基于BERT的交互式地質實體標注語料庫構建方法
2022-08-05 02:01:20張春菊,張磊,陳玉冰,劉文聰,薄嘉晨,肖鴻飛
地理與地理信息科學 2022年4期
張 春 菊,張 磊,陳 玉 冰,劉 文 聰,薄 嘉 晨,肖 鴻 飛
(1.合肥工業大學土木與水利工程學院,安徽 合肥 230009;2.深圳市規劃和自然資源局,廣東 深圳 518034;3.烽火天地通信科技股份有限公司,江蘇 南京 210019)
0 引言
地質實體(包括巖石、地質構造、地層等)[1]是地質信息表達中的關鍵和核心要素,如何準確識別文本中的地質實體以有效抽取地質信息、獲取地質知識,成為地質大數據建模和礦產資源知識圖譜構建的基礎性和關鍵性工作。地質大數據[2]中的地質文獻和調查報告等地質文本數據多為非結構化數據[3,4],需將其轉化為結構化數據以便進一步挖掘利用。命名實體識別作為信息抽取的重要任務[5],其目的是識別出文本中具有明確意義的實體成分,對于文本數據的結構化處理至關重要。命名實體識別方法可分為:1)基于規則的方法,通過制定規則和模板,輔以實體詞典實現命名實體識別[6],該方法無需標注語料、準確率較高,但依賴領域專家制定規則和模板,受領域知識差異、語言結構不同的限制,存在耗時耗力、難以移植等問題;2)基于半監督學習的方法,通過使用少量標注數據和大量無標注文本對模型進行訓練,取得較好結果[7];3)基于監督學習的方法,主要采用支持向量機(SVM)[8]、條件隨機場(CRF)[9]、深度神經網絡(DNN)[10,11]等模型,通過學習訓練大量的標注語料數據進行命名實體識別,取得理想效果[12,13]。除地質實體外,地質時間信息的高效抽取有助于描述地質實體的狀態和演變信息[14]。因此,基于監督學習的方法需要高質、高效地構建地質語料庫,將其作為標準的訓練和測試數據。
命名實體標注語料庫構建方法主要包括人工標注和自動標注兩種方式:前者準確性高,但標注效率低、耗時耗力、規模有限,同時存在主觀性,很難保證標注結果的一致性;后者效率高、應用領域廣,但存在明顯的錯標、漏標等現象。常用的中文命名實體語料庫有針對通用領域的1998人民日報語料庫[15]、MSRA語料庫[16]以及地理學領域的中國大百科(地理版)語料庫[17]等,但地質實體特有的描述特征使得上述標注語料庫無法直接、有效地應用于地質實體識別領域。目前,地質實體語料庫主要基于地質報告、地質文獻等數據源,采用人工標注方式進行構建,其規模少則數萬字,多則幾十萬字,尚沒有統一的語料庫構建方法[13,18];隨著深度學習的發展,基于遠程監督的方式逐漸應用于構建地質實體語料,但精度較低[19]。當前語料庫的常見標注格式為BIO、BIOES,部分使用XML格式保存[10,13,14,18]。
BERT(Bidirectional Encoder Representations from Transformers)是基于雙向Transformer的神經網絡模型[20],能極大地增加詞向量模型的泛化能力,充分提取字符級、詞級、句級甚至句間關系特征,相較于Word2vec[21]、Glove[22]語言模型,能充分利用詞的上下文信息,得到更好的詞分布式表示;長短期記憶(Long Short-Term Memory,LSTM)模型[23]很好地解決了循環神經網絡(RNN)的長距離依賴問題,但只能獲取文本的單向信息,因此,Graves等[24]提出了雙向長短期記憶(Bi-directional Long Short-Term Memory,BiLSTM)模型,將單向LSTM網絡結構轉變為雙向結構,能有效提取上下文信息,成為命名實體識別等任務中最常用的模型;CRF[25]多用于序列標注任務中,可對BiLSTM的輸出添加約束,以保證輸出預測標簽的順序正確,因此將CRF層作為模型的輸出層進行解碼,在命名實體識別任務中表現較好[26]。鑒于此,本文通過BERT-BiLSTM-CRF模型自動標注文本中的地質實體并結合人機交互方式校正,同時利用標注的語料優化地質實體識別模型的性能,最終實現大規模、高質量地質實體標注語料庫的構建。
1 研究方法
本文技術路線(圖1)為:首先收集發表在學術期刊上的地質文章,歸納總結地質實體的特征,制定地質實體的標注規范,利用自主開發的標注軟件人工構建初始的地質實體語料;其次利用標注的語料對BERT-BiLSTM-CRF地質實體識別模型進行訓練,保存訓練好的模型;然后將其嵌入人機交互式地質實體標注軟件中,用于識別文獻中地質實體;最后對模型識別錯誤的地質實體進行人工校驗,保存改正后的地質實體語料。當新增的地質實體語料達到一定規模時,標注軟件將使用包含新語料的地質實體語料庫對地質實體識別模型進行重新訓練,對比訓練前后兩個模型的識別效果,保留效果較好的地質實體識別模型。

圖1 交互式地質實體標注方法技術路線Fig.1 Technical route of interactive geological entity annotation method
1.1 地質實體語料庫構建
地質領域缺少公開的標注數據集或語料庫,而地質期刊文獻是地質工作者優質科研成果表達的重要載體,其內容表述比較規范,包含的知識密集、豐富。因此,本文將發表在《地質學報》《巖石學報》《地質通報》等期刊上的300篇地質文獻作為數據源,去除圖表、參考文獻等無關內容,將清洗后的內容保存為txt格式。
對于地質實體的分類,Qiu等[10]將地質實體信息分為地質構造、巖石、地質年代、地層、地名5類;張雪英等[18]將地質實體信息總結為基本類型、空間分布、屬性信息及相互關系4種要素分類體系;馬凱[27]將銅礦床實體分為大地構造單元、成礦時代、礦體特征、礦石特征、礦區地質、礦床類型和其他;謝雪景等[28]將地質實體分為地質年代、地質構造、地層、巖石、礦物與地點6類。本文總結地質實體分類體系,以金礦地質實體為研究對象,參考《黃金礦業術語》(GB/T 34167-20173)、《巖金礦地質勘查規范》(DZ/T 0205-2002)、《金礦石》(GB/T 32840-2016)等行業規范以及《中國礦床模式》等書籍,按照構造尺度、埋藏范圍、埋藏規模將金礦地質實體分為礦區(KQ)、礦床(KC)、礦段(KD)、礦體(KT)4類。
對于保存的地質文獻數據,利用交互式地質實體標注軟件的人工標注功能進行標注,語料的標注格式采用BIO格式(“B”代表地質實體的開始部分,“I”代表地質實體的中間或結尾部分,“O”代表非實體部分),標注樣例如圖2所示。為保證語料的質量和權威性,本文首先參考地質領域已有研究成果中的實體分類體系并與地質學專家進行探討,制定標注規范。在標注前對標注人員進行培訓,使其對地質實體標注規范有足夠的知識儲備。在遇到模糊的標注實體或多人標注出現異議的實體時,需集中討論并請教地質學專家。經過多人交叉檢查校驗,不斷對標注規范進行修正,以減少主觀因素導致的錯標、漏標問題,最終得出統一的標注結果。經過多次核定,獲得50萬余字的初始地質實體標注語料,作為地質實體識別模型標準化訓練和測試數據。
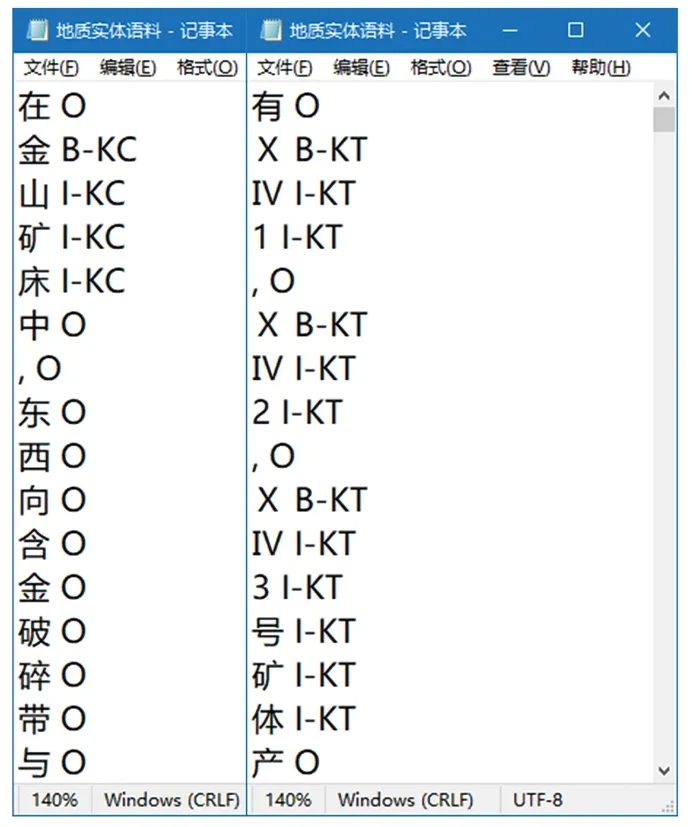
圖2 語料標注樣例Fig.2 Corpus annotation examples
1.2 基于BERT的地質實體識別模型構建
本文采用BERT-BiLSTM-CRF模型框架(圖3)進行地質實體識別。首先利用BERT預訓練語言模型獲取地質實體描述特征,將輸入的字符轉化為含有字符向量、句級向量和位置向量的拼接向量;然后通過BiLSTM模型提取BERT輸出的向量特征,充分學習上下文信息;最后根據CRF模型計算標注序列的概率分布,從而確定描述文本所包含的地質實體信息。

圖3 BERT-BiLSTM-CRF模型框架Fig.3 Framework of BERT-BiLSTM-CRF model
1.3 人機交互式地質實體標注
基于構建的地質實體標注語料庫和識別模型,利用Python的Tkinter模塊開發人機交互式地質實體標注軟件,主要包括地質實體人工標注、基于識別模型的地質實體自動識別和地質實體人工校正三大功能(圖4)。人工標注功能選定地質文本中的地質實體進行標注,構成地質實體識別的初始語料庫;自動識別功能對待處理的地質文本數據應用訓練好的模型進行識別,對識別結果的人工檢查與校正構成地質實體校正模塊。首先,通過“打開文件”按鈕或直接復制粘貼將待處理文本輸入標注軟件,可選擇模型識別或人工標注方式對待處理文本中的地質實體進行識別,用不同顏色表示不同地質實體類別;而后對于識別錯誤的地質實體可通過鼠標選中后右擊選擇“取消設置實體”功能進行校正,對于未能識別出的地質實體可選擇“設置地質實體”功能標定為地質實體,同時通過點擊“改正后實體結果對比”按鈕直觀顯示人工修訂前后的結果;最后,點擊“保存結果”按鈕將修訂好的語料保存為txt格式文件,其內容與圖2的示例語料格式一致。
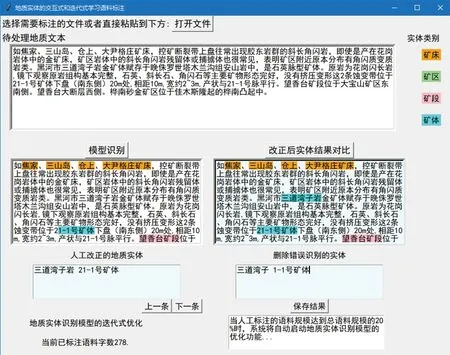
圖4 交互式地質實體標注軟件Fig.4 Software interface for interactive geological entity annotation
為提高地質實體識別模型的效果和最大化利用已標注地質實體語料的價值,本文設計了基于迭代式學習的BERT-BiLISTM-CRF地質實體識別模塊。
將新增標注語料與已有地質實體語料融合,經過混合、清洗等操作后,將標注語料輸入地質實體識別模型中再次訓練(滿足閾值要求時),并將新增語料加入地質實體標注語料庫;迭代循環上述步驟直至所構建語料庫滿足要求。鑒于初始地質實體語料庫已達50萬余字,為保證新增語料庫規模足夠大及模型參數重新訓練的頻率,本文將閾值設定為初始語料庫的20%,隨著語料規模增加,可重新設定閾值。
2 實驗結果與分析
為驗證模型的效果,使用標注好的地質實體語料進行模型性能判斷。本文采用BERT全詞遮蔽語言模型(BERT-wwm),該模型是哈工大訊飛聯合實驗室對Google發布的原始(origin,ori)BERT模型通過全詞遮蔽方式再訓練[29]生成的,一定程度上能解決中文分詞錯誤問題,同時使用地質標注數據對BERT進行微調,使BERT能更好地表征地質領域的特征。該模型包含12層Transformer結構,隱層為768維,使用多頭(12頭)注意力機制,共110 M參數,訓練過程中,BERT-BiLSTM-CRF模型的最大序列長度為128,批處理參數為8,學習率為2×10-5,Dropout為0.5。本文實驗配置為Intel Core i7-9750H CPU、64 GB內存、Window 10操作系統、Python 3.6編程語言、PyCharm編輯器。通過實驗發現,當訓練集、驗證集、測試集的數量比例為3∶1∶1時,模型識別效果最好,因此,后續實驗以該比例下的識別結果為基準進行對比。本文采用自然語言處理領域中常用的3個評測指標(準確率P、召回率R、F1值)對地質實體識別結果進行評測,計算公式為:
P=正確識別實體個數/識別出的實體個數
(1)
R=正確識別實體個數/文本中的實體個數
(2)
F1=2×P×R/(P+R)
(3)
2.1 與其他方法的對比
選取CRF、Word2vec-BiLSTM-CRF、Lattice-LSTM-CRF[30]3種常用的命名實體識別模型進行對比分析(表1),其中,CRF使用CRF++0.58工具,Word2ve-BiLSTM-CRF使用預訓練Word2vec詞向量(基于維基百科數據庫訓練得到)。由表1可知,本文BERT-BiLSTM-CRF模型識別結果優于上述3種常用模型,尤其是比CRF模型的P、R、F1值分別提升了8.30%、23.03%、16.10%。分析其原因,CRF通過設置特征模板獲取特征,對于未登錄詞的識別效果差,而本文模型基于BERT能結合上下文語境自動提取詞級特征,可有效識別未登錄詞,特征提取能力更強,能更好地表征不同語境中的詞法和語義信息,提高了地質實體的識別效果。
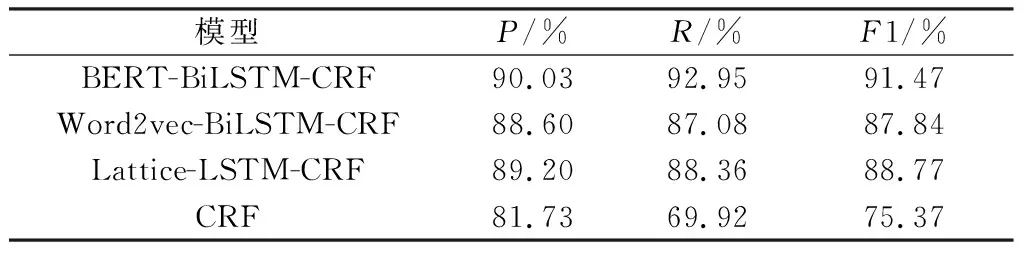
表1 不同模型識別結果Table 1 Recognition results of different models
由部分地質實體識別結果示例(表2)可知:例一中,地質實體識別模型能準確識別出“望鄉臺礦段”“大寶山礦區”等地質實體信息;例二中,能準確識別文本中出現的“Ⅰ”“Ⅱ”等數字;例三中,人工標注出現錯誤,但模型仍能正確識別出地質實體,具有校正語料的功能;例四中,對于連續出現的地質實體,模型的識別效果較好。

表2 地質實體信息識別結果示例Table 2 Examples of geological entity information recognition results
2.2 地質實體語料庫結果分析
為進一步測試本文構建的金礦地質實體語料庫的完備性,對構建的地質實體語料庫進行分析。考慮到地質實體的類型較多,選擇部分實體進行測試。其中構建的測試集中含有礦區實體141個、礦床實體702個、礦段實體81個、礦體實體168個。利用訓練后的BERT-BiLSTM-CRF地質實體識別模型對測試集進行識別,結果如表3所示。可以看出,在測試集上識別出的地質實體與人工標注的地質實體數量較一致,且對不同類別的地質實體識別效果均較好,驗證了地質實體分類的合理性和地質實體語料庫構建的可行性。
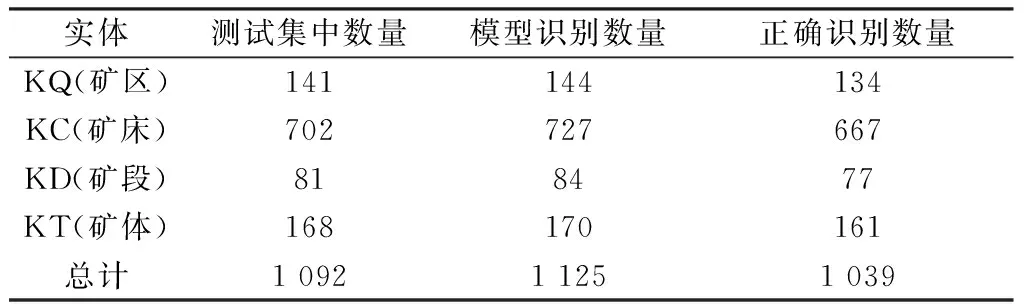
表3 基于BERT-BiLSTM-CRF模型的金礦實體識別結果Table 3 Gold entity recognition results based on BERT-BiLSTM-CRF model
為驗證語料庫規模對地質實體識別模型的影響,本文利用該標注軟件對地質文本數據進行人機交互式標注和訓練模型的迭代式學習,以擴大語料規模和提升地質實體識別模型的性能。在原始訓練集的基礎上,當新增的語料規模達到設定閾值20%時,標注軟件將重新訓練BERT-BiLSTM-CRF地質識別模型,并評價新訓練模型的性能。如表4所示,在保證驗證集和測試集不變的情況下,通過交互式標注語料擴大訓練集規模,模型的準確率P、召回率R和F1值均有提升,說明擴大語料的規模對模型精度有提升作用。

表4 BERT-BiLSTM-CRF模型在增加訓練集規模前后的金礦實體識別結果Table 4 Gold entity recognition results based on BERT-BiLSTM-CRF model before and after increasing the scale of training set
應用本文交互式地質實體語料庫構建方法對地質文本進行標注,最終獲得63萬余字的地質實體語料庫,包含句子11 039句,實體6 657個,其中礦區、礦床、礦段和礦體實體數量分別為765個、4 358個、468個和1 066個。語料庫中地質實體呈以下特點:1)礦區實體名稱通常由“地名”+“礦區”或“地名”+“類型”+“礦區”構成,如“埠南礦區”“文峪金礦區”等,且礦區實體的命名具有多樣性,如“文峪金礦區”“文峪Au礦區”等多種描述均表示同一礦區實體;同時文本中的礦區描述會出現省略情況,如“金山、石塢礦區”,省略了“金山”后的“礦區”,在標注與識別時需要與表示地名實體的描述信息區分。2)礦床實體的名稱描述與礦區實體相似,“類型”描述多采用“大型”“中型”“小型”等詞語刻畫礦床的規模特征。3)礦段多用于描述礦區或礦床中的具體部分,因此礦段實體名稱多為“地名”+“礦段”形式,而且在文本描述中,常與表示礦區或礦床的信息一同出現。4)礦體為礦床的基本組成單位,一個礦床中往往包括多個礦體,因此其命名多用排序的方式表示,如“Ⅰ-1、Ⅱ-1、Ⅲ-1號礦體”。
BERT-BiLSTM-CRF地質識別模型對地質文本自動標注時,若地質實體名稱過長,該模型往往不能對其正確識別,需借助人工校正。通過對語料庫中不同類型的地質實體名稱長度(漢字、數字、英文字母、特殊符號等的字符數均設為1)進行統計(表5)可知:地質實體名稱長度多為2~4個字符,模型對于此類實體名稱識別效果較好;長度小于2個字符多為實體的省略情況,如“Ⅰ、Ⅱ號礦體”中,礦體實體“Ⅰ”省略了礦體信息;長度大于6個字符的地質實體多為漢字、數字、英文字母、特殊符號等組合形式,如“S8201-③號礦體”“蔡家營Pb-Zn礦區”等,在識別時會出現分詞錯誤導致地質實體名稱邊界錯誤。
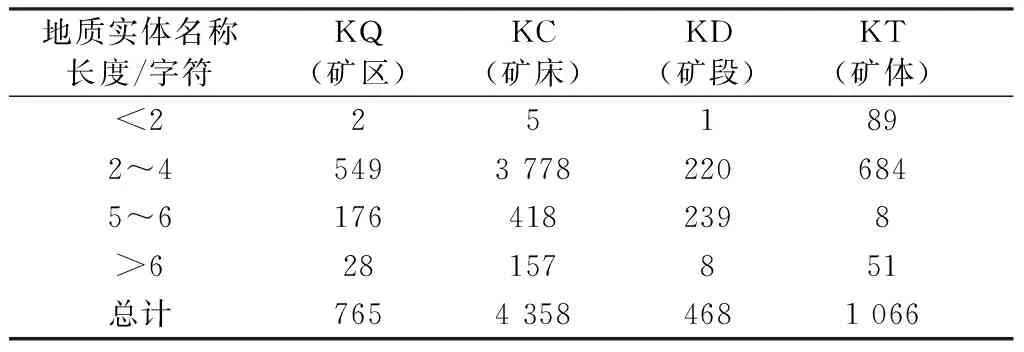
表5 語料庫中地質實體名稱長度統計Table 5 Length of geological entity names in corpus
3 結論
針對目前中文地質實體識別中公開的標注語料較少且人工標注語料難度大、成本高的難題,本文提出基于BERT的交互式中文地質實體標注方法。該方法集成高性能的BERT-BiLSTM-CRF中文地質實體識別模型、人機交互標注模塊和標注語料庫智能優化模塊,通過交互式迭代學習的BERT-BiLSTM-CRF中文地質實體識別模型,以金礦實體為例,實現大規模地質實體標注語料庫的構建。實驗結果表明:本文BERT-BiLSTM-CRF中文地質實體識別模型比CRF、Word2vec-BiLSTM-CRF、Lattice-LSTM-CRF 3種常用模型的識別效果好,在初始語料庫上F1值達91.47%,通過人機交互模塊增加語料規模后,模型識別效果提升了1.36%,既增加了地質實體標注語料庫的規模,又提升了識別模型的性能。但本研究未涉及地質實體的屬性、關系等相關信息的標注,后續將開展此方面的研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
