機器學習和深度學習的并行訓練方法
2022-09-20 02:55:06祝佳怡
現代計算機 2022年14期
關鍵詞:模型
祝佳怡
(西南民族大學計算機科學與工程學院,成都 610225)
0 引言
人工智能(artificial intelligence,AI)這一概念的出現最早可以追溯到20世紀50年代。隨著Marvin Minsky和John McCarthy于1956年共同主持的達特矛斯會議(dartmouth summer research project on artificial intelligence,DSRPAI)的舉辦,“人工智能”這一概念被正式定義。該會議的舉辦標志著人工智能進入了第一次發展期。在當今時代,因機器學習(machine learning,ML)和深度學習(deep learning,DL)方法和大數據技術的不斷發展,人工智能已經成為必不可少的科學技術之一。如今人工智能模型的效果越來越好,這離不開高性能模型的設計,而無論是在工業界還是學術界,機器學習方法及深度學習模型都越來越傾向于向更復雜的方向發展。這一發展趨勢使得模型的訓練成本越來越大,再加上數據量的龐大,訓練一個效果優秀的深度學習模型往往需要數月的時間。
在一般的計算機程序中,解決問題的算法通常是以指令序列流的形式執行,這些指令通過中央處理器(central processing unit,CPU)來進行計算,這種方法被稱為串行計算(serial computing)。與之相對的并行計算(parallel computing)則將一個任務劃分為互不相關的多個計算部分,并使用多個計算單元對這些計算部分并行地分別進行計算,最終將結果匯總起來,實現了性能的提升。在理想的情況下,并行化所帶來的性能提升是指數級別的,即把問題規模劃分為一半,性能提升兩倍,以此類推。但是在更一般的情況下,并行計算的性能提升遵循Gustafson法則。消息傳遞接口(message passing interface,MPI)是實現并行計算的一種主流方式,各個進程間通過這一接口來進行任務的分配、消息的接收發送等機制,實現并行的目的。隨著目前云服務器和大數據的普及,并行計算將是解決大規模方法的最有效優化手段之一。
傳統的ML、DL模型的訓練方法是對訓練樣本一個一個地進行計算,并根據所有樣本的結果對模型進行調整。這是一種非常典型的串行的實現思路。通過對該問題進行簡要分析可知,每個訓練樣本之間的計算都是獨立的計算單元,這些樣本自身的計算之間互不相干,因此可以使用并行化的思想來解決該問題,從而大幅縮減模型的訓練時間。多個節點并行地計算各自的樣本子集結果,并將這些結果匯總到主節點中,對模型的參數進行更新,完成了一輪的訓練流程。在本實驗中嘗試將這一思想應用于最簡單的機器學習模型訓練當中。理想情況下,隨著計算節點數量的增加,訓練所消耗的時間應逐漸減少。實驗結果表明,在模型的規模較小時,使用MPI技術實現并行化方法的訓練時間會隨著節點數的增加而增加。通過分析可知,在各節點的消息接收和發送階段也會存在一定的時間消耗。如果一個樣本計算所消耗的時間小于進程間消息接收發送的時間,則會導致這一與理想情況相悖的現象發生。本實驗中的模型是最簡單的線性回歸模型。在實際中,深度學習模型是非常龐大且復雜的。在這種常規的情況下,一個樣本計算所消耗的時間會大幅度多于進程間的通訊時間,這時并行化所帶來的計算效率的收益是巨大的。
1 數據集準備及方法介紹
1.1 數據集
本文以回歸任務作為示例,并使用其中最基礎的線性回歸來解釋本文闡述的ML、DL并行訓練思想。所使用的數據集是隨機生成的用于線性回歸的數據。數據集的生成使用基于Python語言的Sci-kit Learn工具包中的make_regression()函數來實現,代碼段如下:

其中指定了樣本數量為500,特征數量為1。生成的是一個長度為500的向量,也是一個長度為500的向量,中的每一個元素都通過一個參數與中的對應值進行匹配。該數據集的可視化如圖1所示。需要注意的是該可視化雖然在視覺上是一條直線的形式,但實際上是由500個數據點構成的。
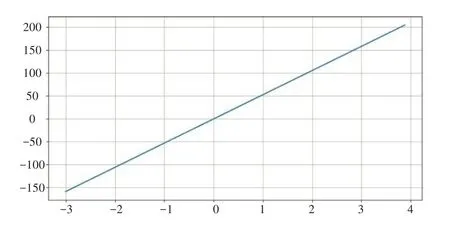
圖1 隨機生成線性回歸數據集的可視化
機器學習及深度學習模型的目標就是找到最好的擬合數據的參數,實現對訓練集的特征學習。圖2很好地展示了不同的模型或不同的模型參數的擬合情況。
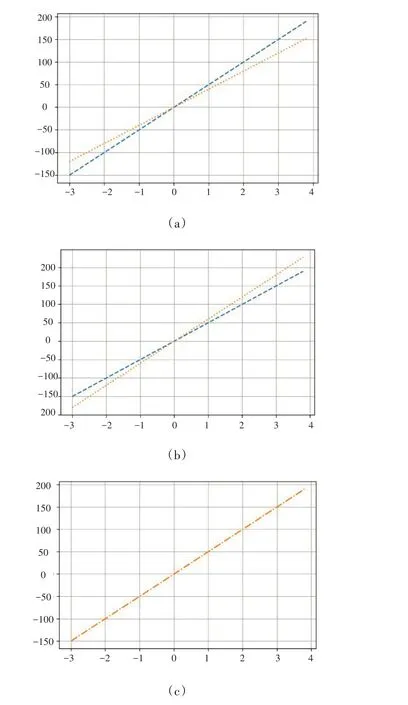
圖2 對數據集不同的擬合情況(長線段表示原始的數據集,點線表示擬合情況)
從圖2可知,(a)和(b)均沒有很好地擬合數據集;而(c)是一個擬合較好的情況,因此本文要盡可能使我們的模型達到如圖2(c)所示的效果。
1.2 串行的實現思路
為了更好地闡述以上的問題,在這里給出一些數學符號來對問題進行定義。設訓練集的樣本總容量為,每個樣本含有個特征,則給定訓練集∈R,其對應的標簽∈R。在上述的數據集中,每個樣本只有一個特征,即=1;且保證了本實驗中的數據集中所有樣本的平均值為0,因此可以用一條=的直線來對數據進行擬合。
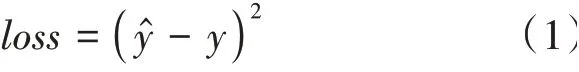
值越小,證明模型對該樣本的預測效果越好。對所有樣本都進行該運算,最后將所有樣本的值進行累加,得到模型總的損失。總損失也被稱為模型的代價(cost value)。
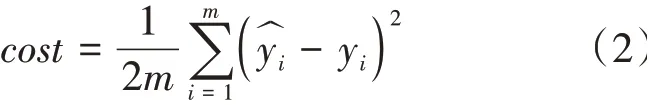
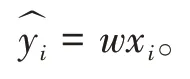
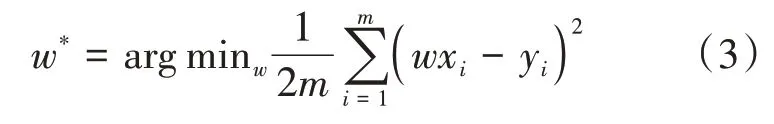
一種通用的求解的方法被稱為梯度下降法。根據模型的代價,對參數求偏導,可以使用該值對模型的參數不斷進行更新迭代,數學定義如下:
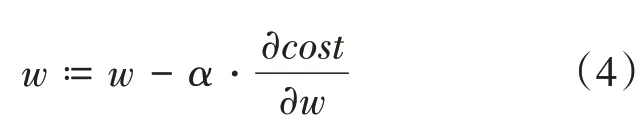
其中為學習率,可以用來調節更新迭代的步長大小。合適的學習率可以使模型的損失更快速地收斂到局部或全局最小值。迭代更新多次后,模型的損失逐漸收斂,不再減小,這時可以認為模型已經訓練完畢,此時的參數為模型訓練的最終結果。
上述的步驟中,對所有的訓練樣本是一個一個地進行計算損失,并進行累加作為模型的代價,最終使用梯度下降法進行更新。對訓練樣本分別進行計算是一個典型的串行思維方式。該思路的偽代碼實現如下:
串行的梯度下降算法

假設計算每個樣本的預測和計算梯度的時間復雜度為(),則訓練一輪需要的時間復雜度為(×),其中是訓練樣本的數量。通常情況下()的規模是十分巨大的,又由于訓練樣本數量通常也有很大的規模(>10),采用這種串行的計算方式會導致訓練大型深度學習模型的時間開銷過于龐大。
1.3 并行思想
通過上述的訓練過程可以知道,模型的代價計算是一個求和的過程,是對所有樣本的損失值進行累加,進而進行更新迭代。在該求和的過程中,每一項(樣本的損失值)的計算并不會相互影響,因此每個樣本計算損失的過程可以被多個進程或多個計算節點并行化。因此模型的訓練過程與最簡單的數列求和背后的邏輯是一致的。由于進程之間沒有相互依賴,該問題可以很好地被并行化。
根據這一思想,本實驗提出的并行訓練方法與簡單的數列求和思想非常相近。考慮一個數列求和的并行化問題:1+2+…+100,假設由四個節點來計算,一種巧妙的方法是令:
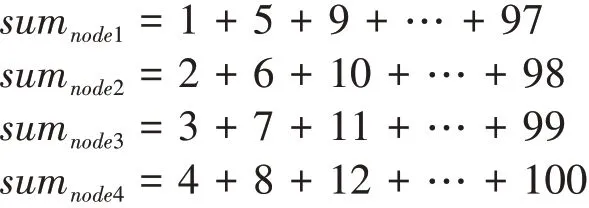
可以看到四個節點分別計算各自的和,并且能夠覆蓋1…100的所有值。回到模型的訓練問題,模型訓練中的關鍵是進行模型的代價,而代價是所有樣本的損失值的累加和。因此:
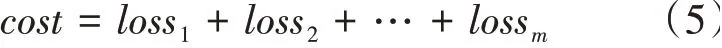
用與數列求和相似的思路可以很好地解決該問題的求解。本實驗的機器學習及深度學習模型梯度下降的并行訓練算法的偽代碼如下所示:
并行的梯度下降算法

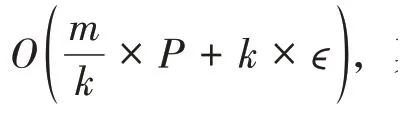
2 代碼實現
本節闡述了上述方法的具體代碼實現過程。首先是MPI的初始化部分:

初始化后進行數據的讀入部分。在這里已經將數據集分別存入X.in和y.in文件中,讀入數據的代碼如下所示:

指定一些其余的參數,如訓練樣本數量等,如下所示:

接下來是訓練環節。判斷當前節點是否為主節點,如果不是主節點則計算后傳給主節點,如下所示:


上面的代碼中,變量predict為預測結果,loss為損失值,node_derivative為梯度信息。計算完畢后使用MPI_Send()將梯度信息和損失分別用不同的標識符發送給主節點。主節點部分的代碼如下所示:


主節點在計算完自己的部分后,接收來自其他節點的梯度信息和損失信息,并進行累加。累加后求得總損失和總梯度,然后使用weight=weight-alpha*derivative進行梯度更新。上述過程循環epoch次,循環結束后訓練終止。在最后主節點對訓練的結果進行輸出:

需要注意的是,在第一輪循環結束后,主節點要把更新后的weight傳給其他節點,其他節點接收更新后的weight后再進行下一輪的計算。主節點發送weight的代碼如下:
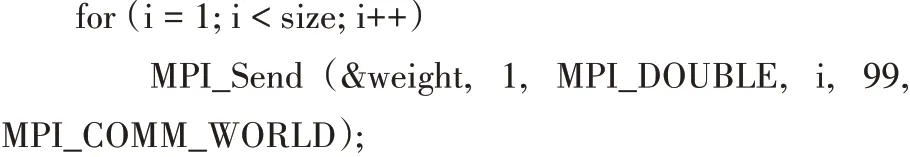
其他節點接收weight的代碼如下:

其他節點在第一輪的訓練中,使用0作為參數進行計算,后續的迭代過程中,使用主節點發送的weight來進行計算。以上便是并行訓練的核心代碼部分。
3 實驗結果
在本節中,為了分析并行方法在線性回歸模型中所帶來的性能提高程度,分別設置了節點數為1,2,4,8,16,32。為了得到可靠的結果,每個節點數量都分別運行了五次。對方法的性能評估主要是用以下三個指標:運行時間、計算所得的參數值、訓練300輪后的損失值。將五次的運行結果取平均值和方差,作為最終結果。實驗結果如表1所示。
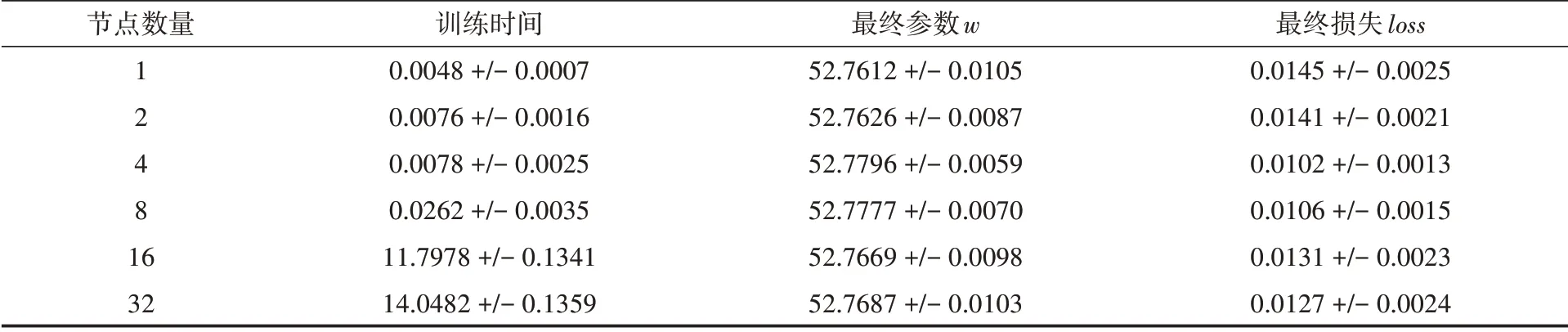
表1 不同節點數量的各個指標統計結果
將模型的參數進行可視化,得到如圖3所示的結果。從圖中可以看出,預測結果很好地擬合了數據集(點線表示的預測結果與數據集完全重合)。
圖3 訓練的參數可視化結果
4 分析與討論
根據表1的結果可以了解到,不同的節點數量訓練后最終的參數和最終的損失都保持基本一致。訓練的最終效果是一致的,都能擬合到最優的情況。但是訓練的時間卻出現了與理想情況相悖的現象:隨著節點數量的增加,模型所需要的訓練時間越來越多。然而理想情況應該是隨著節點數量的增加,訓練時間越來越少。
這一現象的產生可以從并行方法的時間復雜度進行考慮。在第二節中提到過,并行訓練的時間復雜度形式為
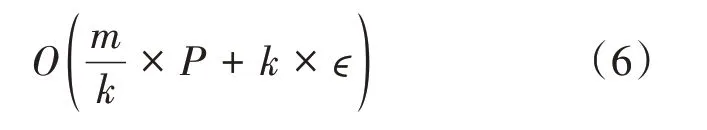
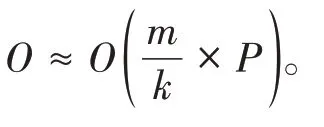
5 結語
在本實驗中針對機器學習和深度學習模型的訓練過程提出了一種并行化的策略,用于解決大規模的數據和大量的計算所帶來的時間消耗問題。本實驗以最基礎的線性回歸作為示例,展示了并行訓練的一種思路。對實驗結果進行分析,說明基于MPI技術的并行化方法有它的適用場景,也存在不適用的情況。本實驗提出的并行化方法適用于大規模的數據集和大規模的網絡框架,隨著節點數量的增加,訓練耗時將大大減少;而對于小規模數據和小規模模型的情景,隨著節點數量的增加,訓練時間將逐漸增加,因此該并行化方法不適用于此場景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
