基于生成對抗網絡的遙感影像場景分類
2022-07-26 09:04:14陳紅順陳文杰
微型電腦應用 2022年6期
陳紅順, 陳文杰
(北京師范大學珠海分校,信息技術學院, 廣東,珠海 519087)
0 引言
近年來,卷積神經網絡(CNN)在圖像分類方面取得了很多的應用[1-3],這得益于帶有訓練標簽的大型圖像數據集。由于遙感圖像特殊性,制作帶有訓練標簽的大型遙感圖像數據集成本高、過程復雜,因此目前公開的遙感圖像數據集規模不大,且不同數據集之間存在遙感平臺、傳感器、拍攝角度、分辨率、拍攝時間的差異,造成同一類型的地物在不同的數據集中差異巨大,這給遙感圖像場景分類造成了困難。近年來,遷移學習方法開始應用于遙感圖像場景分類[4]。
生成對抗網絡[5](GAN)由Goodfellow等人于2014年提出,自提出以來引起了許多研究者的興趣。目前,許多學者提出了各種改進模型,如深度卷積生成對抗網絡(Deep Convolutional GAN,DCGAN)[6]、條件生成對抗網絡(Conditional GAN)[7]等,并廣泛應用于圖像超分辨率合成、圖像風格轉移、圖像分割[8]等領域。
本文針對遙感圖像場景分類中帶有標簽數據不足的問題,提出一種生成對抗網絡的分類算法,并應用于遙感圖像場景分類。
1 生成對抗網絡
如圖1所示,生成對抗網絡的結構主要包含2個模型:生成器(Generator,記作G)和判別器(Discriminator,記作D)。生成器通過學習得到真實數據的分布,生成盡可能與真實相似的數據,以達到讓判別器無法鑒別;判別器的目標則是盡可能的區分真實數據和生成器生成的假數據。生成器和判別器交替訓練,互相對抗博弈,最終達到納什均衡。此時,生成器能夠生成與真實數據分布相似的數據,判別器無法識別數據的“真假”。
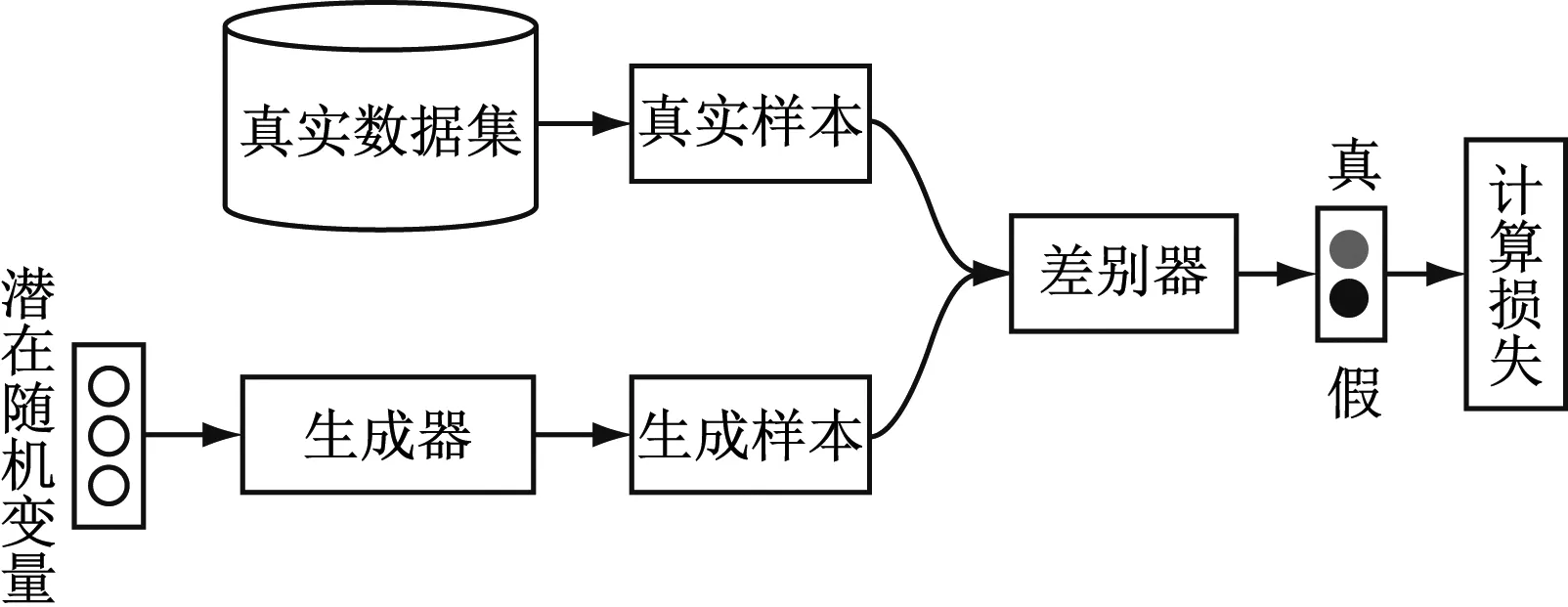
圖1 生成對抗網絡結構
修改原始GAN判別器的輸出類別標簽可以將GAN擴展成半監督分類器[9]。此時,生成器不再生成數據而是作為特征提取器,通過對抗學習方法擬合兩個數據分布,并把結果分別傳入判別器和分類網絡,并調整標簽決策來增加類間差異。
基于GAN的訓練機制,通過交替訓練擬合兩組數據,生成器(也稱為特征提取器)在源域和目標域中共享參數,把源域數據和目標域數據交替放進去訓練,達到生成網絡能夠弱化2個域的差異,提取到2個域的共同特征。
2 基于標簽改進生成對抗網絡的分類算法
2.1 算法模型
在前人研究的基礎上,本文在原有模型中添加標簽,以解決域適應過程中減弱類間差異的問題。整個算法流程如圖2所示。為測試算法效果,使用MNIST和MNIST-M數據集進行分類(見圖3)。MNIST-M是彩色帶背景的手寫數據集,它是由BSDS500數據集中隨機提取圖片,然后對其隨機位置剪裁成28*28的大小,減去黑白的手寫數據集取絕對值得到的,其線條特征與MNIST有一定的相似。如表1所示,網絡結構由兩部分組成,一部分是2個卷積層和2個池化層組成的特征提取網絡,另一部分由全連接層組成的類間分類器和領域判別器。
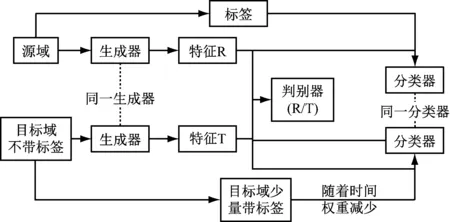
圖2 算法流程

(左:MNIST數據集,右:MNIST-M數據集)圖3 測試數據集

表1 基于標簽改進生成對抗網絡的網絡結構
2.2 訓練算法
在開始訓練源域網絡前,將MNIST數據集圖像轉為假彩色,作為3通道輸入到網絡,測試時仍轉假彩色去測試。batch設置為64,epoch設置為30,使用Adam優化器,其學習率為0.001,衰減率為(0.9,0.99),以迭代器的方式提取數據來應對源域和目標域數據量不相等。數據量少的將會重復抽取,直到數據量大的數據集完成一次讀取為止。一個Epoch里,域分類器和特征提取器的訓練次數為1∶10,原因是域分類器訓練效果明顯,收斂速度快,而特征提取器以欺騙域分類器訓練以求得到域不變特征,故訓練時間要長一些。損失函數無監督訓練采用經sigmoid處理后的BCE損失函數,驗證集部分采用交叉熵損失函數。最后是權重衰減參數,衰減權重為
W=w+w(1-t/epochs)
(7)
其中,w為目標域的驗證集相關權重,設置為0.1,t為當前的epoch次數,epochs為總的迭代次數。總損失函數為
LOSS=Wloss1+(1-W)loss2
(8)
算法訓練過程如下。
(1)訓練源域網絡,把源域數據和類別放入特征提取器和分類器,使網絡能夠很好的區分源域數據的類別,然后把此網絡的參數模型保存下來,稱為源域網絡。
(2)訓練領域判別器,固定特征提取器的參數交替(或合并)地輸入源域和目標域的數據,以此來判斷輸入的圖片來自源域或目標域,使領域判別器的參數更新,能夠更好地區分圖片來自源域還是目標域。
(3)訓練特征提取器,固定領域判別器的參數交替(或合并)地輸入源域和目標域的數據,此時,域分類器將以錯誤的域類別作為訓練,以此來訓練特征提取器,使特征提取器能夠提取到兩個領域的共同特征,以此來欺騙域分類器。兩種方式以一定的比例交替訓練,達到擬合兩組數據的分布。
(4)訓練類間分類器,把驗證集少量的目標域帶標簽數據輸入生成的特征R作為監督學習,以此交叉熵作為損失函數的部分權重來訓練整個網絡。
2.3 實驗結果與分析
將本文方法與WDGRL[10]、ADDA[11]方法進行比較,結果分別見圖4和表2。可以看出,對假彩色處理后的MNIST已經有很好分類效果的源域網絡直接用于目標域的彩色MNIST_M,有33%的準確率,說明源域和目標域之間確實有著一定的共同特征。ADDA通過域對抗方法,對齊2個域的分布,得到了良好的分類效果。WDGRL通過Wasserstein距離衡量2個樣本的分布差異,參與了網絡的更新標準。本文方法基于ADDA方法的基礎上,目標域少量驗證集以一定的減弱權重參與網絡更新,相比較于前2種方法,準確率高一點,但訓練時間要長約30%。

圖4 訓練過程中的目標域分類精度

表2 不同方法準確率對比
3 遙感影像場景分類實驗
3.1 數據集
從AID[12]、NWPU-RESISC45[13]、UCMerced_LandUse[14]和WHU-RS19[15]數據集分別取出相應類別的數據來構建源域數據和目標域數據。AID共分為30個類別,每個類別有220~420張圖像;NWPU-RESISC45數據集共分為45個類別,每個類別有700張圖像;UCMerced_LandUse共分為21個類別,每個類別有100張圖像;WHU-RS19共分為19個類別,每個類別有50張圖像。源域數據來源為:從AID數據集中選取機場、橋梁、商業區、沙漠、工業區、湖泊、草地、公園、海港和地鐵站共10個類別;從UCMerced_LandUse數據集中選取沙灘、林業區、河流和停車場共4個類別。目標域數據來源為:從NWPU-RESISC45數據集中選取機場、橋梁、商業區、沙漠、工業區、草地、停車場和地鐵站共8個類別,從WHU-RS19數據集中選取沙灘、海港、湖泊、公園、林業區和河流共6個類別。
源域和目標域數據集數據的空間分辨率為0.2~30 m,從圖5、圖6可以看出,兩者之間存在明顯差異。由于不同數據集中的圖片尺寸不一,需要對圖片進行歸一化處理,先把不同數據集的圖片大小統一以最短邊縮放成224,再把圖片中心剪裁成224*224,對應VGG16網絡的輸入。訓練過程中,分別從源域和目標域的各類別中取出10%的比例作為驗證集。

圖5 源域數據

圖6 目標域數據
3.2 實驗過程
各部分采用的網絡結構如表3所示。生成器(特征提取器)采用VGG16網絡[2],類間分類器和領域判別器均采用三層全連接層(fully connected layer),其中前兩層全連接均使用激活函數ReLU,類間分類器在第1層引入了Droupout、第3層引入了平均池化。

表3 用于遙感網絡場景分類的網絡結構
由于網絡初始化訓練速度很慢,特別是生成器的訓練,所以本文選取預訓練的VGG16網絡來初始化生成器的參數,加快初始訓練速度。batch設置為64,epoch設置為30,使用Adam優化器,其學習率為0.002,衰減率為(0.9,0.99)。
一個epoch里,領域判別器和生成器的訓練次數為1∶k,原因是域分類器訓練效果明顯,收斂速度快,而生成器以欺騙域分類器訓練以求得到域不變特征訓練時間長。本文在訓練過程中,k的值設置為10。
3.3 實驗結果與分析
本文的方法與DDC(Deep Domain Confusion)遷移學習方法[6]進行對比,其最終在目標域上的精度見表4,訓練過程中的精度和loss變化分別見圖7、圖8。

圖7 訓練過程中目標域的分類準確率變化曲線

圖8 訓練過程中目標域的loss變化曲線

表4 精度評價
可以看出,僅利用訓練好的源域網絡對目標域進行分類,其精度達到47%,說明源域和目標域有著一定的相似特征。與DDC遷移學習方法相比,本文的方法分類精度略高。從loss變化趨勢來看,DDC遷移學習方法波動明顯,而本文方法的loss下降比較平穩。從準確率來看,兩者的變化曲線相似,但是訓練時間明顯比DDC遷移學習方法要長。
4 總結
本文針對目標域帶標簽樣本數據量少的問題,通過改進生成對抗網絡模型,更好地利用標簽信息增強目標域類間的區分度。在常用的遙感圖像場景分類數據集上進行了實驗,結果表明本文方法對目標域有較好的分類效果。但本文方法還存在一些問題,如在實際應用中往往不知道目標域的類別數量,無法明確地將目標域和源域類別一一對應,同時本論文方法也不適用于多領域遷移分類。
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
電子制作(2019年15期)2019-08-27 01:12:00
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年19期)2018-11-14 02:37:08
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
自動化學報(2017年11期)2017-04-04 02:52:58
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
