一種基于深度強化學習的機動博弈制導律設計方法
2022-08-02 07:50:14朱雅萌張海瑞周國峰
航天控制 2022年3期
朱雅萌 張海瑞 周國峰 梁 卓 呂 瑞
中國運載火箭技術研究院,北京 100076
0 引 言
突防策略是決定高速機動飛行器突防能力的關鍵因素[1]。目前常用的突防策略是大范圍機動,即在原有的飛行軌跡上疊加一個規律的周期性機動,包括螺旋機動[2-3]、蛇形機動[4-8]等。然而,現有的這些機動方法是射前裝訂的,不能根據攔截方的情況調整自己機動的時間和方向,導致適應性不強。特別是,如果遭遇攔截方的時間早于機動開始時間或處于機動指令的波節處,就會極大地影響突防效果[6-8]。此外,高速機動飛行器飛行過程中自身運動狀態也存在一定不確定性[9]。與此同時,針對攔截方的探測手段是當前熱門的研究方向,實時獲知攔截方的信息在將來會成為可能,為基于雙方信息的針對性突防策略提供了硬件基礎。
在針對性突防策略中,目前研究較多的是以微分對策為代表的理論方法。微分對策理論是將突防攔截問題看作兩點邊值的雙向極值問題,通過求解系統的黎卡提微分方程得到最優策略。Singh等[10]、Garcia等[11-12]與Liang等[13]采用微分對策理論解決目標-攻擊者-防御者的三方博弈問題。毛柏源等[14]將突防攔截問題轉換為兩方零和博弈問題,并推導了解析形式的捕獲區。魏鵬鑫等[15]基于線性二次型微分對策理論,解析推導了攻防雙方過載能力的關系。然而,微分對策理論目前多適用于線性系統,否則黎卡提方程難以求得解析解。在實際的突防攔截問題中,動力學過程使得系統十分復雜,全部進行線性化處理會損失較大的擬真度。
人工智能技術的發展,使得借助智能算法解決突防攔截問題成為可能。智能算法主要分為深度神經網絡(Deep Neural Network, DNN)和強化學習(Reinforcement Learning, RL)2種算法。DNN是由大量處理單元互聯組成的非線性、自適應信息處理系統,適用于擬合非線性系統。而RL算法是一種無模型的機器學習方法,通過與環境交互自主尋找最優策略,適用于離散空間的決策問題。吳其昌等[16-17]采用數值算法求解微分對策問題,并嘗試了利用DNN擬合同一問題并求解的可能。Rizvi等[18]采用輸出反饋的RL算法解決離散時間線性二次調節器問題。Odekunle等[19]將RL算法、微分博弈論和輸出反饋結合用于基于數據的控制器。
新興的深度強化學習(Deep Reinforcement Learning, DRL)算法將RL算法和DNN相結合,融合了二者的優勢[20],使得智能體能夠在連續空間內自主尋找最優決策。突防攔截問題處于連續的狀態空間和動作空間中,將DNN與RL算法結合能更切合地處理這類問題。譚浪等[21]基于深度確定性策略梯度算法DDPG設計了一種追逃博弈算法,但僅在小車上進行了驗證。
本文基于DRL算法提出了一種機動博弈制導律,并以增大交會擺脫量為導向設計了回報函數。經仿真分析得到,在遭遇高速機動攔截方時,該制導律使飛行器能夠根據信息實時自主決策,完成突防。與傳統的蛇形機動相比,應用該制導律的交會擺脫量顯著提升,且突防效果較穩定。
1 突防制導問題描述
本文研究一對一的突防攔截問題,假設進攻方在下壓點之前完成突防,雙方都為軸對稱無動力飛行器,攔截方機動能力強于進攻方。將雙方視為質點,考慮地球自轉等因素,在三維空間中對仿真場景建立數學模型。
1.1 運動學模型
在三維笛卡爾坐標系下建立模型,以A,D分別代表進攻方和攔截方,突防攔截場景如圖1所示,相應的運動學方程為:
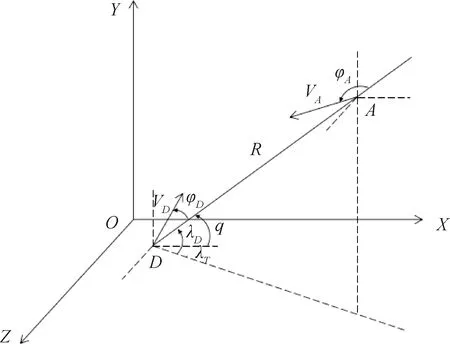
圖1 突防攔截場景示意圖
(1)
式中,進攻方和攔截方的運動速度分別為VA和VD,R表示雙方斜距,q表示視線角,φA和φD分別表示進攻方和攔截方的前置角,λT表示雙方視線所在的縱平面與基準坐標系X軸的夾角,λD表示雙方視線與水平面的夾角。
1.2 動力學模型
進攻方和攔截方采用相同的動力學模型。在發射慣性系下建立飛行器的三自由度動力學模型如式(2)~(8)所示。
質心運動動力學方程:
(2)
附加方程:
(3)
(4)
(5)
(6)
(7)
h=r-R
(8)
式中:m表示飛行器質量;t表示時間;x,y,z表示飛行器在發射慣性系下的位置;v表示飛行器的速度;AB表示飛行器箭體系到發射慣性系的坐標轉換矩陣,CA,CN和CZ表示軸向、法向和側向的氣動力系數,q表示動壓,Sm表示飛行器參考面積;r表示飛行器質心的地心矢徑,ωe表示地球自轉角速度,gr,gωe分別表示重力加速度g在r,ωe方向上的分量;R0表示發射點的地心矢徑;φ表示飛行器的地心緯度,ae和be分別表示地球橢圓模型的長半軸和短半軸;R表示飛行器下方地面到地心的距離,h表示飛行器的飛行高度。
1.3 雙方制導律
1.3.1 攔截方制導律
攔截方采用針對進攻方的比例導引律,在視線系中可以表示為:
(9)
式中,NcS表示攔截方在視線系的需用過載;vc表示相對速度大小;λD和λT分別為高低角和方位角;GSL表示地球表面重力加速度,取值為 9.80665m/s2。
將需用過載和重力加速度轉換到箭體系后相減以獲得角度指令。由于攔截方做無動力飛行,可使用的過載垂直于箭身,因而X軸方向的過載不用于生成箭身姿態角度指令。過載轉換及角度指令計算公式可以表示為
(10)
αCX=f(NcBy)
(11)
βCX=f(NcBz)
(12)
式中,NcB表示攔截方在箭體系的需用過載,g表示慣性系下質心處重力加速度,SB和AB分別為視線系和慣性系到箭體系的坐標轉換矩陣,αCX和βCX分別表示指令攻角和指令側滑角,f表示將過載轉換為指令角的公式。
1.3.2 進攻方制導律
在不機動的情況下,進攻方處于平飛狀態,其制導律在本文稱為平飛基礎制導律。此時,進攻方在視線系下的需用過載指令近似為常值,可以表示為:
(13)
式中,KM1和KM2為常數。
基于DRL算法的機動博弈制導律則是采用DRL方法來擬合進攻方的制導指令,根據進攻方和攔截方的位置和速度實時算得基準坐標系內的需用過載,可以表示為:
NcT=h(x,y,z,vx,vy,vz)
(14)
式中,NcT表示基準坐標系的需用過載,x,y,z,vx,vy,vz為雙方的位置和速度,h表示DRL方法所擬合的制導規律。
進攻方角度指令的生成方式與攔截方相同,也是將需用過載轉換到箭體系后舍棄X軸分量,分別用Y軸和Z軸分量生成攻角指令和側滑角指令。
2 基于深度強化學習的機動博弈制導律設計
2.1 深度強化學習
DRL算法是一類通過與環境交互自主尋找最優決策的算法,其交互過程示意圖如圖2所示。
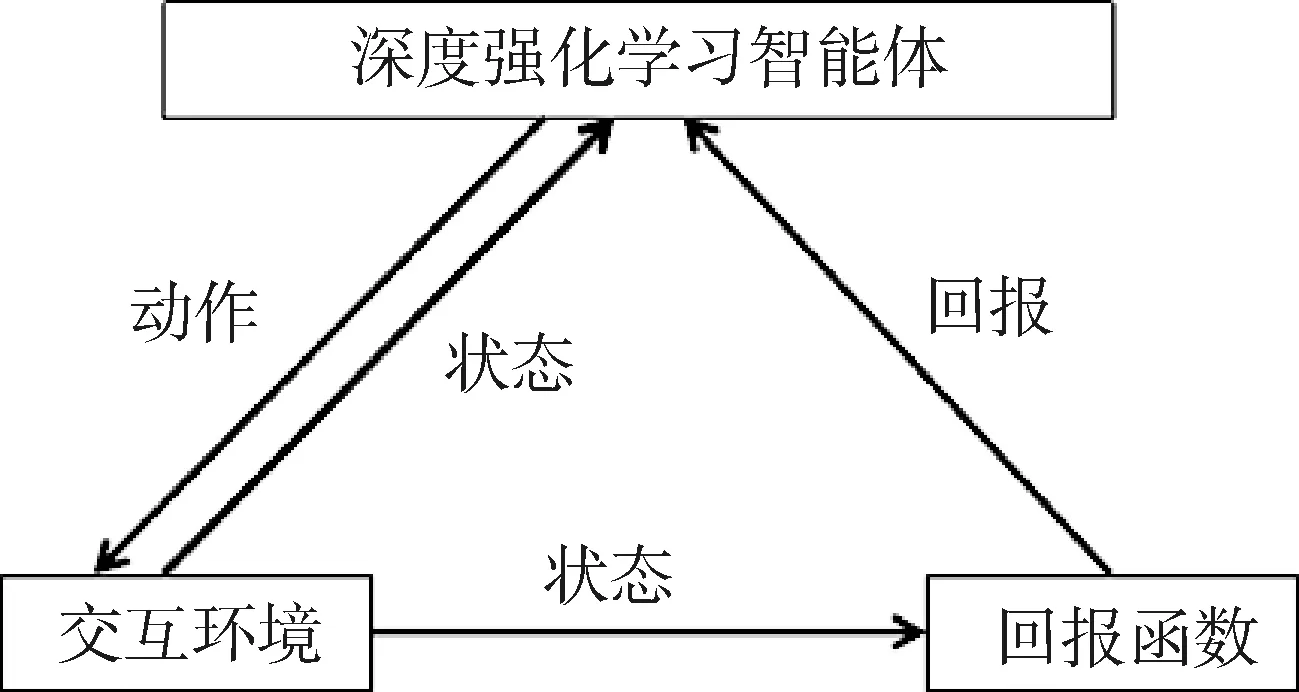
圖2 DRL算法交互過程示意圖
DRL算法的交互過程可以用馬爾科夫決策過程(Markov Decision Process, MDP)來表示。MDP包含5個要素[S,A,p,r,γ],其中S表示狀態空間,即智能體做出決策的依據信息;A表示動作空間,即智能體可以做出的決策范圍;p表示狀態轉移概率,即在當前狀態采取某一動作的情況下,下一時刻系統變為某一狀態的概率;r表示回報函數,用于計算一次交互所產生的回報;γ表示折扣因子,以γ為參數對r加權累積,得到交互一個完整回合獲得的總回報。DRL算法的學習過程就是通過改變在特定狀態下選取不同動作的概率,以得到一種最優策略,使得一個完整回合所獲得的總回報最大。
本文采用的是一種基于“行動者-評論者”(Actor-Critic, AC)框架的深度強化學習算法。AC框架包含2個DNN,分別擬合在傳統RL算法中的策略函數(Actor網絡)和值函數(Critic網絡)。在與環境交互的過程中,智能體首先根據當前的狀態和回報,更新Critic網絡;再根據狀態和Critic網絡擬合的近似值函數,更新Actor網絡,產生新的策略函數。最終,Actor網絡的輸出即為待求的策略。AC框架的計算流程如圖3所示,相關表達式如式(15)~(19)所示。

圖3 AC框架的計算流程圖
算法的目標函數:
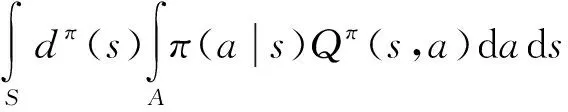
(15)
Actor網絡的策略梯度:
(16)
Critic網絡近似的值函數:
Qω(s,a)≈Qπ(s,a)
(17)
根據Critic網絡近似的值函數計算策略梯度:
(18)
更新Actor網絡的參數:
(19)
式中:J表示算法的目標函數;π表示Actor網絡輸出的策略,θ表示Actor網絡的參數;Eπ{·}表示在策略π下的期望;dπ表示在策略π下的狀態分布;Qπ表示系統在策略π下的值函數;s,a分別表示系統的狀態和智能體采取的動作,S,A分別表示系統的狀態空間和動作空間;Qω表示Critic網絡擬合的值函數,ω表示Critic網絡的參數;ε表示參數更新的學習率。
經過AC框架的計算,算法最終得到的策略具有如下形式:
Y=tanh(B3+(W23)T·tanh(B2+(W12)T·
tanh(B1+(W01)T·X)))
(20)
式中,X,Y分別表示輸入的狀態和輸出的動作;tanh為雙曲正切函數;Wij和Bj分別為權重矩陣和偏置矢量,即為前述Actor網絡的參數θ,其中i,j為Actor網絡的層數序號。
2.2 馬爾科夫決策過程設計
采用DRL方法研究突防制導問題,需要將問題轉換為MDP形式。MDP的設計至關重要,直接影響DRL算法的最終效果。
2.2.1 狀態空間S
狀態是DRL算法產生決策的依據,也是AC框架中兩個DNN的輸入。狀態空間應當全面、合理地反映出所交互的環境信息,避免不必要的信息干擾。本文為了避免先驗知識的干擾,沒有選用傳統導引律所依據的角度信息,而是選用了突防攔截雙方原始的位置和速度作為狀態。
S:〈x,y,z,vx,vy,vz〉
(21)
2.2.2 動作空間A
DRL算法作為決策的控制量稱為動作,其取值范圍由動作空間表示。本文選用在基準坐標系中的需用過載作為動作。
A:〈NCx,NCy,NCz〉
(22)
當需用過載輸出到環境(仿真程序)中以后,通過式(10)轉換到箭體系并舍棄X軸方向的分量,再通過式(11)~(12)求得角度指令。
2.2.3 狀態轉移概率p
狀態轉移概率p表征了環境的交互規則,在突防攔截問題中主要為雙方軌跡積分所用的動力學規律。在本文選用的DRL方法中,狀態轉移概率p不通過解析表達式給出,而是包含在Critic網絡所擬合的關系中,在交互過程中自行更新。
2.2.4 回報函數r和折扣因子γ
回報函數應當設計得形式簡單,易于使算法獲得優化的方向。本文將回報函數設計為2部分之和:1)過程回報,每步都有值;2)終點回報,只在回合的最后一拍才有值。為了避免先驗知識的干擾,本文只選用雙方斜距構建回報函數,最后一拍的雙方斜距就是交會擺脫量,也就是算法最優化的目標。
本文將過程回報rt設置為當前的雙方斜距dt與前一刻的雙方斜距dt-1之差,如式(23)所示。將終點狀態分為“被攔截”和“成功突防”兩類,將終點回報rend設置為擺脫量dend與常系數k1的積再加上偏置常數k,其中2類結果對應的偏置常數取值分別為k2和k3,如式(24)所示。這樣設置使得不同結果獲得的總回報有區分度,便于導向期望的結果。
rt=dt-dt-1
(23)
(24)
而折扣因子γ用于對回報函數加權累積以得到一個回合的總回報,進而計算策略梯度。折扣因子γ的取值范圍為[0,1],用于調整距離初始步較遠的回報的重要程度。由于本文關心的是最終的交會擺脫量,而不關心每一步的雙方斜距,因而將折扣因子γ設置為1。
最終得到每個回合的總回報R如下:
(25)
式中,Tn表示該回合的總交互步數。
可以看出,算法的總回報就是最終的交會擺脫量與初始雙方斜距的線性和。這樣設置使得算法每次交互都可以獲得與最終目標相關的量,便于系統規律的擬合,同時避免了將路徑計入優化的目標。
2.3 基于DRL算法的機動博弈制導律訓練過程
基于DRL算法的機動博弈制導律交互過程如圖4所示。圖中,轉換過程是指1.3.1中所述將需用過載和重力加速度統一轉換到箭體系后相減。

圖4 基于DRL算法的機動博弈制導律交互過程
軌跡平均獎勵值曲線如圖5。可以看出隨著交互步數的增加,平均獎勵值曲線逐漸上升,最終穩定在了一個較高值,表明收斂到了一個較優的解。
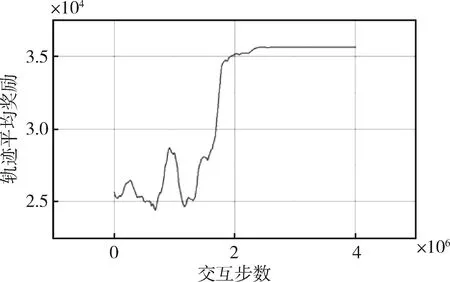
圖5 軌跡平均獎勵
算法直接輸出的需用過載曲線如圖6所示。
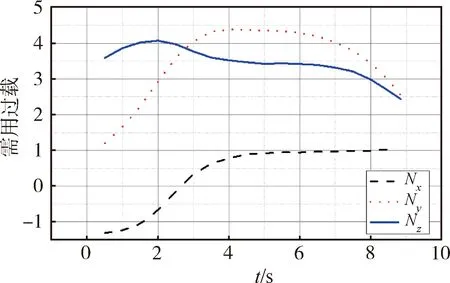
圖6 需用過載曲線
3 仿真校驗
3.1 實驗描述
本節對三維空間內的一對一突防場景進行了仿真模擬,假設進攻方在下壓點之前完成突防,所選用的進攻方和攔截方均為軸對稱無動力飛行器,攔截方機動能力強于進攻方。由于目前部分反導攔截器采用破片殺傷戰斗部[22-23],毀傷半徑大于動能攔截器,故將雙方斜距小于20m視為突防失敗。作為對照,添加了不同相位的蛇形機動仿真,以模擬傳統蛇形機動在不同的攔截方遭遇時間下的表現。相關設置如表1所示。

表1 仿真實驗相關設置
其中,蛇形機動的制導指令生成方式為:在無機動制導指令的基礎上,側向疊加一個以正弦規律變化的過載指令。疊加正弦指令后的視線系過載如式(26)所示。
(26)
式中,所選指令相位φ為+π/4,-π/3.5,分別為仿真得到的使交會擺脫量相對較大和較小的指令相位。
3.2 實驗結果與分析
圖7(a)~(d)分別為無機動、2個相位的蛇形機動和采用DRL制導律機動的指令角度曲線圖。圖8(a)~(d)分別為4種機動下的突防軌跡圖。表2列出了4種機動下的交會擺脫量和突防增加時間。
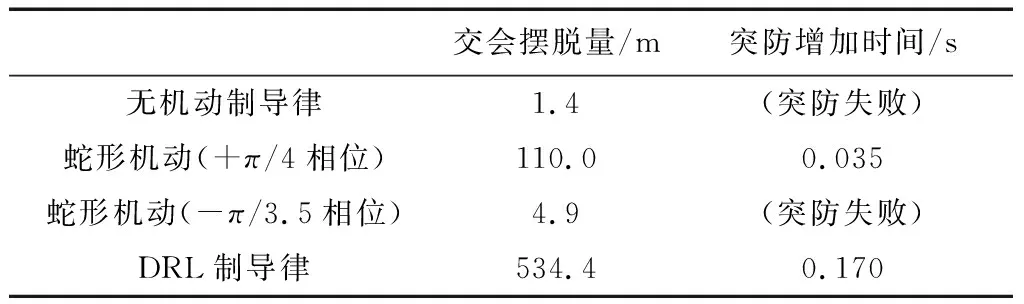
表2 交會擺脫量與突防增加時間對比
由圖7(d)和圖8(d)可以看出,由DRL算法得到的突防策略是根據攔截方的位置和速度方向以最大過載向某一方向進行機動。

圖8 突防軌跡圖
由圖7~8和表2可以看出,蛇形機動的交會擺脫量受機動指令相位影響較大,指令相位為-π/3.5

圖7 指令角度曲線圖
時會導致突防失敗,而DRL制導律機動則不存在相位問題,突防效果較穩定。由表2可以看出,相較于蛇形機動表現較好的情況,DRL制導律機動的交會擺脫量有顯著提升。
由表2還可以看出,DRL制導律機動突防所用的時間比蛇形機動略長。因為較大機動量的飛行軌跡較長,所以在速度接近的情況下,用時會較長。
在突防完成后,將采用DRL制導律機動的進攻方的制導律切換回平飛基礎制導律,繼續完成進攻軌跡,得到在擊中目標點處的落速損失約為14.5%,尚在可以接受的范圍內。因而,在只進行一次突防機動的情況下,DRL制導律機動不會對后續打擊任務產生太大影響。
4 結論
提出了一種基于DRL算法的機動博弈制導律。在能獲取攔截方位置和速度信息的情況下,該機動博弈制導律能夠根據信息自主決策,產生合適的制導指令完成突防。經仿真驗證表明,相較蛇形機動而言,該機動博弈制導律能夠顯著提升交會擺脫量,且突防效果較穩定。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
數學大世界(2018年1期)2018-04-12 05:39:14
電信科學(2016年10期)2016-11-23 05:11:56
時代英語·高三(2014年5期)2014-08-26 02:49:51
