基于隨機森林的滑坡災(zāi)害空間預測
2022-07-14 08:34:20郭方民周小莉
資源導刊(信息化測繪) 2022年5期
郭方民 周小莉
(1.河南理工大學測繪與國土信息工程學院,河南 焦作 454000;2.四川水利職業(yè)技術(shù)學院,四川 崇州 611231)
1 研究背景
20世紀80年代以來,幾乎每年都有大型滑坡災(zāi)害發(fā)生,且呈現(xiàn)出逐年加重態(tài)勢。以2020年為例,全國共發(fā)生地質(zhì)災(zāi)害7840起,其中滑坡4810起,主要分布在28個省(區(qū)、市),其中湖南、江西、四川、浙江、廣西、廣東為重災(zāi)區(qū)。頻發(fā)的滑坡災(zāi)害造成了巨大的人員傷亡和財產(chǎn)損失。
目前,滑坡空間預測一般分為確定性預測和非確定性預測。確定性預測通過力學計算模型結(jié)合基礎(chǔ)地理信息預測滑坡,但只適用于小范圍預測。非確定性預測是結(jié)合歷史滑坡數(shù)據(jù)與滑坡誘發(fā)因子來預測不同尺度區(qū)域的滑坡災(zāi)害[1]。其中,許石羅[2]利用數(shù)據(jù)驅(qū)動的機器學習方法,建立了單個滑坡和區(qū)域范圍的滑坡災(zāi)害空間預測模型,實現(xiàn)了秭歸至巴東段滑坡災(zāi)害動態(tài)空間預測;姚鑫、譚國煥[3]以香港自然滑坡空間預測為例,采用支持向量機進行滑坡災(zāi)害空間預測。
2 研究方法
隨機森林模型是一種基于分類回歸樹的算法,其主要思想是通過自助法抽樣從原始訓練集中抽取k個樣本,且每個樣本的樣本容量均與原始訓練集的大小一致,然后對每個樣本分別進行決策樹建模,得到k個建模結(jié)果,最后利用所有決策樹的建模結(jié)果,通過投票表決決定最終分類結(jié)果[4]。決策樹學習的目的是為了產(chǎn)生一棵泛化能力強,即處理未見示例能力強的決策樹[5]。森林中樹的數(shù)量是一種重要的超參數(shù),通過增加樹的數(shù)量提高模型性能,但同時會消耗算力。通常決策樹算法由信息增益或基尼不純度作為衡量方式,通過選擇在每個節(jié)點能產(chǎn)出最佳分隔的特征來組織樹。實際應(yīng)用中,為了避免隨機森林參數(shù)設(shè)置的主觀影響,其主要參數(shù)一般通過使用scikit-learn中的網(wǎng)格搜索和隨機搜索方法進行確定[6]。與傳統(tǒng)應(yīng)用于滑坡易發(fā)型評價的機器學習方法相比,隨機森林引入了樣本和特征的隨機抽樣,降低了在分類過程中對數(shù)據(jù)噪聲和異常值的敏感性,提高了預測模型的準確率。
3 隨機森林空間預測實例分析
3.1 研究區(qū)概況
萬源市位于四川省東北部,達州市北部,大巴山中段南麓,東鄰重慶市城口縣,南接達州市宣漢縣,西連巴中市平昌、通江縣,北與陜西省鎮(zhèn)巴縣、紫陽縣交界,地處川陜渝鄂四省(市)交界處,有“秦川鎖鑰”之稱。萬源市地理坐標為東經(jīng)107°29′3.5″~108°30′34.4″,北緯31°38′56.2″~32°20′18.2″,轄12鎮(zhèn)40個鄉(xiāng),373個行政村,總?cè)丝?98685人,平均人口密度為147.27人/km2,全市區(qū)域面積4065.25km2。
3.2 模型建立及精度評價
滑坡空間預測是指對可能發(fā)生滑坡的地點展開預測,主要內(nèi)容包括區(qū)域性滑坡預測,即判斷滑坡的易發(fā)區(qū)域。其預測模型需要兩類輸入變量,一為滑坡誘發(fā)要素,例如降雨、高程、坡度、植被覆蓋度等。二為滑坡訓練樣本所需的標簽,即需要對研究區(qū)目前所有的已探明滑坡進行編錄。本次實驗選取植被覆蓋度、降雨、高程、坡度、坡向等滑坡誘發(fā)要素,如表1所示。

表1 滑坡誘發(fā)要素來源及提取方法
3.2.1遙感影像預處理

3.2.4預測結(jié)果及精度評價
根據(jù)經(jīng)驗設(shè)定非滑坡塊狀區(qū)域,利用gdal庫讀取融合后的滑坡誘發(fā)要素影像,制作樣本集。首先遍歷標簽影像,分為滑坡隱患區(qū)域和非滑坡隱患區(qū)域,記錄區(qū)域內(nèi)各像素對應(yīng)行列號,取對應(yīng)特征集中的降雨量、植被覆蓋度、高程、坡度、坡向生成樣本集合。實驗共獲得176170個樣本數(shù)據(jù),將該樣本集按照8∶2比例,分為訓練集和測試集。模型通過python實現(xiàn)。根據(jù)決策樹的不同,測試精度有所不同,如表2所示。隨著隨機森林中決策樹個數(shù)的不斷增加,隨機森林的訓練精度不斷提高,當決策樹個數(shù)為20時,訓練集精度達到0.998706256,測試集精度達到0.931731589。
利用訓練好的隨機森林模型,對研究區(qū)特征集進行測試,預測結(jié)果如圖5所示。可以發(fā)現(xiàn)由于多山、地勢陡峭、降雨量充沛等原因,萬源市大面積處于滑坡多發(fā)、易發(fā)區(qū)域,相對而言東部及中部地區(qū)由于居住人口多,經(jīng)過多年來人類的開發(fā)保護利用,地勢相對平緩,滑坡發(fā)生的可能性小。而西部居住人口少,大量地區(qū)處于無人居住地帶,滑坡等自然災(zāi)害發(fā)生概率更大。相關(guān)職能部門應(yīng)及時掌握道路、村莊附近的坡體變形情況,加大雨季巡察頻率,對于變形明顯區(qū)域,建立專業(yè)設(shè)備監(jiān)測點,有效減少滑坡?lián)p失。
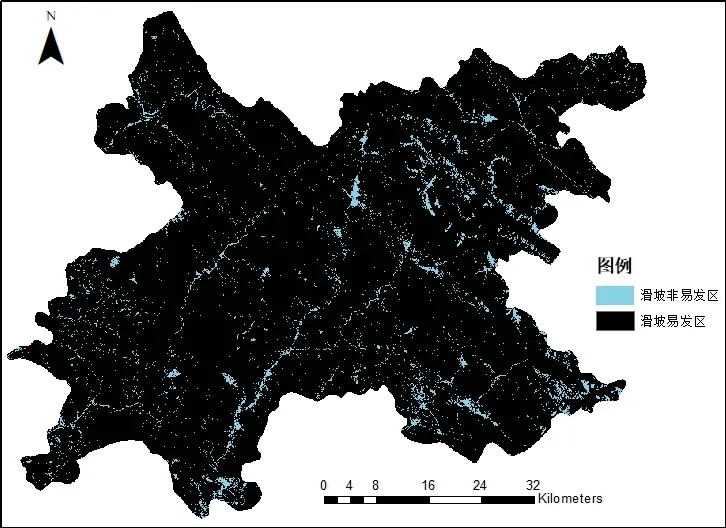
圖5 隨機森林預測結(jié)果
4 結(jié)論與展望
滑坡預測以滑坡監(jiān)測點滑坡分布為基礎(chǔ),考慮滑坡的誘發(fā)因素,采用隨機森林算法研究滑坡空間分布特征。隨著隨機森林中決策樹個數(shù)的不斷增加,隨機森林的訓練精度不斷提高,當決策樹個數(shù)為20時,訓練集精度達到0.998706256,測試集精度達到0.931731589,滿足實際要求。但是由于時間和能力限制,仍有很多問題急需探討研究。
(1)滑坡是一個動態(tài)的復雜系統(tǒng),滑坡系統(tǒng)的隨機性導致預測模型存在許多不確定因素。而文中涉及的模型算法的誘發(fā)因素輸入、模型結(jié)構(gòu)及參數(shù)都是確定性的,而忽視了滑坡系統(tǒng)的隨機性和模糊性特征。
(2)文中采用單時相遙感影像對研究區(qū)域滑坡空間分布規(guī)律進行探究,而忽視了時間維度上的演變過程。未能從時間角度,探討滑坡地質(zhì)災(zāi)害發(fā)生與相關(guān)影響因素之間的聯(lián)系,建立動態(tài)滑坡空間演化模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農(nóng)業(yè)(2021年9期)2021-11-26 07:41:24
發(fā)明與創(chuàng)新·小學生(2021年3期)2021-03-25 11:48:49
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
核科學與工程(2015年4期)2015-09-26 11:59:03
電測與儀表(2015年5期)2015-04-09 11:30:52
