一種基于改進AOD-Net 的航拍圖像去霧算法
2022-07-03 02:11:34李永福崔恒奇張開碧
自動化學報 2022年6期
關鍵詞:模型
李永福 崔恒奇 朱 浩 張開碧
隨著無人機航拍技術的日益成熟,無人機航拍技術逐漸被頻繁地應用于復雜環(huán)境地圖測繪[1],輔助駕駛[2]以及道路監(jiān)控[3]等領域.然而,由于航拍無人機與拍攝對象的距離通常較遠,因此航拍圖像更容易受霧霾環(huán)境的影響.在霧霾環(huán)境中,地面拍攝的普通圖像中近景受到霧霾的影響較小,而航拍圖像整體都會包含濃度較高的霧霾,這極大地影響了航拍圖像的成像質量.此外,航拍圖像的比例尺較大,這要求航拍圖像具有極高的成像質量從而保證拍攝對象清晰可見,而霧霾環(huán)境中采集的航拍圖像的信息量會嚴重下降,其實用價值也會大打折扣.因此,為了降低霧霾環(huán)境對航拍圖像的影響,需要對無人機采集的有霧航拍圖像進行去霧處理,同時需要增強去霧圖的視覺效果,強化圖像中的特征信息以便于后續(xù)高級計算機視覺系統(tǒng)進行二次處理.
圖像去霧算法可以分為基于傳統(tǒng)數(shù)字圖像處理與物理模型結合的方法[4-8]和基于深度學習設計的去霧網絡模型的方法[9-16].基于傳統(tǒng)數(shù)字圖像處理與物理模型結合的方法一般以大氣散射物理模型[17]為基礎,在此基礎上針對大氣光值與透射矩陣設計求解算法以期獲取準確的數(shù)值.其中具有代表性的算法有如下三種:He 等[6]提出了基于暗通道先驗(Dark channel prior,DCP)的去霧方法,該方法通過尋找圖像中的暗通道圖像來求解透射矩陣,再結合估計的大氣光值來消除圖像中的霧氣.Berman等[7]利用了一種邊界約束和正則化(Boundary constraint and contextual regularization,BCCR)的方式來配合大氣散射模型對圖像進行去霧.Zhu 的團隊[8]利用顏色衰減先驗假設(Color attenuation prior,CAP)來獲取透射圖,再結合大氣散射模型進行圖像去霧.
隨著深度學習在圖像領域的發(fā)展,許多學者嘗試通過設計合適的去霧神經網絡來進行圖像去霧.基于深度學習設計的圖像去霧模型能夠被進一步細分為基于大氣散射模型的間接參數(shù)求解型網絡模型和直接圖像生成型網絡模型[9-10].其中,基于大氣散射模型的間接參數(shù)求解型網絡模型一般是通過對大氣光值或者傳輸矩陣進行網絡設計,通過構建高效的特征提取網絡結構來準確獲取二者的數(shù)值,然后進而通過大氣散射物理模型生成無霧圖像.其中近年來具有代表性的算法有:Cai 等[11]提出了一種可以端到端進行訓練的卷積神經網絡模型DehazeNet,該網絡可以學習有霧圖像于介質傳輸圖之間的映射關系,但是僅僅四層的單尺度直線型卷積網絡的特征提取能力非常有限,很容易造成傳輸圖的估計出現(xiàn)錯誤.Ren 等[12]提出了一種多尺度卷積神經網絡(Multi-Scale Convolutional Neural Network,MSCNN)用于去霧,該網絡使用精細介質傳輸網絡對粗糙介質傳輸網絡進行傳輸特征的細化,有效提升了去霧圖的細節(jié)特征,然而龐大的網絡結構使得該網絡并不能短時高效地去霧,需要依賴強大的圖形化硬件設備.Li 等[13]提出了AOD-Net去霧算法,該方法簡化了去霧模型,通過對大氣散射模型進行變形使大氣光值以及大氣透射率合并為一個參數(shù)變量,并設計了一種簡單高效的特征融合型卷積神經網絡來有效獲取該變量的值.但是該算法處理真實霧圖的時候非常容易使圖像的色調丟失并且損失較多色值.而直接圖像生成型去霧網絡模型與間接參數(shù)求解型網絡模型不同,該網絡能夠直接學習到有霧圖像與清晰圖像之間的映射關系,將這種關系以權重文件的形式保存起來,每張圖像在經過加載了該權重文件的神經網絡后能夠直接生成清晰圖像,無需依賴大氣散射模型.例如,Ren 等[14]設計了一種門控融合網絡(Gated fusion network,GFN),該網絡通過融合白平衡派生圖、對比度增強派生圖以及伽馬增強派生圖直接端到端生成無霧圖像.Chen 等[15]設計了一種門控聚合網絡(Gated context aggregation network,GCANet),該網絡通過編碼-解碼的網絡結構學習到原圖和有霧圖之間的殘差,通過將霧氣的特征殘差附加在霧圖上即可獲得去霧圖像,恢復的圖像會出現(xiàn)區(qū)域色調失衡以及圖像飽和度過低的現(xiàn)象.Qin 等[16]設計了一種端到端的特征融合注意網絡(Feature fusion attention network,FFANet)來獲取霧氣的殘差特征,去霧后的圖像通常會出現(xiàn)顏色失真和對比度下降的問題.雖然端到端圖像生成型網絡可以不依賴大氣散射模型,但是對霧氣分布不均勻的圖像進行去霧時非常容易出現(xiàn)去霧不徹底的問題,并且容易出現(xiàn)大量的噪點.
由于AOD-Net 的網絡結構非常輕巧,算法耗時極短,因此該算法非常適用于無人機航拍圖像實時去霧.本文重點針對AOD-Net 去霧圖的細節(jié)信息丟失嚴重,去霧圖的對比度過強以及去霧圖噪音過多的問題,提出一種基于AOD-Net 的多尺度航拍圖像去霧算法.本文的主要創(chuàng)新點如下:
1) 本文在AOD-Net 的基礎上學習FPC-Net對網絡層的優(yōu)化方式[18]對AOD-Net 的網絡層進行了改良,并將改良的AOD-Net 嵌入到多尺度結構中.改良后的網絡結構能夠有效提升神經網絡對圖像細節(jié)部分的處理能力,并且能有效削減遠景部分的霧氣.
2) 與以往一些文獻中僅僅關注圖像重構的像素差異而設計的損失函數(shù)不同[11-13],本文設計的損失函數(shù)在訓練網絡時不僅監(jiān)視了生成圖與標準清晰圖之間的結構差異,還關注了生成圖的視覺主觀感受以及圖像的平滑度.
3) 與以往研究中采用唯一損失函數(shù)訓練模型的方式不同[9-16],本文訓練所提網絡模型時采用了分段訓練的方法,這種通過優(yōu)化訓練方式來提升網絡的去霧性能的方式能夠有效保留網絡的模型復雜度,并且能夠極大程度地保證算法的實時性.
1 AOD-Net 去霧算法
AOD-Net 算法是基于簡化的大氣散射模型設計的去霧算法.該算法將大氣散射模型中的大氣光值和透射矩陣合并為了一個過渡矩陣,然后利用多尺度特征融合網絡來獲取過渡矩陣中的數(shù)值,最后利用簡化的大氣散射模型來獲得無霧圖像.AODNet 算法主要包含以下5 個步驟:
步驟 1.大氣散射模型的簡化.清晰圖與對應的有霧圖像的函數(shù)關系可以表示為:
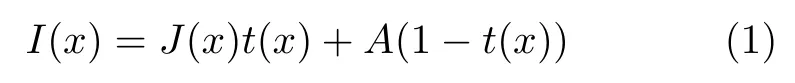
其中t(x) 表示傳輸圖,A表示大氣光值,若要恢復出清晰圖像則必須準確估計二者的值,而在AODNet 中,將式(1)中的兩個未知量通過數(shù)學公式變換合并為了一個未知量K,K的求解公式如式(2)所示,簡化的大氣散射模型如式(3)所示.

步驟 2.多尺度特征融合網絡提取霧氣特征.AOD-Net 采用了一種多尺度特征融合的方式來增強網絡的特征提取能力,該網絡的結構如圖1 所示.其中第2 個特征層合并了第1 層的特征圖,第3 個特征層融合了第2 層的特征圖,第四層特征層合并了前3 層的特征圖,最后一層輸出過渡圖像K的數(shù)值矩陣.該網絡結構較為簡單,無復雜的支路,這保證了AOD-Net 算法的實時性.

圖1 AOD-Net 的網絡結構Fig.1 The network architecture of AOD-Net
步驟 3.霧氣數(shù)據(jù)集的生成.AOD-Net 通過設置不同的大氣光值和散射系數(shù)將NYU2[19]的室內清晰圖像數(shù)據(jù)集擴充為包含了多種霧氣濃度的合成霧數(shù)據(jù)集.
步驟 4.設計用于訓練網絡的損失函數(shù).AOD-Net選擇的是最簡單也是最直接的均方誤差損失函數(shù)[20],該損失函數(shù)可用式(4)表示.
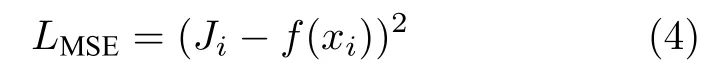
式(4)中的xi表示了輸入網絡的有霧圖像,Ji表示了合成霧圖對應的清晰無霧圖像,f(xi) 表示AOD-Net 生成的去霧圖像.
步驟 5.經過訓練后的AOD-Net 可獲取對應的權重文件,加載權重文件并用AOD-Net 讀取有霧圖像即可直接獲取去霧圖像.
2 改進的多尺度AOD-Net
AOD-Net 去霧算法雖然擁有非常優(yōu)秀的去霧效率,但是該算法去霧后的圖像非常容易出現(xiàn)去霧不徹底、對比度過強、邊緣細節(jié)模糊以及色調偏暗的問題.因此,本文對AOD-Net 算法進行了改進.首先,針對步驟2,本文根據(jù)FPC-Net 中對網絡層的優(yōu)化方式改良了AOD-Net 的多尺度特征融合網絡,FPC-Net 中采用了全逐點卷積與不同大小池化層結合的方式替換了大尺度卷積層,從而有效提升網絡的特征表達能力[21].然后,本文構建了多尺度網絡結構,提升網絡對圖像細節(jié)霧氣的處理能力.隨后,用包含了圖像重構損失函數(shù)、SSIM 損失函數(shù)和TV 損失函數(shù)[22]的復合損失函數(shù)替代了步驟4中的均方誤差損失函數(shù),以有效提升多尺度去霧網絡去霧圖的視覺效果.最后,本文還通過分段訓練的方式替換了單一損失函數(shù)訓練的方式,進一步提升圖像的生成質量.
2.1 單尺度AOD-Net 網絡層的改良
為了提升AOD-Net 的特征表達能力,本文參考FPC-Net 的網絡層優(yōu)化方式來改良AOD-Net的網絡結構,用該方法來強化網絡的特征表達能力,本文改良的網絡結構如圖2 所示.這種改良方式不僅能有效提升網絡對特征的表達能力,使網絡更加緊湊,也能夠在一定程度上減少訓練時出現(xiàn)過擬合的現(xiàn)象[18].另外,本文認為第一層的特征有必要融合至第二個特征融合層,通過實驗發(fā)現(xiàn),這樣的優(yōu)化能夠在一定程度上改善網絡對景深霧的處理能力.

圖2 本文所提的網絡結構Fig.2 The proposed network architecture
本文所提的網絡結構總共包含5 個全逐點卷積層,3 個不同大小的池化層,3 次特征圖融合和1 次解卷積層組成.其中每個逐點卷積的卷積核大小均為1×1,輸入層和輸出層的1×1 逐點卷積層后無池化層和批歸一化層,其余每個逐點卷積后均會連接批歸一化層、ReLU 激活函數(shù)和池化層.第一個池化層的濾波核大小為3×3,padding 值為1,第二個池化層的濾波核大小為5×5,padding 值為2,第三個池化層的濾波核大小為7×7,padding 值為3,每個卷積核和池化層的濾波核的行進步長均為1,下一層輸入的特征圖會融合之前所有層網絡輸出的特征圖,本文的網絡結構細節(jié)如表1 所示.
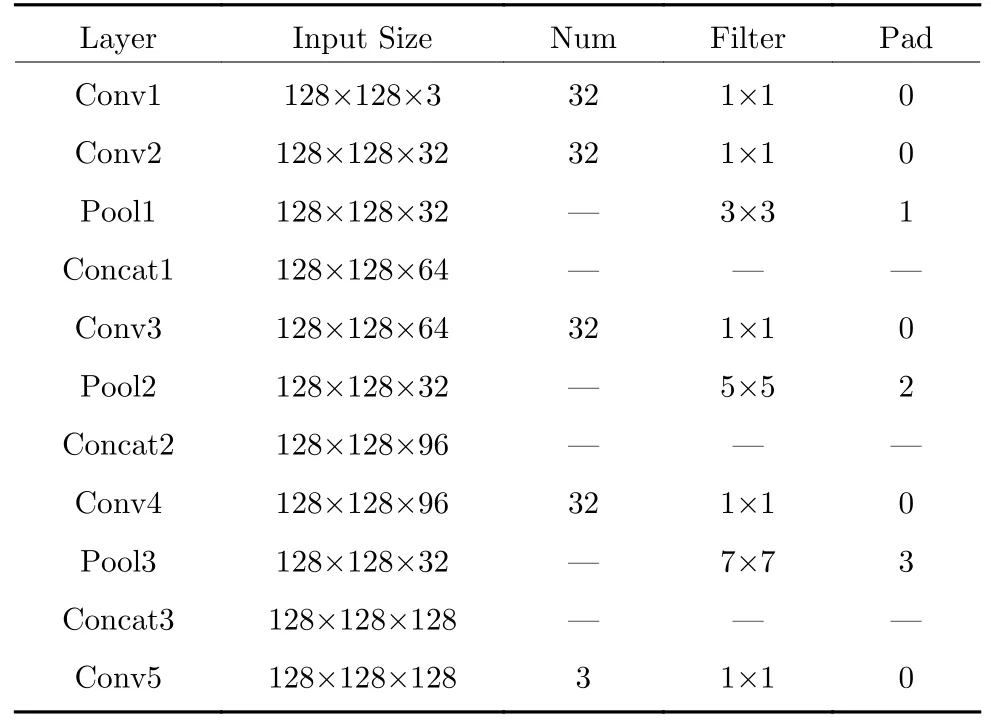
表1 本文所提網絡的參數(shù)Table 1 The architectures of proposed network
圖3 展示了本文所提網絡對景深霧的處理能力.從圖3 中可以看出AOD-Net 經過本文的改良,圖像的遠景部分的霧氣能夠被進一步消除,而原版的AOD-Net 處理后的圖像遠景部分依舊有霧氣殘余,這說明本節(jié)在AOD-Net 的網絡上的改良是有效的.

圖3 去霧效果 ((a) 有霧圖像;(b) AOD-Net;(c) 改良后的AOD-Net)Fig.3 Defogging effect ((a) Fog image;(b) AOD-Net;(c) Improved AOD-Net)
2.2 多尺度網絡結構的構建
AOD-Net 僅采用單尺度的網絡模型對圖像特征進行提取,導致其對圖像細節(jié)的恢復程度較差.而多尺度結構的網絡模型則對圖像的細節(jié)和紋理的恢復效果較為理想[23-25].因此本文將改進的AODNet 嵌入多尺度網絡結構進一步提升網絡的去霧能力,多尺度網絡結構如圖4 所示.

圖4 多尺度網絡結構Fig.4 The architecture of multi-scale network
本文所設計的多尺網絡首先將原始霧圖I進行了2 倍和4 倍的下采樣,然后將下采樣4 倍的霧圖輸入到Scale 3 的K估計模塊得到該尺度的K估計圖,再結合式(3)獲取該尺度的去霧圖I0.25.接下來將I0.25恢復至與Scale 2 輸入圖一致的尺寸,然后將I0.25和2 倍下采樣的原圖一起輸入到Scale 2的K估計模塊,再模仿上一步獲取該尺度的去霧圖I0.5,最后,將I0.5恢復至與Scale 1 輸入圖一致的尺寸,將I0.5和原圖I一起輸入到Scale 1 的K估計模塊,再根據(jù)式(3)獲取最終的去霧圖.需要說明的是,Scale 1 尺度上的估計模塊的輸入圖像的尺寸大小為128×128,輸入通道數(shù)為6,Scale 2 尺度上的估計模塊的輸入層的圖像尺寸為32×32,輸入通道為6,Scale 3 尺度上的估計模塊的輸入層的圖像尺寸為8×8,輸入通道為3.
2.3 損失函數(shù)的改良
本文在訓練網絡時采用了一種包含了圖像重構損失、圖像結構相似損失和TV 損失函數(shù)的復合損失函數(shù),復合損失函數(shù)中的圖像重構損失選擇了常用的最小均方誤差損失函數(shù)(L2損失),每張訓練圖的重構損失如式(5)所示.

其中Ji表示的是無霧清晰圖像,xi表示了該清晰圖像對應的有霧圖像,Fm(xi) 代表了該有霧圖像經過本文m尺度上網絡去霧處理后的圖像.
圖像結構相似損失函數(shù)的作用是使圖像視覺效果更符合人眼主觀視覺感受.而SSIM 相較于峰值信噪比(Peak signal-to-noise ratio,PSNR)能直觀反映生成圖與標準清晰圖之間的結構相似程度[26],因此該損失函數(shù)可以表示為式(6).
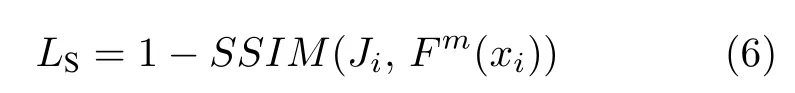
其中SSIM(Ji,Fm(xi))表示了合成霧圖去霧后的生成圖與對應的標準無霧圖像之間的SSIM 數(shù)值.
圖像TV 損失函數(shù)是一種能夠約束圖像噪聲的損失函數(shù),通過降低TV 損失函數(shù)的數(shù)值可以在一定程度上消除因去霧算法和重構損失函數(shù)帶來的噪聲[27].TV 損失函數(shù)的表達式如式(7)所示.

其中?x與?y分別表示了生成圖的像素在橫軸方向和縱軸方向上的梯度幅值.復合損失函數(shù)總公式如式(8)所示.

其中N代表了訓練圖的總量,λ1、λ2和λ3分別代表了每個損失函數(shù)的權重系數(shù),?代表了訓練時設定的權重衰減因子,w代表了網絡的可學習參數(shù),?‖w‖為函數(shù)約束項,作用是為了減少函數(shù)訓練時出現(xiàn)過擬合現(xiàn)象.
本節(jié)所提的復合損失函數(shù)相較于AOD-Net 中使用單一的均方誤差損失函數(shù)能更有效地修正生成圖與清晰圖之間的對比度、亮度以及紋理之間的差異.
2.4 訓練方式的改良
本文所設計的網絡在訓練時采用了分段訓練的方式,與以往單獨使用一種損失函數(shù)訓練網絡的方法不同,這種分段訓練的方式能夠擺脫局部最優(yōu)解,進一步優(yōu)化網絡生成圖的質量[28].分段函數(shù)的兩段分別由式(8)和式(9)組成.不同于式(8),式(9)中將重構損失函數(shù)的L2損失改為了L1損失.

在進行網絡效果測試前,本文對分段損失函數(shù)的有效性進行了測試.測試實驗的結果如圖5 和圖6所示.

圖5 不同方法訓練本文所提模型獲得的損失曲線 ((a) 單一函數(shù)訓練方法;(b) 分段函數(shù)訓練方法)Fig.5 The loss curve obtained by training the proposed model with different methods ((a) The training method of single function;(b) The training method of piecewise function)

圖6 不同訓練方式下的SSIM 與PSNR 變化曲線((a) SSIM 曲線;(b) PSNR 曲線)Fig.6 The curve of SSIM and PSNR under different training methods ((a) The curve of SSIM;(b) The curve of PSNR)
圖5(a)中的曲線分別代表了僅使用式(8)或式(9)對本文所提模型訓練時的Loss 走勢曲線,可以看出當訓練至1 000 輪左右時兩個曲線均達到收斂狀態(tài),然而此時的模型還沒有達到全局最優(yōu),當本文在1 000 輪之前選擇LMS,1 000 輪之后改用訓練時,可以獲得圖5(b)中上方的曲線,反之可以獲得圖5(b)中下方的曲線,最終用于訓練網絡的損失函數(shù)如式(11)所示.

本文每10 輪訓練會保存一次權重文件,用網絡加載每個權重文件對測試集中同一張有霧圖像進行去霧,可獲得150 張生成圖.圖6 展示了這些生成圖與對應的清晰圖樣之間的SSIM 和PSNR 的變化曲線.從圖6 中可以看出,在改變了訓練方式之后,生成圖的SSIM 與PSNR 值均有小幅度的提升.圖7 展示了兩種不同訓練模式下本文模型生成的去霧圖的效果.從圖7 中可以看出,圖7(e)與圖7(c)的主觀視覺效果相近,而圖7(f)虛線框中的墻壁色彩相較于圖7(d)更接近圖7(b)的墻壁色彩.

圖7 兩種不同訓練方法下的去霧效果 ((a) 合成霧圖;(b) ground truth;(c) 所提模型用LMS 訓練1 000 次的效果;(d) 所提模型用LMS 訓練1 500 次的效果;(e) 所提模型用式L 訓練1 000 次的效果;(f) 所提模型用式L 訓練1 500 次的效果)Fig.7 Defogging effect of two different training method((a) Synthetic fog image;(b) Ground truth;(c) The proposed model was trained after 1 000 times by LMS;(d) The proposed model was trained after 1 500 times by LMS;(e)The proposed model was trained after 1 000 times by L;(f) The proposed model was trained after 1 500 times by L)
綜上可知,選擇式(11)作為本文所提網絡的損失函數(shù)能夠獲得更好的去霧效果.
3 實驗結果及分析
3.1 實驗設備環(huán)境及參數(shù)設置
本文所提的去霧網絡是基于Caffe 框架實現(xiàn)的,Caffe 框架通過Matlab2016a 提供的接口來運行,網絡的訓練與霧圖處理均采用了GPU 進行加速,GPU 型號為Nvidia RTX 2 070,顯存容量8GB,初始學習率大小設置為10–5,采用ADAM 優(yōu)化器進行訓練優(yōu)化,訓練輪數(shù)設置為1 500,批處理圖像的數(shù)量為16,權重因子λ1設置為1[21],λ2的選值需根據(jù)實驗和數(shù)據(jù)集進行測試,本文在第3.4 節(jié)給出了測試過程,該參數(shù)設置為0.84,λ3的值選用了文獻[24]中的建議值2×10–8,λ4設置為1[22],動量和權重衰減因子設置為0.9 和0.0001.訓練所使用的霧氣數(shù)據(jù)集有AOD-Net 所提供的NYU2 合成霧數(shù)據(jù)集,內含1 449 張清晰圖以及27 531 張對應的合成霧圖像,同時本文還隨機選擇了RESIDE[29]的OTS (Outdoor training set)數(shù)據(jù)集中的500 張室外清晰圖,并通過這些清晰圖生成9 500 張合成霧圖,兩個合成霧數(shù)據(jù)集總計37 031 張圖片,本文按8:1:1 的比例劃分出29 616 張圖片用于訓練、3 707張圖片作為驗證集、3 708 張圖片作為測試集.本文選用大疆的DJI-Mini2 無人機在霧天拍攝的低空航拍圖像驗證所提去霧算法處理自然航拍霧圖的有效性.本文所提算法還與目前使用頻率較高的幾種去霧算法進行了對比,其中經典去霧算法包括了DCP[6]、BCCR[7]和CAP[8],基于深度學習的去霧算法包括了DehazeNet[11]、MSCNN[12]、AOD-Net[13]、GFN[14]、GCANet[15]和FFANet[16].
3.2 在合成有霧數(shù)據(jù)集上的實驗結果及分析
本文首先在合成有霧數(shù)據(jù)集上進行去霧效果測試,所選用的測試圖像均來自本文構建的測試集.采用SSIM 和PSNR 兩個指標從客觀數(shù)值上來評價各去霧算法的優(yōu)劣,再結合各算法去霧圖的主觀視覺感受來系統(tǒng)性地評價每個算法的去霧效果.圖8展示了各個去霧算法去霧后的主觀視覺效果.表2展示了各去霧算法在測試集的3 708 張合成霧圖上的SSIM 和PSNR 指標平均值對比.
從圖8 中可以看出,DCP 算法處理的圖像偏暗,并且天空區(qū)域會出現(xiàn)一定的失真現(xiàn)象(參考圖8(c)建筑物與天空的交界處).BCCR 算法去霧后的圖像會出現(xiàn)明顯的噪聲,并且圖像的對比度過高(參考圖8(d)室內沙發(fā)的顏色和電視塔周明暗區(qū)域的顏色).CAP 算法對圖像的去霧程度不足(參考圖8(e)中室內圖像依舊殘留較多霧氣),并且圖像的飽和度過高(參考圖8(e)中電視塔天空的色澤).DehazeNet算法去霧后的圖像會殘留較多霧氣(參考圖8(f)室內的遠景區(qū)域),但該算法對圖像色調的恢復程度較高.SCNN 算法對圖像色彩的恢復程度較弱但該算法對圖像色調的恢復程度較高,且圖像部分區(qū)域依舊有大量霧氣殘余(參考圖8(g)電視塔圖片的邊角區(qū)域).AOD-Net 去霧后的圖像的飽和度和對比度都過強,導致圖像整體偏暗(參考圖8(h)中室外場景的天空區(qū)域),此外過于簡單的損失函數(shù)使其對于霧氣集中區(qū)域的恢復效果較差(參考圖8(h)中圖書館中間區(qū)域的霧氣).GFN 算法去霧后的圖像對比度過強,過強的對比度會導致圖像中色值偏低的區(qū)域損失大量的細節(jié)信息(參考圖8(i)的室內圖像中有明顯偏暗的區(qū)域,室外夕陽圖中建筑物的顏色也明顯偏暗).GCANet 處理后的圖像有明顯的霧氣殘留(參考圖8(j)中天空背景和建筑物交界區(qū)域的霧氣殘余).FFANet 去霧后的室內圖像較為清晰,其去霧圖的整體色調和細節(jié)恢復程度均與清晰圖非常接近.本文所提算法去霧后的圖像的飽和度相對清晰圖會更高一些,室內外圖像上的去霧效果略弱于FFANet(參考圖8(k)和圖8(l)的圖書館遠景部分),相較于AOD-Net 在主觀視覺效果上有了一定的改善,不會出現(xiàn)太多過暗的區(qū)域,且去霧程度也更理想.

圖8 合成有霧圖像的實驗結果展示 ((a) 有霧圖像;(b) Ground truth;(c) DCP;(d) BCCR;(e) CAP;(f) DehazeNet;(g) MSCNN;(h) AOD-Net;(i) GFN;(j) GCANet;(k) FFANet;(l) 本文算法)Fig.8 Experimental results of the synthetic fog images ((a) Fog image;(b) Ground truth;(c) DCP;(d) BCCR;(e) CAP;(f) DehazeNet;(g) MSCNN;(h) AOD-Net;(i) GFN;(j) GCANet;(k) FFANet;(l) Proposed algorithm)
從表2 中客觀數(shù)值指標可以看出,本文所提算法在合成有霧圖像數(shù)據(jù)集上的SSIM 均值和PSNR均值相較于AOD-Net 均有一定幅度的提升,整體效果略弱于FFANet 以及GCANet.需要說明的是,FFANet 的網絡層數(shù)多,模型更為復雜,因此其網絡對合成霧圖的去霧效果與清晰圖更接近,僅通過合成霧數(shù)值指標對比并不能確定更適合航拍圖像的算法,因此本文在第3.3 節(jié)和第3.5 節(jié)將會分別展示各個算法在真實自然霧圖上的表現(xiàn)以及參數(shù)量和耗時的對比.
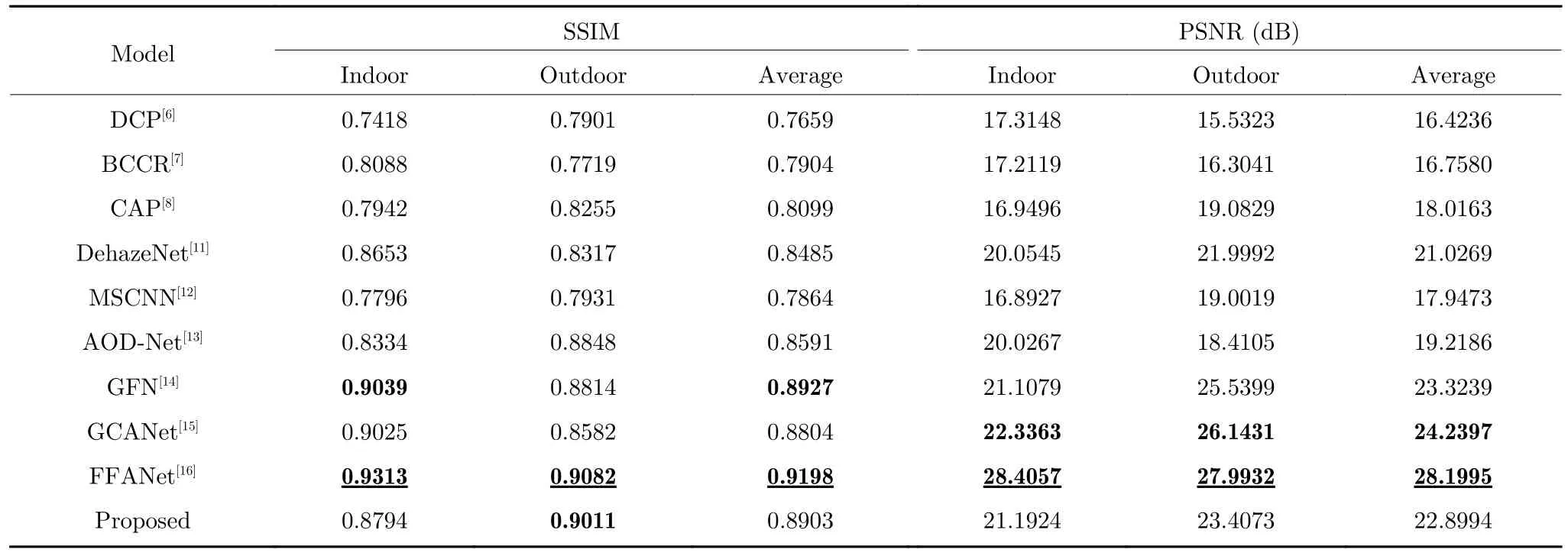
表2 在合成有霧圖像上的SSIM 與PSNR 結果Table 2 Comparison of SSIM and PSNR tested on synthetic fog images
3.3 在自然航拍霧圖上的實驗結果及分析
為了進一步體現(xiàn)本文所提算法的去霧有效性,本文用大疆DJI-Mini2 無人機在重慶拍攝了20 張真實有霧航拍圖像,并用各去霧算法在該組有霧航拍圖像上進行實驗,圖9 展示了各去霧算法在四張具有挑戰(zhàn)性的航拍霧圖上的去霧效果.從圖9 中可以看出各個去霧算法在航拍霧圖上的去霧表現(xiàn)與合成有霧數(shù)據(jù)集上的表現(xiàn)基本一致,其中DCP、GFN和GCANet 算法對小范圍的霧氣去除效果不理想(參考圖9(b)、圖9(h)和圖9(i)的塔尖鐵框中的霧氣有殘余).BCCR 去霧后的圖像有明顯的色彩失真現(xiàn)象(參考圖9(c)的濃霧區(qū)域出現(xiàn)了色彩分層).AOD-Net 圖像整體亮度偏低,細節(jié)可見性較差.CAP 和FFANet 僅去除了圖像中部分霧氣,整體圖像依舊殘留有大量霧氣(參考圖9(d)的高速路右側的區(qū)域和圖9(j) 高塔周圍大量殘余的區(qū)塊霧).而DehazeNet 與MSCNN 對遠景部分的霧氣去除程度較差(參考圖9(e)和圖9(f)的大橋圖像的遠景部分依舊可以看見大量殘存的霧氣).本文所提的去霧算法對航拍霧圖的去霧效果較為自然,去霧圖較少出現(xiàn)過亮或者過暗的區(qū)域,不足之處是對景深霧的去除效果不佳,這可能是由于訓練數(shù)據(jù)是合成霧而非自然霧導致的.

圖9 真實有霧航拍圖像的實驗結果展示 ((a) 有霧圖像;(b) DCP;(c) BCCR;(d) CAP;(e) DehazeNet;(f) MSCNN;(g) AOD-Net;(h) GFN;(i) GCANet;(j) FFANet;(k) 本文算法)Fig.9 Experimental results of the real aerial fog images ((a) Aerial fog image;(b) DCP;(c) BCCR;(d) CAP;(e) DehazeNet;(f) MSCNN;(g) AOD-Net;(h) GFN;(i) GCANet;(j) FFANet;(k) Proposed algorithm)
與有ground truth 作為對比的全參考指標不同,由于真實有霧圖像沒有對應的無霧圖像用于測試SSIM 和PSNR 指標.因此,本文選擇使用如下8 種不同的客觀數(shù)值評價指標來測試所提模型在真實霧圖上的有效性:
1) 增強圖像的盲圖評測方法BIQME (Blind image quality measure of enhanced images),該方法是一種包含了圖像對比度、銳度、亮度、色彩保真度以及自然程度這五種圖像因素在內的打分機制,可以在綜合五種影響程度上給出一種較為可信的評判分數(shù)[30].
2) 霧氣密度評估方式FADE (Fog aware density evaluator),該方法可以直接評測一幅圖像中霧氣保留的程度[31].
3) 能見度指數(shù)VI (Visibility index),該值用于評測去霧后圖像的能見度,主要評測景深霧的消除效果[32].
4) 真實性指數(shù)RI (Realness index),該值重點用于評測人眼視覺主觀感受,這種視覺感受程度也能夠在一定程度上反映去霧后圖像的顏色失真程度[32].
5) 基于人類啟發(fā)感知的圖像融合質量評價CB(Chen-blum metric),該方法重點用于測試輸入與處理圖之間的對比度特征得分[33],其值不僅反映了圖像對比度信息,也反映了原始圖像保留的信息量[34].
6) 圖像視覺信息保真程度評價VIF (Visual information fidelity),該方法是利用處理后圖像信息與原始圖像信息進行比對,得分值可以反映圖像因處理算法而導致圖像的失真程度[35].
7) 基于圖像梯度的處理性能評價GB (Gradient-based performance metric),該值是一個常用的圖像質量評估指標,通常被用來評估圖像的邊緣信息丟失程度[36].
8) 圖像熵評價指標Entropy,該值通常用于評測處理后圖像中信息的復雜程度,即信息量的多少,常被用于測試各類圖像增強或復原算法的優(yōu)劣[37].
其中BIQME、VI、RI、CB、VIF、GB 以及Entropy 的值越大代表去霧圖效果越好,而FADE 的值越小代表圖像去霧程度越高.
圖10 和表3 展示了所有對比算法與本文算法在8 種評價指標上的客觀數(shù)值對比,從中可以看出本文算法的FADE、CB、VIF、GB 以及Entropy均排名前三,這說明本文去霧算法在去霧程度、對比度、色彩保真程度、邊緣信息保留程度以及圖像信息量上有著較為優(yōu)秀的表現(xiàn),而其余略弱于其它對比算法的指標相較于AOD-Net 也有一定程度的提升,這說明本文對于AOD-Net 的改進在各項對比指標上有著全面的提升.此外,我們利用本文數(shù)據(jù)集訓練了FFANet 后,發(fā)現(xiàn)該網絡僅對霧氣分布均勻的圖片去霧效果良好,而對于霧氣濃度分布不均的真實圖像表現(xiàn)較差,這可能是因為該網絡較深,對訓練霧圖數(shù)據(jù)的擬合程度較高,一旦霧氣濃度和霧氣分布與數(shù)據(jù)集中的合成霧氣差別較大時,該網絡的適應性相較于淺層網絡會下降得更多.
另外,由于本文在網絡層中相較于AOD-Net額外引入了池化層,但這種逐點卷積與N×N大小的池化層組合的方式與N×N大小的單卷積層的感受野是一致的,并且兩者在特征提取的效果上可以劃等號[21],因此,額外引入的池化層相較于AODNet 并不會丟失更多的細節(jié)特征,而本文還進一步通過多尺度框架提升了網絡對細節(jié)處霧氣的特征提取能力,從表3 中GB 與Entropy 兩項定量的圖像信息保留量指標也證實了本文的改良方式相較于AOD-Net 能夠保留更多的細節(jié)信息.
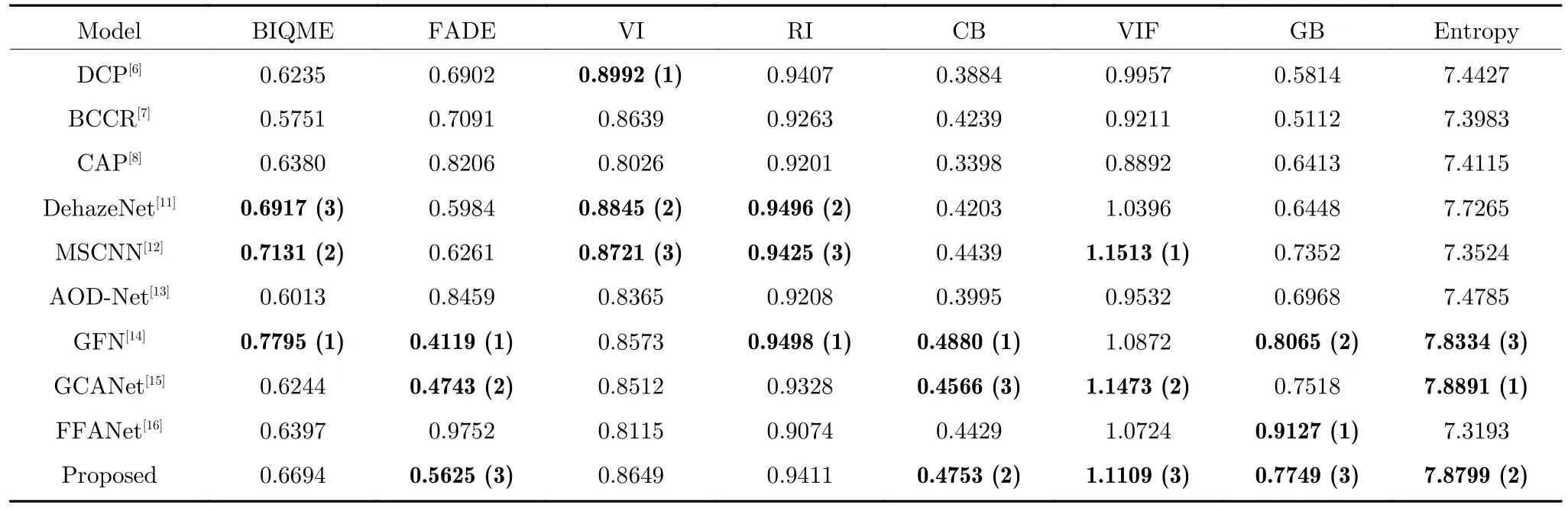
表3 在真實航拍霧圖上的客觀數(shù)值評價:(1) 最好的結果;(2) 次好的結果;(3) 第三好的結果Table 3 Objective numerical evaluation on the fog map of real aerial photography:(1) The best result;(2) The second-best result;(3) The third-best result
3.4 損失函數(shù)的消融實驗結果及分析
本文在損失函數(shù)的設計上采用了多個損失函數(shù)組合的方式.為了體現(xiàn)每個損失函數(shù)對最終生成圖像的影響,本文進行了相關的消融實驗,所用圖片取自AOD-Net 測試圖像集中提供的真實City 霧景圖.消融實驗結果如圖11 所示.從圖11 中可以看出,組合損失函數(shù)L中缺少了L1與L2會出現(xiàn)圖像的色調偏暖,而且圖像的飽和度較差(參考圖11(c)的天空區(qū)域的顏色和房屋墻體的顏色),這說明圖像重構損失函數(shù)會影響去霧圖像的色彩.當L中缺少了LS時圖像的對比度會過高,而且圖像的亮度偏低(參考圖11(d)中的圖像的亮度),這是由于LS中帶有SSIM 函數(shù),而SSIM 函數(shù)的計算與圖像的亮度,結構信息以及對比度有直接關系,因此,LS會影響去霧圖的對比度以及亮度.當缺少LTV時,建筑物表面會出現(xiàn)大片的偽影,例如圖11(e)中建筑物表面出現(xiàn)了大量灰色覆蓋,并且建筑物邊緣信息損失嚴重,這說明LTV會直接影響圖像的邊緣信息以及主觀視覺感受,缺少多尺度框架會導致近景部分出現(xiàn)過度去霧而導致對比度升高,圖像變暗,而遠景區(qū)域的霧氣去除程度則較弱.圖11(g)為圖2所示網絡結構的測試結果,選用了與AOD-Net 中相同的均方誤差損失函數(shù).將圖11(g)與圖11(f)進行對比,可以看出圖2 所示的網絡比AOD-Net 擁有更強的遠景霧去除能力,進一步佐證了第2.1 節(jié)中改良的有效性.同樣地,本文也在測試集圖片組上測試了消融實驗每種情況下的數(shù)值指標對比,從表4中也能直觀看出缺少任何一個部分均會導致最終圖像的視覺感受、真實程度、去霧程度、邊緣信息有一定程度的下降,這也證明了本文改良的網絡結構以及損失函數(shù)每個部分的必要性.
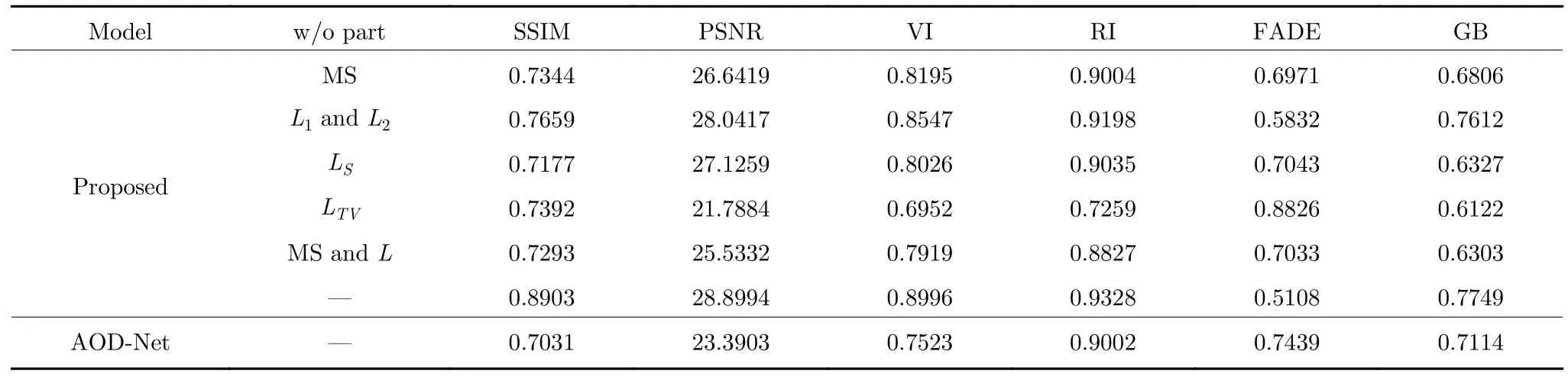
表4 消融實驗中的數(shù)值指標Table 4 The numerical index in ablation experiment

圖11 消融實驗結果 ((a) 航拍霧圖像;(b) 本文方法;(c) 缺少L1 與L2;(d) 缺少LS;(e) 缺少LTV;(f) 無多尺度(Mutil-Scale,MS)結構;(g) 無MS 結構和L (損失函數(shù)為均方誤差);(h) AOD-Net)Fig.11 Experimental results of ablation study ((a) Aerial fog image;(b) Proposed algorithm;(c) w/o L1 and L2 loss function;(d) w/o LS loss function;(e) w/o LTV loss function;(f) w/o MS structure;(g) w/o MS structure and L(The loss function is the mean square error);(h) AOD-Net)
接下來為了確定本文λ2的取值,我們采用了一種范圍縮小的方法,通常λ2的取值在0 至1 之間[26],于是本文每0.1 為間隔訓練了模型,并對圖像進行了主觀和客觀分析,另外,由于λ2關系到圖像的視覺成像效果,因此,本文在記錄客觀數(shù)值指標時選擇記錄了FADE、VI、RI 與CB 四個評價指標來觀測不同的λ2對圖像的去霧程度、能見度、色彩保真度以及對比度的影響,以此來確定λ2的大致取值范圍,圖12 給出了不同取值的λ2對去霧效果的影響,可以看出當取值為0.7 時圖像飽和度過高,而當取值為0.9 時則會導致圖像去霧效果變差;從圖13 則可以看出λ2取值在0.8 至0.9 之間時可以取得最優(yōu)的指標,因此可以確定最優(yōu)解在0.8 至0.9 之間.接下來繼續(xù)以0.01 為間隔測試了0.81~0.89 范圍內的λ2的最優(yōu)值,通過圖14 可以看出,綜合四種對比指標,λ2的取值為0.84 時最適合本文霧氣數(shù)據(jù)集的訓練.

圖12 所提算法在λ2 不同取值時的去霧效果Fig.12 The dehazing effect of the proposed algorithm at different values of λ2

圖13 λ2 不同取值時的圖像指標變化(λ2=0.1~0.9)Fig.13 The change of image index when λ2 takes different value (λ2=0.1~0.9)
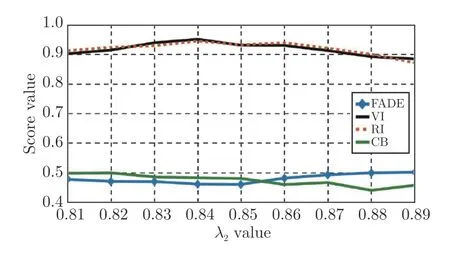
圖14 λ2 不同取值時的圖像指標變化(λ2=0.81~0.89)Fig.14 The change of image index when λ2 takes different value (λ2=0.81~0.89)
3.5 算法的耗時及模型參數(shù)對比
本文所提算法不僅關注了去霧圖像的視覺效果和圖像質量,同時還盡力保證了去霧實時性.表5展示了各算法在原始分辨率和縮小分辨率的航拍霧圖上的處理耗時,其中DCP、BCCR、CAP、DehazeNet、MSCNN 均在Matlab2016a 上運行,使用CPU 來處理圖像.GCANet 和FFANet 采用的Pytorch-gpu 框架,而AOD-Net、GFN 和本文算法均采用MatCaffe-gpu 框架,從表中可以看出采用GPU 加速的算法在圖像處理耗時上要明顯低于采用CPU 進行圖像處理的算法,其中AOD-Net 的去霧速度最快,而本文所提去霧算法的處理速度僅次于AOD-Net,處理640×480 分辨率大小的航拍視頻的幀率可達到35.71 FPS,基本能夠滿足該分辨率下的航拍圖像實時處理.

表5 去霧耗時對比(s)Table 5 Comparison of the defogging time-cost (s)
此外,由于無人機能夠攜帶的硬件設備有限,因此需要輕量級的模型,在考慮到后續(xù)圖像還需要經過目標檢測模型的處理,因此本文的模型需要預留較多的內存給其余算法模型.表6 展示了每種算法的參數(shù)量以及模型大小.從中可以看出本文模型的參數(shù)量在多尺度結構的影響下相較于AODNet 有較大的上升,這也使得本文模型體積相較于AOD-Net 更大,達到了286.5 KB,參數(shù)量和模型大小分別相較于AOD-Net 增加了10.9 倍和31.2 倍,但相較于其它對比模型,本文模型依舊較好地控制在了1 MB 以下,綜合去霧性能,去霧速度及模型大小,本文模型依舊是較理想的無人機圖像去霧算法.
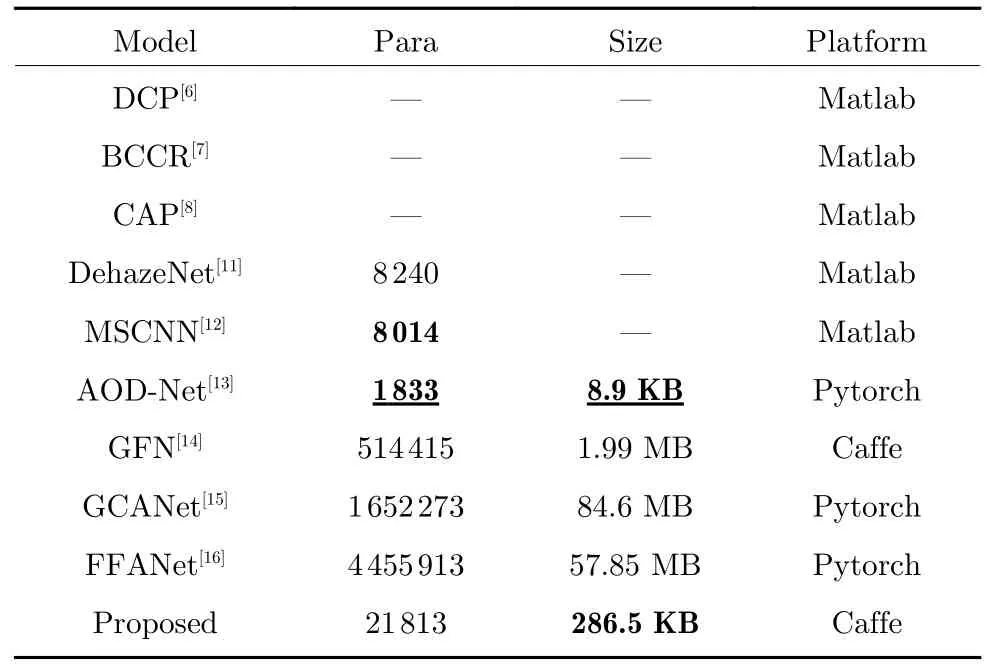
表6 參數(shù)量與模型大小比較Table 6 Comparison of the parameters and model size
3.6 霧天航拍圖像的目標檢測實驗
本文還測試了所提算法對目標檢測算法的輔助效果.為了體現(xiàn)所提去霧算法性能的優(yōu)秀,本文用目標檢測算法分別對有霧圖像中的車輛和去霧后圖像中的車輛進檢測,目標檢測算法使用的是YOLO算法[38],視頻來源于大疆Mini2 拍攝的霧天道路情況,我們從15 s 的視頻中隨機抽取了50 幀圖像進行車輛檢測測試.
車輛檢測的主觀視覺效果如圖15 所示.從圖15中可以看出,在未被去霧算法去霧之前,圖像中能被YOLO 算法檢測出來的車輛數(shù)量有限,并且檢測的置信度數(shù)值較低,如圖15(a)所示.DCP、CAP、AOD-Net 以及FFANet 去霧后的圖像中能被YOLO 算法較為準確地確定6 輛車,但DCP、CAP以及FFANet 去霧后的圖像中容易出現(xiàn)誤檢測的現(xiàn)象.BCCR、DehazeNet 與本文去霧算法效果較為理想,YOLO 算法能夠準確地框出7 輛車,MSCNN、GFN 以及GCANet 效果較差,能被確定的車輛數(shù)均低于5 輛.

圖15 航拍去霧圖像中車輛檢測結果示例 ((a) 原圖;(b) DCP;(c) BCCR;(d) CAP;(e) DehazeNet;(f) MSCNN;(g) AOD-Net;(h) GFN;(i) GCANet;(j) FFANet;(k) 本文算法)Fig.15 Example of aerial image dehazing in vehicle detection ((a) Original;(b) DCP;(c) BCCR;(d) CAP;(e) DehazeNet;(f) MSCNN;(g) AOD-Net;(h) GFN;(i) GCANet;(j) FFANet;(k) Proposed algorithm)
表7 展示了50 幀圖片中框選出車輛的置信度的平均數(shù)值,并標記出了表內效果最好的前三個數(shù)值,從表中的客觀數(shù)值指標中能夠看出本文所提去霧算法去霧后圖像中被檢測出的目標車的置信度數(shù)值最高,該值相較于去霧前圖像提升了22.31%,此外圖中被檢測出的車輛數(shù)輛僅次于BCCR,綜合檢測度可以看出,本文提出的算法配合YOLO 檢測算法能夠有效檢測無人機霧天圖像中拍攝的車輛,具有一定的應用價值.

表7 車輛檢測的置信度數(shù)值,標出三個最優(yōu)的結果:(1) 最好的結果;(2) 次好的結果;(3) 第三好的結果Table 7 Confidence value of vehicle detection,marking the three best results:(1) The best result;(2) The second-best result;(3) The third-best result
3.7 在無霧圖像上的實驗結果及分析
為了體現(xiàn)本文算法的穩(wěn)健性與魯棒性,所提算法除了在第3.2 節(jié)與第3.3 節(jié)中對有霧航拍圖像進行測試,還對20 張隨機拍攝的無霧圖片補充了測試實驗,圖16 展示了各算法在清晰無霧圖像上的去霧效果對比,表8 展示了各算法處理的無霧圖像與原圖之間的PSNR 與SSIM 值,其中最優(yōu)值用粗體加下劃線標出,次優(yōu)值用粗體標出.從表8 可以看出,本文算法對無霧圖像的處理效果較為理想,而從圖16中能看出,本文算法對無霧圖像處理后依舊在某些區(qū)域出現(xiàn)了輕微的過度去霧現(xiàn)象,這種現(xiàn)象相較于其它對比算法要更加輕微.具體表現(xiàn)見圖16(k)路面顏色,部分路面的顏色相較于原圖的路面顏色要深一些,這說明了本文會把灰色路面上磨砂區(qū)域的顏色錯誤判斷為霧氣進行過度去霧.結合有霧圖像與無霧圖像的處理結果,可以看出雖然本文模型僅采用了合成霧圖進行訓練,但卻夠在一定程度上區(qū)分有霧與無霧圖像,對有霧圖像能進行有效去霧,而對輸入的自然清晰圖像的去霧負面影響較小,這也體現(xiàn)了本文改進的算法具有一定的魯棒性.

表8 清晰航拍圖像上的客觀數(shù)值評價Table 8 Objective numerical evaluation on the clear images of aerial photography

圖16 清晰圖像上的去霧效果對比((a) 原圖;(b) DCP;(c) BCCR;(d) CAP;(e) DehazeNet;(f) MSCNN;(g) AOD-Net;(h) GFN;(i) GCANet;(j) FFANet;(k) 本文算法)Fig.16 Comparison of dehazing effects on clear images ((a) Original;(b) DCP;(c) BCCR;(d) CAP;(e) DehazeNet;(f) MSCNN;(g) AOD-Net;(h) GFN;(i) GCANet;(j) FFANet;(k) Proposed algorithm)
3.8 所提去霧算法的局限及結論
本文所提算法雖然在薄霧圖像與無霧圖像上擁有較好的處理效果,但是在某些場景下效果較差,其一是在濃霧情況下,本文的算法較難消除濃霧帶來的影響,無法恢復因濃霧遮擋的圖像細節(jié),例如圖17(a)內大面積的濃霧,另外這種大面積且分布極其不均勻的霧氣會使本文算法在霧氣較薄的區(qū)域進行過度去霧,這會導致出現(xiàn)如圖17(a)內出現(xiàn)對比度升高而變暗的現(xiàn)象,原因可能是因為λ2的數(shù)值不合適,使訓練出的模型不能適配這種霧氣濃度分布極其不均的圖像.其二是本文算法在處理強光源區(qū)域時會把強光當成濃霧進行處理,這會導致算法在去霧時出現(xiàn)一定程度的失真現(xiàn)象,并且色彩保真度也較低,例如圖8(l)第四列圖像、圖17(b)和圖17(c)部分高曝光區(qū)域周圍的天空出現(xiàn)了一定程度的失真,并且從表2 的PSNR 以及表3 的RI 定量指標可以看出,本文算法去霧后圖像的色彩保真程度相較于對比算法并不算優(yōu)秀,綜合第3.2 節(jié),第3.3 節(jié),第3.7 節(jié)以及第3.8 節(jié)的實驗及結論,可以判斷本文模型能夠勝任的環(huán)境為薄霧、無霧環(huán)境.目前還無法勝任的復雜環(huán)境為極低能見度的濃霧,并且抑制強光的能力較弱,未來需要考慮設計更優(yōu)質的損失函數(shù)或改進模型以及在訓練數(shù)據(jù)集中加入復雜環(huán)境的圖像來提升算法適應性與泛化性.

圖17 去霧失敗時的示例圖Fig.17 The example images of failure in defogging
4 結論
針對航拍圖像易受霧氣干擾、AOD-Net 對圖像細節(jié)恢復程度較差以及圖像偏暗的問題,本文提出了一種基于改進AOD-Net 的航拍圖像去霧算法,并與DCP 算法、BCCR 算法、CAP 算法、DehazeNet算法、MSCNN 算法、AOD-Net 算法、GFN 算法、GCANet 算法以及FFANet 算法進行了對比.本文對AOD-Net 的網絡結構、損失函數(shù)以及訓練方式進行了改良,實驗結果表明,本文算法雖然在去霧速度上相較于AOD-Net 有所下降,但去霧圖的對比度、色彩飽和度、色調恢復程度以及圖像明暗度相較于AOD-Net 均有較大改善.此外,本文所提算法去霧后的圖像的多項評價指標數(shù)值相較于AODNet 均有明顯的提升.需要說明的是,本文算法在濃霧圖像和強光源圖像上的表現(xiàn)不太理想,因此后續(xù)需要考慮增加此強光以及濃霧的訓練數(shù)據(jù),同時考慮設計自適應對比度拉伸方法來減少因過度去霧導致圖像過暗的現(xiàn)象.最后,綜合主客觀效果、算法耗時以及霧天航拍圖像中目標檢測的效果,本文算法是一種較為優(yōu)秀的航拍圖像去霧算法.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
