基于智能視覺感知的車內孩童監控預警系統*
2022-09-28 01:40:40張雪翔史訓昂郭鵬宇姚廣華
計算機與數字工程 2022年8期
張雪翔 史訓昂 郭鵬宇 姚廣華
(上海工程技術大學機械與汽車工程學院 上海 201620)
1 引言
在現代社會經濟迅猛發展、汽車工業成熟、人民生活水平穩步提高的今天,私家車已經成為大部分公民出行的日常工具。隨著汽車技術的進步和發展,車廂的密封性能越來越好,但這樣的密封性同時也阻礙了車廂內外空氣的流通,使得車廂在車門緊閉時形成相對密閉的空間,導致車廂內二氧化碳濃度升高。當車廂內二氧化碳濃度高于氧氣濃度時不僅會對人體健康造成負面影響,還會造成乘客和司機疲勞、嗜睡和行動反應遲鈍的情況。
在汽車乘員中,有很大一部分是孩童,而孩童的自主能力差,是易受忽視和傷害的群體。當駕駛員離開車時,特別是當孩童熟睡時,駕駛員極有可能忽視或忘記車內還有乘員,而夏天溫度極高,車內溫度會驟升,孩童在密閉的車內很有可能在短時間內因高溫悶熱而窒息死亡。而窒息的最大緣由,在于車內二氧化碳濃度的升高,這就需要在司機離開車后車輛能自動檢測車內是否有孩童的存在,并結合孩童的當前評估狀態和車內二氧化碳濃度,對車主分級報警,并及時做出相關處理,避免悲劇的發生。
本文設計的基于視覺感知的車內智能預警系統主要由以下三部分組成:1)人臉識別模塊:本文在基于Dlib 庫實現人臉面部檢測和關鍵點定位的基礎上,提出采用ResNet 模型和KNN 算法對人臉進行特征提取和分類,從而進一步提高車內滯留孩童面部識別的實時性和精度;2)姿態估計模塊:在車內滯留孩童的姿態估計上,本文考慮到因車內空間狹小而存在的遮擋問題,創新性的提出了一個多尺度監督模型,其模型不僅能有效的推斷出被遮擋的部位,而且能有效提高人體關鍵點定位的精度,間接地為車內滯留兒童的狀態評估(包括熟睡、玩鬧等)提供依據;3)分級預警模型:為了更好地保障車內遺留孩童的生命安全,本文基于人臉識別、姿態估計和CO2濃度檢測建立車內監控分級預警機制,該機制會根據車內的環境惡化程度和滯留孩童的當前狀況選擇相應的預警等級,并及時通知車主或降下車窗進行通風換氣。
2 方法
2.1 人臉識別模塊
在車內疑似滯留孩童的面部識別上,本文設計的人臉識別模塊主要包括人臉檢測、人臉定位,面部特征提取和人臉識別[1]。圖1中顯示了人臉識別的整個網絡框架和訓練所用的數據集,其主要分為三個階段:ResNet訓練,KNN 訓練和KNN 測試。人臉識別的步驟和具體細節如圖1所示。

圖1 人臉識別網絡框架
2.1.1 人臉檢測和定位
在面部關鍵點的定位上,本文依賴于Dlib庫中經過預訓練的面部關鍵點定位檢測器[2],該檢測器會預測出68 個繪制面部輪廓的關鍵點。而在本文中,首先僅使用12 個點來對齊面部圖像,其中6 點代表左眼輪廓,6 點代表右眼輪廓,這樣我們就可以通過6 點的坐標得到眼中心的坐標。然后在獲取兩只眼睛的中心坐標(兩只眼睛的中心是面部圖像中旋轉的中心)之后,并通過旋轉,縮放和平移對人臉圖像進行歸一化處理,從而實現人臉關鍵點定位[3]。圖2 展示了人臉歸一化處理步驟,其是將具有傾斜角度的人臉原始面轉換為沒有傾斜角的對齊面。

圖2 人臉歸一化處理
2.1.2 面部特征提取
本文主要是基于ResNet[4]深度神經網絡架構來提取人臉面部特征。由于ResNet 在物體實例分類,檢測和分割方面的出色表現和其模型易于訓練的特點,它在ILSVRC(ImageNet大規模視覺識別競賽)和COCO-2015 競賽中獲得了第一名。在本文中,我們使用3 層ResNet 網絡架構,一層內含有兩個卷積層,如圖3 所示。ResNet 網絡的輸入是歸一化處理后的人臉圖像和其相對應的標簽,然后通過預訓練好的ResNet 來提取人臉面部特征,其中中間層和L2 歸一化層的輸出都是人臉面部的特征向量。最后將所獲的面部特征向量(也稱為嵌入)作為KNN分類模型的輸入。

圖3 3層ResNet網絡架構
2.1.3 人臉識別
針對于人臉數據集很大的場景,考慮到識別算法的實時性和對噪聲的魯棒性,我們選擇K最近鄰分類算法(KNN)去計算要分類的對象與數據集中每個對象之間的歐式距離。在數據集訓練之前,首先定義K 的值,然后從數據集中選取要分類對象的K 個鄰居。每個鄰居都有一票,該對象的鄰居的多數票決定了該對象的分類屬性。在本文中,我們將ResNet 嵌入層的輸出用作KNN 分類模型的輸入。在此步驟中,將使用來自其他數據集標注好的人臉圖像來訓練分類模型。在人臉識別模型的測試驗證中,將測試人臉未標記圖像,從而驗證模型識別分類的精度和實時性。
2.2 姿態估計模塊
為了更好地對車內孩童的當前狀態進行評估,我們還需對車內孩童的姿態進行估計,從而實現預警等級的有效劃分,并及時做出相應的處理。本文考慮了車內姿態估計時存在的遮擋問題,為了有效消除人體關鍵點在匹配時的歧義,包括左右身體部位的不匹配,并更好地推斷出被遮擋的部位,本文提出了一個多尺度的監督網絡模型,其模型組成部分如圖4所示。
本文提出的孩童姿態估計模型的新穎之處主要在以下兩個方面:1)首先,在基于卷積-反卷積現有姿態估計作品中[5~6],準確的人體關鍵點的對應關系很大程度上取決于多尺度匹配的一致性,針對此我們將中間監督擴展為在訓練期間明確覆蓋反卷積層的多級監督,這大大提高了在不同尺度上提取更一致且更具代表性特征的能力;2)其次,由于每個人體關鍵點熱圖(對應于關鍵點的位置可能性)是在卷積-反卷積步驟期間獨立估算的,因此各個關鍵點之間的結構關系未在卷積-反卷積模塊中建模。為此,我們最后使用全局關鍵點回歸網絡在熱圖的頂部對關鍵點之間的關系進行建模。在不同場景下,這種回歸網絡結構能有效提高全局姿態估計中身體結構的一致性。
作者簡介:林舒虹,女,龍崗區機關幼兒園,幼教一級,龍華區優秀教師,甘露名園長工作室學員,本科學歷,研究方向:學前教育。
2.2.1 多尺度監督
我們建議在各個反卷積層中強制執行多個監督步驟(如圖4 所示),以通過學習更豐富的多尺度特征,來實現更好的人體關鍵點定位。隨著卷積-反卷積塊堆疊深度的增加,梯度消失將成為訓練過程中的關鍵問題。為了解決模型訓練期間梯度消失的問題,我們在兩個卷積-反卷積塊間增加中間監督層[7](圖4 中的淺色層),其可以在某種程度上有效解決梯度消失的問題。

圖4 多尺度監督網絡模型
雖然多尺度監督方法是對原始中間監督的擴展,但是我們提出的多尺度監督的實現方式與以往是不同的。我們的實現方式是通過在圖4 的每個反卷積層上計算與下采樣的人體關鍵點真值熱圖(記為GT/4,GT/2,GT)相關的多尺度殘差[8]來進行的。具體來說,我們通過計算各個尺度上的關鍵點真值熱圖殘差來保持特征圖通道的一致性,并使用1×1卷積核(圖4中的梯形)將高維的反卷積特征圖轉換為人體關鍵點的單獨熱圖。這樣,我們就可以使用均方誤差(MSE)對人體關鍵點的降維特征圖和其相對應尺度的真值進行監督。在此過程中,我們發現提出的多尺度監督方法可以有效提高人體關鍵點熱圖預測(在人體關鍵點上有更集中的分布)的準確性。
本文在描述監督損失時,將l2損失[9]作為人體關鍵點熱圖預測的損失函數。為了提高人體姿態估計的精度,我們采樣了人體的16 個關鍵點(包括頭部,頸部,骨盆,胸部,肩膀,肘部,腕部,膝蓋,腳踝和臀部等相關部位),每個卷積-反卷積塊都會生成N個關鍵點熱圖。在第i個尺度上,人體所有關鍵點預測的熱圖與其真實熱圖之間的Li損失如下所示:

其中Pn(x,y)和Gn(x,y)分別表示第n個人體關鍵點的像素位置坐標(x,y)的預測值和真實值。模型總的損失函數為L=∑iLi,其表示為中間監督損失和多尺度監督損失的組合。
2.2.2 全局關鍵點回歸
在卷積-反卷積塊之后,我們使用一個全卷積回歸網絡[10]來細化人體多尺度關鍵點熱圖,以提高姿態估計時人體結構的一致性。手臂和腿、頭部和軀干之間的相對位置作為有用的先驗知識,其可以從回歸網絡[11]中學習,并與多尺度特征圖相結合來進行人體姿態細化。我們的卷積-反卷積塊首先會根據人體的姿態/活動提取關鍵點熱圖,如圖5(B)所示,然后回歸網絡會將多尺度熱圖作為輸入,并在相應的尺度下匹配真值圖像。通過這種方式,回歸網絡可以有效地監督所有尺度的熱圖,以便進行細化。

圖5 人體關鍵點定位及熱圖提取
具體而言,本文主要是通過多尺度特征[12]和人體關鍵點上的回歸特征圖[13]來細化人體的位姿結構。在結合考慮人體結構先驗的基礎上,該回歸過程可以有效地提高人體關鍵點位置預測的精度。圖5(a)表示人體關鍵點預測,圖5(c)表示人體關鍵點位置的輸出結果,圖5(d)則表示回歸處理后的關鍵點熱圖,從圖5(c)、(d)中我們發現模型不僅使得關鍵點熱圖峰值更加集中,而且也進一步提高了人體姿態估計的精度。
2.3 分級預警模型
在車內智能監控預警模型的建立上,考慮到滯留孩童在車內熟睡時,其CO2的呼出量相比于氧氣增加了一百倍左右[14],如表1 所示,在密閉的車內環境下極易會造成車內人員的窒息,本文利用二氧化碳濃度檢測儀(如圖6 所示)對車內的CO2濃度進行實時監測,當車內存在滯留孩童的情況下,檢測到車內CO2濃度急劇升高時,系統會控制車窗上的步進電機降下車窗,進行通風換氣,其車內智能監控分級預警模型如圖7所示。
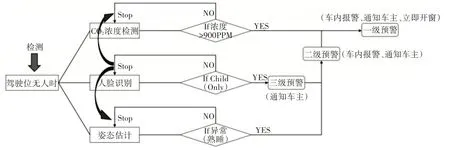
圖7 車內智能監控分級預警模型

表1 空氣及人體呼氣中各氣體含量

圖6 二氧化碳濃度檢測儀
3 實驗評估
3.1 人臉識別實驗
在車內疑似滯留孩童人臉識別模型的訓練上,考慮到算法的實時性和人臉識別精度要求,本文主要是使用LFW 數據集來訓練3 層ResNet 特征提取網絡,該數據集的13233幀圖片中總共有1680個人(包括成年人、孩童和老人);而在人臉識別上,我們將采集并標注好的車內孩童數據集和Chokepoint數據集進行融合,融合之后的數據集共有75 人(成年男性19人,成年女性16人,孩童40人)。
在人臉面部特征提取的實驗中,本文主要是使用Adam 優化算法來訓練ResNet 網絡,并使用學習率為0.001的交叉熵損失函數。本文設計的ResNet網絡中的殘差塊是由兩個卷積層和兩個批量歸一化層組成,在提出的人臉特征提取模型中,我們使用三個殘差塊,相比于兩個或四個殘差塊,其具有最優的性能,如圖8 所示。在人臉數據集訓練的規模上,相比于FaceNet人臉識別模型,其是通過訓練100 萬到200 萬張人臉圖片并將其特征壓縮成128維嵌入向量來區分人臉面部的關鍵特征,而本文模型的訓練數據集規模是很小的。因此,我們通過使用ResNet 網絡將224×224×3 的人臉輸入圖像轉化為256 維嵌入向量來表示面部特征,與128 維嵌入特征向量相比,256 維的嵌入向量具有人臉更加豐富的信息。在實驗中我們發現,當epoch 設置為70 時,模型具有較高的測試精度,當epoch 大于70時,模型的測試精度會下降。圖9和圖10分別展示了ResNet 特征提取模型訓練和測試時隨epoch 大小設置的損失和精度變化。

圖8 ResNet網絡復雜度性能對比

圖9 3層ResNet網絡損失變化
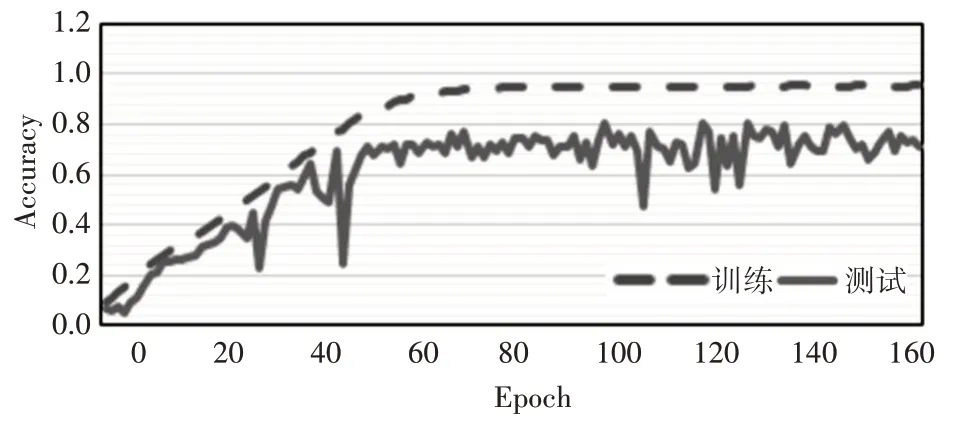
圖10 3層ResNet網絡精度變化
而對于人臉面部識別,本文主要是從標注好的人臉融合數據集中隨機抽取60人,每個人含有120幅不同視角的人臉圖像,其中80 幅圖像作為訓練圖像,40 幅圖像則用于測試。因此,本文在人臉分類KNN 模型中總共訓練了4800 個人臉圖像,其余2400 幅圖像用于人臉識別測試。在實驗中,我們定義K 的值為5,這就意味著5 個鄰近的對象決定了被預測人臉的分類屬性。在車內孩童人臉識別率和算法實時性上,該模型每秒可同時處理25 幀圖片且平均識別準確率可達94%,其具體識別效果如圖11所示。

圖11 車內孩童人臉識別效果圖
3.2 姿態估計實驗
在車內孩童姿態估計實驗中,分別依據自身采集的孩童姿態數據集CMP(28K/12K,訓練/測試)和公開數據集FLIC(5K/1K,訓練/測試)[15]對我們的姿態估計模型進行訓練和測試。對于模型中的卷積/反卷積塊的訓練,不管是CMP或是FLIC數據集,本文都是采用學習率為0.0005 的ADAM 優化算法來降低模型的訓練損失,并同時設置訓練參數batch_size=64和epoch=100。
在孩童姿態估計算法的評估上,本文主要是從以下兩個方面對其性能進行綜合評估。
1)模型精度評估:在人體姿態的評估上,本文將人體正確定位關鍵點的標準百分比PCK(人體關鍵點定位預測落在其真實值標準范圍內的百分比)作為其模型評估的度量指標。對于FLIC 數據集,本文在對人體軀干尺寸大小進行標準化之后,將PCK 設置為被檢測的人體關鍵點與其真實值之間的百分比差異;對于CMP 數據集,這種百分比差異PCKh則是對人體頭部尺寸大小進行標準化而形成的。PCK評價指標的公式如下所示:

其中M是數據集的尺寸;N是人體關鍵點的數量;IA(·) 是一個指示函數:如果(·) 里成立則IA等于1,否則IA則是0;‖Gtn-Predn‖2則表示被預測人體關鍵點n的位置與其真實值之間的歐幾里德距離;標準化H則是PCK人體軀干尺寸和PCKh人體頭部尺寸的一半;α則是人為設定的閾值,其是為了評估人體關鍵點是否被正確預測到。
表2總結了模型在CMP數據集上的性能評估,實驗發現我們的模型在CMP 數據集上所有關鍵點定位(肩膀、肘部、腕部等)上都實現了最優的結果。而表3則總結了模型在FLIC數據集上的結果,其中肘部的PCK 達到了99.2%,腕部則是97.3%。綜合而言,由于模型在多尺度特征監督和關鍵點全局聯合回歸上的改進,其在肩膀、肘部、手腕等關鍵點的預測和定位上都表現的很好。

表2 CMP姿態數據集評估結果
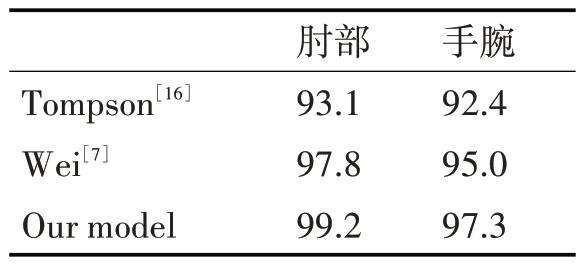
表3 FLIC數據集評估結果
2)模型遮擋處理評估:遮擋問題是人體姿態估計的一個常見挑戰。我們在提出的CMP 孩童姿態測試集的一個子集上評估了我們的模型,該測試集具有可用的被遮擋的孩童關鍵點標簽。本文提出的姿態估計模型主要是關注可見身體部位的相連部分,并從中推斷出被遮擋的人體關鍵點,例如,模型可以從可見的肩部和手腕位置恢復被遮擋的肘部關鍵點。該姿態估計實驗可以評估所提出的關鍵點全局回歸網絡是如何在多尺度特征監督下實現關鍵點遮擋的恢復,在PCKh=0.5 和GT、GT/2、GT/4 等多尺度真值的監督下,孩童關鍵點預測的定位精度是86.7%。相比之下,在模型沒有多尺度監督的情況下,精度則是84.3%。
最后,我們對車內孩童的姿態估計進行了實驗,其實驗效果如圖12所示。

圖12 車內孩童姿態估計實驗效果圖
4 結語
為了保障車內疑似滯留孩童的生命安全,在考慮到算法實時性、精度以及車內遮擋等問題的基礎上,本文主要是基于卷積神經網絡的方法提出了孩童面部識別和姿態估計算法,在孩童的面部識別上,主要是采用ResNet 網絡和KNN 算法來實現人臉面部的特征提取和精確識別;在孩童姿態估計上,主要是采用多尺度監督和關鍵點全局回歸的方式來推斷出被遮擋的人體關鍵點位置。最后,再結合孩童在車內的當前狀態和車內二氧化碳濃度的變化情況建立車內智能監控及分級預警模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
學生天地(2020年31期)2020-06-01 02:32:06
光學精密工程(2016年6期)2016-11-07 09:07:19
計算機工程(2015年8期)2015-07-03 12:19:07
中國衛生(2014年2期)2014-11-12 13:00:16
