛育土以及各類風沙土。主要土地利用類型為草地、沙地、林地、耕地、水體和建筑用地。

圖1 研究區(qū)地理位置與采樣區(qū)分布圖Fig.1 Geographical location and sampling layout of study area
1.2 數據
1.2.1遙感數據
選取2016年4月21日、8月27日的Landsat8 OLI影像,數據來源于美國地質調查局網站(https:∥earthexplorer.usgs.gov),通過ENVI 5.3軟件完成影像預處理,具體包括:輻射定標、大氣校正、影像鑲嵌、裁剪和波段運算。從而進一步得到地表溫度、地表反照率、纓帽變換要素、反射率、植被指數、水體指數、建筑指數和干旱指數等環(huán)境變量。其中植被指數和地表溫度是表述地表特征的兩個重要參數,以及二者構成的溫度植被干旱指數均與地表土壤水分存在著緊密關系,是土壤水分監(jiān)測的常用參數。反照率是影響地表輻射平衡的一個重要參數,其可以進一步影響土壤水分的變化。不同的光譜反射率對土壤水分的敏感性也不一樣。纓帽變換要素的濕度對不同植被覆蓋的土壤水分也有一定的表征。水體指數與建筑指數可以直接影響地表溫度來間接影響土壤水分。哨兵1A數據是Level-1地距影像(Ground range detected,GRD),成像方式為干涉寬幅 (Interferometric wide swath,IW)模式、極化方式(Vertical vertical(VV)和Vertical horizontal(VH)),經過輻射標定等得到所需要的后向散射系數。考慮地形條件對土壤水分的影響,本研究還通過地理空間數據云網站(http:∥www.gscloud.cn/)獲取ASTER數字高程模型。
1.2.2野外實測數據
根據衛(wèi)星過境時間在2016年4月20—22日、8月26—28日進行了兩次地面采樣實驗。采樣區(qū)域共24個,每個采樣區(qū)域之間的最小間隔為1 km。采樣時,首先記錄每個采樣區(qū)域5個點的GPS位置信息,各點間隔30 m,然后用土鉆從土壤表面0~10 cm處分別采集土壤樣品。最后,在現(xiàn)場對這5個點的土壤樣品進行混合和稱量。使用烘干稱量法進行土壤含水率的測量,計算公式為
(1)
式中W——土壤質量含水率,%
W1——空土盒質量,g
W2——土盒和濕土質量,g
W3——土盒和干土質量,g
1.3 最優(yōu)子集篩選
全子集回歸是對所有預測變量的可能組合模型都進行擬合,然后根據貝葉斯信息準則(Bayesian information criterion,BIC)篩選出現(xiàn)有變量條件下的最佳模型,又叫最優(yōu)子集篩選,計算公式為
BIC=mInc-2InL
(2)
式中m——模型參數個數
c——樣本數量L——最大似然函數
1.4 建模方法及模型評價指標
偏最小二乘回歸利用對系統(tǒng)中的數據信息進行分解和篩選的方式,提取對因變量的解釋性最強的綜合變量,辨識系統(tǒng)中的信息與噪聲,從而更好地克服變量多重相關性在系統(tǒng)建模中的不良作用[20]。極限學習機是在單隱層前饋神經網絡上發(fā)展起來的一種機器學習方法,可以隨機初始化輸入權重和偏置并得到相應的輸出權重,彌補了傳統(tǒng)神經網絡中運行時間長等缺點[21]。隨機森林是多重決策樹的組合,輸出類別由個別樹輸出的類別眾數而決定的分類回歸模型。不需要關于響應協(xié)變量關系的分布假設,該過程通過平均決策樹進行統(tǒng)計上的可靠估算,降低過擬合風險[22]。
采用決定系數R2、均方根誤差(RMSE)和平均絕對誤差(MAE)驗證反演模型的精度。RMSE、MAE越小,R2越大,表明模型反演精度越高。
2 結果與分析
2.1 描述性統(tǒng)計

圖2 土壤含水率描述性統(tǒng)計Fig.2 Descriptive statistics of soil moisture content
為了對預測模型進行訓練和驗證,分別將2016年4月21日、8月27日土壤含水率數據(120個)隨機分為兩組:建模集(70%,84個樣點)對模型進行訓練,驗證集(30%,36個樣點)對模型進行檢驗。全集、建模集和驗證集描述性統(tǒng)計結果如圖2所示。4月,全集土壤含水率均值為4.84%,標準差為5.18%。建模集(0.45%~20.13%)和驗證集(0.61%~15.89%)均值分別為4.73%和5.90%;8月,全集土壤含水率均值為7.51%,標準差為6.98%。建模集(0.82%~24.67%)和驗證集(1.19%~24.00%)均值分別為7.20%和8.22%。表明建模集和驗證集與全集土壤含水率保持類似的統(tǒng)計分布,在確保代表性樣本的同時盡可能縮減了建模集和驗證集中存在偏差的估計。
2.2 環(huán)境變量與表層土壤含水率的相關性分析
基于機器學習環(huán)境變量的數據來源與性質,包括17個變量:后向散射系數(σVV、σVH)、地表溫度(Land surface temperature,LST)、地表反照率(Albedo)、亮度(Bright)、綠度(Green)、濕度(Wet)、波段反射率(紅光、近紅外、短波紅外)、植被指數(Normalized difference vegetation index,NDVI)、水體指數(Normalized differential water index,NDWI)、建筑指數(Normalized differential building index,NDBI)、高程(DEM)、坡度(Slope)和溫度植被干旱指數(Temperature vegetation drought index,TVDI)等要素(圖3)。

圖3 環(huán)境變量空間分布Fig.3 Surface biophysical characteristics and topographic parameters
通過對不同環(huán)境變量與表層土壤含水率進行相關分析,結果發(fā)現(xiàn)不同的環(huán)境變量與表層土壤含水率之間的相關程度不同(圖4中*、**分別表示P<0.05、P<0.01)。首先,溫度植被干旱指數與土壤含水率相關性最高,決定系數為0.64,主要原因是溫度植被干旱指數綜合植被和地表溫度信息,從裸地到植被全覆蓋可以準確體現(xiàn)土壤濕度狀況[23]。其次為地表溫度與土壤含水率相關性,決定系數為0.6,地表溫度在土壤濕度和地、氣相互循環(huán)過程中有重要作用,同時能間接反映土壤水分狀況,表征旱情分布,因而對地表溫度數據的研究是不可或缺的內容[24],本研究地表溫度與土壤含水率為高相關性,對土壤含水率高精準反演有重要價值。最后,σVV、植被指數、波段7反射率、σVH、波段6反射率、建筑指數、水體指數、反照率、亮度、綠度和濕度與土壤含水率之間的決定系數分別為0.38、0.38、0.35、0.32、0.30、0.18、0.13、0.26、0.14、0.15、0.06,其中NDVI與土壤含水率的相關性從4月到9月增加最明顯,主要原因是NDVI在植被覆蓋度高的月份更加敏感,反映的信息更為豐富;NDBI與土壤含水率的相關性從4月到9月減小最明顯,主要原因是NDBI在植被覆蓋度低的月份更加敏感。σVV、σVH在植被覆蓋度低的月份對土壤含水率更加敏感。地形因素中DEM和坡度的正向相關性較好,這主要是地形會影響地表徑流與該地所受的太陽光照、植被生長環(huán)境等[25],從而對土壤水分產生影響,此外烏審旗的地形呈現(xiàn)西北高東南低的特征,這對DEM和坡度間相關性影響較大。反射率與土壤含水率也有很好的相關性,主要是由于土壤水分的變化會引起土壤顆粒物理性質和反射率也發(fā)生變化,通常隨著土壤水分的減少,其反射率也會相應增大[25];而植被的生長狀態(tài)能夠間接反映出土壤水分,通常來說,植被密度越大,生長態(tài)勢越好的地方的土壤含水率越高。其中,波段反射率中B6、B7波段反射率與表層土壤含水率的相關性高于B4、B5波段,主要原因是短波紅外光譜域包括水分吸收帶,影響植被和土壤中水分含量的反射率敏感性[26]。

圖4 不同月份環(huán)境變量與土壤含水率的相關性分析Fig.4 Correlation analysis of environmental variables and soil moisture in different months

圖5 4月土壤含水率實測值與預測值比較Fig.5 Comparison of measured and predicted soil moisture content in April
總體而言,2個月間表層土壤含水率與后向散射系數均值R2(0.35)、波段反射率均值R2(0.26)、地表溫度、地表反照率、纓帽變換要素、植被指數、水體指數、建筑指數均值的R2(0.24)以及干旱指數均值的R2(0.6)高于表層土壤含水率與地形參數的均值R2(0.19)。這一結果表明,表層土壤含水率對研究區(qū)后向散射系數、干旱指數、波段反射率和地表生物物理特征的依賴性較高。
2.3 最優(yōu)子集篩選特征變量
基于BIC最小的原則,利用最優(yōu)子集篩選法(Best subset selection,BSS)選取不同月份最優(yōu)的環(huán)境變量組合,如表1所示。

表1 全子集篩選結果統(tǒng)計Tab.1 Statistics of full subset selection
2.4 土壤水分反演模型的精度評價與分析
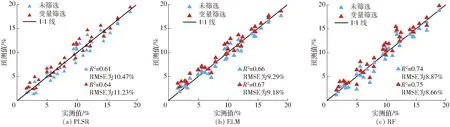
圖6 8月土壤含水率實測值與預測值比較Fig.6 Comparisons of measured and predicted soil moisture content in August
為了驗證3類模型的可靠性和適用性,使用2期驗證集中的36個樣點實測數據分別進行精度檢驗。圖5、6分別為2016年4月21日和2016年8月27日PLSR、ELM、RF 3種模型預測值與實測數據的散點圖。由圖5、6可知,預測值與實測值都具有很高的相關性。由表2可知,4月,建模集中3種模型方法的精度差異較大,相比于未篩選變量所構建的模型,利用BSS篩選變量所構建的模型精度均有所提升,且在RF模型的R2最高,為0.88,而RMSE和MAE均為最小值,分別為8.25%、5.17%;PLSR模型的R2最低,為0.66,RMSE和MAE分別為10.07%、9.43%,均為建模集中最大值;ELM模型性能介于二者間。由表3可知,8月,建模集中3種模型方法的精度差異較大,相比于未篩選變量所構建的模型,利用BSS篩選變量所構建的模型精度均有所提升,且在RF模型的R2最高,為0.89,而RMSE和MAE均為最小值,分別為7.36%、4.61%;PLSR模型的R2最低,為0.69,RMSE和MAE分別為9.74%、9.37%,均為建模集中最大值;ELM模型性能介于二者間。綜上所述,建模集中,RF模型性能明顯優(yōu)于PLSR和ELM方法,反演效果由優(yōu)到劣依次為RF、ELM、PLSR。在驗證集中,3種模型的各指標相較于建模集均無明顯下降,表明模型比較穩(wěn)定,但三者相比較而言,仍然是RF模型的各項指標明顯優(yōu)于ELM和PLSR,而ELM和PLSR相比,ELM模型的R2明顯高于PLSR模型,而RMSE和MAE低于PLSR模型。綜合考察各模型建模集與驗證集的評價指標,3種模型的預測性能和穩(wěn)定性從高到低排序依次為RF、ELM、PLSR,基于PLSR的模型精度最低,這是由于土壤的組分非常復雜,功能團多樣,偏最小二乘回歸方法僅僅將環(huán)境變量與土壤含水率進行線性回歸,同時沒有將部分與土壤含水率非線性相關的關系考慮進來,導致所構建的模型具有一定的缺陷。而ELM、RF模型充分考慮了環(huán)境變量對表層土壤含水率的影響,并且具有對非線性問題的強解析能力和模型的穩(wěn)健性。研究區(qū)表層土壤含水率模型預測精度結果進一步表明了RF模型自身的優(yōu)越性和利用環(huán)境變量預測研究區(qū)表層土壤水分空間分布的可行性。

表2 4月土壤含水率反演模型與精度Tab.2 Soil moisture content retrieval models and accuracies in April

圖7 4月表層土壤水分空間分布特征Fig.7 Spatial distribution characteristics of surface soil moisture in April

表3 8月土壤含水率反演模型與精度Tab.3 Soil moisture content retrieval models and accuracies in August
2.5 土壤水分的空間分布特征

圖8 8月表層土壤水分空間分布特征Fig.8 Spatial distribution characteristics of surface soil moisture in August
由圖7、8可知,不同月份ELM和RF模型預測的土壤水分分布圖與PLSR模型預測的土壤水分分布圖比較相似。高土壤含水率出現(xiàn)在研究區(qū)的北部和東南部,主要由于這些地區(qū)有密集的植被覆蓋,土壤持水性好。中北部平坦地區(qū)的土壤含水率較低,主要由于這些地區(qū)植被覆蓋度低,地表蒸散強烈。此外, ELM反演的土壤水分分布(4月,1.06%~22.47%;8月,2.48%~30.57%)與RF模型(4月,1.56%~23.71%;8月,2.63%~34.93%)相似。而PLSR模型(4月,0.72%~22.03%;8月,2.16%~29.92%)的土壤水分分布圖更強烈地表現(xiàn)出所有部分的低土壤含水率。一般情況下,PLSR方法反演土壤水分的空間變異性低于ELM和RF方法,其主要原因是ELM和RF方法更能識別和反演土壤水分中的局部微小變化,能夠更詳細地表達地表信息和空間異質性。
3 討論
土壤水分是了解地表過程、陸-氣相互作用、干旱預測、作物生長模式等的基礎,是一個動態(tài)變量,受多種因素的影響,如植被覆蓋、地表粗糙度、土壤類型、地形等,在不同的時空尺度上,即使在較小的區(qū)域內也會發(fā)生顯著的變化。本文在建模方法上選擇了PLSR、ELM和RF構建研究區(qū)土壤含水率反演模型,經過對比分析發(fā)現(xiàn),在相同條件下ELM、RF算法效果優(yōu)于PLSR算法,因為土壤含水率與環(huán)境變量之間并非簡單的線性關系,PLSR模型在處理土壤含水率與環(huán)境之間復雜關系時具有一定的局限性[27],而ELM、RF算法在非線性問題中具有較強的解析力和較高的模型魯棒性,這與葛翔宇等[18]和蔡亮紅等[13]研究結果一致。但在ELM、RF土壤含水率反演模型中,本文建模集和驗證集R2均不小于0.65,其中RF模型的精度最高,這與王浩等[28]利用RF方法考慮溫度、蒸散發(fā)、地形等因子對土壤水分影響的結果相一致。土壤水分不僅與這3個變量有關,還與坡度、波段反射率、地表反照率和植被指數等其他變量有關[29]。本研究與傳統(tǒng)的經驗模型相比,基于機器學習的檢索算法避免了復雜的公式,提高了土壤水分的檢索效率[30]。但各環(huán)境變量對研究區(qū)土壤水分的影響不同,在紅色、近紅外、短波紅外1和短波紅外2波長范圍內,土壤含水率和土壤光譜反射率之間存在不顯著的線性關系,主要由于水在非飽和砂中的水力特性,土壤水分低時光譜反射率的降低非線性[26],本研究發(fā)現(xiàn)短波紅外1和短波紅外2波長與土壤水分之間線性相關。主要原因是短波紅外波段裸土和植被土壤的反射率與表面粗糙度的相關性最好。但是光譜反射率會受到土壤固有因素的影響,例如有機質含量、粒徑分布、礦物成分、表面粗糙度和土壤元素的顏色[31]。溫度植被干旱指數對土壤水分的影響最大,它可以將植被指數和地表溫度結合起來,從水分脅迫開始到植被指數出現(xiàn)變化的時刻之間的時間延遲是最小的,從而避免了紅波段和近紅外波段光譜響應的延遲[32],這一結果與王思楠等[33]利用不同干旱指數研究土壤水分的結果較為相似。地表溫度對土壤水分的影響也很大,因為它直接影響能量平衡分量和地表蒸散發(fā)。隨著地表溫度的增大,土壤水分含量減小。BABAEIAN等[34]和CARLSON等[35]也表明,影響土壤水分空間變異性的最重要參數是地表溫度。因此,在基于遙感數據常用的TVDI[36]、條件溫度植被指數(Vegetation temperature condition index,VTCI)[37]、植被供水指數(Vegetation supply water index,VSWI)[38]等反演土壤水分時,都使用了地表溫度參數。因此,有研究表明,土壤水分也受到這些環(huán)境變量因素的直接和間接影響。在環(huán)境變量中,研究區(qū)NDVI和綠度的增加表明植被覆蓋度增加,蒸騰作用增加,因此土壤水分增加。增加NDBI和亮度會增加地表反照率,從而降低土壤水分。地形參數也是一個控制地表溫度的重要影響因素,高程的增加導致氣溫下降,地表蒸散發(fā)減少,從而土壤水分增加。在該區(qū)域,表面生物物理性質對土壤水分的影響大于地形的影響。這些結果與其他一些研究結果相似[30]。
土壤水分受不同環(huán)境因素的顯著影響,不同模型在不同月份的反演結果相似。在毛烏素沙地腹部,4月降水量變化小,而且農作物處于生長初期,蒸發(fā)量小,土壤水分變化量不大;8月降水高度集中,沙壤土入滲率高,降水很快能滲入土壤,故很少能形成徑流,土壤水分出現(xiàn)明顯增加。土地利用在確定土壤水分變化的空間變異性方面非常重要,因為它影響植被覆蓋、入滲和徑流速率、蒸散過程、土壤表面特征。土地利用甚至可以消除地形相關參數對土壤含水率的影響。一些研究提供了通過反射圖像和輔助地理空間數據估計土壤濕度的解決方案。烏審旗南部地區(qū)的高土壤水分可能是由于土壤表面的蒸發(fā)潛力相對較低,降水多,植被對降水的截留作用比較大。北部地區(qū)土壤含水率低可能是降水稀少,植被覆蓋率低,基本上為沙地,水分下滲非常快。當沙丘被梭梭穩(wěn)定后,粘土和淤泥的數量迅速增加,因為懸浮顆粒堆積和細顆粒是由沙子的風化機制產生的。粘土和淤泥含量的增加也與土壤含水率有輕微的正相關關系[39]。沙地的表層土壤含水率低是因為由于高太陽輻射,土壤表面蒸發(fā)潛力高,植物的生長主要受土壤水分的控制,而土壤水分是光合作用所必需的。此外,土壤濕度調節(jié)植物蒸騰和蒸發(fā)的速率,進而影響近地表溫度、濕度和大氣水蒸氣[40]。本研究由于其他土壤特性(例如土壤孔隙度、堆積密度和土壤有機質含量)很難獲取,僅使用了17個環(huán)境變量,可能會導致反演結果的不確定性。除此之外,光學遙感受天氣的影響較大,本研究選取的遙感影像獲取時間范圍內研究區(qū)處于晴空狀態(tài)下,因此未考慮降雨條件下的不同模型的土壤水分估算表現(xiàn)。
4 結論
(1)通過對不同環(huán)境變量與表層土壤含水率進行相關分析,發(fā)現(xiàn)不同的環(huán)境變量與表層土壤含水率之間的相關程度不同。環(huán)境變量溫度植被干旱指數和地表溫度均與土壤含水率相關性較高。
(2)對比PLSR、ELM和RF 3種模型評價指標發(fā)現(xiàn),4月,RF模型的R2為0.74,RMSE為8.85%;8月,RF模型的R2為0.75,RMSE為8.66%,表明RF為土壤水分反演最優(yōu)模型。
(3)不同月份ELM和RF模型預測的土壤水分分布圖與PLSR模型預測的土壤水分分布圖比較相似。高土壤含水率出現(xiàn)在研究區(qū)的北部和東南部,中北部平坦地區(qū)的土壤含水率較低。此外, ELM與RF模型反演的土壤水分分布,突出了研究區(qū)地理位置的高低土壤含水率。而PLSR模型更強烈地表現(xiàn)出所有的低土壤含水率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
