基于改進Fairmot 框架的多目標跟蹤
2022-09-01 08:53:14席一帆何立明
液晶與顯示 2022年6期
席一帆,何立明,呂 悅
(長安大學 信息工程學院,陜西 西安 7100064)
1 引 言
多目標跟蹤最初源于雷達技術的研究。在軍事上,數據關聯算法利用目標的位置和運動信息進行軌跡和觀測目標的匹配。近年來,隨著我國視頻監控和無人駕駛行業的飛速發展,基于視頻的多目標跟蹤技術顯得尤為重要。多目標跟蹤根據初始化的方式劃分為基于檢測跟蹤的流程和基于人工初始化的跟蹤流程。由于基于人工初始化的跟蹤無法處理軌跡的生成和消亡,因此基于檢測的跟蹤為當前的主流方式。基于檢測的跟蹤包括目標檢測和數據關聯,兩者功能相互獨立,但卻在關系上緊密聯系,良好的檢測器能為數據關聯提供較好的觀測結果。
早期的目標檢測主要依靠人工設計的特征訓練支持向量機進行分類。2005 年,Dala[1]利用HOG 特征來訓練分類器;2008 年,DPM[2]檢測器依據改進HOG 特征,采用根濾波器和部件濾波器在多尺度金字塔上滑動檢測;2014 年,隨著深度學習的興起,傳統的目標檢測方式被逐漸取代;R-CNN[3]在傳統目標檢測方式的基礎上,以卷積神經網絡作為特征提取器,訓練支持向量機;Fast-RCNN[4]是首個利用全卷積神經網絡訓練的目標檢測器。Faster-RCNN[5]提出區域建議網絡,對任意尺度輸入的圖像都會生成一組后選框,首次引入錨框機制,速度比Fast-RCNN 快一個數量級。YOLO[6-9]系列框架主要基于錨框(Anchor)機制,將目標的位置和尺寸視為回歸問題,該系列框架檢測速度快,但錨框機制存在正負樣本不均衡,超參數管理復雜等缺點。近些年,基于關鍵點的目標檢測逐漸興起,Cornernet[10]通過利用目標的左上角點和右下角點對目標進行定位。Centernet[11]通過中心點對目標的尺寸、位置和中心點的偏移量進行預測,擁有更高的檢測效率。
數據關聯負責將目標的軌跡與觀測目標進行匹配。數據關聯算法分為確定性優化算法和概率推斷算法。確定性優化算法將其建模成優化問題,通過優化算法解決匹配問題。二分圖匹配模型[12]、動態規劃[13]、最小成本最大流網絡模型[14]、條件隨機場[15]和最大權值獨立集模型[16]屬于確定性的優化模型。概率推斷模型基于現有的觀測狀態估計目標狀態的概率分布。卡爾曼濾波[17]、擴展卡爾曼濾波[18]和粒子濾波[19]屬于概率推斷模型。
端到端的多目標跟蹤框架近些年飛速發展,將目標檢測和數據關聯都用神經網絡來處理,使得網絡的訓練效率得到提升。DAN[20]跨幀提取特征,計算親和性矩陣,并用交并比信息作為掩模進行匹配。DeepMOT[21]根據匈牙利算法不可微分的特點,通過MOTA 和MOTP 的跟蹤指標創建損失函數,訓練深度匈牙利網絡替代數據關聯。DMAN[22]提出空間注意力模塊和時間注意力模塊,空間注意力模塊匹配兩幅圖像空間相同區域,時間注意力模塊對歷史軌跡分配不同的權重,濾除不可靠的軌跡。本文基于檢測與數據關聯的Fairmot[23]框架,提出一種改進算法,提高對目標對象的跟蹤精度。
2 Fairmot 基本框架
Fairmot 框架的目標檢測部分包括主干網絡、目標檢測分支和行人重識別分支。數據關聯部分采用DeepSort[24]框架進行匹配。
2.1 主干網絡
Fairmot 框架采用改進后深度聚合網絡作為特征提取網絡,該特征提取網絡采用可變形卷積適應不同尺度目標。通過不同層級的跳級連接進行語義信息和空間信息融合,使深度聚合網絡以目標尺度、分辨率為關注點。
2.2 目標檢測分支

視頻幀經過主干網絡會產生下采樣4 倍的特征圖,當目標的中心點預測結果映射回原圖時會產生4 個像素的誤差,因此通過中心點預測偏移
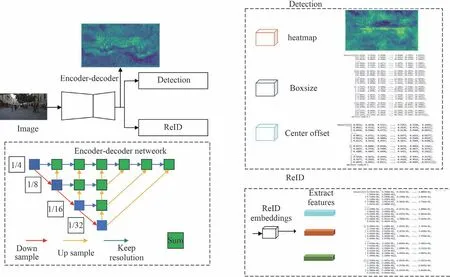
圖1 Fairmot 框架Fig.1 Fairmot framework
2.3 行人重識別分支


2.4 數據關聯
數據關聯部分采用DeepSort 框架。如圖2所示,DeepSort 首先通過級聯匹配得到最初的匹配軌跡集合、未匹配的檢測集合和未匹配的軌跡集合,然后將級聯匹配結果中的未匹配軌跡集合和未匹配檢測集合進行IOU 匹配得到最終的匹配結果。
匹配的軌跡集合作為觀測結果進行卡爾曼濾波更新,經過IOU 匹配得到的未匹檢測框集合。如果連續3 幀都匹配上軌跡,則認為是新的軌跡,然后進行卡爾曼濾波更新。最終的未匹配集合依據狀態來判斷該軌跡是否消亡。卡爾曼濾波更新得到的軌跡若為確認態則送入級聯匹配,否則送入IOU 匹配。圖2 右下角為部分視頻的兩次匹配結果。

圖2 數據關聯框架Fig.2 Data association framework
2.5 卡爾曼濾波
卡爾曼濾波主要分為兩個階段,分別為預測和更新階段。卡爾曼濾波的預測階段負責對目標狀態均值和協方差進行預測,如式(7)和式(8)所示:

式(10)中K為卡爾曼濾波增益,x?k和Pk為經過反饋調節后的最優軌跡值和協方差。實驗中使用的狀態變量為x=[u,v,r,h,u?,v?,r?,h?]T,(u,v)表示行人的中心點位置,r為框尺寸的長寬比,h為高,其余4 個分量表示其速度分量,實驗中的狀態轉移矩陣和觀測矩陣為:

各協方差的初始狀態設置為:

3 基于Fairmot 的改進
針對Fairmot 框架的主干網絡產生的高維信息缺乏維度之間的信息交互問題,采用三重注意力機制,提高對目標中心點的定位能力和特征提取能力;且由于行人重識別分支的Softmax 損失函數優化缺乏靈活性,采用Cirlce Loss 根據當前的狀態選擇優化程度,使其提取更為精確的身份嵌入向量。
3.1 三重注意力機制
針對深度聚合網絡后端高維信息缺乏維度間信息交互的問題,通過三重注意力機制[25](圖3)進行維度間信息交互。該機制能分別從(C,H),(C,W),(H,W)維度捕捉信息產生注意力掩模。其中的Z-Pool 模塊通過最大池化和平均池化將特征圖的第0 維度的通道數降至2,使特征圖保持豐富語義信息的同時,進一步簡化計算量。其公式如式(16)所示:
Z-Pool=[MaxPool0d(x),AvgPool0d(x)].(16)
第一條分支將輸入的特征圖(C×H×W)以H為軸進行逆時針旋轉90°得到(W×H×C)的特征圖,首先通過Z-Pool 單元得到(2×H×C),再利用k×k的標準卷積層、批歸一化層和Sig?moid 激活函數層產生(1×H×C)的注意力掩模,然后通過殘差連接與(W×H×C)的特征圖元素相乘得到通道維度與空間高維度的注意力熱圖,再將特征圖進行順時針旋轉90°得到(C×H×W),第二條分支與其類似。第三條分支只需捕捉空間維度的信息,無需旋轉,得到空間注意力效果圖。最后通過將3 條分支的注意力熱圖進行平均得到最終的注意力效果圖。圖3 分別給出了不同維度注意力掩膜作用后的注意效果圖,該效果圖是將四維張量在第1 維度壓縮可視化得到的,展示了不同維度信息交互的過程與結果。
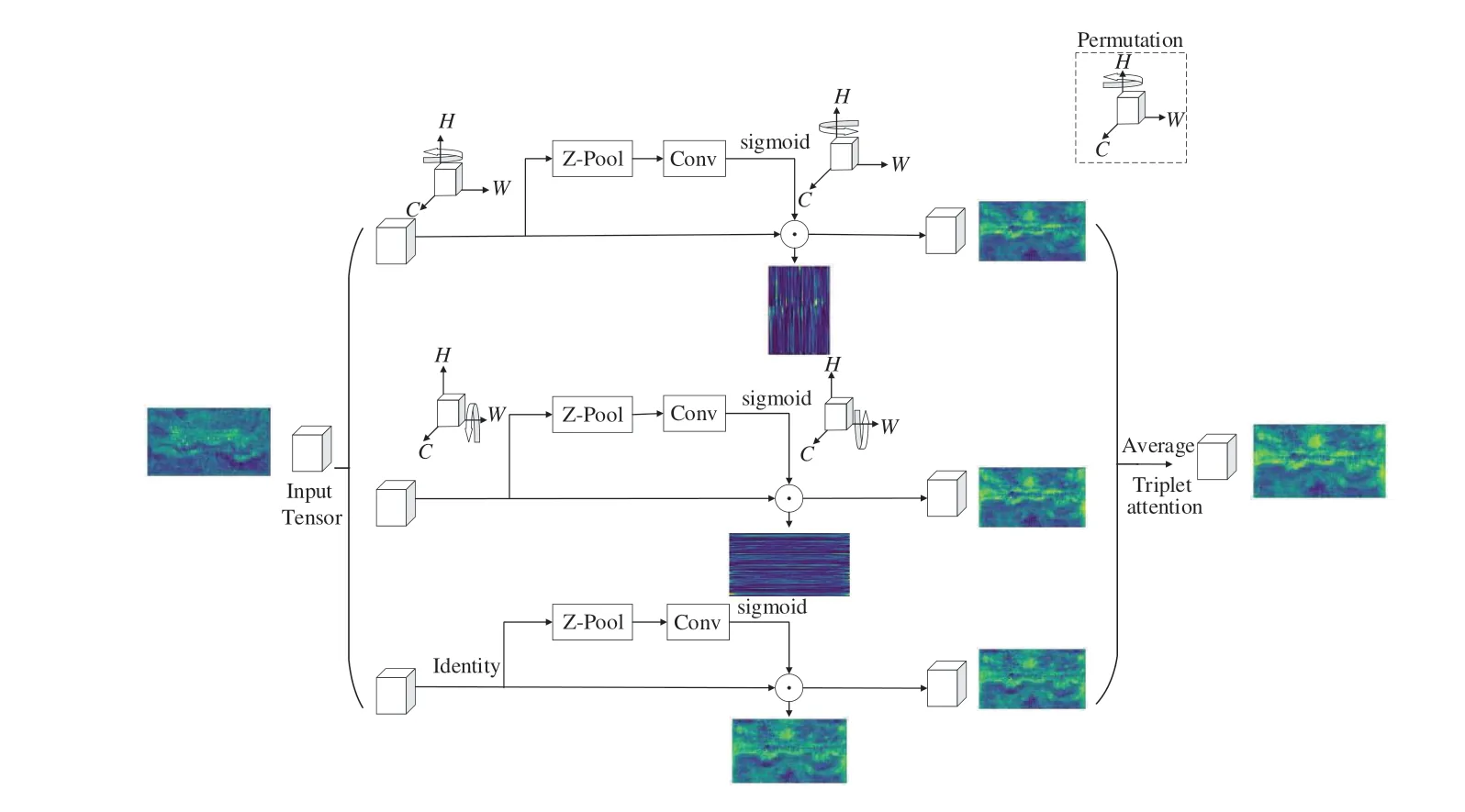
圖3 三重注意力機制Fig.3 Triplet attention mechanism
3.2 Circle Loss
深度學習的目標是將類內特征的相似度最大化,類間特征的相似度最小化,因此Circle Loss[26]概括出一個統一的損失函數表達式:


該損失函數對sn和sp優化梯度相等,反向傳播時的懲罰項是一樣的,因此不利于尋找最優點,優化方式缺乏靈活性。Cirlce Loss 提供一個能夠靈活優化目標的損失函數,其公式如式(19)所示:

4 實驗結果與分析
4.1 實驗環境與數據集
實驗運行環境為Ubuntu 16.04 操作系統,GPU 型號為:2 塊NVIDIA GeForce GTX 1080TI(11G 顯存),基于Pytorch 1.3 深度學習框架。采用的數據集為MOT 數據集,MOT 數據集分為MOT15、MOT16 和MOT17,該數據集包含了靜止或者移動拍攝、低中高角度拍攝以及黑夜等復雜的環境。實驗首先在CrowedHuman 數據集進行預訓練,然后通過MOT16 的訓練集進行訓練,在MOT15 的訓練集進行消融實驗。對比實驗在MOT15 的訓練集訓練,通過MOT15 測試集測試。實驗超參數設置如表1 所示,實驗評價指標如表2 所示。

表1 實驗超參數設置Tab.1 Experimental hyperparameter settings

表2 多目標跟蹤評價指標Tab.2 Multi-target tracking evaluation index
4.2 消融實驗
對Fairmot 模型、采用注意力機制的Fairmot(Fairmot+A)模型和采用Circle Loss 和注意力機制的Fairmot(Fairmot+A+CL)模型進行實驗,結果如表3 所示。

表3 3 種模型的消融實驗在MOT15 訓練集上的測試結果Tab.3 Ablation experiments of the three models tested on the MOT15 training set
采用三重注意力機制后,MOTA 得到了1.1%的提升,且身份切換次數明顯降低。注意力機制能夠提供更可靠的目標檢測,從而提升跟蹤精度。Fairmot+A+CL 在采用Circle Loss 后相比原模型在MOTA 上提升3.3%,且在MOTP、MT、ML、FM 等指標上明顯優于原模型。但Fair?mot+A+CL 模 型 與Fairmot+A 模 型 相 比,IDS指標上升許多,可能采用Circle Loss 之后對多任務學習目標檢測分支的性能產生影響,產生漏檢或虛檢現象,使改進后的模型身份切換指標上升。
圖4 展示了3 種模型的跟蹤能力對比。對于圖4(a)藍色箭頭所指的女士,Fairmot 模型上只在第一個視頻幀中檢測到該女士,在后續的視頻幀中出現部分遮擋未檢測出該行人。待遮擋結束時,行人身份發生切換。Fairmot+A 模型在前兩幅視頻幀中跟蹤到該女士,采用注意力機制能夠明顯提高其跟蹤精度,但在遮擋結束時,行人的身份發生切換。Fairmot+A+CL 模型在全程視頻幀中均跟蹤到該女士。可見,引入Circle Loss 之后,增強了行人重識別分支的特征提取能力,使其能夠提取更精確的表觀特征。

圖4 3 種模型在MOT15 訓練集上的測試結果Fig.4 Test results of the three models on the MOT15 training set
4.3 對比實驗
如表4 所示,改進后的模型在MOTA、IDF1和MT 上要明顯優于其他4 種模型。與原模型相比,MOTA 提升1.4%,MT 得到稍許提升。引入注意力機制和Cirle Loss 之后,提高了對目標的定位能力和跟蹤能力,使得提取的表觀特征更具區分性。

表4 5 種模型在MOT15 測試集上的對比實驗Tab.4 Comparative experiments of five models on the MOT15 test set
如圖5 所示,改進模型在目標檢測和跟蹤上明顯優于其他4 種模型。對遠處的小目標,改進模型跟蹤效果最佳。在第195 幀中,改進模型能準確檢測出坐在左側的行人,而原模型卻未檢測出,表明三重注意力機制和Circle Loss 增強了對目標的定位能力和表觀特征表達能力,產生了較好的跟蹤效果(圖6)。

圖5 5 種模型在MOT15 測試集上的對比效果圖Fig.5 Comparison of the five models on the MOT15 test set

圖6 軌跡跟蹤功能展示Fig.6 Display of trajectory tracking function
5 結 論
本文對Fairmot 框架提出兩種改進措施,首先利用三重注意力機制提高對高維信息的維度交互能力,產生精確定位;然后通過Circle Loss損失函數優化行人重識別分支,使其根據當前距最優點的距離選擇優化目標和程度,提取更精確的表觀特征。實驗結果表明,本文所提模型明顯優于其他模型,在MOT15 測試集上的跟蹤精度為62%,IDF1 提升至65.1%,身份切換降低68次。但是對于長時間遮擋的目標,本文方法會發生身份切換,產生較多的軌跡碎片,未來將著重研究長時遮擋問題以及模型壓縮問題。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
北京航空航天大學學報(2017年9期)2017-12-18 07:12:25
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
電源技術(2016年9期)2016-02-27 09:05:39
電源技術(2015年1期)2015-08-22 11:16:28
