情智信息的建模與應用
2022-07-23 10:34:26葉龍段丹婷鐘微胡飛張勤
中國傳媒大學學報(自然科學版) 2022年2期
葉龍,段丹婷,鐘微,胡飛,張勤
(1.中國傳媒大學媒體融合與傳播國家重點實驗室,北京 100024;2.中國傳媒大學媒介音視頻教育部重點實驗室,北京 100024)
1 引言
在經過幾十年發展而逐步健全的人工智能技術體系支持下,針對文本、音頻、視頻等數據的分析與處理技術有效地解決了人類在體力勞動過程中的諸多問題:工業生產中的操作問題、醫療手術中的控制問題、駕駛與航行中的導航問題、圖像識別與知識搜索問題等等。然而,在信息技術飛速發展的今天,我們不能將目光停留在僅通過人工智能技術來實現對人類體力的解放上,如何將其應用于服務人類智力發展的新型媒體上將是未來信息技術領域研究的核心問題之一。
信息技術如何促進智力水平的提高對人類社會的發展具有重要的意義。從情感與智力關聯性角度的研究發展來看,人類智力是以腦活動為基礎的,而智商的高低取決于皮層神經元的工作效率與相關信息的存儲。早在1937年,Kluver和Bucy就曾通過實驗發現[1],猴子邊緣性區域(尤其是顳葉內側杏仁核區域)的損傷會帶來“精神失明”——盡管動物保留了正常視力,但是視覺刺激失去了它們的情感意義,影響對外界事物的認知。此后的大量研究也證實了大腦邊緣區域在刺激信息加工過程中的主觀作用[2-5]。Hanying通過實驗驗證[6]注意力對視覺刺激誘發響應具有調制作用,在不同背景腦電與刺激強度條件下注意力的調制作用是不同的。在特定腦電節律振蕩與初始相位及視覺刺激對比度高時,注意力對視覺刺激響應有顯著調節作用。因此,在視聽刺激下,人體的生理信號(主要包括外周生理信號和腦信號等)會產生一系列的變化,對應不同的情感狀態。良好的情境會使人產生愉悅的情感,有助于集中注意力,進而提高大腦的活動效率,由情感變化導致的注意力改變會直接影響大腦對視聽刺激的接收。情感與智力表現之間存在一定的相互影響作用,智力是情感的基礎,并引導情感的發展。只有通過對客觀事物的反映,主體才能確定客觀事物是否滿足自身的需求,從而產生相應的態度體驗,進而引發不同的情感,而情感反過來對認知過程也起調節作用。
從音視頻等信息與情感關聯性角度的研究發展來看,情感與音樂有著緊密的關系,情感對人的思維與行為一直存在著重要的調控作用,情感是音樂影響智力表現的重要橋梁[7]。心理學實驗表明[8],當一個人欣賞喜愛的音樂時,更容易激發積極的情感,從而有效地促進其智力水平的正常發揮。音樂認知可以在很大程度上活化腦力,鍛煉、提高大腦的工作效率,從而起到促進智力正常或者超常發揮的作用。雖然音樂和智力之間的關聯為人所知,但還是處于知其然不知其所以然的階段,對這種關聯的模型和關聯的度量都缺少科學的研究與本質的認知。因此,本文從情感角度出發,針對信息、情感與智力發展的耦合問題進行研究,給出了情智模型的定義及其研究范疇,提出了六覺(聽覺、視覺、味覺、嗅覺、觸覺和意境知覺)交叉感知模型以建立起情感與智力互通的橋梁,并在此基礎之上構建了服務于人類智力發展的情智模型。此外,在構建的情智模型指導下,實現了腦波信號驅動的情感音樂生成系統,從而達到促進人類智力水平提升的目的。
2 情智模型的提出
2.1 情智模型的定義
情感與智力是人類進化的結晶,情感是人類各種機械能力之上的核心抽象概念,提供了人類行為和思維管理與調制的機能。智力被認為與一系列認知任務的表現有密切聯系,智力發展意為在這些認知任務中智力的表現情況[9]。人的信息接收、情感生成與智力表現是一個相互耦合的過程。如果把用于影響人的智力表現的情感信息稱為情智信息的話,對人類自我認知的主要科學問題之一就是信息、情感與智力發展的關系與機理,本文將其定義為情智模型。如圖1所示,未來的智能是具有完善類人功能的智能,我們認為,在類人方面,“信息+情感”的非理性調節與“訓練+記憶”的理性調節同樣重要。情智模型的研究目的是要通過實現理性調節與非理性調節的耦合,從而達到完善的類人智能。
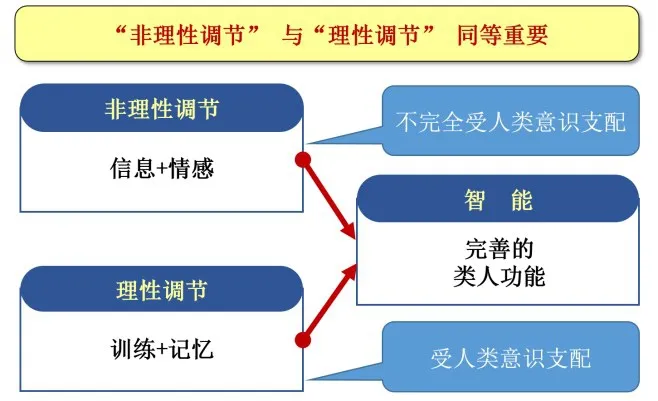
圖1 情智模型的研究目的
2.2 與現有研究的關聯
近年來,基于深度神經網絡的特定機器學習方法在人工智能領域占據了主流,從而使得計算機視覺、人機交互等技術能夠更好地體現出服務于人類體力發展的價值。然而,針對服務于人類智力發展的情感表征方式與處理方法的研究,目前國內外還基本處于空白階段。因此,本節主要從以下兩個方面體現情智模型與現有研究的關聯。
(1)情感與智力表現的交互作用
情感是人類一種重要的本能,在人們的日常生活、工作、交流、處理事務和決策中扮演著重要的角色[10]。從美國哲學家James提出“情感是什么?”[11]這個問題到現在,“情感”始終是心理學及哲學領域里引人注目的研究對象。一百三十年后的今天,“情感”已經變成了神經科學、生物學、工學、社會學、經濟學等諸多領域的重要研究對象。在已有的研究中,離散表示和連續(維度)表示是兩種最基本的情感描述形式。以Ekman為代表的基本情感模型[12]將情感狀態分類成離散的情感類別,根據情感的純度和原始度,可以將情感劃分為基本情感(主要情感或原始情感)和復合情感(次要情感)兩大類。Ekman提出的六種基本情感:生氣、害怕、難過、驚訝、高興和厭惡在情感計算領域認可程度較高[13]。與此類似的理論還有“調色板理論”[14]。Buck從生理情感、認知狀態情感、社會情感和精神狀態情感等方面分別給出了基于不同角度的基本情感類型[15]。
近年來,隨著交叉領域研究的興起,對于“情感”的研究正朝著一個通過跨領域的研究來探索的新方向前進。情感影響智力表現的研究往往聚焦于情感對認知能力的影響,尤其是注意力和情感的相互作用過程。考慮到事件流進入認知系統的過程及認知系統處理能力的限制,情感和注意力的產生均包含一個關鍵過程——相對于中性或一般事件,會優先處理相關事件,這就導致了知覺分析的增強、記憶和運動行為的激活。因此,面部表情和聲音中社會信號的情感處理可能與注意力相關機制密切關聯。有結果表明[16-19],具有特定情感相關性的視覺事件,如面部表情或情感圖片,也能比中性事件更容易吸引人們的注意力。Sander等人通過功能磁共振實驗探究了聲音情感刺激與個體注意之間的關系,根據實驗中受試者呈現出的憤怒和中性聽力范式下的表現,確定了人類情感的產生受個體內部注意力的調節,以及聽覺區域存在對情感信號加工的調節機制[16]。Blair等人用情感Stroop范式進行實驗,指出至少在一些患者中,額葉外側及中間皮層的能力下降,會導致情感和焦慮障礙患者抑制情感對目標產生注意力的能力受損[17]。
另外,情感與記憶之間也存在一定的聯系。早在1981年2月,美國斯坦福大學心理學家Pourtois在《美國心理學家》雜志上介紹了他的一項研究成果[18],記憶力與人的情感狀態密切相關并提出了記憶與情感相關效應假說。Phelps研究發現[19],在不同的情感狀態中,杏仁核可以調節依賴于海馬體的記憶編碼和存儲功能,而海馬復合物通過形成情感意義和事件解釋的情節表征,可以影響遇到情感刺激時的杏仁核響應,這進一步說明了情感會對人的記憶產生一定的影響。
目前大多數關于情感與智力表現相互作用的研究都是基于單一感覺刺激的。然而已有研究表明,大多的情感都是多種刺激疊加誘發而成的,即聽覺、視覺、味覺、觸覺、嗅覺等多感覺刺激下所產生的復雜的情智信息。因此需要開展基于多種感覺刺激下的情感影響智力表現的基礎理論研究,分析多感覺刺激下不同感知系統的信息交互和作用、系統之間信息的不同表示形式和信息傳遞的方式。通過研究多感覺刺激下情感對包含感覺、知覺、注意力、記憶等在內的認知的影響,構建多感覺刺激下情感促進智力表現的多媒體模型,才能夠進一步地開發人的大腦,豐富精神世界、培養創新意識,從而促進人的智力發展。
(2)情感模型
情感分析被證明是一個融合心理學、社會學、神經科學、計算機科學等多學科高度交叉融合的研究領域。2012年,Koelstra等人[20]提出了一個用于分析人類情感狀態的多模態數據庫,并研究了各個生理信號與主觀情感分析之間的相關性。這些生理反應信號包括心率變異性(Heart Rate Variability,HRV)、腦電圖(Electroencephalogram,EEG)、皮膚電導(Skin Conductance,SC)、血容量脈搏(Blood Volume Pulse,BVP)和呼吸率(Respiration Rate,RR)。悉尼大學的Daniel等人[21]收集了65名志愿者休息狀態下的HRV,實驗表明HRV能夠為識別人類情感提供新的標記。Fabien等人[22]通過提取RECOLA數據庫中包括HRV在內的生理信號以及音視頻特征,采用時序神經網絡預測回歸模型,并對比特征級融合與決策級融合的結果,確定每段音視頻的最優喚醒度——效價值。Anuharshini等人[23]通過受試者的HRV和RR這兩個生理參數的有效變化以及行為反應來研究兩種印度古典音樂的情感反應。Cabredo等人[24]通過提取音樂切片的特征以及聽眾對應的BVP指數,采用生物學的motif發現算法構建出音樂特征和生理特征的映射關系。Takahashi等人[25]使用音頻內容進行心理學實驗以激發受試者的情感,來收集生物電位信號。測量實驗采集了兩種生命體征BVP和SC以評估三種情感:積極情感(放松和愉悅),消極情感(壓力和不愉快)和中性情感,并采用支持向量機(Support Vector Machines,SVM)設計情感識別系統,對于三種情感實現了41.2%的識別率。
EEG信號是一種非侵入性的腦機接口,它允許外部機器在沒有手術的情況下感知來自大腦的神經生理信號。從中樞神經系統捕獲的非侵入性EEG信號已被用于探索情感,這種與個性化差異關聯性較小的特征能更好地用于情感分析的研究。Tanu Sharma等人通過實時提取各個參與者在不同情感下的生理信號包括HRV、BR、BVP、EEG,探究各種生理信號與情感之間的關聯性[2]。日本大阪大學產業科學研究所的Cabredo等人針對個人的音樂感受獨立性,提出了基于EEG信號的音樂模型,通過記錄多人聽取音樂的EEG信號以及相應的個人情感標簽,對EEG信號的譜特征和情感標簽做了關聯性分析[3]。新北市輔仁天主教大學的Hsu等人提取音樂特征和個人EEG信號特征,通過人工神經網絡融合兩種特征完成了相應的情感分類任務[4]。Park等人通過生理信號識別主體的負面情感,其中皮膚電活動(Electrodermal Activity,EDA)、皮膚溫度(Skin Temperature,SKT)、心電圖(Electrocardiogram,ECG)和體積描記(photoplethysmography,PPG)被記錄為情感的生理信號,使用機器學習算法分析提取28個特征用于情感識別,并通過比較每個算法的識別結果來確定優選算法,結果顯示支持向量機(SVM)取得了最高的訓練精度,而線性判斷分析(Linear Discriminant Analysis,LDA)獲得了最高的測試精度[5]。
從上面的分析可知,現有的情感模型,無論是特征訓練的神經網絡模型,還是基于生理反應信號處理的模型,都沒有明確地揭示出激勵信號與人類情感之間的關系。因此,如何構建能夠真正反映出激勵與人類情感之間關系的模型,仍然是情感計算領域的基礎問題和難點問題之一。
3 情智信息的建模
目前,關于情智模型的研究工作主要集中在情感計算階段。關于情感的產生,至今還沒有一個合理的模型解釋。詹姆斯—朗格學說、丘腦情感學說、激活學說是目前主要的三種學說[26],而現有的關于腦科學的一些研究已經逐步驗證了激活學說的正確性,即情感的來源是對情景的評估,情景向腦提供感覺信息,引起皮層皮下的整合活動,產生情感體驗,整個過程是一種“場景—評價—情感”的激活過程。由這個模型導出的情感計算方式已經成為目前情智模型問題研究的基礎,但是無論在定性與定量的研究上,現有方式都存在很多不足,導致情感計算只有在特定的數據庫中準確率較高(作為一個數據處理問題),距離實際應用還有一定的差距。其主要原因是在研究復雜的情感問題時,采用了過于簡化的情感模型,缺少各種影響情感反應的調制因子,比如文化水平、經濟基礎、社會地位等。
眾多不同場景因素的人群會有不同的情感反應。另一方面,目前情智模型的研究也缺少各場景類型(聽覺、視覺、嗅覺等)交叉感知的橋梁。在情感產生的過程中,皮層下神經過程的作用處于情感形成的顯著地位,大腦皮層神經中樞、腦垂體、下丘腦、腎上腺等部位和腺體對情感起著調節作用。為了建立起情感智力互通的橋梁,本文把人的感覺場景按照聽覺、視覺、味覺、嗅覺、觸覺和意境知覺分別表述,提出了基于上述六覺的交叉感知模型,如圖2所示。該模型將情感產生過程中的神經類別分為感知神經和處理神經兩種神經元,各種感覺在情感層面耦合形成聯覺。
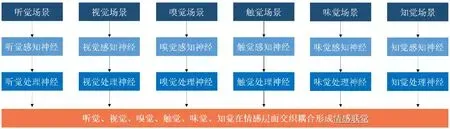
圖2 情感聯覺模型
在上述六覺情感聯覺模型的基礎之上,圖3給出了情智模型的構建過程。如圖3所示,情智模型是融合腦科學、生物學、心理學、人工智能、數字媒體等的交叉領域的研究,其以腦科學中情感影響智力的神經反應機理為基礎,通過采集多模態生理信號,在心理學領域尋求情感聯覺模型,使用人工智能領域的模型計算方法,結合數字媒體領域的數據生成手段,力求建立情感與智力耦合的橋梁。這里,情智模型是一個復雜的變參數的概率問題,可以表示為式(1):
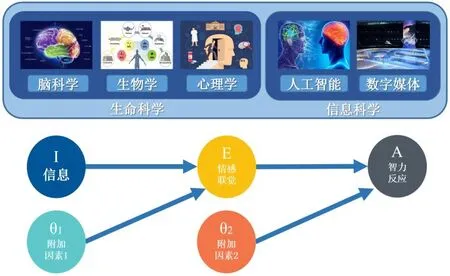
圖3 情智模型
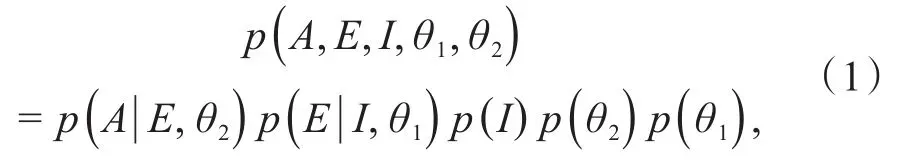
其中,A表示智力反應,E表示情感聯覺,I表示信息,θ1、θ2分別表示附加因素。
從科學領域的層面來看,隨著信息科學的發展和人工智能研究的不斷深入,科學家們對人類智能的認識也不斷深入,由人腦表現出來的心智現象不僅體現在單純智的方面,還體現在知覺、情感方面。智能并不是一個單獨或者割裂的人腦功能,智能和感知、情感等有著密切的聯系。在情感影響智力表現的研究中,情感對人腦認知能力、記憶能力的影響已經有了很多的測試數據作為佐證[27],因此人的信息接收、情感生成與智力表現是一個相互耦合的過程。情智模型的研究突破了以往人工智能研究單純從智能出發實現智能計算,在激發情感影響智能方向上獨樹一幟,使機器智能與情智模型相結合,真正朝著類人智能、類腦智能的方向開展原創性工作。已有的腦認知和心理學的模型可以作為情智模型研究的基石,但還遠遠不夠,通過多種方式進行情智模型建模,能夠推動情感和智力耦合的腦認知研究,促進大腦神經認知學和心理學的發展。
4 情智模型在音樂生成系統中的應用
音樂是人類傳遞情感的一種載體,也是抒發和表達人類情感的最佳工具,聽眾渴望從音樂中產生情感的共鳴[28]。因此,為聽眾生成符合心境的個性化音樂成為藝術創作領域的關鍵問題之一。然而,傳統的人工作曲方法不僅要求創作者具備扎實的樂理知識,而且創作過程耗時耗力。近年來,隨著人工智能與藝術融合技術的迅猛發展,如何借助計算機實現音樂生成已成為一個炙手可熱的課題[29]。
腦波音樂是將EEG信號按照特定的規則轉化而成的樂曲,它是一種兼具音樂性與生理性的新穎的音樂形式。EEG信號自1924年首次被發現并記錄以來,各個領域的學者圍繞EEG信號開展了大量的研究[30]。1934年,Andian和Mattews實現了人類腦波的發聲,從而開創了腦波音樂的先河[31]。遺憾的是,由于早期的研究局限于單一的EEG信號處理方式,腦波音樂效果并不理想。經過幾十年的發展,尤其是20世紀90年代以來,對腦波音樂的探索逐步深入,腦波音樂的實用價值受到越來越多學者的青睞[32]。現今,大量的腦波音樂涌入音樂市場,極大程度地提高了音樂創作的工作效率[33]。然而,在以往的腦波音樂生成研究中,大多忽視了對其情感表達的分析。對音樂作品的評價標準不應該僅停留在提升可聽性這個層面,一首好的音樂作品必定是會打動人心的。音樂作品的精髓就是情感產生共鳴進而激發人腦智力的其他表現。我們認為,在人工智能技術的加持下,對情智模型的探索將加速服務于智力發展的新媒體系統的開發,從而達到真正的類人智能。為了探索情智模型在音樂生成中的應用,本文設計并實現了一個EEG信號驅動的情感音樂生成系統,我們將此系統取名為“人人都是貝多芬”。顧名思義,通過使用此系統,任何人都可以像著名音樂家貝多芬一樣創作出優美動聽又情感飽滿的音樂。
4.1 “人人都是貝多芬”系統
“人人都是貝多芬”系統如圖4所示,該系統主要包括三個模塊,即EEG信號采集及預處理、EEG信號情感識別模塊和情感音樂生成模塊。首先,被試佩戴腦電帽觀看誘發情感的短視頻(短視頻時長24-177s,分為積極、中性、消極三種情感類型),采集被試觀看短視頻時的EEG信號。然后,對EEG信號進行預處理、提取差分熵特征。接著,將提取到的特征輸入分類器進行實時情感識別,得到情感分類結果。而后,由計算得到的情感類型驅動音樂生成網絡,生成帶有情感的個人專屬音樂。最后,將生成的情感腦波音樂作為新的情感誘發材料刺激被試產生情感,不斷循環上述步驟直到評價模型的評價指標收斂,從而得到最終反映被試真實情感變化的音樂。
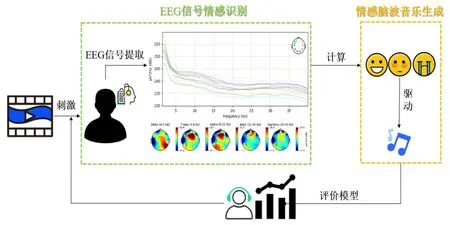
圖4 “人人都是貝多芬”系統流程圖
4.2 EEG信號采集及預處理
實驗環境由被試室和主試室組成。如圖5所示,EEG信號采集實驗在安靜、明亮的被試室進行,通過一臺24.5寸、刷新率為165 Hz的顯示屏呈現刺激。EEG信號數據通過無線便攜式腦電儀Emotiv EPOC X設備進行采集而得,其主要參數為14導(包括國際通用10-20系統中的AF3、F7、F3、FC5、T7、P7、O1、O2、P8、T8、FC6、F4、F8、AF4,共14個通道),0.2-43 Hz帶寬,256 Hz采樣頻率。被試的EEG信號數據通過EmotivPRO軟件記錄。同時,本系統還可使用MER-502-79U3C工業相機、Tobiipro眼動儀、GSR皮膚電傳感器采集被試的微表情、眼動、皮膚電阻等多種生理信號。為了避免電磁設備對EEG信號質量的干擾,被試室顯示屏與主機采用有線的方式連接。主機放置于主試室,主試通過主試室顯示器實時監控設備連接情況及被試狀態。
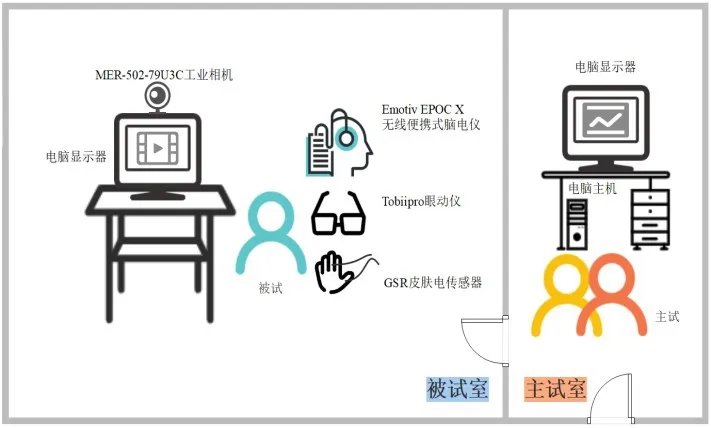
圖5 實驗環境示意圖
實驗開始前由1名主試向被試詳細說明實驗流程。當了解實驗流程后,被試被帶進被試室,由2名主試幫助他佩戴腦電帽,并提醒被試調整座椅至觀看舒適位置。正式采集數據前,被試先進行一次練習來熟悉這個系統。在15s基線記錄后,播放一段短視頻,然后被試填寫主觀評價。接下來,確保被試完全理解實驗流程、音量調整至合適大小后,主試提醒被試EEG信號采集實驗正式開始并離開房間,之后被試點擊屏幕上的“開始”鍵開始實驗。被試參與EEG信號采集實驗如圖6所示。

圖6 腦電信號采集情景圖
EEG信號預處理包括人工去除偽跡、濾波、特征提取。人工去除偽跡是為了避免實驗過程中由于補充腦電液而產生的干擾信號,以及由于被試頭部肌肉收縮、眨眼或眼球移動產生的明顯的肌電、眼電信號。濾波過程使用帶通濾波器保留了0.1-50 Hz頻率的EEG數據,陷波濾波器去噪50 Hz,采樣頻率設置為256 Hz。特征提取過程以2秒為一個片段進行切分,提取EEG信號在δ(1-4 Hz)、θ(4-8 Hz)、α(8-12 Hz)、β(13-30 Hz)、γ(31-45 Hz)五個頻段的差分熵特征[34]。
4.3 EEG信號情感識別模塊
實驗共收集了40名被試(男性20人、女性20人,平均年齡27.6歲、標準差為3.92)的EEG信號數據用于情感識別的分類器選擇。分類器性能的優劣直接影響了腦波音樂生成過程中輸入情感音樂生成網絡的情感類型是否準確。本文比較了機器學習方法中常用的11種分類器在EEG信號情感識別中的分類性能。這些分類器使用前面提到的差分熵特征作為輸入,將采集到的EEG信號數據按照8∶2的比例劃分訓練集和測試集,輸出為情感三分類結果(積極、中性、消極)。
圖7給出了不同分類器對EEG信號的情感識別結果。實驗結果表明,Gradient Boosting算法在分類準確率和泛化能力上表現最好,準確率達到了95%。因此,本系統選用Gradient Boosting算法作為EEG信號情感識別模塊的分類器。
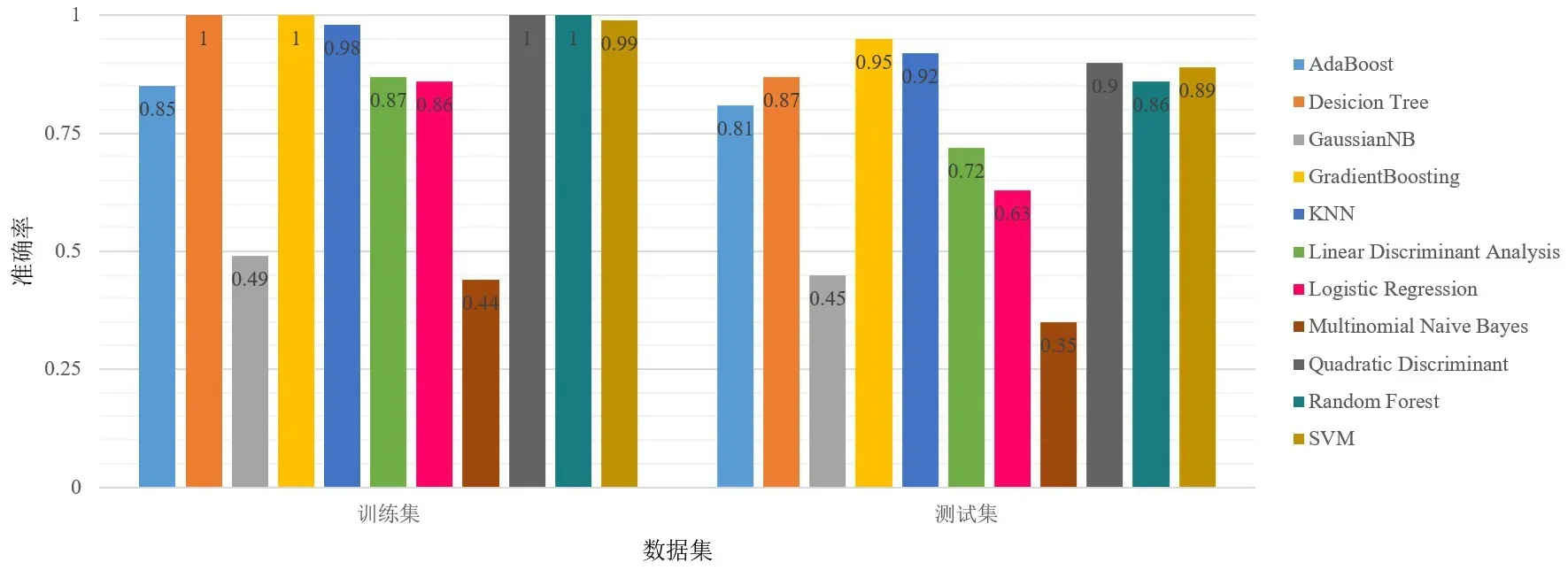
圖7 11種常見的機器學習算法情感識別結果
4.4 情感音樂生成模塊
在情感音樂生成模塊,將嵌入情感標簽和音樂結構特征作為條件輸入生成網絡,同時添加感知優化的情感分類損失函數,生成帶有情感的腦波音樂。該網絡模型包括情感音樂生成器和情感音樂分類器兩部分,如圖8所示。具體來說,情感音樂生成器采用自監督訓練模式來構建模型,將EEG信號的情感識別結果和音樂結構特征作為條件輸入,輸出為MIDI事件序列。在情感音樂分類器中,為了縮短生成的特征分布與真實特征分布之間的距離,對情感音樂分類模型進行預訓練。網絡的輸入是MIDI序列,輸出是情感分類的結果。
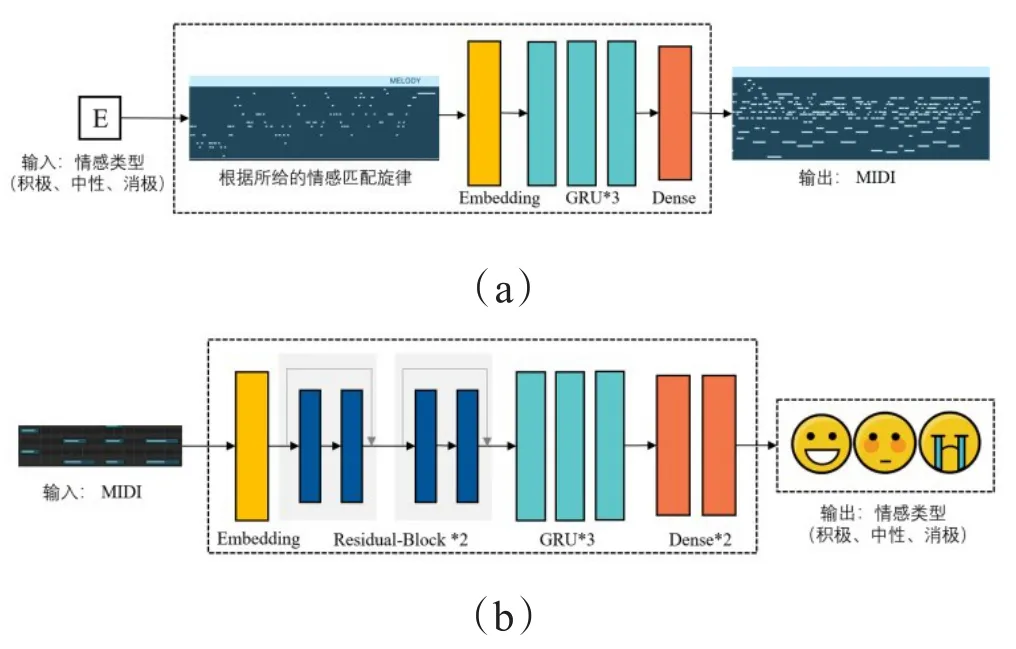
圖8 腦波音樂生成網絡
在系統中,使用VGMIDI數據集[35]進行模型訓練。VGMIDI的原始標簽分為積極和消極兩類,經主觀評價可將情感不突出的音樂片段標注為中性,得到情感標簽為積極、中性和消極三類的數據集。隨后,將EEG實時情感識別的結果輸入訓練好的音樂生成網絡,以控制網絡生成相應情感的音樂。
5 結束語
本文創新性地提出了“信息、情感與智力的耦合模型構建”這一科學前沿問題,創建了情智模型理論體系,并在此理論研究的基礎上,提出并實現了基于情智模型的腦波情感音樂生成系統,從而在“情智信息的感知、建模與生成”研究中邁出了堅實的一步。
情智模型問題涉及到未來信息技術、工業技術、國防科學、社會科學、醫療健康等多個關乎國計民生的重大領域,在現實應用中也將服務于我國新舊動能轉換、社會安全、城鄉均衡發展、“一帶一路”等國家戰略需求,具有很強的研究意義與應用價值。情智模型的研究突破了以往人工智能單純研究機器智能的局限,在激發情感影響智能方向上獨樹一幟,使機器智能與情智模型相結合,有助于真正實現類人智能、類腦智能。未來工作中,將針對“信息、情感與智力的耦合模型構建”這一重大科學前沿問題,圍繞情智信息的感知提取、建模表征、生成驗證三個層面,開展相關研究工作以創建情智信息理論體系,并在此理論研究的基礎上,探索基于情智耦合模型的音頻、視頻與場景的生成技術,構建情智信息理論驗證的音頻、視頻與場景數據測試平臺,從而建立服務于智力發展的新媒體理解架構。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
中國生殖健康(2020年5期)2021-01-18 02:59:48
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
電子制作(2018年11期)2018-08-04 03:25:42
兒童繪本(2017年24期)2018-01-07 15:51:37
東方藝術·大家(2016年6期)2016-09-05 07:30:56
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
