融合多通道CNN 與BiGRU 的字詞級文本錯誤檢測模型
2022-09-15 06:58:58郭可翔王衡軍白祉旭
計算機工程 2022年9期
郭可翔,王衡軍,白祉旭
(1.信息工程大學 密碼工程學院,鄭州 450001;2.中國人民解放軍96714 部隊,福建 永安 366001)
0 概述
隨著社會信息化水平的不斷提升,無紙化辦公成為新趨勢,然而電子文本數量急劇增多,不可避免地會出現各種各樣的文本錯誤,機關公文、學術論文、法律文書等重要文本錯誤將影響各類文書的權威性和公信力。因此,如何有效減少文本錯誤,確保文本正確性和可靠性成為當前的研究熱點。
文本校對是自然語言處理(Natural Language Processing,NLP)領域的重要分支,是文本撰寫工作中不可或缺的關鍵環節,主要利用NLP 技術,按照一定的規則和要求,識別并糾正文本中所包含的錯誤。文本校對一般由檢錯和糾錯兩部分組成,正確糾錯離不開檢錯,精準高效的檢錯是校對工作的基礎。通常地,文本檢錯的輸入為可能包含錯誤的待檢錯句子,輸出為T(正確文本)或F(含字詞錯誤文本)二類檢測結果。
與英文文本相比,中文文本不存在非字錯誤,常見錯誤可分為字詞錯誤、語法錯誤和語義錯誤3 類。詞是自然語言中能夠獨立運用的最小單位,也是自然語言處理的基本單位。字詞錯誤在文本中出現頻率相對較高,對文本檢錯而言,字詞錯誤檢測十分重要。字詞錯誤包括多字、缺字、別字、易位等錯誤。
傳統的文本檢錯采用人工逐字逐句校對的方式,不僅考驗審校者的語言學知識水平,而且費時費力、效率不高。國內對中文文本自動檢錯的研究始于20 世紀90 年代初且發展迅速,主要采用基于規則、基于統計和基于傳統機器學習等方法。近年來,深度學習技術因強大的特征學習能力被廣泛應用于自然語言處理領域,尤其長短時記憶(Long Short-Term Memory,LSTM)網絡[1]在中文分詞、命名實體識別[2-3]、語法分析[4]等應用上取得較好成果,因此已有一些學者將深度學習技術應用于中文文本校對任務。
本文以中文文本字詞錯誤為檢測對象,提出一種基于多通道卷積神經網絡(Convolutional Neural Network,CNN)和雙向門控循環單元(Bidirectional Gated Recurrent Unit,BiGRU)的中文文本字詞錯誤檢測模型,主要包括詞向量層、多通道CNN 層、BiGRU 層和Softmax 輸出層。
1 相關工作
1.1 傳統的文本檢錯方法
傳統的文本檢錯方法包括基于規則的檢錯方法、基于統計的檢錯方法和基于傳統機器學習的檢錯方法。
基于規則的檢錯方法[5-6]主要利用語言學規則來偵測文本錯誤,規則越豐富,檢錯效果越好。該方法通俗易懂、可解釋性強、精確度高,但文本錯誤千變萬化、層出不窮,規則難以覆蓋所有錯誤類型,限制了檢錯的效果。
基于統計的檢錯方法[7-9]主要利用統計規律來檢測文本錯誤,很大程度上依賴訓練語料的規模和質量,規模越大,質量越高,檢錯效果越好,但容易出現數據稀疏問題,需要使用各種平滑技術來解決,且準確率有待提升。
基于傳統機器學習的檢錯方法主要利用大規模人工標注的語料樣本建立數學模型,通過調試模型的參數使其達到最優,其性能好壞取決于數學模型本身、訓練樣本規模的大小和模型參數的調試情況[10]。CHENG 等[11]提出一種基于條件隨機場(Conditional Random Field,CRF)的文本亂序錯誤診斷方法。WU 等[12]基于CRF 模型訓練一個線性標記器,構建中文語法錯誤診斷系統。CHEN 等[13]利用統計的方法在大規模語料庫上收集搭配信息,并將搭配特征集成到CRF 模型中,得到了更精確的文本檢錯模型。卓利艷[14]提出一種基于CRF 和n-gram散串技術的聯合檢錯方法,該方法首先標注數據、訓練模型,利用訓練好的CRF 檢錯模型判斷錯誤位置及錯誤類型,然后在分詞的基礎上得到散串,利用n-gram 模型確認錯誤位置。傳統機器學習方法在處理結構復雜的數據泛化問題時性能較差,且只能人工提取到淺層特征。
1.2 基于深度學習的文本檢錯方法
目前,運用深度學習技術處理中文文本檢錯問題的研究仍處于起步階段。但神經網絡能通過訓練模型參數實現特征自學習,學習到文本抽象的語義特征,使模型具有良好的泛化能力,因此基于深度學習的中文文本檢錯方法具有廣泛的研究前景。為提高文本檢錯準確率:ZHENG 等[15]提出一種CRF 和LSTM 相結合的模型,將CRF 的輸出作為LSTM 輸入層的離散特征;YANG 等[16]在LSTM 的輸出層后接一個CRF 層,確保預測標注序列的合法性,提高了句子標注的準確性;龔永罡等[17]在Seq2Seq 模型的基礎上,加入BiLSTM 單元和注意力機制,有效提升了檢錯水平。針對表達冗余、詞匯誤用和內容缺失等問題:葉俊民等[18]提出一種基于層次化修正框架的文本檢錯糾錯模型,利用基于預訓練模型獲得的文本語義表示來識別錯誤的位置,根據層次化修正框架計算精化的修正操作并修正錯誤;王辰成等[19]將語法檢錯糾錯任務轉換成翻譯任務,提出一種基于Transformer和多頭注意力機制的糾錯模型,利用殘差網絡動態連接不同神經模塊的輸出,使模型能更好地捕獲語義信息;段建勇等[20]改進了Transformer模型,在自注意力中加入高斯分布偏置項,加強了模型對局部信息的關注及對錯誤字詞與前后文關系的提取,同時采用ON_LSTM 結構,提升了模型獲取語法錯誤結構信息的能力;曹陽等[21]基于Transformer 網絡提出一種中文單字詞錯誤偵測方法,利用原始語料、漢字混淆集自動構建單字詞錯誤訓練語料并使用不同大小的移動窗口診斷單字詞錯誤。
2 基礎模型
2.1 卷積神經網絡
CNN 在機器視覺、圖像處理領域取得了巨大成功,近年來也被廣泛應用于NLP 領域且表現出色。CNN主要由輸入層、卷積層、池化層、全連接層和輸出層等組成,其中卷積層和池化層是核心部分,結構如圖1所示。
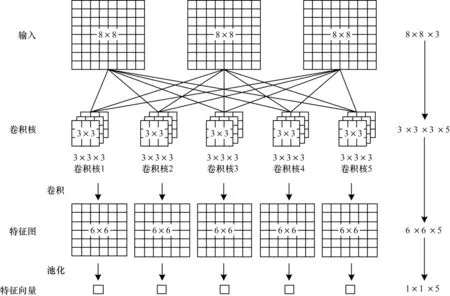
圖1 CNN 卷積層和池化層結構Fig.1 Structure of CNN convolutional layer and pooling layer
在NLP 任務中,CNN 的輸入層主要為文本的詞向量表示,如式(1)所示:

其中:Α為矩陣表示符;n為句子中詞向量的個數;m為詞向量的維度。
卷積層主要作用是基于卷積核對輸入向量進行卷積操作,提取局部特征f,利用其稀疏連接和權值共享的特性,降低輸入數據的維度,防止出現過擬合。卷積操作如式(2)所示:

其中:x為詞向量矩陣;W為權重矩陣,即卷積核矩陣;b為偏置量;φC為卷積核激活函數ReLU;*為卷積操作。以圖2 為例,卷積操作如式(3)~式(6)所示:


圖2 卷積操作Fig.2 Convolution operation
池化層主要作用是進行下采樣,篩選出卷積操作后最重要的特征,減小特征規模,提高特征魯棒性。常見的池化策略有最大池化(max pooling)和全局平均池化(global average pooling)。池化后的輸出作為全連接層的輸入,全連接層相當于前饋神經網絡的隱藏層,通常在CNN 的尾部進行重新擬合,減少特征信息的損失。輸出層主要用于輸出結果。
考慮到CNN 強大的局部特征提取能力,本文以CNN 模型為基礎,研究字詞級文本錯誤檢測模型。在文本檢錯任務中,CNN 模型可以提取句子中類似n-gram 的關鍵局部信息。
2.2 門控循環單元
循環神經網絡(Recurrent Neural Network,RNN)是深度學習技術在自然語言處理任務中的重要應用,t時刻隱藏層狀態的計算依賴于t時刻的輸入和t-1 時刻隱藏層的輸出狀態,因此具有一定的記憶功能,能夠提取到上下文的文本特征,處理序列識別建模問題時優勢明顯。然而,RNN 在反向傳播前面時刻的參數計算過程中,隨著參數W初始化為小于1的值,容易出現梯度消散的問題,從而導致訓練的停滯。通常,RNN 只能記憶5~10 個時間步的信息,難以捕獲序列中長時間和長距離的依賴關系。
在RNN 模型的基礎上,HOCHREITER 等[1]提出長短時記憶網絡,通過使用輸入門、輸出門和遺忘門3 個門結構,LSTM 在記憶重要上下文信息的同時,遺忘無用的信息,在一定程度上解決了RNN 長期記憶和反向傳播中梯度消散等問題。然而,LSTM 訓練時間較長、參數較多且計算復雜。CHO 等[22]提出門控循環單元(Gated Recurrent Unit,GRU),GRU 是長短時記憶網絡模型的一種變體模型,結構如圖3所示。

圖3 GRU 結構Fig.3 Structure of GRU
對于任意時刻t,假定此刻GRU 的隱藏層的輸入為xt、輸出為ht,GRU 的計算過程如式(7)~式(10)所示:

其中:rt、ut和分別表示t時刻的重置門、更新門和候選隱藏層的狀態;ht-1表示t-1 時刻的隱藏層的輸出;Wr、Wu、Wh、br、bu、bh分別表示重置門的權重矩陣、更新門的權重矩陣、候選隱藏層的權重矩陣、重置門的偏置量、更新門的偏置量、候選隱藏層的偏置量;φ和σ分別為tanh 和Sigmoid 激活函數;[]表示向量拼接操作;?為哈達瑪積,表示向量元素相乘操作。
GRU 利用2 個門單元(重置門、更新門)代替LSTM 中的3 個門單元(輸入門、輸出門和遺忘門),實現對上下文信息的有效篩選與過濾。由式(7)、式(9)可知,重置門主要負責確定t-1 時刻隱藏單元的狀態ht-1在t時刻候選狀態中被重置的程度,重置門的值越大,則被重置的程度越高。由式(8)、式(10)可知,更新門主要負責確定t-1 時刻隱藏單元的狀態ht-1、t時刻候選狀態對當前狀態ht的影響程度,更新門的值越大,則前一時刻隱藏層狀態被遺忘的程度越高,當前候選狀態被記憶的程度也越高。
GRU 具備了LSTM 的優點且只有兩個門單元,模型結構更簡單、參數更少、收斂性更好,很大程度上縮短了模型訓練時間,提高了訓練效率。在經典的GRU 模型中,狀態是根據序列由前向后單向傳輸的,忽略了后序狀態對前序狀態的影響。BiGRU 是GRU 的一個變體模型,既能提取前文特征,又能捕捉后文信息,彌補了單向GRU 的不足,提升了模型的效果,結構如圖4 所示。在圖4 中,xi(i=1,2,…)表示當前的輸入,表示經過GRU 輸出的正向隱藏狀態,表示經過GRU 輸出的反向隱藏狀態,hi表示正向和反向拼接后的隱藏狀態。

圖4 BiGRU 結構Fig.4 Structure of BiGRU
在通常情況下,中文文本中的字詞錯誤與上下文均有關。因此,綜合考慮硬件的計算能力、時間成本以及對上下文特征提取的需求,本文以BiGRU 模型為基礎,研究字詞級文本錯誤檢測模型。在文本檢錯任務中,BiGRU 模型可以捕獲變長且雙向的n-gram 信息。
3 基于多通道CNN 與BiGRU 的文本錯誤檢測模型
本文提出一種基于多通道CNN 與BiGRU 結構的字詞級文本錯誤檢測模型,既能充分發揮CNN 提取待檢錯文本局部特征的優勢,又能利用BiGRU 深入學習待檢錯文本的上下文語義信息及長時依賴關系。該模型主要由詞向量層、多通道CNN 層、BiGRU 層和Softmax 輸出層等組成,整體結構如圖5所示。采取無監督學習的方式訓練模型,利用帶標簽類的語料訓練基于多通道CNN 與BiGRU 的字詞錯誤檢測模型,使其自動學習模型中的各參數,采用訓練得到的檢錯模型對待檢錯語句進行分類,判斷是否存在字詞錯誤并輸出結果。

圖5 基于多通道CNN 與BiGRU 的字詞級文本錯誤檢測模型結構Fig.5 Structure of the word-level text error detection model based on multi-channel CNN and BiGRU
3.1 詞向量層
詞向量層主要是將輸入的待檢錯文本向量化。詞向量是詞匯的分布式表示,關鍵在于將詞匯轉化為相對低維的連續的稠密實數向量,在深度學習技術應用于NLP 領域扮演著重要的角色。詞向量之間的距離表征了詞語間的相似性,距離越近,則相似程度越高。
給定一個含詞量為n的句子X=x1,x2,…,xn,xi(i=1,2,…,n)為句子中的第i個詞語,經過詞向量層的映射后,則句子X可表示為由n個詞向量拼接而成的二維矩陣,如式(11)所示:

其中:ei表示句子中xi對應的詞向量。
3.2 多通道CNN 層
多通道CNN 層主要利用多通道卷積神經網絡有效提取文本的局部特征,輸入為預訓練好的詞向量。選擇不同大小的卷積核對輸入的詞向量進行卷積操作,可以提取到廣度不同的上下文信息,即不同粒度的特征信息[23],從而達到提取文本局部特征的目的。
使用不同尺寸的卷積核進行卷積操作,從而得到文本的局部特征,如圖6 所示。令第i個通道所使用的卷積核為k,如式(12)所示:
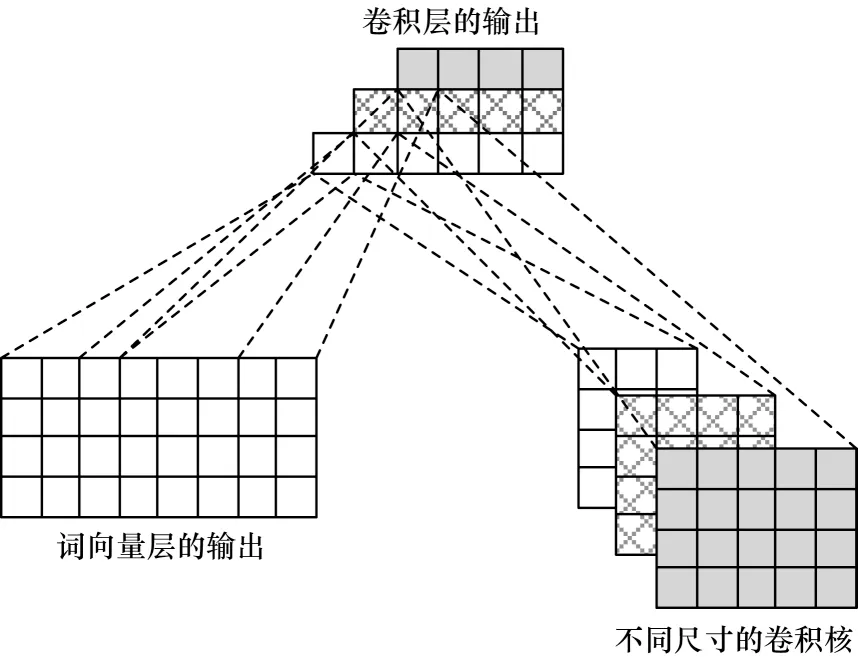
圖6 多通道卷積操作Fig.6 Multi-channel convolution operation

經該卷積核k卷積操作后的特征fij的計算如式(13)所示:

其中:Xi:i+n-1∈Αn×m表示n個詞向量組成的卷積核動態處理窗口。當窗口從X1:h動態移動至Xn-h+1:n時,{X1:h,X2:h+1,…,Xn-h+1:n}所對應的第i個通道得到的特征序列如式(14)所示:

多通道CNN 提取到的局部特征進行最大池化操作后生成固定維度的特征序列,再將多個固定維度的特征序列拼接形成融合特征序列f,令通道個數為u,則f可表示如下:

3.3 BiGRU 層
BiGRU 層主要利用雙向門控循環單元挖掘文本的上下文信息、解決長時依賴問題,輸入為多通道CNN 層經卷積操作提取的特征序列的融合。權值共享的BiGRU 將粒度不同的特征信息映射到相同的向量空間內。
對于給定的n維輸入(x1,x2,…,xn),t時刻BiGRU的隱藏層輸出為ht,計算過程如式(16)~式(18)所示:

當BiGRU 模型參數過多、訓練樣本較少時,容易產生過擬合現象。為防止訓練過度,BiGRU 層采用dropout 機制,隨機丟棄一些隱藏層節點使其暫時不參與模型訓練,迫使BiGRU 網絡在訓練過程中學習魯棒性更強的特征,提升模型的泛化能力。
3.4 Softmax 輸出層
Softmax 輸出層主要利用Softmax 函數對BiGRU層的輸出進行歸一化處理,提升模型的精度和收斂速度,最終得到文本檢錯結果,如式(19)所示:

其中:WS為Softmax 層的權重矩陣;bS為Softmax 層的偏置量。采用最小化交叉熵損失函數(crossentropy loss function)的方式來求解和評估模型,同時引入L2 正則項,使模型參數更少、結構更簡單,防止過擬合,損失函數的計算如式(20)所示:

其中:i為待檢錯文本的句子索引;j為待檢錯文本類別的索引T(正確文本)或F(含字詞錯誤文本);M為訓練數據集的大小;N為檢測結果的類別數量;yi為待檢錯文本實際所屬的類別,為待檢錯文本經模型預測的類別;λ||ω||2為L2 正則化項,λ為正則化參數,ω為模型參數。
4 實驗與結果分析
4.1 實驗環境、數據集與評價指標
實驗環境為:CPU 為Intel Core i7-7800X,GPU 為GeForce RTX 2080Ti,內存為DDR4 16 GB,操作系統為Windows10(64 位),深度學習框架為tensorflow1.14。
實驗在公開數據集SIGHAN2014、SIGHAN2015上進行,采用SIGHAN2014、SIGHAN2015 中文拼寫檢查任務的訓練集作為實驗訓練語料,SIGHAN2014 中文拼寫檢查任務的測試集作為實驗測試語料。訓練語料包括9 701 個段落(共計8 325 個字詞錯誤),其中SIGHAN2014 訓練集中有6 527 個段落(共計5 224 個字詞錯誤),SIGHAN2015 訓練集中有3 174 個段落(共計3 101 個字詞錯誤)。測試語料包括1 062 個段落,段落文本的平均長度為50,其中50%文本中無字詞錯誤,50%文本中至少含有1 個字詞錯誤(共計792 個字詞錯誤)。如果句子中包含至少1 個字詞錯誤,則該句子為含字詞錯誤文本且被標記為F,否則為正確文本且被標記為T。
實驗采用檢錯的準確率(P)、召回率(R)、調和平均值(F1)作為文本檢錯模型性能好壞的評價指標,其中F1值為P和R的調和平均值,計算如式(21)所示:

4.2 實驗數據預處理與參數設置
在實驗開始前需要對實驗語料進行數據預處理。在NLP 任務中,預訓練詞向量的效果影響著文本校對、機器翻譯、文本分類等NLP 下游任務模型性能的好壞。本文使用Word2vec 詞向量工具[24],基于大規模中文維基百科語料訓練skip-gram 模型。考慮到詞的數量,將中文文本詞向量的維度設置為300。在訓練詞向量的過程中,詞出現次數的閾值設置為5。若一個詞出現次數大于5,則將該詞添加于詞向量詞典;反之舍棄。對于未登錄詞,隨機初始化其向量表示。考慮到實驗語料中文本的平均長度為50,將句子長度的閾值設置為50。當句子長度小于50 時,進行補零操作;反之進行截斷操作。對于實驗語料中待檢錯文本,需要先使用jieba 分詞工具進行中文分詞。
目前,深度神經網絡模型中使用較多、效果較好的優化算法是Adam[25],其引入動量和自適應性學習率使得網絡更快收斂。因此,本文實驗采用Adam 作為模型的優化器。
本文多通道CNN 所用的卷積核寬度分別為3、4、5,尺寸分別為3×300、4×300、5×300,數量均為128;BiGRU 隱藏層數分別1、2、3、4,隱藏層節點數為128;同時采用L2 正則化和dropout 策略來避免過擬合現象的發生。經過多次實驗優化參數,本文模型的實驗超參數設置如表1 所示。

表1 實驗超參數設置Table 1 Setting of experimental hyperparameters
4.3 實驗設計與結果分析
本文共設計4 個實驗。實驗1、實驗2、實驗3 利用控制變量法針對影響基于多通道CNN 與BiGRU 字詞錯誤檢測模型(簡稱為CNN-BiGRU 模型)性能的多個重要參數進行實驗驗證,使模型性能達到最優。在實驗1、實驗2、實驗3 的基礎上,設計實驗4,將性能最優的CNN-BiGRU 模型與基于RNN、LSTM、GRU、BiGRU的文本檢錯模型進行比較,從而驗證CNN-BiGRU 模型的有效性和優越性。
實驗1驗證卷積核通道數和寬度對CNN-BiGRU模型性能的影響。在BiGRU 隱藏層數為3、dropout 丟棄率為0.2 的情況下,分別選取單通道卷積核寬度為3、4、5 和多通道卷積核寬度為(3,4,5)進行實驗,結果如表2 所示,其中最優指標值用加粗字體標示。

表2 CNN-BiGRU模型在不同卷積核寬度下的測試結果Table 2 Test results of CNN-BiGRU model with different convolutional kernel widths
由表2 可以得出,利用不同通道數和寬度的卷積核對文本進行卷積操作,均能有效挖掘文本的局部特征。多通道CNN-BiGRU 模型效果優于單通道CNN-BiGRU 模型效果。在單通道CNN-BiGRU 模型中,隨著卷積核寬度的增大,模型性能越來越好。
實驗2驗證BiGRU 隱藏層數對CNN-BiGRU 模型性能的影響。在dropout 丟棄率為0.2 的情況下,分別選取BiGRU 隱藏層數為1、2、3、4 進行實驗,結果如表3 所示,其中最優指標值用加粗字體標示。

表3 CNN-BiGRU 模型在不同BiGRU 隱藏層數下的測試結果Table 3 Test results of CNN-BiGRU model with different BiGRU hidden layers %
由表3 可以得出,隨著BiGRU 隱藏層數的增加,CNN-BiGRU 模型的網絡不斷加深,表現越來越優,說明適當地增加隱藏層數能夠豐富網絡結構,提高網絡學習能力,從而改善檢錯模型效果。當隱藏層數為3 時,CNN-BiGRU 模型的精度達到最高。但隨著隱藏層數的繼續增加,模型參數會大幅增多,模型復雜度也急劇加大,模型性能有所下降,由此說明隱藏層數也不宜過多,否則容易出現過擬合。
實驗3驗證dropout 機制的有效性及dropout丟棄率對CNN-BiGRU 模型性能的影響。在BiGRU隱藏層數為3 的情況下,分別選取dropout 丟棄率為0.0、0.2、0.5 進行實驗,測試在每一輪迭代后檢錯F1值的變化情況,結果如圖7 所示。

圖7 CNN-BiGRU 模型在不同丟棄率下的迭代后檢錯F1值Fig.7 Error detection F1 value of CNN-BiGRU model after iteration with different drop rates
由圖7 可以得出,dropout 機制對于防止過擬合、提升檢錯模型的性能起著重要作用。在丟棄率為0.0 即不采用dropout 機制的情況下,前幾輪迭代中CNN-BiGRU 模型性能較好,但當迭代輪數逐漸增大,檢錯F1值趨于穩定時,丟棄率為0.2 的模型性能優于不采用dropout 機制的模型性能。在丟棄率選取為0.5 的情況下,CNN-BiGRU 模型性能較差,因此,采用dropout 機制時丟棄率不宜選取過大,否則容易丟棄重要特征導致模型性能下降。
實驗4驗證CNN-BiGRU 模型的有效性。在BiGRU 隱藏層數為3、dropout 丟棄率為0.2 的情況下,對基于RNN、LSTM、GRU、BiGRU、CNN-BiGRU 的文本檢錯模型進行實驗,結果如表4 所示,其中最優指標值用加粗字體標示。

表4 不同文本檢錯模型的測試結果Table 4 Test results of different text error detection models %
從表4 實驗結果可以看出:
1)基于RNN、LSTM、GRU 的文本檢錯模型均能提取文本序列間的長時依賴關系,基于LSTM、GRU的文本檢錯模型效果相當,明顯優于基于RNN 的文本檢錯模型,但基于GRU 的文本檢錯模型結構簡單,更具優勢。
2)相較于GRU 的文本檢錯模型,基于BiGRU 的文本檢錯模型能夠充分提取上下文特征信息,彌補了單向GRU 的不足,檢錯F1值提升了0.77 個百分點。
3)相較于BiGRU,本文基于多通道CNN 與BiGRU 的文本檢錯模型能夠學習文本序列間的局部特征信息,檢錯F1值提升了1.65 個百分點。
目前公開的字詞錯誤檢測的語料較少,實驗主要依賴于SIGHAN2014、SIGHAN2015 中文拼寫檢查任務中的訓練集,且訓練語料規模不大。然而,字詞錯誤檢測模型對訓練語料的規模要求較高,制約了基于多通道CNN 與BiGRU 的字詞級文本錯誤檢測模型在測試語料中預測準確率、召回率的進一步提升。例如,“那一天我會穿牛仔褲和紅色的外套;頭上會帶著藍色的帽子。”和“我也想試試看那一家的越南菜;網路上說很多人喜歡那一家餐廳。”均為含有字詞錯誤的文本,其中,“帶著”應改為“戴著”,“網路”應改為“網絡”,該文本應被標記為“F”卻被錯誤標記為“T”。
5 結束語
本文提出一種融合多通道CNN 與BiGRU 的中文文本字詞錯誤檢測模型,在多通道CNN 層深入挖掘文本局部特征,在BiGRU 層充分提取文本上下文信息,同時采用L2 正則化和dropout 策略防止模型過擬合。在SIGHAN2014 和SIGHAN2015 中文拼寫檢查任務數據集上,設計字詞錯誤檢測實驗分析并對比模型性能。實驗結果表明,該模型有效解決了字詞級文本錯誤檢測的問題。后續將使用結構更簡單的最小門單元代替門控循環單元,并引入注意力機制完善字詞級錯誤檢測模型,使其檢錯F1值得到進一步提升。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
小學教學參考(2015年20期)2016-01-15 08:44:38
