近似馬爾科夫毯混合式特征選擇
2022-06-25 01:59:42殷柯欣謝愛鋒翟峻仁
長春工業大學學報 2022年1期
殷柯欣, 謝愛鋒, 翟峻仁
(長春工業大學 計算機科學與工程學院,吉林 長春 130012)
0 引 言
特征選擇[1-2]作為一種數據預處理技術被廣泛應用于機器學習、模式識別和數據挖掘等領域。特征選擇過程可以分為子集生成、子集評估、停止準則和驗證四部分。子集生成是一個搜索過程,根據搜索策略生成特征子集,然后利用評價準則對特征子集進行評估。當特征子集的條件滿足停止準則時,輸出當前的特征子集,并對其進行驗證。
在生成特征子集的過程中,根據特征子集的搜索方式可將搜索策略[3-4]分為全局搜索、序列搜索和隨機搜索。全局搜索,又名指數搜索,需要評估的特征子集數量隨著特征個數呈指數增加。這種方法雖然能夠獲得全局最優解,但由于計算量大、花費時間長,在高維數據集中是不適用的。全局搜索算法有窮舉搜索法、分支定界法。隨機搜索策略隨機地選取特征,避免了算法陷入局部最優,能夠獲得近似最優解。常見的隨機搜索算法有遺傳算法(GA)、模擬退火算法(SA)等。與全局搜索和隨機搜索相比,序列搜索的時間復雜度最低。序列選擇策略從空集(全集)開始,然后添加特征(移除特征),直到獲得使準則函數最大化的特征子集。依據序列搜索策略已經開發了多個高性能的搜索算法。首先是序列前向選擇算法(Sequential Forward Selection,SFS)和序列后向選擇算法(Sequential Backward Selection,SBS)[5]。
SFS算法從空集開始,每次選擇一個使準則函數最大的特征加入到已選特征子集中。而SBS算法與之相反,它從全集開始,每次刪除一個對準則函數貢獻最小的特征。SFS算法計算量小,但沒有充分考慮到特征之間的聯系[6],即最優的單個特征組成的集合不一定是最優的特征子集。相對而言,SBS算法雖然計算量大,但其充分考慮了特征之間的聯系,算法性能優于SFS算法。但是,SBS算法和SFS算法本身都存在“嵌套效應(nesting effect)[7]”。“嵌套效應”意味著SFS算法選中的特征以后不能丟棄,SBS算法丟棄的特征以后不能再選擇。這導致SFS和SBS只能獲得局部最優解。
廣義序列前向選擇算法(Generalized Sequential Forward Selection,GSFS)和廣義序列后向選擇算法(Generalized Sequential Backward Selection,GSBS)分別是SFS和SBS的加速算法。GSFS算法從空集開始,根據準則函數每次向已選特征集合中加入一定數量的特征。GSFS算法改進了SFS在特征關系上的不足,但增大了計算開銷。與GSFS算法類似,GSBS算法根據準則函數,每一次刪除一定個數的特征。GSBS算法速度相對較快,但是過快地進行特征刪除,會導致重要特征的丟失,以至于無法找到最佳特征子集。無論是GSFS還是GSBS依舊存在“嵌套效應”。為了解決上述算法中存在的“嵌套效應”,提出了Plus-L-Minus-r(l-r)[8]的方法,即在每次循環中添加L個特征,刪除r個特征,直到獲得期望的特征子集。這種方法的主要缺點是沒有理論上的方法來預測L和r的值,以獲得最佳的特征集。與上述改進相比,最值得一提的改進算法就是序列浮動搜索[9]:序列前向浮動搜索算法(Sequential Forward Floating Selection,SFFS)和序列后向浮動搜索算法(Sequential Backward Floating Selection,SBFS)。
SFFS(SBFS)算法靈活地改進了Plus-L-Minus-r方法,使L和r的大小動態化不是固定值。在SFFS(SBFS)算法的每一輪循環中刪除(添加)的特征個數是不同的,這是一種非常適用的改良。由于SFFS(SBFS)算法在一輪循環中只添加(刪除)一個特征,這意味著SFFS(SBFS)算法所選取的特征子集中可能會包含兩個高度相關的特征。并且在搜索過程中,SBFS算法和SFFS算法偶爾會偏好較差的特征子集,特別是SFFS算法。為了解決序列浮動搜索存在的問題,一種自適應的浮動搜索算法[10]被提出:自適應序列前向浮動選擇(Adaptive Sequential Forward Floating Search,ASFFS)和自適應序列后向浮動選擇(Adaptive Sequential Backward Floating Search,ASBFS)。由于這兩種新的自適應浮動搜索方法比經典的浮動搜索更徹底地搜索,它們有可能找到更接近最優解的解,當然是以更長的計算時間為代價。
改進的正向浮動選擇(Improved Forward Floating Selection,IFFS)[11]是對SFFS算法精度的一種改進,它在SFFS算法的回溯步驟之后增加額外的步驟,用新的更好的特征代替弱特征來形成當前子集。與SFFS相比,IFFS算法依舊增加了計算時間。
綜上,上述所有SBS、SFS的改進算法在尋求算法最優解時,增加了時間耗費,以時間為代價換取高性能的特征子集。并且上述算法采用不同的特征選擇方式(包裝式或過濾式),其時間復雜度、特征子集的性能是不同的。過濾式(filter)選擇算法效率高、普適性強,但特征子集性能相對較差,因為特征子集之間存在冗余且所選特征子集不一定是最優特征子集。與過濾式選擇算法相比,包裝式(wrapper)特征選擇算法選擇出的特征子集性能較好,但時間復雜度高,不適合高維數據集。
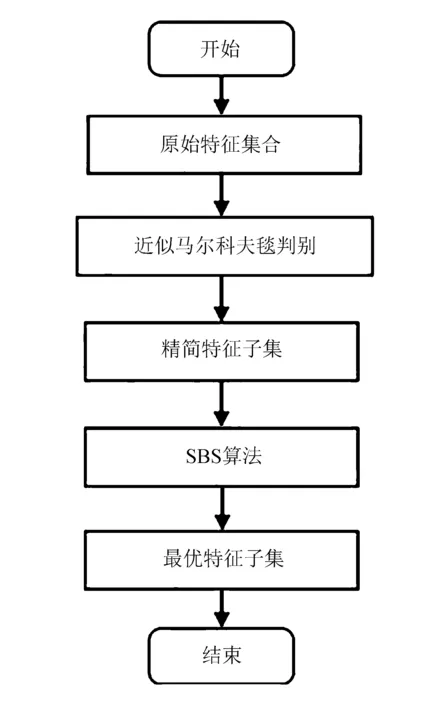
針對以上存在的問題,文中提出基于近似馬爾科夫毯[12-13]混合式[14]特征選擇算法Hybrid Sequential Backward Selection Algorithm(HSBS算法)。該算法將包裝式和過濾式有機結合,在保證時效的前提下,提高了特征子集的性能。所提算法HSBS框架如圖1所示。

圖1 混合式特征選擇框架
其中,HSBS包括兩個階段:
1)利用近似馬爾科夫毯算法對原始特征集合進行去冗余,輸出精簡特征子集;
2)使用SBS算法對精簡特征子集進行選擇,選出最佳特征子集。
實驗結果表明,與SBS算法相比,HSBS算法所選的特征子集數平均減少9.0個,平均時間耗費降低約70%,成功克服了SBS算法在高維數據集上耗費時間大的問題。同時,混合式選擇適用于高維數據集,克服了包裝式方法在高維數據集不適用的缺陷。
1 背景知識
1.1 SBS算法
SBS算法是一種自上而下的搜索方法,從原始特征集開始搜索,每次從特征子集中刪掉一個使評價函數達到最優的特征。SBS算法可以描述為:設原始特征集合為S,假設有一個含有n個特征的特征子集Xn,Xn是S的子集,對于Xn的每一個特征fi,計算其準則函數
Fi=J(Xn-fi),
選擇使Fi最大的那個特征,并把它從Xn中刪除。SBS算法將分類正確率作為評價準則。
1.2 互信息
互信息(Mutual Information)[15]是信息論里一種很實用的信息度量,是一個隨機變量中包含的關于另一個隨機變量的信息量。兩個隨機變量X和Y的互信息可以定義為
(1)
式中:p(x),p(y)——分別為隨機變量X和Y的邊緣概率密度;
p(x,y)——聯合概率密度。
1.3 相關性、冗余性與近似馬爾科夫毯
1.3.1 相關性
特征的相關性[16-18]指的是特征與類標簽之間的關系,特征與類標簽的關系越緊密,特征的相關性越大。根據特征與類標簽的相關度,特征被分為無關特征、弱相關特征和強相關特征。假設有一個特征集合S,Xi是S中的一個特征,
Si=S-{Xi},
式中:C——類標簽;
I(·)——互信息。
如果特征Xi是強相關特征,需要滿足
I(C|Xi,Si)≠I(C|Si),
表明特征Xi的重要性,特征Xi有無直接影響類標簽C發生的概率。
如果特征Xi是弱相關特征,需要滿足
I(C|Xi,Si)=I(C|Si),
?Sj?Si,
I(C|Xi,Sj)≠I(C|Sj),
表示特征Xi可以被其他特征所取代,取代后就變成無關特征。
如果特征Xi是無關特征,需要滿足
?Sj?Si,
I(C|Xi,Sj)=I(C|Sj),
表示特征Xi對于類標簽C毫無貢獻。
1.3.2 冗余性與馬爾科夫毯
馬爾科夫毯[19]定義:特征Xj屬于特征集合S,S0是S的一個子集,Xj不屬于S0。如果S0滿足
P(S-S0-Xj,C|Xj,S0)=
P(S-S0-Xj,C|S0),
則稱S0是Xj的馬爾科夫毯。
冗余性[20]是指一個特征與其他一個或多個特征對分類任務起到相似的作用。如果特征Xj為弱相關特征且在特征集合S中存在一個馬爾科夫毯S0,表明特征Xj是冗余特征。
1.3.3 近似馬爾科夫毯
馬爾科夫毯方法可以直接刪除無關特征和冗余特征,由于馬爾科夫毯方法是對所有的特征子集進行遍歷搜索,導致馬爾科夫毯在高維數據集上的時間復雜度為O(2n),計算復雜度偏高。為了降低計算復雜度且保留馬爾科夫毯的優點,文中引入馬爾科夫毯的簡化版,近似馬爾科夫毯。
近似馬爾科夫毯算法同樣可以刪除特征集合中冗余與不相關的特征,并且時間復雜度為O(n2),計算復雜度較低[12]。
近似馬爾科夫毯定義:對于來自于同一個特征集合的特征Xi和Xj(i≠j),如果滿足
I(Xi;C)>I(Xj;C),
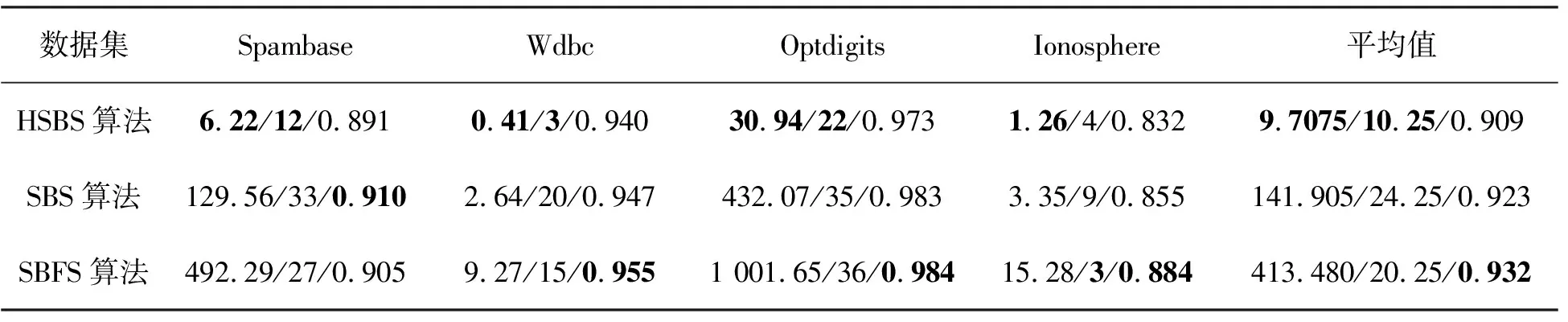
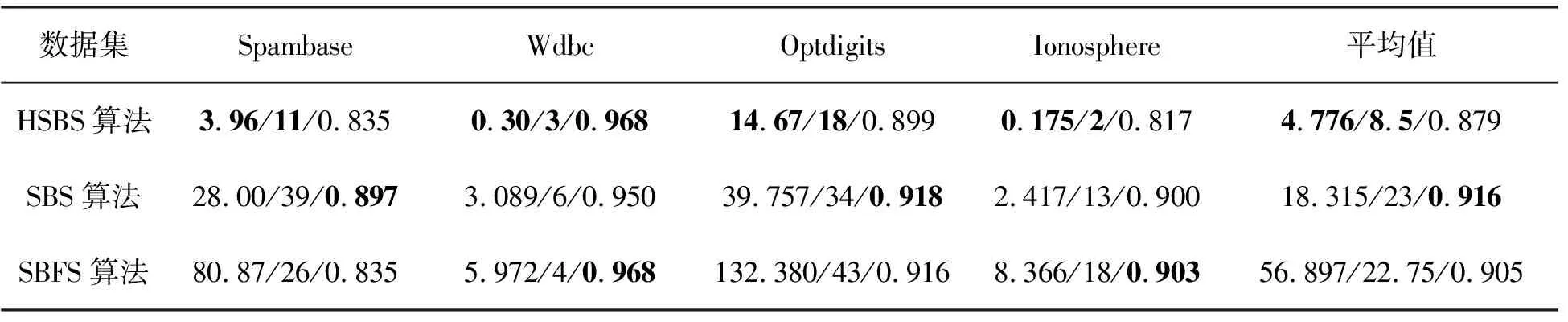
I(Xj;C) 則說明特征Xi是特征Xj的馬爾科夫毯,Xj為冗余特征,直接刪除。 HSBS算法采用混合式特征選擇模型,算法流程如圖2所示。 圖 2 HSBS算法流程 第一層采用filter選擇方法,使用基于互信息的近似馬爾科夫毯對特征集合進行精簡。首先遍歷特征集合S中的每一個特征fi,并計算特征fi與類標簽C的互信息值I(fi;C)。按照互信息值I(fi;C)的大小對特征集合S進行排序,生成新的特征集合S′。根據近似馬爾科夫毯的判斷條件,即 I(Xi;C)>I(Xj;C), I(Xj;C) 刪除特征集合S′中冗余和不相關的特征,輸出精簡特征子集。 第二層wrapper選擇方法采用SBS算法,從精簡子集中選擇出最優特征子集。輸入精簡特征子集X,利用SBS算法的準則函數逐個將分類效果差的特征從精簡子集X中剔除,從而獲得最佳特征子集S0。這一層在保證分類精度的同時進一步降低了特征個數。 文中提出的HSBS算法具體步驟如下: 輸入:原始特征集合S={f1,f2,…,fn},C為目標類,n為特征個數,d為選定的特征個數; 輸出:最優特征子集S0 步驟: 1)X=?,F=?,S={f1,f2,…,fn} 2)計算S中每一個特征fi的I(fi;C),并根據I(fi;C)值,從大到小對S進行排序,得到S′ 3)for fiin S′ 4)for fjin {S′-fi} 5)if I(fi;C)>I(fj;C)and I(fj;C) 6)S′=S′-{fj} 7)end if 8)end for 9)end for 10)X=S′ 11)while len(X)!=d # len(X)表示X的長度 12)for in len(X) 13)x=arg maxJ(X-xi),xi∈X 14)end for 15)X=X-{x} 16)end while 17)S0=X 18)return S0 文中實驗環境為Inter(R)-Core(TM)i7-1050H,8 G內存,Window10-64 bit操作系統,仿真軟件是python3.7 和Jupyter Notebook。 實驗選擇了UCI通用數據集,涉及醫學、工程科學等領域,4個數據集包含不同的樣本數、特征數和類別數。 數據集的具體參數描述見表1。 表1 數據集的描述 實驗采用KNN分類器和Native Bayes分類器[21]來構造預測模型。 在實驗過程中,采用10折交叉驗證方法,10折交叉驗證就是每一次將數據集均分成10份,其中9份作為訓練集,1份作為測試集。然后對數據集進行10次實驗,用10次測試結果的平均值作為最終的準確率。與SBS算法和SBFS算法進行對比,驗證文中算法在保證高分類準確率的前提下,是否降低了計算時間和減少了特征子集中特征的個數。 通過兩種分類器分別在4個數據集上的實驗數據來比較不同算法的優劣。 經過近似馬爾科夫毯去冗余后的精簡子集特征個數見表2。 表2 原始數據集與精簡子集特征個數比較 由表2可以看出,經過近似馬爾科夫毯去冗余后,所選特征子集的個數明顯減少。 3種算法在KNN、Native Bayes兩種分類器中時間花費、最佳特征子集個數和分類準確率分別見表3和表4。 表3 3種算法在KNN分類器上的時間花費(s)/特征選擇數/分類準確率的比較 表4 3種算法在Native Bayes分類器上的時間花費(s)/特征選擇數/分類準確率的比較 由表3可以看出,HSBS算法在相同數據集上所花費的時間均小于SBS算法。與 SBS 算法相比,HSBS算法平均時間花費降低約93%;HSBS算法所選出的平均特征子集數比SBS算法少 14個;HSBS算法在4個數據集上的分類準確率均略低于SBS算法,并且HSBS算法的平均分類準確率能達到90%。 由表4可以看出,在4個實驗數據集中,HSBS算法花費的時間均低于SBS算法。同時,與SBS算法相比,HSBS算法的平均時間花費降低約77%;在4個數據集上,HSBS算法所選特征數均低于SBS算法,HSBS算法的平均特征子集數比SBS算法少14.5個;在Wdbc數據集中,HSBS算法的分類準確率略高于SBS算法,但在其他3個數據集上,HSBS算法分類準確率均低于SBS算法。雖然HSBS算法的平均分類準確率只有87.9%,但與最高的平均分類準確率相比,僅差3.7%。 從表 3可以看出,與SBFS算法相比,HSBS算法的平均時間花費降低約97.6%,平均特征子集數減少了10個,平均分類準確率降低了2.3%。 從表 4可以看出,與SBFS算法相比,HSBS算法的平均時間花費降低了91.6%,平均特征子集數減少14.25個,平均分類準確率降低了2.6%。 綜合表3和表4實驗數據分析發現,HSBS算法的平均時間花費僅占SBS算法的10.1%,時間花費降低約90%。與SBFS算法相比,HSBS算法效果更加明顯,其時間花費降低約96.9%。HSBS算法的平均特征子集數也遠小于SBS算法和SBFS算法。同時,HSBS算法也存在不足之處,它的分類準確率低于SBS算法和SBFS算法,但相差不大。因此,HSBS算法在降低時間花費、減少特征子集個數的同時,亦能保證較高的分類準確率,HSBS算法在高維數據集具有實用性。 提出一種基于近似馬爾科夫毯的混合式特征選擇算法——HSBS算法。該算法首先利用近似馬爾科夫毯刪除數據集中冗余和不相關的特征,生成精簡特征子集;然后,利用SBS算法對過濾后的精簡特征集進行選擇,篩選出最佳特征子集。HSBS算法的優勢在于,將數據集中冗余和不相關的特征刪除后,降低了數據集的特征個數,提高了剩余特征的質量。 HSBS算法在KNN、Native Bayes分類器上均取得了優良的效果,其降低時間花費的優良表現在KNN分類器上尤為突出,同時還表現出較高的分類效果。 因此,HSBS算法在保證較高分類準確率的情況下,能夠降低時間花費、減少最優特征子集的個數,它在高維數據集的分類任務中有較強的實用性。2 HSBS算法描述
2.1 HSBS特征選擇方法
2.2 HSBS算法偽代碼
3 實驗結果與分析
3.1 HSBS算法實驗
3.2 實驗結果分析

4 結 語
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56大眾健康(2021年6期)2021-06-08 19:30:06世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28當代陜西(2019年10期)2019-06-03 10:12:04中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06初中生世界·七年級(2017年9期)2017-10-13 22:27:46數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
