地鐵乘客站點的選擇行為分析及預測
2022-07-15 08:10:36肖健和李明倫
電子科技大學學報 2022年4期
關鍵詞:模型
王 璞,肖健和,李明倫,郭 寶
(1. 中南大學交通運輸工程學院 長沙 410075;2. 軌道交通大數據湖南省重點實驗室 長沙 410075)
地鐵是城市公共交通的骨干,具有速度快、運力大等優點[1]。發展地鐵被廣泛認為是緩解大城市交通擁堵的有效方法[2]。但新建或擴建現有地鐵線路需要高額投資,因此在規劃階段需要詳細評估所規劃的線路能否滿足居民的實際出行需求。研究地鐵網絡擴建中乘客的站點選擇行為,對于地鐵新線路的規劃和選址,以及提高地鐵新線路的運營管理水平具有十分重要的理論和實際意義。
步行是乘客到達地鐵站點的主要方式[3],乘客從出行起點到地鐵站點間的步行距離是影響乘客出行選擇的重要因素。但在過去的研究中,由于難以獲取高空間分辨率的乘客出行起點信息,研究人員通常利用集計模型研究步行距離與站點選擇之間的關系。文獻[4]基于乘客購買火車票的郵政編碼數據,以郵政編碼區中心點為乘客出行起點,分析了荷蘭鐵路出行用戶對火車站點的出行選擇。文獻[5]基于日本東京交通小區至地鐵站點的客流數據,提取交通小區到地鐵站點的道路網絡距離,構建乘客出行站點選擇模型。文獻[6]采用將個人層面數據匯總的方法,利用上海市人口柵格數據,以柵格中心點和地鐵站點之間的距離作為乘客步行距離進行乘客出行站點的選擇分析。集計模型以交通小區為研究對象,缺乏乘客個體特征,對模型預測準確性會造成一定的影響。
非集計模型以實際交通出行的個人為單位,研究結果可以更好地反映個體選擇行為,因而在新地鐵線路的出行需求評估中得到廣泛應用。在地鐵網絡擴建情景相關研究中,國內外研究人員通常基于調查數據獲取乘客出行特征和個體特征,使用非集計模型進行乘客個體選擇地鐵新線路的行為分析。文獻[7]對希臘雅典的居民進行意向(stated preference,SP)調查,包括乘客的出行時間、出行成本、出行目的等出行特征,構建層次極值Logit 模型探究新地鐵線路開通后乘客選擇不同交通方式的驅動因素。文獻[8]利用SP 調查方法,調查了不同性別、職業、收入、出行目的的乘客在西安新地鐵線路開通前后出行方式的選擇情況,通過邏輯回歸模型分析了更傾向于使用新地鐵線路的乘客的個體特征。文獻[9]借助烏魯木齊市居民的出行方式選擇行為SP 調查數據,不僅調查了出行者的出行特征和個體特征,還調查了居民對交通信息的獲取和采納情況以及乘客的出行方式選擇習慣,構建巢式 Logit模型,預測了新地鐵線路開通后各出行方式的出行分擔比例。利用調查數據研究乘客個體選擇使用新地鐵線路的驅動因素,方法簡單易行。但這通常需要耗費巨大的人力和物力資源,并且受樣本代表性的影響較大。
近年來,數據驅動的方法被廣泛用于研究各類交通問題,如交通流量的估計[10]、交通速度分布估計[11]、出行需求預測[12]等。公交數據的空間分辨率較高,被廣泛用于研究公交網絡瓶頸路段甄別[13]、公交乘客的移動模式[14]、通勤模式[15]以及來源信息[16]。大數據技術和雙層交通網絡融合方法[17-18]的不斷成熟,使得大范圍研究地鐵乘客的站點選擇行為成為可能。因此本文通過融合公交、地鐵智能卡數據及公交車GPS 軌跡數據,采用大數據驅動的方法在更精細的空間尺度上分析了乘客公交出行質心與地鐵站點之間的距離對乘客選擇新地鐵站點的影響,并進一步建立Logit 模型預測乘客是否選擇使用新地鐵站點。
1 數 據
1.1 深圳市公共交通地理信息數據
深圳市地鐵地理信息系統(geographic information system, GIS)數據由深圳市交通運輸委員會提供。2016 年10 月28 日前,深圳地鐵共有6 條線路(1~5 號線、11 號線),132 個站點。2016 年10 月28 日,深圳地鐵7 號線、9 號線開通運營,站點數量增加到166 個。7 號線和9 號線與16 個換乘站相連。
深圳市公交站點GIS 數據也由深圳市交通運輸委員會提供,深圳市共有公交站點9114 個。公交站點密度遠高于地鐵站點密度,這意味著利用公交站點能夠以更高的空間分辨率記錄乘客的出行起點位置信息。而且,在地鐵新線路投入運營之前,公交站點就已經存在。因此在新地鐵站點投入運營之前,其周邊的公交乘客出行信息可以用于預測乘客在新地鐵站點開通后的出行行為。
1.2 乘客智能卡數據
本文所使用的地鐵智能卡數據和公交智能卡數據均由深圳市交通運輸委員會提供。在兩組智能卡數據中,乘客擁有唯一的匿名ID。因此,可以同時研究一個乘客的公交出行和地鐵出行。這為從乘客歷史公交出行中推斷出該乘客未來的地鐵出行起點創造了條件。
地鐵智能卡數據的收集時間為2016 年8 月?2016年12 月,共有10775905 名乘客產生了599786003條地鐵智能卡記錄。其中有12 天數據缺失,本研究僅使用剩余的141 天地鐵智能卡數據。每條地鐵智能卡記錄包含乘客ID、記錄時間、交易狀態和設備編號。根據設備編號可以得到乘客進站或出站的站點ID。
公交智能卡數據的收集時間為2016 年8 月?2016年12 月,共有10112676 名乘客產生了451814608條公交智能卡記錄。每條公交智能卡記錄包含乘客ID、公交車牌號和記錄時間。
1.3 公交車GPS 軌跡數據
為了推斷地鐵新線路開通前乘客的公交上車站點,本研究使用了2016 年8 月?2016 年10 月的公交車GPS 軌跡數據。每條數據記錄包含公交車牌號、記錄時間、公交車經緯度,在數據記錄期內共有16192 輛公交車產生了3632007303 條公交車GPS軌跡記錄。具體信息如表1 所示。
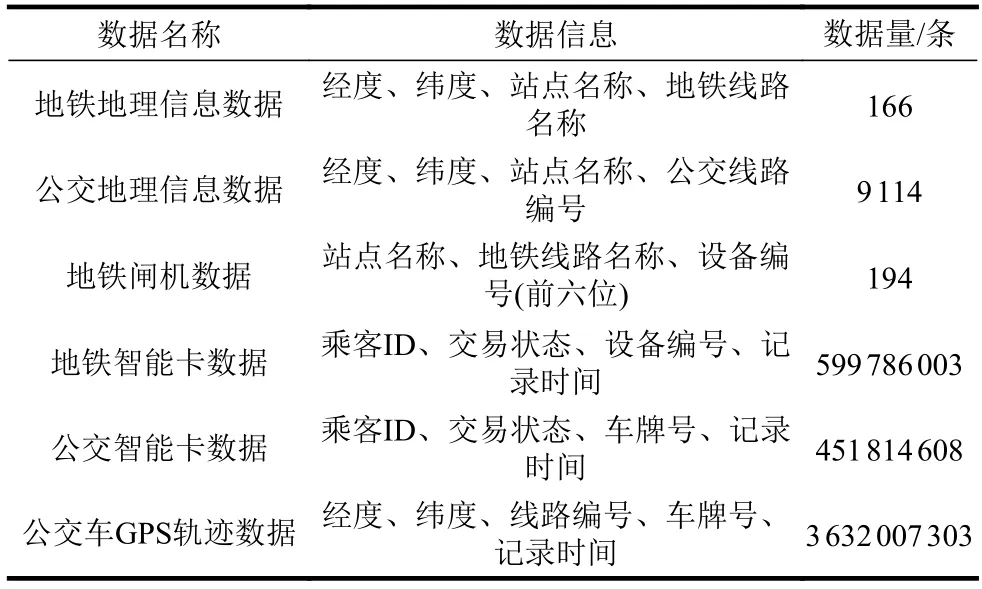
表1 深圳市公共交通數據信息表
2 方 法
為了利用乘客公交出行數據充分探究乘客出行起點與地鐵站點間的步行距離對乘客使用新地鐵站點的影響,本文首先分析了地鐵站點吸引區域及競爭地鐵站點,并提出了識別被新地鐵站點吸引的乘客及未被新地鐵站點吸引的乘客的方法。在此基礎上,利用居民空間行為指標——出行質心,計算乘客的公交出行質心,并將乘客的公交出行質心估計為乘客的出行起點,計算乘客出行起點與地鐵站點間的步行距離。
2.1 識別地鐵站點吸引區域和競爭地鐵站點
為了確定可能使用新地鐵站點的乘客,首先分析了地鐵站點的吸引區域。如圖1 所示,以地鐵站點為圓心,半徑800 m 內的區域被估計為地鐵站點的吸引區域[19-20]。地鐵站點吸引區域內的乘客更偏向乘坐地鐵出行。當新地鐵站點的吸引區域與既有地鐵站點的吸引區域重疊時,部分乘客可能會由在既有地鐵站點乘車轉變為在新地鐵站點乘車。其中,將吸引區域與新地鐵站點有重疊區域的既有地鐵站點定義為競爭地鐵站點。
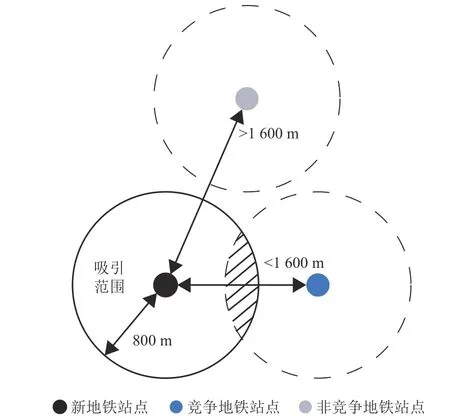
圖1 新地鐵站點的競爭地鐵站點與非競爭地鐵站點示意圖
2.2 識別地鐵新線路潛在影響的乘客
研究乘客的站點選擇行為需要獲取該乘客的歷史出行數據。在新地鐵站點及其競爭地鐵站點的吸引區域內至少有3 次公交出行且在新線路開通前平均每周使用地鐵大于等于1 次的乘客被定義為潛在受影響的乘客。新線路開通后,平均每周使用新地鐵站點大于等于1 次,且使用新地鐵站點次數大于使用競爭地鐵站點次數的潛在受影響乘客定義為被吸引乘客pa;新線路開通后,平均每周使用競爭地鐵站點大于等于1 次,且使用競爭地鐵站點次數大于使用新地鐵站點次數的潛在受影響乘客定義為未被吸引乘客pna。
2.3 推斷乘客公交上車站點
乘客歷史公交出行的上車站點數據是計算乘客公交出行質心的基礎。采用以下方法獲取乘客的公交上車站點。首先將公交車的GPS 記錄點按時間排序,將公交軌跡根據公交線路的起終點分為多段公交行程。然后,計算每個公交車的GPS 記錄點與該線路中每個公交站點k之間的距離,將每段行程中距離k站點最近的GPS 點的記錄時刻視為公交車b在k站 點的停靠時刻,依此可以得到所有公交車b在各個公交站點的停靠時刻。最后,對于每個乘客乘車記錄p,以車輛到達各站點的時刻作為聚類中心,以最小時間差為標準,將乘客的乘車記錄時刻聚類到各個類別中,各聚類中心的站點k為該類別中乘客的上車站點k[16,21-22]。
2.4 計算乘客公交出行質心與新地鐵站點、競爭地鐵站點間的距離
如圖2 所示,新地鐵站點與競爭地鐵站點吸引范圍的并集構成了研究乘客地鐵站點選擇行為的區域。經統計,深圳地鐵站點800 m 吸引范圍內平均有26 個公交站點,公交站點的分布密度遠高于地鐵站點的分布密度。文獻[23]研究發現,公共交通密度更高的區域,乘客的平均步行距離更短。乘客乘坐公交的平均步行距離要遠低于乘坐地鐵的平均步行距離,這意味著公交站點能夠以更高的空間分辨率記錄乘客的出行起點位置信息。綜合考慮每個公交站點的位置和乘客在公交站點的上車次數對乘客的出行起點進行估計。
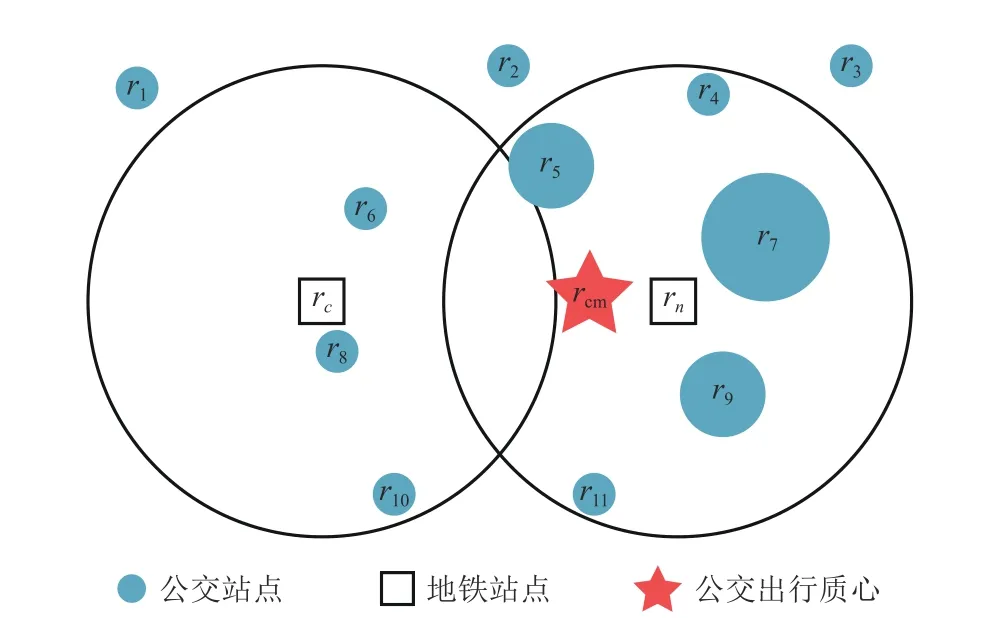
圖2 乘客公交出行質心計算示意圖
近年來,居民空間行為分析與建模領域發展迅速[24-28],本文利用居民空間行為指標——出行質心[29]以及乘客的公交上車站點來計算乘客的公交出行質心,并將該位置估算為乘客的出行起點。其中,對于乘客的公交上車站點,不考慮乘客從地鐵換乘公交時的公交上車記錄,即乘客從地鐵出站后30 分鐘內的公交上車記錄[17]。
乘客公交出行質心的計算方法如圖2 所示,對于每個潛在受影響乘客,將研究區域內的公交站點(如r4,r5,r6,r7,r8,r9,r10,r11)視為質點,不考慮研究區域外的公交站點(如r1,r2,r3)。然后將乘客在每個公交站點的上車次數作為每個質點的權重,反映在圖2 中為圓圈的大小。最后,加權平均各個質點的位置得到乘客公交出行質心:
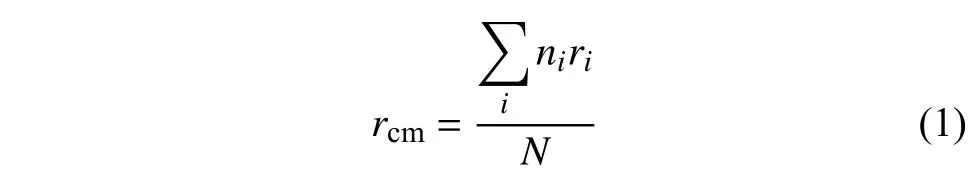
式中,i為公交站點序號;ni為 乘客在公交站點i的上車次數;ri為 公交站點i的位置坐標;N為乘客的公交出行總次數。
在計算了每個乘客的公交出行質心rcm后,分別計算乘客公交出行質心rcm與 新地鐵站點rn和競爭地鐵站點rc之 間的距離,分別用dn和dc表示,用于評估乘客從出行起點前往新地鐵站點和相應競爭地鐵站點的便利程度。
3 結 果
3.1 乘客地鐵出行站點選擇行為分析
分別對被吸引乘客pa和 未被吸引乘客pna的公交出行質心rcm與 新地鐵站點rn、 競爭地鐵站點rc間的距離dn和dc進行分析,如圖3 所示。結果表明,有79.94%的被吸引乘客的公交出行質心更靠近新地鐵站點(dc?dn>0),而86.37%的未被吸引乘客的公交出行質心更靠近競爭地鐵站點(dc?dn<0)。結果表明,大多數乘客(86.15%)使用地鐵出行時會選擇距離他們公交出行質心更近的地鐵站點。
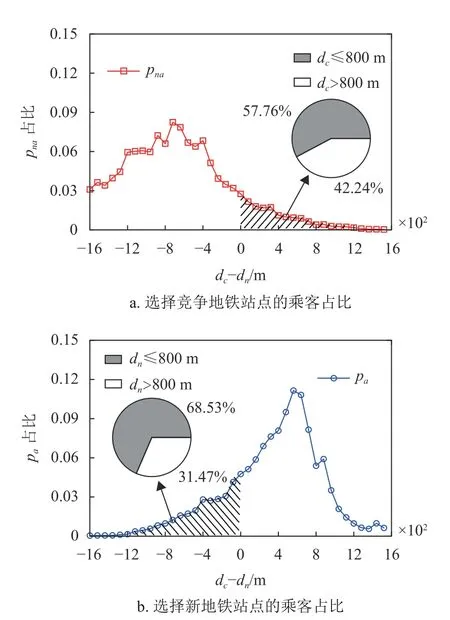
圖3 不同d c ?dn 下的乘客地鐵出行站點選擇概率
少數乘客在使用地鐵出行時會選擇距離其公交出行質心較遠的地鐵站點,這可能是因為乘客的公交出行質心在兩個站點吸引區域的重疊區域內,距離因素的影響有所降低。如圖 3 所示,對于被新地鐵站點吸引但質心離競爭地鐵站點更近的乘客,有68.53%的乘客質心在新地鐵站點800 m 的吸引范圍內;而未被新地鐵站點吸引但質心離新地鐵站點站更近的乘客,有57.76%的乘客質心在競爭地鐵站點800 m 的吸引范圍內。
3.2 乘客地鐵出行站點選擇預測
Logit 模型是研究出行選擇行為時常用的離散選擇模型。Logit 模型假設出行者會選擇隨機效用最高的交通方式,被廣泛應用于交通方式劃分問題。本文使用Logit 模型預測乘客是否會選擇乘坐新地鐵站點。
本文利用乘客公交出行質心與地鐵站點間的距離(dn和dc)建立Logit 模型,選擇使用新地鐵站點與其相應競爭地鐵站點的概率關系為:
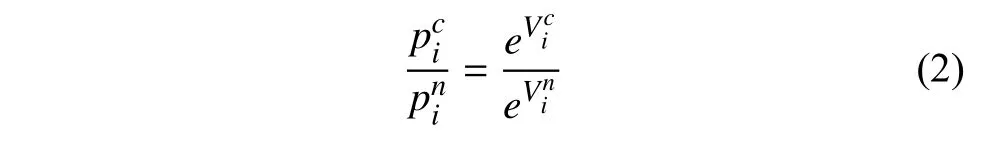
其中,
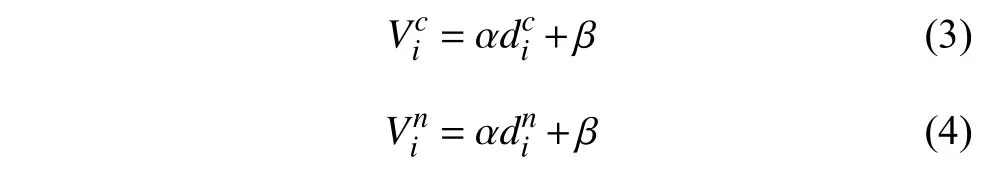
因此,
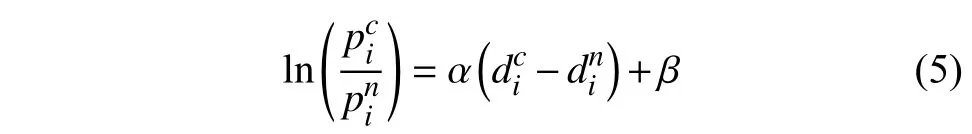
本研究隨機抽取50%的乘客數據集作為模型的訓練集,剩余50%的數據集作為模型的測試集。由于數據集中被吸引乘客pa和未被吸引乘客pna樣本數之比約為1:30,屬于典型的類別不平衡問題。本文通過欠采樣[30]來調整數據的不平衡,即隨機抽取數據集中未被吸引乘客pna,使得模型的訓練集和測試集中的被吸引乘客pa和未被吸引乘客pna的樣本數保持相同。然后借助極大似然估計方法(式(6)),求得 α=1.003, β =1.297 2。Logit 模型預測結果的混淆矩陣如圖4 所示。

圖4 Logit 模型預測結果的混淆矩陣
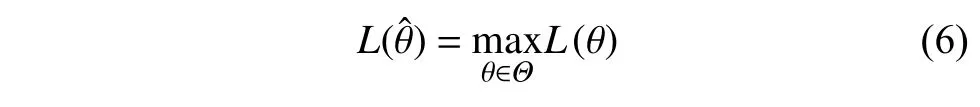
其中,
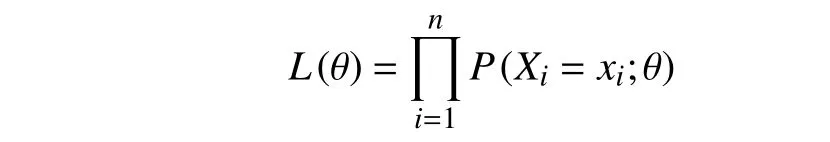
式中,xi為 樣本Xi的觀測值,Xi∈X;P(Xi=xi;θ)為總體X的分布律; θ是未知參數, θ ∈Θ , Θ是參數空間。
準確率(accuracy)、精確率(precision)、召回率(recall)、特異性(specificity)是確定分類模型性能的常用度量指標[31],分別為:
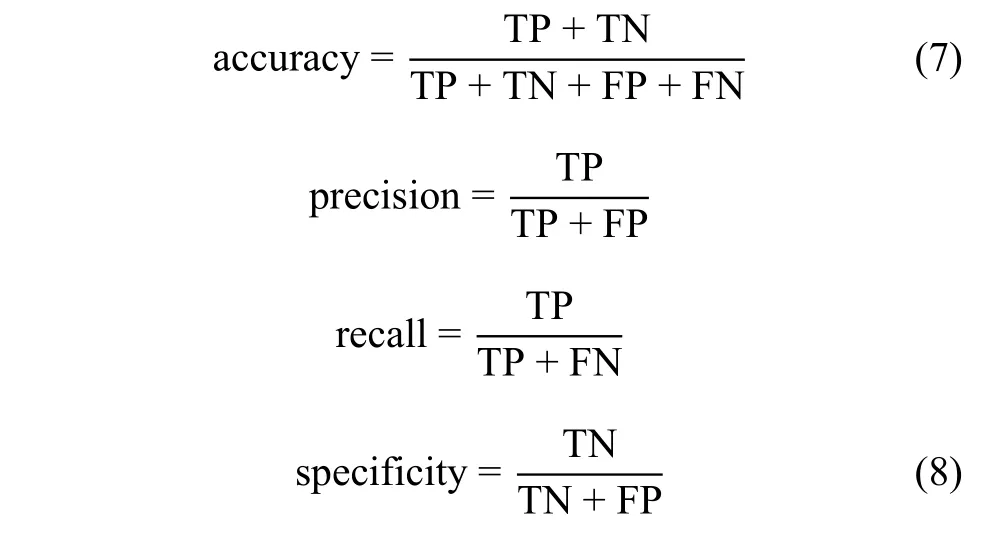
式中,TP 表示實際是pa且預測為pa的數量;FN 表示實際是pa但預測為pna的數量;FP 表示實際是pna但 預測為pa的 數量;TN 表示實際是pna且預測為pna的數量。
Logit 模型的準確率為83.87%,精確率為84.23%,召回率為83.66%,特異性為84.09%。結果表明,通過引入出行質心度量,Logit 模型能夠有效預測潛在受影響乘客出行時是否會使用其公交出行質心附近的新地鐵站點或繼續使用競爭地鐵站點。
Logit 模型是乘客出行選擇研究的傳統模型。地鐵乘客的站點選擇問題屬于二分類問題,BP(back propagation)神經網絡和支持向量機(support vector machine, SVM)是機器學習中解決二分類問題的常用方法,部分研究人員也通過機器學習中BP 神經網絡[32]和支持向量機[33]對乘客的出行選擇進行預測。
BP 神經網絡是一種誤差逆向傳播的多層前饋神經網絡,該網絡包含了輸入層、隱藏層和輸出層, 本文以乘客公交出行質心與地鐵站點間的距離(dn和dc)作為輸入,乘客是否選擇新地鐵站點作為輸出。本研究隱藏層取7 個節點數,隨機數生成器選取種子數為1,懲罰參數為0.00001、采用默認的激活函數(relu 函數)、最大迭代次數200、優化容忍度0.0001。本文首先通過式(9)對輸入特征進行歸一化,并根據式(10)得到隱藏層節點個數K。最后以最小化誤差為目標,通過擬牛頓法優化器進行優化求解,取誤差最小的隱藏層節點數的結果作為預測結果:
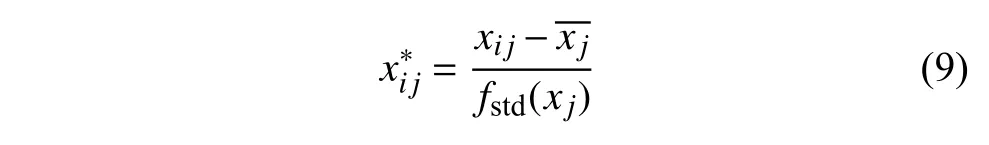
式中,xij為樣本i的 第j個特征;為歸一化后的特征;為第j個特征的均值;fstd(·)為標準差函數。
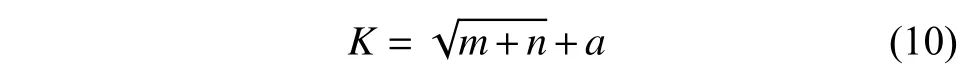
式中,K是隱藏層的節點數;m是輸入層的節點數;n是 輸出層的節點數;a是0~10 之間的整數。
SVM 是一種監督學習的分類器,它通過輸入特征構建的特征空間中的超平面,將待學習樣本進行分類。本文基于乘客公交出行質心與地鐵站點間的距離(dn和dc)作為輸入特征,通過式(9)進行歸一化,利用多項式核函數,對乘客的出行站點選擇進行分類學習和預測。本研究使用的錯誤項懲罰系數為1,核函數階數為3,核函數系數為樣本特征數的倒數,核函數獨立項為0,采用啟發式收縮方式,取0.001 為停止訓練的誤差精度。
3 類模型的乘客站點選擇分類預測結果如表2所示。

表2 3 類模型的乘客站點選擇預測結果
3 類模型的預測結果差異不大且都表現良好,這表明基于乘客出行質心的方法能夠有效地對乘客出行站點選擇進行預測。Logit 模型在3 類模型中不僅有更高的精確率(84.23%)和特異性(84.09%),而且Logit 模型基于隨機效用理論進行選擇預測,相較于機器學習模型有更好的可解釋性。
4 結 束 語
1) 通過利用數據互補、跨交通方式數據融合技術,在更精細的空間尺度上分析了地鐵乘客出行站點的選擇行為,彌補了先前研究通過調查獲取數據的不足,提出了研究地鐵乘客站點選擇行為的新方法。
2) 引入居民空間行為指標——出行質心,發現乘客公交出行質心與地鐵站點間的距離是影響乘客使用新地鐵站點的重要因素,并建立了相應的站點選擇Logit 預測模型,為探索影響乘客使用新地鐵站點的因素提供了新思路。
3) 研究發現乘客通常會選擇距離自身公交出行質心更近的地鐵站點,研究有助于在地鐵新線路開通前識別被新地鐵站點吸引的乘客,為地鐵新線路的選址規劃及運營管理提供關鍵信息。
4) 由于缺乏步行數據,本文估算的乘客出行起點與實際出行起點存在一定的誤差。未來在獲取步行數據的情況下,可在現有研究基礎上研究地鐵站點的實際吸引區域,預測新地鐵站點開通后從競爭地鐵站點到新地鐵站點的客流轉移。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
