基于Sentinel 數據的臨海市森林地上生物量估測
2022-09-07 05:39:38曹依林吳達勝方陸明
浙江林業科技 2022年5期
曹依林,吳達勝,方陸明
(1.浙江農林大學 數學與計算機科學學院,浙江 杭州 311300;2.林業感知技術與智能裝備國家林業和草原局重點實驗室,浙江 杭州 311300)
森林是地球上面積最大、結構最復雜的陸地生態系統,具有保持水土、調節氣候、維護生態平衡等多種生態功能[1-2],是地球上最大的碳庫[3-4]。森林生物量是森林生態系統最基本的數量特征,約占陸地生態系統生物量總量的90%[5],是森林碳儲量估測的常用替代方式[6],包括了地上生物量和地下生物量。森林地上生物量(Above-ground Biomass,AGB)約占整個森林生物量的70%~90%[7-8],是森林生態系統固碳能力的直觀表達和評估森林生態系統碳收支的重要指標,是森林生態系統發揮其他生態功能的物質基礎[2,9-10]。
近年來,森林AGB 的研究受到研究人員的廣泛關注,在數據源變得愈加豐富的今天,特征選擇尤為重要。在森林AGB 估測研究中,特征選擇方法常用估測方法本身對特征變量進行篩選,如用隨機森林[11-12]、多元線性回歸[12-13]等方法來對參數進行篩選,或者引入專門的方法對特征進行相關性分析,如皮爾遜相關系數(Pearson Correlation)[14-15]等。使用特征選擇算法結合集成學習算法探索特征數量和組合的研究較少[16-17]。同時,大部分研究結果尚不夠理想,估測精度在70%~80%[18]。雖有極少量的研究表明估測精度超過80%,但多數集中在針對少量的森林資源固定樣地或自設的調查樣地得到的研究結果[19-21]。研究中用大區域尺度上的建模技術探究不同林分下的特征數量及組合,更準確地估測森林AGB,仍然是待解決的難題。
據此,本研究以浙江省臺州市臨海市為研究區域,利用Sentinel-1 SAR 數據與Sentinel-2 光學遙感影像進行融合,以森林資源二類調查數據和數字高程模型作為輔助數據,對高維數據產生的大量特征使用遞歸特征消除法篩選出主要的影響因子,選擇隨機森林(Random Forest,RF)、自適應提升機(AdaBoost)和類別提升機(CatBoost)三種機器學習算法構建臨海市森林地上生物量估測模型,并比較其性能指標,以期探究森林地上AGB 的影響因素及高精度的估測方法。
1 研究區域概況
臨海市是浙江省縣級市,地處浙江東部沿海,地理坐標為28°40′~29°04′ N,120°49′~121°41′ E,海拔在700~1 200 m,東西最大橫距為85 km,南北最大縱距為44 km,陸地總面積為2 203 km2。全市森林覆蓋率為64.2%,城市綠地覆蓋率為41%。屬亞熱帶季風氣候,年平均氣溫為17.3℃,常年平均降水量為1 638 mm,無霜期為241 d,氣候溫暖濕潤。該地區的主要林分類型有闊葉混交林、針闊混交林、針葉混交林、其他硬闊林、馬尾松Pinus massoniana林、杉木Cunninghamia lanceolata林6 種。
2 研究方法
2.1 研究數據與預處理
2.1.1 遙感數據及預處理 研究涉及的Sentinel-1、Sentinel-2 遙感影像數據來自于歐洲航天局官網,Sentinel-1產品選用干涉寬模式下的S1 TOPS-mode SLC 數據,包括2017 年10 月13 日、10 月15 日各1 景影像。Sentinel-2產品類型選擇L1C 級多光譜數據(MSI),包括4 景影像,獲取時間從2017 年10 月底至11 月中旬。
采用哨兵衛星數據處理的開源軟件SNAP 對Sentinel-1 進行軌道校正、邊界噪聲消除、熱噪聲去除、相干斑濾波、輻射定標、分貝化等預處理;Sentinel-2 數據的預處理包括使用Sen2cor 插件進行大氣校正,使用SNAP進行超分辨率合成。然后,使用ENVI 軟件將Sentinel-1 和Sentinel-2 影像坐標系轉換為CGCS_2000 坐標系,再分別拼接Sentinel-1 的2 景影像和Sentinel-2 的4 景影像。最后,以臨海市行政矢量圖為邊界對拼接后的遙感影像進行裁剪,最終得到研究區域影像,見圖1 和圖2。由于日期不同以及入射角度和光照等差異,在圖像拼接時進行透明處理、勻色、羽化等操作后,連接處仍存在一定的顏色差異。
圖1 臨海市Sentinel-1 遙感影像Figure1 Sentinel-1 remote sensing image of Linhai city
圖2 臨海市Sentinel-2 遙感影像Figure 2 Sentinel-2 remote sensing image of Linhai city
2.1.2 DEM 數據處理 研究區的DEM 數據來源于2009 年美國地質勘查局(USGS)發布的ASTER GDEM第二版(v2)數據,包括4 景影像,空間分辨率為30m。使用ArcGIS 軟件將4 景圖像坐標轉換為CGCS_2000坐標系并進行拼接處理,再以臨海市行政矢量圖為邊界裁剪后得到研究區域最終的DEM 影像,如圖3 所示。
圖3 臨海市DEM 影像Figure 3 DEM image of Linhai city
2.1.3 森林資源二類調查數據預處理 本研究使用的森林資源二類調查數據來自于2017 年臨海市森林資源二類調查結果,包括59 636 個小班初始數據,由于本文計算生物量使用的是蓄積量—生物量轉換公式,故對森林資源二類調查數據中蓄積量值為空的小班進行剔除,繼而剔除灌木、非林地、耕地等小班,之后再使用三倍標準差法剔除異常小班,最后得到有效小班數據24 183 個,按林分類型劃分為六類:闊葉混交林8 408個、針闊混交林5 693 個、針葉混交林1 977 個、其他硬闊林3 725 個、馬尾松林2 852 個、杉木林1 528 個。
三倍標準差法又稱拉依達法,以三倍標準偏差作為可疑數據篩選的標準,如公式(1)所示。

式中,n為樣本個數;xi為第i個樣本的值;為總樣本的算術平均值;σ為標準差。正常值為范圍內的數值,超出該范圍的值則為異常值。
2.2 生物量計算公式
國內外許多研究表明,森林蓄積量和生物量之間存在顯著的回歸關系。本研究采用方精云等[22]提出的生物量轉換因子函數法根據蓄積量求得生物量,具體計算方法如公式(2)所示。

式中,B為單位面積生物量(t·hm-2);V為單位面積蓄積量(m3·hm-2);a、b 均為常數。不同林分類型對應的a、b 參數如表1 所示,除針葉混交林的參數引自文獻[23],其余林分的參數引自文獻[22]。
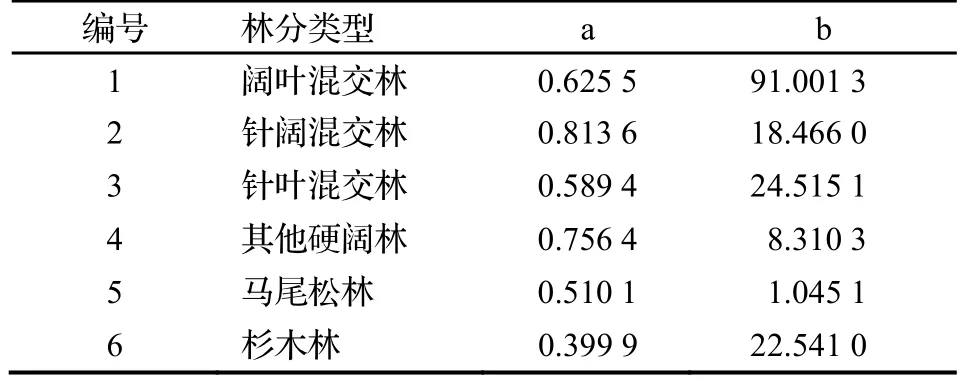
表1 生物量和蓄積量轉換模型參數Table 1 Parameters for biomass and stand volume conversion model
使用生物量轉換因子函數法結合森林資源二類調查數據對研究區小班的六類林分的地上生物量進行統計,結果如表2。
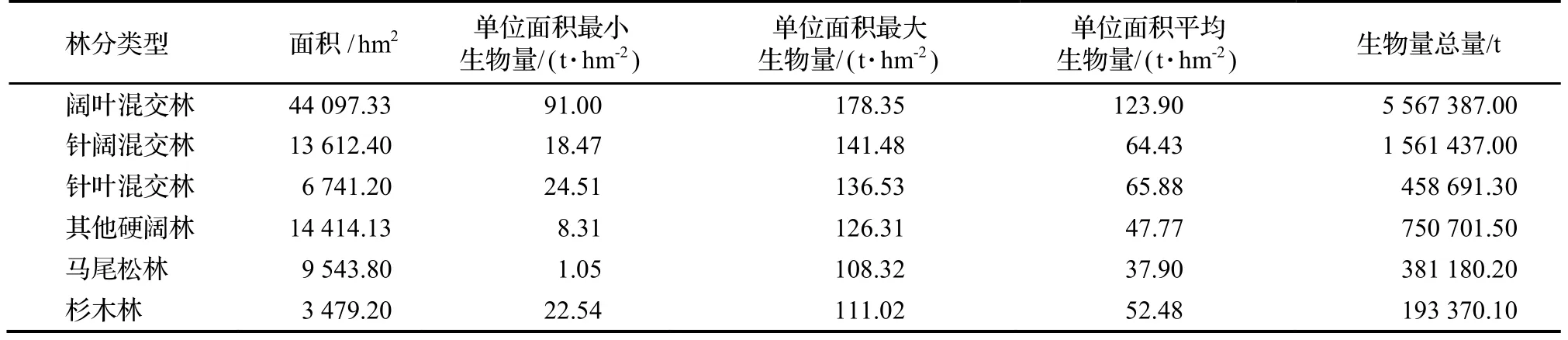
表2 基于生物量轉換因子函數法計算各林分森林地上生物量結果Table 2 AGB based on biomass conversion model
2.3 構建初始自變量因子集
2.3.1 光學遙感自變量因子(1)光譜特征因子 Sentinel-2 可覆蓋13 個光譜波段,其中,B1、B9、B10 三個波段的空間分辨率較低(僅為60 m),同時考慮到B10 波段作為卷云波段未進行大氣校正,B1 深藍波段和B9 水汽波段與本研究的相關性不大,因而去除這3 個波段,剩余的10 個波段參與后續實驗。為進一步豐富研究數據維度,基于上述10 個波段計算得到9 個常用植被指數和從紅邊波段提取的5 個植被指數也參與后續實驗,如表3。

表3 植被指數及計算公式Table 3 Vegetation index and computational formula
(2)紋理特征因子 本研究的紋理圖像使用灰度共生矩陣(GLCM)計算,選取7 種窗口大小(1×1、3×3、5×5、7×7、9×9、11×11、13×13)及2 種角度(45°右斜線方向、135°左斜線方向)計算森林紋理特征值,分析不同窗口和角度下各紋理因子對AGB 的預測能力。各組紋理特征均采用默認步長進行計算。
紋理特征包括:均值(Mean)、方差(Variance)、協同性(Homogeneity)、對比度(Contrast)、相異性(Dissimilarity)、熵(Entropy)、角二階矩(Angular second moment)、相關性(Correlation)8 個因子。
2.3.2 雷達遙感自變量因子 使用了4 個Sentinel-1 雷達遙感因子,分別為后向散射系數(VV、VH)、極化比值(VV/VH)和極化差值(VV-VH)。
2.3.3 DEM 自變量因子 從數字高程模型(DEM)中提取海拔、坡度和坡向3 個因子。
2.3.4 森林資源二類調查自變量因子 從森林資源二類調查數據中選用自變量因子郁閉度(YU_BI_DU)、年齡(NL)、起源(QI_YUAN)和地貌(DI_MAO)4 個因子。
2.4 自變量因子數據集成
將2.3 節共計43 個自變量因子的數據都以森林小班為單元進行集成,即每個小班為一條記錄,每條記錄均包含了43個數據項,最終得到24 183 條記錄作為本文的實驗樣本。繼而將24 183 個樣本按7∶3 的比例劃分為訓練集和測試集參與后續的建模和估測。
2.5 遞歸特征消除
在AGB 估測中,特征變量的選擇是影響估測效率及效果的重要因素之一。高維的特征因子豐富了信息的維度,但過多的特征變量容易導致訓練速度過慢,同時也可能導致過擬合等問題。為加快模型訓練速度,提高模型的泛化能力,本文在正式估測AGB 之前,采用遞歸特征消除法(Recursive Feature Elimination,RFE)進行特征選擇。RFE 通過逐步移除特征重要性最低的某個特征來達到降維的目的,其算法流程如圖4。
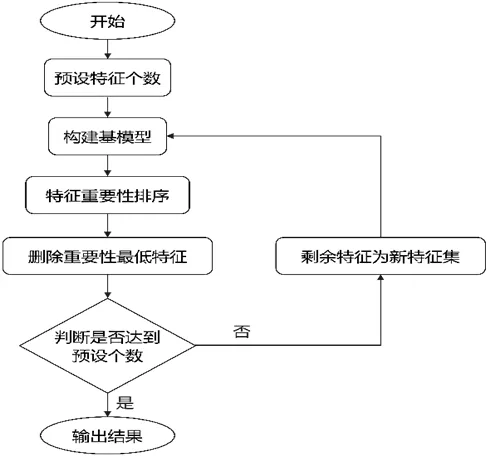
圖4 RFE 流程圖Figure 4 Flow chart of recursive feature elimination
2.6 機器學習算法
本文所涉及的三種算法(RF、AdaBoost 和CatBoost)均采用Python 編程實現,使用網格搜索的方式得到最優參數。因三種算法中,僅有CatBoost 能自動處理類別變量,而RF 和AdaBoost 并不具備這種能力,本研究使用獨熱編碼(One-Hot)對這兩種算法涉及到的分類變量值進行預處理。
2.6.1 RF 隨機森林算法(RF)是一種建立在決策樹上的集成學習算法,應用Bagging 模型對多棵決策樹進行組合[24-25]。對于回歸問題,隨機森林通常采用均值的方法將所有結果整合。本研究設置樹的數量(n_estimators)為150,最大特征數(max_features)設置為特征個數的平方根,最大深度(max_depth)設為16。
2.6.2 AdaBoost 自適應提升算法(AdaBoost)是一種Boosting 類型的迭代算法。首先,建立一個弱學習器模型,通過對各樣本評估,調整其權重大小,從而在后續的新模型中可以更專注于前模型的難點[26-27]。最終結果的獲取通過各學習器加權平均得到。AdaBoost 模型構建使用基學習器(base_estimators)為DecisionTreeRegressor,基學習器提升次數(n_estimators)為150,學習率(learning_rate)為0.05,損失函數(loss)為linear。
2.6.3 CatBoost CatBoost 算法來源于“Category”和“Boosting”,屬于Boosting 算法的一種。該算法基于對稱決策樹的高準確性GBDT 框架,最顯著的特點是可以高效合理地處理類別特征。CatBoost 算法首先對類別特征做一些統計,計算某個類別特征出現的頻率,之后加上超參數,生成新的數值特征[28-29]。在參數設置上,CatBoost設置迭代次數iterations=200,深度(depth)為8,學習率為0.05。
2.7 模型評價指標
本研究通過十折交叉驗證法進行模型評估,評價指標包括:決定系數(R-squared,R2)、均方根誤差(Root Mean Square Error,RMSE)、平均絕對誤差(Mean Absolute Error,MAE)和估測精度(Prediction,P),計算公式如下:
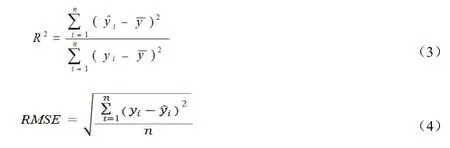

式中,n表示樣本數,yi為實測值,為預估值,為實測值平均值,。
3 結果與分析
3.1 紋理特征選擇結果
本文利用SelectKBest 方法來衡量紋理特征因子的重要性程度,對14 組共計112 個紋理特征因子的重要性進行排序(如圖5),再優先選取重要程度相對較大(>20)的紋理特征加入到估測模型的自變量集中。可以看出,在135°下各窗口特征重要性>20 的特征數量最多,均為4 個,且在該角度下13×13 窗口的特征重要性占比最高。據此選取窗口大小為13×13、角度為135°的紋理特征加入到自變量因子集參與建模與估測。
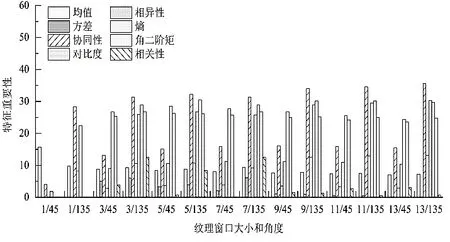
圖5 不同窗口大小/角度下紋理特征的重要性Figure 5 The importance of texture features at various window sizes/angles
3.2 自變量選擇
本研究所涉及的初始自變量共計43 個因子,包括10 個光學遙感波段因子、4 個雷達遙感影像因子、14 個植被指數、8 個紋理特征、3 個地形因子以及4 個森林資源二類調查數據。其中,二類調查數據中的起源和地貌2 個因子為類別特征,直接進入后續實驗;其余的41 個特征,采用遞歸特征消除法進行逐步刪減,每次移除特征重要性最低的某個特征。對不同數量和組合的自變量分別基于RF、AdaBoost 和CatBoost 算法對6 種林分的AGB 進行估測,計算出決定系數(R2)和均方根誤差(RMSE),并進行對比分析,結果如圖6。
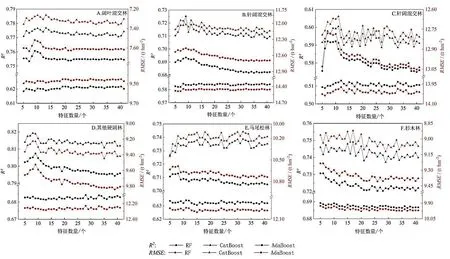
圖6 各模型在不同特征組合和林分下的性能指標Figure 6 Performance index of different models based on various feature combinations and various forest types
為了兼顧模型的效率及效果,本文盡量選取性能指標好同時特征數量少的模型及特征數量。依據這一原則,在RF、AdaBoost、CatBoost 模型中,闊葉混交林分別選用9、19、13 個特征,針闊混交林分別選用9、14、7個特征,針葉混交林分別選用7、12、11 個特征,其他硬闊林分別選用9、8、8 個特征,馬尾松林分別選用8、11、15 個特征,杉木林分別選用5、5、15 個特征。
3.3 AGB 建模與估測
分別針對6 種林分使用與其對應的最佳特征組合對其AGB 進行建模,計算得到各自林分類型的R2、RMSE、MAE和P性能指標,如表4。從表4 可知,CatBoost 模型的效果最佳,RF 模型次之,AdaBoost 模型最后。針對6 類林分類型,CatBoost 的最優特征組合如表5 所示。

表4 RF、AdaBoost 和CatBoost 的建模性能指標Table 4 Modeling indexes for RF,AdaBoost and CatBoost

表5 CatBoost 最佳特征組合Table 5 The best combinations of features for Catboost
為進一步探究遞歸特征消除法對模型性能的影響,分別使用特征優選后構建的模型與所有特征構建的模型進行性能指標(R2和RMSE)對比,結果如圖7。從圖7 可知,特征消除后的18 個模型估測效果均得到不同程度的改善。遞歸特征消除法從整體上刪減了冗余特征,降低了特征之間的共線性,減少了過擬合,進而使基于降維后特征構建的生物量估測模型的泛化能力更強,估測精度更高。
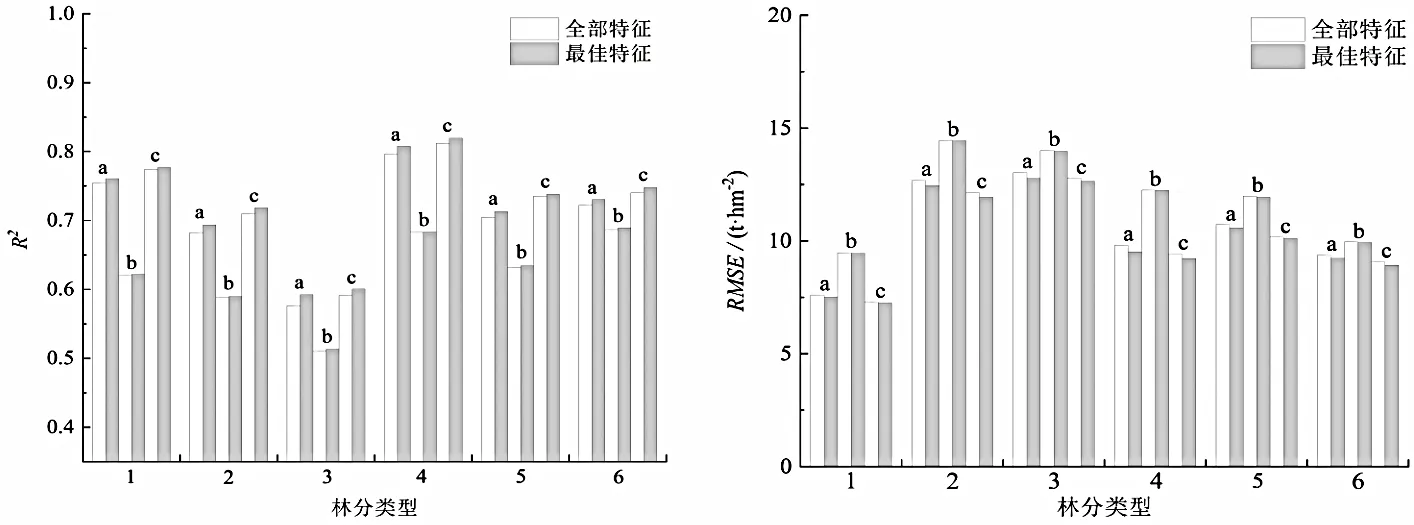
圖7 基于全部特征和最佳特征的估測結果的性能指標對比Figure 7 Comparison on performance indexes of estimation based on all features or the best features
3.4 AGB 估測結果分析
使用樣本數據的30%作為測試集估測6 種林分的AGB,與基于森林資源二類調查的蓄積量根據公式(1)計算得到AGB 值作為實測值進行對比,6 種林分的生物量情況如表6。
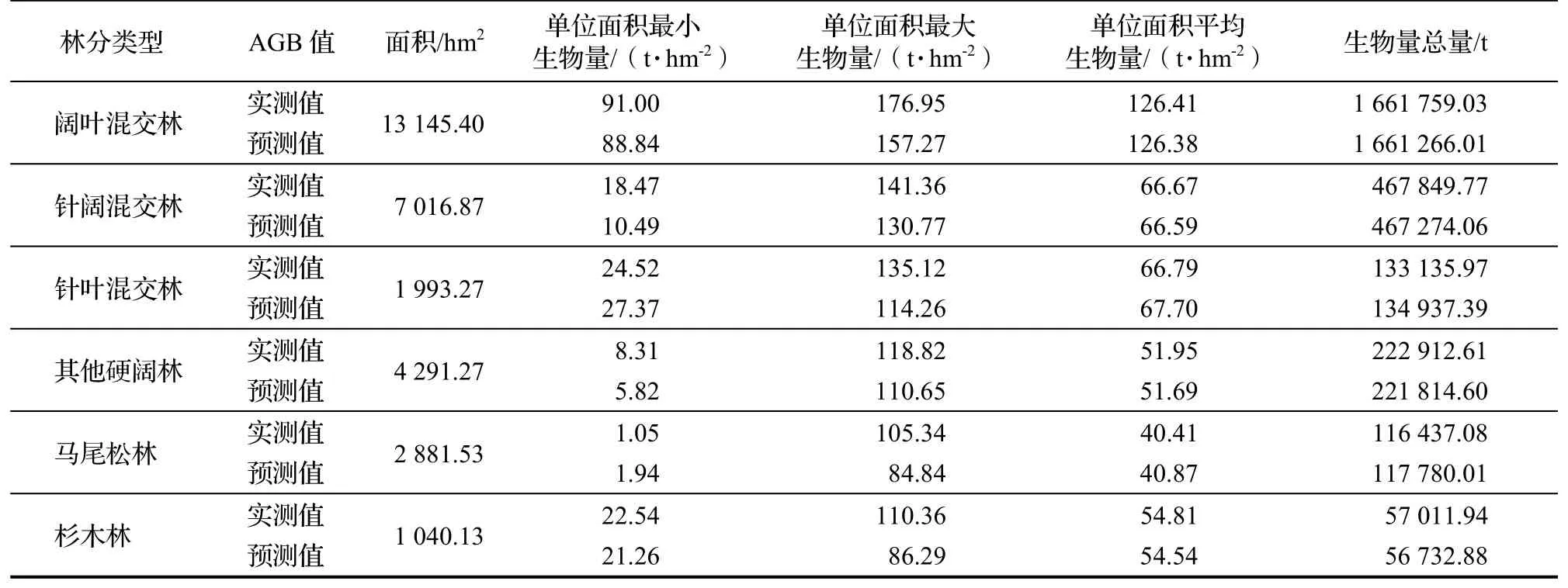
表6 測試集中6 林分森林地上生物量的分布情況Table 6 AGB of estimation and measured of different forest types
從表6 可知,6 種林分的單位面積最小生物量和單位面積最大生物量的估測值與實測值相差較大,但單位面積生物量平均估測值與平均實測值則非常接近,說明以單個小班而言估測結果可能存在一定的誤差,但從區域角度而言,估測結果的誤差較小,具有非常重要的參考價值。
4 討論
經遞歸特征消除法處理后的最佳特征組合中,紋理特征對提高估測精度有較大貢獻,特別是13/135/Correlation、13/135/Variance。窗口大小、角度、步長等參數的選擇對紋理特征的提取有一定的影響,從而影響模型精度,若今后的研究中再加入灰度差分向量(SADH)和差直方圖(GLDV)下更多窗口和角度的紋理因子,則存在進一步提升估測精度的可能性。
CatBoost 在建模和估測時,能夠自動處理類別特征,使得數據處理更加便捷化和優化,從而大幅降低模型的時間復雜度并得到最佳的估測效果。但在做遞歸特征消除時的訓練速度相比另外兩個算法較慢,原因可能是面對多維度的連續性特征,CatBoost 算法需將特征進行分箱,以減小內存的使用,但也增加了訓練時間。AGB估測常涉及到連續性的特征(如海拔),如何進一步調優CatBoost 參數以適應處理連續性特征,值得深入探究。
遞歸特征消除法通過逐次移除重要性最低的某個特征,能夠選擇出最適合基學習器(如RF、AdaBoost 和CatBoost)的特征組合。AGB 估測中的特征選擇方法通常直接使用機器學習模型,如隨機森林、多元線性回歸等,通過特征重要性排序進行篩選,但是沒有考慮自變量個數遞減的過程中特征重要性發生變化的問題。另外,常用的還有皮爾遜相關系數(Pearson Correlation)法,該系數是一個用來反映兩個變量之間相似程度的統計量,在機器學習中可以用來計算特征與類別間的線性相關程度,但不太適合用于多變量組合時的特征優選。
當前,森林地上生物量的研究大多只是針對少量的森林資源固定樣地或自設的調查樣地[2-3,17]而開展,或者是只針對某一特定樹種類型進行研究[14-15,18,20]。在對特征選擇的方法上,常用皮爾遜相關系數法或者估測方法本身對特征變量進行篩選[11-15]。本研究使用遞歸特征消除法,探究不同優勢樹種林分下估測AGB 的最優特征數量及組合,并比較了三種機器學習算法,能夠為中、大尺度森林AGB 估測提供一定的參考作用。
5 結論
本文針對森林地上生物量估測研究中多源數據集成下導致特征維度過高、特征選擇方法與機器學習方法相結合的研究還較少,在中、大尺度區域估測精度不高等問題展開研究。以臨海市作為研究區域,整合Sentinel-1、Sentinel-2 遙感影像數據、DEM 數據、森林資源二類調查數據,使用RF、AdaBoost 和CatBoost 三種機器學習算法分別對闊葉混交林、針闊混交林、針葉混交林、其他硬闊林、馬尾松林、杉木林6 種林分建立模型并估測其森林AGB,取得了較好的研究效果。具體結論如下:
(1)從特征組合來看,集成光學遙感、雷達遙感、地形因子及森林資源二類調查數據能夠更全面地利用多源數據的信息,有效提高森林AGB 的估測精度;
(2)遞歸特征消除法降低了模型的復雜度,消除了自變量之間的共線性,能在保持甚至提高模型估測精度的前提下,加快模型訓練速度;
(3)從6 種林分的AGB 的估測結果來看,6 種林分的AGB 的主要影響因素與個數不盡相同,這也緣于不同樹種有不同生物學和生態學特點,其中有3 個因子是共同的,即年齡、郁閉度和海拔;
(4)基于RFE 的CatBoost 的方法模型可以較好地完成中、大尺度下的森林地上生物量估測,既具備較快的估測速度,又具有較高的估測精度。該方法對各林分AGB 的建模精度為:闊葉混交林94.14%、針闊混交林81.40%、針葉混交林80.82%、其他硬闊類林80.77%、馬尾松林73.06%、杉木林83.02%。總體平均估測精度超過80%,高于當前大部分的森林AGB 估測結果。CatBoost 模型效果優于RF 和AdaBoost 模型效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
