ISLM:克服災難性遺忘的增量深度學習模型
2022-09-20 02:55:02程虎威
現代計算機 2022年14期
程虎威
(北京交通大學計算機與信息技術學院,北京 100044)
0 引言
深度神經網絡(deep neural networks,DNNs)在多個領域取得了顯著的成功,包括計算機視覺,自然語言處理和強化學習等。然而,傳統的DNNs方法在訓練時需要所有訓練樣本,這在現實世界中很難實現,因為現實中的數據往往會隨著時間、地點的變化以及其他條件而逐漸被收集。針對這種情況,研究人員提出令DNNs按照人類的學習方式進行增量學習。但是,研究人員發現如果DNNs按照人類學習的方式順序學習一系列任務,DNNs會遭受災難性遺忘而忘記先前學習的知識。因此,如何解決增量學習中出現的災難性遺忘問題是研究人員關注的重點。
當前解決災難性遺忘的增量學習研究工作大致可以分為三類。第一類方法通過重放先前的任務樣本來解決災難性遺忘問題,不過這些基于重放的方法需要額外的存儲空間來存儲舊任務的樣本和舊模型的權重;第二類方法在學習新任務時引入了控制參數變化的約束,從而緩解舊任務權重丟失,然而在這類方法中遺忘仍然會發生,尤其是當任務數量增加時;第三類方法在凍結舊任務參數的同時,通過添加少量參數來完全避免遺忘。以上這些增量學習方法雖然可以緩解災難性遺忘問題,但是通常存在三個缺點:性能較差,開銷較大,以及設計復雜。為了解決上述問題,本文提出了一個有效的并且能夠克服災難性遺忘的增量深度學習方法(incremental structure learning model,ISLM)。
1 增量深度學習算法
圖1顯示了本文實現增量式深度學習模型的方法概述。該方法進行增量學習時主要有兩個流程,首先,根據新任務樣本借助注意力機制對模型通道進行區分,然后根據區分的結果進行增量訓練。模型通道的區分過程如圖1(①③④)所示,首先,在空神經網絡結構中插入注意力模塊;其次,訓練插入注意力模塊的空網絡,得到可以度量通道重要性的統計量;再次,挑選一定比例的重要通道作為新任務下的共享通道,未挑選的通道作為新任務的輔助通道;最后,挑選的新共享通道與舊模型的共享通道進行交操作,相同的通道作為當前模型下的共享通道,其余通道作為當前模型下的輔助通道。區分結束后,模型根據區分結果進行增量學習,增量訓練過程如圖1(②⑤)所示。本文在共享通道上對所有任務使用一組參數,每次訓練新任務時以微調的方式更新參數,并且在輔助通道上保持舊任務參數。此外,ISLM還會為特定任務在輔助通道上并行添加濾波器來提高識別精度。
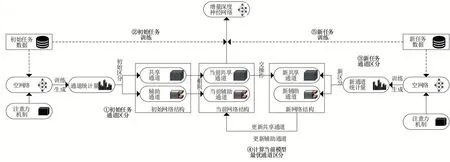
圖1 ISLM方法概述
2 算法實現
2.1 模型通道區分
注意力機制最初被應用在機器翻譯領域,它能夠在大量信息中迅速找到所關注的重點區域并忽略不相關的部分。由于其出色的性能,注意力機制被越來越多的研究人員應用在計算機視覺領域。在計算機視覺領域中,其通過輸入特征圖來生成通道權重,從而在對重要特征信息進行增強的同時抑制非重要信息表達。
目前根據區分標準的不同,注意力可以分為以下三類:空間注意力,通道注意力以及混合注意力。其中,與空間注意力考慮使用空間域信息來生成權重參數不同的是,通道注意力主要關注通道域信息。然而,無論是根據空間域還是通道域信息產生權重的方式,均會忽略部分信息。因此,研究人員提出混合注意力,其通過綜合考慮空間和通道域信息,更為準確地分辨特征圖中重要與非重要通道。與此同時,ISLM方法需要極其精確地分辨出模型的共享通道、輔助通道,以達成在共享通道上訓練新任務,輔助通道上保持舊任務的設計目標,因此本文將混合注意力機制引入ISLM作用于通道選擇,保障模型性能。

通道區分算法


為空模型插入注意力模塊


2.2 模型增量訓練




其中,R是參數的正則化因子,本文在優化參數模型時,采用范數對W進行正則化,其中ε≥0。通過這種方式,使得參數總數存在上界,從而避免退化的情況,并且本文在共享通道上以微調的方式訓練新任務,在輔助通道上保持舊任務參數不變,來最大程度避免改變損失函數。
在此基礎上,本文在輔助通道上采用固定任務參數并且為特定任務添加濾波器的方式,進一步提高模型緩解災難性遺忘的能力以及模型性能。假設模型( )·;W中每個卷積層為φ,設F∈R是該層的一組濾波器,其中C是輸出特征的數量,C是輸入的數量,×是卷積核大小,那么F中濾波器的值為:

此外,如果任務精度較差,本文把f∈R濾波器并行添加到對應任務的濾波器上。在進行增量訓練時,權重保持不變,同時學習f參數。那么,每個卷積層的輸出()將變為(;)。

2.3 通道剪枝
由于ISLM是通過添加濾波器的方式來提高緩解災難性遺忘的能力,會增加額外的參數。因此,為了驗證ISLM方法的有效性,本文對模型進行了基于范數的通道剪枝,使得ISLM精度近似達到3.3節中Baseline精度,進而比較模型大小以體現ISLM方法的優勢。相比于其他壓縮方法,基于范數的通道剪枝會避免模型權重稀疏,并且范數具備計算簡單,操作性強的優勢,所以本文采用基于范數的通道剪枝對增量深度模型進行網絡壓縮。它可以表示為:

其中,二進制掩碼中的每一項表示對應的輸出通道是否需要修剪,并且是保存下來的輸出通道的數量。參數用來控制中非零值的數量,越大,中的非零值就越少。
3 實驗
3.1 實驗設置
本實驗中,采用的是PyTorch 1.1.0深度學習框架,開發語言為Python 3.6.9,訓練和推理平臺均為GeForce RTX 2080Ti。采用的數據集包含ImageNet、Omniglot、CIFAR-10和CIFAR-100數據集,它們是圖像分類任務中常用的經典數據集。特別的是,我們在3.3節的實驗中將CIFAR-100數據集拆分為20個任務,每個任務分為5個類,用來模擬增量學習環境。網絡模型選用的是VGG16、ResNet50兩種典型的網絡結構。
3.2 注意力模塊評估
在本節中,我們先后通過實驗探索了注意力機制對ISLM模型結構的影響。然后,通過對比實驗尋找最優ISLM模型最佳注意力模塊。接下來,將詳細介紹實驗結果并進行分析。
本文對引用注意力機制和未引用注意力機制的ISLM模型進行對比實驗,分別以10%、30%、50%、70%、90%共享通道比例來比較注意力模塊的影響。值得注意的是,我們引入目前流行的注意力模塊SCA作為實驗比較對象。實驗結果如表1所示。其中,Baseline表示網絡模型訓練CIFAR-10識別精度。實驗結果表明,不論是基于VGG16的ISLM增量模型,還是基于ResNet50的ISLM增量模型,在引入注意力模塊后,ISLM增量模型對CIFAR-10的識別精度都有所提升,并且基于ResNet50的ISLM增量模型以70%共享通道比例區分通道時精度提升最大,提高了0.94%,而基于VGG16的ISLM增量模型以50%共享通道比例區分通道時精度提升最大,提高了0.62%。

表1 基于CIFAR-10數據集的ISLM模型對比
此外,為了驗證注意力機制對ISLM模型結構通道區分有效,我們使用基于VGG16的ISLM模型分別順序訓練ImageNet、CIFAR-100數據集和ImageNet、Omniglot數據集。圖2(a)和圖2(b)分別顯示了不同任務上ISLM模型上的注意力權重。如圖2(a)所示,當這兩個任務相似時(ImageNet和CIFAR-100都由自然圖像組成),這兩個任務的重要通道大部分相同;當使用兩個截然不同的任務時(ImageNet和Omniglot),如圖2(b)所示,這兩個任務的重要通道相差很大,導致大部分通道區分為輔助通道。上述實驗結果表明,注意力機制能夠區分出有效的通道。

圖2 不同數據集生成的注意力權重
最后,本文對比了幾種目前流行的注意力模塊在ISLM增量模型上的性能,它們分別是SCA、CBAM、SGE、DMSA和EPSA注意力模塊。在本次實驗中,本文挑選75%重要通道作為共享通道,剩余通道為輔助通道。其中,Baseline表示網絡模型順序訓練CIFAR-10識別精度,實驗結果如表2所示。通過分析實驗結果,我們可以得到以下結論:首先,引入注意力模塊后的ISLM模型在精度上都有提升;其次,SCA模塊和DMSA模塊不論是對基于VGG16的ISLM增量模型,還是對基于ResNet50的ISLM增量模型,都有優秀的性能。其中SCA模塊在VGG16上精度提高1.39%,在ResNet50上精度提高了0.84%;DMSA模塊在VGG16上精度提高1.45%,在ResNet50上精度提高了1.03%。但是相比較SCA,DMSA參數量更多,并且設計方法也比SCA更加復雜。所以,本文選擇SCA模塊作為區分ISLM模型共享通道的注意力模塊。

表2 基于CIFAR-10數據集的不同注意力模塊性能比較
3.3 增量訓練評估實驗
為了評估插入ISLM模型的最優區分通道比例,本文以基于VGG16的ISLM模型為例,在拆分的CIFAR-100數據集上進行實驗,比較了19組不同比例的ISLM模型。得到順序訓練20個任務的平均精度如圖3所示。
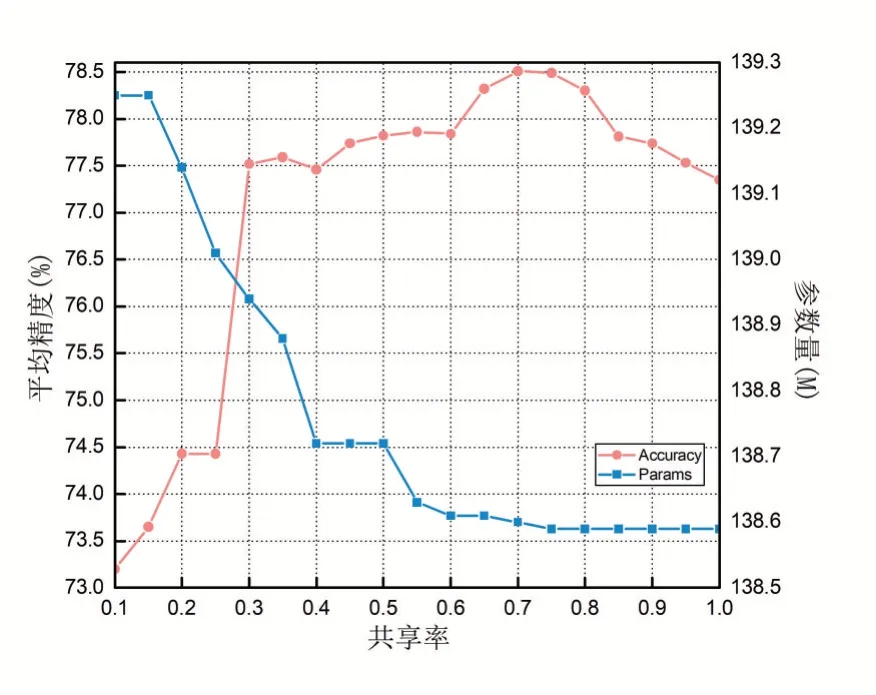
圖3 不同通道劃分對ISLM模型性能影響
從實驗結果可以得出以下結論:共享率會影響ISLM增量模型的性能。例如,當共享率為70%時,增量模型精度達到最高值,為78.51%,并且此時的模型結構所帶來的參數量也較少;如果共享率太低,ISLM增量模型會為每個未達到目標精度的任務增添濾波器,這樣會導致模型過擬合并且參數量也會增多;如果共享率太高,ISLM增量模型就會退化成普通的微調增量模型,緩解災難性遺忘不顯著。以上實驗結果全都表明了合適的共享率會提高ISLM增量模型性能,并且ISLM增量模型以70%通道區分比例在CIFAR-100數據集上有著最優的性能。因此,本文在接下來的實驗中都挑選70%重要通道來區分共享通道與輔助通道。
最后,本文分別將基于VGG16和基于ResNet50的ISLM模型與目前最為流行的增量深度模型,包括EWC,CPG,HAT進行比較,它們都是增量深度模型領域具有代表性的工作。為了減少訓練時間,本文只對前十個任務的實驗結果進行對比。需要注意的是,在本次實驗中,我們把單獨訓練每個任務生成的模型作為Baseline。實驗結果如圖4和表3所示。

表3 不同深度增量模型平均精度及參數量

圖4 基于CIFAR-100數據集的不同深度增量模型性能對比
對實驗結果進行分析得到以下結論:首先,本文提出的方法和目前流行的增量學習方法都有不錯的緩解災難性遺忘的能力;其次,ISLM模型在CIFAR-100數據集識別的平均精度分別達到了76.20%和76.14%,提高了1.87%和0.27%。此外,為了驗證剪枝后的ISLM模型仍然具有較好性能,本文進一步對訓練后的ISLM模型進行通道剪枝,實驗結果如表4所示。當基于VGG16的ISLM模型剪枝率為0.6時,ISLM精度達到Baseline精度,并且與Baseline模型相比其模型大小減少了47%;當基于ResNet50的ISLM模型剪枝率為0.4時,模型精度達到Baseline精度,模型大小比Baseline模型減少21%。以上實驗結果說明,基于VGG16的ISLM模型要優于其他流行的增量學習方法。

表4 不同剪枝率下ISML模型平均精度及參數量
4 結語
在這項工作中,本文提出了一種新的增量學習方法ISLM,用于克服DNN連續學習中的災難性遺忘問題。ISLM方法的核心思想是根據注意力模塊提供的注意力統計信息把模型通道區分為共享通道和輔助通道,本文使用共享通道以微調的方式訓練增量任務,而當無法滿足任務精度需求時在輔助通道上為其添加特定濾波器以提升性能,與此同時,舊任務的輔助通道參數保持不變。本文在拆分的CIFAR-100數據集上進行DNN的持續學習,ISLM不僅能夠正確區分模型通道,而且利用通道共享和為特定任務添加濾波器的方法可以有效避免災難性遺忘,優于其他主流增量學習方法。在未來工作中,我們計劃將ISLM與其他模型優化方法(如模型量化等)相結合,以進一步提升其性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
