404 Not Found
404 Not Found
基于相似性指數聚類的風電功率預測方法研究
師洪濤,張智峰,丁茂生,2,潘俊濤
(1. 北方民族大學電氣信息工程學院,寧夏銀川750021;2. 寧夏電力有限公司,寧夏銀川750001)
1 引言
風能得到了廣泛的開發利用,但是風的隨機性、間歇性等特點造成風力發電的不穩定,大量的風電并入電網,會對系統產生沖擊[1]。風電功率預測技術是解決這一問題的有效方法之一,通過提前對風力發電功率的預測,用于電力部門制定調度計劃,從而提高風能的利用率,減小并網的沖擊影響。
風電功率預測方法可大致分為兩類:一是物理方法,通過對風電場周圍的環境參數的采集,將其代入至風機曲線中,從而得到風電場的發電功率,但是此方法需要的參數較多[2];二是統計方法,根據風電場記錄的天氣預報數據和功率數據,將它們之間的非線性關系表示出來,建立對應的模型,采用天氣預報等因素,對預測模型進行訓練與預測。目前采用統計方法的預測模型較多,常用預測算法有神經網絡[3]、支持向量機[4]、多種方法組合預測[5]等。
風電場記錄保存的數據龐大復雜,很難直接從中直接得出天氣因素與風電功率之間的關系,因此需要對數據做預處理,以提取數據中隱含的特性。聚類方法將具有相似特性的數據放在一起,數據之間的關聯性強,從而容易提取數據中的特性信息,常用的聚類方法有k-means聚類[6]、模糊C均值聚類[7]、密度峰值聚類[8]等。
目前用聚類方法處理風電功率數據,一般可分為三類:一是將功率數值相近的數據歸為一類,建立對應的預測模型進行訓練,但在實際數據中存在天氣數據差異較大、功率值相近的情況,會影響模型的預測精度[9];二是利用天氣因素對風電功率數據進行聚類,如根據風速對風電數據進行一次聚類,在此基礎上,再對每一個樣本子集利用風向做二次聚類,這樣忽視了功率點在整體上所處的功率段變化趨勢[10];三是對天氣數據和功率數據分別進行聚類,再將聚類出的子集進行組合,這樣做雖然能夠提高預測精度,但是增加了需要建立模型的數量,數據處理的過程更加復雜,需要較長的時間[11]。
歐氏距離是常用來計算數據之間距離的一種方式,其計算過程簡單,物理意義明確。但是采用歐式距離作為樣本點劃分的依據,只表示出樣本點與聚類中心的關系,沒有將數據所包含的整體性表達出來。針對上述問題,本文提出使用指數相似系數法對模糊C均值聚類中的歐式距離進行改進,通過計算每個點與聚類中心在樣本整體離散情況的相似變化程度,將數據點所處的天氣變化程度和功率段趨勢同時提取出來,得到的樣本子集包含更多數據點在原來樣本整體上的信息,再對此進行分類建模,建立不同的BP神經網絡模型進行訓練。
2 風電數據特征提取方法
2.1 傳統風電預測中的聚類方法
以往對風電功率數據使用聚類算法進行預處理時,常用樣本數據中的功率或幾個天氣因素,以此對風電數據進行分類,這樣雖然可以進行一定的聚類劃分,但忽視了各天氣因素是整體對風電功率起作用,單一利用某一特征對記錄的整個風電功率數據進行劃分,是不合理的。風電功率預測框架圖如圖1所示。

圖1 風電功率預測框架圖
從圖1可以看出,常用的風電影響因素中仍能挖掘出一些隱藏的特性數據,在聚類時如果能考慮到這些特性,就會使得樣本子集更加緊致,但實際中很少被用到,這一點還需改善。
另外,大多數聚類算法采用歐氏距離度量數據點之間的關系,通過計算樣本點與聚類中心之間的距離,將距離相近的樣本點劃分到一類中,具體的計算公式為(1)式

(1)
式中,dij表示第i個樣本點xi到第j個聚類中心oj之間的距離;xik和ojk分別表示樣本點xi和聚類中心oj的第k個特征數據。
但是,歐式距離只是將樣本點與聚類中心當作兩個孤立的點,注重兩點之間的距離。然而,風電場所在地區的天氣和功率數據是連續變化的,使用歐式距離作為判據,在聚類過程中,無法對數據中趨勢特性進行有效提取,最終影響聚類出的樣本子集內部的緊致性。圖2為使用歐式距離聚類出的樣本子集散點圖。
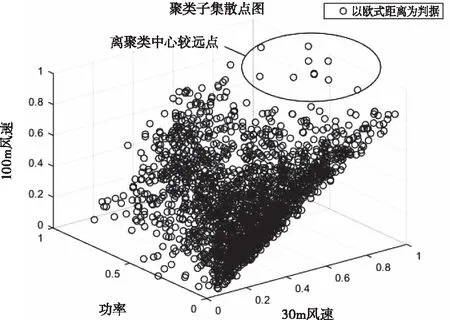
圖2 聚類子集散點圖
從圖2可以看出,雖然使用歐氏距離聚類出的大部分樣本點聚集在一起,但仍有少部分點遠離原來的聚類中心,影響到聚類子集的緊致性。因此,應該選取一種能對樣本數據整體進行更好衡量的方法。
2.2 趨勢特性數據特性提取原理
風電功率變化是多種天氣因素共同作用的結果,當前時刻的天氣和風電功率較前一時刻的數據不完全相同的,且各天氣因素對風電功率的作用不同,各天氣因素的變化程度和功率段趨勢可通過下列公式計算得到:
ΔXI=XIt-XI(t-Δt),I=1,2,…,d
(2)
上述公式,通過不斷變化I計算風電數據中的風速、風向、溫度、壓強、功率等特征數據的變化ΔXI,XIt為當前時刻的風電功率數據,XI(t-Δt)為前一時刻的風電功率數據,d為記錄的風電場數據的特征維數,Δt為采樣的時間間隔。
風電功率頻繁變化時,會影響風力發電并入電網的穩定性,也會導致預測模型預測精度降低[12]。因此,通過式(2)計算出各種天氣變化和功率段變化趨勢,再利用指數相似系數法,對風電中的隱藏特性數據進行有效提取,以下將對提取的方法進行詳述。
3 基于相似性指數聚類的預測模型構建
3.1 基于相似性指數的多維數據距離度量方法
模糊C均值聚類算法(fuzzy c-means algorithm,FCM)是一種經典的用于提取具有相似特性的聚類方法[13-15]。為了對風電數據中包含的天氣變化程度和功率趨勢進行有效提取,而且不增加聚類算法的復雜度,本文提出使用指數相似系數法對FCM中的歐式距離進行改進。
指數相似系數法是一種常見的用于模糊聚類的判據[16],其具體的計算公式為式(3):
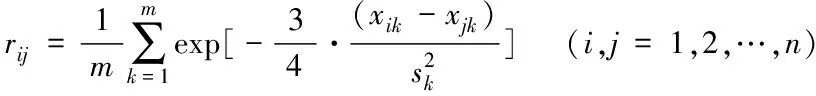
(3)
式中,xik為樣本中第i個樣本數據的第k維特征值,xjk為樣本中第j個樣本數據的第k維特征值。使用(3)式進行聚類時,需計算出每個樣本點與所有點的指數相似系數,計算量較大,且具體將數據劃分為幾類,還需確定閾值。
考慮到要對樣本點與聚類中心之間多維度數據進行衡量,且聚類中心影響到聚類的效果。因此,基于指數相似系數法,將距離判定公式改進為(4)式
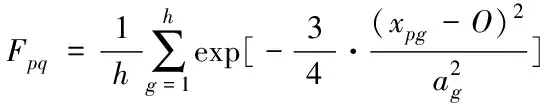
(4)
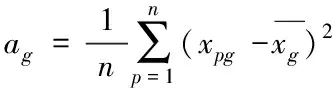

改進后的(4)式,只需要計算樣本點與聚類中心的指數相似系數,減小了計算量。同時,聚類中心O的個數的確定,省去了原本模糊聚類中閾值設定的步驟。
另外,與使用歐式距離作為判據相比,聚類出的樣本子集能最大程度上保留原有的特性,同時不會增加所需要建立預測模型輸入的維度,幫助模型更好地學習數據中隱藏的關系,從而提高風電功率的預測精度。
3.2 功率與氣象數據的相關性聚類流程
為了找尋功率與氣象數據的關系,根據天氣變化程度對風電功率造成的不同影響,利用3.1中的新判據對FCM算法進行相應的更新,將具有相似變化的風電數據聚在一起。
使用新判據后進行更新迭代的隸屬度矩陣,如表1所示。

表1 隸屬度矩陣表
表中,uqp表示的是樣本點xp對于聚類中心oq的隸屬度。
改進FCM聚類算法的流程圖如圖3所示。圖中虛線部分為對算法進行改進的部分,分別是利用指數相似系數法計算各天氣因素變化值、功率段變化值、計算綜合天氣變化和功率變化值,最終得到所需的各樣本點與聚類中心的離散相似變化矩陣。
3.3 多神經網絡模型的構建
使用指數相似系數完成對FCM的相關改進后,對每個樣本子集建立相應的風電預測模型。如圖4所示。
從圖中可看出建立多神經網絡預測模型的步驟如下所示:
1)對樣本數據使用改進后的FCM進行處理,得到聚類出的各樣本子集;
2)對每個樣本子集分別建立相應的BP神經網絡模型進行訓練,調整好模型內部的參數;
3)再有新的數據進入時,根據數據對應的類別,送入訓練好的神經網絡模型中進行預測;
4)預測結果按照分類前相應的時間順序進行排列,得到預測時間段的風電功率曲線。
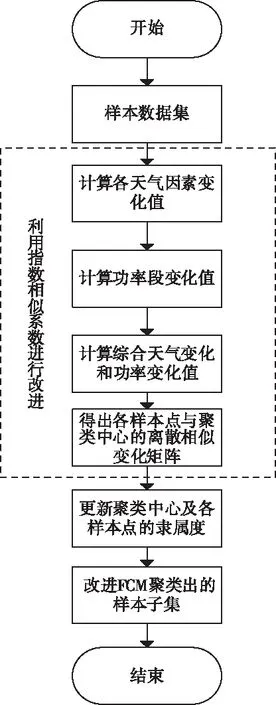
圖3 改進FCM算法聚類流程圖
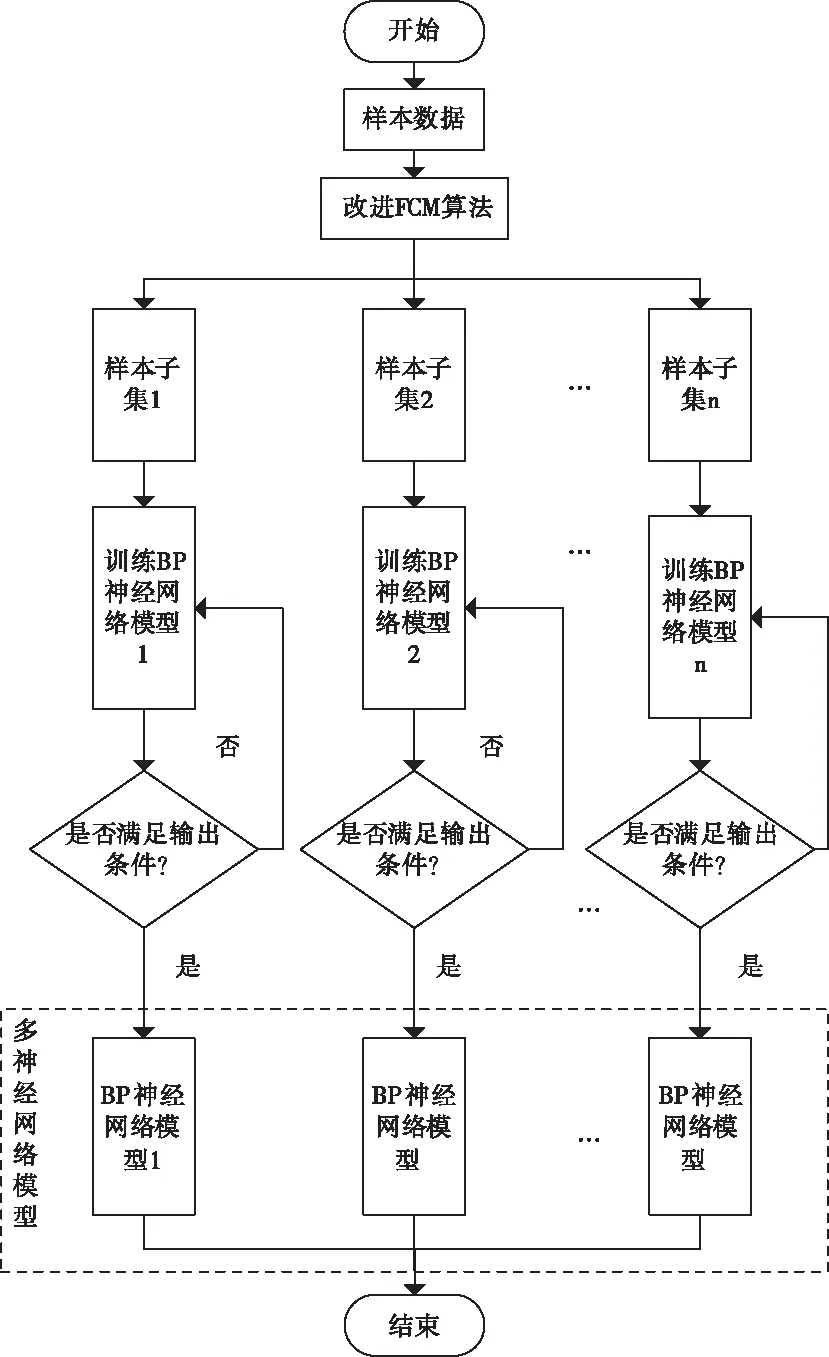
圖4 多神經網絡模型框架圖
4 實驗驗證
采用風電數據進行驗證,對數據先進行歸一化操作,采樣的時間間隔為1h,進行短期風電功率預測。選擇30m風速、100m風速、100m風向、溫度、壓強和風電功率數據共同組成樣本數據,分別使用改進后FCM和FCM進行聚類,具體步驟如3.2節所示,樣本數據被聚為3類。使用CH(+)和FS(-)[18]兩個指標對兩種算法聚類結果的有效性進行評判,結果如表2所示。

表2 兩種聚類算法聚類有效性表
由表2可知,以指數相似系數為判據的FCM聚類算法得到的樣本子集的緊致性要優于使用歐式距離作為判據的FCM。將兩種聚類算法得到的不同樣本子集按照3.3節中的步驟分別建立對應的多神經網絡模型進行訓練,再建立一個BP神經網絡模型直接進行預測,將三種不同方法的預測結果進行對比。預測的結果如圖5所示。
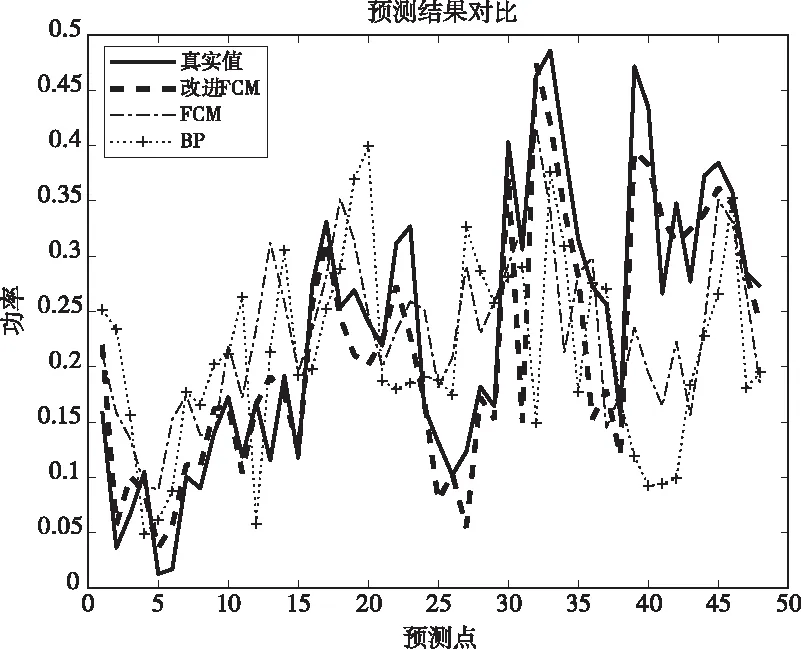
圖5 不同方法的預測結果對比圖
不同方法對應的誤差分析圖如圖6所示。
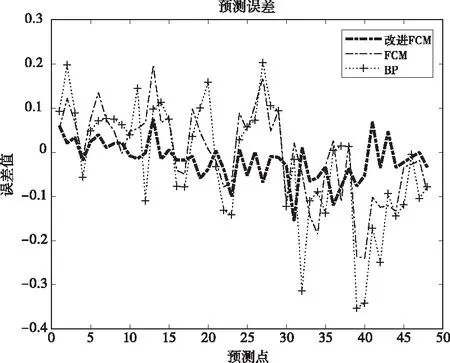
圖6 不同方法的預測誤差對比圖
結合圖5和圖6,可以看出使用指數相似系數作為判據的FCM的預測圖像與使用歐氏距離作為判據的FCM、直接使用BP神經網絡相比,擬合效果更好。
采用平均絕對誤差(Mean Absolute Error,MAE)和均方根誤差(Root Mean Squared Error,RMSE)進行結果評比,結果如表3所示。
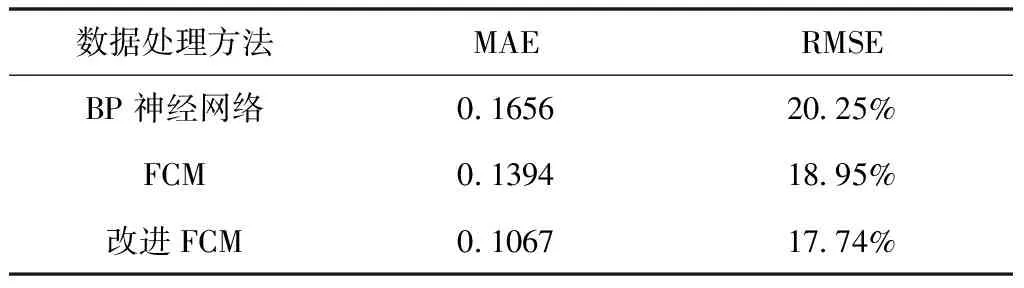
表3 不同方法的預測結果對比
從表3分析可知,使用聚類算法進行數據處理能夠提高預測模型的預測精度,改進后的FCM與其它兩種方法相比平均絕對誤差分別降低了0.0589和0.0327,均方根誤差分別降低了2.51%和1.21%,預測精度要優于其它兩種方法。
5 結論
本文提出一種基于相似性指數聚類的風電功率預測方法,算例驗證表明采用指數相似系數法對FCM中的歐式距離進行改進后,能夠在聚類時考慮到樣本點所在位置的氣象因素變化程度和功率段趨勢的關聯性,進而聚類出的樣本子集包含更多數據特征,且風電樣本子集中的數據點更加緊湊;結合分類建模思想,建立多神經網絡預測模型,與傳統方法相比,風電預測精度有所提高,證明了所提方法的有效性;同時,該聚類方法對樣本點隸屬度的更新迭代計算量較大,對此可做進一步優化,以提升算法的性能。
