基于負載關系圖的微服務自動伸縮方法
2022-07-12 14:03:26趙文耘
計算機應用與軟件 2022年6期
冀 超 彭 鑫 趙文耘
(復旦大學軟件學院 上海 201203) (上海市數據科學重點實驗室 上海 201203)
0 引 言
微服務(Microservice)架構是一種目前在企業實踐中得到廣泛應用的軟件架構。微服務架構將一整個軟件應用按照細粒度的模塊劃分規則解耦成一個個功能獨立的模塊[1]。每個模塊獨立開發與部署,擁有獨立的進程與運行環境。各個模塊通過RPC或HTTP等輕量級的通信協議調用其他模塊的接口,協同完成系統功能。這樣的模塊稱之為微服務。目前微服務架構已成為云原生技術[2]領域的關鍵技術[3],并在企業中得到廣泛使用[4]。例如,Netflix公司用了7年時間完成了由單體系統向微服務系統的遷移工作[5];騰訊公司的微信系統包含了部署在20 000多臺虛擬機上的3 000多個微服務[6]。
微服務細粒度功能劃分與獨立運行環境的特性使得軟件系統的部署更具靈活性與動態性。一個微服務一般部署若干個副本共同分流請求,稱為微服務實例。當系統某些部分的負載產生變化時,系統將會調整這些功能涉及微服務實例的數量。例如,在用餐高峰時間,外賣訂餐系統增加負責點單的微服務實例以應對增長的請求;而在夜間和凌晨時段,一些微服務部署副本將會被刪除以節約運算資源。開發人員希望微服務實例可以自動伸縮,自動地適應系統不斷變化的負載。但是,微服務之間存在復雜的網狀調用負載關系。如果獨立地對各個微服務的伸縮需求進行計量,很容易導致負載瓶頸從一個微服務沿著網狀關系傳遞到另一個微服務上,使得系統在多輪伸縮操作后才達到穩態,導致自動伸縮操作所耗時間較長。
為了解決上述問題,本文提出基于負載關系圖的微服務自動伸縮方法。首先,本文對微服務負載關系圖進行了定義,并介紹了其構建與更新過程及數據抽取方法。接著,本文介紹了基于負載關系圖的自動伸縮方法。該方法在自動伸縮操作觸發后,根據微服務負載關系圖評估各個微服務的新時段預期負載強度,并計算各個微服務的伸縮需求,最后一并完成所有微服務的伸縮操作。基于前述方法,本文設計并實現一個面向部署在Kubernetes平臺上的微服務系統的自動伸縮工具LRGAS。最后,本文使用TrainTicket開源微服務基準系統開展了自動伸縮方法的對比實驗,并通過實驗驗證了本文方法的高效性。
1 相關工作
微服務架構功能劃分的細粒度性與運行環境的隔離使得各個微服務的部署具有很高的靈活性與動態性。當系統負載增加時,系統可以為特定的微服務分配更多資源以提高其請求處理能力。系統可以為現有的微服務實例分配更多的CPU使用時間、內存空間以提高單個實例的請求處理能力,這種方式稱為縱向伸縮;系統也可以保持單個微服務實例的資源限額不變,但增加微服務實例的數量以分流請求,這樣的方式稱為橫向伸縮。橫向伸縮相比縱向伸縮具有更高的靈活性與可操作性,因此目前微服務的自動伸縮大多使用橫向伸縮的方式。該方法的工作方式為:開發人員在部署微服務時設定某個監控指標的上下門限值;當負載變化使得監控指標超出門限值范圍時,微服務系統自動增加或減少實例數量,確保指標在門限值范圍內。該方法常被用到作為門限值的監控指標有CPU使用時間、內存占用量或是請求響應時間等。目前使用最為廣泛的Kubernetes容器編排平臺的橫向伸縮方法便是使用該方法。
由于目前的自動伸縮方法在微服務指標超出門限值范圍后才觸發伸縮操作,導致伸縮操作存在滯后性。一些研究嘗試對微服務實例監控指標的未來走勢進行預測[7-10],進而在系統流量變化前預先完成伸縮操作。其中,文獻[7]提出了一套基于微服務工作負載預測的自動伸縮框架。該框架借助人工神經網絡、遞歸神經網絡及資源擴展優化算法構建了一個自動化系統,借助微服務系統的基礎架構層數據完成各個服務的自動伸縮操作。此外,由于指標的選取和門限值的設定依賴于開發人員的經驗,這導致門限值的設定并不準確。一些研究[11-12]致力于尋找可以更精準反映微服務伸縮需求的指標。文獻[11]在自動伸縮所使用的監控指標類型上進行了改進。該方法構建了工具Microscaler,通過對接口的響應時間進行統計和計算定義了微服務的“服務能力”指標。該指標對微服務負載強度的描述比其他監控指標更為準確,計算伸縮需求時也更加精確。目前的工具和研究大多關注微服務監控指標門限值的預測、設定和監控指標的選取和定義。這些研究存在的問題是,微服務之間存在著復雜的調用關系,但目前的伸縮方法獨立地考慮各個微服務的伸縮需求,無法避免負載瓶頸轉移的問題發生。自動伸縮方法應當統籌規劃整個系統中各個微服務伸縮操作,一次性并行對多個相關微服務并容,使得系統可以盡快達到穩態以滿足新的負載需求。
2 背景知識
2.1 容器、容器編排與服務網格
微服務架構的引入使得軟件應用的部署方式產生了變化。一個微服務系統包含許多獨立部署的微服務實例,它們的部署配置環境可能互相產生沖突,這使得運行環境管理變得復雜。容器技術的出現解決了這個問題。容器技術借助操作系統提供的命名空間和資源隔離機制,將一臺虛擬機上同時運行的多個微服務實例的運行環境隔離,避免了進程間運行環境沖突的問題。容器平臺還提供了統一的部署與運行接口,抹平了不同虛擬機之間的差異性,使得各個微服務可以無差異地在各種機器環境下分發與部署。目前最為廣泛使用的容器技術是Docker[13]。
容器技術解決了微服務獨立部署和運行的問題,但是沒有解決微服務集群的維護與管理的問題。在微服務系統的部署過程中,部署平臺需要把各個微服務實例調度到空閑資源充足的虛擬機上去;同時為了避免各個微服務實例網絡地址沖突問題,需要從全局對各個微服務實例的地址進行唯一性分配;此外,為了保證系統的正常運行,系統需要確保有預期數量的微服務實例處于正常運行狀態。為了解決這樣的需求,容器編排平臺出現。借助容器編排平臺,開發人員可以自定義微服務系統的部署方案,簡化微服務系統的部署與維護工作。目前在實際生產實踐中廣泛使用的平臺有Kubernetes[14]、Docker Swarm[15]、Mesos[16]、Spring Cloud[17]等,這些平臺都對微服務系統所需要的功能進行了不同程度的實現。目前最為廣泛使用的容器編排平臺是Kubernetes,已成為容器編排平臺的事實標準。目前也有一些關于微服務編排工具的研究[18-19]實現了前述功能。例如,文獻[18]提出了一套名為MiCADO的微服務編排工具,提供了云應用的自動伸縮功能。
隨著微服務系統規模的擴大,微服務之間的交互關系也變得越來越復雜,這使得系統內部的網絡配置與操控變得困難。例如,在新服務上線時開發人員希望流量按照比例逐漸切換到新的服務上;而有些時候,開發人員希望根據請求的元信息分流某些請求。在這種情況下,需要一個全局的控制平面來對系統內部網絡流量進行管理,而服務網格技術解決了這個問題。服務網格向每一個運行的微服務實例中添加一個邊車組件(sidecar)用于接管微服務實例的所有網絡操作,使得微服務系統內部的網絡交互實際上變成sidecar之間的網絡交互。如此一來,開發人員即可通過配置規則并將其應用于sidecar的方式來對整個應用內部的網絡調用進行操控。Istio[20]是服務網格技術的典型代表。
2.2 微服務系統的調用鏈追蹤
微服務系統內部存在著復雜的調用關系,一個請求的處理過程往往需要一到多個微服務的協同。在系統的運行過程中,為了在故障發生時對請求的調用關系進行追蹤以便查明故障,需要對微服務系統的調用鏈進行追蹤,以便獲取請求被各個微服務實例處理的順序和處理時間等數據。
OpenTracing標準[21]是目前被廣為接納的微服務鏈路追蹤標準。根據OpenTracing標準的數據模型定義,一個完整的請求鏈路與OpenTracing中的一條Trace所對應,而一個完整請求鏈路中的每次跨服務服務調用(如一次RPC或HTTP調用)則對應OpenTracing的一條Span。也就是說,一條Trace是由若干個Span構成的樹狀結構或是有向無環圖。如圖1所示,用戶向微服務A發送一條請求,系統生成對應的調用鏈Trace_x。該請求分別產生了對微服務B、微服務C、微服務D、微服務E的調用,并生成對應的4條Span。OpenTracing還定義了Trace和Span中應該包括的諸多指標數據、標簽等信息。通過這些信息,開發人員可以得到請求調用中的細節信息,例如請求的來源、目的地、發生時間、時延等。
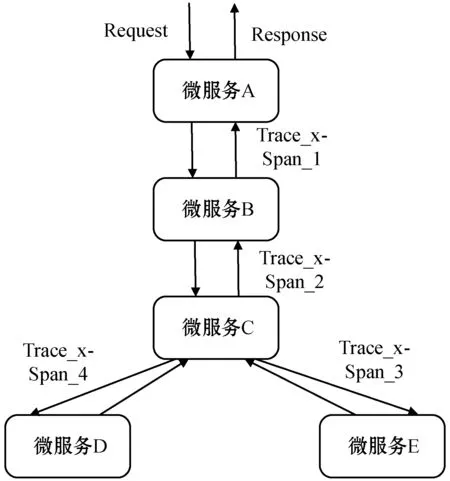
圖1 Request、Trace與Span關系
OpenTracing標準目前有很多開源項目實現。Spring Cloud Sleuth是一個Java庫,將其引入基于Spring框架的Java微服務項目后,即可通過在跨服務調用的請求Header頭上插入特定請求ID的方式,將整條調用鏈串接起來。Zipkin是一個開源調用鏈收集和展示工具,包含數據存儲和UI界面兩部分。Spring Cloud Sleuth會將自動生成調用鏈傳輸給Zipkin進行存儲。開發人員可以借助其UI界面完成調用鏈的查詢和展示。該調用鏈追蹤系統的架構如圖2所示。
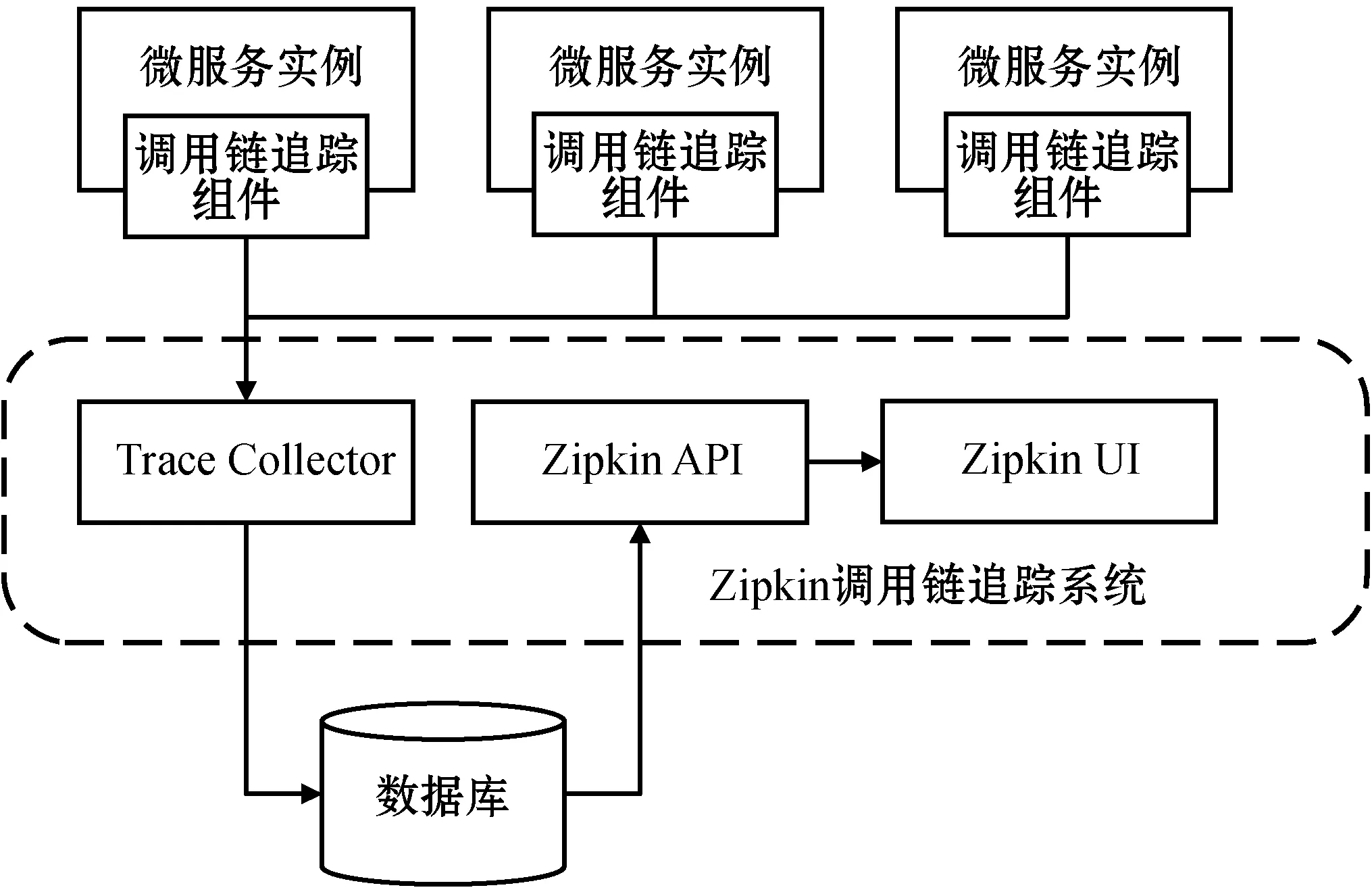
圖2 Zipkin調用鏈追蹤系統架構
3 微服務負載關系圖
與單體應用不同,微服務系統的各個微服務完成獨立的功能并使用獨立的方式部署,并通過調用其他微服務的方式協同完成一系列功能。這樣的情況使得不同微服務之間的依賴關系不同:有些微服務之間聯系緊密,而有些微服務之間很少發生調用關系。整個系統的自動伸縮操作必須考慮到微服務間的負載關系的不同,并對各個微服務實行不同程度的伸縮操作。
為了達到前述目的,本文設計并定義微服務負載關系圖。該圖描述了過去時間內系統中各個微服務之間的負載強度關系,其中:節點表示微服務;兩個節點間關系表示兩個微服務發生過調用關系;關系上的數字是對一段時間內調用次數的記錄,反映了兩個微服務之間一段時間內的負載強度。每個微服務的負載強度等于所有指向其關系上的負載總和。如圖3是一個包含6個微服務的微服務負載關系圖的示例。“微服務系統外部”是一個特殊的節點,代表使用微服務系統的用戶方。微服務A、F直接接收外部請求,并調用系統內部的微服務B、C、D等。本文將微服務A、F這樣的系統外部請求首先到達的微服務稱為系統的入口微服務。入口微服務同時也是請求調用鏈中第一個出現的微服務。
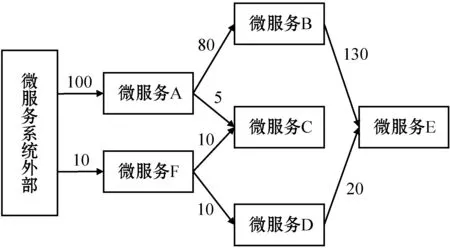
圖3 微服務負載關系圖示例
微服務負載關系圖的數據來源于調用鏈監控系統收集的調用鏈數據。正常運行的微服務系統一段時間會采集到大量調用鏈日志,而每條調用鏈日志(即Trace)中包含若干次跨服務調用(即Span)。每條Span都可以提取出一個微服務對另一個微服務的一次調用。圖4為一條Span數據的示例。可以看出,這是一次ts-login-service對ts-sso-service的調用。

圖4 調用鏈日志示例
微服務負載關系圖隨著系統運行持續進行構建與更新。該過程固定間隔時間循環執行,主要包括以下步驟:1) 從調用鏈平臺中抽取最近一個時間段內新產生的Trace數據;2) 對于每條Trace,逐個檢查其包含的Span數據,記錄調用發起方的微服務名稱和調用接收方的微服務名稱;3) 對記錄的兩個微服務間的每次調用,將負載關系圖中對應關系上記錄的數字加一;4) 將新的負載關系數據存入數據庫中,取代舊數據,等待一段時間后返回1)步繼續下一輪更新。經過更新后的節點間關系上記錄的數字便是兩個微服務之間的負載強度。
4 自動伸縮方法
4.1 問題分析與過程概述
目前廣泛使用的基于指標門限值設定和監控的微服務自動伸縮方法存在一些不足。按照該方法,當僅僅針對某一個繁忙的服務進行伸縮時,系統的負載瓶頸很有可能會很快轉移到另一個下游的微服務,進而引發另一次伸縮,如此迭代多次后才能最終達到相對穩定狀態。這樣的方式將會使得系統較長時間處于正在伸縮狀態,不利于系統迅速適應新的負載需求。當某些功能的訪問量變化時,需要一并找到所有可能受到較大影響的微服務進行伸縮,而不是孤立地對監控指標超標的微服務逐個進行伸縮。
圖3為包含6個微服務的調用負載示意圖。可以看出,在一段時間內,微服務A共接收了100次調用,并分別調用了80次微服務B和5次微服務C;微服務F接受了10次調用,并分別調用了10次微服務C和10次微服務D;微服務B和微服務D分別調用了微服務E共計130次和20次。根據數據看出,微服務A和微服務B、微服務E三者之間關系密切,而微服務A和微服務C之間關系并不緊密。這意味著,如果微服務A為了應對劇增的用戶請求而進行伸縮,那么微服務B首先會受到大量請求的沖擊而引發伸縮操作,進而影響蔓延到微服務E,微服務C由于接收微服務A的負載較少,基本不會受到影響。假設微服務A伸縮所需時間為TA,微服務B的伸縮所需時間為TB,微服務E的伸縮所需時間為TE。如果使用傳統的微服務自動伸縮方法,微服務系統最終完成所有伸縮操作所需總時間Told為:
Told=TA+TB+TE
(1)
如果可以在微服務伸縮操作前分析微服務間的調用關系,確定微服務的伸縮需求后再并行進行伸縮,那么所需要的總時間Tnew為:
Tnew=max(TA,TB,TE)
(2)
根據上述分析可以看出,在各個微服務伸縮所需時間相近的情況下,改進后的方法可以大大減少整個系統伸縮操作所需要的時間。其主要原理是,通過分析服務間負載關系的方法,將多個需要伸縮的微服務從串行伸縮變成并行伸縮。
本節提出的微服務自動伸縮方法主要包括兩個部分:首先該方法從微服務歷史調用鏈日志中提取整個系統過去一個時段的微服務負載關系圖。接著,通過監控系統獲取到的入口微服務的請求頻率變化幅度,借助微服務負載關系圖分析系統中各個微服務的負載水平,最終得出各個微服務的伸縮需求。
基于負載關系圖的微服務自動伸縮方法的流程如圖5所示,共包含4個步驟:1) 觸發自動伸縮。此步使用與傳統自動伸縮相同的觸發方法,即設置監控指標的門限值并對其進行監控,在指標越過門限值時觸發自動伸縮。2) 計算各個微服務的預期負載。自動伸縮觸發后,根據入口微服務請求頻率的變化,借助微服務間負載關系評估各個微服務在新時段的預期負載。3) 根據各個微服務新時段的預期負載計算其伸縮需求。4) 向容器編排平臺發送請求并執行微服務伸縮操作。該流程的核心步驟為微服務預期負載的計算和微服務伸縮需求的計算。
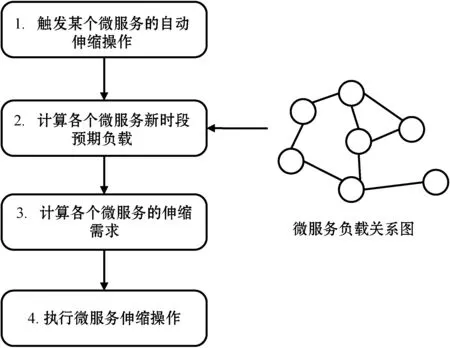
圖5 基于負載關系圖的微服務自動伸縮方法流程
4.2 微服務預期負載的計算
該過程的目的是借助系統的新舊時段入口微服務請求頻率變化幅度和微服務間負載關系來對各個微服務新時段預期負載進行預估。該方法的執行過程如算法1所示。該方法首先實時監控系統入口微服務的請求頻率變化情況,計算自動伸縮操作觸發前后入口微服務的請求頻率變化比值關系。接著,將入口微服務的舊負載乘以該比值作為入口微服務的新負載。由于入口微服務的新負載水平也會對其調用的微服務造成影響,接下來計算因為入口微服務負載變化而受到影響的微服務的預期負載變化,進而逐個計算系統其他微服務的預期負載變化。如此往復,最終得到整個系統中各個微服務在新時段的預期負載水平。
算法1計算微服務在新時段的預期負載強度
輸入:微服務負載關系圖中的微服務節點集V,微服務間負載關系集E。
輸出:每個微服務節點v和其預期新負載水平newLoadOfV。
1.forvinV
2.v.inbound=count(e∈Eande.to==v)
3.end for
4.將集合V中的所有入口微服務節點加入S
5.forsvcinS
6.定義svc與系統外部的負載關系為enterEdge,其伸縮操作觸發前后該系統外部請求頻率的比值為enterChange
7.enterEdge.newFlow=enterEdge.oldFlow*enterChange
8.end for
9.forsvcinS
10.oldLoad=0,newLoad=0
11.定義集合E中終點為svc的關系集為inboundEdges
12.foredgeininboundEdges
//計算該微服務新舊負載
13.oldLoad=oldLoad+edge.oldFlow
14.newLoad=newLoad+edge.newFlow
15.end for
16.map.put(svc,newLoad)
//該微服務的新時段預期負載
17.change=newLoad/newLoad
//計算該微服務新舊負載比值
18.定義集合E中起點為svc的關系集為outboundEdges
19.foredgeinoutboundEdges
//計算該微服務負載變化后,對
//其調用微服務的負載產生的影響
20.edge.newFlow=edge.oldFlow*change
21.svcTo=edge.to
22.svcTo.inbound=svcTo.inbound-1
23.ifsvcTo.inbound==0
24.S.add(svcTo)
25.end if
26.end for
27.end for
28.return map(v,newLoadOfV)
舉例如圖6所示,當入口微服務A的外部請求頻率倍增時,微服務A的負載也倍增,但其他各個微服務負載受到的影響各不相同。例如微服務C、E與微服務A聯系密切,因此負載均出現較大增長;但是由于微服務A較少調用微服務D,因此微服務D負載增長幅度不大;而微服務B并未參與到增長的請求的處理中去,因此該微服務的負載強度不發生變化。在這種情況下,只有微服務A、C、E需要伸縮,而微服務B、D基本無須伸縮。
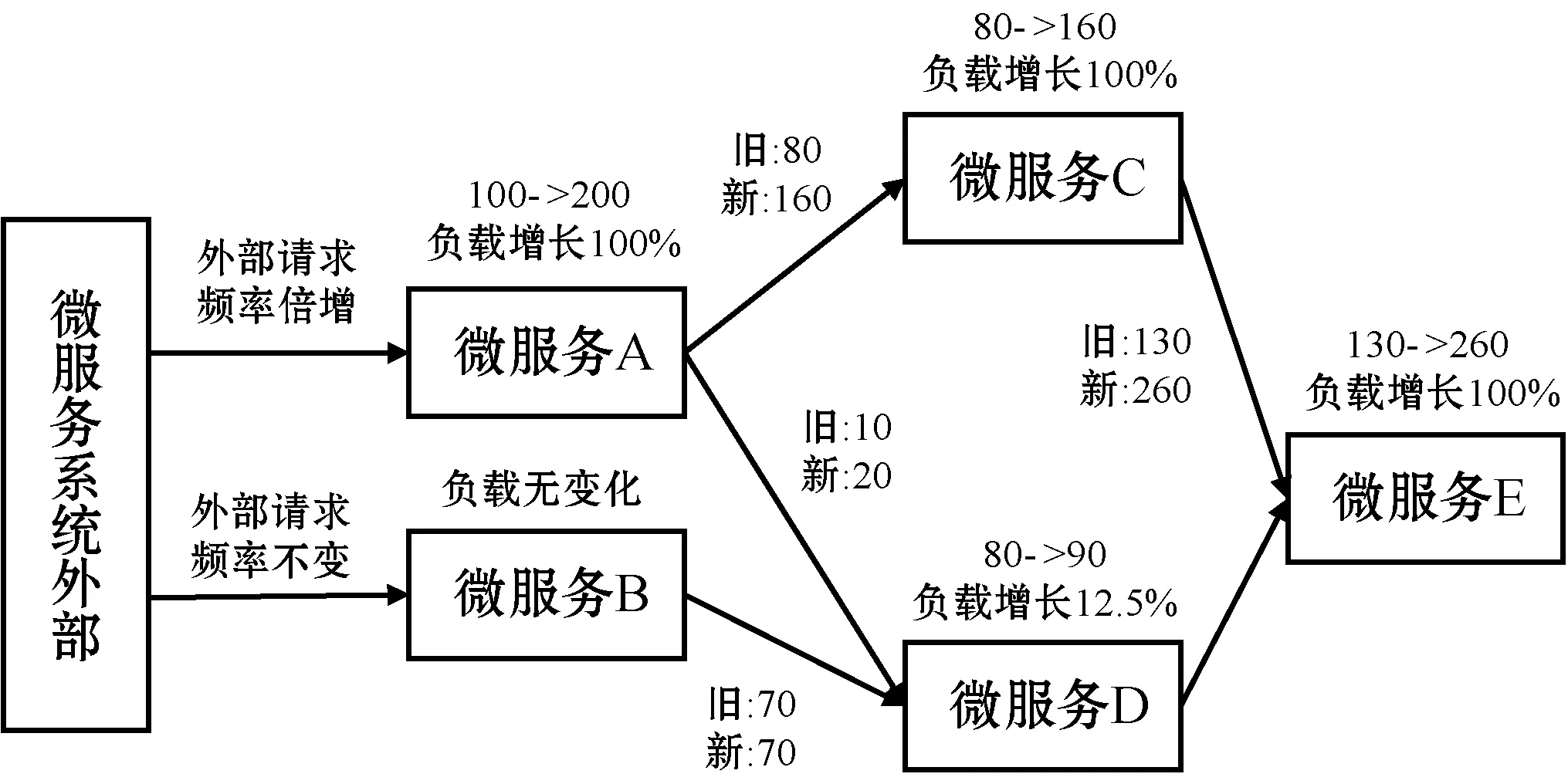
圖6 微服務的負載強度變化示例
在計算得到各個微服務的負載強度后,下一步即可計算各個微服務的伸縮需求,調用容器編排平臺相應接口執行伸縮操作,并等待操作的完成。
4.3 微服務伸縮需求的計算
計算得到各個微服務在新時段預期負載強度后,即可借此計算各個微服務在新時段的實例需求數,并在微服務容器編排平臺上執行自動伸縮操作并等待操作完成。本文假設對于某一個微服務上一系統穩定時段的負載為Lold,上一時段該微服務實例數量為Nold;新時段該微服務預期負載為Lnew,預期新負載強度下的實例數量為Nnew。那么對于Nnew,本文采取如下計算方法:
(3)
通過計算得到在新時段各個微服務的預期的實例數量之后,即可調用容器編排平臺提供的相關接口,更新各個微服務的微服務實例數量配置信息,并等待其更新配置數據并部署或刪除指定數量的微服務實例。由于各個微服務的自動伸縮是并行進行的,因此最終耗費的時間大致與伸縮耗時最長的微服務所需時間相同。
5 工具設計
基于前文所述的負載關系圖構建方法和基于負載關系圖的微服務自動伸縮方法,本文設計并實現工具LRGAS。該工具的實現架構如圖7所示。該工具監控和操作的目標對象為部署于K8S集群上的微服務系統。對于目標微服務系統,微服務系統中還應當配合部署Zipkin調用鏈追蹤平臺和Prometheus指標監控平臺。目標微服務系統部署在若干臺虛擬機組成的集群上,而LRGAS工具相關服務與數據庫部署在另一臺集群外的獨立虛擬機上,以防對微服務系統的運行產生干擾。
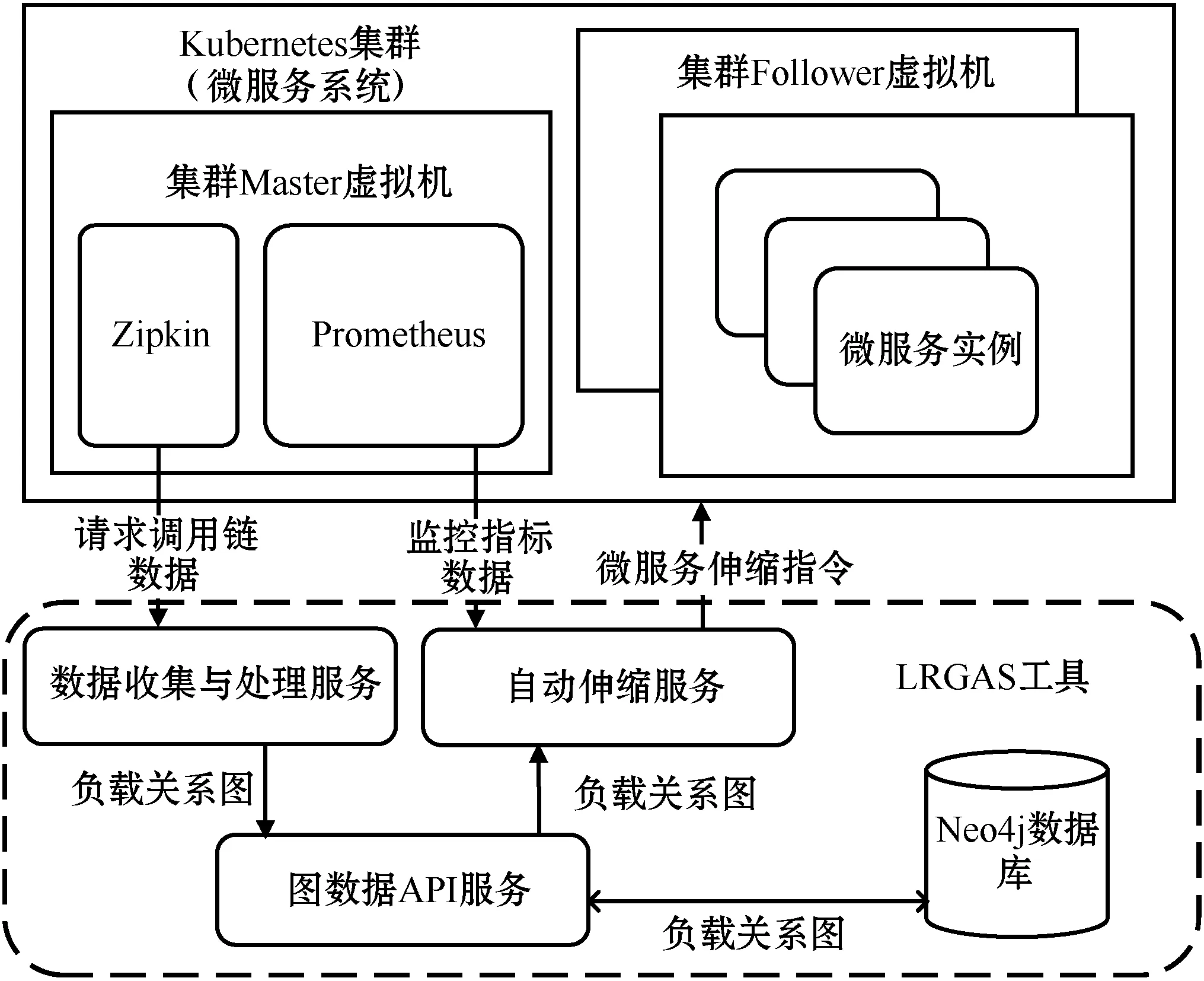
圖7 LRGAS工具實現
LRGAS工具使用的外部數據共有兩種。其一是Zipkin調用鏈追蹤平臺收集的微服務系統請求調用鏈數據。每隔一段時間,本工具將會采集一次最新的調用鏈數據,用于構建和更新負載關系圖中的數據。其二是Prometheus監控平臺提供的監控指標數據。這部分數據一方面用于監控入口微服務的請求頻率變化,另一方面用于判斷各個微服務的監控指標是否處于預設閾值范圍內,并最終用于判定是否觸發微服務的自動伸縮操作。
該工具主要包括三個Java服務和一個圖數據庫。三個服務均基于Spring Boot框架完成開發。數據收集與處理服務實現負責關系圖的構建和維護,定時從Zipkin平臺抽取調用鏈數據并將更新的負載關系圖發送到圖數據庫API服務。圖數據API服務對接neo4j圖數據庫,負責負載關系圖數據的讀取和存儲。自動伸縮服務從Prometheus平臺實時抽取各個微服務的監控指標數據,判斷自動伸縮操作是否觸發。若自動伸縮操作被觸發,自動伸縮服務從圖數據庫API服務獲取最新的微服務負載關系圖,計算出各個微服務的伸縮需求后,向K8S平臺發出伸縮指令,并等待操作的完成。
6 實 驗
6.1 實驗過程
本實驗使用部署在Kubernetes容器編排平臺上的TrainTicket開源微服務基準系統作為實驗對象。TrainTicket使用的是在工業界生產環境中使用較多的Spring Cloud Sleuth[22]與Zipkin[23]進行調用鏈日志的收集,可以很好地模擬微服務系統在真正生產環境中的運行狀況。
在TrainTicket的眾多功能中,本文選取了三種涉及不同規模微服務數量且在實際使用中使用較為頻繁的場景,如表1所示。場景1模擬的是單一微服務需要伸縮的場景,對應于TrainTicket系統的登錄場景。該場景模擬用戶登錄高峰期,涉及驗證碼請求與核對等操作。在該場景下大量用戶登錄導致對于驗證碼服務的請求數量激增。此處涉及一個微服務,即驗證碼服務。場景2模擬的是有較多微服務需要伸縮的場景,對應于TrainTicket系統出現大量用戶訂票場景。該場景模擬用戶火車票預訂高峰期,包括余票查詢、價格計算、訂單創建和通知發送等請求。該場景是TrainTicket系統中最為復雜的場景,需要9~15個微服務協同完成該功能。場景3模擬的是中等數量微服務需要伸縮的場景。該場景模擬用戶退票高峰期,包含訂單狀態修改、退款等操作。該場景是一個中等復雜的功能,包括訂單狀態修改、退款等操作,涉及5~7個微服務。由于微服務負載強度會影響請求響應時間,因此本實驗以請求響應時間為自動伸縮監控指標。對于三種場景,實驗將入口微服務的請求頻率變為正常運行下的3倍,以觸發自動伸縮操作。
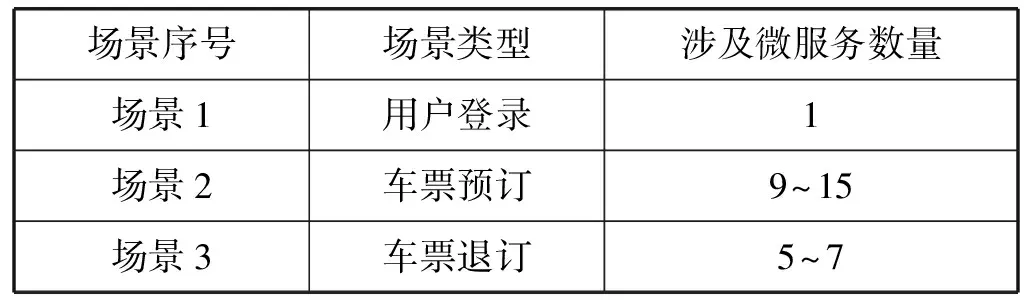
表1 自動伸縮場景列表
為了使負載關系圖收集到完整且全面的數據,在觸發自動伸縮操作前,應先維持系統正常運行一段時間。本實驗實現了一個簡單的請求模擬器,以設定頻率向微服務系統發送各種類型請求。請求的頻率會隨著時間產生小幅變化,以模擬微服務系統在實際應用中運行狀況。
本文實驗主要通過對比微服務系統在不同的場景下使用傳統的各個微服務獨立自動伸縮的方法以及基于負載關系圖的自動伸縮算法最終完全適應新的負載并達到穩態(也就是微服務實例數量不再變化)的時間,來驗證本文方法的高效性。實驗按照場景分為三組。對于每組實驗,使用請求模擬器模擬系統一段時間的正常運行,以確保微服務系統的負載依賴圖收集到足夠的數據。然后,依照各個場景的描述,逐步增加對應場景功能的請求頻率以增加對應微服務的負載。當負載增大到一定程度時,自動伸縮操作將會被觸發。本實驗將會記錄從自動伸縮操作的觸發到整個系統最終完成全部操作的時間。對于每種場景,本文將會進行3次實驗,并取平均值作為最終結果。
6.2 實驗結果與分析
本次實驗的最終實驗結果數據如表2所示。本實驗對三個場景分別使用兩種自動伸縮方法的所需平均時間折線圖如圖8所示。
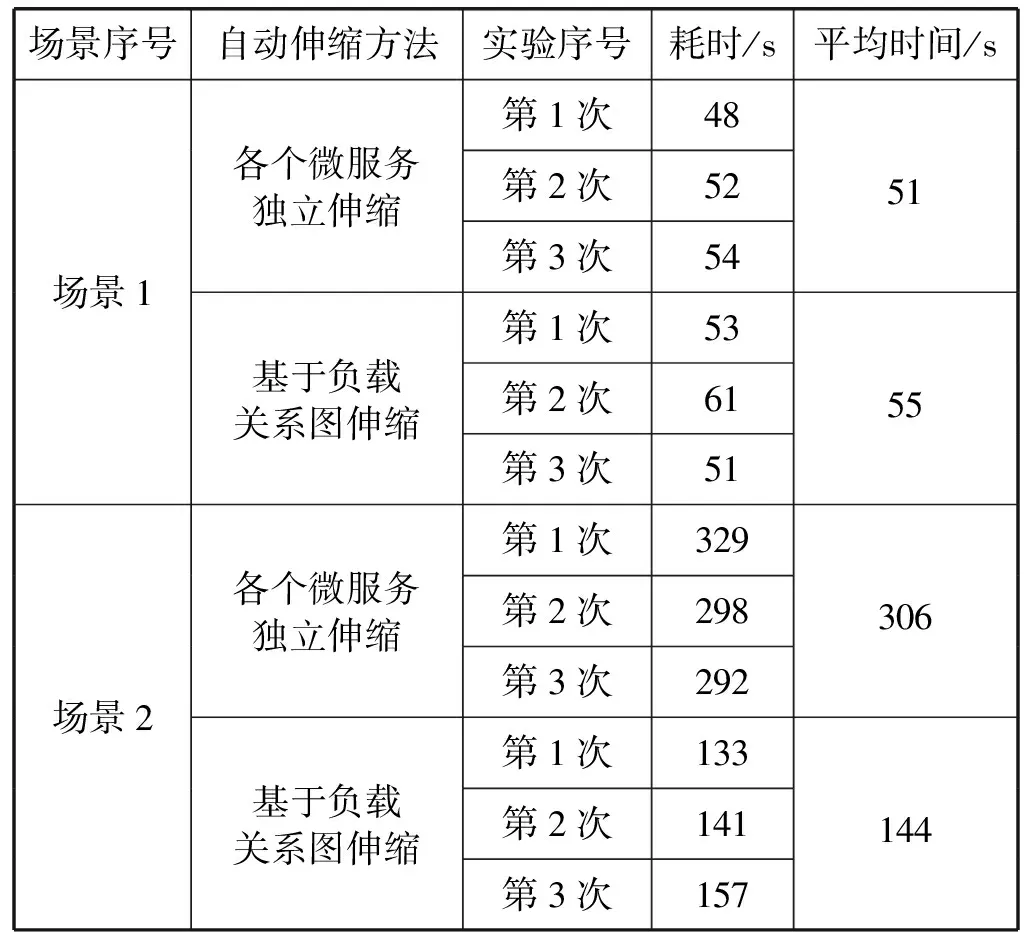
表2 自動伸縮實驗結果統計表

續表2
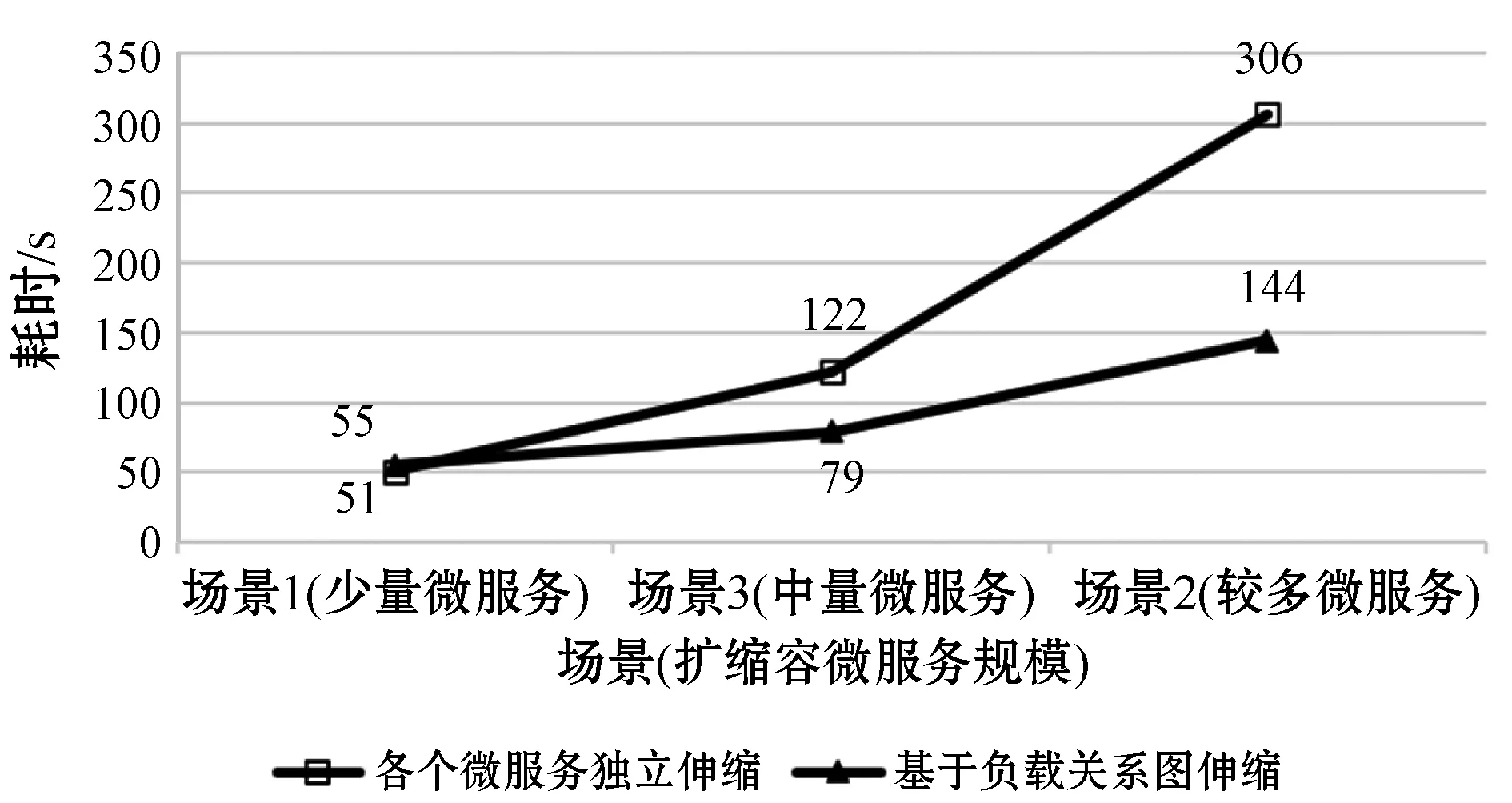
圖8 兩種自動伸縮方法使用時間對比
根據圖8中的數據可以得出,在微服務數量較少時,本文所述的自動伸縮方法沒有優化效果,甚至有時耗時高于各個微服務獨立伸縮的方法。但在自動伸縮的微服務數量逐漸增加時,本文方法逐漸體現出時間上的優勢。這是由于在微服務規模增大的情況下,微服務之間的依賴關系也變得更加復雜。使用傳統的微服務伸縮方法在微服務數量規模較大且調用關系又復雜的情況下,很容易在一個微服務擴容后,流量瓶頸迅速轉移到另一個微服務上,進而引發另一輪擴容操作,如此多輪后最終完成擴容。而在僅有少量或一個微服務需要擴容時,無論使用何種方法都只需一輪即可完成所有伸縮操作,而本文方法還需要額外進行各個微服務需求的計算操作,反而會浪費一些時間。根據測算,根據微服務負載依賴圖計算各個微服務伸縮需求的時間大約在2~3 s左右。此外,由于本文所提出的自動伸縮方法一并完成所有微服務的伸縮,導致在同一時刻有更多微服務實例處于正在調度和啟動狀態,在實際系統運行中這將會拖慢單個微服務實例的啟動時間,但總體上來說由于伸縮操作的并行性,本文方法仍然相比傳統方法能節省大量時間。
7 結 語
目前微服務架構已經在企業實踐中得到了廣泛的應用。然而,獨立地對各個微服務進行監測的自動伸縮方法存在微服務系統內部負載瓶頸轉移的問題,使得系統適應新負載所耗費的時間較長。針對上述挑戰,本文提出基于負載關系圖的微服務故障自動伸縮方法。首先,本文設計和定義微服務負載關系圖的結構,并介紹了圖譜的數據抽取方式和數據示例。接著,本文借助微服務間負載關系圖,在系統外部負載發生變化后,分析各個微服務的負載強度變化,進而計算各個微服務的伸縮需求,最后向容器編排平臺發出伸縮指令并完成操作。基于前文所述方法,本文設計并實現了工具LRGAS。最后,本文使用TrainTicket開源微服務基準系統開展了伸縮方法對比實驗。實驗結果表明,隨著微服務數量的增加,本文方法的高效性體現愈加明顯。
本文方法目前也存在一些不足。本文自動伸縮方法在監控指標超出門限值范圍時才會觸發,使得入口微服務的自動伸縮操作存在滯后性。未來可以引入機器學習方法對微服務系統的負載走勢進行預測,在請求頻率大幅變化前即觸發伸縮操作,以更快適應新的負載強度。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
家庭影院技術(2017年9期)2017-09-26 03:41:45
商周刊(2017年9期)2017-08-22 02:57:56
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
