特征域多假設預測視頻壓縮感知重構神經(jīng)網(wǎng)絡
2022-07-08 03:26:28楊春玲凌茜呂澤宇
華南理工大學學報(自然科學版) 2022年6期
楊春玲 凌茜 呂澤宇
(華南理工大學 電子與信息學院,廣東 廣州 510640)
為了解決視頻壓縮編碼方法(如H.264、MPEG等)編碼端復雜、耗時長、難以適用于采樣資源受限的應用場景的問題,文獻[1-2]提出了壓縮感知理論,實現(xiàn)了信號采樣與壓縮過程的合并,大大節(jié)省了采樣成本。
視頻壓縮感知(CVS)重構算法是視頻壓縮感知研究的核心任務之一。在視頻壓縮感知重構中,運動估計/補償是提升圖像質(zhì)量的關鍵技術。多假設預測算法作為優(yōu)秀的運動估計/補償方案,在視頻壓縮感知重構中取得了較好的效果。文獻[3-4]基于多假設預測-殘差重構框架提出了多假設視頻壓縮感知重構算法MHR,通過加權組合多個塊的信息來實現(xiàn)當前幀的多假設預測。在此過程中,假設集構造以及假設權重求解是兩個關鍵的問題。為了優(yōu)化假設集的構成,文獻[5]在多個候選幀中選擇最優(yōu)參考幀進行多假設預測;文獻[6]在多個參考幀中選取指定數(shù)量的高相似度假設塊進行預測,避免了無關塊在預測過程中引入的噪聲;文獻[7]提出了多參考幀的兩階段多假設重構算法2sMHR,在觀測域多假設重構的基礎上進行第二階段圖像域重疊分塊多假設,提高了匹配塊的整體質(zhì)量。為了提高假設塊權值的求解精度,文獻[8]引入了彈性網(wǎng)模型;文獻[9]則在彈性網(wǎng)模型基礎上對l2范數(shù)正則化項進行權值調(diào)整。多假設視頻壓縮感知重構算法深入挖掘了視頻信號的時間相關性,獲得了較好的重構質(zhì)量,但其重構過程中存在迭代優(yōu)化繁瑣、算法復雜度較高等問題。
近年來,研究人員結合視頻壓縮感知理論與深度學習方法[10],提出了一些優(yōu)秀的視頻壓縮感知重構神經(jīng)網(wǎng)絡,在提升重構質(zhì)量的同時,緩解了傳統(tǒng)視頻壓縮感知重構算法耗時長的問題,有良好的研究與應用前景。文獻[11]首次提出了端到端深度學習視頻壓縮感知重構算法CSVideoNet,通過合成估計長短期記憶網(wǎng)絡將關鍵幀的信息傳遞至非關鍵幀,然而該算法存在像素空間相關性建模效果差、訓練難度大的問題。文獻[12]提出了VCSNet,利用關鍵幀的多級特征對非關鍵幀進行補償,然而基于2維卷積的神經(jīng)網(wǎng)絡難以挖掘視頻信號準確的運動信息。CSVideoNet與VCSNet延續(xù)了神經(jīng)網(wǎng)絡低延時的特征,但在一定程度上忽視了傳統(tǒng)算法明晰的理論基礎,無法實現(xiàn)高質(zhì)量的運動估計與補償。為了解決該問題,文獻[13]提出了基于對齊預測與殘差重構的視頻壓縮感知重構算法(PRCVSNet),該算法從傳統(tǒng)多假設理論出發(fā),利用時域可變形卷積對齊網(wǎng)絡(TDAN)與殘差重構網(wǎng)絡實現(xiàn)了特征域多假設預測與殘差重構,取得了優(yōu)秀的重構性能。為了選擇合適的參考幀構造最優(yōu)假設集,文獻[14]對PRCVSNet進行改進,設計了兩階段串聯(lián)的多假設運動補償,以及基于此的視頻壓縮感知重構算法(2sMHNet),進一步提升了重構質(zhì)量。PRCVSNet與2sMHNet的重構性能表明,傳統(tǒng)壓縮感知重構算法理論對神經(jīng)網(wǎng)絡的設計具有巨大的參考意義,在保證理論可解釋性的同時實現(xiàn)了高質(zhì)量快速重構。
PRCVSNet與2sMHNet可有效挖掘視頻信號的時間相關性,但仍然存在一定的不足:①運動估計子網(wǎng)絡過于淺層,難以準確地找到最優(yōu)假設集;②僅采用尺寸為3×3的卷積核實現(xiàn)多假設加權求和過程,假設集容量過小導致圖像中一些相關信息被忽略;③利用卷積核參數(shù)作為假設集權重,這些參數(shù)在訓練結束后即被固定,無法針對不同假設集特征自適應地求解加權系數(shù);④2sMHNet采用兩階段串行式重構模式,對于運動較慢的序列,在第二階段選擇相鄰幀作為參考幀并非為最優(yōu)方案。為了解決以上問題,本研究提出了新的特征域多假設預測模塊(FMH_Module)與兩階段多參考幀運動補償模式,以及基于此的視頻壓縮感知重構網(wǎng)絡。FMH_Module通過設計新的運動估計模塊與假設權重求解模塊來提升假設集構造的合理性與假設集權重的求解精度,以增強網(wǎng)絡的預測能力;兩階段多參考幀運動補償模式通過同時將關鍵幀與相鄰幀作為參考,使不同運動特征序列均能合理地構造最優(yōu)假設集,以進一步提升預測精度。
1 多假設理論與深度學習實現(xiàn)算法
1.1 多假設-殘差重構理論
在視頻壓縮感知中,視頻序列被劃分為固定時長的多個圖像組(GOP)以進行分塊采樣,每個GOP的第一幀為關鍵幀,以較高的采樣率rk進行采樣以保留更多的細節(jié)信息,而其余的非關鍵幀則以極低的采樣率rnk進行單幀獨立采樣以降低平均采樣率。由于關鍵幀采樣率較高,因此直接采用圖像重構算法即可獲得高質(zhì)量的重構結果;而對于獨立重構效果較差的非關鍵幀,則利用已重構信息預測當前幀,并在預測的基礎上進行殘差重構。
多假設預測算法借鑒了傳統(tǒng)編解碼框架中的運動補償方案。該算法以圖像塊為基本單位,首先根據(jù)指定的匹配準則在參考幀中尋找L個當前塊的相似塊組成假設集H,并使用觀測矩陣Φ獲得觀測值,然后通過最小化觀測域歐氏距離得到假設塊的對應權重w,即
(1)
最后通過線性組合假設集與假設權重得到當前塊的預測塊xp,即
(2)
殘差重構過程如下:首先計算預測幀xp的觀測值與原始觀測值y的殘差,然后利用重構算法FΦ-1(·)將殘差映射回像素域,與預測幀相加使其逼近原始信號,即
xres=xp+FΦ-1(y-Φxp)
(3)
1.2 基于深度學習的多假設視頻壓縮感知重構算法
傳統(tǒng)多假設重構算法雖然能高效地挖掘視頻時間相關性,但存在時間復雜度過高、塊效應嚴重、預測精度受限等不足。文獻[13-14]為了挖掘幀間相關性,提出了基于深度學習的多假設預測模塊與殘差重構模塊。多假設預測模塊利用時域可變形對齊卷積神經(jīng)網(wǎng)絡[15],在特征域?qū)崿F(xiàn)各像素的多假設預測,在參考幀中取出K個最優(yōu)相似像素構成假設集,然后通過一個卷積實現(xiàn)對假設集的加權求和并輸出預測幀,即
(4)

最后,將預測結果從特征域映射至像素域,得到各像素的多假設預測幀。
殘差重構模塊基于殘差重構理論,通過重構預測幀殘差來進一步提升重構質(zhì)量。另外,文獻[14]為了構造最優(yōu)假設集提出了兩階段運動補償模式,在第一階段利用細節(jié)信息豐富的關鍵幀作為參考幀進行多假設預測,在第二階段利用相關性更強的相鄰幀作為參考幀,充分利用了圖像組幀間相關性。
2 特征域多假設視頻壓縮感知重構神經(jīng)網(wǎng)絡
在多假設預測殘差重構框架中,構造高匹配程度的假設集以及求解高精度的假設集權值是算法研究的重點。針對這兩個方面,本研究基于深度學習強大的學習能力,利用卷積神經(jīng)網(wǎng)絡模擬多假設預測中假設集構造、假設權重求解等過程,提出了一種新的特征域多假設預測視頻壓縮感知重構神經(jīng)網(wǎng)絡FMH_CVSNet,具體包括提出新的特征域多假設預測模塊(FMH_Module)和兩階段多參考幀補償模式與特征域融合網(wǎng)絡。
2.1 FMH_CVSNet算法框架
在重構過程中,首先利用圖像壓縮感知重構算法SPLNet[16]對所有幀進行初始重構,然后利用增強重構子網(wǎng)絡進一步提升非關鍵幀的重構質(zhì)量。
FMH_CVSNet算法框架如圖1所示,增強重構子網(wǎng)絡由兩個階段組成,在第一階段重構中,選擇已重構的關鍵幀作為參考幀,利用FMH_Module實現(xiàn)多假設預測,并通過殘差重構模塊[13-14]進行殘差重構,得到第一階段的重構幀;在第二階段重構中,分兩種情況選擇參考幀實現(xiàn)當前幀的預測。當相鄰幀為非關鍵幀時,將第一階段重構的相鄰幀與關鍵幀同時作為參考幀對當前幀進行多假設預測,并利用本文提出的特征域融合模塊將兩個預測幀進行自適應融合得到最終的預測;當相鄰幀為關鍵幀時,只選擇關鍵幀作為參考幀得到預測。最后利用殘差重構模塊進行重構,得到最后的重構幀。
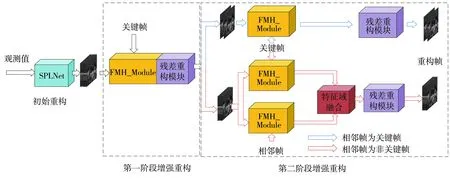
圖1 FMH_CVSNet算法框架Fig.1 Algorithm framework of FMH_CVSNet
2.2 特征域多假設預測模塊
多假設預測-殘差重構框架具有結構簡單、支持理論完善、重構性能好等優(yōu)點。本研究基于多假設理論與信號特征提出了一種新的特征域多假設預測模塊FMH_Module,其網(wǎng)絡結構如圖2所示。
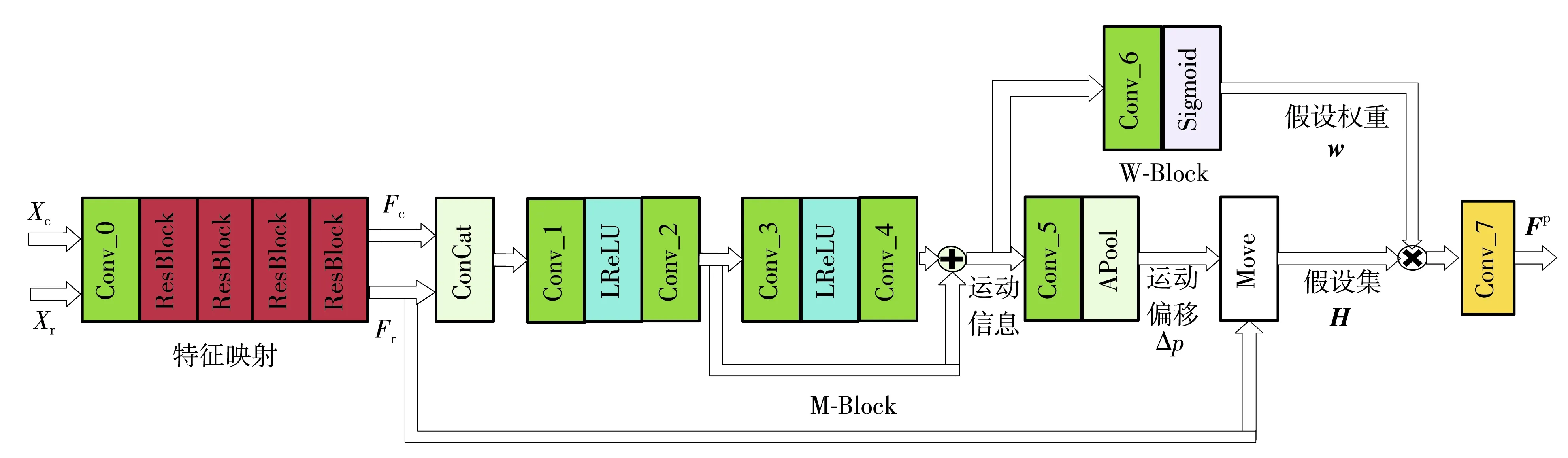
圖2 FMH_Module的網(wǎng)絡結構Fig.2 Network structure of FMH_Module
輸入空間尺寸為H×W×1的待重構幀與參考幀,首先利用d個大小為3×3×1的卷積濾波器(Conv_0)、1個LReLU激活層以及3個殘差學習單元[17](ResBlock,每個ResBlock包括2個大小為3×3×d的卷積層及1個ReLU激活函數(shù))實現(xiàn)幀圖像空間(Xc,Xr)到d維特征空間(Fc,Fr)的映射,此時Fc與Fr的空間尺寸為H×W×d。然后利用本研究設計的運動估計模塊(M-Block)以及假設權重求解模塊(W-Block)分別求得最優(yōu)假設像素的運動偏移矢量及對應的權重。運動估計模塊通常利用堆疊的卷積層來學習輸入特征(Fc,Fr)到最優(yōu)假設像素的運動偏移(Δp)的映射。在此過程中,若卷積網(wǎng)絡過淺,則代表模型僅采用了小范圍的感受野求解匹配信息,與傳統(tǒng)塊匹配運動估計中搜索窗受限的情況類似,難以估計較大的運動。因此,運動估計模塊通過級聯(lián)多個卷積層增加感受野,從而對運動劇烈的視頻構造出高質(zhì)量的假設集。但在處理慢速運動序列時,過大的感受野反而會引入額外的不相關信息,因此運動估計模塊在加深多假設預測網(wǎng)絡的同時,引入了跳躍連接結構,對不同尺寸感受野信息進行融合,使網(wǎng)絡能同時適應運動劇烈程度不同的序列,并在一定程度上可以防止梯度消失[18],更有利于網(wǎng)絡的訓練。如圖2所示,輸入Fc與Fr,在拼接參考幀與當前幀特征空間的通道后,運動估計模塊首先通過2個卷積層和1個LReLU非線性激活層學習小范圍運動信息,在此基礎上為擴大感受野,疊加2個卷積層與1個LReLU激活層,輸出較大范圍的運動信息,然后通過殘差連接將不同感受野下的特征相加,得到較豐富的運動信息。圖2中,Conv_1由d個大小為H×W×2d的卷積濾波器組成,Conv_2、Conv_3、Conv_4由d個大小為3×3×d的卷積濾波器組成。最后,運動估計模塊利用2K個大小為3×3×d的卷積濾波器Conv_5與平均池化操作,輸出K個假設運動偏移Δp(Δp∈RH×W×2K)。利用求得的運動偏移Δp,即可在參考幀對應位置找到對應的假設像素構造假設集H∈RH×W×d×K。
在傳統(tǒng)多假設理論中,當前假設塊與待重構塊的相似程度越高,則該假設塊的權值越大。因此,本研究構造了一個假設權重求解模塊,通過K個核大小為3×3×d的卷積層Conv_6與Sigmoid非線性層來自適應求解各假設像素的權重。在求解過程中,由于運動估計模塊得到的運動偏移Δp僅包含假設集的空間位置信息,而無法表征當前待預測像素與假設像素的相關程度,因此本研究選擇同時包含空間位置信息與相關程度的運動信息作為假設權重求解模塊的輸入。通過該過程,不同待預測像素的每個假設像素都可以針對其信號特征自適應地求解,得到對應的假設權重w∈RH×W×1×K。
假設權重w表征了當前待重構像素對應的多個假設像素的重要性,本研究首先利用其對假設集進行加權:
Hw=wH
(5)
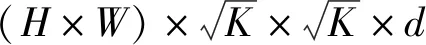
Fp=wc*Hw
(6)
式中,wc為卷積核權重,F(xiàn)p為特征域的預測幀。在此過程中,假設權重卷積w針對不同待重構像素的不同假設集均能自適應計算,但對每個特征通道共享;而卷積權重wc則偏重于表征假設像素不同通道的重要性關系。在具體實驗設置中,本研究為平衡網(wǎng)絡計算量,將特征通道d設置為64,假設集容量K設置為25,以獲取充足的相關像素。
2.3 兩階段多參考幀補償模式與特征域融合網(wǎng)絡
在運動補償過程中,參考幀的選擇取決于兩個因素:幀質(zhì)量q、與待重構幀的相關程度c。視頻壓縮感知在重構質(zhì)量優(yōu)秀的關鍵幀(xk)與相關性較強的相鄰幀(xn)之中選擇參考幀(xr),即
(7)
式中,qk、qn、ck、cn分別為關鍵幀和相鄰幀的質(zhì)量,以及與待重構幀的相關程度。
在本文的兩階段重構框架下,在第一階段的重構中,關鍵幀重構質(zhì)量遠遠高于非關鍵幀的初始重構質(zhì)量,即qk/qn>cn/ck,因此選擇關鍵幀作為參考幀較為合理。第一階段增強重構后,由于非關鍵幀的重構質(zhì)量得到提升,qk/qn減小,相關程度差異cn/ck成為第二階段重構的主要影響因素。在第二階段中,在同一個GOP內(nèi)幀的相關程度與序列的運動特征有關,若序列為快速運動序列,cn/ck較大,則選擇相鄰幀作為參考幀更為合理;反之,若序列為慢速運動序列,則選擇關鍵幀為參考幀更為有效。為了綜合幀質(zhì)量和相關程度對參考幀選擇的影響,同時滿足快速運動序列與慢速運動序列不同的參考幀需求,本研究提出了兩階段多參考幀運動補償模式以及一個自適應特征域融合網(wǎng)絡。
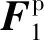

圖3 FMH_CVSNet參考幀的選擇(GOP=8)Fig.3 Reference frame selection of FMH_CVSNet(GOP=8)
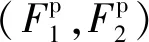
2.4 損失函數(shù)
FMH_CVSNet采用訓練好的SPLNet作為圖像壓縮感知重構網(wǎng)絡,并在此基礎上進一步訓練增強多假設重構網(wǎng)絡以實現(xiàn)幀間時空相關性的有效學習。網(wǎng)絡訓練中目標函數(shù)包括兩部分限制:重構幀和原始幀盡可能接近;重構幀的觀測值和原始觀測值盡可能接近。以均方誤差作為損失函數(shù),這兩個部分的損失目標表示分別為
(8)
(9)
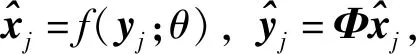
(10)
3 仿真實驗
為驗證FMH_CVSNet的有效性,本文設計了一系列不同條件下的實驗,對FMH_CVSNet進行重構質(zhì)量與算法復雜度的分析,并通過消融實驗分析了網(wǎng)絡中各模塊的性能。在GOP大小為8,關鍵幀采樣率為0.5,非關鍵幀采樣率分別為0.20、0.10、0.05的條件下進行仿真測試實驗。
3.1 網(wǎng)絡訓練
本研究采用與2sMHNet[14]相同的UCF-101數(shù)據(jù)集進行SPLNet的預訓練以及增強多假設重構網(wǎng)絡的訓練。在訓練過程中,SPLNet超參數(shù)設置參考文獻[16],增強多假設重構網(wǎng)絡采用默認超參數(shù)設定下的AdamOptimizer優(yōu)化器,學習率設置為0.000 01。使用PyTorch框架來實現(xiàn)本文的FMH_CVSNet并在NVIDIA 2080Ti進行訓練與測試。
3.2 實驗結果與分析
3.2.1 重構性能與重構視覺效果對比
選取6組CIF格式(354×288)的標準序列Akiyo、Coastguard、Foreman、Mother_daughter、Paris、Silent作為測試序列,將FMH_CVSNet與基于深度學習的視頻壓縮感知重構算法(2種基于幀間多級特征補償?shù)木W(wǎng)絡VCSNet-1[12]、VCSNet-2[12]以及兩種基于可變形卷積的多假設預測重構網(wǎng)絡PRCVSNet[13]、2sMHNet[14])進行了對比,每個序列前兩個GOP在各采樣率下的平均重構峰值信噪比(PSNR)與結構相似性指數(shù)(SSIM)如表1所示。由表中可見:FMH_CVSNet相比于VCSNet-1與VCSNet-2,平均PSNR分別顯著提升了4.30、3.87 dB,平均SSIM分別提升了0.044 6、0.029 1,表明了FMH_CVSNet網(wǎng)絡結構的合理性與有效性,以及結合信號先驗信息與傳統(tǒng)壓縮感知理論來構造神經(jīng)網(wǎng)絡結構的重要性;相比于已有的多假設殘差重構網(wǎng)絡PRCVSNet與2sMHNet,F(xiàn)MH_CVSNet的平均PSNR分別提升了2.96、2.15 dB,平均SSIM分別提升了0.017 1、0.003 7,證明了本研究網(wǎng)絡結構的有效性。
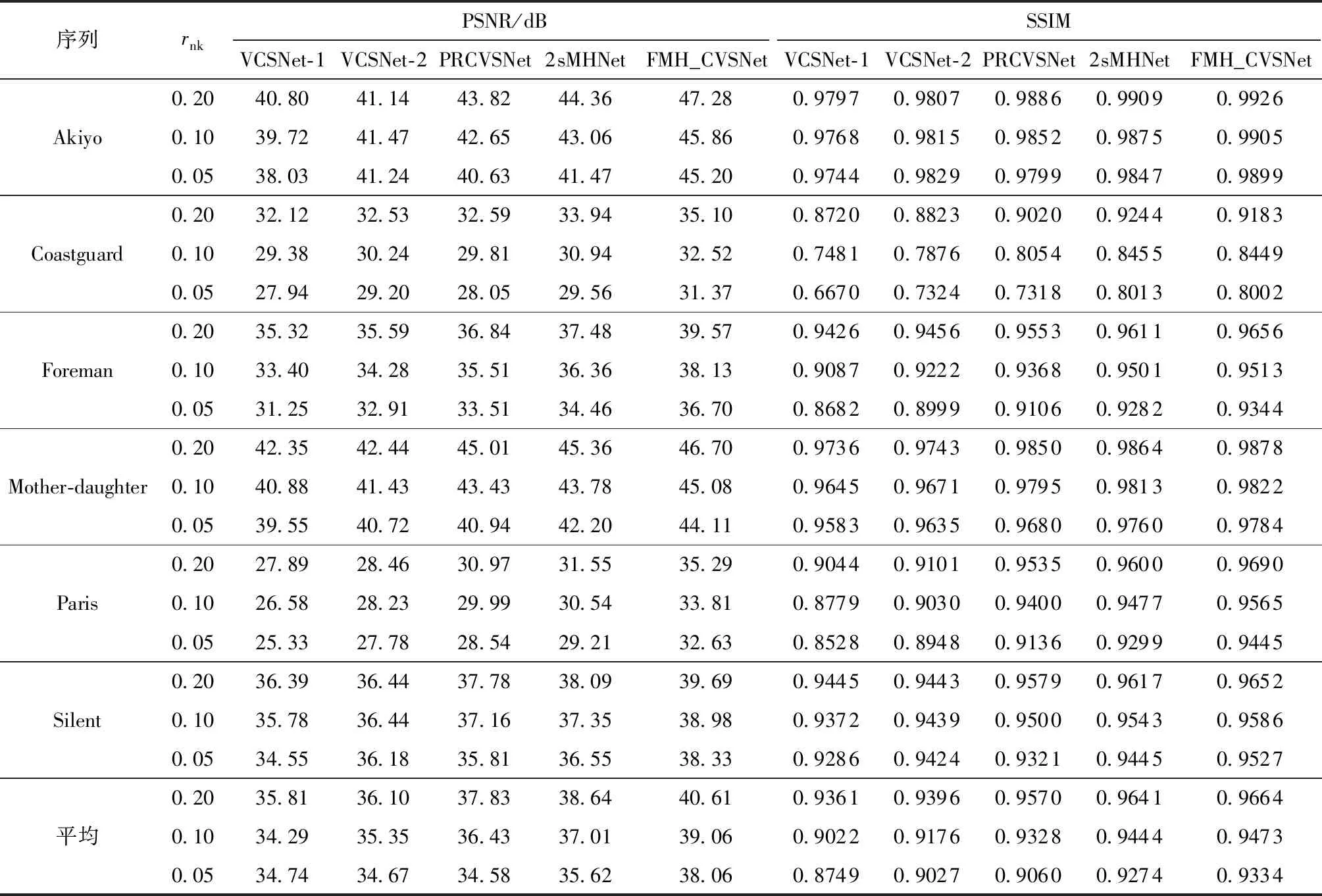
表1 CIF格式下FMH_CVSNet與基于深度學習的CVS重構算法的PSNR與SSIM對比Table 1 Comparison of PSNR and SSIM between FMH_CVSNet and deep learning based CVS reconstruction algorithms in CIF format
以6個QCIF格式(176×144)的標準視頻序列(Soccer、Football、Ice、Foreman、Hall、Suzie)為測試序列,將本文FMH_CVSNet與傳統(tǒng)多假設視頻壓縮感知重構算法(MHR[4]、2sMHR[7])及傳統(tǒng)CVS重構算法SSIM-InterF-GSR[18]進行了對比,6個QCIF格式視頻序列前12個GOP的重構性能對比如表2所示,其中對比算法均使用原作者發(fā)布的代碼進行實現(xiàn)與仿真。由表中可知:FMH_CVSNet相對于傳統(tǒng)算法的性能提升明顯,平均PSNR比MHR、2sMHR分別提升了8.37、4.76 dB,平均SSIM分別提升了0.127 3、0.049 7,證明了深度神經(jīng)網(wǎng)絡的強大學習能力與優(yōu)秀的泛化能力;SSIM-InterF-GSR是目前重構質(zhì)量最好的傳統(tǒng)算法之一,而FMH_CVSNet的性能均優(yōu)于SSIM-InterF-GSR,在3個采樣率下平均PSNR分別提升了2.44、3.50、4.57 dB,平均SSIM分別提升了0.019 6、0.029 7、0.055 4;在采樣率較低時,基于深度學習的CVS重構算法的重構性能較傳統(tǒng)算法提升更為明顯,表明了深度學習在信息有限時相比于傳統(tǒng)算法能更好地挖掘深層特征,獲得更好的重構性能。
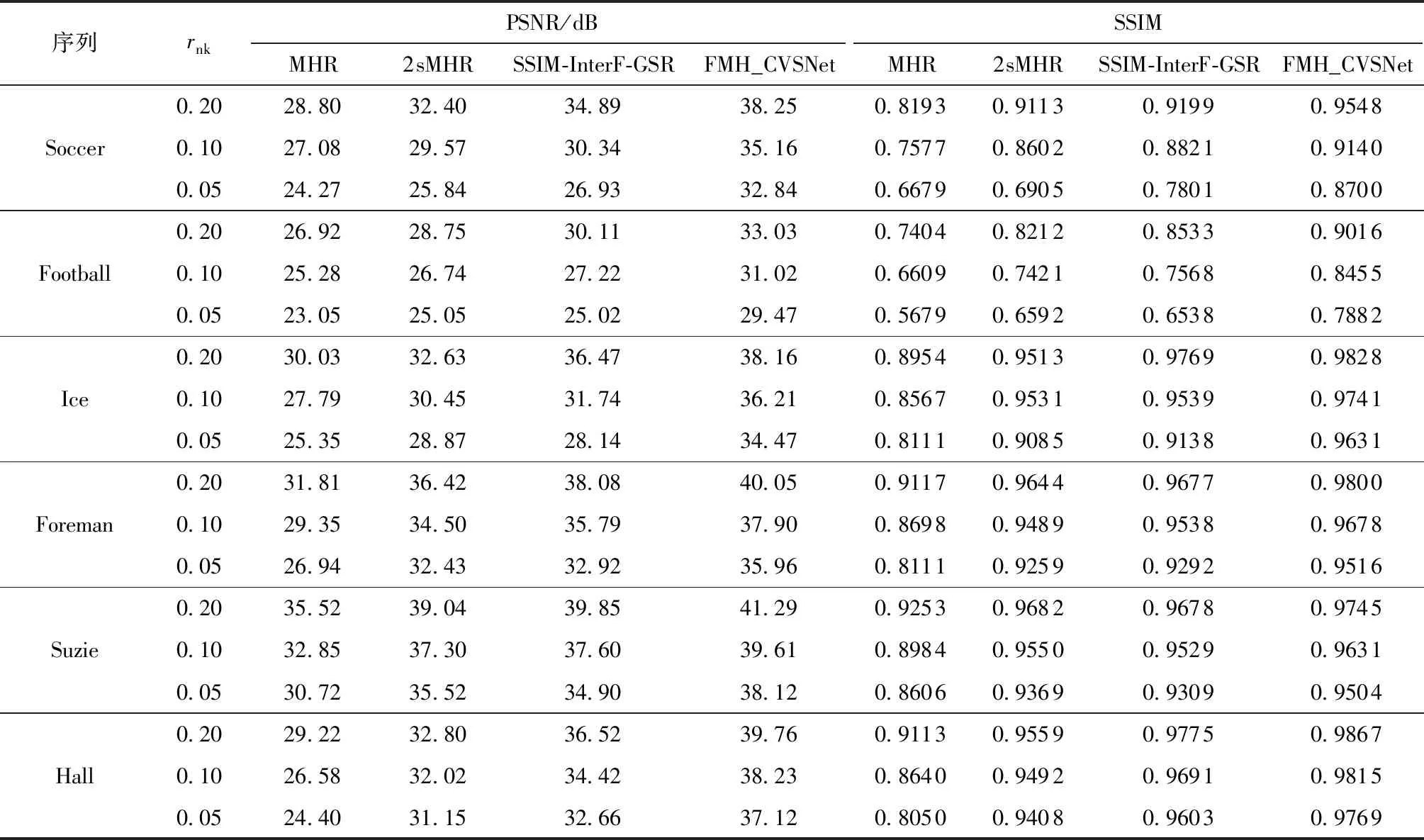
表2 FMH_CVSNet與傳統(tǒng)視頻壓縮感知重構算法的PSNR與SSIM對比Table 2 PSNR and SSIM comparison between FMH_CVSNet and traditional video compression sensing reconstruction algorithms
FMH_CVSNet與傳統(tǒng)重構算法(2sMHR[7]與SSIM-InterF-GSR[18])以及基于深度學習的CVS重構算法(PRCVSNet[13]與2sMHNet[14])在關鍵幀采樣率為0.5、非關鍵幀采樣率為0.1、GOP大小為8時,Hall序列第31幀以及Football序列第2幀的重構效果如圖4、圖5所示,圖中標注了每個重構結果的PSNR值。從圖中可知:傳統(tǒng)算法2sMHR出現(xiàn)了明顯的塊效應與噪點,而SSIM-InterF-GSR則出現(xiàn)了過平滑,腿部輪廓、手部細節(jié)、服飾紋理等大量信息被抹去;3種基于深度學習的多假設重構網(wǎng)絡均能較好地重構出圖像的輪廓信息與細節(jié)信息,但本文的FMH_CVSNet能更清晰地重構出人物衣服、腿部等區(qū)域,重構視覺效果最優(yōu)。

圖4 非關鍵幀采樣率0.1時各算法在序列Hall第31幀的重構視覺效果Fig.4 Reconstructed visual results of the 31st Hall frame with different algorithms at 0.1 sampling rate

圖5 非關鍵幀采樣率0.1時各算法在序列Football第2幀的重構視覺效果Fig.5 Reconstructed visual results of the 2nd Football frame with different algorithms at 0.1 sampling rate
3.2.2 算法復雜度對比
本文將FMH_CVSNet與PRCVSNet[13]與2sMHNet[14]進行了重構時間與網(wǎng)絡參數(shù)量對比。當非關鍵采樣率為0.1時,3種算法對QCIF標準序列的平均每幀GPU重構時間以及網(wǎng)絡參數(shù)量比較如表3所示。由表中可知,F(xiàn)MH_CVSNet的時間復雜度與空間復雜度略高于PRCVSNet與2sMHNet,這是由于FMH_CVSNet采用了算法復雜度較高的SPLNet作為圖像壓縮感知重構網(wǎng)絡,并使用了更復雜的多假設重構網(wǎng)絡。因此,本文提出的FMH_CVSNet雖然提升了重構質(zhì)量,但在一定程度上增加了網(wǎng)絡運算與存儲負擔。
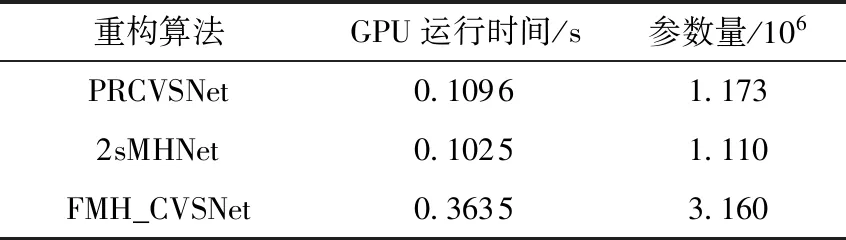
表3 3種基于深度學習的CVS重構算法的復雜度對比Table 3 Comparison of complexity among three CVS reconstruction algorithms based on deep learning
3.2.3 消融實驗結果分析
為驗證本研究提出的特征域多假設預測模塊(FMH_Module)以及多參考幀運動補償模式的有效性,本文在訓練與測試條件相同的情況下,以FMH_CVSNet為基礎,分別設置了不同的多假設網(wǎng)絡(包括本文的FMH_Module與TDAN多假設網(wǎng)絡[13])、不同的參考幀選擇模式(本文的多參考幀模式與兩階段單相鄰幀運動補償模式[14]),并比較了其重構性能。當非關鍵幀采樣率為0.1時,不同網(wǎng)絡結構在QCIF數(shù)據(jù)集及CIF數(shù)據(jù)集上的平均PSNR如表4所示,其中QCIF數(shù)據(jù)集中每個序列選取前96幀,而CIF數(shù)據(jù)集中每個序列選取前16幀進行測試。
由表4可以看出:FMH_Module與多參考幀運動補償模式都不同程度地提升了重構精度。選擇FMH_Module作為多假設預測網(wǎng)絡相比于利用TDAN在兩個數(shù)據(jù)集上的平均PSNR分別提升了0.17、0.36 dB;選擇多參考幀運動補償模式相比于單相鄰幀運動補償模式[14]在兩個數(shù)據(jù)集上的平均PSNR分別提升了0.34、0.33 dB。
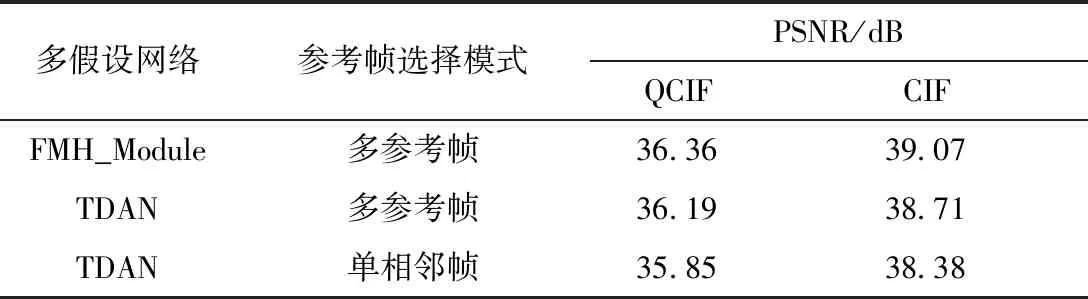
表4 不同網(wǎng)絡結構在不同測試集上的平均PSNRTable 4 Average PSNR of different network structures on diffe-rent test sets
為了提升網(wǎng)絡的預測能力,本文提出了新的多假設預測網(wǎng)絡FMH_Module,通過設計運動估計模塊、假設權重求解模塊以及擴大假設集容量等方式,在特征空間實現(xiàn)了高質(zhì)量的多假設預測。為了評估這些不同網(wǎng)絡結構與參數(shù)設置對FMH_Module預測精度的影響,本文設置了5個對比實驗:①縮小假設集容量,更改Conv_7卷積核大小為3×3,標記為MH-C3;②移除自適應假設集求解模塊,標記為MH-AW;③移除平均池化層APool,標記為MH-AP;④刪除運動估計模塊中的殘差連接,標記為MH-RL;⑤縮小運動估計神經(jīng)網(wǎng)絡層數(shù),刪除Conv_3、Conv_4以及中間的LReLU層,標記為MH-ME。
由于FMH_CVSNet完整網(wǎng)絡的訓練周期較長,故本文僅對多假設預測模塊進行訓練并測試,即以SPLNet初始重構結果為輸入,選擇最近關鍵幀作為參考幀,利用不同結構的多假設預測網(wǎng)絡輸出預測幀,該預測幀的質(zhì)量在一定程度上反應了多假設預測網(wǎng)絡的性能。當非關鍵幀采樣率為0.1時,不同網(wǎng)絡結構的多假設預測模塊在CIF及QCIF數(shù)據(jù)集上的PSNR對比如表5所示。
由表5可知:完整結構的FMH_Module取得了最好的預測結果,相比于其他網(wǎng)絡結構均有不同程度的提升;設置自適應權重模塊對預測結果的影響最大,加入自適應權重求解模塊后,CIF與QCIF序列的平均PSNR分別提升了2.67、1.12 dB;加大假設集容量可使平均PSNR提升了0.42 dB;設置平均池化層對預測結果的提升較小,僅提升了0.08 dB;運動估計深度不同對預測結果的影響不同,加深運動估計層數(shù)使平均PSNR提升了0.70 dB,而僅增加殘差連接使平均PSNR提升了0.27 dB。以上結果均表明了FMH_Module網(wǎng)絡結構設計的合理性,均在不同程度上提升了多假設預測的精度。

表5 不同設置下FMH_Module預測結果的PSNRTable 5 PSNR of FMH_Module prediction results under different settings
4 結論
在多假設預測算法中,獲得高質(zhì)量預測的關鍵是構造匹配程度高的假設集以及求解高精度的假設集權值。本文針對現(xiàn)有網(wǎng)絡假設集構造以及假設權重求解的不足,提出了特征域多假設預測視頻壓縮感知重構網(wǎng)絡FMH_CVSNet。FMH_CVSNet以SPLNet為初始重構網(wǎng)絡,設計了新的基于特征域多假設模塊FMH_Module與兩階段多參考幀運動補償模式的增強重構子網(wǎng)絡。FMH_Module通過設計合理的運動估計模塊、假設權重求解模塊以及擴大假設集容量等方式,在特征空間實現(xiàn)了高質(zhì)量的多假設預測;兩階段多參考幀運動補償模式為了同時適應快速運動序列與慢速運動序列不同的信號特征,在第一階段選擇關鍵幀作為參考幀的基礎上,在第二階段同時利用關鍵幀與相鄰幀進行特征域多假設預測,并通過一個融合網(wǎng)絡對二者進行優(yōu)勢互補,得到最后的預測幀。仿真結果表明,與現(xiàn)有算法相比,F(xiàn)MH_CVSNet的重構性能提升明顯,相比于2sMHR和VCSNet-2,平均PSNR分別提升了4.76、3.87 dB。
