基于自注意力機制的視頻超分辨率重建
2022-08-23 07:16:40秦昊宇張力波吳學致任衛軍
計算機技術與發展 2022年8期
秦昊宇,葛 瑤,張力波,吳學致,任衛軍
(長安大學 信息工程學院,陜西 西安 710064)
0 引 言
隨著智能手機及各類攝影攝像設備的普及,圖像、視頻在人們生活中占據著越來越重要的地位。同時,人們對于圖像、視頻清晰度的需求也在逐漸提高。自Harris和Goodman首次提出圖像超分辨率重建的概念與方法[1]以來,超分辨率方法作為計算機視覺領域中圖像處理的一項技術,能夠提高已經拍攝出的圖像視頻的分辨率,已經廣泛應用到人們生活中的各個方面,具有重要的研究價值。
超分辨的核心在于尋找低分辨率圖像與高分辨率圖像特征之間的映射關系[2]。Dong Chao等人在2014年首次將深度卷積網絡CNN融入圖像超分辨重建,提出了一種全卷積網絡模型SRCNN[3]。隨著深度學習的不斷深入研究及其在圖像處理應用范圍的擴大,更多基于深度學習方法的超分辨率重建網絡模型正在進一步發揮作用[4],而超分辨率技術也不再局限于圖像,而是開始向視頻領域發展。視頻超分辨率重建可分別在時間域和空間域上進行重建[5]。空間視頻超分辨率重建通過引入更多的相鄰幀,將幀間互補信息對齊融合到關鍵幀以提高關鍵幀重建效果。時間可變形的對齊網絡(temporally deformable alignment network,TDAN)[6]對從原始幀提取的特征使用可變形卷積網絡,自適應地完成當前幀與相鄰幀的對齊,并動態地根據估計出的特征空間補償信息進行隱式運動補償,從而通過重建模塊得到高分辨率的視頻幀。EDVR[7](enhanced deformable convolutional networks)在TDAN模型的基礎上提出了多尺度特征圖對齊模塊,更好地完成了幀間互補信息對齊。時間域的視頻超分辨率重建主要是通過給定當前幀圖像和下一幀圖像,從而生成中間幀的視頻插幀技術來實現。目前,通過深度神經網絡學習現有幀與未知幀的映射關系存在一定困難,因此常用通過學習得到的中間幀的光流信息來進行傳統插值,進而生成中間幀。該文是在現有的算法研究基礎上對視頻超分辨率重建進行深入研究,構建了一種融合時間與空間域的視頻超分辨率重建模型VTSSR,實驗證明,該模型充分考慮到了視頻幀間運動時間與空間的關聯性,提高了視頻超分辨率的重建效果。
1 超分辨率重建理論
現實生活中,各種外在影響會使得采樣得到低分辨率圖像,這一現象稱為圖像退化[8]。逆向處理圖像退化,從而恢復出高分辨率圖像和視頻的技術就稱為超分辨率重建技術。
視頻超分辨率重建分為時間域和空間域的視頻超分辨率重建。時間域超分辨率重建主要是將由于采樣設備、視頻壓縮等造成高頻信息丟失的低幀率視頻幀重構成高幀率[9],重構過程主要使用視頻插幀的方法。常用的視頻插幀方法主要是基于運動補償的視頻插幀,其主要思想是通過運動估計和運動補償在原視頻序列連續的兩幀之間插入圖像幀,基于運動補償的插幀方法步驟如圖1所示。

圖1 基于運動補償插幀
如圖1所示,該過程將輸入的原始低幀率視頻序列經過運動估計得到相鄰幀之間的運動矢量,再將這些運動矢量經過運動補償插幀等操作生成插幀后的高幀率序列。其中,運動估計是計算視頻幀上同一個像素點在相鄰圖像幀之間運動時發生的空間偏移量[10],而運動補償就是根據這些偏移量計算該像素點在中間幀的對應位置,從而補償差值生成中間幀。
空間域超分辨率重建是從連續的低分辨視頻幀序列中重建得到對應的高分辨率幀序列,其中重構過程使用多幀圖像超分辨率重建方法實現,其關鍵在于多幀幀間信息的配準。這些由視頻得到的多幀圖像在亮度和像素上存在細微差別,能夠通過捕獲幀間差異信息完成超分辨率重建[11],方法過程如圖2所示。

圖2 視頻超分辨率重建
由圖2可知,該過程首先將輸入的原始低分辨率視頻幀序列利用運動估計算法預測幀間運動矢量,再對本段序列幀中的關鍵幀進行運動補償,接著將相鄰幀圖像與當前關鍵幀圖像進行對齊配準,使兩幀位于同一坐標系中,最后經過重建網絡將多個特征圖像融合得到關鍵幀的高分辨率圖像。
2 融合時間域與空間域的視頻超分辨率重建模型
2.1 模型框架
融合時間域和空間域的視頻超分辨率重建模型中的重建網絡由特征提取、特征插值、自注意力機制融合以及亞像素卷積上采樣和殘差塊四部分組成,能夠同時對視頻進行時間域和空間域超分辨率重建,最后輸出高幀率的高分辨率視頻。由于視頻幀間互補信息在時間和空間上具有一定的關聯性,該模型采用可變形卷積對齊、自注意力融合技術增強了這一關聯性,從而進一步提升了視頻超分辨率重建的效果。模型框架如圖3所示。

圖3 VTSSR模型結構
2.2 特征提取
基于深度學習的視頻超分辨率重建使用卷積神經網絡,區別于光流法復雜的假設條件和公式推理,直接通過卷積運算來學習相鄰幀之間的運動信息,降低了特征提取的復雜度,提高了特征的語義性。此外,引入殘差塊能夠加深卷積結構,從而增強模型重建能力并提高重建視頻質量。該文使用卷積神經網絡進行特征提取的模塊如圖4所示。

圖4 特征提取模塊
圖4中展示了該特征提取模塊的操作流程,該模塊由一個卷積層和多個殘差塊組成。首先,輸入的相鄰奇數幀It+i經過卷積網絡提取出其特征圖Ft+i,再將提取的特征圖Ft+i經過殘差塊提高模型重建能力,最后將其用于特征插幀模塊的輸入。
2.3 特征插值
由于該模型是融合了時間域和空間域的視頻超分辨率重建模型,模型關鍵在于增強視頻幀間互補信息在時間和空間上的關聯性,因此特征時間插值模塊在相鄰幀的特征圖上直接對齊得到中間幀特征圖,而不是先重建生成中間幀再得到中間幀的特征圖。TDAN[12]基于可變形卷積的對齊模塊,利用卷積網絡學習幀間運動進行信息建模代替了光流預測法,能夠更好地對齊相鄰特征圖。融合了時間域和空間域的視頻超分辨率重建模型參考了TDAN提出的原理,采用同模型不同方向的卷積,并加入了特征時間插值模塊的設計,如圖5所示。
圖5中,模塊輸入為相鄰的兩幀特征圖Ft+1和Ft-1,待插中間幀的特征圖為Ft,通過學習一個特征時間插值函數f(·)并利用相鄰的兩幀特征圖Ft+1和Ft-1直接合成和待插中間幀的特征圖Ft,它們之間的關系用公式表示為:
Ft=f(Ft-1,Ft+1)=H(Ft-1→t,Ft+1→t),t∈2N
(1)
其中,Ft+1→t為Ft+1到中間幀特征圖Ft的對齊特征,Ft-1→t為Ft-1到中間幀特征圖Ft的對齊特征,H(·)為一聚合采樣特征的混合函數。

圖5 特征時間插值模塊
由于中間幀特征圖Ft還未合成,無法直接計算Ft與Ft-1、Ft與Ft+1之間的運動信息,因此使用可變形采樣函數來隱式地獲取Ft-1與Ft+1之間的運動信息,以此來近似代替。首先輸入Ft+1和Ft-1合并Concat后經過3*3的卷積層,目的是減少通道數降低參數量。然后通過一個卷積層去預測輸出通道數量為|R|的采樣參數θ1,如式(2)所示:
θ1=g1(Ft-1,Ft+1)
(2)
其中,采樣參數θ1為可偏移學習量,g1表示多個卷積層的一般函數。同理,輸入Ft-1和Ft+1,Concat后經過3*3的卷積層,然后通過一個卷積層去預測輸出通道數量為|R|的采樣參數θ2,如式(3)所示:
θ2=g2(Ft-1,Ft+1)
(3)
接著使用可變形卷積計算出Ft+1到中間幀特征圖Ft的對齊特征Ft+1→t和Ft-1到中間幀特征圖Ft的對齊特征Ft-1→t,如式(4)所示:
Ft+1→t=T(Ft+1,θ1)=DConv(Ft+1,θ1)
Ft-1→t=T(Ft-1,θ1)=DConv(Ft-1,θ2)
(4)
最后,得到的兩個對齊特征通過H(·)混合函數分別相乘1*1卷積層再對位相加得到了最終中間幀的特征圖Ft。
2.4 特征融合
該模型在特征融合模塊中引入自注意力機制,將通過聯合學習對齊得到的多特征圖的時間、空間維度特征信息賦予新的權重并重新分配,能夠自適應地學習特征信息在不同維度之間的關聯性。基于這種方法的特征融合,能夠增強有用特征而抑制無用特征,從而更好地處理特征的幀間運動并利用幀內信息在時間和空間上挖掘特征信息。其結構如圖6所示。

圖6 基于自注意力融合模塊
如圖6所示,首先將需要融合的特征圖序列Fi合并concat后得到全部特征圖的和F,然后將特征圖通過全局池化層得到全部通道數的加權平均值向量S,其中S的通道數為C個,計算公式如式(5)所示:

(5)
接著使用兩個全連接層學習全部通道間的相關性,前一個全連接層使用壓縮因子r壓縮通道數C/r,后一個全連接層將通道數擴為原始的通道數C,計算得到F的特征向量矩陣M,計算公式如式(6)所示:
M=W2(σ(W1·F))
(6)
其中,W1和W2是兩個全連接層的權重矩陣。這樣先壓縮后擴充通道的方法能夠給各通道分配各自的注意力,從而可以達到增強有用特征而抑制無用特征的目的。接著使用卷積核為1*1的卷積層來卷積壓縮特征圖的時間維,將Fi的尺寸從C*H*W變為H*W,學習每個輸入特征矩陣在空間維度上的內部相關性得到序列{qi}計算公式如式(7)所示:
qi=CNN(W3·Fi)
(7)
式中,W3是卷積層的權重矩陣。
將得到的{qi}和特征向量矩陣M進行向量點乘得到通道和空間的相關性{Pi}計算公式,如式(8)所示:
Pi=qi·M
(8)
使用激活函數sigmod得到更加突出重要元素的權重矩陣{gi},如式(9)所示:
(9)
式中,(w,h,c)指像素的空間坐標和通道位置。最后將權重矩陣和輸入特征Fi對位求和得到最終的融合特征圖:
(10)
2.5 重建模塊
現有常見的基于深度學習的重建網絡主要是提取出低分辨率圖像中的特征,并通過學習這些特征將它們擴大成高分辨率圖像,從而實現超分辨率重建。該文提出的融合時間域與空間域的視頻超分辨率重建模型在重建時使用高分辨率圖像HR重建模塊,該模塊輸入來自低分辨率圖像中提取深層特征后構成的特征圖序列,使用多個堆疊殘差塊和兩個卷積網絡將輸入的低分辨、高幀率的特征圖像序列轉為高分辨、高幀率圖像輸出。
由圖7可知,HR重建模塊對輸入的特征圖序列使用殘差塊組成的網絡來繼續學習特征,這種方法能夠更好地利用圖像高頻信息[13],減小運算量。最后利用亞像素卷積上采樣擴大特征圖尺寸,輸出重建的目標分辨率圖像。
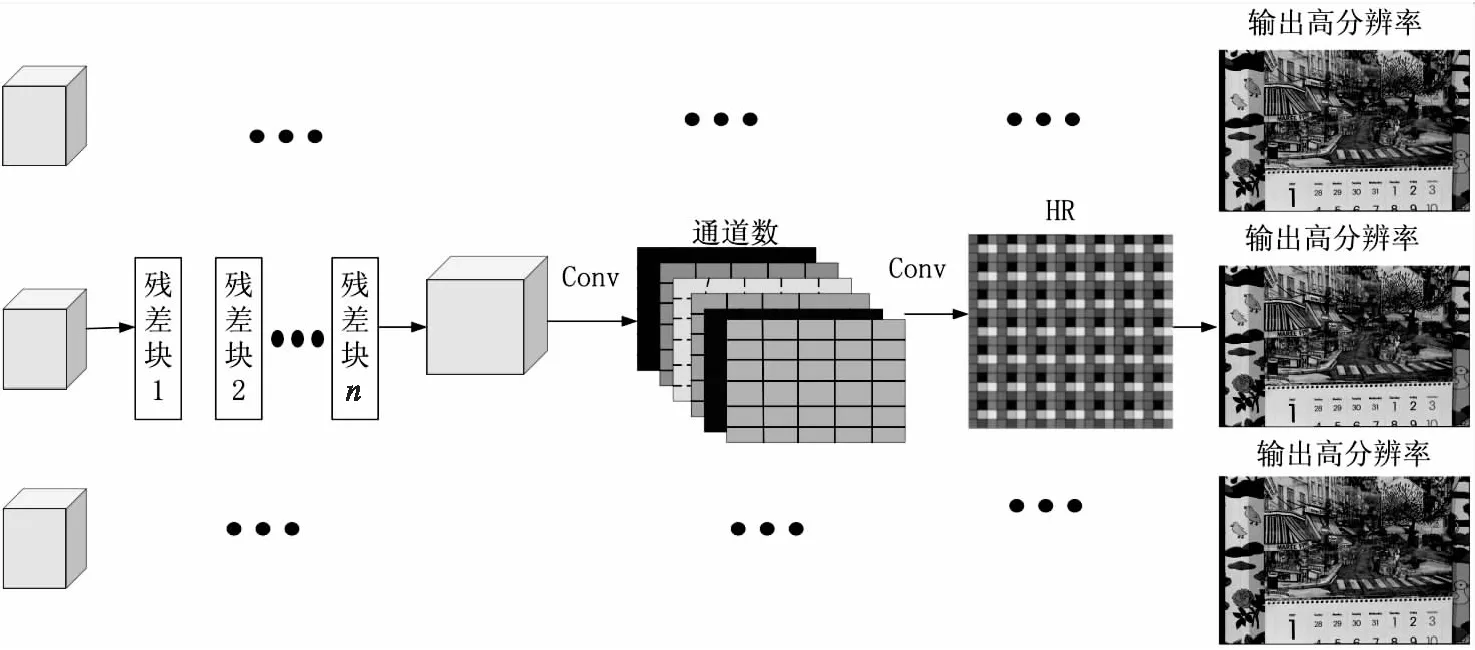
圖7 HR重建模塊
3 實驗結果與分析
3.1 實驗數據集
為了驗證該文提出的融合時間域與空間域的視頻超分辨重建模型的有效性,使用視頻超分辨領域主流的數據集Vimeo-90k[14]、Vid4[15]對模型進行實驗驗證,并將實驗結果和目前的視頻超分辨算法模型進行比較。本模型在獲取低分辨率圖像數據集時采用雙三次插值下采樣方法,測試時對放大4倍的圖像進行模型重建,并使用主觀視覺和客觀指標峰值信噪比PSNR、結構相似性SSIM[16]對模型重建效果進行評價。
3.2 實驗處理及參數設置
由于下載的公開數據集主要是高分辨率視頻,而訓練時需要與之對應的低分辨率視頻,因此使用Matlab工具將高分辨率視頻下采樣縮小成與之對應的低分辨率圖像,再分別將這些高分辨率圖像和低分辨率圖像生成lmdb格式以便作為輸入數據。本次實驗使用視頻序列中奇數標簽作為輸入,訓練模型配置文件參數如表1所示。

表1 配置文件參數設置
模型中使用的損失函數如式(11)所示:
(11)

3.3 實驗結果分析
訓練完成后,在Vid4和Vimeo-90k數據集上對構建的融合時間域和空間域視頻超分辨率重建模型VTSSR的可行性和有效性進行驗證。
3.3.1 PSNR和SSIM指標值
從Vid4數據集和Vimeo-90k訓練集中抽取測試集,對超分辨倍數為4的樣本進行實驗,與兩種時間插幀模型Sepconv[17]、DAIN[18]和三種空間超分辨模型Biubic[19]、RCAN[19]、EDVR[6]聯合的方法進行對比。VTSSR是該文構建的融合時間域和空間域的視頻超分辨率重建模型。通過對比可以看出,該模型在一定程度上優于其他模型,各自模型的峰值信噪比PSNR和結構相似性SSIM指標對比如表2所示。

表2 模型客觀指標對比(PSNR(DB)/SSIM)
3.3.2 主觀對比
為了進一步對比重建效果,在Vimeo-90ktest數據集選取多個不同的視頻片段的圖像,對這些圖像進行模型重建,并在主觀視覺上對高分辨率圖像、下采樣低分辨率圖像、SepConv+EDVR、DAIN+Bicubic、DAIN+RCAN與構建的模型VTSSR的重建結果進行評價對比;在Vid4數據集上將高分辨率圖像、下采樣低分辨率圖像與構建的模型VTSSR的重建結果進行評價對比。對比結果如圖8所示。

圖8 Vimeo-90ktest和Vid4測試集主觀視覺對比
圖8中,選取了Vimeo-90ktest和Vid4數據集中各一個視頻片段圖像,通過對比可以看出VTSSR模型主觀視覺優于其他模型重建的效果。
通過比較不同重建模型在相同測試集上的結果,提出的融合時間域和空間域的視頻超分辨率重建模型VTSSR在量化指標和觀察主觀效果上都有一定的優勢。
4 結束語
為提高視頻分辨率,構建了一種融合時間域和空間域的視頻超分辨率重建模型VTSSR,可以在同一個網絡模型中同時對視頻進行時間域和空間域超分辨率重建。該模型以低幀率的低分辨率視頻作為輸入,首先,使用卷積層和多個殘差塊進行特征提取,使用幀特征插值生成中間幀的特征圖;其次,采用改進的基于自注意力機制模塊,融合特征圖時間和空間信息;最后,采用亞像素卷積上采樣重建,輸出高幀率的高分辨率視頻。在Vimeo-90ktest和Vid4測試集上的測試表明,該模型能夠克服光流預測難以處理遮擋、復雜運動的局限性、解決不同相鄰幀對于關鍵幀重建貢獻不同的問題。在Vimeo-90ktest測試集上其峰值信噪比為35.79 dB,結構相似性為0.937 4;在Vid4測試集上其峰值信噪比為26.29 dB,結構相似性為0.795 6,與其他重建模型相比均有提高。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
現代出版(2020年3期)2020-06-20 07:10:34
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
