基于知識圖譜的大學(xué)生職位推薦方法
2022-08-04 04:19:50徐紅艷王碧瑩王嶸冰
徐紅艷,王碧瑩,馮 勇,王嶸冰
(遼寧大學(xué) 信息學(xué)院,遼寧 沈陽 110036)
0 引言
在國內(nèi)經(jīng)濟(jì)穩(wěn)定、高速發(fā)展及國際重視中國市場的背景下,各行業(yè)都在擴(kuò)大生產(chǎn)經(jīng)營規(guī)模,藉此產(chǎn)生了更多的職位需求.在信息技術(shù)的推動下,這些職位需求數(shù)據(jù)在網(wǎng)絡(luò)空間迅猛增長和快速傳播,進(jìn)而引發(fā)信息過載問題[1].在海量的職位信息中找到適合的職位對求職者來說是一件復(fù)雜而又耗時(shí)的事情,尤其對缺乏工作和社會經(jīng)驗(yàn)的應(yīng)屆大學(xué)生,職位選擇顯得愈發(fā)困難.
當(dāng)前的職位推薦系統(tǒng)大多是熱門職位推薦或是基于關(guān)鍵詞匹配的推薦,然而熱門職位推薦缺乏針對性,基于關(guān)鍵詞匹配的推薦不能滿足用戶的個(gè)性化職位需求[2].知識圖譜作為一種新興知識處理技術(shù),它可以從知識層面表述知識實(shí)體及知識間的關(guān)聯(lián),將其應(yīng)用于職位推薦領(lǐng)域可以更好地處理職位供需間的匹配,帶來更為準(zhǔn)確的職位推薦.面對互聯(lián)網(wǎng)中海量的招聘數(shù)據(jù),基于知識圖譜的職位推薦不僅能滿足求職者對所需職位的高覆蓋率,也能體現(xiàn)出職位推薦的個(gè)性化特征.因此,本文提出了一種基于知識圖譜的大學(xué)生職位推薦方法,通過借助知識圖譜工具顯示招聘資源間的結(jié)構(gòu)關(guān)系以及職位的分布情況,根據(jù)知識圖譜中展現(xiàn)的關(guān)系,將與求職大學(xué)生有著直接或間接關(guān)系的職位推薦給他們,這樣有助于提高大學(xué)生的就業(yè)率.本文通過引入知識圖譜相關(guān)技術(shù),開發(fā)出來的職位推薦系統(tǒng)能為高校畢業(yè)生提供一個(gè)簡潔高效的職位推薦平臺,使學(xué)生可以更精準(zhǔn)地獲取到適合自己的職位信息,這樣可以加快畢業(yè)生的求職速度,有效地緩解學(xué)生的就業(yè)壓力,也能為企業(yè)節(jié)約時(shí)間和招聘成本.
1 相關(guān)工作
1.1 知識建模
知識建模是知識圖譜構(gòu)建技術(shù)的基礎(chǔ).有2種搭建知識圖譜的方法:自頂向下(top-down)和自底向上(bottom-up).自頂向下是預(yù)先定義好本體和數(shù)據(jù)模式,然后把實(shí)體加進(jìn)知識庫系統(tǒng)中,這種搭建方法必須采用當(dāng)前的部分結(jié)構(gòu)化知識庫系統(tǒng)作為基礎(chǔ)知識庫系統(tǒng),F(xiàn)reeBase知識庫就是采用這種方法構(gòu)建而成的.自底向上是從一些對外界開放的數(shù)據(jù)信息中獲取實(shí)體,選擇可靠性比較高的放到知識庫系統(tǒng)中,然后對頂層的本體模式進(jìn)行搭建,很大一部分知識圖譜就是依靠自底向上的方法搭建出來的,這里面最具代表性的是Google和微軟構(gòu)建的知識庫,這也符合互聯(lián)網(wǎng)數(shù)據(jù)內(nèi)容知識產(chǎn)生的特點(diǎn).
1.2 知識抽取
知識抽取中最重要的是如何從異構(gòu)數(shù)據(jù)庫中自動抽取信息內(nèi)容以獲得替代的知識單元.相對于垂直領(lǐng)域的知識圖譜,其數(shù)據(jù)通常采用2種方式獲得:1)業(yè)務(wù)本身的生成數(shù)據(jù)信息,這類數(shù)據(jù)大體上是指企業(yè)內(nèi)部的數(shù)據(jù)庫表,并將其以結(jié)構(gòu)化形式存儲起來;2)以網(wǎng)頁形式存在的非結(jié)構(gòu)化數(shù)據(jù),這類數(shù)據(jù)一般是從Internet上抓取的公開數(shù)據(jù).第1種類型的數(shù)據(jù)通常經(jīng)過簡單的預(yù)處理就可以用作AI系統(tǒng)后續(xù)的輸入數(shù)據(jù),而后1種類型的數(shù)據(jù)就要依靠自然語言的處理技術(shù)來獲得結(jié)構(gòu)化的數(shù)據(jù)信息.這一點(diǎn)恰好是知識抽取部分的一個(gè)難題,它涉及的核心技術(shù)包括實(shí)體抽取、關(guān)系抽取以及屬性抽取[3].
1.2.1 實(shí)體抽取
實(shí)體抽取指的是從文本數(shù)據(jù)中自動檢索出命名實(shí)體[4],它的目的是在知識圖譜中構(gòu)建節(jié)點(diǎn).實(shí)體抽取的質(zhì)量很大程度上影響著后面知識獲取的質(zhì)量和獲取速度,所以說實(shí)體抽取是知識抽取環(huán)節(jié)中最基礎(chǔ)也是最重要的模塊.
1.2.2 關(guān)系抽取
文本語料在前面的實(shí)體抽取后獲得的是一系列分散開來的命名實(shí)體,為了更好地從中獲得語義信息,在把這些實(shí)體和概念關(guān)聯(lián)在一起之前,必須從與之對應(yīng)的語料中獲取出實(shí)體間的關(guān)聯(lián)信息,這樣才能得到知識系統(tǒng)的網(wǎng)狀結(jié)構(gòu).關(guān)系抽取技術(shù),歸根結(jié)底就是從文本語料中抽取實(shí)體之間關(guān)聯(lián)關(guān)系的一項(xiàng)技術(shù)[5].
1.2.3 屬性抽取
屬性抽取的最終目的是要從不一樣的信息源中收集指定實(shí)體的屬性相關(guān)信息,以達(dá)到詳細(xì)描述實(shí)體屬性這一目的[6],如針對某款筆記本電腦,可以從互聯(lián)網(wǎng)中獲取多源異構(gòu)的數(shù)據(jù),從中得到其品牌、配置等信息.
如果把實(shí)體的屬性值看作是一種特殊的實(shí)體,那么屬性抽取實(shí)際上也是一種關(guān)系抽取.百科類網(wǎng)站提供的半結(jié)構(gòu)化數(shù)據(jù)是通用領(lǐng)域?qū)傩猿槿⊙芯康闹饕獢?shù)據(jù)來源,但具體到特定的應(yīng)用領(lǐng)域,涉及大量的非結(jié)構(gòu)化數(shù)據(jù),屬性抽取仍然是一個(gè)巨大的挑戰(zhàn)[7].
1.3 知識表示
知識表示旨在通過計(jì)算機(jī)來展現(xiàn)知識的可行性和有效性,它想要達(dá)到數(shù)據(jù)結(jié)構(gòu)與控制結(jié)構(gòu)的統(tǒng)一,因此,不僅要注意知識存儲上容易出現(xiàn)的狀況,也要想到知識使用方面的問題.知識表示可以看作是敘述一組事物的約定,從而將知識表示為能夠被機(jī)器識別處理的數(shù)據(jù)結(jié)構(gòu)[8].
2 基于知識圖譜的大學(xué)生職位推薦方法描述
本文提出了一種基于知識圖譜的職位推薦方法,推薦方法的框架如圖1所示.通過將知識圖譜的概念引入到職位推薦中,以此來彌補(bǔ)當(dāng)前職位推薦方法中存在的推薦精度不高、缺乏個(gè)性化等問題.所提方法的思想:首先將知識圖譜映射到低維稠密向量空間里,以獲取職位信息中的職位相似度;接下來依據(jù)職位信息生成用戶的行為矩陣,進(jìn)而計(jì)算出職位之間的相似度;然后通過融合這2種類型的職位相似度,得到融合后的職位相似度矩陣,并以該矩陣作為基礎(chǔ),得到用戶對職位庫中所有職位的估算分值;最后依據(jù)這個(gè)分?jǐn)?shù)得出推薦給用戶的職位排序列表.下面分別對方法中的核心環(huán)節(jié)加以詳細(xì)描述.
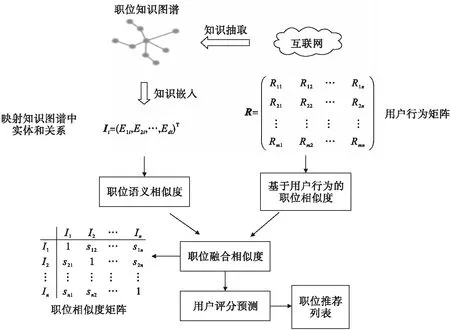
圖1 基于知識圖譜的大學(xué)生職位推薦方法框架
2.1 向量化表示
關(guān)于知識建模等構(gòu)建知識圖譜的相關(guān)技術(shù)和方法已經(jīng)在第1節(jié)中詳細(xì)介紹,下面介紹知識圖譜的向量化表示.
這里使用TransE算法將知識圖譜中的實(shí)體與關(guān)系嵌入到低維向量空間中[9],TransE算法的主要思想是將三元組(h,r,t)中的關(guān)系看作從實(shí)體head到實(shí)體tail的翻譯.其中,h是頭實(shí)體的向量表示,r是關(guān)系的向量表示,t是尾實(shí)體的向量表示.通過不斷調(diào)整三者的向量表示,使得h+r盡可能與t相等,即h+r=t,那么就說明知識圖譜中的三元組成立.如果成立,TransE算法就必須達(dá)到公式(1)和公式(2)的要求:
對正樣本三元組:h+r≈t
(1)
對負(fù)樣本三元組:h+r≠t
(2)
在上面兩式中,h+r與t的關(guān)系表示與向量相似度的近似等價(jià)程度.這里向量相似度通過計(jì)算歐氏距離實(shí)現(xiàn),得分函數(shù)的公式如式(3)所示:
f(h,r,t)=‖h+r-t‖L1/L2
(3)
得分函數(shù)值越小,越有利于正樣本三元組;得分函數(shù)值越大,對負(fù)樣本三元組越有利[10].接著,TransE算法通過損失函數(shù)測試表示學(xué)習(xí)的效果,損失函數(shù)的計(jì)算如公式(4)所示:
(4)
其中,S是正樣本的集合,S′h,r,t是三元組(h,r,t)的負(fù)樣本.知識圖譜中三元組的負(fù)樣本是通過隨機(jī)替換頭實(shí)體h或尾實(shí)體t后經(jīng)過大量訓(xùn)練得到的.以x表示公式(4)中方括號內(nèi)的式子,則[x]+指的是max(0,x);γ表示函數(shù)間隔的大小,且γ>0.TransE算法通過不斷地訓(xùn)練和優(yōu)化算法,損失函數(shù)的值可以達(dá)到最小.算法通過不斷地迭代來更新參數(shù),直到收斂或者達(dá)到最大迭代次數(shù),這時(shí)知識圖譜中的實(shí)體就會被映射到向量空間中的相應(yīng)位置[11].
2.2 相似度計(jì)算
本小節(jié)主要對系統(tǒng)中職位的相似度進(jìn)行計(jì)算,分為2個(gè)部分:基于簡歷的職位相似度計(jì)算和基于用戶行為的職位相似度計(jì)算.
本文所提方法的相似度計(jì)算有2個(gè)來源:1)通過提取用戶簡歷中的信息計(jì)算其與職位的相似度;2)由用戶在系統(tǒng)上對職位作出查看或收藏等用戶行為而得到的職位相似度.最后融合這2種來源的相似度,以此獲得最終的職位信息相似度.
2.2.1 基于簡歷的職位相似度
前文介紹了知識圖譜中富含大量的語義信息,可以從語義的層面描述職位之間的相似度[12].2.1節(jié)里又詳細(xì)地闡明了知識圖譜中實(shí)體向量化表示的具體步驟,因此獲得了實(shí)體在高維空間里的向量表示.接下來根據(jù)職位的嵌入向量,介紹職位語義相似度的詳細(xì)計(jì)算.
首先,把知識圖譜上職位信息的實(shí)體和關(guān)系都映射到d維空間里去,職位Ii嵌入一個(gè)d維的向量如公式(5)所示:
Ii=(E1i,E2i,…,Epi)T
(5)
這里的Epi指的是職位Ii在第p維上嵌入向量的數(shù)值.
然后使用歐幾里得距離計(jì)算后獲得的評分函數(shù),對知識圖譜中的實(shí)體和關(guān)系做嵌入操作[13].還需使用它測算向量的語義相似度,以此來精準(zhǔn)表達(dá)用戶的簡歷與職位信息之間的相似性.在這一步之前,需要先用公式(6)來計(jì)算職位之間的距離:
(6)
通過公式(6)的計(jì)算最終歐幾里得距離大于等于零,再經(jīng)過公式(7)的計(jì)算,可以把它控制在區(qū)間(0,1]:
(7)
這個(gè)式子的計(jì)算結(jié)果越大,就表明用戶的簡歷信息與職位信息之間的語義相似度數(shù)值越大.如果該數(shù)值是等于1的,簡歷信息與職位信息之間的語義相似度就是最大的,可以認(rèn)定兩者相似程度很高;反之,如果該值是趨近于0的,就認(rèn)定兩者之間毫無關(guān)聯(lián).
2.2.2 基于用戶行為的職位相似度
根據(jù)用戶行為得到的所有信息可以看出用戶自身對于職位信息的關(guān)注[14].基于物品的協(xié)同過濾推薦的主要思路也是如此.基于物品的協(xié)同過濾推薦可實(shí)現(xiàn)領(lǐng)域范圍之內(nèi)的推薦,是依據(jù)訪問系統(tǒng)的全部用戶對物品做出的用戶行為進(jìn)而得到物品之間的相似度,接著把認(rèn)定是相似的物品按照用戶行為的歷史數(shù)據(jù)進(jìn)行推薦.本文將用戶對職位信息的用戶行為劃分成許多個(gè)類別,這里以最為尋常的評分信息作參照對職位信息進(jìn)行向量化表示.
假設(shè)本文實(shí)現(xiàn)的系統(tǒng)里有訪問系統(tǒng)的m個(gè)用戶U=(U1,U2,…,Um)和被單位發(fā)布出來的n個(gè)職位I=(I1,I2,…,In),那么用戶對職位的評分信息可以表示為如公式(8)所示的m×n矩陣Rm×n:
(8)
接下來,要把職位Ii表示成如公式(9)所示的一個(gè)m維的向量,它的數(shù)值意味著在每一個(gè)維度上都有相應(yīng)的求職者對職位的一個(gè)打分.
Ii=(R1i,R2i,…,Rmi)T
(9)
這里利用余弦相似度公式得到基于用戶行為的職位信息相似度[15],具體的計(jì)算如公式(10)所示:
(10)
公式(10)計(jì)算出來的數(shù)值越大,就代表職位Ii與職位Ij之間被用戶行為的影響程度越深.一旦計(jì)算結(jié)果等于1,就可以說這2個(gè)職位從某種程度上來講是一樣的;如果計(jì)算結(jié)果等于0,就意味著這2個(gè)職位之間完全無關(guān).另外,如果這個(gè)用戶u沒有給職位i打出評分?jǐn)?shù)據(jù),那么Rui的數(shù)值就是零.
2.2.3 相似度融合
根據(jù)獲取到的簡歷信息對于職位相關(guān)信息的嵌入向量,可以獲得基于簡歷信息的職位相似度simknowledge_graph.同時(shí),依據(jù)用戶行為而生成的職位相關(guān)的評分矩陣,可以獲得基于用戶行為的職位相似度simusers_behavior.這里用加權(quán)的方法對這2種相似度進(jìn)行融合計(jì)算,可以獲取所需的最終相似度數(shù)值,詳細(xì)的計(jì)算方式如公式(11)所示:
sim(Ii,Ij)=α·simknowledge_graph(Ii,Ij)+(1-α)simusers_behavior(Ii,Ij)
(11)
這里α代表2種相似度算法的融合度,它的區(qū)間在[0,1],表示最終職位相似度中根據(jù)簡歷信息計(jì)算的職位相似度的占比大小.α的數(shù)值等于1說明最終相似度的結(jié)果全部是根據(jù)簡歷中用戶信息獲取的職位相似度數(shù)值;α的數(shù)值等于0說明最終相似度結(jié)果全部是根據(jù)用戶行為計(jì)算出來的相似度值.職位相似度融合之后的區(qū)間也是[0,1].
對全部用戶信息與職位信息之間的相似度進(jìn)行融合以后,基于職位信息的相似度通過矩陣的方式展現(xiàn)如下:

這里,sij表示職位Ii和職位Ij之間的相似度,sij=sji.另外,如果i等于j,sij的值為1,即這里全部的職位信息和它們自己的相似度數(shù)值都是1.
2.3 推薦列表生成
這里幫助求職者進(jìn)行偏好職位推薦的基本思想:首先根據(jù)2.2節(jié)計(jì)算獲取到的簡歷信息與職位之間生成的相似度矩陣以及求職者對于職位的用戶行為生成的矩陣,然后通過預(yù)測來獲得每個(gè)求職者給未評價(jià)過的職位內(nèi)容的打分?jǐn)?shù)值;最后系統(tǒng)根據(jù)求職者對每個(gè)職位內(nèi)容的預(yù)測評分生成一個(gè)按照評分由高到低排序的職位列表.
生成職位相似度矩陣之后,這里通過pui指代預(yù)估出來的用戶u對職位i的分值,借助公式(12)就可以計(jì)算出pui的數(shù)值.
(12)
其中sij表示職位Ii和職位Ij之間的相似度,Ruj指代現(xiàn)存評分矩陣?yán)镉脩魎給職位j打出的分值,N(u)是用戶u已經(jīng)給出評分的職位信息的全部集合,S(i,k)指代和職位i相關(guān)性最高的k個(gè)職位的全部集合.
經(jīng)過公式(12)計(jì)算得出的預(yù)測評分?jǐn)?shù)值越高,代表該職位與用戶過往評分?jǐn)?shù)值很大的職位相似程度越高,其在系統(tǒng)中職位推薦列表里的位置排列更靠上些.
在本文實(shí)現(xiàn)的職位推薦系統(tǒng)中,系統(tǒng)給每位求職者都推薦一個(gè)含有N個(gè)職位在內(nèi)的詳情列表.系統(tǒng)給求職者作出推薦的依據(jù)如下:如果求職者對職位的預(yù)測評分?jǐn)?shù)值很高,那么就有理由認(rèn)定該用戶對這個(gè)職位偏好強(qiáng)烈,這個(gè)職位信息在列表中的位置就靠前,也更易被訪問系統(tǒng)的求職者注意到;反之,這個(gè)職位的信息可能出現(xiàn)在列表中相對靠后的位置,甚至可能因?yàn)閿?shù)值過低沒有出現(xiàn)在列表中.按照這個(gè)思路,系統(tǒng)最終會生成一個(gè)包括N個(gè)職位信息在內(nèi)的、依據(jù)數(shù)值由高至低排列的職位推薦列表.
3 實(shí)驗(yàn)分析
3.1 數(shù)據(jù)集與實(shí)驗(yàn)環(huán)境介紹
本系統(tǒng)通過網(wǎng)絡(luò)爬取技術(shù)抓取互聯(lián)網(wǎng)招聘數(shù)據(jù)[16],數(shù)據(jù)包括23 213條節(jié)點(diǎn)數(shù)據(jù),11種關(guān)系類型在內(nèi)的關(guān)系數(shù)據(jù)126 559條.下面將其按照7∶3的比例分為訓(xùn)練集和測試集,并針對這2個(gè)數(shù)據(jù)集進(jìn)行實(shí)驗(yàn).
本文實(shí)驗(yàn)環(huán)境如下:
1)操作系統(tǒng):Windows 7
2)CPU:頻率 2.60 GHz
3)編程工具:PyCharm Community Edition 2019.2.3和Python
4)顯卡信息:Intel(R)HD Graphics 4000
3.2 指標(biāo)和參數(shù)選取
本文實(shí)現(xiàn)的職位推薦系統(tǒng)是向用戶推薦偏好的職位信息,因此針對系統(tǒng)生成的職位推薦列表,選取2個(gè)數(shù)據(jù)集采用交叉驗(yàn)證的方法進(jìn)行實(shí)驗(yàn)分析,從準(zhǔn)確率(Precision)和召回率(Recall)2個(gè)指標(biāo)評價(jià)職位推薦系統(tǒng)的推薦結(jié)果.
為了更加清楚地解釋準(zhǔn)確率和召回率,本文定義一些符號如下:
TP(True Positive)代表推薦系統(tǒng)已經(jīng)推薦,且實(shí)際的用戶行為也確實(shí)發(fā)生了的樣本;
FP(False Positive)代表推薦系統(tǒng)已經(jīng)推薦,但實(shí)際的用戶行為并沒有發(fā)生的樣本;
FN(False Negative)代表推薦系統(tǒng)沒有推薦,但實(shí)際的用戶行為發(fā)生了的樣本.
準(zhǔn)確率的定義如公式(13)所示:
(13)
準(zhǔn)確率計(jì)算公式的含義是,在所有被職位推薦系統(tǒng)預(yù)測推薦的樣本中實(shí)際推薦的概率.
召回率的定義如公式(14)所示:
(14)
召回率計(jì)算公式的含義是,在職位推薦系統(tǒng)實(shí)際推薦的樣本中被預(yù)測推薦的職位概率.
這里融合度的變化范圍是[0,1],設(shè)定融合度的變化數(shù)值為0.1,共做11組實(shí)驗(yàn),即觀察融合度數(shù)值以0.1為步長的情況下準(zhǔn)確率和召回率的變化情況.融合度數(shù)值等于0,代表職位推薦方法全部采用基于簡歷信息與職位信息的相似度算法;融合度數(shù)值等于1,代表推薦方法使用的都是基于用戶行為的相似度算法.隨后,用數(shù)據(jù)集對這些算法做實(shí)驗(yàn)分析,以此得到指標(biāo)狀況最佳時(shí)的融合度數(shù)值.下面對不同融合度數(shù)值下的各個(gè)算法進(jìn)行實(shí)驗(yàn)分析.
圖2為2種相似度算法在不同融合度數(shù)值下準(zhǔn)確率指標(biāo)變化情況,圖3為相同條件下召回率的變化情況,當(dāng)融合度數(shù)值為0時(shí),表示基于簡歷信息與職位信息的相似度算法的指標(biāo)情況.由圖2和圖3可以發(fā)現(xiàn),當(dāng)融合度值在0.6的時(shí)候,融合相似度算法在2個(gè)指標(biāo)上都達(dá)到了最高點(diǎn),表明在這個(gè)融合度下,該融合算法在準(zhǔn)確率、召回率上的表現(xiàn)都是最佳的.

圖2 不同融合度下的準(zhǔn)確率

圖3 不同融合度下的召回率
3.3 實(shí)驗(yàn)結(jié)果
本文選取使準(zhǔn)確率和召回率都到達(dá)最理想效果的融合度0.6,驗(yàn)證當(dāng)融合度值確定時(shí)本方法在不同近鄰數(shù)K下的準(zhǔn)確率和召回率,使用主流應(yīng)用的基于內(nèi)容的推薦方法、協(xié)同過濾推薦方法以及混和推薦方法作為本文提出的推薦方法的對比方法.通過對比實(shí)驗(yàn)比較這4種方法在近鄰數(shù)的不同選值下準(zhǔn)確率和召回率的情況.近鄰數(shù)K的值分別選取50,70,90,110和130,實(shí)驗(yàn)10次取得平均值作為實(shí)驗(yàn)的最終結(jié)果.
從圖4和圖5中可以看出,本文提出的推薦方法在準(zhǔn)確率和召回率上表現(xiàn)良好,說明在引入知識圖譜概念的基礎(chǔ)上,對2種相似度進(jìn)行融合,推薦的效果比基于內(nèi)容的推薦方法和協(xié)同過濾推薦方法相比要更好,當(dāng)近鄰數(shù)為100時(shí),本文提出的方法在準(zhǔn)確率上提升了約5%,在召回率上提升了約3%,彌補(bǔ)了當(dāng)前推薦方法的不足,同時(shí)也說明了本文提出的職位推薦方法的優(yōu)越性.
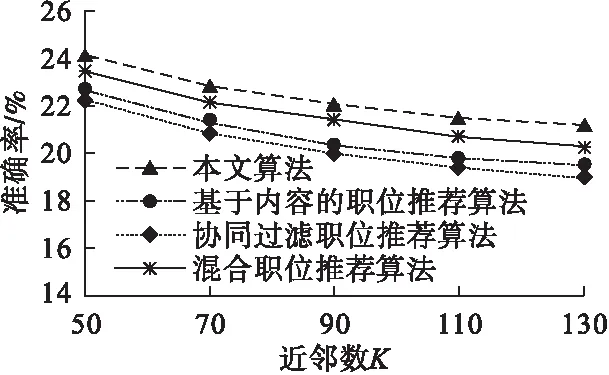
圖4 不同近鄰數(shù)K下的準(zhǔn)確率

圖5 不同近鄰數(shù)K下的召回率
4 結(jié)束語
針對大學(xué)生面對海量招聘信息時(shí)的職位選擇困惑,本文提出了基于知識圖譜的職位推薦方法,通過使用圖形數(shù)據(jù)庫Neo4j構(gòu)建一個(gè)求職招聘領(lǐng)域知識圖譜,將知識圖譜中的實(shí)體映射到低維稠密向量空間里,對其中的實(shí)體和關(guān)系進(jìn)行向量化表示,計(jì)算用戶的簡歷信息與職位信息之間的相似度,同時(shí)根據(jù)用戶行為計(jì)算其與職位間的相似度,通過融合相似度計(jì)算得到用戶對職位的預(yù)測評分,進(jìn)而生成職位推薦列表,以提高推薦系統(tǒng)的精準(zhǔn)度.經(jīng)對比實(shí)驗(yàn)驗(yàn)證,本文所提職位推薦方法能夠更好地滿足當(dāng)前大學(xué)生的就業(yè)需求.
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
