基于機器學習預測自發性腦出血血腫擴大研究
2022-06-22 08:05:24袁偉侯文仲王倩莊堅偉謝國喜陳向林
廣東藥科大學學報 2022年3期
關鍵詞:模型
袁偉,侯文仲,王倩,莊堅偉,謝國喜,陳向林*
(1.廣州醫科大學基礎醫學院生物醫學工程系,廣東 廣州 511436;2.廣州醫科大學附屬第六醫院腦血管病科,廣東 清遠 511518)
自發性腦出血是指非創傷性的腦實質內或非腦室系統局灶性的血液集聚并多伴隨快速進展的神經功能障礙[1-2]。其在腦卒中各亞型中的發病率僅次于缺血性腦卒中,位居第二,約占所有卒中的10%~15%,是一種高致死致殘的疾患[3]。在早期約有30%的患者會出現血腫增大,并且致死致殘率會有明顯的上升。盡管存在一些爭議[2],但一般認為血腫體積增大13%~32%會明顯引起預后向更差的方向發展[4]。同時有學者研究證實針對有血腫增大風險的患者進行早期干預可以降低血腫增大的發生幾率[5-6]。
目前預測腦血腫擴大概率的方法有“9 分評分”“BRAIN 評分”“BAT 評分”“NAG 評分”等多種評分模型。最為常用的BRAIN 評分是由學者Wang[7]在2014年提出,評分項包括基線腦出血量(B)、復發性腦出血(R)、使用華法林抗凝(A)、腦室出血(I)和從發病至CT 時間(N)5 項,總分最高24 分,如表1 所示。其基于一項前瞻性大樣本研究,隨著分數的增加伴隨著腦血腫擴大的可能性上升,0~24分的血腫擴大概率為3.4%~85.8%。BRAIN 評分對腦出血患者血腫擴大具有較好預測效能。
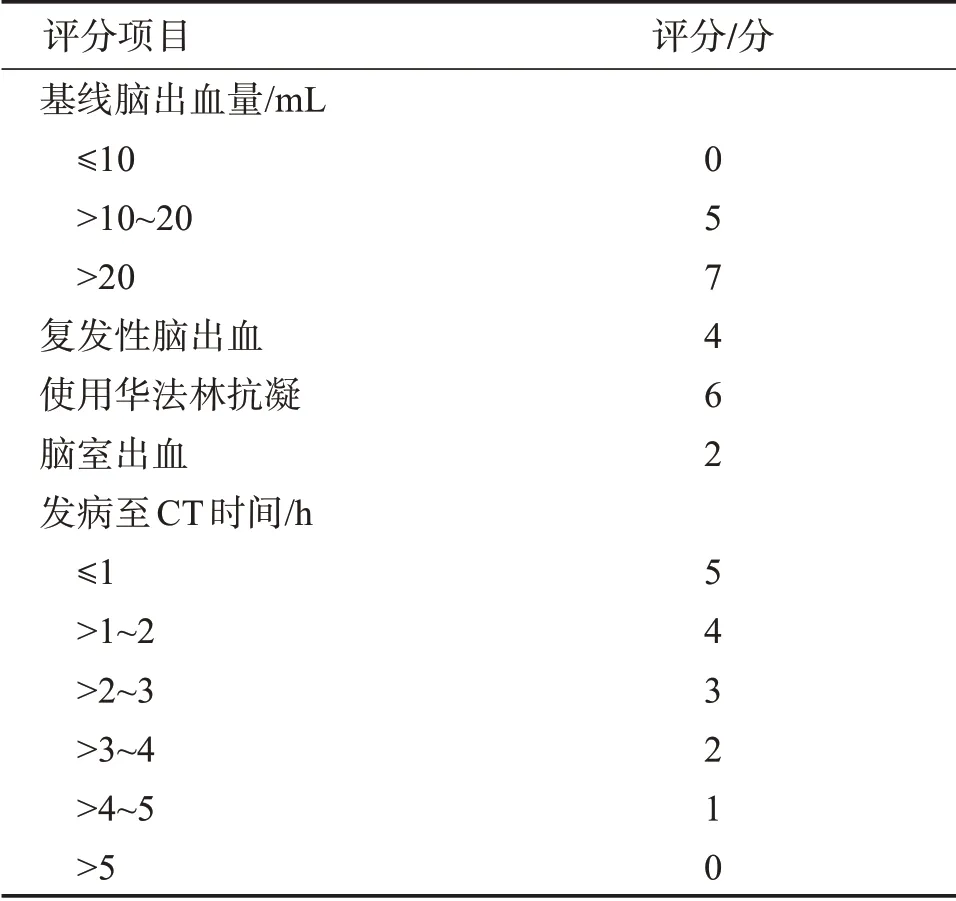
表1 BRAIN評分量表Table 1 BRAIN rating scale
但BRAIN 評分也存在一定的局限性。BRAIN評分標準提出者只是寬泛地給出了0~24 分的血腫擴大概率范圍,而在實際應用中,計算出某位病人BRAIN 評分后,參照這個結論也無法準確地獲得血腫擴大的具體概率值,臨床應用具有局限性。而其他研究者,如王永平等[8]根據收集的111例病人數據進行血腫擴大概率計算,結果為0%~62.9%,與BRIAN 結論不同。學者Joshua[9]統計的122 位病人的BRAIN 血腫擴大概率為11%~57%,也與其結論存在較大的差異。基于上述的疑問,研究團隊對該中心部分病人使用金標準(即24 h 內2 次CT 檢查,且血腫擴大體積超過6 mL)確定血腫擴大與否,得到的血腫擴大概率為25.0%~72.8%,與BRAIN 評分結果差異性較大。因此,如果本研究采集的樣本數據直接采用BRAIN 作者的血腫擴大概率結論來預測血腫擴大發生的可能性,會產生較大的誤判,指導臨床診斷會有一定的錯誤,不利于后續治療的進行。此外,因為很多臨床醫生在實際使用時會將0~24 的評分劃分為0~5、6~9、10~11、12~244 個區間段,分別計算每個區間對應的血腫擴大概率,具體病人根據所屬區間段確定血腫擴大的可能性[8-9]。但是因為樣本空間的問題,不同單中心計算的區間血腫概率也存在很大的差異,直接參看相互結論會造成大概率的誤診。可見BRAIN 評分非常依賴研究對象本身的樣本特點,因此使用時不應參照已有的研究結果,應該根據本中心的數據,獨立地進行0~24分的概率值或者概率區間的統計,同時應留意樣本數據的增加,及時進行重新統計,確保結論的準確性。
相比于BRAIN評分,血腫擴大的金標準雖然檢測手段單一,但是因為資源的限制,并且2 次CT 檢查間隔需要一定的時間,期間病人的病情會發生劇烈的變化,因此,常常希望借助已有的常規檢查數據在第1 次CT 檢查后就能得出病人血腫擴大的可能性,以為及時正確的治療方案提供幫助。但是BRAIN 評分又有一定的不足。基于上述的問題,本研究使用支持向量機、邏輯回歸、決策樹和極限學習機4 種自動預測模型進行血腫擴大的分類,對比BRAIN 評分結果的優劣,預期在訓練精度、測試精度、敏感性、特異性、模型的實時訓練提升等指標上獲得提高,同時減輕醫生的計算負擔,更好地輔助臨床的診斷和治療。
1 對象與方法
1.1 對象
回顧性連續納入廣州醫科大學附屬第六醫院2015 年1月至2019 年12月期間腦科住院的自發性腦出血患者150例。其中男性98例,女性52例。本研究遵守赫爾辛基宣言,并獲得廣州醫科大學附屬第六醫院倫理委員會的批準,每位參與研究的對象均簽署了知情同意書。
納入標準:(1)腦出血診斷符合2019 年中國腦出血診治指南修訂的腦出血診斷標準;(2)發病6 h內首次行頭部CT;(3)發病24 h 內完成頭部CT 復查。排除標準:(1)既往發生顱內出血;(2)單純的腦室出血(不伴有明顯的腦實質出血)、腦干出血、蛛網膜下腔出血、硬膜下血腫、硬膜外血腫及腦梗死后出血等;(3)因血液系統疾病導致的腦出血或其他原因不明的腦出血。
1.2 研究方法
1.2.1 資料收集 基線數據收集 患者的年齡、性別、居住地、種族、出生日期(可用身份證信息識別)。其他一般病史相關資料,包括既往有無高血壓史、糖尿病、吸煙、酗酒、相關其他遺傳病史及家族史、手術史、藥物治療史,過敏史以及其他特殊疾病史。
所有自發性腦出血患者入院的生命體征,包括體溫、血壓、脈搏及呼吸次數,其中血壓記錄最重要,包括收縮壓及舒張壓數值。患者入院時的格拉斯哥昏迷量表評分(GCS)標準包括睜眼、語言、運動反應,最高分為15分。目的是準確判斷自發性腦出血患者入院時意識障礙程度,分數越低意識障礙越重。
影像學資料收集:收集發病后6 h 內的首次CT和發病后24 h內2次復查CT資料,包括初始血腫體積、增大后血腫體積。血腫體積計算由廣州醫科大學附屬第六醫院2名影像科醫師獨立閱片并出具書面報告結果。計算方法是根據多田公式計算得出,公式為:V(出血量)=即血腫體積=(A×B×C)/2[10],其中A:最大血腫面積層面血腫的最長徑,B:最大血腫面積層面上與最長徑垂直的橫徑,C:CT片中出現出血的厚度,長度計算方式為:層厚×層面數,實際應用中組織層厚常設為5 mm。血腫擴大定義為血腫體積較前增加超過6 mL,并將其作為血腫擴大的金標準。所有患者的原始DICOM 圖像均由GE 公司的64排螺旋CT掃描完成,層厚為5 mm。
高血壓病定義為:既往確診高血壓病史,或收縮壓≥140 mmHg,或舒張壓≥90 mmHg,或使用降壓藥物。吸煙的定義為:吸煙≥1 支/天。飲酒的定義為:任意的酒精攝入≥1 次/周[11]。
最終確定納入數據分析的檢測項目包括:性別、吸煙史、飲酒史、使用華法林抗凝、抗血小板、破入腦室、年齡、GCS、入院收縮壓、入院舒張壓、急診血壓、急舒張壓、血糖(Glu)、總膽固醇(TC)、三酰甘油(TG)、高密度脂蛋白膽固醇(HDL-C)、低密度脂蛋白膽固醇(LDL-C)、活化部分凝血活酶時間(APTT)、凝血酶原時間(PT)、國際標準化比值(INR)、血紅蛋白(Hb)、血小板計數(PLT)、血鈣(Ca)、初始血腫體積、發病至首次CT 檢查時間。總共25項。
1.3 自動預測模型簡介
1.3.1 支持向量機 支持向量機由Cortes和Vapnik[12]于1995年提出,是一種二分類模型。它的基本思想是求解特征空間上正確劃分訓練數據集的唯一分離超平面,并且使得距離超平面最近的異類樣本之間的間隔最大化。可形式化為一個求解凸二次規劃問題[13-14]。一般分離超平面被定義為:

對于給定的超平面樣本點(xi,yi)來說,只需根據公式(2),(3)計算得到w和b的值,超平面即可確定:
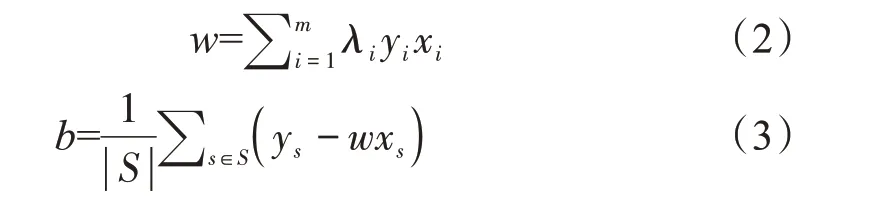
其中:λi為拉格朗日乘子,S為假設的支持向量個數[15]。
支持向量機是在包括醫療領域在內,廣泛使用的數據分類方法[16-17]。根據本研究的數據特點,參數設置時懲罰系數的取值為0.1;核函數選取為線性(linear);正則化時采用L2 正則化,即直接在原來的損失函數基礎上加上權重參數的平方和;誤差項達到指定值時則停止訓練參數為0.001;默認所有類權重值相同。
1.3.2 邏輯回歸 邏輯回歸又稱為邏輯回歸分析,是一種廣義線性回歸分類模型,目標是通過一組變量的組合使得預測結果的概率最大化[18]。
邏輯回歸采用對數似然損失函數(代價函數)[19]:
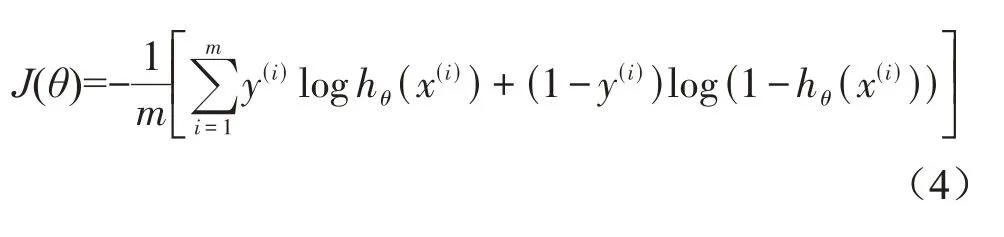
預測函數為:

使用梯度下降算法進行邏輯回歸模型參數的更新:
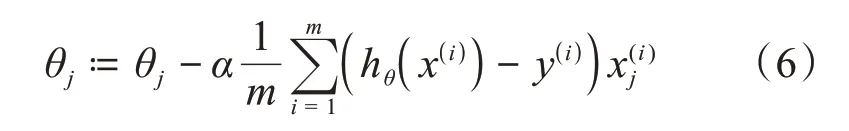
其中:α為懲罰系數,調節懲罰項的大小。
邏輯回歸具有簡單高效、并行性、解釋性好以及方便擴展等優點,被廣泛地應用于醫學數據分類任務[20-23]。本研究中正則化系數取值為0.00001;正則化時采用L1正則化,即直接在原來的損失函數基礎上加上權重參數的絕對值;誤差項達到指定值時則停止訓練參數大小為0.0001;最大迭代次數為1000。
1.3.3 決策樹 決策樹是一種基于if-then-else 規則的有監督分類學習算法,采用樹形結構,使用層層推理來實現最終的分類。一般由根節點(包含樣本的全集)、內部節點(對應特征屬性測試)和葉節點(代表決策的結果)3 個元素構成。決策樹的生成通常有3 個步驟:特征選擇、決策樹的生成、決策樹的修剪。
1、特征選擇
“佳禾農資不管發展到多大規模,永遠不離開農業,離不開農村。我們種地就是為農民打工。”他表示,作為一個負責任的化肥貿易商、生產商,通過整合農業生產各要素,輸出種植模式,才能更好地為農業服務,使自身的經營工作更接地氣、更加穩健,從而才能把佳禾打造成一個基業長青的“百年老店”。
在訓練數據集中,每個樣本的屬性可能有很多個,不同屬性的作用大小不同。通常使用“信息增益”篩選出與分類結果相關性較高的特征,也就是分類能力較強的特征,公式(7)。
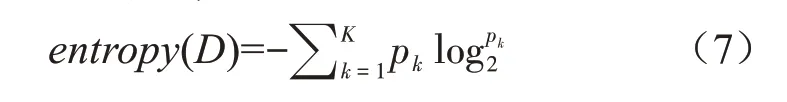
其中,pk為當前樣本集D中第k類樣本所占的比例。K為類別的總數。
2、決策樹生成
特征選定,就可以從根節點觸發,計算所有節點特征的信息增益,選擇信息增益最大的特征作為節點特征,再根據該特征的不同取值建立子節點,并對每個子節點使用相同的方式生成新的子節點,直到信息增益很小或者沒有特征可以選擇為止。
3、決策樹剪枝
防止算法過擬合,去掉部分分支來降低過擬合的風險。
決策樹是最簡單的機器學習算法,它易于實現,可解釋性強,完全符合人類的直觀思維,在金融決策、醫療診斷領域有著廣泛的應用[24-25]。
1.3.4 極限學習機 極限學習機是一種用來訓練單隱藏層前饋神經網絡算法[26]。根據插值定理和普通極限定理推導可知,只要激活函數無限可微,當隱含層神經元數等于訓練樣本數時,單隱藏層前饋神經網絡可以零誤差逼近訓練樣本,且與隱含層輸入權值wi和閾值bi的選取無關[27]。
極限學習機的輸入層權值和閾值采用隨機選取方式產生,并且不需要人為設置網絡初始權值和初始閾值等參數,大大提高了訓練速度,同時克服了過擬合問題。
“廣義”的單隱藏層前饋神經網絡極限學習機的輸出表示為[28]:
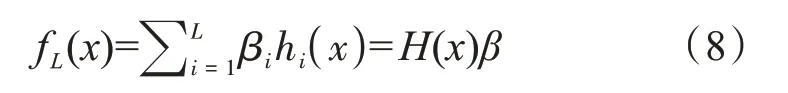
其中:L為節點數目,β是隱藏層與輸出層之間的輸出權重,hi(x)是第i個隱藏層節點的輸出,H(x)是隱藏層輸出矩陣。在實驗中設置的神經元數為120,與訓練樣本數相同。
近些年極限學習機在醫學領域得到廣泛的使用,Hu 等[29]使用深度CNN 和極限學習機器從X 射線圖像中進行實時COVID-19 的診斷,徐丹使用極限學習機進行乳腺腫瘤識別和診斷[30],王之瓊等[31]利用基于極限學習機算法進行輕度認知障礙的輔助診斷,都取得了比較好的效果。
1.4 統計學分析
應用SPSS 26 軟件對數據進行統計分析,采用多因素logistic 回歸統計樣本的基本數據,并進行血腫擴大的影響因素及其共線性分析,見表2。其中性別使用女性作為統計參考類別;吸煙史、飲酒史、抗凝、抗血小板、破入腦室使用陰性作為統計參考類別。根據BRAIN 評分標準(24 分制,見表1),統計每位病人包括基線腦出血量(B)、復發性腦出血(R)、使用華法林抗凝(A)、腦室出血(I)和從發病至CT 時間(N)在內的5 個指標,給出BRAIN 評分結果。將0~24 的評分劃分為0~5、6~9、10~11、12~244 個區間段,對應CT 檢測金標準分別計算每個區間對應的血腫擴大、非血腫擴大以及血腫擴大的概率。應用受試者工作特征曲線(receiver operating characteristic curve, ROC)評估BRAIN 評分對血腫擴大的預測結果,計算其敏感度、特異度,以及曲線下面積(area under the curve,AUC)數值,以P<0.05為差異有統計學意義。
支持向量機、邏輯回歸、決策樹與極限學習機4種算法是在基于python3.6,tensorflow1.2.0 版本Pycharm 軟件下編程實現的。電腦配置為Intel(R)Xeon(R)CPU E3-1225 v6@3.30GHz,RAM 12.0GB。隨機抽取80%(120 個樣本)形成訓練集,剩余20%(30 個樣本)為測試集。算法訓練時采用10 折交叉驗證,取平均值作為結果。最后統計4 種算法的訓練精度和測試精度、敏感度、特異性和ROC 曲線以及AUC值。
2 結果
2.1 腦出血血腫擴大的危險因素分析
根據統計結果(P<0.05),150 例腦出血患者中65例(43.33%)出現血腫擴大,85例(56.67%)未出現血腫擴大。吸煙史、使用華法林抗凝、抗血小板、GCS 評分、均有統計學意義,為血腫擴大的獨立影響因素。其中吸煙的患者比不吸煙的患者血腫擴大概率增加1.925 倍;使用了華法林抗凝比未使用的情況血腫擴大概率增加14.50 倍;使用抗血小板后血腫擴大的概率會比未使用的情況增加9.97 倍;GCS 評分增加一個級別,血腫擴大概率下降為73.1%,即較低的GCS 評分與血腫擴大顯著相關。對上述因素進行共線性分析,吸煙史、使用華法林抗凝、抗血小板、GCS 評分的方差膨脹因子(VIF)分別為1.695、1.373、1.785 和1.710,容差分別為0.590、0.729、0.560 和0.585。膨脹因子均小于10,同時容差均大于0.1,各因素之間無共線,均為獨立危險因素,見表2。
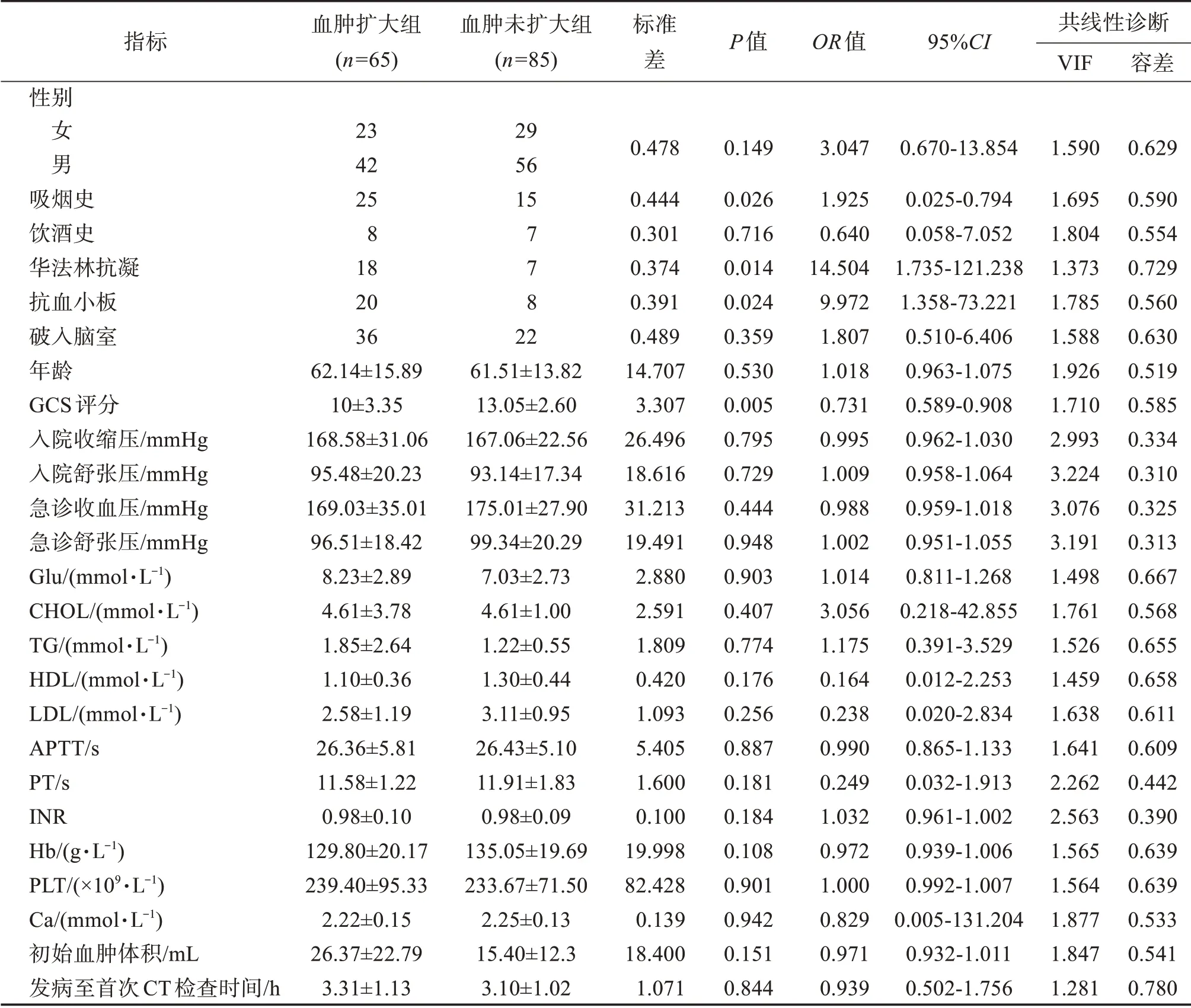
表2 患者臨床資料統計結果Table 2 Statistical results of clinical data of patients
剩余的因素均無顯著性(P>0.05),是血腫擴大的非獨立因素。其中與血腫擴大概率增大正相關的因素為“性別”“破入腦室”“年齡”“入院舒張壓”“急舒張壓”“血糖”“總膽固醇”“三酰甘油”“國際標準化比值INR”“血小板計數”。與血腫擴大概率增大負相關的因素為“飲酒史”“入院收縮壓”“急診血壓”“高密度脂蛋白膽固醇”“低密度脂蛋白膽固醇”“活化部分凝血活酶時間”“凝血酶原時間”“血紅蛋白”“血鈣”“初始血腫體積”和“發病至首次CT 檢查時間”。共線性分析顯示,所有因素的膨脹因子也均小于10,且容差均大于0.1,各因素之間無共線,是影響血腫擴大的必要因素。
2.2 自動預測模型與BRAIN評分對比
單獨對BRAIN 評分進行分析,所有樣本的BRAIN 評分平均值為8.65(標準誤差0.041),顯著性小于0.01,且評分值增加一個等級血腫擴大概率增加1.18倍。ROC曲線結果顯示,BRAIN評分預測血腫擴大的敏感度為56.9%,特異性為74.1%,曲線下面積為0.706,95%CI 為: 0.62~0.79,見表3、圖1。根據BRAIN 評分標準,0~5、6~9、10~11、12~244 個區間的實際血腫擴大概率分別為25%(11/44)、36.2%(17/47)、45.5%(10/22)、72.8%(27/37),見表4。結果顯示隨著BRAIN 的評分增加血腫擴大率有明顯的上升趨勢,但是較低分數段的血腫擴大概率高于以往研究結論(0~24 分的血腫擴大概率為3.4%~85.8%)[7]。
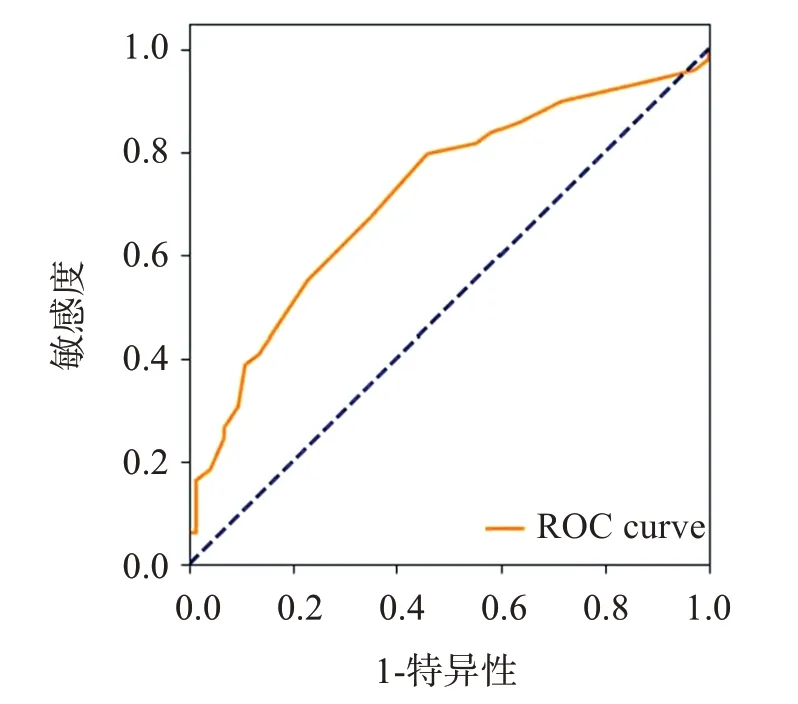
圖1 BRAIN 評分預測血腫擴大的受試者工作特征曲線Figure 1 ROC curve of BRAIN score prediction model
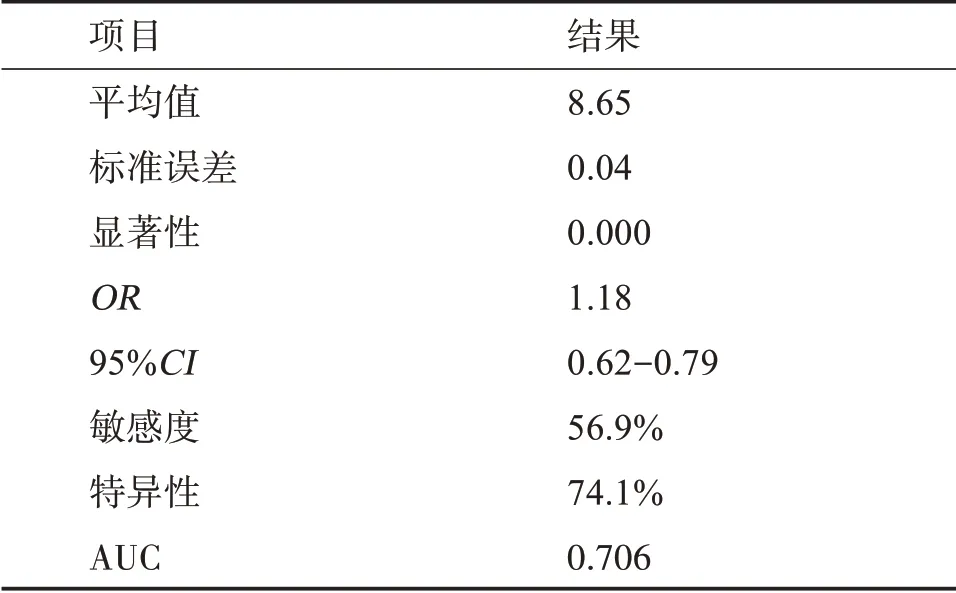
表3 BRAIN 評分的logistic回歸分析Table 3 Logistic regression analysis of BRAIN score
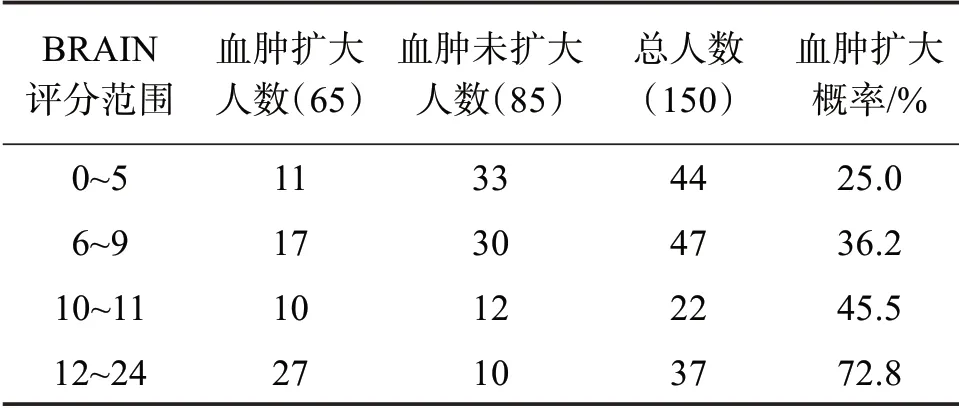
表4 BRAIN評分區間實際血腫擴大和非血腫擴大的統計結果Table 4 Statistical results of actual hematoma enlargement and non-hematoma enlargement in BRAIN score range
從4 種算法之間的對比來看,決策樹模型雖然在訓練精度和敏感度上分別達到了93.33% 和80.00%,高于支持向量機和邏輯回歸模型,但是在測 試 精 測(66.67%)、特 異 性(53.33%)和AUC(0.667)3 個指標中都是4 種算法最差的。支持向量機與邏輯回歸模型的5項指標非常接近。最好的模型為極限學習機,它的訓練精度為99.25%,測試精度為93.33%,敏感度為98.50%,特異性為85.90%,AUC為0.926,所有指標都是4種算法中最優的。可見目前作為主流的神經網絡方法優于傳統的統計學分類方法,能夠學習更為復雜的樣本數據,也說明其廣泛應用于醫學數據分類任務的合理性,見表5。圖2可以直觀看到4種算法的ROC對比圖。

表5 4種自動預測模型間的指標對比Table 5 Index comparison among four automatic prediction models
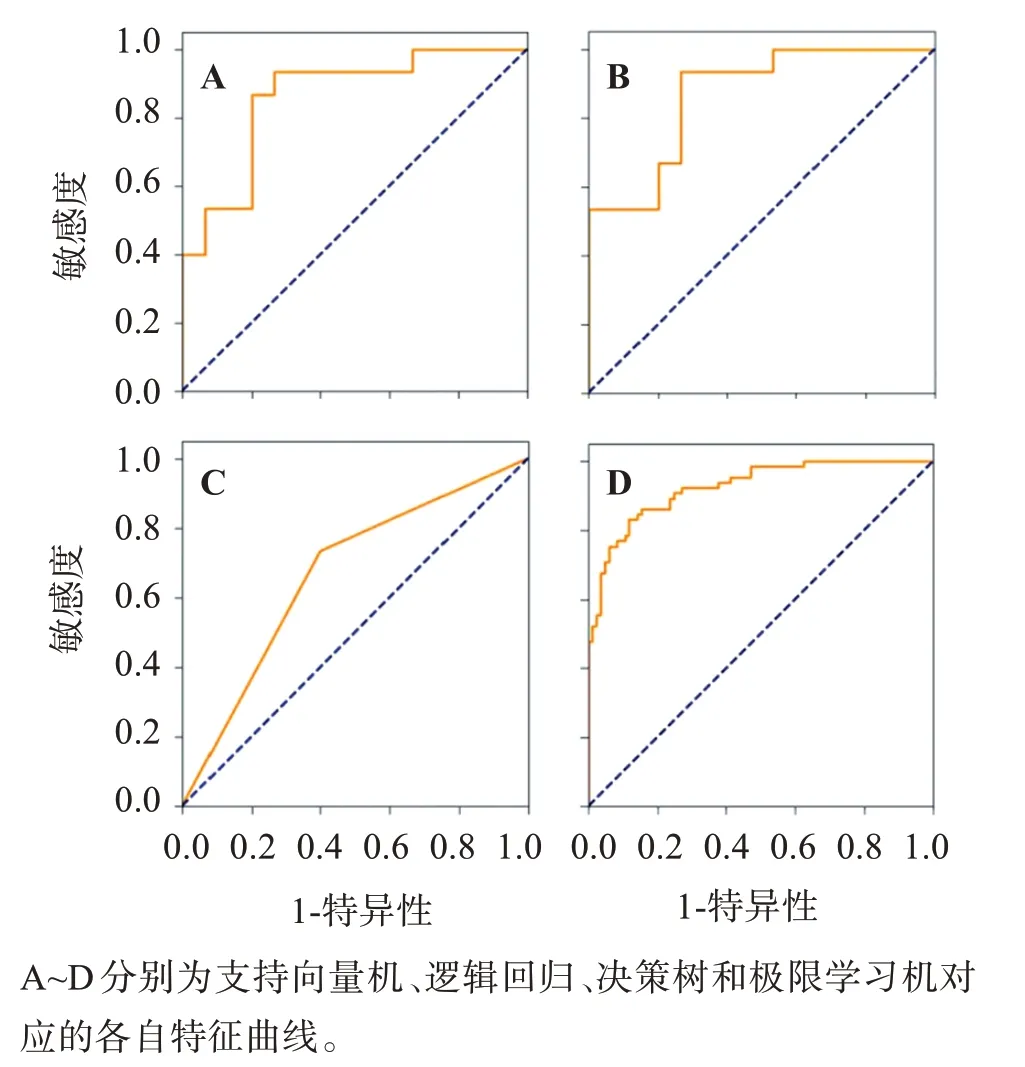
圖2 4種自動預測模型血腫擴大的受試者工作特征曲線Figure 2 ROC curve of four automatic prediction models
將4 種算法與BRAIN 評分進行對比,決策樹在特異性、AUC 兩個指標以及邏輯回歸模型的特異性一個指標比BRAIN 評分稍差,其他結果都高于BRAIN 評分。總體而言,支持向量機、邏輯回歸和極限學習機都優于BRAIN評分,尤其是極限學習機模型,敏感度、特異性、AUC 3項指標都遠超BRAIN評分。這也說明按照金標準統計出的BRAIN 0~24分血腫擴大概率值,用來評判新的數據,在準確度上遜色于機器學習算法,反映出BRAIN評分標準設計合理性欠缺。
此外,本研究也對比了不同研究者BRAIN區間概率統計結果的差異性。表6 提供了學者王永平[8]和Joshua[9]各自給出的BRAIN 區間血腫擴大概率值,同時也計算了本研究150 例病人在金標準下實際的區間血腫概率擴大值,并且對比了4 種算法按照BRAIN 評分區間各自預測的血腫擴大概率結果(樣本數據中每個區間隨機抽取20%樣本數據進行預測)。從中可以看出,兩位學者統計的BRAIN 4個區間的血腫擴大概率值與本中心實際血腫擴大的概率值差距較遠,也與BRAIN評分提出者給的結論不同,說明4個研究中的數據差異較大,無法直接作為結論相互參看。而如果使用4種血腫擴大的自動預測模型進行BRAIN 區間的血腫擴大概率計算會發現,支持向量機、邏輯回歸和決策樹3種模型只是在0~5 范圍預測血腫擴大概率相對誤差稍大(其中邏輯回歸模型預測概率相對較好,為18.2%,實際血腫擴大概率為25.0%)。隨著BRAIN 評分區間的提高,3 種算法的預測血腫擴大概率都與實際金標準值逐漸接近。當為最大值區間12~24 時,基本和實際血腫擴大概率值相同,其中支持向量機模型預測結果與實際血腫擴大概率完全吻合(實際血腫擴大概率為72.8%),而決策樹相對差一些。單獨分析極限學習機模型,其在BRAIN 評分的4 個區間內,都可以準確地預測血腫擴大的概率,與實際金標準統計結論的情況非常接近。相比BRAIN模型,預測血腫發生概率更符合樣本采集醫院的實際情況,預測的結果也更加準確,屬于4種模型中最好的。

表6 4種自動預測模型在BRAIN評分區間預測血腫擴大概率的對比結果Table 6 Comparison results of four automatic prediction models in predicting hematoma expansion probability in BRAIN score interval %
另外,4 種算法都可以保存以往的訓練模型,當新的樣本數據加入,可以自動地進行血腫擴大的判定,減輕了醫護人員的負擔。表7 列舉了支持向量機、邏輯回歸、決策樹和極限學習機在進行模型訓練和測試新增單一數據時的運行時間。不同于BRAIN 評分標準的較長計算時間,只有極限學習機的訓練時間為18.902 s,其余時間均在1 s 以下。日后當病例數據增加時動態地進行模型的重新訓練也非常的省時,也能使得模型更為貼合研究所在醫院的實際血腫擴大概率分布特點。

表7 4種自動預測模型的模型訓練與新樣本血腫擴大概率判別時間對比Table 7 Comparison between model training time of four automatic prediction models and evaluating time of hematoma enlarge‐ment probability of new samples
3 討論
腦出血具有較高發病率、病死率、致殘率的特點。血腫擴大是腦出血急性期較為常見現象,也是不良預后的重要危險因素。因此,發現靈敏準確的血腫擴大概率的預測模型,盡早識別腦出血患者中血腫擴大的高危人群,成為目前該領域研究的重點問題。
本研究根據多因素logistic 回歸統計分析,得出吸煙史、使用華法林抗凝、抗血小板、GCS 評分為血腫擴大的獨立因素,在血腫擴大概率評判時應該作為重點因素考慮。同時本研究對比了BRAIN 評分模型與支持向量機、邏輯回歸、決策樹和極限學習機這4 種自動預測模型的優缺點。測試結果也顯示,無論從訓練精度、測試精度、到敏感性、特異性和ROC 曲線下面積,支持向量機、邏輯回歸和極限學習機3 種算法都優于BRAIN 評分標準,尤其是極限學習機模型,各項結果都非常的優異。并且當數據量增加時,極短的運行時間,自動地進行模型的訓練,都使得模型的調整成為可能,而傳統的BRAIN 評分的區間統計方式是不具備這樣的優勢的。
分析上述預測模型優略的原因,主要的因素在于BRAIN評分的分數取值為離散值,并且各個因素的取值大小也是作者的經驗考慮,沒有能夠進行精確的數學建模和計算,自然精準性就差一些,同時該模型也只是考慮了血腫擴大的5個因素,而廣泛的研究顯示影響血腫擴大的因素并非只有這5個指標,因此該評分標準與血腫擴大的關聯性就不夠全面。
而4種自動預測模型將與血腫擴大相關的獨立和非獨立因素全部納入到預測模型的輸入變量中,根據數學的統計算法和神經網絡學習機制,客觀的進行血腫擴大概率的學習和識別,自然可以得到相對較好的判別結果。支持向量機、邏輯回歸、決策樹屬于傳統的機器學習模型,它們是根據具體的算法規則進行血腫擴大的預測,一些特異性的數據在“規則”下是無法正確地評判的。而極限學習機算法屬于神經網絡模型的一種,具備處理線性不可分的問題,并且更精準,容錯性更好。在學習過程中,神經網絡能夠從輸入數據中挖掘更多的信息,完成更復雜的任務。因此非常適合學習非線性、高緯度、復雜的樣本數據,掌握區分是否血腫擴大的特征,得到了最優的結果。這也是目前在醫學數據分析中大量引入神經網絡的原因。因此根據腦血腫擴大預測指標的特點,建議臨床醫生在選擇自動預測模型時使用極限學習機模型。
本研究也具有一定的局限性,如所有模型的測試精度都稍差于訓練精度,造成的原因是樣本量太少,測試數據和訓練數據不完全一致,模型訓練后始終無法對少量測試數據進行識別。應該在今后的研究中不斷的加大樣本數據量。此外,樣本量的不足也造成了采用多因素logistic 回歸進行數據統計時,飲酒史對于血腫擴大的影響并沒有正確的體現出來,而在很多研究中這個因素都被認定為影響血腫擴大的獨立影響因素。
4 結論
綜上所述,本研究引入支持向量機、邏輯回歸、決策樹和極限學習機這4種自動預測模型來進行血腫擴大概率的預測分析,在多個指標對比中都優于傳統的BRAIN 評分標準,尤其是極限學習機模型,各項結果都非常的優異。并且模型可以動態地學習和調整樣本數據,進一步提高了預測準確性,能夠得出更為準確的血腫擴大預測結果,為臨床醫生的后續診斷和治療提供幫助。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
