小樣本圖像分類中的類別信息融合網絡
2022-08-30 09:18:34尚志華郭曉楠黃福玉劉毅志
南京航空航天大學學報 2022年4期
張 玉,尚志華,郭曉楠,黃福玉,劉毅志
(1.鄭州師范學院信息科學與技術學院,鄭州 450044;2.中國科學技術大學信息科學技術學院,合肥 230026;3.北京中科研究院,北京 100049;4.湖南科技大學計算機科學與工程學院,湘潭 411201)
深度學習被廣泛應用于各種圖像識別任務中并取得了顯著的效果提升[1-6],但是基礎的深度學習框架通常需要大規模標注的數據集作為監督,例如ImageNet 數據集[7]等,才能得到能夠準確分類的模型。然而,在一些領域獲取海量數據集的代價很高,尤其是一些安全領域,由于一些類別的圖像出現頻次低,采集標注難度大,因此這些類別往往可供學習樣本數量極少,這種情況下,基礎的深度學習方式并不適用。同時,一個已經在特定類別訓練良好的深度學習模型在應用到新類別時,通常需要大量的新類別樣本,這與人類的學習方式有極大的不同。人類在積累了足夠多的知識后,能夠僅從少量的圖片中學習到新類別的概念,并能準確地識別該類別的其他圖片。為了縮小深度學習模型與人之間的這種差距,許多研究人員致力于研究如何用深度學習網絡模擬上述的人類學習行為,即小樣本圖像分類問題。
小樣本圖像分類問題的目的是讓模型能夠僅通過少量的樣本學習新的類別,從而能夠對新類別的樣本進行分類。一些先前的工作在小樣本分類中取得了很大的成功[8-15],Snell 等[10]學習一個嵌入,從而能夠使用最近鄰或線性分類器對來自新類別的圖像進行識別。Sung 等[11]則直接使用基于度量的模型對新類別的查詢圖像進行分類,無需更新網絡參數。Qiao等[15]利用預先訓練的卷積神經網絡提取樣本的特征,并利用這些特征生成新的類別分類器。但是,當計算某個類別的參數時,上述工作均只使用該類別中的樣本,而忽略其他類別中的樣本。
為了在小樣本分類任務中更充分地利用不同類別樣本中的信息,本文的重點是在前向傳播中利用類間信息。其網絡框架如圖1 所示。在所示五分類任務中,從每個類別中選取1 張樣例圖像輸入網絡,經過特征提取器和融合模塊獲得融合后的各類別特征,并通過分類器參數預測器生成分類器。之后提取查詢圖像特征并通過生成的分類器獲得預測結果。本文網絡中,來自不同類別的樣本的信息通過一個可學習的映射融合在一起,通過這種方式,可以利用類間信息,學習到更準確的新類別概念。但是如何對不同的輸入樣本改變融合映射,以及如何合理地改變融合映射,都是本文需要關注的問題。因此,本文設計了3 個不同的融合模塊來進行融合映射,從而探討上述問題:(1)類無關模塊。使用常量映射來融合輸入樣本的特性。通過類無關模塊,在訓練過程中直接學習融合映射,不因測試樣本而改變。(2)半相關模塊。學習生成動態映射。當學習一個新的類別時,半相關模塊分別為屬于該類別和其他類別的輸入樣本計算兩種權值,然后將它們通過權值融合在一起。(3)完全相關模塊。計算不同類別樣本特征的內積,然后利用這些內積生成融合映射。
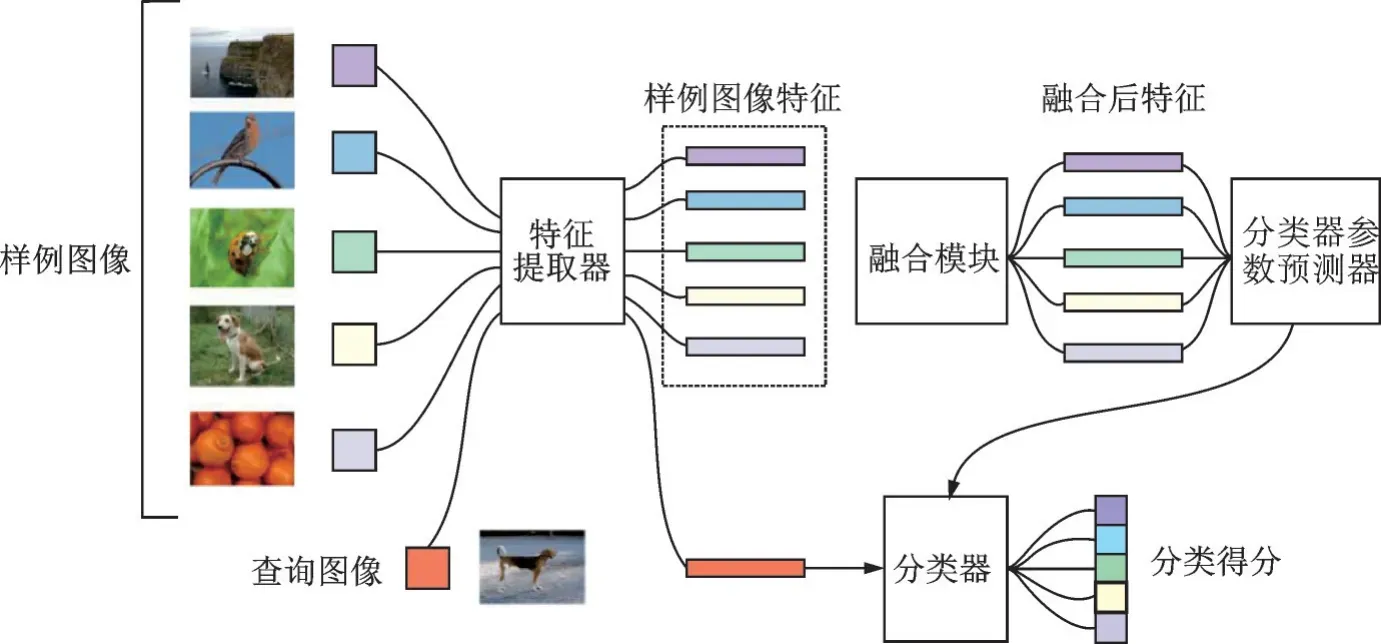
圖1 本文網絡框架圖Fig.1 Framework of our network
1 相關工作
近年來,許多研究者對小樣本學習產生了興趣。其中,小樣本分類問題的目標是讓機器學習模型在學習了一些類別的大量數據后,對于新的類別只需要少量的樣本就能快速學習,達到在這些類別上的精確分類。對于一個具體的小樣本任務,設其新的類別數為C,每個類別的樣本個數為K,則稱其為C-wayK-shot 任務。許多小樣本學習方法[8,10-12,15]可被歸納為3 類:基于元學習的方法、基于優化器的方法和基于度量學習的方法。以上方法都能夠從類似的任務中提取一些可轉移的知識用于進行新任務。基于元學習的方法。元學習方法[16]旨在訓練1 種元學習模型,這種模型可以從1個新任務的幾個訓練例子中快速學習出1 個新的模型。具體來說,MAML 方法[12]學習了1 個良好的初始條件,用于對小樣本問題進行微調而不會嚴重過擬合。神經網絡的初始權值可以在幾個梯度下降步驟中進行微調,以適用于新的分類任務。本文網絡是一種元學習網絡,用于學習可遷移的融合樣本信息和生成分類器的方法。元學習方法的快速泛化能力源自其訓練機制,在訓練過程中產生的梯度被用來作為快速權重的生成。模型包含1 個元學習器和1 個基準學習器,元學習器用于學習元學習任務之間的泛化信息,并使用存儲機制保存這種信息,基準學習器則用于快速適應新的任務,并和元任務交互產生預測輸出。
基于優化器的方法。基于優化器的方法認為普通的梯度下降方法難以在小樣本任務的場景下擬合,因此通過調整優化方法來完成小樣本分類的任務。文獻[17]提出了在樣本較少的情況下,原有的分類任務中基于梯度的優化器算法失效的原因。Finn 等[12]提出了1 種新的優化方法,能夠學習模型的初始化參數,使得一步或幾步迭代后在新任務上的精度最大化。本文方法可以學習任意標準模型的參數,并讓該模型能快速適配。Antoniou 等[18]提出對MAML 進行優化,進一步提高了系統的泛化性能,加快了網絡的收斂速度,減少了計算開銷。Nichol 等[19]提出的基于優化的元學習模型Reptile,也是通過學習網絡參數的初始化,與MAML 不同的是,Reptile 在參數優化時不要求使用微分。
基于度量學習的方法。度量學習方法的目的是學習圖像的特征表示,并以前饋的方式對查詢和樣本圖像進行分類。原型網絡[10]學習了1 種嵌入,這樣模型就可以通過計算到樣本圖像的距離來分類查詢圖像。關系網絡[11]則學習1 個深度距離度量來比較樣本圖像和查詢圖像。這里的深度距離度量比起歐幾里得距離和余弦距離更加復雜,由卷積神經網絡計算得到。TADAM[8]學習了1 個任務相關的度量空間,該度量空間針對不同的任務度量不同尺度的距離。TADAM 用向量表示任務,并將其輸入到后續網絡中,計算相應的度量尺度。Cai 等[20]提出了一種生成式匹配網絡,認為新樣本的生成服從某一條件概率分布,使用該分布生成新樣本來進行數據增強。該方法將樣本映射到語義嵌入空間,在嵌入空間中利用條件似然函數對樣本的語義特征向量進行匹配,減小了特征空間和語義空間的鴻溝。同時,Cai 等[20]還提出了一種利用內部存儲來進行記憶編碼的元學習方法,它將提取到的圖像特征用記憶寫入控制器壓縮進記憶間隙,然后利用上下文學習器,即雙向的Long short-term memory(LSTM)對記憶間隙進行編碼,不僅提高了圖像特征的表示能力,而且能夠探索類別之間的關系,其輸出為未標注樣本的嵌入向量,記憶讀入控制器通過讀入支持集的嵌入向量,將兩者點乘作為距離相似度度量,相比于余弦距離,計算復雜度更加簡單。Zhou 等[21]提出了基于嵌入回歸的視覺類比網絡,學習低維的嵌入空間,再從嵌入空間中學習到分類參數的線性映射函數,對新類分類時,將新類樣本與學習到基類的嵌入特征進行相似度度量。
除了以上常見的3 類方法之外,還有一些方法被應用于小樣本圖像分類任務中,基于遷移學習的小樣本圖像分類有3 種實現方式:基于特征[22-23]、基 于 相 關 性[23-26]和 基 于 共 享 參 數[27-28]的 方 式 等。在一些工作中,對偶學習[21]、貝葉斯學習[29]和圖神經網絡[30-32]等也被用于處理小樣本圖像分類問題。與本文最相關的方法是Qiao 等[15]中的激活中預測參數。該方法的目的是學習1 個參數預測器,以便在給定特定類別的樣本圖像時,模型能夠生成用于查詢圖像的分類器參數。一般來說,小樣本學習是一種多分類的任務。但是文獻[15]中的參數預測器僅從A 類別的樣本中學習生成A 類別的分類器參數,在前向傳播中忽略了類間信息。相比之下,本文網絡根據來自不同類別的所有樣本圖像預測分類器的參數,與文獻[15]相比只需要很小的額外計算量。
2 類別信息融合網絡模型
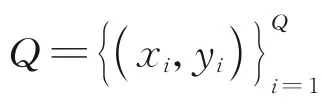
本文算法步驟主要分為兩部分:(1)融合特征矩陣的計算,本文設計了多種可選方法,在第2.1 節融合映射模塊中分別進行了詳細描述;(2)基于融合特征矩陣進行分類器參數預測并對查詢圖像進行分類,在第2.2 節類別融合網絡中進行了表述。
2.1 融合映射模塊
2.1.1 類別無關模塊
期望類別無關能夠學習到一種通用的、不變的融合映射來進行小樣本的學習。同時,在小樣本學習中,由于采樣的隨機性和訓練集/測試集的標記空間的差異性,參數模型往往不能很好地從訓練樣本中學習。因此,設計了一個具有少量額外參數的類 別 無 關 模 塊(Class-irrelevant module,CIM)。CIM 通過在RC×C中的矩陣WCIM直接學習融合映射。如圖2 所示,CIM 通過1 個全連接層將A映射為L,即
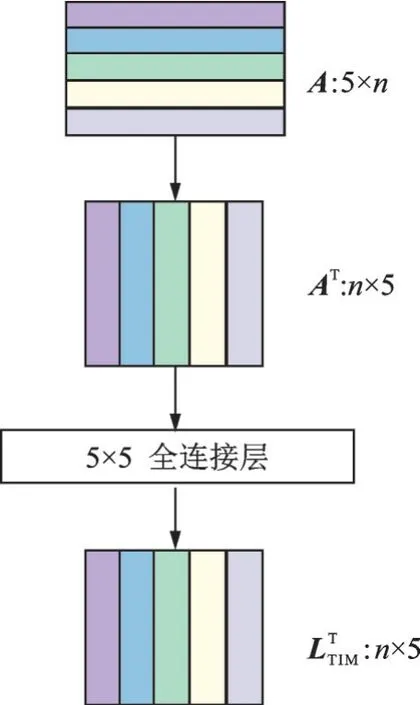
圖2 類別無關模塊結構圖Fig.2 Illustration of the class-irrelevant module architecture

CIM 中參數較少,但有2 個優點:(1)不對實驗儀器產生更多的運算要求;(2)可以避免過擬合。此外,CIM 中也沒有添加更多人為約束。因此,CIM 的性能可以直觀地說明利用類間信息的有效性。
2.1.2 半相關模塊
由于CIM 沒有考慮融合映射和輸入示例之間的關系,因此設計一個半相關模塊(Semi-relevant module,SRM)將這種關系進行融合。SRM 就是為了學習這種關系并動態生成融合映射而設計的。用WSRM∈RC×C表示由SRM 生成的融合映射矩陣,在WSRM中,每個元素是1 個融合權值,它與兩個類別相關,分別是輸入示例所屬的源類別和輸出特征所屬的目標類別。如果是來自目標類別的樣本,它們與目標類別的邏輯關系相同。如果不是來自目標類別的樣本,它們與目標類別的邏輯關系相同,在融合中權重相近。因此,在SRM 中增加了1 個約束,即只考慮融合權值與目標類別之間的相關性來控制參數的數量。如果用完全連接的層來實現SRM,那么約束至少可以減少一半參數。因此,給定樣本矩陣A,SRM 生成兩個權重向量α、β∈RC×1,并可計算WAFM和L,即

式 中:αi、βi分 別 代 表α和β中 的 第i個 元 素;αrepeat∈RC×n,其每一列為α;Aarg∈R1×n為A中每行的平均值;(·)表示hadamard 乘積。由于SRM 只考慮融合映射與目標類別之間的關系,本文稱之為“半相關”,結構圖如圖3 所示。圖中α的“×”運算表示沿某一維重復α以匹配A的大小并計算它們的hadamard 積β積下方的“×”運算則表示矩陣乘法。
圖3 半相關模塊結構圖Fig.3 Illustration of the semi-relevant module architecture
2.1.3 全相關模塊
SRM 生成帶有強約束的融合映射,全相關模塊(Fully-relevant module,FRM)則根據沒有約束的輸入學習融合映射。但是,由于圖像特征的維數較高,如果FRM 直接從層間完全連接圖像特征生成融合映射,則FRM 參數過多,容易導致過擬合。因此,首先計算樣本的內積。內積包含了樣本之間的關系,用這種方法可以顯著減少參數數量,FRM結構圖如圖4 所示。FRM 中計算L的方法為
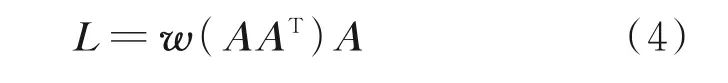
式中w( ·)為FRM 生成的融合映射的函數,即圖4中的2 個全連接層。本文對全連接層的輸入和輸出進行了重新設計,以便進行后續計算。

圖4 全相關模塊結構圖Fig.4 Illustration of the fully-relevant module architecture
2.2 類別融合網絡
2.2.1 參數預測
由于最終目標是分類,因此類別融合網絡(Category-fusion network,CFN)期望生成1 個融合特征的分類器。Qiao 等[15]中的研究表明,圖像特征與分類器參數具有較高的相關性。同時,CFN學習的融合特征包含了大量的圖像特征信息。因此,CFN 以與Qiao 等[15]類似的方式生成分類器。CFN 通過Ψ將L映射到WL的線性映射學習預測分類器的參數,其中L是最終分類的參數,即

式中:WL,y為類y的分類器中的參數;a( ·)為利用卷積神經網絡實現的特征提取器。
2.2.2 目標函數
為了訓練CFN,通過最小化分類損失在訓練集上訓練本文的模型,有
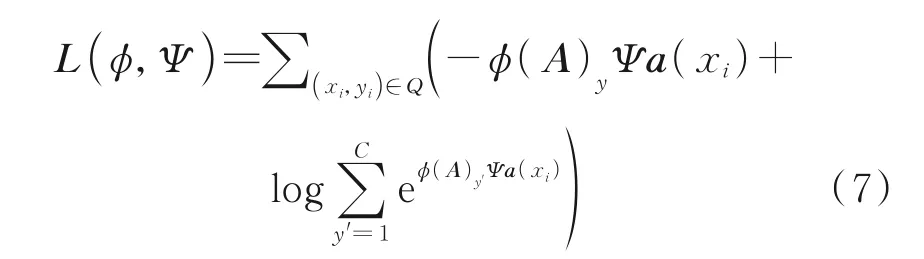
式中φ(A)y為φ(A)中的第y列。在實驗中,分別使用CIM、SRM 和FRM 作為融合映射模塊,而φ代表其中之一。
2.2.3 測試過程
在測試過程中,CFN 首先使用預先訓練的特征提取器a( ·)提取樣本集合和查詢集合中圖像的特征向量。然后,CFN 用融合映射φ對實例進行融合。使用融合特性,Ψ生成1 個分類器,該分類器可以對整個查詢集合進行分類。
3 實驗與分析
3.1 數據集
在MiniImageNet 數據集上評估了本文方法,該數據集是較大規模的ILSVRC-15 數據集中的一部分。該數據集由來自100 個類別的60 000 張彩色圖像組成,其中每個類別中有600 個樣本圖像。遵循Qiao 等[15]提出的劃分方式,選取80 個類別用于訓練,20 個類別用于測試。在實驗中預處理圖像像素的方式為:首先,將圖像的大小調整為92×92,然后隨機裁剪它們,以80/92 的比例進行訓練,并以相同的比例進行測試。
3.2 具體步驟
訓練過程中,本文通過使用兩種不同的基礎網絡骨架得到兩種特征提取器,分別是簡單卷積模塊組成的網絡[9]和寬殘差網絡(WRN-28-10)[33]。按照Qiao 等[15]中的方法將這些網絡進行了調整以適應MiniImageNet 數據集。比起CIFAR 數據集上的網絡,本文網絡中將2 倍下采樣改為3 倍下采樣,并在最后添加1 個全局平均池化層。
本文提出了5 種分類的CFN 網絡。對于CIM,使用無激活層的單級全連接層,輸入和輸出維度均為5,如圖2 所示。SRM 則是由2 個完全連接的層和2 個層之間的ReLu 層組成的順序網絡。第1 層的輸入和輸出尺寸與圖像特征相同,第2 層的輸出為α和β。FRM 通過2 個全連接層實現,其中輸入和輸出的大小都是5×5=25。在第1 個全連接層之后還有1 個ReLu 層。使用1 個n×n的全連接層來實現參數預測器Ψ。
在訓練過程中,首先在訓練集上對網絡進行常規的多分類訓練。無論在小樣本學習還是常規的分類網絡學習中,特征提取器的目的都是為了得到具有鑒別性的圖像特征。雖然這部分不是關于小樣本學習的主要研究,但在實驗中證實了其對結果的顯著影響。預訓練之后,將融合映射φ和參數預測器Ψ一起訓練。按照現有的小樣本學習工作的常規設置,進行了5-way 1-shot 和5-shot 分類。在每個訓練/測試集中,查詢集都由來自每個類別的15 張圖像組成。即在1 次5-way 1-shot 實驗中,使用1×5=5 個樣本來生成分類器,并在15×5=75 張圖像上進行分類測試。
3.3 方法對比
在每一個小樣本學習步驟中,將在5 個類別上驗證模型的分類準確性。與Sung 等[11]中一致,最終的準確率平均在600 個隨機生成的測試集上進行測試。表1 對比了本文方法和以往方法的準確性。其中方法欄中上半部分方法使用3.2 節中提到的簡單卷積網絡骨架,下半部分采用的是殘差網絡作為網絡骨架。與其他使用簡單卷積網絡的方法相比,CIM、SRM 和FRM 都有較大的提升,FRM 在1 樣本和5 樣本場景上都獲得了最高的精度。這一結果表明,融合實例信息對小樣本學習是有效的。在以簡單網絡為骨架的本文網絡中,FRM 的性能優于CIM,說明根據輸入實例改變融合映射是可行的。但是,在以WRN 為骨架時,每個模塊對精度的提升要小于簡單卷積網絡作為骨架的情況。本文認為這應該是由于過擬合的原因,因為WRN-28-10 的參數數量是簡單骨架網絡的幾百倍。由于過擬合嚴重,SRM 和FRM的性能受到限制。然而,CIM 仍然達到了最好的性能,證明了CIM 的魯棒性。CIM 具有更少的參數,它可以學習較通用的類別無關的融合映射。因此,在過擬合條件下,該算法具有較好的魯棒性和性能。綜上所述,雖然3 個模塊有不同的優點,但本文提出的融合樣本方法的有效性是毋庸置疑的。
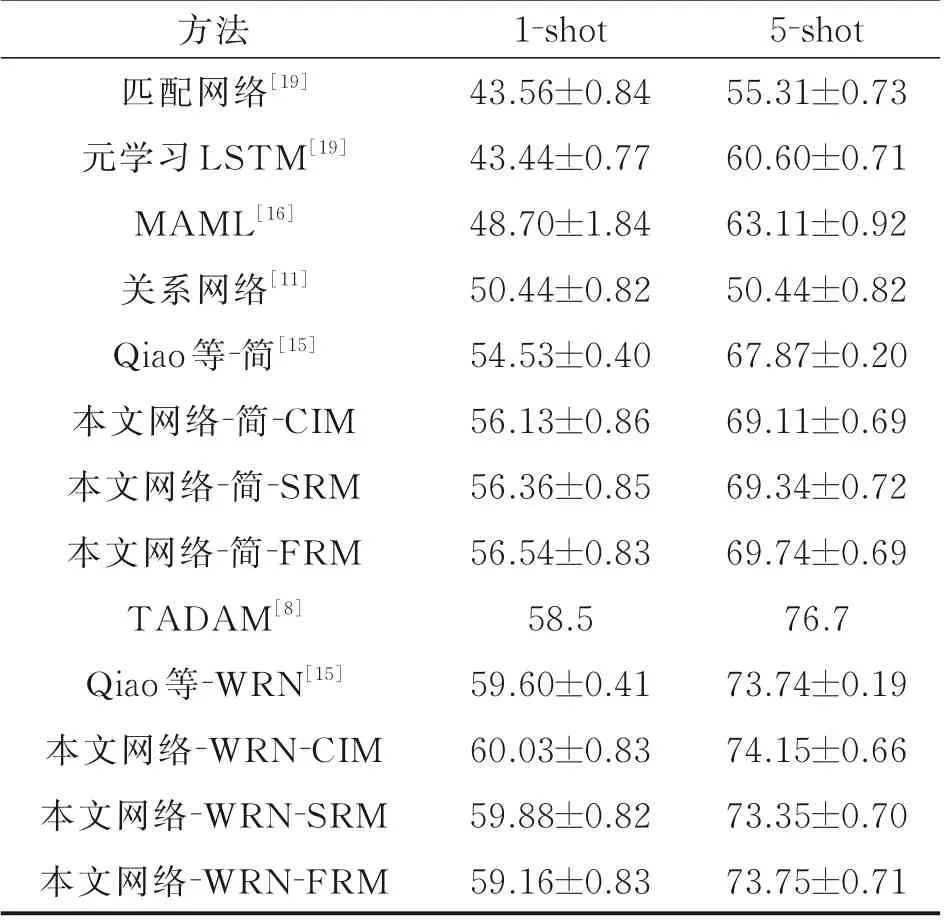
表1 MiniImageNet 數據集上小樣本的學習精度Table1 Few-shot 5-way accuracies on MiniImageNet %
3.4 分析與討論
3.4.1 CIM 學習情況分析
CIM 的設計思路是在不考慮樣本差異的情況下學習融合映射。為了分析CIM 學到的內容,將CIM 的融合映射矩陣的絕對值顯示在表2 中。為了便于觀察,每個部分的值均進行了除以最大值的歸一化。觀察可以發現對角線上的值支配著矩陣,這意味著對于每個目標類別,屬于這個類的樣本對它的影響最大。雖然非對角元素的值較小,但它們的總和也比較可觀,這也說明了類間信息對最終分類是有幫助的。此外還可觀察到,沿對角線,最大值為1.0,最小值為0.52,這表明CIM 并沒有平等地融合每個類的樣本。推測這是因為每個融合的圖像特征都包含了所有類別的信息,CIM 學到了一個適合的策略來利用樣本信息,而不是平均地融合。
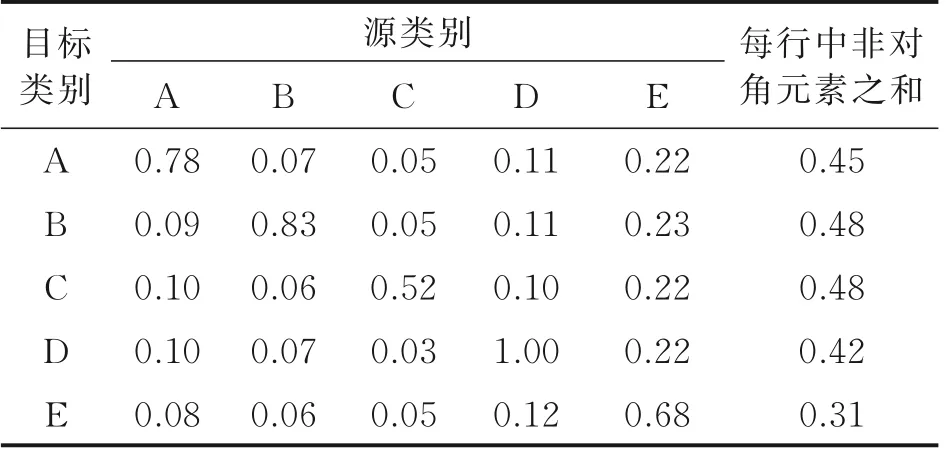
表2 CIM 融合映射矩陣絕對值Table 2 Absolute values of CIM fusion mapping matrix
3.4.2 SRM 學習情況分析
與CIM 不同,SRM 采用動態融合映射,而α和β是理解SRM 融合映射特性的關鍵。圖5 顯示了它們在600 個訓練步中的分布。結果表明,α的分布區間較小,而β的分布區間較大。這說明該方法可以調整非目標類別實例對融合映射的影響,最終根據實例改變融合映射。此外,α和β分布相對密集,這意味著不同輸入的融合映射具有相似性。
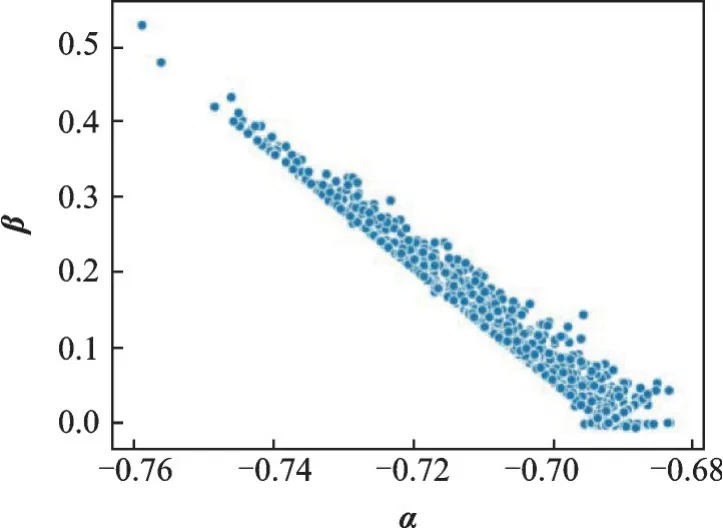
圖5 SRM 中α 和β 的分布Fig.5 Distribution of α and β in SRM
3.4.3 分類器中參數的相關性
通過觀察對應分類器中參數的相關性來分析這3 個模塊。由于最終目標是進行分類,所以分類器的參數直接影響結果。在每1 訓練/測試步中,每個類別都有1 組分類器參數。本文計算了每一集不同參數的平均相關性,并在圖6 中顯示了600步的相關性的核密度估計。顯然這3 個模塊都降低了分類器參數的相關性,這意味著分類器更加關注類別之間的差異,而忽略了多余的相似信息。這個結果是合理的,因為沒有類間的信息,分類器不能學習類別之間的差異是什么,只衡量查詢圖像與樣本圖像的相似程度。毫無疑問,學習這些額外的知識可以幫助分類器做出正確的預測。同時,從圖6 中可見,模塊之間也存在差異。圖中“Base”表示沒有融合映射的類別融合網絡,FRM 的相關性最低,說明FRM 學習融合的方法比其他2 種方法更能提高分類器的識別性能。
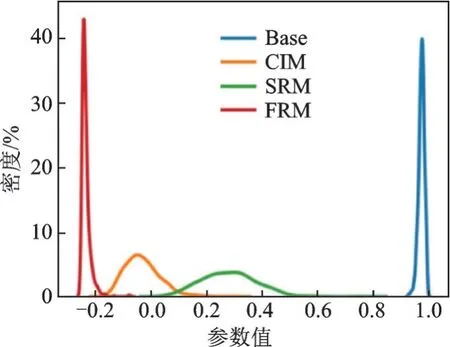
圖6 分類器參數相關性的核密度估計Fig.6 Kernel density estimation of correlation of classifier parameters
4 結 論
本文提出了一種新的類別信息融合網絡,該網絡可以通過融合樣本信息來充分利用樣本中的類間信息。本文的網絡能夠學習前向傳播中類別之間的差異,并生成一個更有分辨力的分類器。此外,設計了3 個模塊,以不同的方式融合不同類別的信息,并討論了它們各自的優缺點。3種模塊間相互獨立,可以根據不同任務上的選擇單一模塊使用,同時3種模塊也可以在模型中并行計算,分別計算相應的融合特征及其分類器,最終對多個分類器進行模型融合得到最終結果。本文網絡在MiniImageNet 數據集上實現了最先進的性能,在每個新類別1 個樣本和5個樣本場景下分別得到了60.03%和74.15%的分類精確度,超越了基準網絡的分類性能。實驗結果證明了該方法對類間信息的有效利用。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
