基于時間序列的微博謠言檢測*
2022-09-28 01:40:30韓連金潘偉民張海軍
計算機與數字工程 2022年8期
韓連金 潘偉民 張海軍
(新疆師范大學計算機科學技術學院 烏魯木齊 830054)
1 引言
微博是幫助人們發布、傳播和共享信息的開放式社交媒體平臺。憑借文本簡短及使用便捷等特點,吸引了大量用戶,改變了社會的信息傳播格局。作為開放的公共信息平臺,微博的低門檻造就了謠言產生的低成本,導致其不可避免地被注入大量謠言[1],而這些謠言的傳播會對用戶使用、平臺發展和國家穩定造成不良影響[2]。因此,研究如何快速有效地檢測微博中的謠言具有重要的現實意義。
微博事件是由源微博及其相關的微博、轉發和評論一起組成,是典型的時間序列數據,包含豐富的上下文信息[3]。對于龐大的時間序列數據,可以將一個較長的時間序列劃分為幾個相對較短的子序列[4]。分割后的時間序列數據進行了一定的壓縮,模型復雜度會降低,有利于計算[5]。針對分割后時間序列的數據挖掘,同樣符合數據變化的模式和規律[6]。因此,本文針對時間序列劃分方法進行研究,提出基于聚類的微博事件劃分方法。根據微博在時間上的聚合程度,針對時間戳進行聚類,將微博事件分割成若干時間段,構建時間序列。同時,基于GRU 網絡構建事件分類模型,自動捕捉微博事件特征隨時間變化的情況,對謠言事件進行檢測。實驗結果表明,本文提出的基于時間序列的微博謠言檢測方法可以有效檢測謠言事件。
2 相關工作
早期謠言檢測普遍采用基于機器學習的方法,其核心技術包括特征提取和訓練分類器。Castillo等[7]提取基于文本、用戶信息、話題和消息傳播的特征,利用J48 決策樹進行檢測,準確率達到86%;Yang等[8]從微博中提取基于內容、賬號、傳播、客戶端和位置的特征,在基于SVM 構建的檢測模型上獲得了5%左右的性能提升;毛二松等[9]開始考慮情感傾向性和意見領袖傳播影響力等深層特征。此外,也有研究通過構建時間序列獲得更高的謠言檢測性能。Kwon 等[10]引入時間序列擬合模型來捕獲傳播過程中特征隨時間變化的情況,根據選擇的特征對謠言進行分類,召回率在87%到92%之間;Ma 等[11]在Kwon 等[10]的基礎上使用動態時間序列擴展了時間序列擬合模型;王志宏等[12]引入域劃分的思想,通過構造動態時間序列特征提高謠言檢測準確度。總體上講,基于機器學習的方法初具成效,特征提取開始挖掘深層特征,同時通過構建時間序列提升性能。但該類方法依賴于特征工程,需要耗費大量的人力、物力和時間,并且需要一定的專業背景。
為了解決基于機器學習方法存在的問題,研究者探索出基于深度學習的方法,自動學習數據中包含的特征。Ma等[13]首次使用深度學習進行謠言檢測,利用tf-idf得到時間段向量表示,然后訓練循環神經網絡自動學習微博特征,在雙層GRU 網絡上獲得91%的準確率;Yu 等[14]利用doc2vec 獲取時間段向量表示,采用卷積神經網絡自動學習微博特征,在評價指標上優于支持向量機等對比方法;Chen 等[15]將微博按固定數量分成時間段,通過注意力機制選擇性地學習時間序列內的特征用于謠言檢測。基于深度學習的方法可以自動學習特征,取得了較好的檢測效果。同時,由于事件之間的微博發帖數量存在很大的差異,每個神經元不可能只處理一條微博。因此,出現了基于等長時間間隔(TETS)[13]和基于固定帖子數(PETS)[15]的微博事件時間序列構建方法。其中,TETS 方法可以保證模型具有合適的輸入序列,而PETS 方法可以使每個時間段有合理的數量[16]。上述方法雖然都考慮了要合理劃分時間序列,但是時間長度固定會導致時間序列內帖子數量不合理,出現帖子數量過多或過少的問題;固定帖子數劃分出的時間序列又不能保證模型得到合適的輸入序列。在這種情況下,本文考慮事件在時間維度上的分布,提出基于聚類的微博事件劃分方法,構建合理的時間序列作為模型輸入,訓練GRU 網絡自動學習特征,對謠言事件進行檢測。
3 本文模型介紹
謠言事件檢測可以看作是二分類問題,對給定的微博事件集合E={Ei},本文任務就是檢測事件Ei是不是謠言。其中,Ei={pij} 包括源微博及其相關的微博、轉發和評論,pij表示事件的某一條文本。在本文提出的基于時間序列的謠言檢測模型中,首先對數據進行預處理,其中包括去噪、去停留詞和分詞;然后基于k-mean 算法針對時間戳進行聚類,實現對微博事件的分割,構建時間序列;最后將時間序列使用doc2vec 進行向量化作為GRU 網絡的輸入,并進行參數調優,返回謠言和非謠言這兩個類別的概率。具體結構如圖1 所示。

圖1 謠言檢測模型結構
3.1 時間序列構建
本文提出基于聚類的微博事件劃分方法,首先將源微博作為時間序列的第一個時間段,之后基于k-mean 算法根據每條微博的時間戳進行聚類,將微博事件劃分成若干時間段,將所有的時間段按時間順序組成時間序列。描述如下:對于每一個事件Ei={(Pij,tij)},Pij表示事件相關的微博,tij是對應微博的時間戳。設置k-mean 的聚類數目為K,即將事件劃分為K 個時間段。基于聚類的微博事件劃分方法偽代碼如算法1所示。
算法1:基于聚類的微博事件劃分算法


3.2 GRU網絡
循環神經網絡是處理序列數據的常用神經網絡,在許多自然語言處理任務中取得了良好的效果。其中GRU網絡對謠言事件的檢測效果較好[13],可以學習語法特征和語義特征。因此,本文采用GRU 網絡進行特征學習,其包括四個部分的計算,結構如圖2所示。

圖2 GRU單元結構
首先是重置門。GRU 使用重置門選擇前一時刻要放棄的信息,其中Wz和Uz為權重,ht-1為前一時刻的輸出值,bz為偏置:

接下來是更新門。GRU 通過更新門選擇有多少信息需要保存并更新當前時刻,其中Wr、Ur為權重,ht-1為前一時刻的輸出值,br為偏置:

然后GRU 決定如何合并之前的信息和新的輸入,這是計算當前輸出的一個重要步驟,其中Wa和Ua為權重,ba為偏差:

最后,GRU根據以上結果計算輸出:
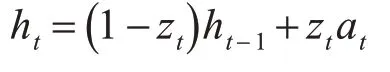
隨后將GRU 網絡輸出的特征矩陣傳入由神經元和Softmax 激活函數構成的全連接層,進行Softmax操作計算謠言和非謠言這兩個類別的概率。
4 實驗及結果分析
本文采用Ma 等[13]公開的用于謠言檢測的數據集,包含4664 個事件及事件對應的標簽,其中包含謠言事件2313 件和非謠言事件2351 件,微博總數3752459條,表1為實驗數據集統計表。同時,在謠言檢測任務中使用準確率、精確率、召回率和F1值做為評價指標。

表1 實驗數據集統計表
4.1 驗證時間序列劃分方法
本文首先對提出的劃分方法所構建時間序列的合理性進行驗證,實驗結果如圖3 所示。同時為了驗證基于聚類劃分方法的有效性,本文和基于等長時間間隔(TETS)及基于固定帖子數(PETS)的時間序列劃分方法做對照實驗,實驗結果如圖4 所示。
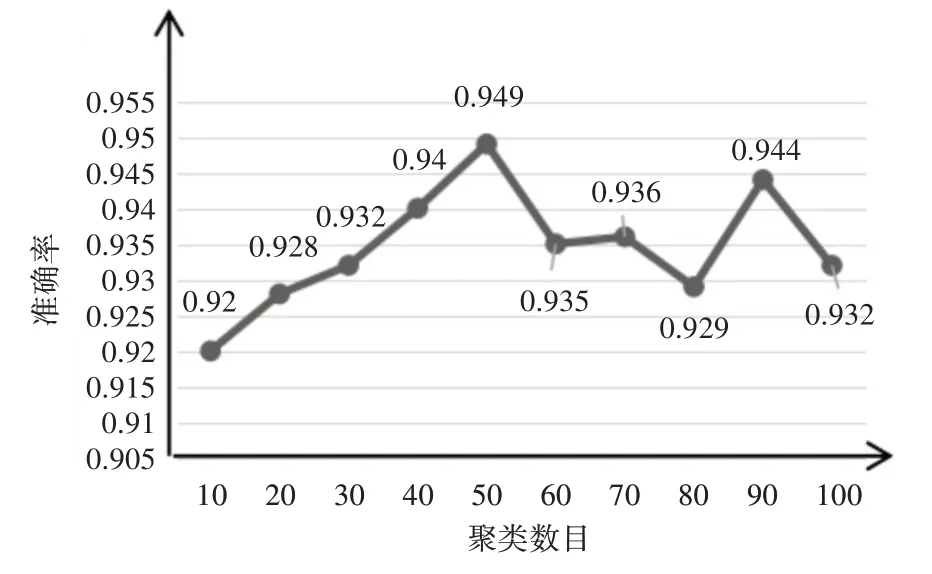
圖3 不同聚類數目的檢測結果

圖4 不同劃分方法的檢測結果
通過圖3 可以看出,在構建謠言事件時間序列的過程中,合理的時間序列劃分能夠影響謠言檢測任務的性能。其中,聚類數目在50 和90 時獲得了94%的準確率,時間序列劃分能反映事件在時間上的聚合程度。上述實驗結果表明,構建時間序列應該考慮事件在時間上的分布特點,合理的事件劃分得到的時間序列應該跟數據在時間上的分布有關。
圖4 實驗結果表明,PETS 對謠言檢測的性能提升最少,在準確率上與TETS 相差3.4%。由表1可以看出,事件平均時長是2460.7h。因此,固定的時間間隔劃分可以得到合適的輸入序列,取得優于PEST 的性能。由表1 還可以看出事件最大帖數為59318 而最小帖數只有10,事件發帖數在時間維度上分布是不均勻的,所以固定的時間長度會導致時間序列內部分時間段的帖子數過多或過少。相反,基于聚類的方法根據設定聚類數目保證了合適的輸入序列,同時k-mean算法利用時間戳進行聚類,根據時間上的聚合程度,保證了每個時間段具有合理的帖數。與這兩種方法相比在準確率、精確度、召回率和F1 值上都取得了更好的結果,能提高謠言檢測性能。
4.2 驗證基于時間序列的謠言檢測模型
為了驗證基于時間序列的謠言檢測模型的有效性,本文將與選取的基準方法在相同的數據集上開展實驗,實驗結果如表2所示,以下為4個選取的基準方法。

表2 不同模型的檢測結果
1)DTC 模型[7]。該模型屬于基于機器學習的方法,通過特征工程提取特征,并采用J48 決策樹進行分類。
2)SVM-TS 模型[11]。該模型通過動態時間序列模型來捕獲微博傳播過程中特征隨時間變化的情況,采用SVM分類器進行分類。
3)GRU-2 模型[13]。該模型先構建時間序列,然后采用tf-idf 計算得到每個時間段的向量表示,最后采用雙層的GRU 網絡來學習微博特征實現對謠言事件的檢測。
4)CAMI模型[14]。該模型先將微博事件劃分為等長的時間段,并利用doc2vec 方法獲取時間段內向量表示,之后利用卷積神經網絡學習微博特征進行事件的分類。
實驗結果表2 表明,基于機器學習方法的DTC模型和SVM-TS 模型實驗結果在評價指標上相對較低。其原因在于通過人工提取特征進行謠言檢測,特征選取主觀性強且無法獲得深層潛在特征及其關系。同時,本文提出的方法和GRU-2 模型使用了相同的網絡結構,對謠言事件的召回率同樣達到95.6%,能很好地學習語義等特征。而在基于聚類的微博事件劃分方法的幫助下準確率能達到96.7%,比利用卷積神經網絡的CAMI 模型高出3.4%。與其他基準方法相比,本文方法的實驗結果在其他評價指標上同樣表現更好,由此驗證了所提方法可以有效地檢測微博中的謠言。
5 結語
本文提出了一種基于時間序列的微博謠言檢測方法,利用基于聚類的微博事件劃分方法,根據微博在時間上的聚合程度將微博事件分割成若干個時間段,構建的時間序列能提高謠言檢測性能。同時,基于GRU 網絡構建謠言檢測模型,捕捉微博事件特征隨時間變化的情況。該方法在對微博數據集的實驗中取得了理想的效果,準確率達到96.7%,為微博謠言檢測提供了新的有效方法。在進一步的研究中計劃對時間序列內每個時間段進行特征提取,獲得更細粒度的特征,進一步提升謠言檢測的效果。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
