基于卷積神經網絡的智能找礦預測方法
——以甘肅龍首山地區銅礦為例
2022-06-23 05:18:50李忠潭薛林福冉祥金李永勝董國強李玉博戴均豪
吉林大學學報(地球科學版) 2022年2期
關鍵詞:模型
李忠潭, 薛林福, 冉祥金,李永勝,董國強,李玉博,戴均豪
1.吉林大學地球科學學院,長春 130061 2.中國地質調查局發展研究中心,北京 100037 3.自然資源部礦產勘查技術指導中心,北京 100083 4.甘肅省地質調查院,蘭州 730000
0 引言
將大數據思維和深度學習方法引入地學領域,并利用數學工具進行數據清理和挖掘,將有助于礦產資源預測[1]。應用機器學習技術進行地質找礦信息挖掘與找礦預測遠景區圈定已經成為當今數字地質科學的前沿研究領域。目前地質礦產勘查工作積累了大量的地質、地球化學、地球物理及遙感地質資料,為機器學習及深度學習算法的應用提供了大數據支撐[2]。
近年來,諸多學者致力于利用機器學習的方法進行地質找礦信息挖掘與集成研究。例如:Brown等[3]將多層感知機模型用于多源數據集成,預測澳大利亞部分地區的金礦成礦潛力,結果表明多層感知機的預測性能要好于證據權方法和模糊邏輯方法;Leite等[4]將徑向基函數網絡應用于巴西北部卡拉加斯礦產省銅-金區域成礦潛力預測,圈定了銅-金成礦的有利遠景區;Leite等[5]又將概率神經網絡模型應用于巴西亞馬遜河流域卡拉加斯礦產省東北部的潛在鉑族元素(鉑族元素)礦化遠景區的預測,繪制了鉑族元素礦點礦產潛力圖;陳永良等[6]定義了面向礦產靶區預測的三層Boltzmann機模型,根據證據權系數和統計單元證據組合特征計算單元成礦有利度,圈定找礦靶區,并應用于新疆阿勒泰地區的礦產靶區預測研究;Carranza等[7]對比了隨機森林、證據權法和邏輯斯蒂回歸等模型的成礦預測應用效果,結果表明隨機森林方法表現出了更優秀的擬合和泛化性能,且對于缺失值和小訓練樣本集(小于20個)同樣具有較好的處理和能力;Zhao等[8]利用多重分形和人工神經網絡方法識別寧強礦區與金銅礦化有關的地球化學異常;Mehrdad等[9]提出了一種基于混合遺傳的廣義隨機森林(GRF)模型,并在伊朗東北部Feizabad地區取得了較好的應用效果;Ghezelbash等[10]提出了一種改進的數據驅動簡單加權法生成遠景模型的方法和基于徑向基函數核的支持向量機(SVM)方法,并在伊朗東北部Moalleman地區圈定銅金成礦有利區,對比發現后者的預測模型更為可靠。
目前,深度學習方法已成功應用于成礦預測和地球化學異常識別研究。例如:Luo等[11]應用深度變分自編碼器(VAE)提取地球化學異常,發現VAE識別的地球化學異常與已知的鐵多金屬礦床具有密切的空間相關性;Zhang等[12]應用自編碼器和基于密度的空間聚類相結合的方法識別地球化學異常,證明了自編碼器和基于密度的空間聚類適用于多元地球化學異常檢測。
卷積神經網絡(CNN)是目前應用最廣泛的神經網絡模型之一[13],在地質學領域,CNN已經成功應用于巖性識別[14]、地質填圖[15]和三維地質結構反演[16]等研究。近年來,諸多學者把CNN應用于找礦預測研究。劉艷鵬等[17]應用CNN建立了安徽省兆吉口鉛鋅礦床地表 Pb 分布特征與礦體就位空間關系模型,并進行成礦預測,得出CNN可以有效挖掘地表元素分布與礦體就位空間關系的結論;Li等[18]提出了一種基于CNN分類的文本挖掘方法,建立了從地學文本數據中提取關鍵找礦信息的工作流程,以四川拉拉銅礦為例,完成了智能分類與標注,探索了數據之間的潛在關系,實現了地質找礦信息的智能提取;蔡惠慧等[19]以甘肅省大橋地區金多金屬礦田為例,提出了利用一維CNN替代傳統的人工計算,通過對研究區金多金屬礦的地球化學及地球物理數據進行訓練,挖掘研究區綜合成礦信息,依據訓練結果劃分出4 類成礦遠景區,發現CNN模型能夠很好地實現礦產資源智能化預測評價;Zhang等[20]測試了在數據驅動的礦產遠景制圖中,使用無監督卷積自編碼(CAE)支持CNN建模以合成多地理信息的有效性,結果表明利用CAE訓練數據建立CNN模型的結果與研究區已知金礦床具有很強的空間相關性,表明其是一種新的潛在的礦產遠景填圖方法;Li等[21]將CNN用于中國福建省西南部的礦產遠景測繪,構造的模型所獲得的礦產遠景區域與已知礦化位置具有很強的空間相關性;Sun等[22]對比了隨機森林(RF)、SVM、人工神經網絡(ANN)和CNN等方法,在中國江西省南部進行了數據驅動的鎢元素礦產遠景建模;Li等[23]將地球化學數據與CNN算法和遷移學習方法相結合,勾勒了中國安徽省東部張八嶺地區地球化學金礦找礦遠景區。
綜上可知,前人基于深度學習方法的礦產預測方法并未將地球化學元素數據和航磁數據結合起來進行討論。甘肅龍首山地區成礦地質條件良好[24],已發現眾多鐵、銅、鉬和金等礦點,具有巨大的礦產資源潛力,且資料齊全,為開展人工智能找礦預測創造了良好的條件。本文以龍首山高臺縣臭泥墩—西小口子地區的銅礦為例,利用地球化學元素數據和航磁數據,旨在探討基于二維卷積神經網絡的智能找礦預測方法的應用。
1 地質背景
研究區位于甘肅省高臺縣臭泥墩—西小口子地區,大地構造上位于華北板塊阿拉善陸塊龍首山基底雜巖帶,阿拉善陸塊南緣龍首山山體(圖1a)。出露地層有新太古界—早元古界龍首山巖群(Ar3-Pt1L.)、中元古界薊縣系墩子溝群(JxD)、侏羅系龍鳳山組(J2l)、白堊系廟溝組(K1m)及古近系白羊河組(E3b)。區域構造極為復雜,主要受加里東期和海西—燕山期陸內調整階段的影響,逆沖構造和伸展構造相互疊加,以EW向和NWW向為主(圖1b)。區內以大青山向斜、大青山北沖斷層、天城—大孤山弧形褶皺帶為主要構造,次級構造發育,且存在隱伏深大斷裂,有利于巖漿侵入和礦床的形成[25]。研究區侵入巖較發育,屬阿拉善構造巖漿巖帶龍首山基底雜巖帶構造巖漿巖亞帶合黎山后碰撞巖漿巖段,主要為大規模中酸性侵入巖,具中深成相,屬鈣堿性系列,侵入活動以加里東中期最強烈,巖漿侵入活動與構造運動序次有較明顯的依存關系。海西早期侵入體分布于盤頭山—窯泉—大青山等EW向構造帶內。加里東期巖體主要侵位于研究區南部方架山—小孤山—猴兒頭一帶。
研究區礦產的形成與巖漿侵入活動緊密相關,尤其與海西早期巖漿侵入活動關系密切,是礦產的主要成礦期,區內礦點、礦化點較多,且礦(化)體具有一定的規模。礦床的形成與地層、構造、巖漿巖有著密切的關系,區內及周邊已發現鐵、鈦、錳、銅、鎳、鉛和鋅等礦種。研究區內現已發現的典型礦床有板凳溝鈦磁鐵礦、大青山銅礦以及東小口子鐵礦等。
研究區內海西期在裂陷拉張環境下形成巨大的巖漿帶[26],在巖漿演化過程中形成一系列與巖漿巖有關的礦產,為區內海西期構造-巖漿旋回巖漿巖成礦系列。成礦模式為隨著加里東期大規模造山運動的結束,在海西期陸內調整階段形成拉張的裂陷環境,在海西早期隨裂陷的拉伸侵入中基性巖漿,巖漿在侵入過程中分異形成閃長巖和角閃巖;海西中期裂陷進一步拉張,以花崗閃長巖和二長花崗巖為主的中酸性巖漿大規模侵入[27],在中酸性巖漿侵入接觸部位形成矽卡巖型銅礦及大規模黃鐵礦化蝕變帶;海西晚期在斷裂構造交匯部位侵入石英二長斑巖體并形成斑巖銅礦;其后隨巖漿期后熱液活動在構造裂隙中形成裂隙型銅礦,從而形成裂陷構造環境下的巖漿成礦模式。
2 卷積神經網絡模型與應用步驟
2.1 基于卷積神經網絡的找礦預測模型
卷積神經網絡是一類包含卷積計算的深度前饋神經網絡[28],在計算機視覺和自然語言處理等領域受到廣泛的關注和應用。卷積神經網絡的核心就是利用局部感受野(感知域)、權值共享和匯聚層的思想來達到簡化網絡參數的目的,并且使得網絡具有一定程度的位移、尺度、非線性形變穩定性[29]。
卷積神經網絡的找礦預測模型主要由數據輸入層、卷積層、池化層、全連接層和輸出層5種網絡層構成[28]。其中:數據輸入層是將網格化的化探和航磁數據作為輸入數據寫入神經單元,卷積層與池化層分別選擇合適的激活函數完成對數據特征的提取和下采樣,全連接層則是在網絡末端實現特征的映射和分類,而輸出層可用于結果輸出或特征可視化。因此,確定合適的卷積層和全連接層結構對卷積神經網絡模型的性能至關重要。本文采用的卷積神經網絡模型由4個卷積層、4個池化層和1個全連接層組成(圖2)。

1. 第四系沖積物、坡積物、洪積物;2. 古近系白羊河組含礫砂巖、泥質粉砂巖夾砂巖及泥巖;3. 白堊系廟溝組磚紅色粉砂質泥巖與淺灰綠色粉砂質泥巖互層,局部夾淺灰褐色細砂巖和中粗粒長石石英砂巖;4. 侏羅系龍鳳山組淺灰色粗砂巖、砂礫巖和灰色細砂巖、砂質泥巖呈韻律夾薄煤層;5. 薊縣系墩子溝群二云斜長片巖、黑云斜長片麻巖夾大理巖、花崗質黑云斜長片麻巖、斜長角閃片巖、淺粒巖;6. 新太古界—古元古界龍首山巖群黑云石英片巖、大理巖、黑云角閃斜長片麻巖、二云石英片巖、黑云斜長變粒巖;7. 早二疊世花崗閃長巖;8. 早二疊世英云閃長巖;9. 早二疊世閃長巖;10. 早二疊世正長花崗巖;11.中奧陶世正長花崗巖;12. 中奧陶世英云閃長巖;13. 中奧陶世二長花崗巖;14. 斷層;15. 地質界線;16. 角度不整合界線;17. 地名;18. 銅礦及編號。Ⅱ-7-2.陸緣巖漿弧;Ⅳ-7-3.龍首山基底雜巖帶;Ⅳ-1-1.走廊弧后盆地。據文獻[25]修編。
圖1 研究區大地構造位置(a)及地質略圖(b)
Fig.1 Geotectonic location (a) and geological sketch (b) of the study area
1)卷積層(convolution):是卷積神經網絡的核心,體現了卷積神經網絡的局部連接和權值共享特性。卷積時先通過使用特定尺寸的卷積核(權值矩陣)提取整體數據的局部特征,然后通過步長平移的方式提取不同位置的數據特征。卷積核相當于卷積操作中的一個過濾器,用于提取數據特征,特征提取完后會得到一個特征圖。
卷積之后,通常會引入非線性激活函數。激活函數也被稱為非線性映射函數,激活函數對神經網絡模型學習、理解非常復雜的目標域具有重要意義[30]。本文使用的激活函數為RuLU函數,計算公式如式(1)所示:
f(x)=max (0,1)。
(1)
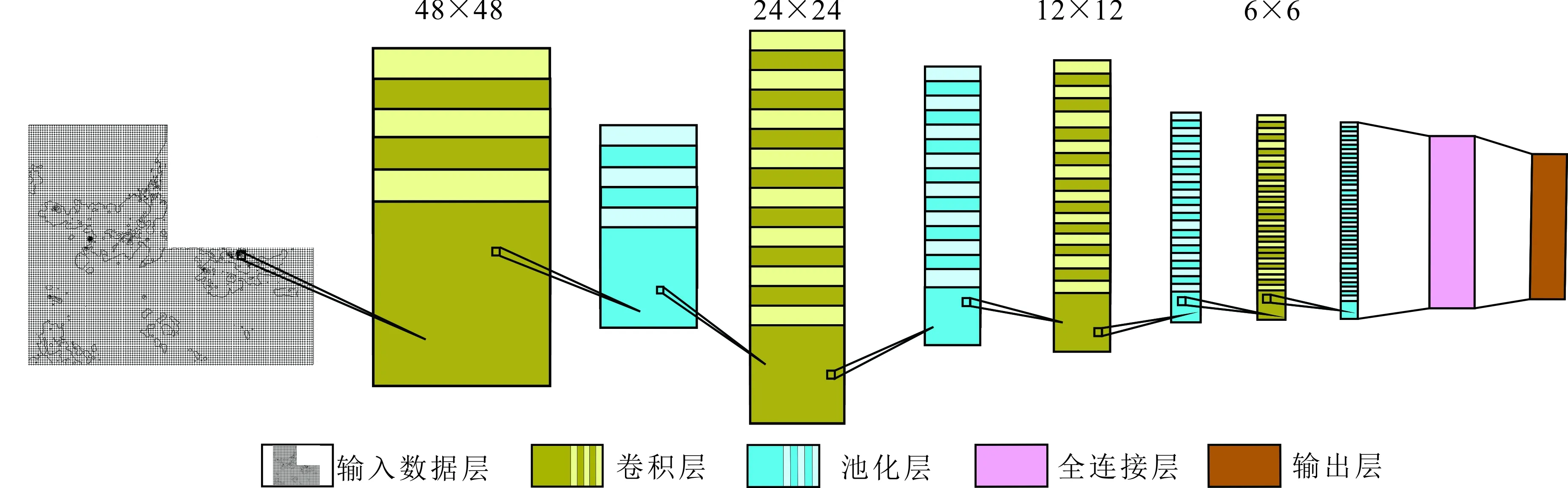
圖2 找礦預測卷積神經網絡模型架構
該公式在保證訓練效果的同時可以加快訓練速度。
2)池化層(pooling):對輸入的特征數據進行壓縮,簡化網絡計算復雜度,提取主要特征[31]。池化操作相當于降維操作,有最大池化和平均池化,本文使用的是最大池化(max pooling)。經過卷積操作后提取到的特征信息,相鄰區域會有相似特征信息,如果全部保留這些特征信息會存在信息冗余,增加計算難度。通過池化層會不斷地減小數據的空間,從而使得參數的數量和計算量會有相應的下降,這在一定程度上控制了過擬合。
3)全連接層(fully connected layers):全連接層的每一個結點都與上一層的所有結點相連,用來把之前提取到的特征綜合起來。對n-1層和n層而言,n-1層的任意一個節點,都和第n層所有節點有連接。即第n層的每個節點在進行計算的時候,激活函數的輸入是n-1層所有節點的加權。
2.2 基于卷積神經網絡的找礦預測方法與步驟
基于卷積神經網絡的找礦預測方法主要是在對元素地球化學異常數據、航磁數據進行網格化的基礎上,先采用數據增強技術獲取訓練數據和驗證數據集,再基于卷積神經網絡訓練生成模型,并應用訓練好的模型預測研究區的有利找礦部位(圖3)。
基于CNN找礦預測的具體步驟如下。

圖3 基于卷積神經網絡找礦預測流程圖
1)數據的收集與處理
收集研究區內已有的元素地球化學異常數據和航磁數據,并將研究區內已知的礦床(點)信息提取出來,為下一步的處理提供數據基礎。收集到的數據是在空間上不均勻分布的數據,需要利用插值方法將其轉化成規則網格數據。在本文中應用克里格法實現二維數據的格網化,得到25種元素地球化學異常數據和3種航磁數據,具體描述見下文。
2)訓練與驗證數據集的生成
在礦產預測研究區,通常已知礦床(點)的數量較少,難以滿足深度學習對訓練樣本量的要求,構建大容量訓練樣本是深度學習找礦預測模型建模過程的一個挑戰。本文采用步長平移數據增強方法構建訓練樣本集,從而得到泛化能力更強的網絡,使得結果更具可信度。步長平移數據增強方法是采用一定窗口大小,如48×48=2304個網格單元,通過移動窗口使礦床(點)位于1個網格單元中(圖4),提取窗口所包括的所有物探和化探網格數據,遍歷所有窗口網格單元。對于1個礦床(點)可以獲取2 304個訓練單元。如果1個研究區有n個礦床(點),則可以獲得2 304n個訓練單元。在研究區隨機選取已知礦床(點)數2倍的網格單元作為未知區,采用與生成已知礦床(點)訓練單元相同的方法獲取未知區的訓練單元。
3)卷積神經網絡模型構建
地質空間的特征是以網格單元為基本單元,每個網格單元上集合了地球化學、航磁等空間特征數據,構建找礦預測CNN模型。利用CNN模型可以提取關鍵空間特征,挖掘礦床與數據特征間的非線性關系。
4)模型的訓練與驗證
先采用準備好的訓練數據集對模型進行訓練與驗證,再采用不同參數和超參數對模型進行訓練,通過驗證數據集選取最優模型。
5)找礦預測區的確定
采用訓練好的模型,通過滑動窗口的方式對研究區進行預測,圈定有利預測區,并根據礦產地質資料,分析預測結果的可靠性,從而確定找礦預測區。
3 數據處理與預測結果
本文探討的是利用元素水系沉積物化探測量數據和航磁數據進行找礦預測區的圈定,在圈定的找礦預測區輔以地質條件分析,具體過程如下。
3.1 數據處理
1)地化數據
研究區有Ag、As、Au、B、Be、Bi、Cd、Co、Cr、Cu、Hg、La、Li、Mn、Mo、Nb、Ni、Pb、Sb、Sn、Th、Ti、U、W和Zn等25種元素水系沉積物化探測量數據,每種元素水系沉積物化探測量數據都反映了該區域不同的元素特征。CNN模型在訓練時,能夠根據已知的銅礦點確定元素所占的權重。利用Surfer軟件對25種元素進行網格化,規則網格的大小需要根據研究目的和工作比例尺來確定。對數據進行網格化,可以將空間上分散的數值轉換成規則分布的網格數值,抑制局部噪音,并按規則對空白網格賦予數值,得到統一的空間結構,對數據進行網格化能夠充分地反映客體變量的空間模式。

圖4 基于CNN的預測方法
綜合對比幾種插值方法,克里格方法不僅能夠反映距離的關系,而且能夠通過變異函數和結構分析,確定已知樣本點的空間分布及與未知樣點的空間方位關系[32]。本文利用克里格插值法,將網格單元大小設為100 m×100 m(表1),得到25種水系沉積物化探網格化數據,總網格單元數為432×316=136512個。

表1 本文地化元素數據網格化標準
選取該區域Cu、Mo、Zn和As等4種元素[33](元素地球化學質量分數單位均為10-6),采用克里格插值法對該元素按100 m×100 m網格單元大小進行網格化,4種元素1∶5萬等值線圖如圖5所示,對比圖1,發現4種元素均在大青山附近有明顯異常,該地區包含已發現的大青山銅礦區域。Cu、Mo元素地球化學異常在盤頭山和窯泉北也有反映,盤頭山異常范圍大,此異常處于海西中期花崗閃長巖中,有一定找礦潛力;窯泉北異常地處位置邊緣有英云閃長巖出露,有一定找礦潛力。Zn、As元素地球化學異常在方架山南也有異常反映,該區域異常有侵入巖體,以加里東期酸性巖為主,出露有二長花崗巖和正長花崗巖區,區域南側有英云閃長巖,出露面積較小。
2)航磁數據
研究區有3幅1∶5萬的航磁數據,利用克里格插值法對航磁數據進行網格化,網格單元大小為100 m×100 m(與表1相同)。利用Geosoft軟件對數據進行處理,得到ΔT化極航磁異常圖(圖6a),考慮到之后需要使用的航磁延拓數據,故對網格化之后的數據分別進行向上50 m(圖6b)、100 m(圖6c)和150 m(圖6d)的延拓。本文需要用到的是ΔT化極航磁異常圖、50 m向上延拓圖和100 m向上延拓圖,將這3種航磁圖提取數據并按照表1的標準進行網格化,得到3種航磁數據的網格化數據。

圖5 研究區4種元素1∶5萬地球化學元素等值線圖
由圖6a可知:研究區的磁異常條帶的延伸方向呈NW向,主要存在南北2個高磁異常帶;對比圖1可以得到,北部高磁異常帶位于該區北部大青山—天城北西西—東西向帶狀高磁異常區帶,帶內為以中酸性侵入巖為主的巨大巖漿帶,異常大多數由閃長巖體等中酸性侵入巖引起,沿北部磁異常條帶發現了銅礦床(點)。
向上延拓主要是對淺部地質體的干擾進行壓制或消除,同時能對深部有意義的地質體產生有用的磁性異常進行突出和顯示。由向上50 m延拓結果圖(圖6b)可知:該地區磁異常較為集中,主要集中在研究區中西部及西南部兩處。為了進一步消除影響,對該區域繼續進行100 m延拓(圖6c)和150 m延拓(圖6d),發現磁異常區域主要集中在中西部及西南部,在后期進行成礦有利區圈定應該盡量集中在磁異常區域。
為了展現研究區航磁異常方向性的變化特征,對研究區網格化之后的原數據在不同方向上進行求導,分別求出該研究區0°(圖6e)、45°(圖6f)、90°(圖6g)和135°(圖6h)的方向導數圖。結果表明,在求導之后,研究區航磁異常區主要呈NW向展布,也顯示出一些NE向變化特征。
3)礦點成礦地質特征
研究區已知銅礦點有4個,分別為大青山Ⅰ號銅礦、大青山Ⅱ號銅礦、大青山Ⅲ號銅礦、未定名Ⅳ號銅礦,具體位置如圖1b所示。銅礦主要發育在大青山地區,銅礦的類型主要為斑巖型銅礦和裂隙浸染型銅礦。
成礦時代主要為海西期,斑巖型銅礦的成礦母巖為石英二長斑巖,斑巖具同心狀分布的青磐巖化帶、鉀化帶、絹英巖化帶、泥化帶和孔雀石化等蝕變帶,礦化產在泥化帶中。大青山Ⅰ、Ⅱ號銅礦為典型斑巖型銅礦,處于中酸性斑巖體附近。裂隙浸染型銅礦在區內普遍分布,主要分布在花崗閃長巖和二長花崗巖大規模的青磐巖化、鉀化蝕變帶的裂隙中,主要為浸染狀的孔雀石。出露的地層為新太古界—古元古界龍首山巖群,成礦母巖為石英二長斑巖。礦體主要賦礦地質體為石英二長斑巖,該巖體侵入于海西中期花崗閃長巖中,形成于海西晚期,為區內基性—中酸性侵入巖巖漿演化晚期的產物,為鈣堿性系列,反映了過渡性構造環境。這種構造環境、巖漿巖類型與斑巖銅礦成礦環境一致。礦體的圍巖為石英二長斑巖,礦體與圍巖界線呈漸變過渡關系,圍巖蝕變以泥化為主。
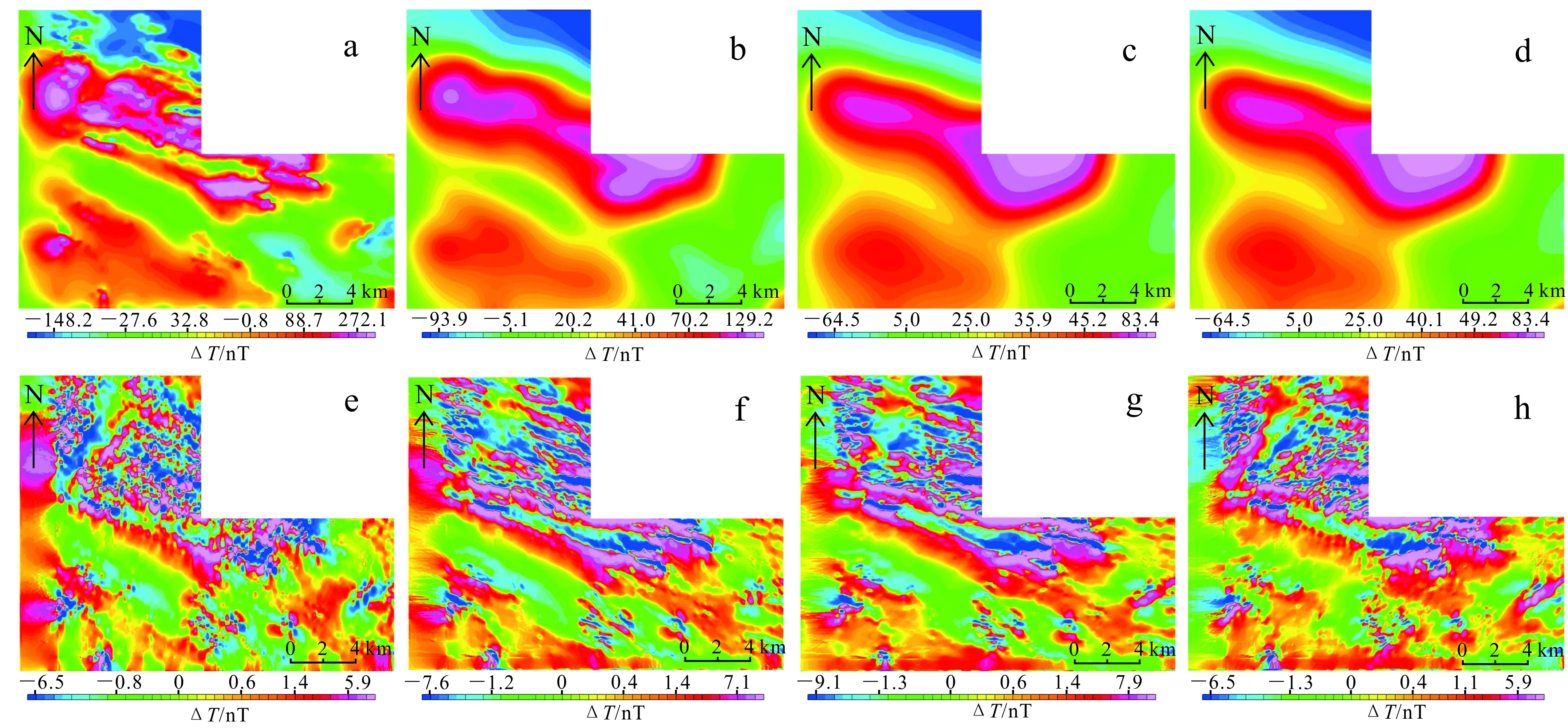
a. ΔT化極航磁異常圖;b. 向上延拓50 m結果圖;c. 向上延拓100 m結果圖;d. 向上延拓150 m結果圖;e. 方向導數為0°的結果圖;f. 方向導數為45°的結果圖;g. 方向導數為90°的結果圖;h. 方向導數為135°的結果圖。
礦區內構造主要為窯泉北逆斷層,為近EW向—NWW向,切割花崗閃長巖和石英二長斑巖(圖1),該斷層發育寬20~60 m的斷層角礫巖、碎裂巖帶并發育強烈褐鐵礦化。
3.2 銅礦預測結果
元素地球化學異常及航磁異常與已知礦床(點)具有較好的對應關系,基于化探和航磁資料,采用CNN模型(圖4)對研究區有利的銅礦找礦區進行了預測。
元素水系沉積物化探測量數據和航磁數據都已經按照圖1的地質圖范圍進行了限定,輸入的數據層為25種元素的地球化學網格化數據、ΔT化極航磁異常、向上延拓50 m、向上延拓100 m的網格化數據,共計28種數據,每種數據都通過Surfer軟件按照表1的網格轉換成了一個432×316的網格數據層。對每種類型的數據均采用離差標準化方法進行處理,采用主成分分析法(principal component analysis,PCA)把28維數據層壓縮為24維。窗口大小設定為48×48個網格單元,窗口覆蓋的實際范圍相當于4 800 m×4 800 m,每個窗口的輸入數據通道數為28,卷積核的大小為3×3,第一層卷積核數量為48,步長設置為1,模型的優化算法選用Adam算法,學習率設為0.001,衰減率設置為默認值。
訓練數據集和驗證數據集是根據已知3個銅礦點,采用數據增強方法獲取了22 934個訓練數據。其中:70%的數據用于訓練模型,包括16 054個訓練數據;30%用于模型驗證,包括6 880個訓練數據。
采用上述參數及數據集對模型進行了200輪訓練和驗證。結果顯示,當進行了50輪訓練后,模型趨于穩定,模型精度為98.1%左右(圖7)。
采用訓練好的模型對研究區的有利銅礦找礦區進行了預測。從預測結果圖(圖8)可以看出,通過建立的CNN模型得到研究區5個找礦有利區。
P-1:位于山頭窯—窯泉—大青山北一帶,預測區內包含已知的4個銅礦點,區內巖體主要為海西期閃長巖和正長花崗巖,具有多期次特征,總體走向與構造線基本一致;中部有后期沉積的侏羅系龍鳳山組淺灰色和灰白色礫巖、砂質礫巖、砂巖及泥巖;南部出露于白堊系廟溝組中,且有新太古界—古元古界龍首山巖群。該區域存在Cu元素化探異常高值。
P-2:位于窯泉北東部地區,區內出露有新太古界—古元古界龍首山巖群及白堊系廟溝組;斷裂構造發育,且具有多期次。該區域存在銅元素化探異常高值。
P-3:位于盤頭山附近,區內有海西期閃長巖、正長花崗巖侵入,具有多期次特征;巖體總體走向與構造線基本一致,南部為侏羅龍鳳山組淺灰色和灰白色礫巖、砂質礫巖、砂巖、泥巖、頁巖夾薄層煤層及煤線。該區域存在Cu元素化探異常高值。

圖7 CNN找礦預測模型訓練與預測過程

圖例同圖1。
P-4:預測區主要地層為薊縣系墩子溝群變砂巖、變粒巖,地層總體呈NW—SE向展布,侵入巖以加里東期酸性巖為主,北側為二長花崗巖和正長花崗巖區,南部為閃長巖。該區域有Cu元素化探異常高值。
P-5:位于研究區南部,區內主要為薊縣系墩子溝群變砂巖、變粒巖,中部出露有加里東期酸性侵入巖,巖性為二長花崗巖。該區域有Cu元素化探異常高值。
4 討論
4.1 超參數對預測結果的影響
4.1.1 PCA主分量數對預測結果的影響
PCA,即主成分分析方法,是一種使用最廣泛的數據降維算法。PCA的主要思想是將n維特征映射到k維上,這k維是全新的正交特征也被稱為主成分,是在原有n維特征的基礎上重新構造出來的k維特征。PCA的工作就是從原始的空間中順序地找一組相互正交的坐標軸,新坐標軸的選擇與數據本身是密切相關的[34]。
本文利用CNN對選取的28維數據進行銅礦有利區進行預測(包括25種元素地球化學數據和3種航磁異常數據),由于28維數據對計算機運算太過冗雜,故需要對數據維度進行壓縮。對數據維度進行壓縮時產生的預測結果不同,對比4種PCA主分量數對預測結果的影響如圖9所示。
實驗結果表明,維度越高,所得的預測區域越復雜,但總體有一定的相似性。4種方法中,將28維數據壓縮為24維數據所得的預測結果更符合實際地質情況。

a. 28維數據壓縮為24維數據;b. 28維數據壓縮為16維數據;c. 化探數據壓縮為14維,航磁數據壓縮為2維;d. 化探數據壓縮為6維,航磁數據壓縮為2維。
4.1.2 窗口大小
窗口大小對訓練數據集、預測結果均有一定影響,并對模型精度產生影響。根據訓練數據的提取方法可知,窗口越大,能夠提取的訓練數據集也越大,當窗口大小分別為12×12、24×24、48×48時,可提取訓練樣本數分別為3 056、8 048、22 934。3種預測結果圖如圖10所示。
實驗結果表明,窗口大小不同會產生不同的預測結果(圖10)。采用較大的窗口,獲得的訓練樣本數據較多,則獲得的預測范圍相對較小,但綜合3種窗口大小來看,預測區的總體位置相似。比較3種不同窗口大小,可以看出當窗口大小為48×48時,預測區的范圍相對較小,此時產生的訓練樣本數較多,模型所得的預測區精度較高。
4.1.3 卷積核數量
卷積層中的卷積核數量直接影響了輸入的局部特征,不同的卷積核導致的結果也有著一定的差異性。本文試驗了第一層卷積核數量(24、48、64)對預測范圍的影響,具體預測結果如圖11所示。
實驗結果表明,卷積核數量不同會產生不同的預測結果(圖11)。卷積核數量越多,提取到的局部特征就越多,3種不同數量的卷積核對應著不同的實驗結果,但綜合3種數量來看,預測區的總體位置相似。比較3種不同卷積核的數量,可以看出當初始的卷積核數量為48時,預測區的范圍相對較小,且更符合地質情況。
4.1.4 步長
卷積層中的步長表示卷積核一次移動多少個格子。不同的步長會導致不同的預測結果,本文對比了3種不同的步長結果,具體如圖12所示。
對比3種步長所得的預測結果,可以發現,隨著步長的增大,所得的預測結果精細程度愈加降低。對比地質圖、地球化學元素異常圖和航磁異常圖可知,當步長為1時更具有可信度。

a. 窗口大小為12×12;b. 窗口大小為24×24;c. 窗口大小為48×48。

a. 卷積核數量為24×24;b. 卷積核數量為48×48;c. 卷積核數量為64×64。
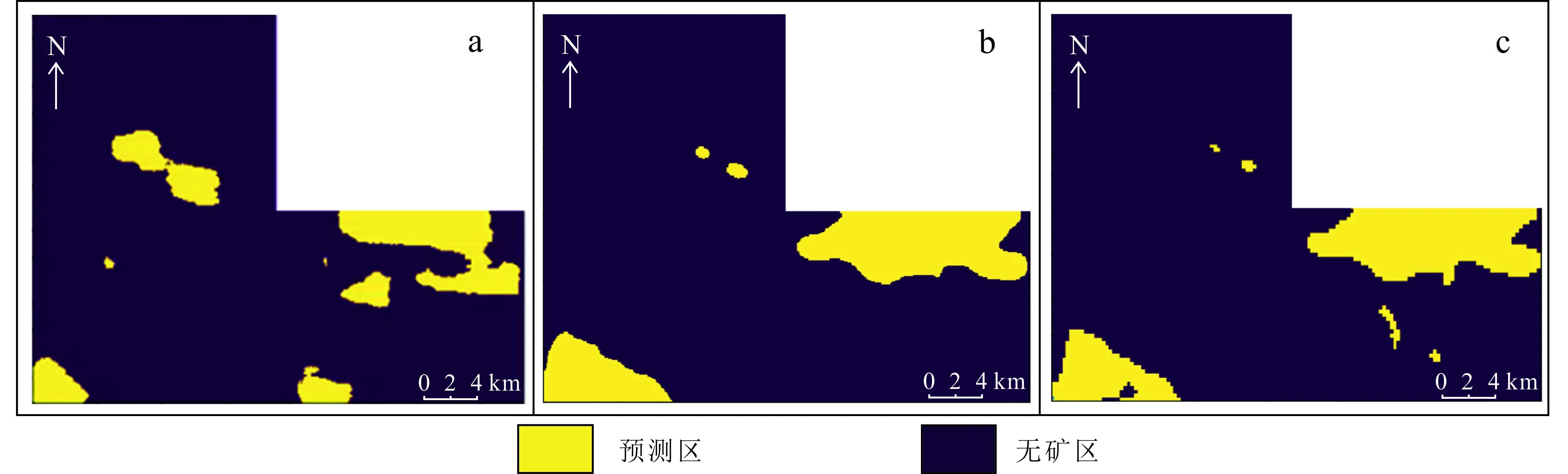
a. 步長為1;b. 步長為2;c. 步長為3。
4.1.5 抓取的樣本數量
Batch_size即一次訓練所抓取的數據樣本數量。適當的Batch_size可以使得梯度方差減小,直接使梯度更加準確,從而使得預測結果更加準確。本文對比3種不同的Batch_size,所得的預測結果如圖13所示。

a. Batch_size為32;b. Batch_size為64;c. Batch_size為128。
對比3種不同Batch_size所得的預測結果發現,每一次訓練所抓取的數據樣本量不同的話,所得的預測結果雖然大體位置相同,但預測面積變化較大。對比元素地球化學異常圖、航磁異常圖和地質圖,發現當Batch_size為64時,所得的預測結果比較可靠。
4.2 不同數據集對預測結果的影響
為了比較不同數據集對預測結果的影響,選取25種化探元素數據、3種航磁數據(化極磁異常,上延50 m和100 m磁異常)、綜合25種化探元素數據與3種航磁數據作為輸入數據進行了實驗(圖14)。
實驗結果表明,基于化探元素數據的預測結果(圖14a)和基于航磁數據所得的預測結果(圖14b)有一定的差距,二者所得的預測結果大體位置相同;但綜合化探元素數據與航磁數據的預測結果范圍相較前兩者包含的信息更多,預測范圍更加可靠。
4.3 不同網格單元大小對預測結果的影響
為了比較不同網格單元大小對預測結果的影響,設定窗口大小為48×48,卷積核的大小為3×3,第一層卷積核數量為48,步長設置為1,Batch_size為64,輸入的數據為壓縮24維的化探元素數據和航磁數據,對比50 m網格的輸入數據和100 m網格的輸入數據,預測結果如圖15所示。
實驗結果表明,50 m網格和100 m網格得到的預測區域相比,預測區位置大體相同,主要是預測范圍有差距,50 m網格得到的預測范圍較大。綜合該區域地質情況來看,100 m網格預測結果更加可靠。
4.4 預測結果的可靠性與精度
本文采用的是利用PCA壓縮得到的24維化探元素數據和航磁數據作為輸入數據集,將窗口大小設定為48×48,卷積核的大小為3×3,第一層卷積核數量為48,步長設置為1,采用100 m網格大小得到研究區的預測結果圖。前人[25]通過大量野外地質調查、物探和化探分析以及綜合研究圈定了研究區銅礦找礦預測區,預測區主要位于山頭窯—窯泉、大青山2個地區。本文得到的預測結果圖與前人預測結果相比較,所提出的方法(比較)具有較小的預測范圍和較高的可靠性。

a. 基于化探元素數據;b. 基于航磁數據;c. 綜合化探元素數據與航磁數據。
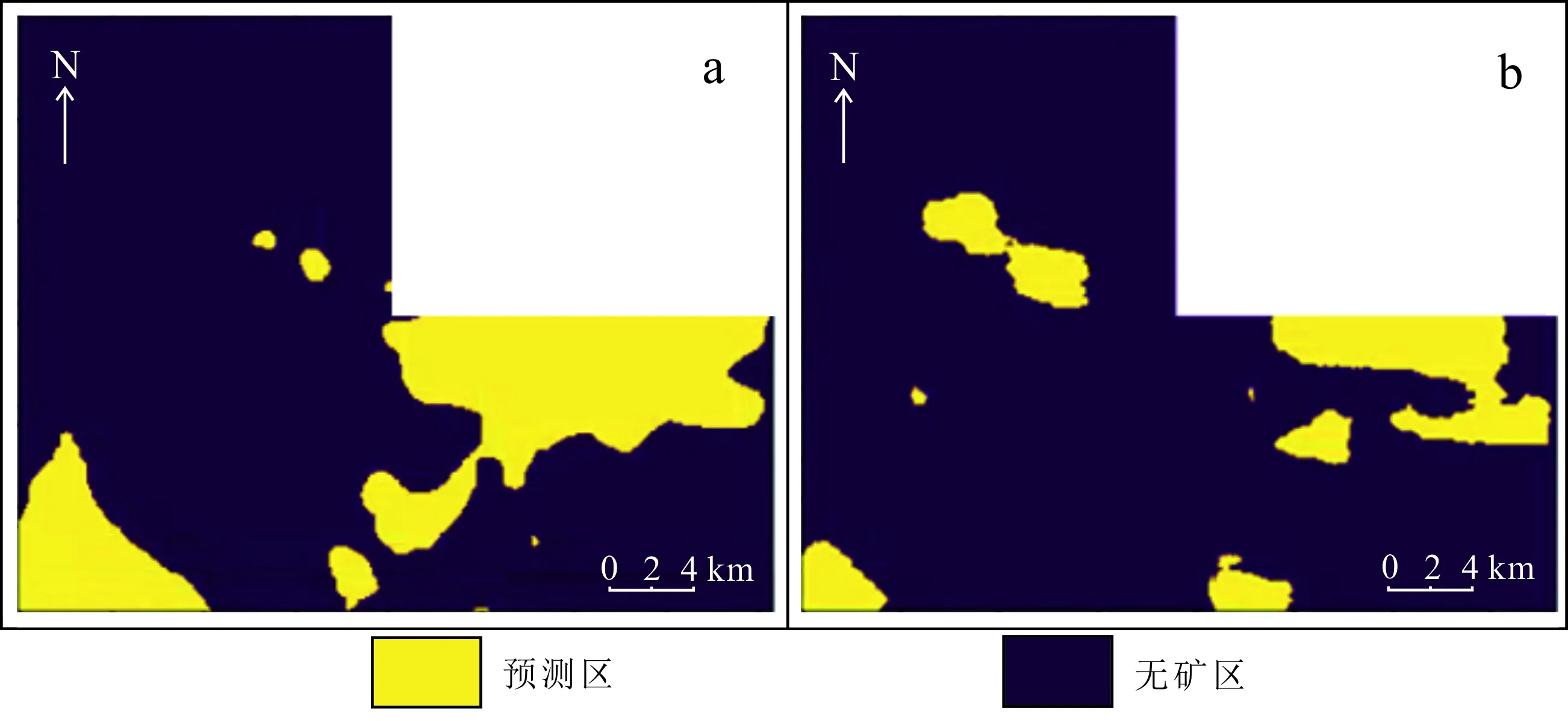
a. 50 m網格大小;b. 100 m網格大小。
5 結論
1)在融合化探元素和航磁數據基礎上,基于深度學習的找礦預測方法可以提高找礦預測的效率和效果。采用本文所提出的方法,可以得到較小的礦產預測范圍和較高的預測可靠性。
2)結合前人研究成果和野外檢查,基于卷積神經網絡在甘肅省龍首山西段高臺縣臭泥墩—西小口子地區圈定5處找礦預測區,具有良好的銅礦找礦遠景,是下一步找礦預測的重點地區。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
