基于伽馬對數算法的文本情感分類研究
2022-09-01 02:29:26張冠東盧方
微型電腦應用 2022年8期
張冠東, 盧方
(上海第二工業大學,1.文理學部,2.計算機與信息工程學院,上海 201209)
0 引言
文本語言的感情色彩一直是判斷輿論走向的一個重要因素,褒義和貶義的文本常常會影響閱讀者的主觀感受。隨著信息技術的發展和大數據時代的來臨,人們獲取信息的方式也在迅速發生變化,但是閱讀各種社交媒體上的文本文字依然是人們了解信息的主要方式。換言之,人們對某些社會事件或者現象的看法,除了受到自身知識面的影響以外,還會受到社交媒體文字情感色彩或者社會輿情的間接影響。例如,一些金融新聞會對投資者的投資策略產生影響,從而改變投資者已有的投資習慣[1]。一些產品使用后的評論會對新聞閱讀者產生影響,從而左右其購買決策[2]。
一般而言,在文本文字撰寫(例如評論、意見等)結束后,作者可能需要對該文本貼上文字標簽以方便歸類。由于文字標簽也是帶有感情色彩的,因此,如果標簽感情色彩和內容感情色彩能夠保持一致,那么就有助于這段文本被更好地歸類以及被更多人傳閱。然而,受到作者水平的限制,文字表達內容的感情色彩往往與其標簽有一定的偏差。所以,如何正確地選擇內容和標簽感情色彩一致的文本是值得探討和研究的話題。
本文通過對伽馬算法的改進提出一種新的算法——伽馬對數(Gamma-Logarithm)算法——對帶有標簽的文本文字的分類進行分析,從而判斷文本感情色彩與標簽的感情色彩是否一致。選用一些文本文字作為實驗對象,實驗結果表明伽馬對數算法比其他算法對文本情感識別的準確率更高。在實際應用中,可以將該模型用于大規模的文本情感篩選,從而判斷識別文本和標簽情感是否匹配。在現實生活中,該模型可用于輿情分析從而快速有效地了解輿情趨勢。
1 文獻綜述
由于文本感情色彩對于文本選擇而言十分重要,目前國內外已經有很多研究在討論文本情感色彩的重要性。在國內,趙澄等[3]利用支持向量機(support vector machines, SVM)模型對金融文本的情感進行分析,使得股票預測方法準確率有所提升。李源等[4]提出了一種基于字詞雙通道網絡的文本情感分析方法,該方法利用卷積神經網絡對字向量和詞向量分別進行卷積運算來對文本進行分類,提高了文本分類的準確率。
在國外,HALIM等[5]通過機器學習的方法采用特征提取的方式對郵件文本進行分析,識別文本中的隱藏情感,這種方法不但能夠幫助收件人確定郵件的正負情緒,還能幫助收件人更好地回復郵件。針對特定的事件或者主題,ABDI等[6]提出了一種文本的感情色彩估計模型(the auxiliary dataset-Latent dirichlet allocation)來預計用戶的感情趨勢,并取得了很好的效果。
雖然國內外諸多研究使得文本情感識別取得了一定的進展,但是由于文本情感的判斷較為復雜,且不同的讀者或用戶對語句的情感理解有一定的差異,因此文本的情感分析仍有不少的挑戰。此外,如果僅僅考慮文本情感的褒義或貶義色彩,那么很多中性的詞匯將很難進行歸類。因此,本研究從文本的中性和非中性的角度對文本的情感色彩進行識別。
2 模型介紹
2.1 伽馬函數
伽馬函數(Gamma function)或者稱為歐拉第二積分,是一種階乘函數,在分析學、概率論、偏微分方程和組合數學中有著重要的應用。對于真實且為正的值,經典伽馬函數公式[7]可表示為
(1)
伽馬函數是統計學上的一種常用分布函數,目前已被用于多個領域的研究。CARDOSO等[8]采用伽馬函數矩陣進行了全面數值計算。
2.2 對數函數
對數函數是以冪為自變量的一種函數,是為了尋求化簡的計算方法而發明的。假設輸入變量x>0,其公式為
F(x)=Logax
(2)
這里a一般為正。對數函數在數據挖掘領域有著廣泛的應用,例如,MOKKADEM等[9]的研究驗證了迭代對數的緊湊特性。本文將該函數結合到新的數學模型中對文本的情感進行研究。
2.3 k均值(k-means)算法
k均值算法是一種常見的聚類算法。該算法通過計算每個類別的中心簇點,將數據聚集在相近的簇點附近。k-means的距離計算一般以歐幾里得距離為基礎,該距離的算法為
(3)
其中,X={x1,x2,…,xn},Y={y1,y2,…,yn} 分別表示n維空間中的兩個點。基于歐幾里得距離,k均值算法的一般步驟為先隨機從數據樣本點中選取k個點作為初始中心點,然后計算樣本數據點到中心點的距離并確定新的中心點,再計算新的中心點到各數據樣本點的距離并再確定新的中心點,一直循環直到中心點不再變化或達到最大的循環次數。k均值算法已經在各種研究中被廣泛地應用。張一迪等[10]基于觀測協方差矩陣相鄰特征值之差統計量構成的五維矢量序列,利用k均值算法使數據分詞信號和噪聲2類取得了較好的精確度。由于k均值算法可以通過設定k的值來確定類別的數量,且文本的感情色彩可以分為中性和非中性色彩,因此本研究通過使k=2,將文本的情感色彩類別分成2類。
3 模型設計——伽馬對數算法
由于伽馬算法能夠對語言信號進行分類[11],因此在基于該算法的基礎上,本文結合對數函數提出一種新型的算法計算文本的情感值并進行分類。假設文本T={t1,t2,…,tn}是由n個詞匯所組成的文本,伽馬對數算法可表示為
(4)
其中,Γ(*)為伽馬算法,Lg(*)是以10 為底的對數函數。由于SnowNLP是一種被用于計算文本情感的工具包,因此先用該方法計算出文本的情感色彩值,再運用伽馬對數算法進行綜合情感色彩計算。
4 檢驗標準
分類模型中的精確率是用于判斷分類準確率的一個重要指標,精確率通過真陽性、真陰性、假陽性和假陰性來定義。真陽性(true positive,TP)指的是數據分類中將正確的類別判斷為正確;假陽性(false positive,FP)表示數據分類中將錯誤的類別判斷為正確;真陰性(true negative,TN)表示數據分類中將錯誤的類別判斷為錯誤;假陰性(false negative,FN)表示數據分類中將錯誤的類別判斷為正確:因此,精確率(precision,P)可以表示為分類的項目中有多少是相關的[12]。由于本研究聚焦于通過文本的情感色彩劃分文本的類別,因此通過對文本內容的情感色彩分類和該文本標簽的情感色彩分類是否屬于同一類別來計算分類準確率。
5 實驗分析
5.1 實驗流程
選用公共數據集(https:∥github.com/aceimnorstuvwxz/toutiao-text-classfication-dataset)中的文本數據進行研究,該數據集包含中文文本數據和其類別。由于該數據集中數據包含了文本內容和標簽,因此需要先將標簽和內容進行分離,并進行數據清洗后再做分析。通過對比研究幾個不同算法的情感值來檢驗伽馬對數算法的優劣,這些對比算法是對數算法、伽馬算法、整句文本情感計算,其流程示意圖如圖1所示。
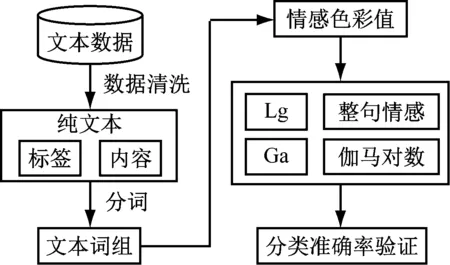
圖1 流程圖
5.2 實驗結果
根據圖1,分別選取不同數量文本進行分析,對比數據如表1~表3所示。
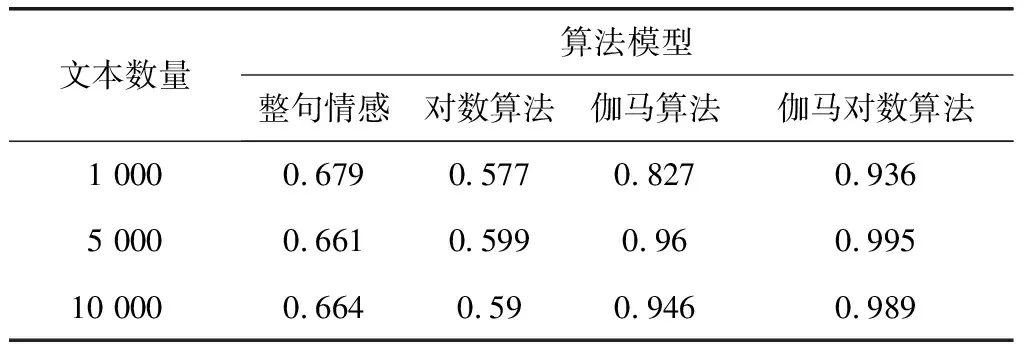
表1 匹配精確度
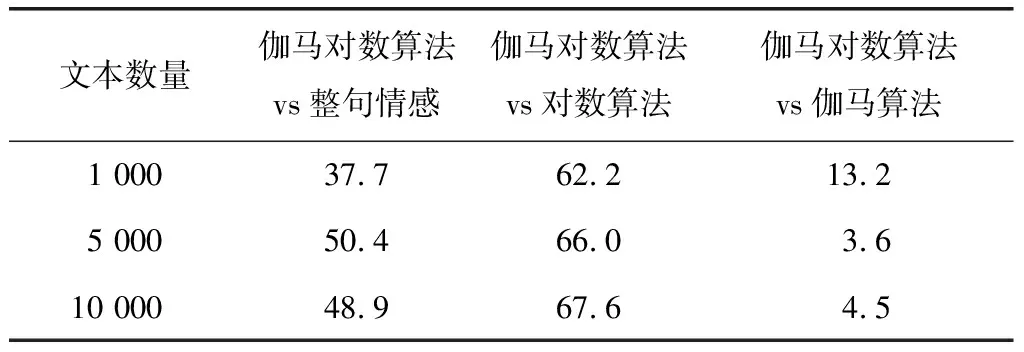
表2 準確度提升率 %

表3 準確率平均提升率 %
表1表示了文本情感色彩的匹配程度,1.0表示完全匹配,其結果說明,和其他幾種算法相比,伽馬對數算法的情感識別準確率較高。從表2的計算結果得出,伽馬對數算法比整句情感計算、對數算法和伽馬算法在分類精確度提升方面都超過了3%,而平均準確率提升幅度也超過了5%(見表3),這說明和其他幾個算法相比,伽馬對數算法在文本情感識別計算方面有了明顯的提升。
6 總結
文本情感分析是文本分析中的一個重要研究方向,本研究在運用SnowNLP得出情感色彩值的基礎上采用伽馬對數模型進行情感識別分類,并取得了較高的準確率。該研究的成功能夠對輿論導向的網民情緒波動、主流媒體的話語引導以及大規模統計文字語言的色彩偏向等方面起到量化分析研究的作用。此外,該模型的運算過程簡潔,適用于大規模的文本分析,可以幫助決策者在特定文本類別的前提下有效地掌握情感導向,從而做好事先的應對。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
軍事文摘·科學少年(2017年1期)2017-04-26 18:30:13
環球人物(2016年9期)2016-04-20 03:03:30
Coco薇(2015年5期)2016-03-29 23:18:25
小學教學參考(2015年20期)2016-01-15 08:44:38
