基于多尺度視覺Transformer的圖像篡改定位
2022-07-08 01:50:02陸璐鐘文煜吳小坤
華南理工大學學報(自然科學版) 2022年6期
陸璐 鐘文煜 吳小坤
(華南理工大學 計算機科學與工程學院,廣東 廣州 510640)
隨著數字拍攝設備的普及和圖像處理技術的發展,用戶可以輕松地對數字圖像進行肉眼無法察覺的編輯,如何定位圖像篡改區域、減少惡意篡改對社會產生的負面影響,逐漸成為一個值得關注的研究方向。拼接篡改是圖像篡改最為常用的手段之一,它利用不同圖像的人或物體拼接到目標圖像中,通過邊緣模糊技術達到制造假象的目的,準確定位目標圖像的篡改區域成為巨大的挑戰,甚至現有的圖像篡改檢測技術也難以取證。
傳統圖像篡改定位算法可以劃分為兩類:基于重疊圖像塊和基于關鍵點的算法。Fridrich等[1]將圖像分割為大小相等的圖像塊,采用離散余弦變換(DCT)提取圖像塊的特征向量,通過計算圖像塊之間的相似度來定位篡改區域和真實區域。為了提高圖像塊特征匹配的速度,Popescu等[2]提出了運用主成分分析(PCA)代替離散余弦變換(DCT)的方法。但是,基于圖像塊的圖像篡改定位算法仍需要消耗大量的計算資源。基于關鍵點的算法,主要運用SIFT[3]、SURF[4]和ORB[5]等算法提取圖像的關鍵特征點。SIFT在圖像縮放、旋轉和平移的情況下仍能有效檢測出圖像篡改區域。Shivakumar等[4]提出了將SURF特征點提取算法與KD-Trees算法結合進行關鍵點匹配的方法,檢測結果具有較低的假陰性率。針對匹配錯誤和魯棒性不高的問題,Zhu等[5]提出了采用隨機樣本一致性方法來過濾匹配錯誤的ORB特征點。
近年來,基于深度學習的算法[6-8]在計算機視覺領域取得了令人矚目的成績,在圖像理解方面遠遠超過了依賴單一傳統特征的算法。Rao等[9]基于深度學習的算法,利用空域富模型(SRM)作為預處理層和卷積神經網絡(CNN)提取高級語義特征,實現了端到端的自適應學習模式。該算法實現圖像級別的圖像篡改識別,但不能實現圖像像素級別的篡改定位,在應用中存在較大的局限性。由于來自不同圖像塊的重采樣特征呈現不一致性,文獻[10]基于圖像塊級別利用重采樣特征進行圖像篡改區域定位。Bappy等[11]通過隨機變換提取重采樣特征,將特征輸入至LSTM網絡判別圖像塊是否被篡改,提出了一種LSTM與編解碼器混合的定位算法。該算法運用LSTM提取圖像塊之間的關系特征,并與卷積編碼器生成的高級語義特征進行結合,輸入至解碼器生成最終掩膜圖像,實現了圖像像素級別的定位,取得了不錯的定位精度,但利用LSTM對圖像塊的空間關系進行建模,計算復雜度較高。為了更加高效準確地識別篡改區域與未篡改區域的差異,文獻[12]改進了U型編解碼器結構[13],提出了環形殘差U型網絡,通過殘差傳播和反饋過程強化篡改邊界的特征差異。Islam等[14]設計了雙階注意力機制的生成對抗網絡,一階注意力圖是位置敏感的,二階注意力圖則是提取像素之間的依賴關系。
上述算法在圖像篡改領域已經取得了巨大進步,但仍然存在許多缺陷。如每層的卷積神經網絡[15]只能提取感受野內部像素之間的關系,缺少全局特征信息。通過增大卷積核的大小,能夠增大感受野,但也會使參數量劇增。深層的卷積層具有更大的感受野,但卷積層過深會帶來梯度消失等問題。因此,淺層的CNN僅在較小像素區域內提取篡改區域與非篡改區域的特征差異,導致定位效果不佳。文獻[16]提出了一種運用預訓練CNN提取圖像特征,利用分層自注意力機制結合空間金字塔捕獲圖像篡改痕跡的方法,但該方法在定位區域較小時未能取得令人滿意的結果。另外,設計有效的特征強化網絡對于改善圖像篡改定位效果也是至關重要的。Kwon等[17]設計了一種高分辨圖像篡改定位網絡,通過多階段特征融合提高了定位篡改區域精度,但該網絡缺乏對全局像素內在聯系建模的能力。
針對上述問題,本研究提出了一種基于多尺度視覺Transformer[18]的篡改定位網絡mVIT-CC,該網絡包括卷積編碼模塊、多尺度視覺Transformer模塊、縱橫自注意力計算模塊和解碼模塊。首先,提出了一種新的多尺度視覺Transformer模塊,用于對不同尺寸的圖像塊序列關系進行建模,以提高對不同篡改區域大小的適應能力;然后,運用縱橫自注意力模塊設計解碼器和Transformer編碼器特征融合結構,優化高級語義特征;最后,在CASIA[19]和NIST2016[20]數據集上進行測試,對該網絡與其他端到端的圖像篡改定位算法進行了對比研究。
1 網絡結構
文中提出的mVIT-CC結構示意圖如圖1所示,它是卷積神經網絡和Transformer的混合結構。在mVIT-CC中,原始篡改圖像經過卷積編碼模塊生成高級語義特征圖,同時運用Transformer模塊提取不同尺寸圖像塊序列的空間信息;然后,利用縱橫自注意力機制(CCNet)將得到的特征圖與對應解碼階段的特征進行融合;最后,將解碼器的預測輸出經過閾值分割生成最終的掩膜圖。
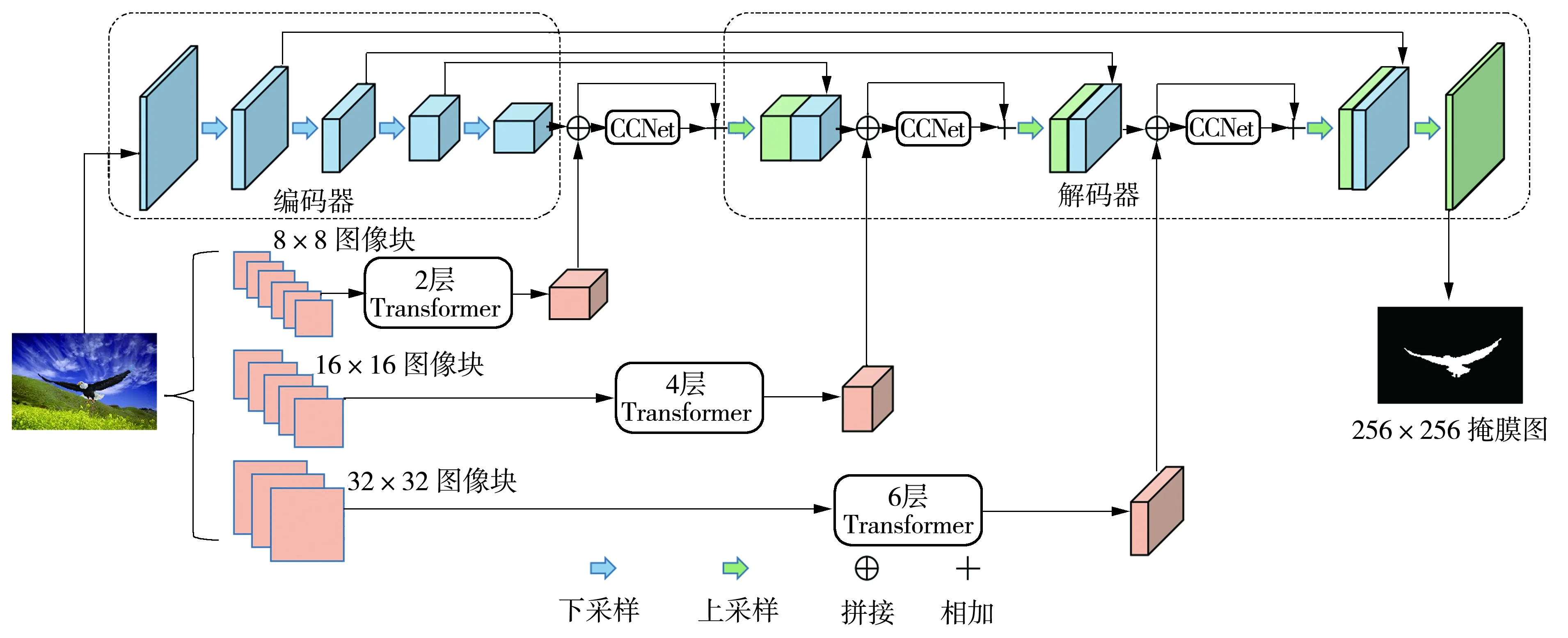
圖1 網絡結構示意圖Fig.1 Network structure diagram
1.1 多尺度視覺Transformer模塊
本文提出的多尺度視覺Transformer模塊設計結構如圖1所示,包括了3個并行的多尺度分支。Transformer模塊的步驟如下:①以3種不同的尺寸對輸入圖像進行劃分并展開得到圖像塊序列;②把圖像塊序列經過線性映射和拼接位置嵌入向量,使Transformer能夠感知圖像空間信息;③把經過處理后的圖像塊序列輸入至多頭自注意力編碼器(MSA)和前向傳播網絡(FFN),MSA和FFN組成Transformer編碼器;④對不同分支的特征圖在通道域求平均值,求得具有全局圖像塊序列特征的輸出結果。mVIT-CC包括3種尺度分支,分別為小分支、中分支和大分支。小分支對應的圖像塊大小為8×8,具有2層編碼器。中分支對應的圖像塊大小為16×16,堆疊4層編碼器。大分支對應的圖像塊大小為32×32,具有6層編碼器。每個分支的Transformer機制可用如下公式表示為
(1)
(2)
(3)
式中:Tcls∈R1×C,為輸入序列頭部的特殊標記[21],C為特征的緯度;Ip∈RN×C,為圖像按一定尺寸劃分后的圖像塊,N為圖像塊總數;E∈RN×C,為線性映射參數矩陣;Epos∈R(N+1)×C,為圖像塊位置嵌入向量;Ln為歸一化層;θA為多頭自注意力機制網絡參數;φl為多層感知器網絡參數;n為迭代步數。
圖像篡改區域定位的本質是提取篡改圖像塊與真實圖像塊之間的隱藏特征差異,從而識別該圖像是否經過篡改操作。大尺寸的圖像塊往往混合篡改區域與真實區域,導致定位結果不佳。小尺寸的圖像塊能更精細地對圖像塊之間的關系進行建模,但數目激增的圖像塊意味著模型參數量的增加。
參數量過多容易導致過擬合,降低網絡泛化能力,同時會影響定位效率。為了權衡圖像篡改定位的精度和網絡的參數量,本文提出了多尺度的Transformer機制,利用不同尺度的圖像序列優化Transformer網絡參數,其工作機制如下:
(4)
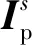
1.2 縱橫自注意力計算
圖像篡改與圖像目標檢測具有很大的差異,目標檢測的區域往往是某一物體,但圖像篡改的區域形狀多樣,不一定是規則幾何形狀的物體,可能是背景的替換、部分物體去除等。某些高級的語義特征在圖像篡改定位任務中并不適用。針對這個問題,本文利用縱橫注意力CCNet[22]增強多尺度Transformer編碼器與卷積解碼器融合特征的表征能力,同時不引入過多的參數量。CCNet能選擇性地關注有用的空間信息,忽略部分無用信息。縱橫注意力機制CCNet的具體過程如圖2所示。可以看到,中間層融合特征通過1×1卷積核進行降維以減少模型參數量,生成特征圖Q、K和V,Q和K通過相關性運算求得注意力圖A,然后根據注意力圖A運用融合操作對特征圖V進行上下文信息收集,讓每個像素點均能感知縱向和橫向像素點的信息。相關性運算和融合操作公式如下:
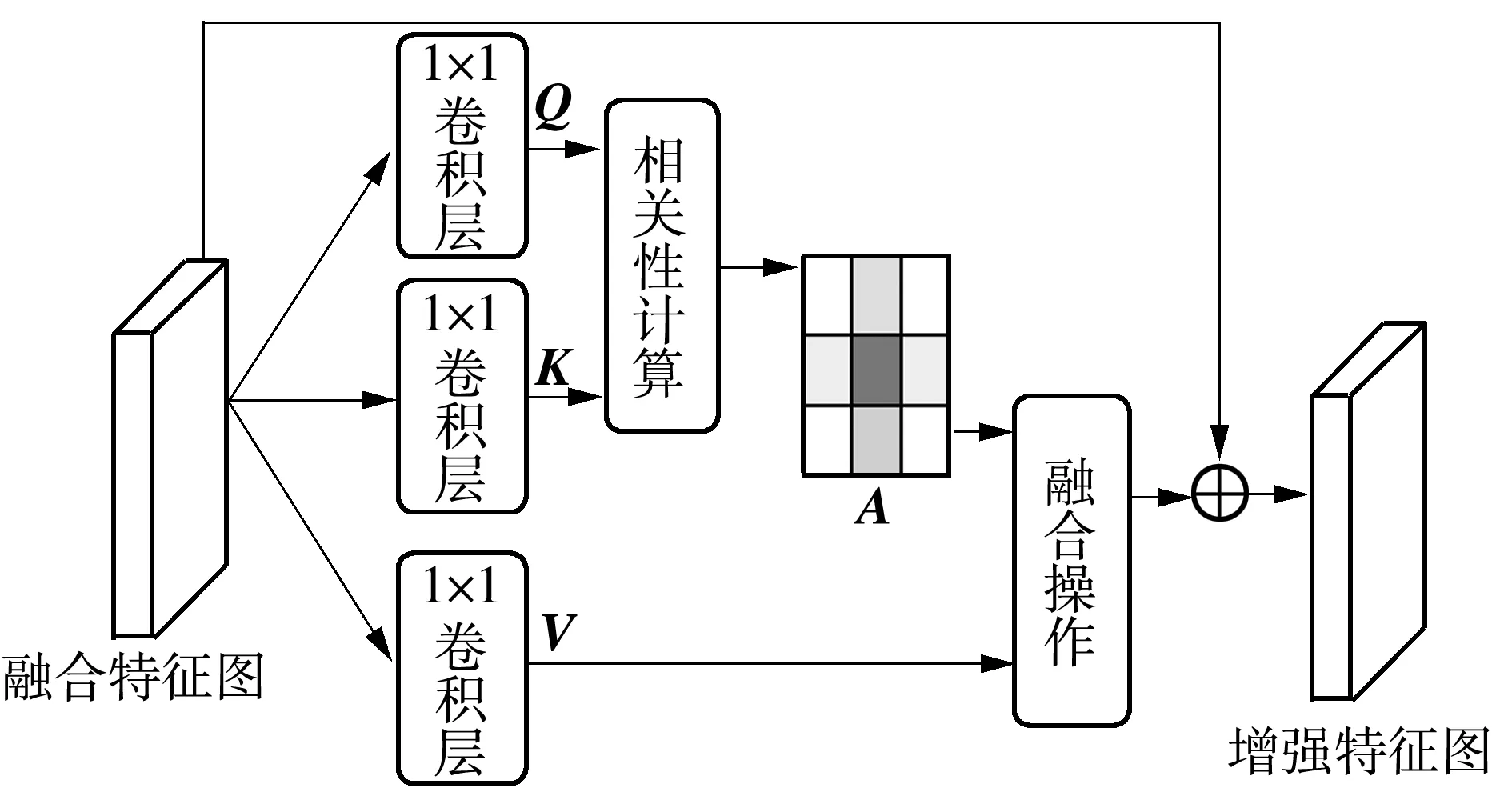
圖2 自注意力模塊Fig.2 Self-attention module
(5)
(6)
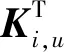
1.3 編解碼器結構
文獻[12]證明了U型對稱的編解碼器結構在圖像篡改定位任務中相當有效,本文卷積編解碼器結構的主干網絡與文獻[12]提出的環形殘差U型網絡一致。編解碼器的基本單元為環形殘差神經網絡,環形殘差U型網絡通過構建前向反饋和負反饋,達到增強篡改區域與真實區域之間差異的目的。編碼器與解碼器同一階段的特征使用跳躍連接相連,從而保存部分圖像的低級語義信息。圖3給出了環形殘差U型網絡基本結構單元的工作原理。從圖中不難發現,環形殘差網絡由兩個正向傳播環和一個反向傳播環構成。靠左邊的正向環由兩個3×3的卷積層組成,另外一個正向環具有兩個1×1的卷積層。反向環通過輸入特征與前向卷積層提取的特征相乘求得,用于計算殘差的反饋信息,挖掘更多隱含信息。

圖3 環形殘差模塊Fig.3 Ringed residual module
1.4 損失函數計算
本文使用的損失函數結合了BCE[23]損失、SSIM[24]損失和IoU[25]損失,公式表示如下:
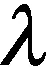
(7)
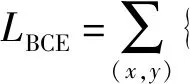
(8)
(9)
(10)
2 實驗
2.1 實驗環境與參數設置
實驗仿真環境:顯卡為AMD的MI 100,顯存大小為64GB,硬盤大小為1TB,CPU處理器型號為AMD 5950X,實驗平臺為Ubuntu 18.04,Python版本為3.8,深度學習框架使用PyTorch。本文實驗輸入的篡改圖像尺寸均縮放為256×256,Batch大小設置為8,訓練采用的優化方法為隨機梯度下降法,學習率設置為0.001,動量為0.9,權重衰減為0.000 5。所有模型均訓練400輪,選取最佳的模型進行測試。
2.2 數據集
本文實驗中用到的數據集包括融合數據集[11]、NIST2016[20]和CASIA[19]。為增強模型的泛化能力,對輸入圖像和標簽采用水平、垂直方向翻轉和中心裁剪的方法來擴充數據。
本文采用的融合數據集來自文獻[11],共有35 712幅篡改圖像,全部用于神經網絡的預訓練。文獻[11]把COCO數據集[27]的目標物體作為源篡改區域,拼接到Dresden數據集[28]中。Dresden是圖像篡改定位任務中標準的數據集。為了保證融合數據集的多樣性,源圖像都經過兩種不同參數的旋轉和縮放后拼接到目標圖。
NIST2016數據集的篡改手段包括復制-粘貼、拼接和移除,而且篡改圖像經過了后處理,通過肉眼難以精確識別出篡改區域。NIST2016包括564幅圖像,圖像的平均分辨率為2 448×3 264,提供篡改區域的二值圖,其中404幅圖像作為訓練集,160幅圖像為測試集。
本文將CASIA2.0的5 123幅圖像用作訓練集,其中有3 274幅圖像的篡改與非篡改區域來源于相同圖像,將CASIA1.0的921幅圖像用作測試集。CASIA2.0和CASIA1.0是圖像篡改定位任務極具挑戰性的數據集,篡改區域尺寸多樣,經過了旋轉、縮放和扭曲等預處理,而且在篡改后還添加了后處理用于模糊篡改痕跡。
2.3 評估指標
本文采用F1和接收者操作特征曲線(ROC)下的面積(AUC)定量分析模型的有效性,以圖像像素級別計算F1和AUC。F1是一種用于衡量二分類模型精確度的指標。F1值越高,表示二分類效果越好,其最大值為1。ROC曲線描述不同分割閾值下的預測性能,AUC越接近1說明模型的二分類表現越好。F1的計算公式如下:
(11)
(12)
(13)
式中:P為查準率,是正確預測的正樣本數占預測為正樣本總數的比例;R為查全率,是正確預測的正樣本數占所有正樣本數的比例;NTP為被正確判斷的篡改像素點的數量,NFP為被錯誤識別的真實像素點的數量,NFN為被錯誤判別為真實像素點的數量。
2.4 實驗結果分析
為驗證本文提出的網絡模型的有效性,將本文算法與基于傳統手工特征提取和基于深度學習的篡改區域定位算法進行對比分析,同時進行了消融實驗和魯棒性分析。實驗對比的算法有以下7種:
(1)ELA[29]算法,該算法通過對待定位圖像進行固定質量壓縮,分析篡改區域與真實區域之間的壓縮錯誤存在的差異,從而定位篡改區域。
(2)NOI1[30]算法,該算法假設真實圖像的噪聲量是均勻的,當圖像塊來自不同圖像時會導致局部噪聲不連續性。NOI1利用高頻小波系數模擬局部噪聲進行篡改定位。
(3)RGB-N[31]算法,該算法是一種雙流的定位框架,包括RGB流和噪聲流,噪聲流通過富含隱寫分析的模型濾波器提取篡改痕跡噪音不一致性。
(4)ManTra-Net[32]算法,該算法利用卷積神經網絡提取篡改特征,運用局部異常檢測網絡實現像素級定位。
(5)J-LSTM[11]算法,該算法混合LSTM和CNN結構,運用LSTM提取圖像塊之間的空間信息。
(6)SPAN[16]算法,該算法是一種空間金字塔和自注意力機制相結合的模型,對多尺度圖像塊之間的關系進行建模,完成像素級別的篡改區域分割。
(7)GSR-Net[33]算法,該算法運用生成對抗網絡擴充訓練數據,通過篡改邊界增強分支來提高定位精度。
本文算法與上述5種算法在標準數據集CASIA和NIST2016上的F1比較如表1所示。從表中可知,基于深度學習的定位算法的定位精度遠高于傳統的定位算法,特別在NIST2016測試集上高出了50%以上。主要原因是傳統算法依靠單一特征進行判斷,面對篡改手段多樣的定位場景表現較差。在CASIA數據集上,本文算法的F1相比性能較好的傳統算法NOI1提高了16.8%,相比RGB-N提高了2.1%。與SPAN相比,mVIT-CC在兩個數據集上的F1分別提高了4.9%和29.5%,SPAN運用局部自注意力機制提取篡改特征,該機制在CASIA和NIST2016數據集上的表現較差。本文算法利用多尺度視覺Transformer模塊提取圖像塊序列之間的關系,具有較大的感受野,生成的特征富含全局圖像信息,因此在CASIA和NIST2016測試集上均取到最好的F1,特別是在NIST2016測試集上相比先進算法RGB-N提高了15.5%。
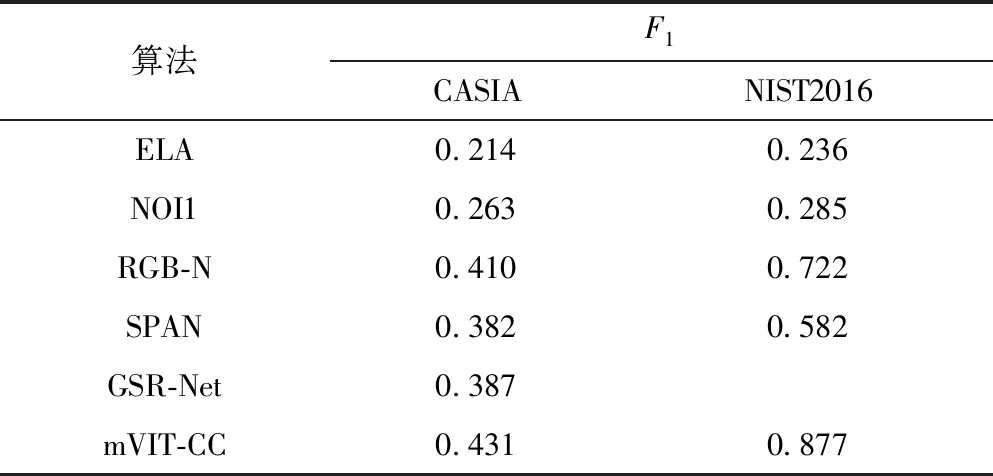
表1 在標準數據集上6種算法的F1值對比Table 1 Comparison of F1 values among six algorithms on the standard datasets
本文算法在標準數據集上與其他算法的AUC值比較如表2所示。從表中可知:傳統算法ELA和NOI1的泛化能力較差,AUC值均沒超過0.7;在NIST2016測試集上,本文算法取得了最高的AUC得分,相比SPAN提高了1%;J-LSTM利用LSTM結構對單一尺寸的圖像塊序列的空間關系進行建模,相比多尺度的mVIT-CC在NIST2016數據集上的AUC值下降了接近21%;在CASIA數據集上,mVIT-CC的AUC分數并不理想,相對SPAN算法下降了11%。CASIA有451幅圖像的篡改區域與真實區域來源于同一幅圖像,本文算法在分割來自同一圖像的篡改區域效果上并不理想,導致AUC分數偏低。本文算法在CASIA和NIST2016測試集上的F1提高明顯,在NIST2016上的AUC分數也略有提高。由此可見,本文算法的綜合性能優于現有的算法。
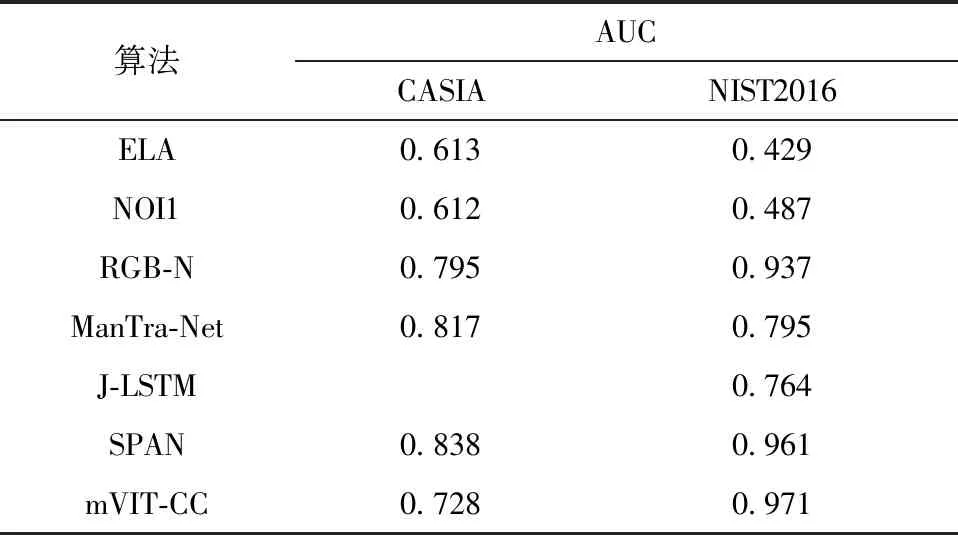
表2 在標準數據集上7種算法的AUC值對比Table 2 Comparison of AUC values among seven algorithms on the standard datasets
為驗證多尺度視覺Transformer定位模型的有效性,本文使用以下4種情況進行消融實驗,結果如表3所示。
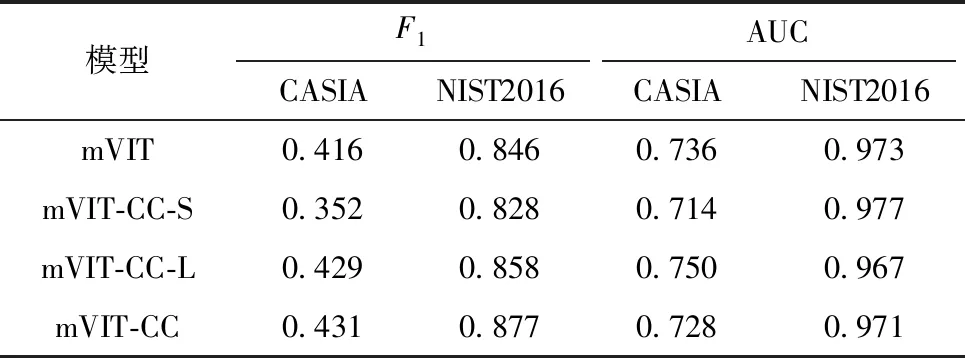
表3 消融實驗結果對比Table 3 Comparison of ablation experimental results
(1)mVIT:采用的Transformer包括三分支結構,但在解碼階段特征時沒使用縱橫注意力機制CCNet進行特征篩選。
(2)mVIT-CC-S:Transformer編碼器結構只有小尺度圖像塊分支,特征融合時采用CCNet機制。
(3)mVIT-CC-L:只有大尺度圖像塊分支的Transformer和CCNet融合機制。
(4)mVIT-CC:同時有多尺度Transformer分支網絡和CCNet融合機制。
本文提出的基于多尺度視覺Transformer的圖像篡改區域定位模型mVIT-CC,相比其他消融模型在標準數據集上的F1最高。mVIT-CC融合3種不同尺度的Transformer分支,增強了網絡適應不同大小篡改區域的能力,同時在特征融合時采用縱橫注意力機制CCNet,過濾無用的高級語義信息。相比只有小尺度分支的mVIT-CC-S,mVIT-CC在CASIA和NIST2016上的F1分別提高了7.9%和4.9%。由于小尺度分支的Transformer編碼深度較淺,提取篡改區域與真實區域的邊界痕跡能力較弱,導致定位結果并不理想。與mVIT-CC-L相比,mVIT-CC在標準數據集上的綜合性能略有提高;將mVIT-CC-L的層數增加至8和10,在CASIA數據集下的F1僅為0.414和0.417,明顯落后于mVIT-CC。由此可見,mVIT-CC-L即使增加堆疊層數,篡改定位能力仍然十分有限。相比不采用縱橫注意力機制收集融合特征上下文信息的mVIT,mVIT-CC在標準數據集上的F1有略微提高。小尺度mVIT-CC-S的綜合性能較差,相比mVIT在CASIA數據集上的F1下降了6.4%,在NIST2016數據集上的F1下降了1.8%,表明小尺度Transformer的綜合性能有限。上述模型的AUC得分相差不明顯,在CASIA和NIST2016數據集上,mVIT-CC僅落后最高得分2.2%和0.6%。圖4展示了mVIT和其他消融模型在標準數據集上的定位效果。由圖可見:相比其他消融模型,mVIT-CC模型預測的篡改區域連通性更好,同時具有更低的假陽性率;mVIT-CC在小尺寸篡改區域的定位能力比mVIT強。由此可見,本文提出的多尺度視覺Transformer和特征融合機制是有效的。
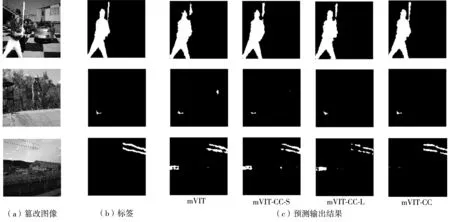
圖4 4種模型在NIST數據集上的樣例篡改定位結果Fig.4 Sample tampering detection results of four models on NIST dataset
2.5 算法魯棒性分析
表4展示了各算法在NIST測試集對JPEG壓縮和縮放攻擊的F1,JPEG壓縮攻擊是最為常見的篡改圖像后處理方法。本文測試的JPEG壓縮因子r為100、70、50。壓縮因子越小,圖像壓縮的效果越好,同時定位圖像篡改區域的難度越大。基于傳統特征的算法在壓縮因子小時的穩定性較差,F1下降接近15%;RGB-N算法在壓縮因子為70和50時,F1下降了4.5%;mVIT-CC算法的F1維持在較高水平,F1下降最多為0.3%,mVIT-CC在壓縮因子等于50時僅僅下降了0.1%,而且圖像縮放因子為0.7和0.5時也不會對圖像篡改區域的定位結果造成精度損失。由此可見,本文算法能有效地抵抗圖像JPEG壓縮和縮放攻擊,具有較強的魯棒性。

表4 8種算法在NIST測試集對JPEG壓縮攻擊的F1值Table 4 F1 values of eight algorithms on NIST test dataset for JPEG compression attacks
2.6 算法復雜度對比
表5展示了基于深度學習的篡改定位模型的參數量和定位一幅圖像的平均耗時。平均耗時為推理NIST中160幅測試圖像耗時的平均值。結果表明,本文提出的定位模型大小為285.8×106,遠遠小于RGB-N模型,引入縱橫注意力機制后參數量僅增加了0.4×106,也沒新增過高的延遲。RGB-N定位一幅圖像篡改區域耗時接近3 s,限制了該算法在圖像篡改定位領域中的應用,不適用于實時性較強的場景。本文提出的模型推理一幅圖像的篡改區域耗時僅需514 ms,能有效滿足現實生活的各種需求。
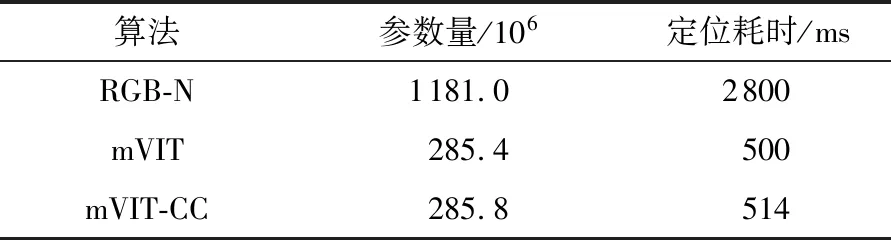
表5 3種算法的網絡參數量和耗時對比Table 5 Comparison of network parameters and time consuming among three algorithms
3 結論
本文提出了一種基于多尺度視覺Transformer的圖像篡改定位網絡mVIT-CC,以實現端到端高效準確地定位圖像篡改區域。本文結合Transformer編碼器和卷積編碼器,提取多尺度圖像塊序列的空間信息,通過縱橫注意力機制將編碼器和解碼器的特征進行融合。Transformer編碼器結構設計了3個不同圖像塊尺度的分支,有利于定位不同形狀大小的篡改區域。實驗結果表明,本文算法在CASIA和NIST2016數據集上取得了優異的綜合性能,同時對JPEG和縮放攻擊具有較強的魯棒性。本文算法主要針對的篡改手段包括圖像拼接、復制-粘貼和移除,未來的研究將加強對生成對抗網絡智能生成的偽圖像進行定位。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
