基于混合多策略優(yōu)化的粒子濾波算法
2022-07-08 03:26:08文尚勝許函銘陳賢東丘志強(qiáng)
文尚勝 許函銘 陳賢東 丘志強(qiáng)
(華南理工大學(xué) 材料科學(xué)與工程學(xué)院,廣東 廣州 510640)
重要性重采樣粒子濾波(SIR-PF)是一種基于蒙特卡羅思想的非線性濾波器[1],通過一組具有關(guān)聯(lián)權(quán)重的離散獨(dú)立隨機(jī)粒子來近似目標(biāo)的后驗(yàn)分布。由于受系統(tǒng)非線性與非高斯或未知噪聲形式的影響較小,相比于擴(kuò)展卡爾曼濾波器(EKF)與無跡卡爾曼濾波器(UKF),SIR-PF可以在高度非線性系統(tǒng)中提供更優(yōu)的目標(biāo)估計(jì),故在統(tǒng)計(jì)學(xué)、機(jī)器學(xué)習(xí)、目標(biāo)跟蹤、計(jì)算機(jī)視覺、通信以及計(jì)算生物學(xué)等領(lǐng)域有許多成功的應(yīng)用[2]。
但SIR-PF在解決非線性問題時(shí)也存在部分缺陷,如嚴(yán)重的粒子退化與貧化問題。為緩解粒子退化與貧化現(xiàn)象,Wang等[3]引入橢圓誤差思想,通過卡方值對(duì)粒子的置信度進(jìn)行評(píng)估分級(jí),對(duì)樣本集進(jìn)行篩選和優(yōu)化。Li等[4]根據(jù)粒子集的空間分布進(jìn)行網(wǎng)格劃分,提出了一種確定性的重采樣方法,該方法可嚴(yán)格保留粒子的原始狀態(tài)。由于元啟發(fā)式算法與粒子濾波具有一定的相似性,Zhou等[5]提出了一種基于遺傳重采樣的粒子濾波器,通過遺傳算法的交叉與變異操作來提高粒子的多樣性,采用精英保存策略使粒子向高似然區(qū)域集中。Zhang等[6]結(jié)合蜂鳥優(yōu)化策略提出了蜂鳥粒子濾波,但由于蜂鳥優(yōu)化本身較為復(fù)雜的尋優(yōu)機(jī)制,此算法的時(shí)間復(fù)雜度較大。陳志敏等[7-8]基于蝙蝠算法與粒子群算法優(yōu)化重采樣過程,實(shí)現(xiàn)粒子間信息的共享,自適應(yīng)地控制高似然區(qū)域內(nèi)粒子的數(shù)量,從而增強(qiáng)粒子的全局尋優(yōu)能力。Zhang等[9]提出了一種多種群循環(huán)結(jié)構(gòu)的粒子濾波器,以不同初始方差生成樣本集,通過交叉與變異生成和保留每個(gè)種群的高權(quán)重粒子,并替代下一個(gè)循環(huán)結(jié)構(gòu)的低權(quán)重粒子,這可降低樣本集對(duì)先驗(yàn)分布估計(jì)的精度要求,并更好地覆蓋后驗(yàn)分布,但受種群數(shù)的限制,解決高維問題時(shí)耗時(shí)較大,內(nèi)存消耗也大。
布谷鳥搜索(CS)算法是由Yang等[10]提出的,模擬了布谷鳥與宿主之間的寄生關(guān)系,標(biāo)準(zhǔn)CS中的萊維(Levy)飛行機(jī)制具有較強(qiáng)的全局尋優(yōu)能力,但在搜索后期也存在種群無法跳出局部最優(yōu)的問題。
本文結(jié)合CS算法,提出了一種基于混合多策略優(yōu)化的粒子濾波算法(HMSPF):在搜索前期先通過Levy飛行策略提高樣本集的有效粒子數(shù),確定樣本集框架;在搜索后期使用差分進(jìn)化算法(DE)[11]增加整個(gè)樣本集的多樣性,并進(jìn)行精細(xì)化處理;在整個(gè)搜索過程中,采用成功歷史(SH)策略[12]對(duì)Levy飛行策略和差分進(jìn)化算法的參數(shù)進(jìn)行自適應(yīng)調(diào)整,修正粒子集的運(yùn)動(dòng)趨勢(shì),將更多的粒子導(dǎo)向高似然區(qū)域,提高算法的局部尋優(yōu)效果。
1 粒子濾波算法的基本原理
考慮一個(gè)非線性的離散系統(tǒng),其狀態(tài)方程和測(cè)量方程為
(1)
式中:xk∈Rnx為k時(shí)刻輸出的系統(tǒng)狀態(tài)向量,nx為向量x的維度;yk∈Rny為k時(shí)刻輸出的系統(tǒng)測(cè)量向量,ny為向量y的維度;f(·)為系統(tǒng)的狀態(tài)轉(zhuǎn)移函數(shù);h(·)為系統(tǒng)的測(cè)量函數(shù);Ek為k時(shí)刻的過程噪聲,方差為Q;vk為k時(shí)刻的測(cè)量噪聲,方差為R。
假設(shè)初始狀態(tài)概率密度為p(x0|y0)=p(x0),且xk與yk-1彼此相互獨(dú)立,可由p(xk-1|y1:k-1)預(yù)測(cè)下一時(shí)刻的先驗(yàn)概率密度p(xk|y1:k-1):
p(xk,xk-1|y1:k-1)=p(xk|xk-1)p(xk-1|y1:k-1)
(2)
式(2)兩端同時(shí)對(duì)xk-1求積分,得到:
(3)
在得到k時(shí)刻的測(cè)量值yk后,對(duì)先驗(yàn)概率密度進(jìn)行更新,得到后驗(yàn)概率密度分布:
(4)
(5)
一般式(5)難以得到解析解,但可根據(jù)大數(shù)定理從建議分布中采樣足夠多的粒子,計(jì)算相對(duì)權(quán)重以逼近后驗(yàn)分布,通過加權(quán)計(jì)算求得估計(jì)值:
(6)
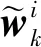
q(x0:k|y1:k)=
q(xk|x0:k-1,y1:k)q(x0:k-1|y1:k-1)
(7)
結(jié)合式(4)與式(7),粒子的重要性權(quán)重可按如下方式遞推:
(8)
將歸一化后的wk代入式(6)即可求得濾波后的估計(jì)值。已有研究表明,隨著時(shí)間的推移,粒子間權(quán)重方差將逐漸增大,少數(shù)粒子具有極高的權(quán)重,大多數(shù)粒子的權(quán)重較小,大量的計(jì)算浪費(fèi)在無效粒子之上,造成粒子退化,顯著降低粒子濾波的估計(jì)效率[13-14]。一般有效粒子數(shù)的近似算式為
(9)
傳統(tǒng)的重要性重采樣(SIR)通過復(fù)制高權(quán)重粒子,拋棄低權(quán)重粒子,在一定程度上減輕了粒子退化,但重采樣后所得的粒子分布只能反映少部分高權(quán)重的似然區(qū)域,后驗(yàn)分布無法被粒子完全覆蓋,造成了粒子貧化問題,而且在測(cè)試誤差較小時(shí),粒子貧化問題更加明顯[15]。傳統(tǒng)重采樣過程如圖1所示,隨機(jī)變量x的先驗(yàn)p(x)與后驗(yàn)分布函數(shù)q(x)如圖1所示,粒子大小反映了粒子的權(quán)重。采樣后雖然保留了優(yōu)質(zhì)粒子,但采樣后粒子集的多樣性嚴(yán)重降低。
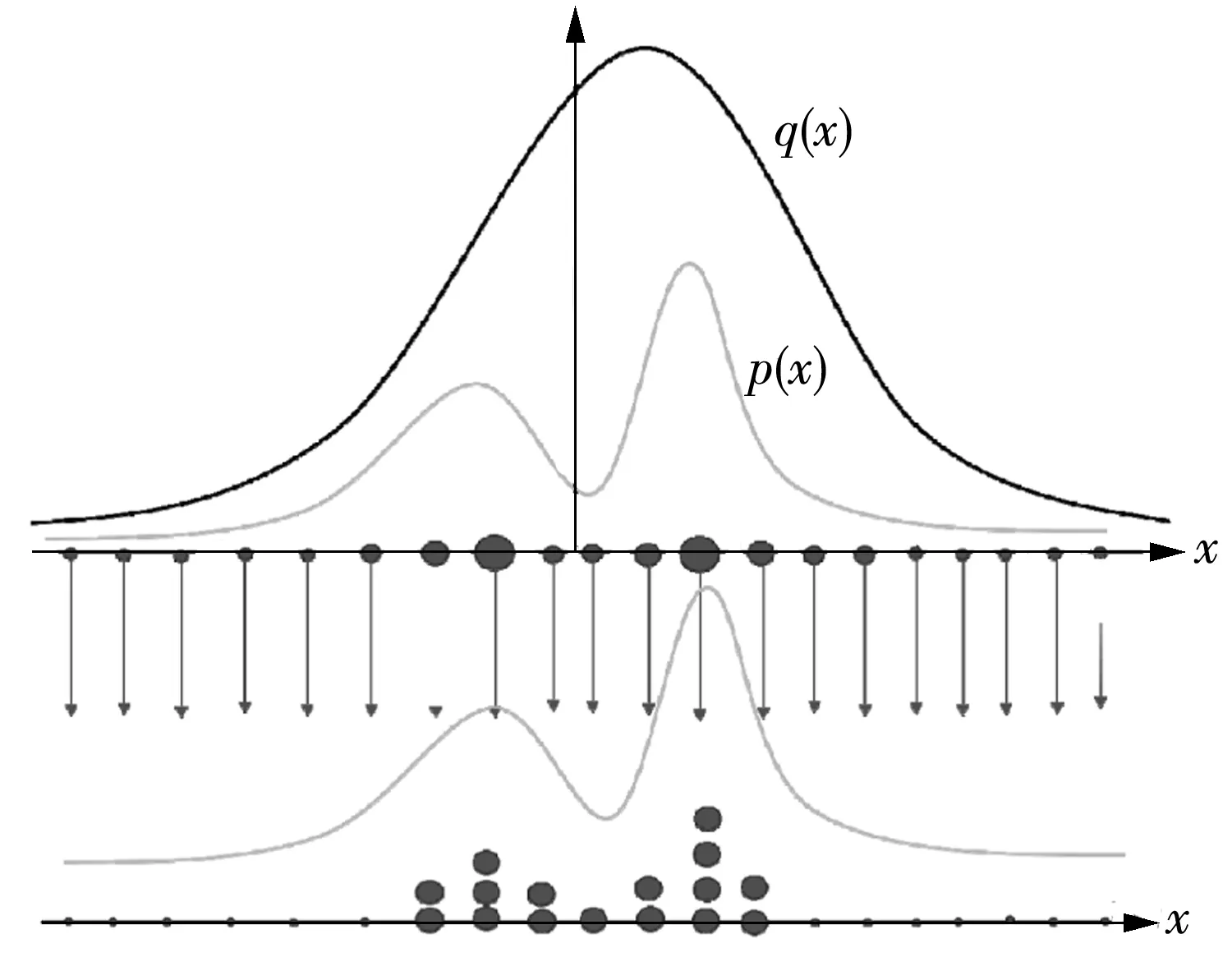
圖1 傳統(tǒng)重采樣導(dǎo)致粒子貧化圖解Fig.1 Illustration of the particle impoverishment problem caused by the traditional resampling
2 標(biāo)準(zhǔn)布谷鳥搜索算法
CS算法是一種元啟發(fā)式算法,將種群數(shù)量為N的布谷鳥群作為D維空間內(nèi)的N個(gè)可行解,將求解過程具體為布谷鳥的產(chǎn)卵過程[16-17]。為了使布谷鳥的尋優(yōu)行為適應(yīng)計(jì)算機(jī)算法,標(biāo)準(zhǔn)CS算法中設(shè)置了3個(gè)理想化規(guī)則:
(1)每只布谷鳥每次只產(chǎn)一個(gè)卵,并且隨機(jī)放置在某個(gè)巢中;
(2)優(yōu)質(zhì)鳥巢的位置會(huì)傳遞給下一代;
(3)在搜索過程中,宿主數(shù)量是一個(gè)常數(shù),每個(gè)鳥蛋有pa∈(0,1)的概率被宿主發(fā)現(xiàn)而被丟棄或放棄當(dāng)前鳥巢,同時(shí)隨機(jī)從種群中生成另一個(gè)新的鳥巢或鳥蛋。
在初始化隨機(jī)位置之后,通過Levy飛行確定下一代鳥巢的隨機(jī)位置:
(10)
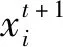
(11)
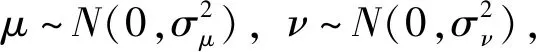
(12)
在每次Levy飛行完畢之后保存偏好的隨機(jī)游走,通過概率pa與隨機(jī)數(shù)r的比較隨機(jī)拋棄部分鳥巢,并生成替代鳥巢,替代鳥巢的位置為
(13)
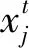
3 混合多策略優(yōu)化的粒子濾波
鑒于元啟發(fā)式算法與粒子濾波的相似性,可將兩者結(jié)合以提高估計(jì)精度。但Levy飛行策略的搜索能力較強(qiáng)[18],粒子運(yùn)動(dòng)范圍較大,粒子容易陷入錯(cuò)誤的似然峰,導(dǎo)致濾波值發(fā)散,所以需要進(jìn)行適當(dāng)?shù)母倪M(jìn),基于混合多策略優(yōu)化的粒子濾波算法的具體步驟如下:
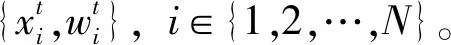
(3)通過Levy飛行將粒子導(dǎo)向高似然區(qū)域后,采用DE算法將剩余無效粒子與高權(quán)重粒子交叉,最后得到較為完整的后驗(yàn)分布。
(4)進(jìn)化期間采用SH策略保留每次進(jìn)化成功的解的各項(xiàng)參數(shù),并進(jìn)行算術(shù)平均,保留更優(yōu)的運(yùn)動(dòng)趨勢(shì)。
3.1 Levy優(yōu)化算法
在接收XH、XM、XL后,XH的位置保持不變,通過Levy飛行策略生成新的低權(quán)重粒子集,粒子的權(quán)重通過適應(yīng)度值來表示,適應(yīng)度函數(shù)定義為
(14)
式中,Zk為濾波器的觀測(cè)值,Znew(i)為將第i(i∈{1,2,…,NL})個(gè)經(jīng)過Levy飛行后的低權(quán)重粒子代入測(cè)量方程h(·)求得的估計(jì)測(cè)量值,Rk為第k次觀測(cè)的誤差。
Levy優(yōu)化算法的偽代碼如下:
LevyOptimalAlgorithm
{inputXH,XL,NL,μα,R,the value of measurementZ.
begin
SA=?;
fori=1 toNL
α(i)=randni(μα,σα);
Generate experimental particlesU(i) according to formulas (10) ,(11) and (12).
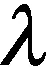
Constrain the particle’s range of motion.
end for
Calculate the weight ofXLbefore optimizationwpre(i) and the weight after optimizationwnow(i).
fori=1 toNL
ifwnow(i)≥wpre(i)
XL(i)=U(i);
SA=[SA,α(i)];∥save more suitable parameters
end if
end for
X=[XH,XL];
outputXandSA;}
3.2 差分進(jìn)化算法
在搜索前期,通過Levy飛行策略確定樣本集框架之后,采用DE算法對(duì)XL集進(jìn)行精細(xì)化處理。DE算法原理與遺傳算法類似,通過個(gè)體間交叉與變異操作提高樣本多樣性[19-22]。
首先,粒子集進(jìn)行變異,生成相同數(shù)量的變異粒子,其變異算子定義如下:
(15)

(16)
其中j∈{1,2,…,d},d是每個(gè)粒子的維度,r是服從[0,1]之間均勻分布的偽隨機(jī)數(shù),jrand∈{1,2,…,d}是其中的一個(gè)隨機(jī)數(shù),C是交叉概率。
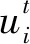
差分進(jìn)化算法的偽代碼如下:
DifferentialEvolutionOptimalAlgorithm
{inputXH,XM,XL,NM,N,μF,μC
begin
SF=?;SC=?;
fori=1 toNdo
r1=select from [1,NM] randomly;
r2,r3=select from [1,N] randomly,r2≠r3;
F(i)=randni(μF,σF);
C(i)=randni(μC,σC);
Generate mutation particlesV(i) according to formula (11).
V(i)=XM(r1)+F(i)[X(r2)-X(r3)];
Generate experimental particlesU(i) according to formula (12).
fori=1 toDdo
jrand=select from [1,D];
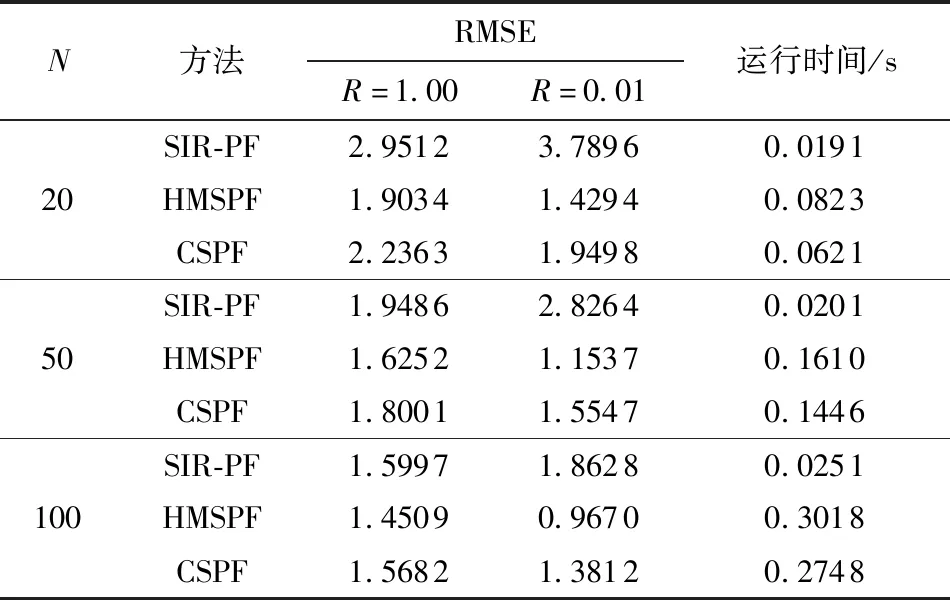
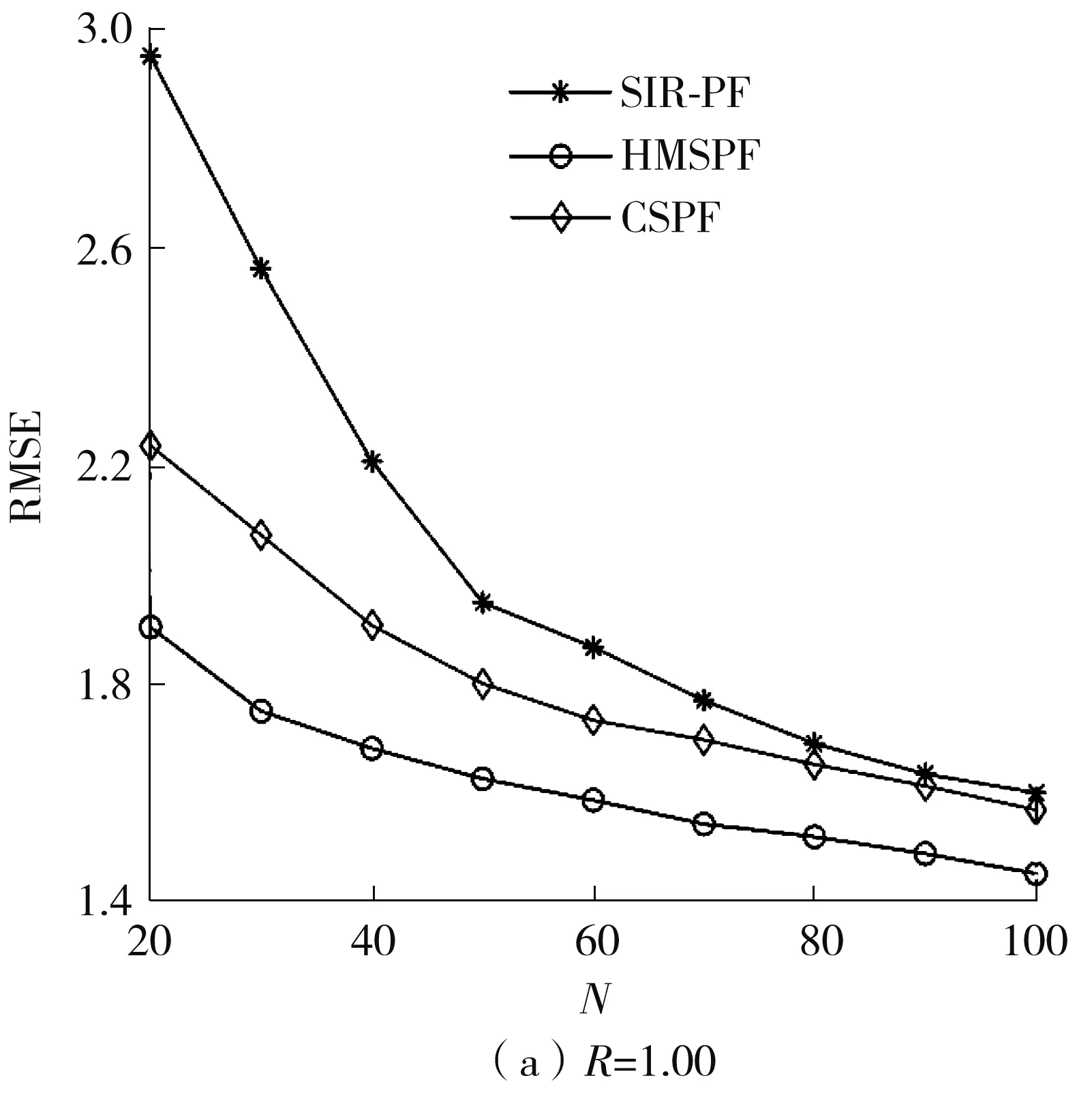
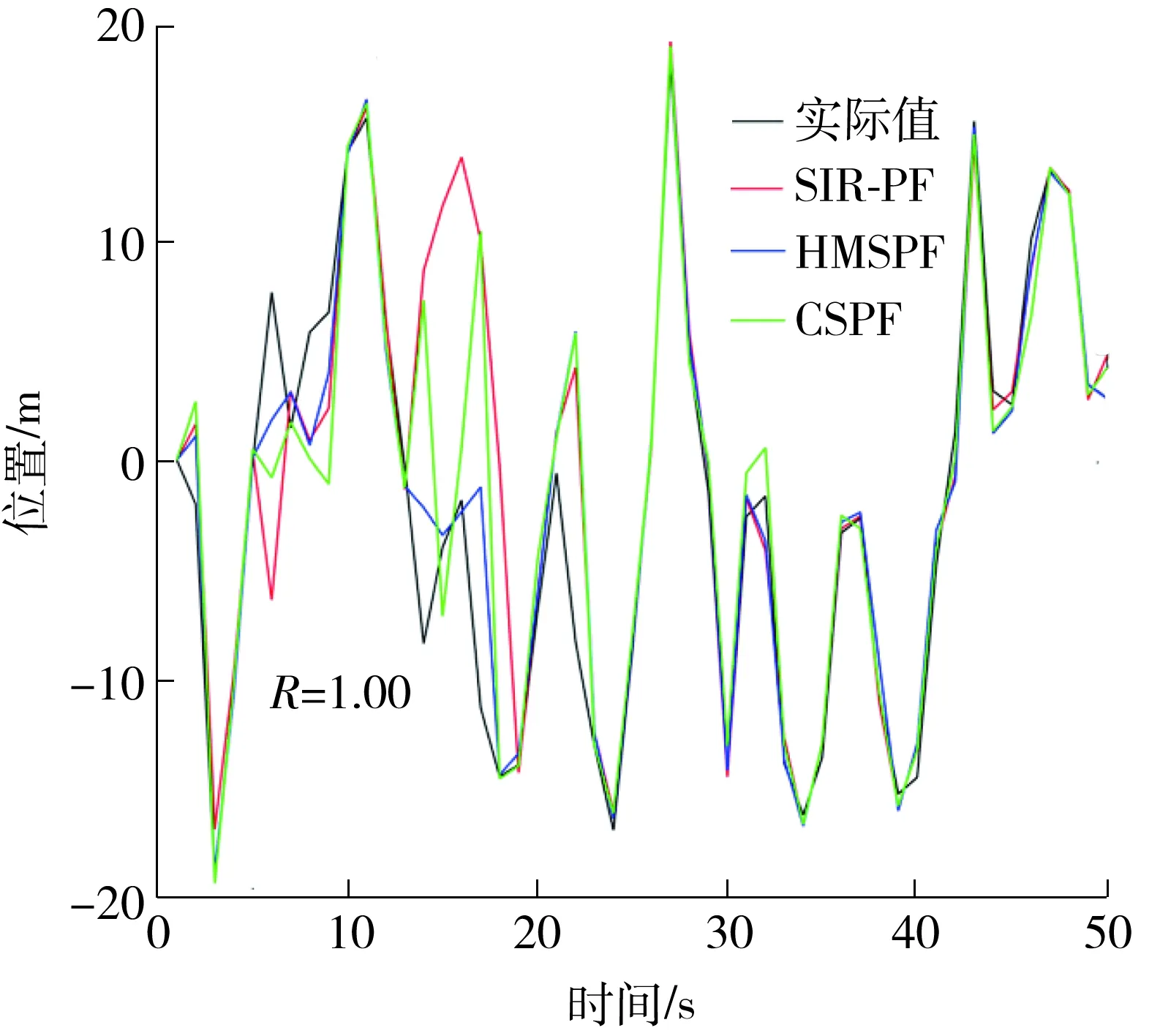
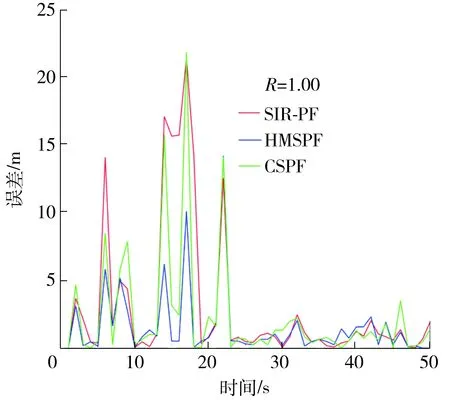
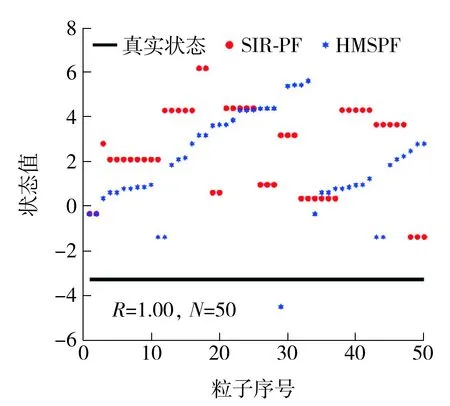
ifj=jrandor rand(0,1) Uj,i,g=Vj,i,g else Uj,i,g=Vj,i,g end if end for end for Sort experimental particles’sUin descending order by weight,take the firstNLparticles to replace the low-weight particles of particles before optimization. Xrank=sort(U,descend); X=[XH,XM,Xrank(1:NL)]; Calculate the weight ofXbefore optimizationwpre(i) and the weight after optimizationwnow(i). fori=1 toN ifwpre(i)≥wnow(i) SF=[SF,F(i)]; SC=[SC,C(i)]; end if end for outputXandSF,SC;} 在一維條件下,當(dāng)時(shí)間序列K=3時(shí),單獨(dú)采用CSPF算法與HMSPF算法優(yōu)化前后的粒子集分布比較如圖2所示。從圖中可知:原始的粒子分布包含大量的無效粒子,通過CS算法優(yōu)化后無效粒子數(shù)減少,靠近右側(cè)真實(shí)似然峰下的粒子數(shù)增多,但有部分粒子集中在錯(cuò)誤的似然峰附近,這是Levy飛行搜索范圍較大造成的“過優(yōu)化”;HSMPF在粒子未達(dá)到過優(yōu)化時(shí),采用DE策略將低權(quán)重粒子與中權(quán)重粒子進(jìn)行變異與交叉操作,使剩余的無效粒子向正確的似然峰轉(zhuǎn)移,從而避免過優(yōu)化。 圖2 CSPF和HMSPF算法優(yōu)化前后的粒子分布對(duì)比Fig.2 Comparison of particle distribution before and after optimization by CSPF and HMSPF algorithms 由于搜索范圍受步長參數(shù)的控制,在狀態(tài)誤差與測(cè)量誤差較小或參數(shù)本身不適合系統(tǒng)方程時(shí),需動(dòng)態(tài)調(diào)節(jié)搜索過程中各參數(shù)的大小[12,23-24]。 經(jīng)前面兩個(gè)策略優(yōu)化完畢,保留更優(yōu)粒子時(shí),將更優(yōu)參數(shù)保留于SA、SF、SC中,并傳遞至下一代。在參數(shù)自適應(yīng)調(diào)整的過程中,大部分粒子在自身周邊尋優(yōu),但存在少數(shù)由于步長跨度較大而成為優(yōu)質(zhì)粒子的劣質(zhì)粒子,這種粒子數(shù)量一般較少而且參數(shù)變化大,無法反映樣本整個(gè)群體的變化趨勢(shì)。 記錄每個(gè)參數(shù)集中參數(shù)的個(gè)數(shù)Npar,為其中的每個(gè)參數(shù)分配平均權(quán)重wpar=1/Npar;將集合中的所有參數(shù)降序排列,并計(jì)算其累計(jì)概率密度CDFi(i=1,2,…,Npar),之后通過輪盤賭選擇法隨機(jī)從中復(fù)制Npar個(gè)鏡像參數(shù)值,再求鏡像參數(shù)的平均值,得到與各參數(shù)相關(guān)聯(lián)的自適應(yīng)參數(shù)μ。 由上可見,符合整體運(yùn)動(dòng)趨勢(shì)的參數(shù)會(huì)占據(jù)較大的賭盤范圍,所得的鏡像參數(shù)值可以較好地反映整個(gè)群體的運(yùn)動(dòng)趨勢(shì)。 αi=randni(μα,σα) (17) Fi=randni(μF,σF) (18) Ci=randni(μC,0.1) (19) 其中randni(μ,σ)表示求期望為μ、方差為σ的正態(tài)分布隨機(jī)數(shù)。文獻(xiàn)[12]通過求服從柯西分布的隨機(jī)數(shù)得到Fi,由于柯西分布為與Levy分布類似的長尾分布,為避免Fi被分配到長尾末端使粒子運(yùn)動(dòng)范圍過大以致最后貼近錯(cuò)誤似然峰,本文將以上三者調(diào)整為正態(tài)分布。基于成功歷史的自適應(yīng)參數(shù)優(yōu)化算法的偽代碼如下: SH-Algorithm {Assign weight to parameters based on the number of parament. Calculate the cumulative density if distribution CDF. fori=1 toNpar r=rand; forj=1 toNpar ifr Snew(i)=S(j); end if end for end for μ=mean(Snew);} HMSPF算法整體流程如下:通過狀態(tài)方程得到粒子的先驗(yàn)估計(jì)后,將所得粒子集與權(quán)重集傳入優(yōu)化函數(shù);在前M代,通過Levy飛行策略生成優(yōu)化后的粒子集,之后通過DE算法生成優(yōu)化后的粒子集。HMSPF算法的偽代碼如下: HMSPF-Algorithm forg=1 toG SetμF,μC,eff; GenerateXH,XM,XLaccording toeff; ifg≤M [X,SA]=LevyOptimalAlgorithm; else [X,SF,SC]=DifferentialEvolutionOptimalAlgorithm; end if Updateμα,μF,μCaccording to SH-Algorithm; Calculate the weight of the new particles and normalize it; end for} 3.5.1 算法收斂性分析 對(duì)于優(yōu)化問題(A,),第k次算法計(jì)算結(jié)果為xk,其中A為可行解空間,為適應(yīng)度目標(biāo)函數(shù),由Lebesgue測(cè)度的下確界可以確定最優(yōu)區(qū)域[25]: (20) 式中,D為充分大的正數(shù),如果算法找到Rbest中的一個(gè)解,則表示算法可找到最優(yōu)值。 設(shè)HMSPF的搜索空間為S,S的Lebesgue測(cè)度顯然是大于0的,即l[S]>0。同樣地,由最優(yōu)解空間定位可知,l[Rbest]>0,且有 (21) 式中,uk(·)為第k次尋優(yōu)時(shí)轉(zhuǎn)移到最優(yōu)集上的概率測(cè)度。由隨機(jī)算法收斂準(zhǔn)則[26]可知,在迭代時(shí)間趨于無窮時(shí),有 (22) 式(22)表示:經(jīng)過一定的迭代次數(shù)之后,樣本集中必然會(huì)有粒子飛入最優(yōu)區(qū)域Rbest中,由于采用精英保留策略,在以后的迭代過程中所有粒子都向最優(yōu)靠攏,最終收斂于最優(yōu)區(qū)域內(nèi),從而實(shí)現(xiàn)全局收斂。 但需要考慮的是,如果算法在每一時(shí)刻的估計(jì)中都實(shí)現(xiàn)了最終收斂,那么粒子集中的所有粒子會(huì)集中在高似然區(qū)域內(nèi)少數(shù)幾個(gè)狀態(tài)值之上,這會(huì)顯著降低樣本多樣性,影響濾波精度,而且最終收斂是以設(shè)置較長迭代次數(shù)為代價(jià)的,這將影響算法的實(shí)時(shí)性。因此,本文采取設(shè)置較少的迭代次數(shù)與差分算法精細(xì)化的方式,使樣本集中的粒子向高似然區(qū)域靠攏,但不會(huì)達(dá)到全局收斂,從而確保算法兼具精度與速度的優(yōu)勢(shì)。 3.5.2 算法時(shí)間復(fù)雜度分析 與標(biāo)準(zhǔn)粒子濾波相比,HMSPF算法加入了自適應(yīng)尋優(yōu)過程,其運(yùn)算復(fù)雜度分析如下: (1)在第一階段,即前M代采用Levy飛行策略,則執(zhí)行適應(yīng)度函數(shù)所消耗的時(shí)間為T(n),n為粒子的維度,粒子數(shù)為N。設(shè)一個(gè)維度轉(zhuǎn)移所消耗的時(shí)間為T1,新解與舊解的比較和替換的執(zhí)行時(shí)間分別為T2和T3,則選擇過程的時(shí)間復(fù)雜度為O(N(T1n+T(n)+T2+T3n)),所以第一階段的時(shí)間復(fù)雜度為MO(N(T1n+T2+T3n+T(n)))。 (2)在第二階段,設(shè)差分進(jìn)化算法每次交叉操作的執(zhí)行時(shí)間為T4,一次變異操作的執(zhí)行時(shí)間為T5,新解與舊解的比較和替換的執(zhí)行時(shí)間與第一階段一致,G為迭代次數(shù),則第二階段的時(shí)間復(fù)雜度為(G-M)O(N(T4n+T5n+T2+T3n+T(n)))。 此外,每一次更優(yōu)參數(shù)的保留都需要逐次比較,假設(shè)在最極端的情況下,有N個(gè)更優(yōu)參數(shù),則所消耗的時(shí)間最大為GO(N2),故在一次估計(jì)中,HMSPF算法的時(shí)間復(fù)雜度最大為MO(NT1n)+(G-M)O(Nn(T4+T5))+GO(N(T2+T3+T(n)))+GO(N2)。 標(biāo)準(zhǔn)濾波算法的時(shí)間復(fù)雜度為GO(N2)+GO(N(T2+T3+T(n))),所以本文算法相對(duì)于標(biāo)準(zhǔn)粒子濾波算法增加的時(shí)間復(fù)雜度最高為MO(NT1n)+(G-M)O(Nn(T4+T5))。綜上分析,與標(biāo)準(zhǔn)粒子濾波算法相比,HMSPF算法的計(jì)算耗時(shí)略有增加,其主要體現(xiàn)在各策略中粒子的轉(zhuǎn)移、交叉與變異之上,在實(shí)際應(yīng)用中可通過設(shè)置更少的粒子數(shù)來彌補(bǔ)。 為了對(duì)所提出的HMSPF算法進(jìn)行性能評(píng)估,采用一維單變量增長模型的一維目標(biāo)跟蹤問題[27]對(duì)算法進(jìn)行性能測(cè)試,實(shí)驗(yàn)采用的一維目標(biāo)跟蹤問題如式(23)、(24)所示,該問題具有高度非線性、多似然峰和非平穩(wěn)性,被廣泛用于評(píng)估估計(jì)方法的性能。 (23) (24) (25) 仿真過程中各參數(shù)設(shè)置如下:μα=0.6,μF=μC=0.3,G=4,M=2。當(dāng)Q=1,粒子數(shù)N為20、50、100時(shí)的仿真結(jié)果如圖3、圖4所示。3種重采樣算法的RMSE隨粒子數(shù)的變化以及運(yùn)行時(shí)間比較如圖5和表1所示。 由圖3、圖4可知,相比于SIR-PF,CSPF與HMSPF有更高的估計(jì)精度,因?yàn)镾IR-PF單純對(duì)似然區(qū)域內(nèi)的高權(quán)重粒子進(jìn)行復(fù)制,對(duì)于多峰問題,有可能復(fù)制錯(cuò)誤似然峰下的粒子,從而對(duì)后續(xù)幾個(gè)時(shí)間序列造成影響,而CSPF與HMSPF保留了高權(quán)重粒子的框架,只對(duì)低權(quán)重的無效粒子進(jìn)行優(yōu)化,同時(shí)算法的自身尋優(yōu)性也使粒子有一定的幾率從錯(cuò)誤的似然峰移動(dòng)到正確的似然峰。 由圖5與表1中可知,在標(biāo)準(zhǔn)測(cè)量噪聲下,隨著粒子數(shù)的增加,CSPF的估計(jì)精度增長的幅度下降,因?yàn)殡S著粒子數(shù)的增加,粒子覆蓋的空間范圍增大,落入錯(cuò)誤峰之下的粒子數(shù)也隨之增加,產(chǎn)生“過優(yōu)化”,對(duì)估計(jì)精度造成一定的影響。 表1 3種重采樣算法的性能對(duì)比Table 1 Comparison of performance among three resampling algorithms 圖5 粒子數(shù)對(duì)RMSE的影響(Q=1)Fig.5 Effect of particle amount on RMSE(Q=1) 在測(cè)量噪聲較小時(shí),SIR-PF的粒子退化明顯,似然峰的范圍與測(cè)量噪聲有關(guān),測(cè)量噪聲越大,似然峰越大;測(cè)量噪聲越小,似然峰越小。越靠近似然峰的粒子,其權(quán)重可能會(huì)特別高,造成重采樣后的粒子種類較為單一。CSPF與HMSPF由于其搜索能力,粒子位置可自由變動(dòng),粒子本身有更好的主動(dòng)性。但CSPF的參數(shù)缺少動(dòng)態(tài)調(diào)節(jié),在似然峰較小時(shí),粒子在尋優(yōu)過程中可能會(huì)跳過似然區(qū)域的位置,搜索后期易陷入局部最優(yōu)。HMSPF參數(shù)的自適應(yīng)調(diào)節(jié),使樣本集向更優(yōu)的方向進(jìn)化,同時(shí)差分進(jìn)化算法可使濾波結(jié)果更加精細(xì)化。 (a)N=20 為比較SIR-PF算法與HMSPF算法在不同測(cè)量誤差下重采樣后粒子的多樣性,取不同的N、R和時(shí)間步長K進(jìn)行實(shí)驗(yàn),粒子空間狀態(tài)分布圖如圖6所示。從圖中可知,與傳統(tǒng)重采樣的粒子濾波相比,HMSPF在狀態(tài)空間內(nèi)具有更廣泛的粒子分布,優(yōu)化函數(shù)將低權(quán)重粒子向高權(quán)重粒子轉(zhuǎn)移,所以粒子相對(duì)均勻地分布于真實(shí)值的兩側(cè),可以更好地覆蓋后驗(yàn)分布。而SIR-PF的估計(jì)精度依賴于復(fù)制高權(quán)重粒子,在測(cè)量誤差較小時(shí),由于似然峰較窄,不一定有粒子分布在附近,傳統(tǒng)采樣方法只能復(fù)制相對(duì)靠近似然峰的粒子,粒子缺乏主動(dòng)性,所以在較小的測(cè)量誤差下傳統(tǒng)的重采樣方法發(fā)生高風(fēng)險(xiǎn)錯(cuò)誤估計(jì)的可能性更大。HMSPF中的主動(dòng)尋優(yōu)機(jī)制與成功歷史策略使粒子有目的地向似然峰移動(dòng),可有效緩解此類問題。 (a)N=20 本文通過分析傳統(tǒng)SIR-PF與CSPF的局限性,提出了一種混合多策略優(yōu)化的粒子濾波算法,該算法兼具全局與局部搜索能力,相比SIR-PF與CSPF在估計(jì)精度上具有更大的優(yōu)勢(shì),并且可以緩解粒子貧化問題。實(shí)驗(yàn)結(jié)果表明,本文算法有效地改善了樣本集的整體質(zhì)量,提高了樣本集的多樣性,綜合能力相對(duì)SIR-PF與CSPF更優(yōu)。 由于本文算法內(nèi)置了參數(shù)調(diào)整,故算法的計(jì)算時(shí)間會(huì)稍有增加,在保證所需估計(jì)精度前提下,可通過適當(dāng)減小粒子數(shù)來處理此類問題,未來將考慮改進(jìn)重采樣算法并應(yīng)用于組合導(dǎo)航,以實(shí)現(xiàn)高精度的位置估計(jì),鑒于應(yīng)用環(huán)境的復(fù)雜性不同,在應(yīng)用過程中,可根據(jù)實(shí)際情況對(duì)算法參數(shù)進(jìn)行調(diào)整。 (a)k=3,Q=1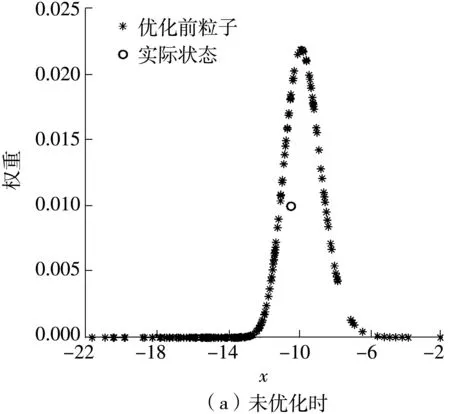
3.3 基于成功歷史的自適應(yīng)參數(shù)優(yōu)化
3.4 粒子濾波算法總體流程
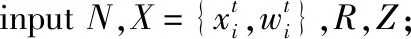
3.5 HMSPF算法性能分析
4 仿真實(shí)驗(yàn)及結(jié)果分析
5 結(jié)論
 猜你喜歡
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52教學(xué)考試(高考化學(xué))(2021年2期)2021-05-30 06:15:52中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年12期)2021-03-08 01:28:50中學(xué)生數(shù)理化·高一版(2020年3期)2020-04-21 08:03:20中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50小學(xué)生作文(低年級(jí)適用)(2019年9期)2019-10-08 08:37:10數(shù)學(xué)大世界(2018年1期)2018-04-12 05:39:14
猜你喜歡
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52教學(xué)考試(高考化學(xué))(2021年2期)2021-05-30 06:15:52中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年12期)2021-03-08 01:28:50中學(xué)生數(shù)理化·高一版(2020年3期)2020-04-21 08:03:20中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50小學(xué)生作文(低年級(jí)適用)(2019年9期)2019-10-08 08:37:10數(shù)學(xué)大世界(2018年1期)2018-04-12 05:39:14
