顧及小目標(biāo)特征的視頻人流量智能統(tǒng)計方法
2022-08-25 03:03:36張?zhí)燹?/span>謝亞坤李闖農(nóng)李維煉
西南交通大學(xué)學(xué)報 2022年4期
朱 軍 ,張?zhí)燹?,謝亞坤 ,張 杰 ,李闖農(nóng) ,趙 犁 ,李維煉
(1.西南交通大學(xué)地球科學(xué)與環(huán)境工程學(xué)院,四川 成都 611756;2.四川豪格遠景市政建設(shè)有限公司,四川 成都610036)
智能視頻監(jiān)控設(shè)備作為安防的重要手段而廣泛存在于商場、醫(yī)院、學(xué)校、景點等公共場所.人流量統(tǒng)計是智能視頻監(jiān)控的重要研究內(nèi)容之一,對于智能安防、智慧旅游、災(zāi)后救援、交通規(guī)劃等領(lǐng)域的研究具有重要價值[1-3].
在機器學(xué)習(xí)技術(shù)出現(xiàn)之前,監(jiān)控視頻中的人流量統(tǒng)計多由人工完成,但這不僅需要耗費大量的人力物力,且視頻中的大量信息不能得到很好理解.隨著計算機視覺和機器學(xué)習(xí)技術(shù)的不斷突破,基于淺層學(xué)習(xí)的人流量統(tǒng)計方法不斷涌現(xiàn)[4-6].由于此類方法采用的是人工設(shè)計和提取特征,特征冗余度較高,且無法智能地提取有用信息,導(dǎo)致統(tǒng)計精度較低.而構(gòu)建深層次神經(jīng)網(wǎng)絡(luò)則可以通過自動學(xué)習(xí)的方式有效提取圖像深層次特征,進一步解決以上問題.
隨著人工智能時代的到來,基于深度學(xué)習(xí)的人流量統(tǒng)計方法不斷被提出[7-8].其與傳統(tǒng)方法的最大不同是它能從數(shù)據(jù)中自動學(xué)習(xí)得到特征,不需要人工設(shè)計和提取特征,且無需進行前景分割.Zhang等[9]通過卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)模型生成密度圖的方式實現(xiàn)了跨場景計數(shù),相比于手工設(shè)計特征的方式具有高效性和魯棒性.雖然此類方法不需要檢測每個行人,可以直接通過回歸或?qū)θ巳好芏葓D積分的方式得到人數(shù),但也正是因為無法獲得每個行人的具體信息,使得無法進行后續(xù)行人軌跡分析等方面的研究.近年來,由于深度學(xué)習(xí)在目標(biāo)檢測任務(wù)中不斷取得突破,基于深度學(xué)習(xí)檢測的人流量統(tǒng)計方法也相繼被提出[10-11].曹誠等[12]提出了一種基于卷積神經(jīng)網(wǎng)絡(luò)的視頻行人分析方法,實現(xiàn)了監(jiān)控區(qū)域中的人流量統(tǒng)計,但當(dāng)行人之間相互遮擋時會導(dǎo)致漏檢.張?zhí)扃鵞13]基于SSD(single shot multibox detector)算法和 KCF (kernel correlation filter)算法對人頭目標(biāo)進行檢測和跟蹤,進而分析目標(biāo)軌跡實現(xiàn)了雙向計數(shù),其通過檢測人頭目標(biāo)有效解決了行人之間的遮擋問題,但由于該方法采取了從行人正上方檢測頭部的策略,使得算法的應(yīng)用場景在很大程度上受到了限制.盡管上述方法取得了一定效果,但由于視頻中行人姿態(tài)、尺度各異,且存在不同程度的遮擋情況,使得現(xiàn)有方法在不同場景下的人流量統(tǒng)計準(zhǔn)確度較低.
為解決上述問題,本文擬開展顧及小目標(biāo)特征的視頻人流量智能統(tǒng)計方法研究.通過研究用于小目標(biāo)檢測的Faster R-CNN (Faster region-convolutional neural network)改進算法、探討基于軌跡預(yù)測的目標(biāo)跟蹤技術(shù)、設(shè)計雙向人流量智能統(tǒng)計算法,并構(gòu)建實驗環(huán)境開展實驗分析,期望實現(xiàn)視頻人流量精確智能統(tǒng)計.
1 視頻人流量智能統(tǒng)計方法
1.1 總體研究思路
視頻人流量智能統(tǒng)計的研究思路如圖1所示,主要包括用于小目標(biāo)檢測的Faster R-CNN改進算法、基于軌跡預(yù)測的目標(biāo)跟蹤、雙向人流量智能統(tǒng)計.
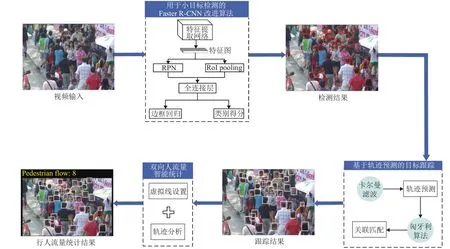
圖1 總體框架Fig.1 Overall framework
1.2 用于小目標(biāo)檢測的Faster R-CNN改進算法
Faster R-CNN[14]在通用目標(biāo)檢測領(lǐng)域表現(xiàn)優(yōu)異,對于常規(guī)目標(biāo)來說,其檢測精度高且速度較快.但由于本文所選擇的檢測對象為人頭目標(biāo),其在圖像上的尺寸較小,而Faster R-CNN對于小目標(biāo)檢測任務(wù)精度受限[15].因此,針對人頭目標(biāo),本文提出一種用于小目標(biāo)檢測的Faster R-CNN改進算法,算法框架如圖2所示.
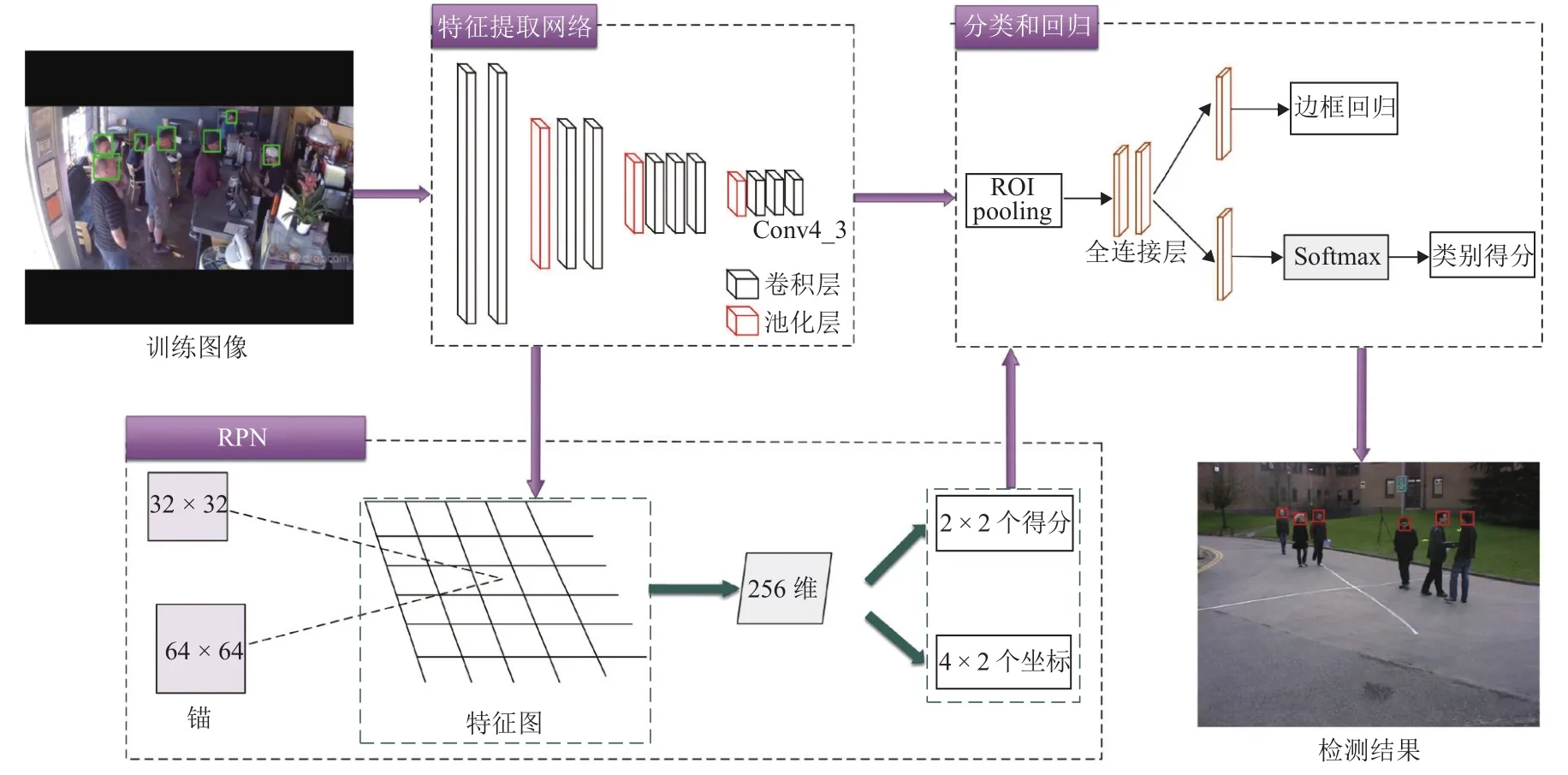
圖2 Faster R-CNN改進算法框架Fig.2 Framework of improved Faster R-CNN algorithm
CNN不同深度對應(yīng)不同層次的特征,深層網(wǎng)絡(luò)雖然能夠較好地表示圖像的語義特征,但同時也會忽略圖像的紋理、邊緣等細節(jié)特征,而淺層網(wǎng)絡(luò)能夠很好地表示這些細節(jié)特征[16].對于常規(guī)目標(biāo)來說,使用深層特征圖能夠提取到較為豐富的語義特征,進而提高算法的魯棒性,但人頭目標(biāo)與常規(guī)目標(biāo)相比,其信息量少且在圖像上占比較小,對應(yīng)區(qū)域像素反映的信息量有限,在語義特征較難提取的情況下再使用深層特征圖更會使得細節(jié)信息缺失.因此,本文將使用VGG16[17]中的Conv4_3層代替Conv5_3層輸入?yún)^(qū)域建議網(wǎng)絡(luò)(region proposal network, RPN)中生成候選區(qū)域(regions of interest, RoI),既能減少網(wǎng)絡(luò)復(fù)雜度,又可彌補小目標(biāo)在深層特征上細節(jié)信息的缺失.
Faster R-CNN中的RPN針對需要進行檢測的通用目標(biāo)設(shè)置了3種尺度(128, 256, 512)、3種寬高比(1∶1, 1∶2, 2∶1)共 9 種不同大小的錨(Anchor),但由于人頭目標(biāo)在圖像上占比較小,因此這種設(shè)置并不適用于小尺度的人頭目標(biāo).本文在RPN的基礎(chǔ)上根據(jù)訓(xùn)練數(shù)據(jù)集中人頭目標(biāo)的寬高比特性,將Anchor的尺度調(diào)整為(32, 64),且由于人頭目標(biāo)多為正方形,因此只設(shè)定一種寬高比例1∶1,這兩種尺度的Anchor既能覆蓋數(shù)據(jù)集中大部分的人頭目標(biāo),且由于產(chǎn)生的Anchor數(shù)量與原來相比大幅減少,導(dǎo)致后續(xù)需要進行坐標(biāo)回歸和分類的Anchor數(shù)量降低.圖3為改進的 Anchor與原 RPN中的 Anchor在Brainwash數(shù)據(jù)集[18]中的對比圖,其中紅色方框代表改進后的Anchor,尺寸分別為32 × 32和64 ×64,藍色方框代表原RPN中1∶1比例的Anchor,尺寸分別為 128 × 128、256 × 256 和 512 × 512.由圖3可以看出:原Anchor(藍色框)由于尺度過大并不適用于人頭目標(biāo),而改進后的Anchor(紅色框)能夠?qū)θ祟^目標(biāo)實現(xiàn)更為準(zhǔn)確的覆蓋.

圖3 多尺度下Anchor尺寸對比Fig.3 Contrast of multi-scale anchor size
1.3 基于軌跡預(yù)測的目標(biāo)跟蹤
基于軌跡預(yù)測的目標(biāo)跟蹤算法[19]主要包含軌跡預(yù)測和數(shù)據(jù)關(guān)聯(lián)兩部分,如圖4所示,首先利用卡爾曼濾波預(yù)測出每個目標(biāo)在下一幀的位置,進而通過匈牙利算法將實際檢測位置與預(yù)測位置進行對比關(guān)聯(lián).詳細闡述如下.
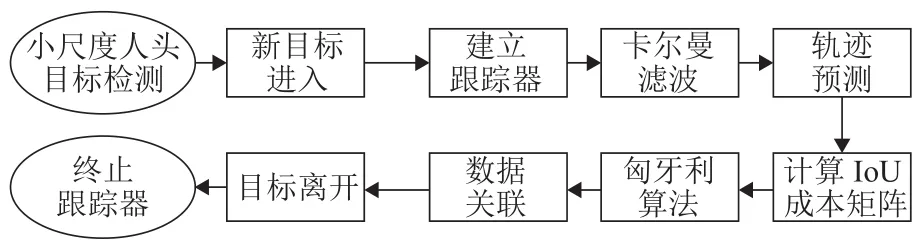
圖4 目標(biāo)跟蹤算法流程Fig.4 Flow chart of object tracking algorithm
卡爾曼濾波用于預(yù)測目標(biāo)軌跡狀態(tài),其將目標(biāo)的幀間運動近似為線性運動,并認(rèn)為目標(biāo)間、目標(biāo)與相機間運動獨立,那么運動目標(biāo)的狀態(tài)可以用式(1)表示.
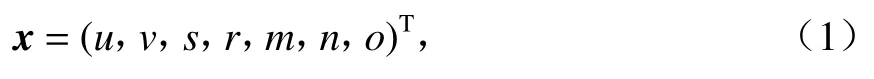
式中:u、v分別為目標(biāo)在水平和豎直方向上的中心坐標(biāo);s為目標(biāo)的面積;r為目標(biāo)的長寬比;m、n分別為目標(biāo)在水平和豎直方向上的運動速度;o為目標(biāo)的變化比率.
若檢測框關(guān)聯(lián)到目標(biāo)后,用檢測框更新目標(biāo)狀態(tài),同時速度分量利用卡爾曼濾波進行優(yōu)化求解;若目標(biāo)沒有與檢測框相關(guān)聯(lián),則用線性速度模型對目標(biāo)位置進行預(yù)測.
匈牙利算法用于前后幀數(shù)據(jù)關(guān)聯(lián).首先,通過運動模型得到前一幀中每個待跟蹤目標(biāo)的預(yù)測框;其次,計算當(dāng)前幀中每個目標(biāo)的檢測框和所有預(yù)測框之間的交并比(intersection over union,IoU)作為成本矩陣;最后,使用匈牙利算法對矩陣進行優(yōu)化求解.此外,應(yīng)拒絕檢測框與目標(biāo)預(yù)測框重疊小于閾值的分配,本文實驗中閾值取值為0.3.
當(dāng)某個目標(biāo)的檢測框和所有現(xiàn)有目標(biāo)預(yù)測框之間的IoU都小于閾值時則認(rèn)為進入新的待跟蹤目標(biāo),此時使用檢測框信息初始化新目標(biāo)的位置信息.若連續(xù)T幀沒有檢測框和目標(biāo)預(yù)測框的IoU匹配,則認(rèn)為目標(biāo)消失,本文實驗中T取值為1.這種基于軌跡預(yù)測的在線跟蹤方式能夠解決目標(biāo)前后幀運動過快以至于匹配失敗的問題,將下一幀預(yù)測的軌跡狀態(tài)與檢測目標(biāo)進行關(guān)聯(lián),使得目標(biāo)跟蹤成功的幾率大大提高.
1.4 雙向人流量智能統(tǒng)計
傳統(tǒng)人流量統(tǒng)計方法主要基于單線法實現(xiàn),但單線法存在無法靈活設(shè)定目標(biāo)區(qū)域、無法準(zhǔn)確判斷行人運動方向等問題,為解決上述問題,本文提出一種雙向人流量智能統(tǒng)計方法.相比于傳統(tǒng)單線法,通過雙虛擬線對需要監(jiān)視的目標(biāo)區(qū)域進行準(zhǔn)確設(shè)定,將復(fù)雜背景干擾因素排除在目標(biāo)區(qū)域之外,為目標(biāo)檢測和跟蹤創(chuàng)造有利條件,提高人流量統(tǒng)計精度,算法流程如圖5所示.
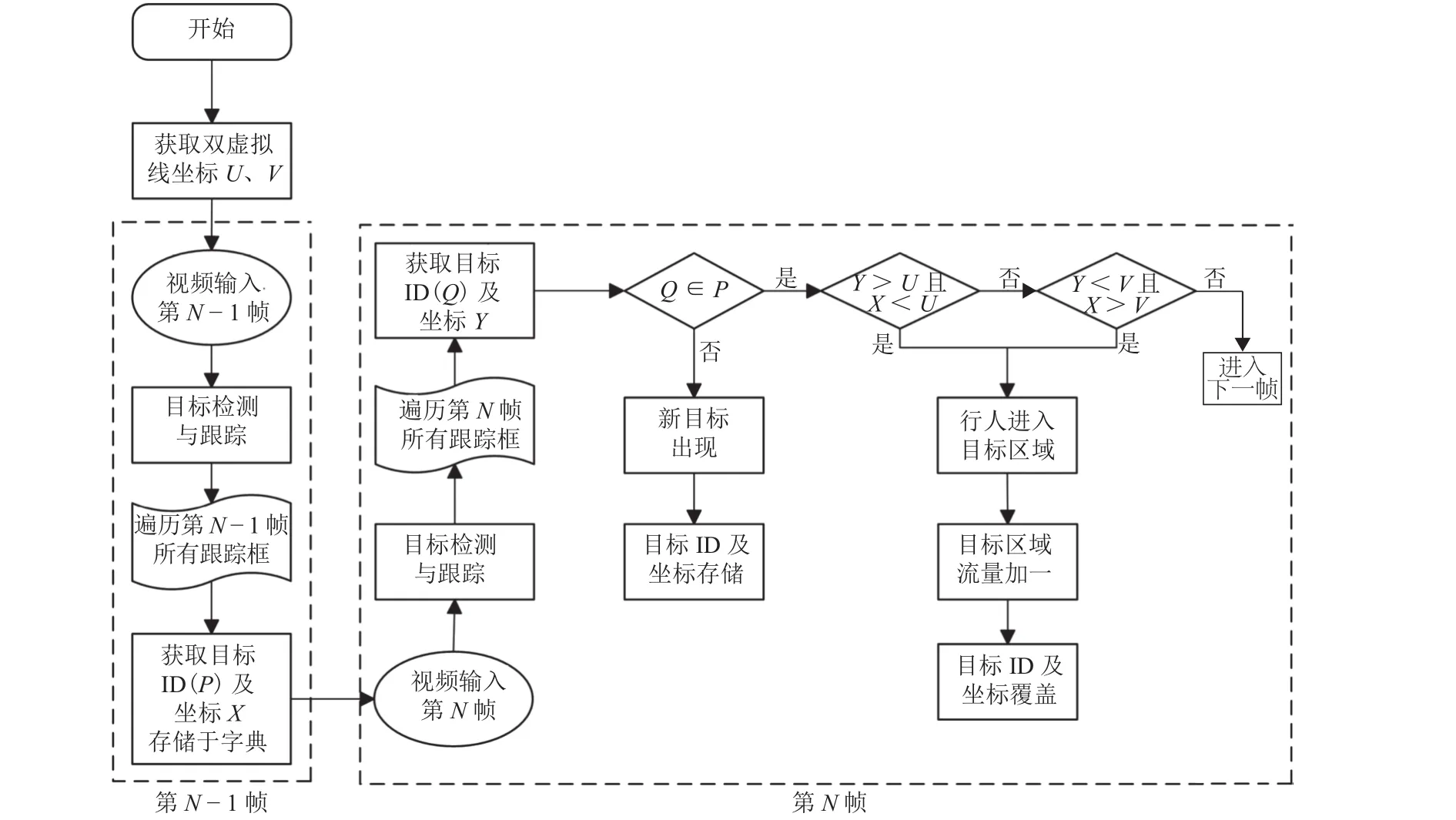
圖5 雙向人流量智能統(tǒng)計算法流程Fig.5 Flow chart of intelligent statistic algorithm of bidirectional pedestrian flow
首先,預(yù)先設(shè)定虛擬線并獲取其坐標(biāo);其次,經(jīng)過目標(biāo)檢測和跟蹤,第N-1幀和第N幀的每個目標(biāo)都被設(shè)定了唯一ID,將第N-1幀的目標(biāo)以ID為鍵、坐標(biāo)為值存儲于字典中;再次,遍歷第N幀中的所有目標(biāo)并依次判斷其是否在字典內(nèi),如不存在,則在字典中增加一條記錄,如存在,則判斷目標(biāo)坐標(biāo)和字典中相同ID的目標(biāo)坐標(biāo)與虛擬線坐標(biāo)之間的大小關(guān)系,具體判斷過程視實際場景而定;最后,遍歷所有視頻幀并重復(fù)上一步驟,完成目標(biāo)區(qū)域內(nèi)的人流量統(tǒng)計.
在實際視頻場景中利用雙虛擬線進行人流量統(tǒng)計的過程如圖6所示,在視頻中預(yù)先設(shè)置兩條虛擬計數(shù)線,其與視頻左右邊界圍成的區(qū)域即為要監(jiān)測的目標(biāo)區(qū)域.如1號目標(biāo)在第N-1幀中的坐標(biāo)小于計數(shù)線1的坐標(biāo),而在第N幀中其坐標(biāo)大于計數(shù)線1的坐標(biāo),表明行人此時進入目標(biāo)區(qū)域,目標(biāo)區(qū)域人流量加一.在實際應(yīng)用中,根據(jù)場景的具體情況靈活設(shè)置虛擬線的位置即可.本文設(shè)計的雙向人流量智能統(tǒng)計方法不僅算法復(fù)雜度低,可實現(xiàn)快速計數(shù),且通過準(zhǔn)確判斷行人運動方向?qū)崿F(xiàn)了人流量高準(zhǔn)確率統(tǒng)計.
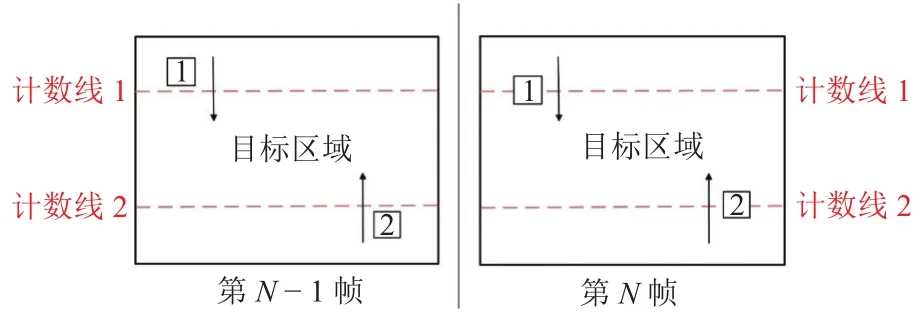
圖6 人流量智能統(tǒng)計過程Fig.6 Intelligent statistic process of pedestrian flow
2 實驗結(jié)果與分析
2.1 實驗環(huán)境與參數(shù)設(shè)置
實驗所用硬件配置為:操作系統(tǒng)為Windows 10,CPU為 Inter(R) i5-8300H@2.30 GHz, GPU為NVIDIA GTX1060,內(nèi)存為8 GB.模型訓(xùn)練的平臺基于深度學(xué)習(xí)開發(fā)工具TensorFlow,編程語言為Python.訓(xùn)練過程中參數(shù)設(shè)置為:學(xué)習(xí)率為0.001,Batch_size為128,最大迭代次數(shù)為20 000.
2.2 數(shù)據(jù)集
實驗訓(xùn)練集采用傾斜向下的攝像機拍攝的Brainwash人頭數(shù)據(jù)集,可有效地處理遮擋問題,并且不會受到應(yīng)用場景的限制,此數(shù)據(jù)集涵蓋了不同光照、不同遮擋程度的場景,以及不同尺度、不同顏色頭發(fā)的行人頭部樣本,數(shù)據(jù)集中用于訓(xùn)練的樣本有10 917幅,驗證樣本和測試樣本數(shù)量各500幅.
為檢驗本文方法在不同場景中的魯棒性,本文選取多種場景下的圖像及視頻進行測試,并分別設(shè)置目標(biāo)檢測實驗和人流量統(tǒng)計實驗,以測試本文方法的可靠性和先進性.
目標(biāo)檢測實驗選用兩種數(shù)據(jù)集進行測試,其一為Brainwash基準(zhǔn)數(shù)據(jù)集中的500幅測試圖像,其二為Pets2009基準(zhǔn)數(shù)據(jù)集[20]中S2L1的4種場景下隨機選取的509幅圖像,如圖7所示.

圖7 目標(biāo)檢測實驗測試集所包含場景Fig.7 Scenes for test set in object detection experiments
人流量統(tǒng)計實驗采用了互聯(lián)網(wǎng)下載的3段密集程度不同的監(jiān)控視頻進行測試,測試視頻具體信息如表1所示.

表1 人流量統(tǒng)計實驗視頻信息Tab.1 Experimental video information of pedestrian flow statistics
2.3 評價標(biāo)準(zhǔn)
本文使用平均準(zhǔn)確率(mean average precision,mAP)作為目標(biāo)檢測算法的評價標(biāo)準(zhǔn),使用召回率(R,式(2))、精確率(P,式(3))和F值(式(4))作為人流量統(tǒng)計算法的評價標(biāo)準(zhǔn),其中:R衡量算法對于正樣本的覆蓋能力;P衡量算法判別正樣本的準(zhǔn)確程度;F值則為權(quán)衡R和P的綜合指標(biāo).

式中:TP指實際為行人且被正確統(tǒng)計的數(shù)量,即正檢人數(shù);FP指實際為非行人但被錯誤統(tǒng)計為行人的數(shù)量,即誤檢人數(shù);FN指實際為行人但沒有被統(tǒng)計的數(shù)量,即漏檢人數(shù).
2.4 實驗結(jié)果分析
2.4.1 目標(biāo)檢測實驗分析
由于目標(biāo)檢測的精度直接影響人流量統(tǒng)計結(jié)果,實驗首先對目標(biāo)檢測算法進行定量精度評定.將本文算法與原始Faster R-CNN算法以及近年來流行的人頭目標(biāo)檢測算法在Brainwash基準(zhǔn)數(shù)據(jù)集上進行對比測試,結(jié)果如表2所示.文獻[18]通過提出一種ReInspect算法解決了密集場景中目標(biāo)檢測的遮擋問題,文獻[21]提出了一種卷積層信息融合的方法,通過聯(lián)合不同尺度的卷積特征信息以提高小目標(biāo)檢測準(zhǔn)確率,文獻[22]提出了一種基于錨點的完全卷積的FCHD頭部檢測算法,文獻[23]提出了一種基于改進YOLOv3-tiny的輕量人頭檢測算法MKYOLOv3-tiny,實現(xiàn)了人頭目標(biāo)的快速檢測.由對比結(jié)果可以看出:本文算法在Brainwash測試集上的平均準(zhǔn)確率達到了79.58%,平均準(zhǔn)確率不僅高出文獻[14]原始算法的7.31%,相比于其余4種模型,整體精度提升了1.58% ~ 37.75%.
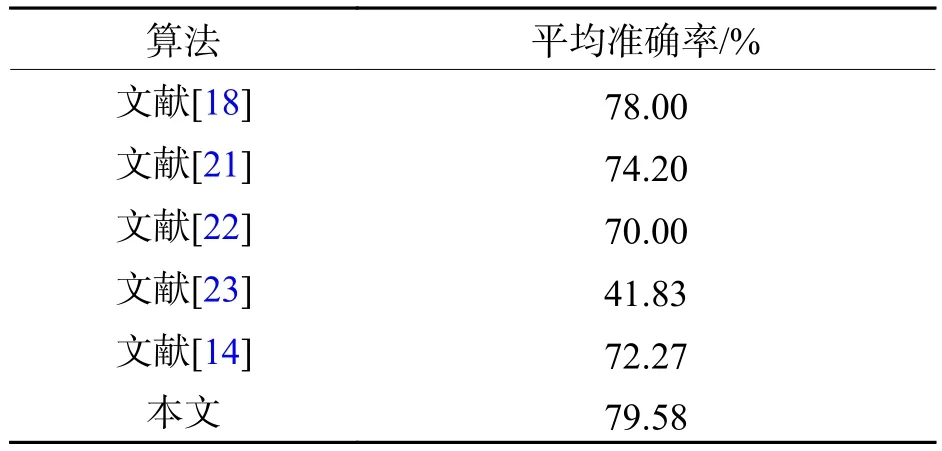
表2 不同目標(biāo)檢測算法結(jié)果對比Tab.2 Result comparison of different object detection algorithms
為測試本文算法在多種不同場景下的有效性,選用涵蓋多種場景的Pets2009數(shù)據(jù)集進行測試,除原始算法和本文算法外,增加對比算法進行測試,其將Conv3_3層代替Conv5_3層輸入RPN中,Anchor尺寸設(shè)置與本文算法保持一致,結(jié)果如表3所示.由結(jié)果可以看出:本文目標(biāo)檢測算法所訓(xùn)練模型的平均準(zhǔn)確率達到了74.24%,平均檢測每張圖像的時間為0.168 s,與原始算法相比,整體精度提升了10.71%,而單張圖像檢測速度相差僅為0.002 s.另一方面,本文算法檢測精度明顯高于對比算法,這說明Conv4_3層相較于Conv3_3層針對小目標(biāo)能夠提取到更加有效的特征.總體看來,經(jīng)過本文方法改進之后的Faster R-CNN通過極少量的時間代價顯著提高了小目標(biāo)檢測精度,有效地平衡了檢測精度與速度.
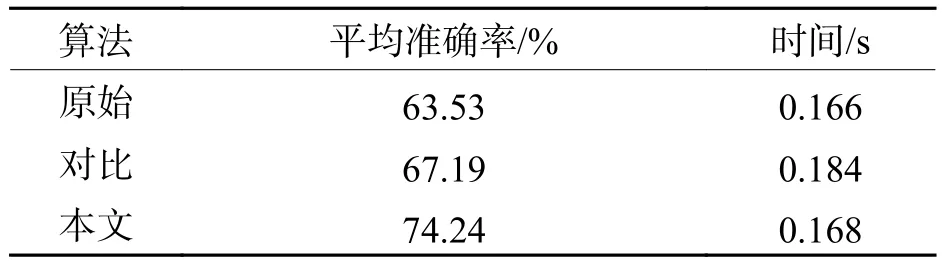
表3 模型對比結(jié)果Tab.3 Result comparison of models
針對小目標(biāo)檢測問題,一些文獻利用多尺度特征融合方式對特征提取網(wǎng)絡(luò)進行改進,以提高檢測精度[24-25].為進一步證明本文改進算法的優(yōu)越性,采用通道疊加方式對多層特征圖進行融合實驗,結(jié)果如表4所示.由結(jié)果可以看出:采用多尺度特征融合方式所訓(xùn)練模型的平均準(zhǔn)確率最高可達到69.46%,雖然與原始算法相比有所提升,但比本文算法低出4.78%.這是由于行人頭部相比于行人全身所占像素小得多,且數(shù)據(jù)集中每個行人頭部在圖像上占比較為平均,因此行人頭部的多尺度特性表現(xiàn)不明顯.另外,越低層特征圖雖然邊緣細節(jié)信息更為豐富,但同時其包含的無關(guān)雜亂信息也就越多,因此Conv4_3相比于多尺度融合而成的特征圖能夠提取到細節(jié)信息更為準(zhǔn)確、語義信息更為豐富的特征,從而本文方法相較于多尺度特征融合方法精度更高,充分證明了本文改進方案是行之有效的.
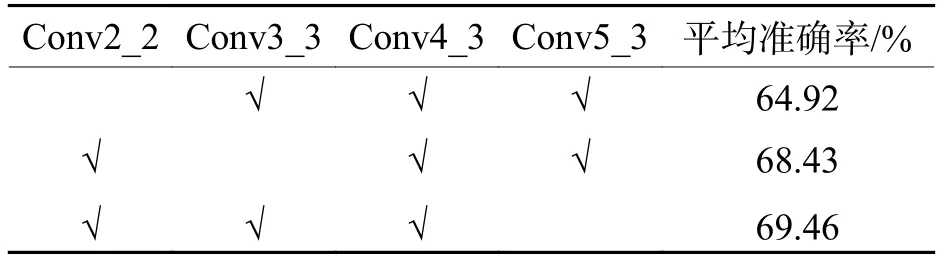
表4 多尺度特征融合方法精度Tab.4 Mean average precision of multi-scale feature fusion methods
2.4.2 人流量統(tǒng)計實驗分析
人流量統(tǒng)計測試結(jié)果如圖8所示.
圖8中:紅色框為檢測結(jié)果;白色框為跟蹤結(jié)果;左上角黃色文字為人流量實時統(tǒng)計結(jié)果;兩條黃色虛擬計數(shù)線所圍成的區(qū)域即為目標(biāo)區(qū)域.圖8(a)、圖8(b)為普通場景下的監(jiān)控視頻,從圖中可以看出:本文方法能夠?qū)崿F(xiàn)行人的全部檢測和跟蹤,并能對人流量進行準(zhǔn)確統(tǒng)計;圖8(c)為密集場景下的監(jiān)控視頻,從圖中可以看出:本文方法亦具有較好的效果,此外對于人頭密集及存在部分重疊的情況下亦可以實現(xiàn)高精度的檢測與跟蹤(圖8(c)中藍色框選部分).由此可以證明本文方法具有較好的精度,且具有一定的魯棒性.

圖8 不同場景下視頻人流量統(tǒng)計結(jié)果Fig.8 Results of video pedestrian flow statistics in different scenes
為定量評價本文視頻人流量智能統(tǒng)計方法的性能,通過人工統(tǒng)計出了測試視頻中的正檢人數(shù)、誤檢人數(shù)、漏檢人數(shù),并由以上統(tǒng)計量計算出召回率、精確率和F值,結(jié)果如表5所示.由結(jié)果可以看出:雖然在密集場景中由于誤檢人數(shù)較多導(dǎo)致在精確率標(biāo)準(zhǔn)上低于普通場景,但整體而言,本文方法在3個視頻中的召回率、精確率和F值標(biāo)準(zhǔn)上表現(xiàn)較好,皆達到了90.00%以上.
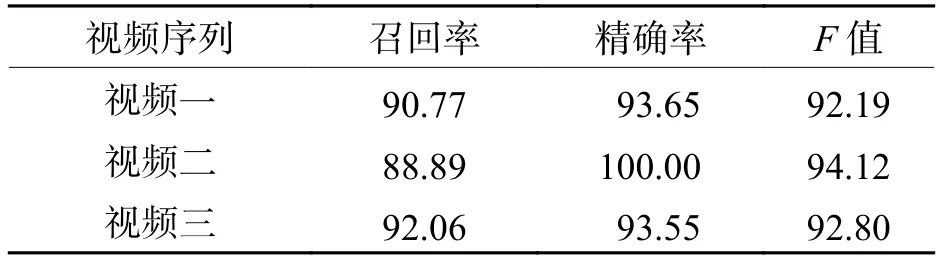
表5 視頻人流量統(tǒng)計結(jié)果Tab.5 Results of video pedestrian flow statistics %
統(tǒng)計了近年來表現(xiàn)優(yōu)異的視頻人流量統(tǒng)計方法,其算法框架主要有基于SSD-Sort檢測跟蹤框架[26]以及基于Yolov3-DeepSort檢測跟蹤框架[27]等.將以上兩種人流量統(tǒng)計算法框架與本文方法在相同的數(shù)據(jù)集下進行對比,結(jié)果如表6所示.由對比結(jié)果可以看出:相較于上述兩個算法,本文方法在召回率標(biāo)準(zhǔn)上提高了1.46% ~ 3.65%,這證明本文方法在普通場景和密集場景下的漏檢情況有所降低.本文方法在精確率標(biāo)準(zhǔn)上相較于SSD-Sort算法提高了2.38%,與Yolov3-DeepSort算法基本持平.總體而言,綜合指標(biāo)F值提高了1.14% ~ 3.04%,充分證明了本文方法在視頻人流量統(tǒng)計應(yīng)用上的魯棒性和先進性.
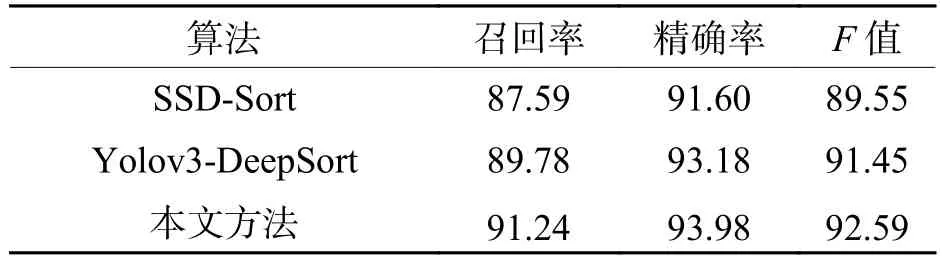
表6 不同算法對比結(jié)果Tab.6 Comparison results of different algorithms for pedestrian flow statistics %
3 結(jié) 論
1) 提出了用于小目標(biāo)檢測的Faster R-CNN改進算法,檢測準(zhǔn)確率在Brainwash數(shù)據(jù)集和Pets2009數(shù)據(jù)集上分別比原始算法高出7.31%、10.71%,相較于傳統(tǒng)多尺度特征融合方法效果更優(yōu).
2) 設(shè)計了雙向人流量智能統(tǒng)計算法,人流量統(tǒng)計指標(biāo)F值在多種場景下均達到了90.00%以上,相較于以往優(yōu)秀算法得到了一定提升,實現(xiàn)了多場景下視頻人流量的精確智能統(tǒng)計.
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
