一種結合GAN的定向口令猜測方案
2022-07-04 05:49:44杜李旭弘楊小雪
西安電子科技大學學報 2022年3期
杜李旭弘,陳 杰,2,楊小雪
(1.西安電子科技大學 通信工程學院,陜西 西安 710071;2.桂林電子科技大學 廣西密碼學與信息安全重點實驗室,廣西壯族自治區 桂林 541004)
隨著互聯網時代的飛速發展,人類許多傳統的生產生活方式都發生了空前的改變,各類信息技術更是將社會的數字化程度大幅提高。與此同時,各類信息安全隱患問題也隨之而生,身份認證的重要性更加不容忽視。身份認證是保障用戶個人信息安全的第一道防線,在很多信息系統中甚至是惟一的一道防線,而基于口令的安全驗證方式作為最基本且應用最為廣泛的身份認證方式,更是起著舉足輕重的作用。
隨著信息的爆炸式增長,越來越多的服務需要通過口令進行保護,更有越來越多的用戶個人信息被儲存至網絡空間。這些信息面臨著被泄露的風險,而在信息泄露的同時,數字時代的攻擊者便有可乘之機。用戶個人信息中往往含有一些未被發掘的潛在聯系,若被攻擊者利用,則可能會導致很嚴重的后果。比如,據國外媒體Inverse報道,美國著名運動品牌Under Armour的MyFitnessPal服務被黑客攻擊,1.5億用戶數據被泄露。在此次數據泄露事件中,黑客可獲得的用戶數據包括用戶名、郵箱地址以及年齡等常規信息[1],雖然這些信息單從表面看并不存在風險,但卻會被不法分子加以利用,從而做出針對用戶的威脅行為,如針對性市場營銷。各種新服務絡繹不絕的上線,都會讓個人可標識信息(Personal Identifiable Information,PII)數據集更加龐大,這意味著數據之間的關系網會更加完善,那么數據之間的潛在聯系會更容易被黑客所提取,從而“窺探”到用戶的潛在行為。若要在此種環境下保護用戶的信息安全,就要試圖研究和了解數據集中數據的來源及構造原理。
由于人類的記憶能力有限,通常情況下只能記憶5~7個口令[2],迫使用戶不可避免地采取如下存在安全隱患的行為:低信息熵弱口令的使用[3]、利用個人信息構造便于記憶的口令[4]以及同一口令在多個網站中的重復使用[5]。口令雖然容易記憶,但作為隨機變量其概率分布不均,因此熵值不高[6]。為研究口令安全,學者們提出了各種口令猜測概率模型,如Markov[7]和概率上下文無關文法(Probabilistic Context Free Grammar,PCFG)[8]等。這些模型均運用于傳統概率猜測算法,猜測過程不借助用戶的個人信息,而是關注于用戶會采取流行口令的行為,攻擊者一旦擁有泄露的口令文件,其攻擊目標則會盡可能多地猜測出文件中的口令。區別于傳統漫步猜測模型,定向猜測模型在漫步猜測使用流行口令行為的基礎上,還會使用用戶個人信息構造口令以及口令重復使用等危險行為[9]。隨著大規模個人信息泄露事件的不斷發生,各種類型的個人可標識信息和用戶在其他網站使用的口令都越來越容易被攻擊者獲取,定向猜測帶來的現實威脅日益嚴峻。比如,據中國互聯網絡信息中心(CNNIC)的2015年度報告,6.68億中國網民中超過78.2%都曾遭遇過個人可標識信息數據泄露[10]。
這意味著,現有建立在那些漫步猜測概率模型[7-8]之上的口令生成規則[11]和口令強度評價算法[12],只考慮了十分受限的離線猜測威脅,而無法防御越來越現實、危害越來越大的定向在線猜測攻擊,并且與傳統方法相比,神經網絡方法在口令猜測領域更為準確和實用。文獻[13]提出的多源深度學習模型GENPass,將神經網絡與PCFG相結合,從單個數據集學習時,該模型比單獨使用神經網絡模型匹配率提高了16%~30%;文獻[14]提出采用循環神經網絡(Recurrent Neural Network,RNN)與PCFG相融合的混合猜測模型。該模型破解率始終顯著高于傳統的PCFG(107量級猜測數下)和Markov模型(106量級猜測數下),為提高口令猜測效率提供了潛在的新途徑。筆者在文獻[14]提出模型的基礎上,對定向猜測中用到的個人可標識信息進一步劃分,并結合生成式對抗網絡,以提升口令猜測的成功率。為了使生成的猜測口令更接近真實口令,筆者對TarGuess-I[15]模型中所用到的個人信息分類中的用戶名進一步劃分:除了單純按照數字、字母段劃分之外,對用戶構造的帶有用戶行為特征的字符串也進行劃分,從而避免合并用戶行為特征。將真實口令經過模型解析后的真實規則再利用生成式對抗網絡進行學習和處理,生成高質量偽規則集,并利用該偽規則集進行口令猜測攻擊實驗。其中生成式對抗網絡由生成網絡以及判別網絡兩部分構成,分別用于猜測口令的生成以及對猜測口令的判定,使得猜測口令的結構在接近真實口令結構的同時,又能產生新的結構規則,從而使口令猜測成功率得到進一步的提升。
1 定向口令猜測模型
不同于漫步口令猜測模型,定向猜測模型是在給定目標用戶的前提下猜測出該用戶的真實口令。通過利用用戶的個人信息提高猜測成功率,同時一定程度上減少猜測次數,并且利用個人可標識信息標簽加強了口令解析以及口令猜測過程的針對性和有效性[16]。用戶的個人信息可歸為兩類:第1類是用戶身份的認證憑證,主要包含用戶的舊口令和其他網站泄露的口令;第2類即為個人可標識信息,主要包含有姓名、出生日期、年齡、身份證號碼、學歷、職業等。如何利用個人可標識信息設計定向猜測模型是現階段關于定向猜測研究的重點。
1.1 用戶構造口令行為分析
用戶構造口令的行為主要分為:流行口令的使用、同一口令的重復使用以及如何使用自己的個人信息構造口令。文獻[17]研究發現,60.1%的用戶在口令中使用了至少一種自己本人的個人可標識信息,因此利用個人信息構造口令的行為具有較高的研究意義。筆者采用帶有用戶個人信息的中文用戶中國鐵路數據集12306進行研究。中文流行口令大多由數字組成,而英文流行口令大多包含有涵義的字母串或者鍵盤鍵位布局,根據中國人構造口令的習慣,中文流行口令相對英文流行口令分布較為集中[15],因此中文用戶面臨的定向在線猜測攻擊的風險也更大。經過統計,在中文口令的構造中,各類用戶個人信息的使用情況如圖1所示,使用頻率最高的個人信息是出生日期、用戶名以及生日,其次是郵箱前綴、身份證號以及手機號。
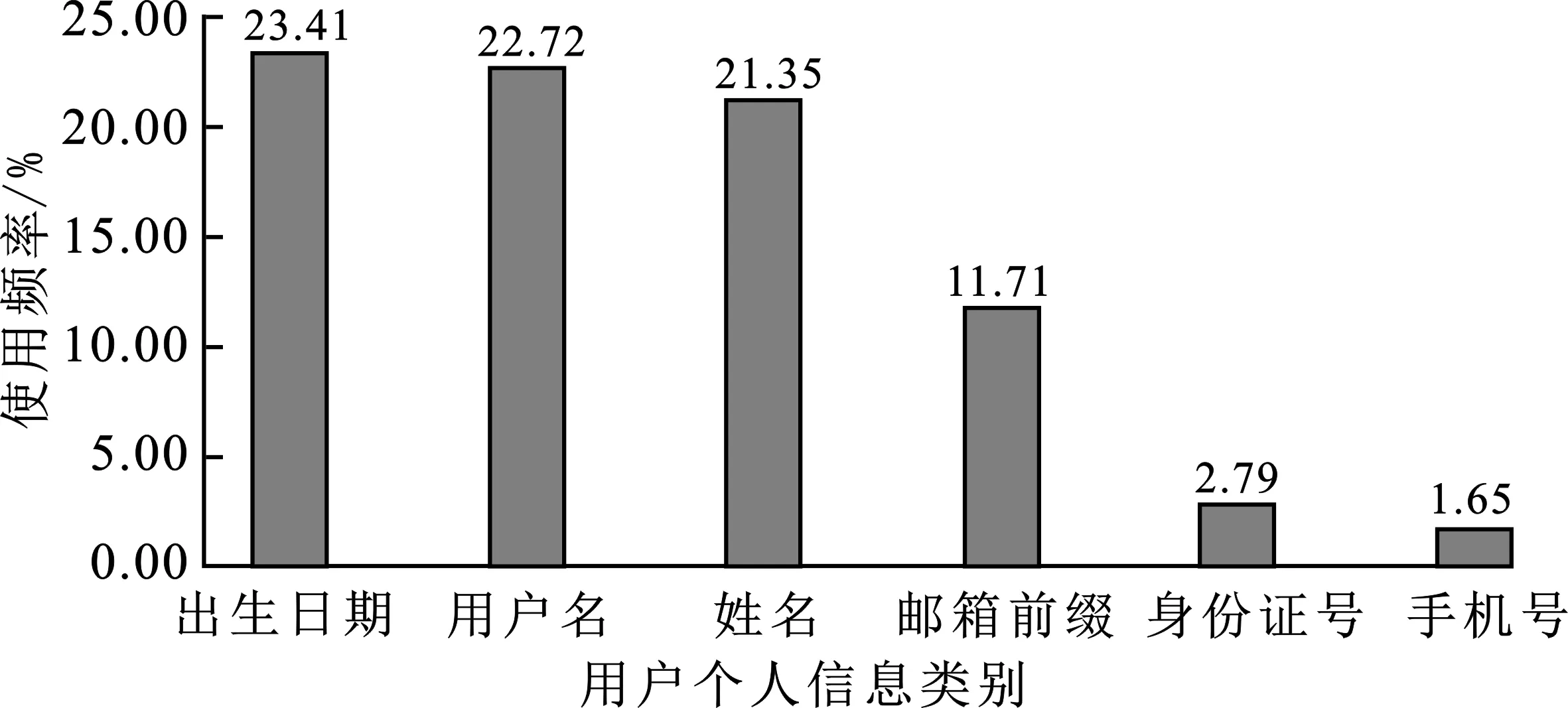
圖1 12306口令集中個人信息使用率示意圖
1.2 鐵路基于PCFG的口令解析
文獻[8]于2009年提出的基于PCFG的漫步口令猜測算法,是PCFG在口令猜測領域的首次應用。其核心思想是將口令按照數字、字母以及特殊字符進行劃分,在口令解析階段統計各個類型中字符串出現的概率并進行降序排列,隨后在猜測攻擊階段利用各類型的字符串概率表,重新組合各類型的字符串,生成猜測列表。文獻[17]于2016年將用戶個人信息應用于猜測攻擊,提出了可識別個人可標識信息語義的定向口令猜測模型Personal-PCFG。Personal-PCFG在前人提出的基于PCFG口令猜測算法的基礎上,又基于長度匹配將用戶個人信息劃分為:姓名、出生日期、電話號碼、身份證號碼、郵箱地址和用戶名。文獻[15]提出了基于 PCFG 定向猜測攻擊模型TarGuessⅠ~Ⅳ系列,與文獻[17]提出模型的不同之處在于,提出的口令猜測模型是基于類型的個人可標識信息匹配,而非基于長度的個人可標識信息匹配,因此在TarGuess模型中用戶的個人信息被劃分得更為具體、準確[16](如,B1表示年月日格式;B2表示月日年格式;B3表示日月年格式;B4表示月日格式;B5表示年份格式;B6表示年月格式;B7表示月年格式;B8表示年份后兩位數字+月日格式;B9表示月日+年份后兩位數字格式;B10表示日月+年份后兩位數字格式)。文獻[18]2019年提出基于主題PCFG的口令猜測模型T-PCFG。該模型關注于個人興趣愛好對口令結構影響的研究,其通過對字母字段的提取方法進行修改,并組成新的猜測集進行試驗。筆者側重于個人習慣對口令結構影響的研究,通過對字母、數字、特殊字符字段的組合提取,進一步防止用戶行為被合并。
根據口令集中個人信息使用率的統計結果以及口令處理過程中發現的規律,考慮用戶名在構造口令過程中的高利用率和高復雜性,筆者提出全面細化用戶名在口令中的構造規則可以提高猜測成功率的設想,從而在文獻[15]提出的定向口令猜測模型TarGuessⅠ的基礎上,將基于類型的個人可標識信息匹配進一步優化:將口令中含有的用戶構造的特殊的字符串,不再只單純劃分為對應個人可標識信息全稱字段以及數字、字母兩種數據類型的字段,而是在包含個人可標識信息全稱字段的基礎上考慮數字、字母以及特殊字符3種數據類型,并且按照“數字+字母”“字母+特殊字符”“數字+特殊字符”的形式劃分(如:口令為“zs1997”,匹配的PII中用戶名為“zs19970606”,則匹配過程不能單純劃分為數字段“19970606”或者字母段“zs”,而是應該劃分為字母+前4位數字“zs1997”),此種劃分方式可防止用戶的某些行為特征被合并,從而提高猜測成功率。文中的個人可標識信息標簽類型見表1。按照文中劃分的個人可標識信息標簽,將真實口令集中的所有口令與每個口令所對應的用戶個人信息進行匹配,從而解析為基于PCFG的規則序列集合。解析過程中除了個人可標識信息標簽的轉換以外,同時從真實口令集中訓練獲得數字(D)、字母(L)和特殊字符(S)分別基于長度的頻次表,并進行降序排列(在解析過程中,口令中的字符串若被轉換為個人可標識信息標簽,則不會添加到L、D、S頻次表中)。
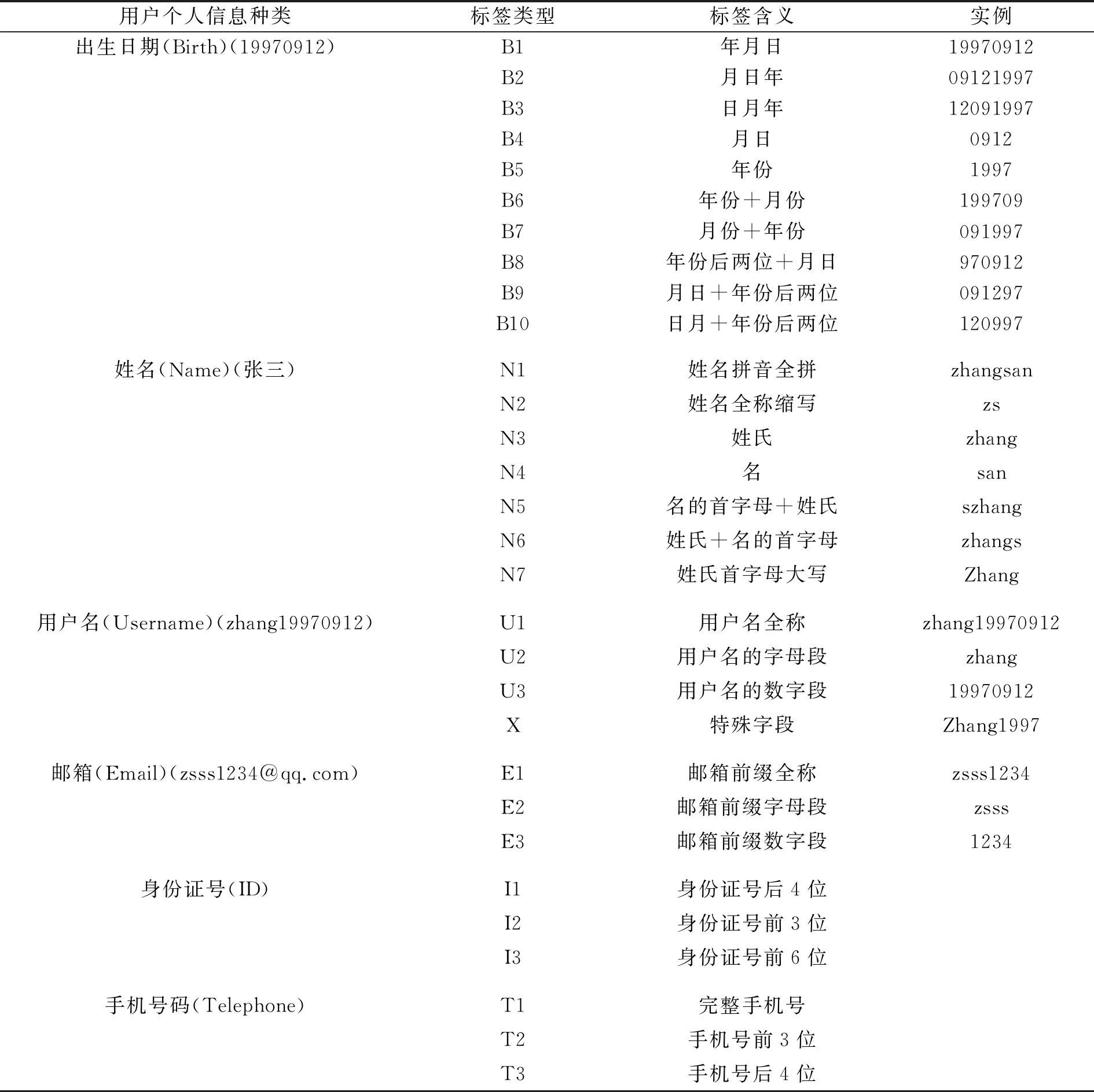
表1 基于PCFG的PII標簽類型
2 生成式對抗網絡模型
將優化后的口令猜測模型與深度學習算法相結合,在無需任何先驗知識的情況下,通過使用生成對抗網絡從實際泄漏的口令中自主學習真實口令分布,并生成高質量的規則序列,運用深度學習的過程中還會學習到口令中一些用戶自己都無法發現的潛在聯系,這意味著在保證規則序列符合規范的同時,還會生成新增規則,從而提升猜測成功率。筆者所用的生成式對抗網絡由生成網絡和判別網絡兩部分組成,真實口令集經過上節所述解析過程之后,得到基于PCFG的口令規則集合,將其與噪聲均用作生成式對抗網絡的輸入,如圖2所示,每次迭代訓練之后,輸出的偽規則都更接近于真實規則序列的分布。
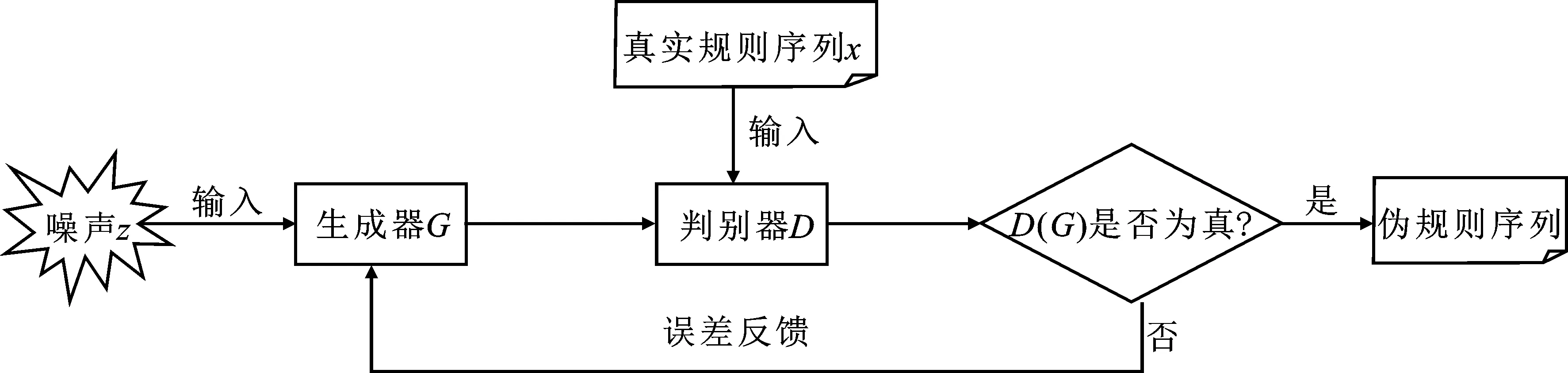
圖2 生成對抗網絡結構示意圖
生成對抗網絡的目標是從訓練集S={x1,x2,…,xn}中學習并生成相同分布的樣本。該網絡將多維隨機樣本z作為輸入以訓練生成器G,訓練過程將密度估計問題轉化為二元分類問題,其要解決的優化問題可以總結為[19]
(1)
其中,f(xi;θd)和g(zj;θG)分別代表D和G。根據生成對抗網絡的訓練目標,定義生成對抗網絡的目標函數為V(D,G),則博弈過程可表示為
(2)
其中,E表示真實數據x和樣本數據z的數學期望。由于V是連續的,因此期望可以通過將V寫成微積分的形式來表示:
(3)
其中,pdata(x)為真實規則分布,pz(z)為生成規則分布。博弈過程為先固定G,求解D的最優解;再固定D,求解G的最優解,然后兩個網絡交替訓練。
設G(z)生成的規則為真實規則x,則噪聲z和噪聲的微分dz可表示為
G(z)=x?z=G-1(x)?dz=(G-1)′(x)dx。
(4)
將z和dz分別代入V(D,G),可得

(5)
定義pg(x)表示噪聲z的生成分布,則
pg(x)=pz(G-1(x))(G-1)′(x) 。
(6)
將式(6)代入式(5),可得
(7)
對式(7)求關于D的偏導數:
(8)
可得D的最大即最優解為
(9)
從D(x)的最優解D*(x)的表達式中可以看出,期望當生成分布與真實分布一致時,即pg(x)=pdata(x)時,D(x)=0.5,即此時判別網絡D只能以拋硬幣的概率來猜測輸入數據的真假性。然后將式(9)代入式(7),并引入連續函數的KL散度。將目標函數整理成散度表達式,可得
(10)
根據KL散度的定義,當生成規則的分布pg(x)與真實規則分布pdata(x)一致時,KL為零,所以當D逼近最優解時,G網絡也無限逼近最小值,符合G網絡的訓練目標。經過多次交替迭代訓練,即可生成合法且遵循真實分布的高質量規則。
2.1 基于生成對抗網絡生成高質量偽規則集
生成網絡是潛在空間Z:Rk和數據空間X之間的確定性映射函數G:Z→X。生成對抗網絡的框架通過遵循對抗式訓練法來學習深層生成模型,訓練過程由判別網絡D引導。在訓練過程中,潛在噪聲點z直接從Rk中采樣并作為輸入提供給G,G再將這些點映射到數據空間中,并將其反饋給生成網絡D。生成網絡D同時接收來自訓練集的真實口令規則和生成網絡G生成的偽口令規則,并且給出G(z)的誤差,從而令生成網絡G得到對抗性訓練從而更新權重。優化目標遵循網絡G、D的誤差最小化。對文獻[19]提出的PassGAN模型進行改進,使其能夠更好地在基于PCFG解析后的規則序列集上訓練,同時輸出更高質量的偽規則序列。文獻[19]使用了Wasserstein GAN改進訓練來實例化PassGAN,同時依靠 ADAM 優化器來最小化訓練誤差[16]。為減少生成模型輸出的偽規則數據與其訓練數據之間的不匹配,筆者主要從以下幾個方面進行了優化改進:latent size、迭代次數、輸入口令向量的最大長度。通過上一節得到的PCFG規則序列集,作為改進后生成對抗網絡的輸入數據集,通過無先驗知識的自主學習,逼近真實口令解析后的規則分布,生成高質量且擴充的偽規則集。通過對生成的偽規則集進行分析和統計,偽規則集中不重復規則、符合規范的合法規則以及出現次數n≥3次的高質量規則序列的數量隨著偽規則集規模的擴大而增加,具體如圖3所示。
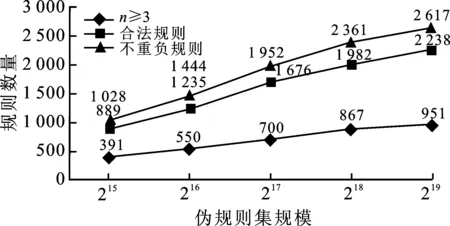
圖3 生成對抗網絡生成的高質量規則數量變化趨勢示意圖
2.2 定向猜測攻擊模型
得到生成對抗網絡學習生成的高質量偽規則集之后,利用該規則集攻擊測試集中的用戶,攻擊過程為:根據生成的偽規則集,給定目標用戶,利用其個人信息以及口令解析過程得到的L、D、S字段的降序表匹配生成該用戶的猜測口令集,若該猜測口令集中包含該用戶的真實口令,則攻擊成功。定向猜測攻擊模型的系統框架如圖4所示。
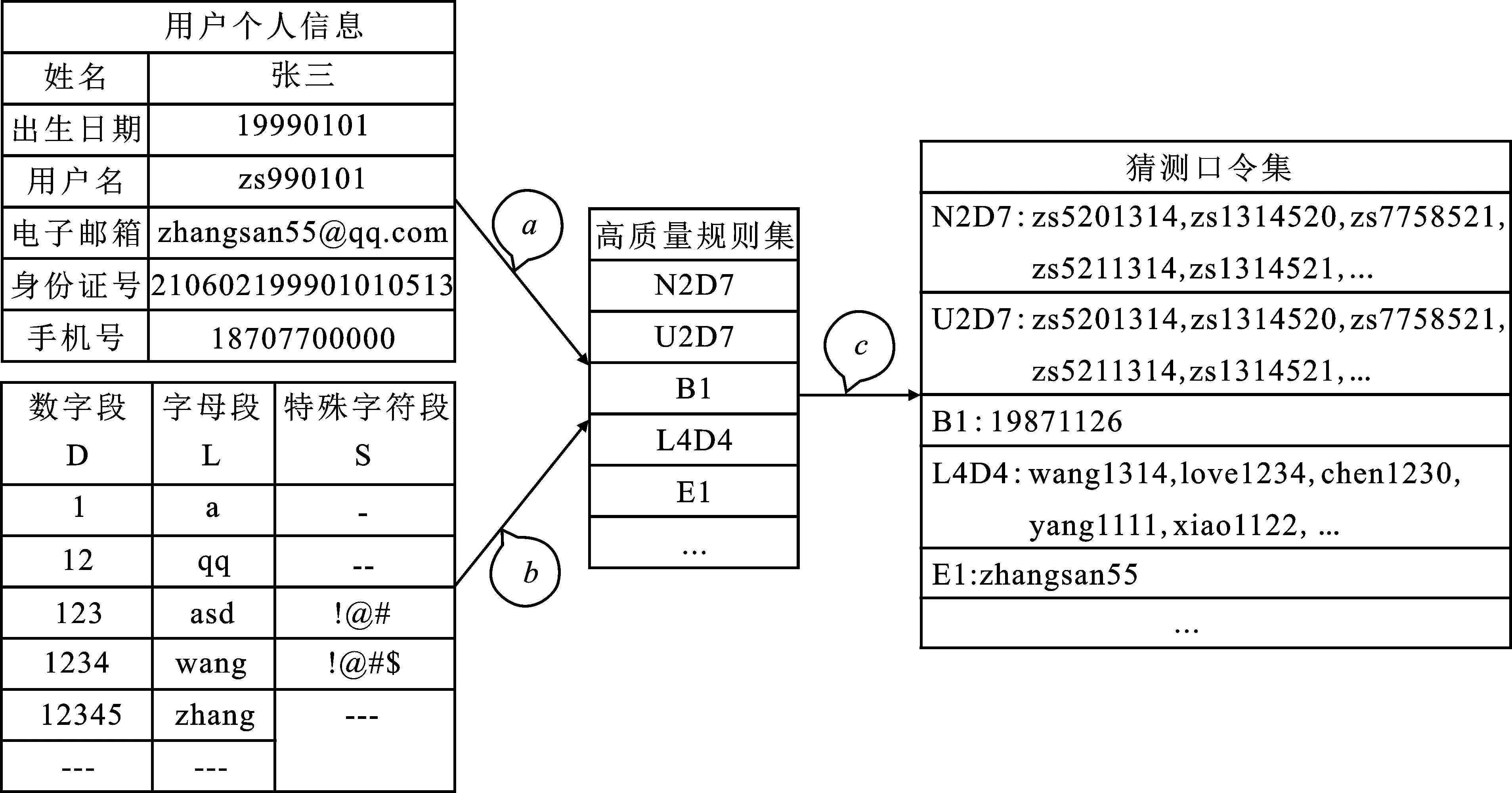
圖4 定向猜測攻擊模型的系統框架示意圖
過程a表示將用戶個人信息按照Nn、Bn、Un、En、In、Tn、Xi,j7種標簽進行劃分,其中n代表字段類型,i代表特殊字符串起始位置,j代表特殊字符串長度;過程b表示按照長度匹配L、D、S字段頻次表中不同長度字符串;過程c表示將過程a、b中匹配到的字符串按照規則集中的規則序列恢復生成猜測口令。在猜測口令的生成過程中,規則序列“N2D7”除了使用用戶的姓名全稱縮寫以外,還需要在長度為7的數字段列表中按照頻率從高到低依次使用數字字符串序列,從而組合生成猜測口令列表,而“B1”則不需要,它僅需要按照用戶出生日期的年月日格式并利用個人信息從而生成對應的猜測口令。
3 實驗結果與分析
在中國鐵路12306數據集上完成了基于個人可標識信息標簽的口令解析實驗、基于生成對抗網絡的偽規則集生成實驗以及基于前兩者的口令猜測攻擊實驗,得到了基于PCFG的真實12306口令集對應的規則序列集,并將其作為訓練數據輸入經過優化的生成對抗網絡,經過多次迭代訓練,生成對抗網絡輸出高質量的偽規則集合;該集合不僅包括顯在的規則序列,還包含潛在的新增規則序列,因此借助該偽規則集合匹配生成的猜測口令質量更高,從而提升了猜測成功率。在實驗過程中,通過對偽規則集進行分析研究,得出偽規則集中符合規范的合法規則占比隨著偽規則集規模的擴大而增加,并且偽規則與真實規則的相似度同樣隨偽規則集規模的擴大而增加,分別如圖5和圖6所示。在偽規則集規模為215時,規則合法率約達到86.48%,隨著其規模增加至219的過程中,規則合法率一直穩定在83%以上。因此,可認為訓練生成的規則集具有較好的合法率;同時,在偽規則集規模從215增至219的過程中,偽規則集與真實規則集的相似度保持在96%以上,并且呈上升趨勢,所以可認為生成的偽規則集與真實規則集也具有較高的相似度。
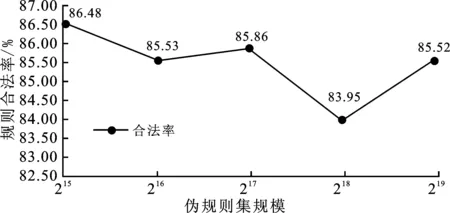
圖5 不同規模偽規則集的合法率變化示意圖
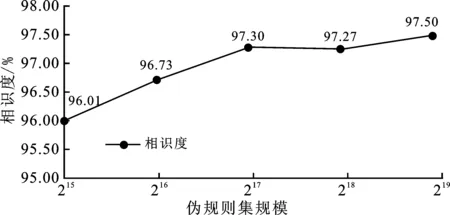
圖6 偽規則集與真實規則集的相似度變化示意圖
本節主要關注于定向口令猜測攻擊的實驗效果。實驗與TarGuess-I模型一樣,都使用中國鐵路12306數據集,并盡量采用相同的實驗配置,將數據集80%的數據作為訓練集以及另外20%的數據作為測試集,在文中優化后的猜測攻擊模型與TarGuess-I模型以及Personal-PCFG模型兩種定向猜測模型上進行比較實驗,實驗結果如表2所示。

表2 定向猜測攻擊效果
實驗結果表明,優化后的定向猜測攻擊模型在猜測規模為102時,成功猜測出36.70%的真實用戶口令,在同等條件下,優于TarGuess-I模型以及Personal-PCFG模型,分別比后兩種模型多猜測成功約16.5%、22.8%的用戶口令。因此,筆者提出的口令解析方案能夠進一步捕捉到用戶構造口令的行為,并通過優化后的生成對抗網絡模型對口令構造規則進行擴充,擴充后的偽規則借助在口令解析階段獲得的L、D、S段序列頻次表以及目標用戶的個人信息對其進行字段匹配,組合生成高質量的新口令序列,從而提高口令猜測的成功率。
4 結束語
針對用戶使用個人信息構造口令的行為,筆者提出了一種基于PCFG并結合生成式對抗神經網絡的定向口令猜測攻擊方案。該方案由基于PCFG的口令解析模型以及基于生成對抗網絡的高質量猜測生成模型組成。在口令解析的過程中,將解析口令的個人可標識信息標簽進一步劃分,使得解析后的口令最大程度地保留用戶的行為習慣。在生成猜測的階段,將解析后的口令以及噪聲作為優化后生成對抗網絡的輸入數據,噪聲經過網絡中生成器和判別器的對抗訓練,會更加關注并逐漸學習到真實解析口令的分布,再通過多次迭代訓練得到包含真實口令規則和新增口令規則的偽規則集,利用偽規則集生成高質量猜測口令從而提高口令猜測成功率。通過在含有用戶個人信息的鐵路12306數據集上進行定向口令猜測攻擊實驗以及與其他方案的對比試驗,驗證了筆者所提方案的有效性。
在今后的研究工作中,將進一步改進生成式對抗網絡的網絡結構,以生成更高質量的猜測口令,進一步提升定向口令猜測攻擊的成功率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
