基于特征篩選和改進深度森林的變壓器內部機械狀態聲紋識別*
2022-09-29 09:19:58馬宏忠張玉良段大衛崔佳嘉
電機與控制應用 2022年9期
李 楠, 馬宏忠, 張玉良, 段大衛, 崔佳嘉, 何 萍
(1.河海大學 能源與電氣學院,江蘇 南京 211100;2.國網南京供電公司,江蘇 南京 210008)
0 引 言
電力變壓器是電力系統的核心設備之一,其可靠運行與電力系統的安全穩定密切相關[1-2]。機械故障是變壓器主要故障類型,也是部分電氣故障、發熱等問題的主要誘因,具有累計效應,易造成絕緣老化加速、抗短路能力降低等隱患[3-4]。國家電網統計表明,由繞組故障引起的變壓器事故占變壓器總事故的69.8%[5-6]。因此,開展變壓器繞組及鐵心機械狀態監測與識別研究,對電力系統的安全穩定運行具有重要意義。
目前,現有的變壓器機械故障診斷方法包括頻率響應法[7]、低壓脈沖法[8]、短路電抗法[9]、油色譜分析法[10]以及振動分析法[11]等。頻率響應法、低壓脈沖法以及短路電抗法需要離線檢測并且一定程度地影響變壓器壽命。油色譜分析法可以實現在線監測,但難以準確地識別故障類型及確定程度。振動分析法具有無電氣聯系、可以在線檢測等優點,但對振動傳感器安裝位置、安裝方式要求嚴苛,尤其是測點位置的改變極易造成測量結果相差較大,因此該方法難以得到推廣。
變壓器運行時產生的聲紋信號包含大量反映設備內部機械狀態的有效信息。基于聲紋的變壓器故障診斷方法具有非接觸、測量方便快捷以及可以在線監測等優點,且能夠有效解決振動分析法中空間敏感度要求高的問題,受到廣泛關注。文獻[12]提出了基于Mel頻率倒譜系數(MFCC)和矢量量化算法的變壓器聲紋識別模型,對不同鐵心壓緊狀態下的變壓器聲紋信號進行識別。文獻[13]使用MFCC進行特征提取,建立了基于快速增量式以及門控循環單元的變壓器機械故障聲紋識別模型。文獻[14]提取MFCC特征量,并建立兩級電氣故障聲紋識別算法,對4種不同工況進行識別。MFCC利用人類聽覺感知試驗得到的Mel非線性譜,進行聲紋特征提取,目前已成為主流的聲紋識別特征向量提取方法。然而,MFCC特征參數主要針對人對聲音的感知特性,考慮到變壓器聲紋信號與人聲之間存在較大差異,MFCC難以用于變壓器聲紋識別。因此,亟需一種切實有效的變壓器聲紋特征提取方法,以提高聲紋識別準確率。
以深度神經網絡為代表的深度學習算法因其強大的數據處理與挖掘能力受到廣泛關注。文獻[15]利用卷積神經網絡在圖像深度數據挖掘方面的優勢,提出了基于Mel時頻譜-卷積神經網絡的變壓器鐵心聲紋識別模型,對3種不同工況下的聲紋信號進行識別。文獻[16]利用深度神經網絡中的門控循環單元強大的特征學習能力,提出一種改進的MFCC和門控循環單元的變壓器偏磁聲紋識別方法。盡管上述方法證明了深度學習用于聲紋識別的有效性,但所提模型均存在網絡結構復雜、對樣本數量要求高、訓練時間長以及過擬合等問題。
為了利用深度神經網絡挖掘故障特征的優勢,同時避免建立模型,深度森林應運而生。文獻[17]提出基于稀疏深度森林的調相機輕微定子匝間短路故障方法,取得了較高的診斷精度和效率。文獻[18]提出一種改進的新型深度森林算法,有效解決了滾動軸承剩余壽命預測精度差、運算效率低等問題。然而,目前深度森林還未應用于變壓器機械狀態聲紋識別[19-21]。
為此,本文提出一種基于特征篩選和改進深度森林的變壓器機械狀態聲紋識別方法。先利用自適應噪聲完備集合經驗模態分解(CEEMDAN)將聲音傳感器采集到的聲紋數據分解成多個本征模態函數(IMF)分量,并根據頻譜分析和皮爾遜相關系數進行IMF分量優化選擇,篩選出有效的IMF分量。再利用各IMF分量在頻段上的分布情況劃分高、低頻段,依據高、低頻段IMF分量的差異性,提取高頻段IMF分量時頻能量和低頻段IMF分量幅值特征構成特征向量。為平衡模型的級聯層數和精度,以提高運算效率,對深度森林進行改進,并將特征向量輸入改進后的深度森林模型,輸出10種機械松動狀態的聲紋識別結果。最后,在現場實測的基礎上對所提方法進行驗證。
1 模態分解與篩選
1.1 模態分解
經驗模態分解(EMD)是一種自適應時頻分析方法,通過多次迭代得到多個單IMF分量,但由于極值點的選擇問題會出現模態混疊現象。為解決極值點的選擇問題,集合經驗模態分解(EEMD)引入高斯白噪聲,利用高斯白噪聲頻譜均勻分布特性,使信號自動分布到合適的參考尺度上,有效抑制EMD的模態混疊現象,但存在計算速度慢和模態分解結果中存在多個無效低頻IMF分量等問題。
CEEMDAN在EEMD方法基礎上,通過加入殘值、高斯白噪聲和多次疊加求平均以抵消噪聲等操作,進一步減少模態混疊,提高了分解的完備性以及對噪聲干擾的魯棒性。具體算法原理如下所示。
1.1.1 第一階段模態分量
對于加入高斯白噪聲的原始信號:
X(i)=y(t)+k0ni(t)
(1)
式中:y(t)為原始信號;ni(t)為滿足N(0,1)分布的高斯白噪聲;k0為第一階段高斯白噪聲的幅值。
將帶噪原始信號EMD分解,并將分解得到的IMF1,i分量平均得到:
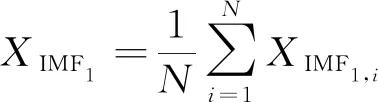
(2)
式中:N為分解后的模態分量個數。
1.1.2 第二階段模態分量
在第一階段模態分量的基礎上計算第一階段殘余分量:
x1(t)=X(t)-XIMF1
(3)
分解加入白噪聲的第一階段殘余分量:
r1(t)=x(t)+k1EMD1[ni(t)]
(4)
式中:EMDi[ni(t)]為分解信號得到的第i個分量;k1為第二階段高斯白噪聲幅值。
將帶噪第一階段殘余分量EMD分解,并將得到的IMF2,i分量平均得到:
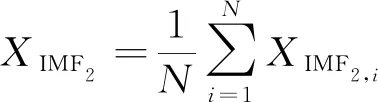
(5)
1.1.3 第k階段模態分量
對于k取3,4,…,k,同樣重復上述步驟計算xk(t)和rk(t),并通過EMD分解及平均操作,直到剩余信號不能被分解,得到第k階段模態分量為
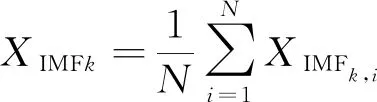
(6)
1.2 模態篩選
1.2.1 頻譜分析
現有研究表明,變壓器聲紋信號分布于0~2 000 Hz的頻率范圍內,且以50 Hz及其倍頻分量為主。本文試驗中的聲紋信號主要由3種頻率成分構成:(1) 頻點為0的直流分量,屬于傳感器測量所造成的直流偏移;(2) 0~50 Hz之間的頻率范圍,屬于測試環境中的背景噪聲;(3) 50 Hz及其倍頻分量,是變壓器本體產生的聲音成分。
1.2.2 皮爾遜相關系數
皮爾遜相關系數用以度量兩組向量之間的關聯程度,本文選擇皮爾遜相關系數量化各個IMF分量與原始信號之間的關聯程度,進而刻畫IMF分量中包含特征信息的豐富程度,其值在-1~1之間,且越接近1,表示兩者之間的相關性越強。皮爾遜相關系數ρXY計算公式如下所示:
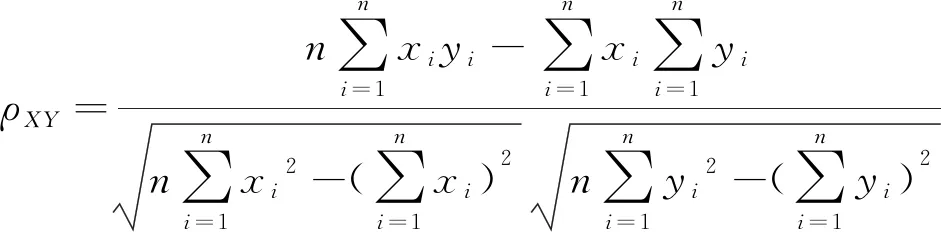
(7)
式中:X={x1,x2,x3,…,xn};Y={y1,y2,y3,…,yn}。
2 特征提取
不同IMF分量在頻譜中表現出較大的差異性。為依據不同頻段IMF分量的特點,有針對性地提取故障特征,可以將IMF分量分為能量大多集中于500 Hz以下的低頻段IMF分量和500 Hz以上的高頻段IMF。低頻段IMF分量頻譜簡單,其主頻集中于100 Hz、200 Hz以及300 Hz,且能量集中、幅值較大。高頻段IMF分量頻譜復雜,表現出非線性、非平穩特征,且能量分散、幅值較小。本文針對高、低頻段IMF分量差異性提取不同特征,并進行歸一化構成故障特征量。
2.1 低頻段IMF分量幅值
低頻段IMF分量相對平穩,頻譜簡單且集中。針對此特點,本文提取低頻段中各50 Hz及其倍頻信號幅值之和作為低頻段IMF分量特征(簡稱為LFA)。其計算方法為先利用短時傅里葉變換,計算各50 Hz及其倍頻信號幅值對應的幅值f(50×i)并將其疊加,計算式如下所示:
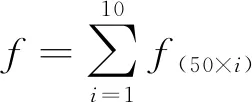
(8)
式中:i為整數,i=1,2,3,…,10。
2.2 高頻段IMF分量時頻能量
高頻段IMF分量頻譜復雜,且表現出非線性、非平穩的特征。小波能量熵針對高頻段IMF特征,融合小波變化和能量熵優勢,能夠從時間和頻率兩方面監測能量分布變化情況,因此,本文選擇小波能量熵(簡稱為WEE)對高頻段IMF分量進行特征提取,利用特征向量構成識別參數,輸入識別模型,計算過程如下所示。
2.2.1 小波時頻分析
對聲音信號進行分幀以及加窗處理后,對聲音信號進行連續小波變換,先確定小波基與尺度,而后求出小波系數,其計算公式如下所示:
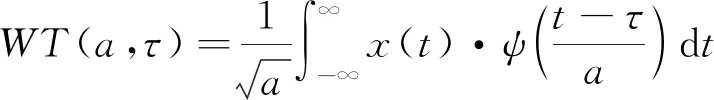
(9)
式中:x(t)為輸入聲音信號序列;ψ為母小波,采用復數小波Complex Morlet,其在時頻兩域具有很好的分辨率,適合處理非平穩的聲音信號。
2.2.2 IMF分量能量計算
從小波系數序列中提取小波系數coefs(50×i)(n),對于給定小波系數coefs(50×i)(n):
coefs(50×i)(n)=[coefs(50×i)(1),coefs(50×i)(2),
coefs(50×i)(3),…,coefs(50×i)(N)]
(10)
定義時間序列數據平方和Ej,其為該時間序列數據能量:
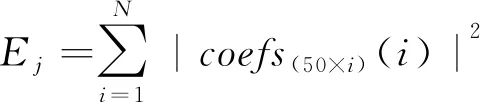
(11)
2.2.3 總能量值計算E
總能量值E的計算式為
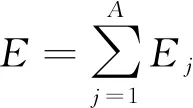
(12)
式中:A為CEEMDAN分解的IMF分量個數。
2.2.4 IMF能量熵計算
IMF能量熵計算式為
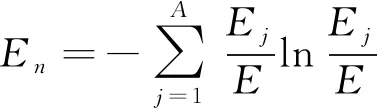
(13)
3 深度森林
深度森林主要包括多粒度掃描和級聯森林。多粒度掃描是通過掃描窗口遍歷以提高子樣本數量的方法。級聯森林采用級聯方式連接各層,且每一層均由隨機森林和完全隨機森林組成。本文對多粒度掃描和級聯森林進行參數調整和模型改進,提高了運算效率和識別準確率。
3.1 多粒度掃描
多粒度掃描利用滑動掃描窗口遍歷樣本,提取時間序列數據空間位置信息。掃描窗口為L維向量,掃描滑動步長為1,對于N維時間序列數據樣本,多粒度掃描后將獲得N-L+1個L維子樣本。利用隨機森林對子樣本進行訓練,產生N-L+1個K維概率特征向量,將上述N-L+1個概率特征向量利用張量壓縮拼接成K(N-L+1)維向量,作為后續級聯森林輸入特征。
3.2 級聯森林
級聯森林是一種借鑒決策樹混合堆疊思想改進的多層級結構,每一級聯層中包含隨機森林和完全隨機森林,其訓練后生成的特征向量為類向量,生成的類向量和原始數據向量拼接構成新的向量,作為下一層的輸入特征向量。當訓練達到較好效果或訓練至最后一層時,對各層輸出的概率特征向量取平均值,則最大的類概率值所對應標簽為最終輸出結果。本文在原始模型的基礎上,增加XGBoost基學習器以調用GPU參與運算,提高計算速度和效率。此外,增加邏輯回歸基學習器以降低數據資源存儲要求,大幅度提高級聯森林網絡模型的性能。
級聯森林是多層堆疊,隨著級聯層數增加,深度森林復雜度線性增加,但是隨著層級增加,訓練準確率提升逐漸變緩。為避免無效級聯,提高模型訓練效率,引入神經網絡中的識別準確率和交叉熵損失值作為級聯結束判定指標。在模型訓練以及層級增加過程中,當識別準確率連續5次未提高或損失值連續5次未降低,則層級增加終止,避免無效的級聯層數增加,以提高模型運算效率。
模型訓練準確率計算公式如下所示:

(14)
式中:TP為將正類預測為正類的數量;TN為將負類預測為負類的數量;FN為將正類預測為負類的數量;FP為將負類預測為正類的數量。
模型訓練損失值計算公式如下所示:
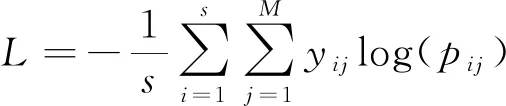
(15)
式中:s為樣本個數;M為多分類類別數;yij為樣本標簽,當樣本i的真實預測類別標簽為j時取1,否則取0;pij為觀測樣本,i屬于j的概率。
4 試驗與分析
4.1 試驗描述與頻譜分析
為驗證本文方法的有效性,在句容變壓器廠搭建變壓器聲紋數據采集平臺,以一臺型號為S-13-M-200/10的10 kV油浸式配電變壓器為研究對象,通過試驗模擬其在不同工況下發生機械故障,并通過采集平臺采集聲紋信號。試驗平臺包括電腦、DHDAS動態信號采集儀、信號傳輸線、前置放大器HS14618以及電容式聲傳感器 HS14401等如圖2所示。本文設置采集儀的采樣頻率為50 kHz以提高試驗精度,按照國標GB/T 1094.10—2003規范,傳感器布置在變壓器四面,距離變壓器油箱30 cm,距離地面高度35 cm,利用龍門吊和扭力扳手設置不同類型的機械故障。
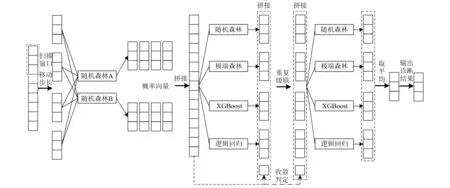
圖1 改進深度森林模型
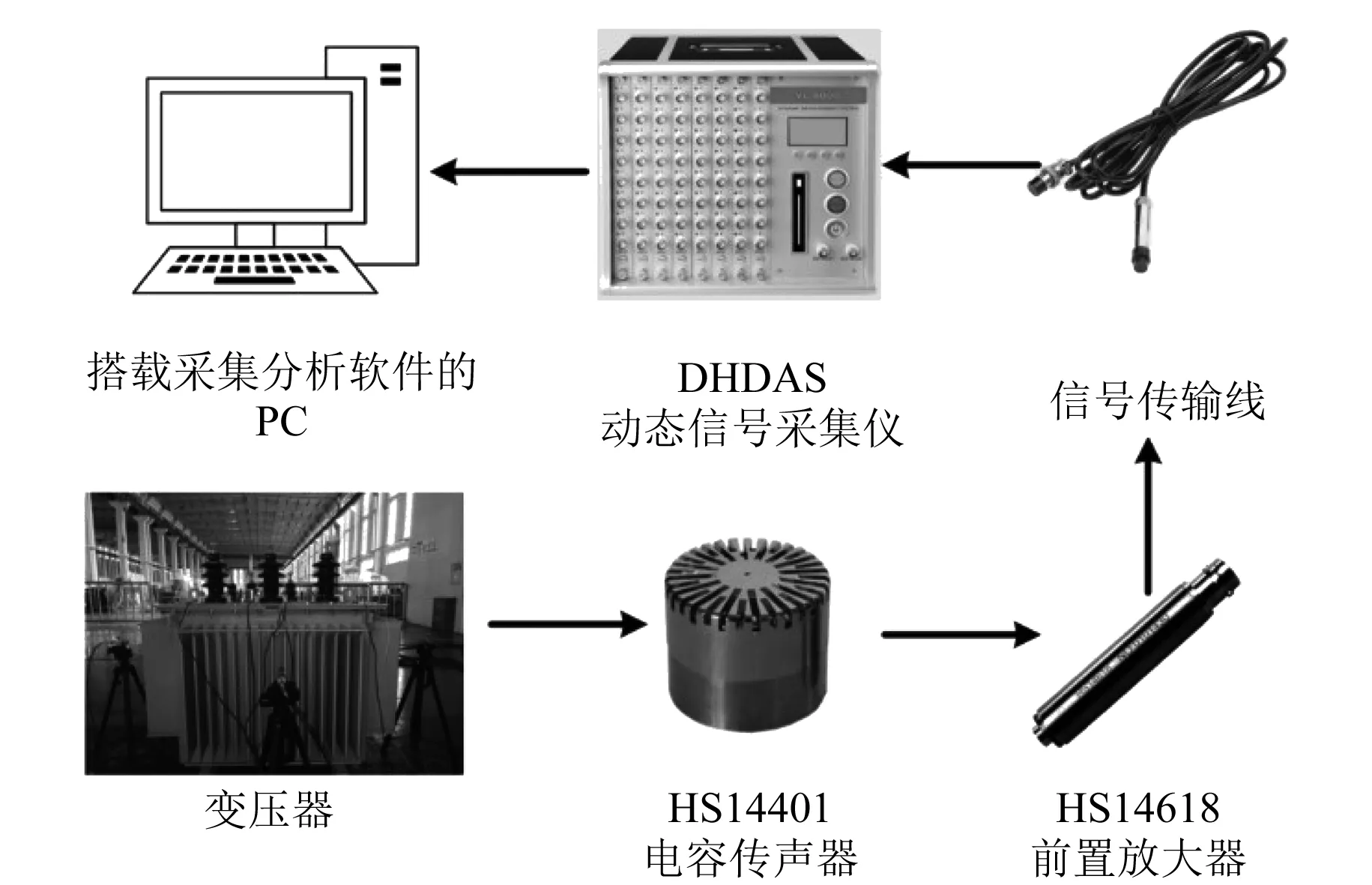
圖2 變壓器聲紋數據采集平臺
變壓器空載試驗下,繞組中僅流過勵磁電流,不足以引起繞組的振動,此時聲音信號主要來源于鐵心振動。變壓器短路試驗下,繞組振動引起的聲音遠大于鐵心振動引起的聲音。本文開展空載試驗和短路試驗,如圖3所示。為了盡可能采集到豐富的聲音信號,本文將4個相同型號的聲音傳感器均勻地放置在變壓器箱體的4個側面。 1號和3號傳感器對應的箱體側面記為“左右側面”,2號和4號傳感器對應的箱體側面記為“上下側面”,以研究變壓器鐵心、繞組的松動機械故障,具體試驗流程如下。

圖3 變壓器機械松動故障試驗
(1) 空載試驗下的鐵心松動故障。設置變壓器高壓側開路,低壓側保持額定電壓,利用龍門吊吊心,并使用扭力扳手調整鐵心水平方向緊固螺絲的松緊程度,調整預緊力為0、0.25FN、0.5FN、0.75FN和FN,此處FN為額定預緊力,最后裝機靜置采集聲紋數據。
(2) 短路試驗下的繞組松動故障。設置變壓器低壓側短路,高壓側逐漸增加電壓至繞組中電流達到額定電流時停止,通過重復變壓器吊心,并利用扭力扳手調整變壓器繞組垂直方向上的緊固螺絲松緊程度,分別調整預緊力為0、0.25FN、0.5FN、0.75FN和FN,靜置測量變壓器聲紋數據。
試驗采集并切片構成11 000個樣本,對樣本進行分類、附標簽以及頻譜分析,將其分為鐵心松動和繞組松動2種松動故障類型。每種松動故障又被分為0、0.25FN、0.5FN、0.75FN和FN5種不同預緊力,對應100%、75%、50%、25%以及正常5種松動程度,并按照9…1劃分訓練集與測試集,各類別標簽及樣本個數如表1所示。
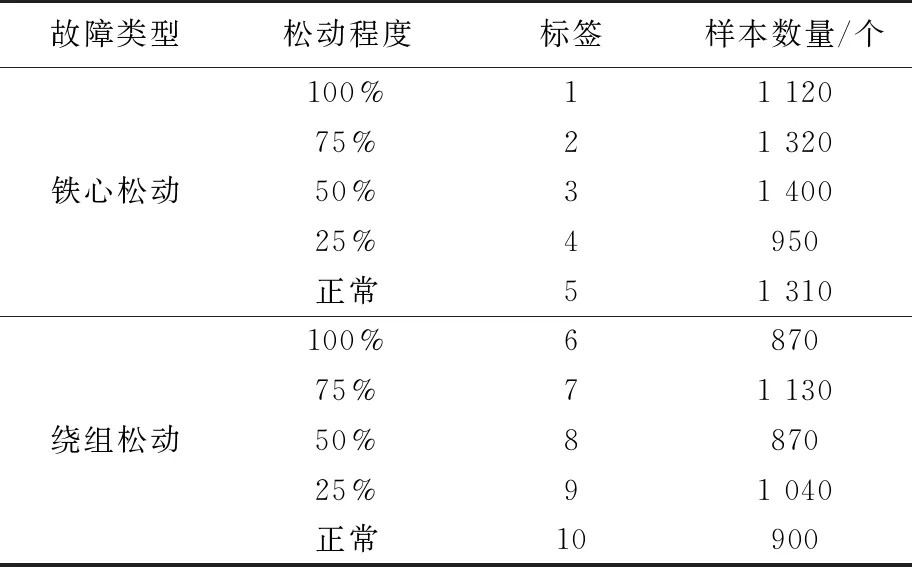
表1 樣本標簽和樣本個數
如圖4所示,變壓器聲紋信號主頻為100 Hz,主要成分為50 Hz及其偶次倍頻分量,50 Hz奇次倍頻分量含量較少,且多集中于低頻段。變壓器鐵心及繞組松動程度的變化,只改變特征頻點的幅值,未改變頻譜分布。此外,在低于50 Hz的頻段也存在少量分布,屬于測試環境中的背景噪聲。此外,2號測點頻譜穩定性高且信號相對簡單,以其為代表進行分析處理。

圖4 聲紋信號頻譜分析
在不同預緊力作用下,聲紋信號頻譜變化各不相同,但未表現出明顯的規律性,且故障特征提取較困難。因此,迫切需要切實可行的故障特征提取方法。
4.2 變量篩選
為驗證本文所提方法的有效性,對真實聲紋數據進行分解,摒棄由于傳感器自身及測量所造成的直流偏移和外界環境噪聲干擾等無關分量,保留包含故障特征的IMF分量。如圖5所示,IMF1~IMF3為全頻段的均勻噪聲,且其幅值遠低于其他IMF分量。IMF12~IMF13所包含的特征分量均為低于50 Hz的低頻段,其屬于測試環境中的背景噪聲。IMF14為傳感器及測量造成的直流偏移。因此,本文舍棄無關分量,保留IMF4~IMF11等包含故障特征的分量。
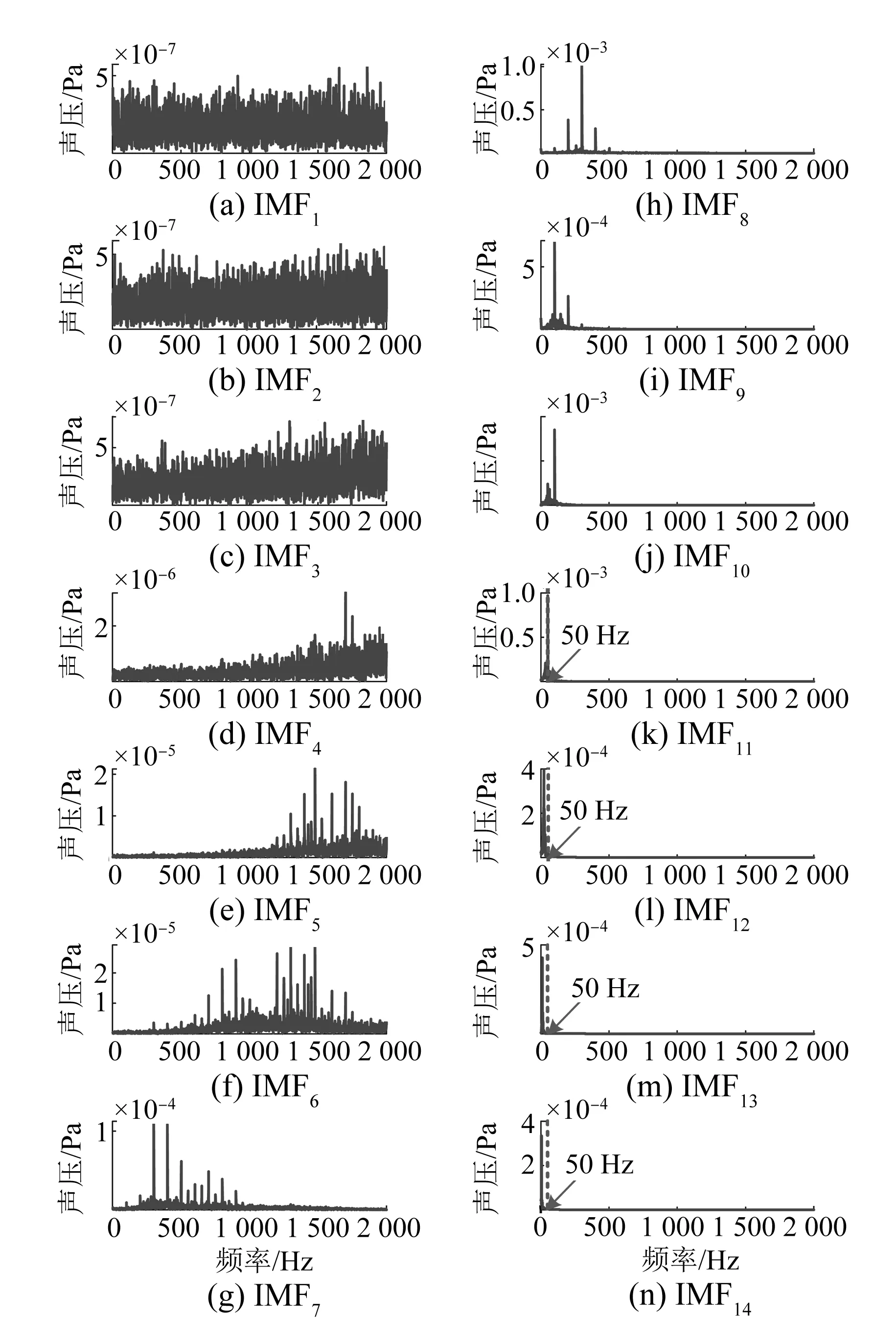
圖5 IMF分量頻譜分析
在去除背景噪聲分量的基礎上,通過皮爾遜相關系數刻畫原始信號與各IMF分量之間及各IMF分量之間的關聯程度,刻畫各IMF分量包含信息的豐富程度和獨立性。各IMF分量相關系數,如圖6所示。IMF4與原始信號之間的皮爾遜相關系數僅為0.008 4,相關程度較低。各IMF分量之間的相關系數均小于0.2,說明各分量之間相對獨立。

圖6 IMF分量相關系數圖
4.3 特征量提取
變壓器聲紋信號經過CEEMDAN分解后,對各IMF分量進行頻譜分析和相關系數篩選,得到包含故障特征信息的IMF分量。針對不同IMF分量特點,利用短時傅里葉變換和小波時頻熵分別提取不同頻段的IMF分量特征,同時隨機選擇提取MFCC一幀進行對比。以5種不同程度鐵心松動故障為例,特征提取結果如圖7所示。MFCC對于不同程度鐵心松動故障區分度較差,存在大量交疊,且特征維度遠超其他特征。短時傅里葉變換幅值特征提取,針對簡單平穩的IMF8~IMF11具有良好的區分度,但對復雜非平穩的IMF5~IMF7存在交疊現象,難以有效區分。小波能量熵針對復雜非平穩的IMF5~IMF7具有較好的區分效果,但不適用于簡單平穩的IMF8~IMF11。本文針對不同分量特征,融合不同特征提取方法優點,提出篩選特征方法,所提取的特征對有效的IMF5~IMF11均具有較高區分度。
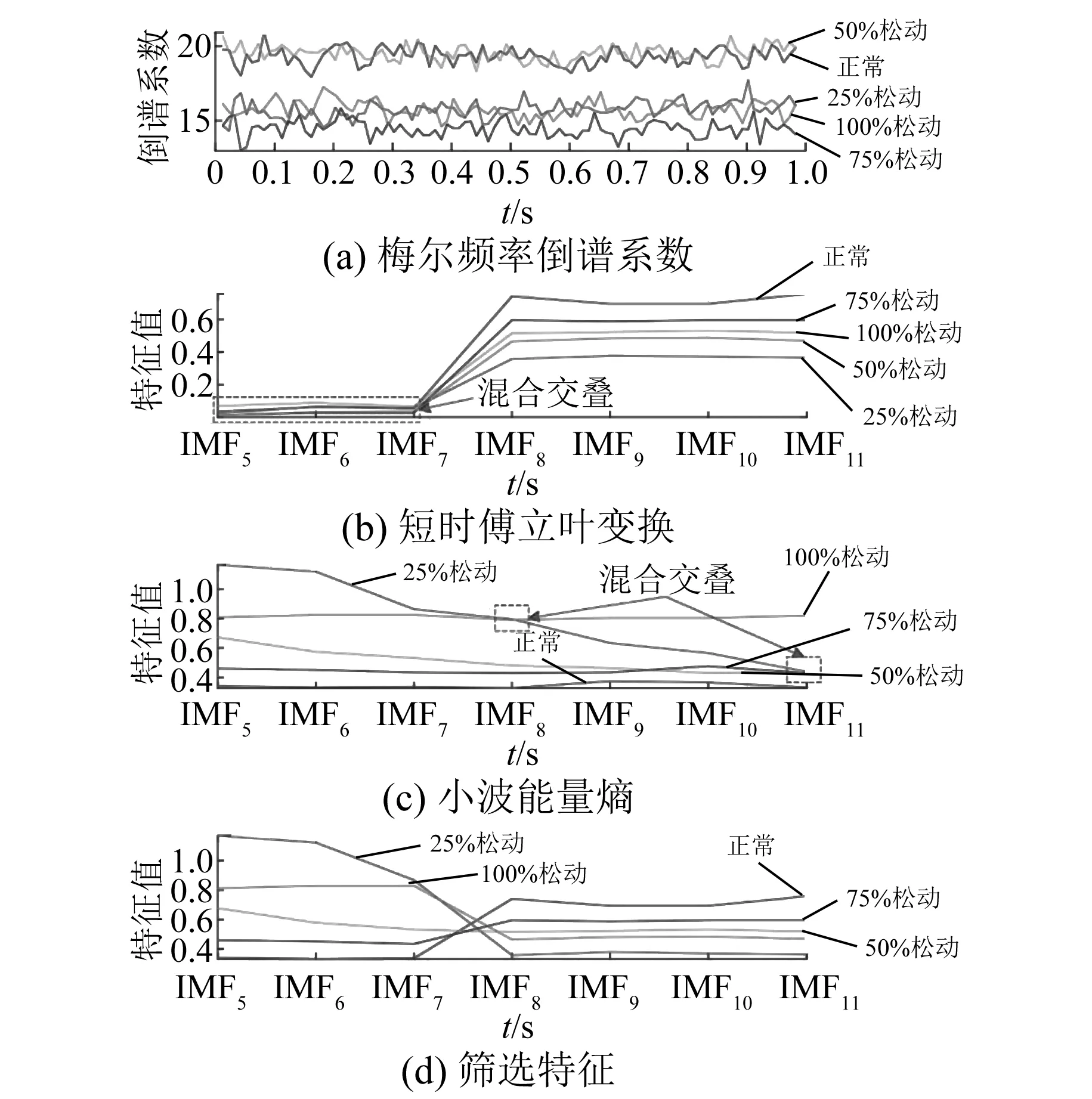
圖7 特征值區分度折線圖
4.4 識別模型搭建與訓練
為避免變電站其他變壓器聲紋信號對測試變壓器產生干擾,在識別模型前增加輔助判據。當變壓器處于空載狀態且50 Hz頻點幅值均小于0.001 Pa,啟動鐵心松動程度識別程序。當變壓器負載狀態下且50 Hz頻點幅值均小于0.001 5 Pa,啟動繞組松動程度識別程序。
本文針對10種類別、共計6 000組樣本數據,隨機提取80%樣本作為訓練集、20%樣本作為測試集。在經過CEEMDAN分解后,選取IMF5~IMF11的樣本熵和能量熵所構成的特征向量,作為深度森林的輸入進行分類識別。
本文對改進深度森林中的3個重要超參數進行優化,包括學習率、基學習器中樹的數量以及k折交叉驗證中的k值。其中k折交叉驗證的k值分別取3,4,5,…,15,基學習器中樹的數量分別取100,200,300,…,1 000,學習率分別取0.1,0.01,0.001,0.000 1。為防止偶然性出現,每種超參數取值后進行5次重復試驗,將5次試驗結果取平均值進行對比,如圖8所示。本文設置k折交叉驗證中的k值取12,基學習器中樹的數量取700,學習率為0.001。

圖8 識別模型超參數訓練過程
按上文重新設置模型超參數,并導入樣本集對模型進行重新訓練,本文采用混淆矩陣來衡量模型對1 100個測試樣本的識別分類結果。如圖9所示,本文所提模型對繞組及鐵心不同松動程度故障均能實現有效識別,平均識別率達98.7%。
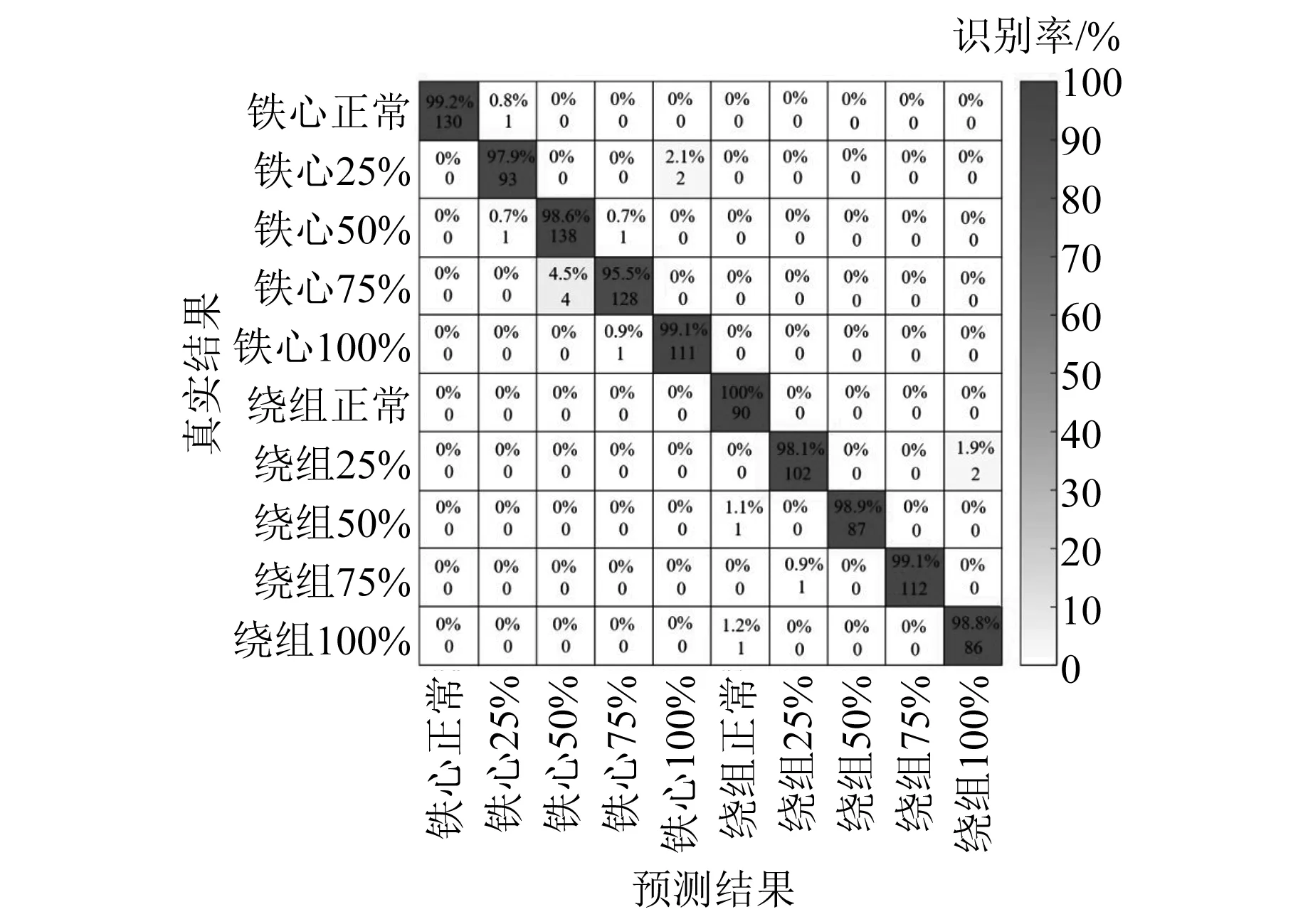
圖9 識別結果混淆矩陣
4.5 模型優越性驗證
為驗證本文所提特征篩選方法的有效性,本文對比MFCC、IMF1~IMF14中提取的倍頻幅值、IMF1~IMF14中提取小波能量熵、IMF5~IMF11中提取的幅值以及IMF5~IMF11中提取的小波能量熵5種特征值,分別記為MFCC、LFA1-14、WEE1-14、LFA5-11、WEE5-11。對1 100組測試樣本進行測試,測試結果如圖10和表2所示。MFCC特征識別準確率較低、訓練時間較長。對比IMF1~IMF14所提特征和IMF5~IMF11所提特征,IMF1~IMF14所提特征的識別準確率均低于IMF5~IMF11所提特征的識別準確率,IMF1~IMF14所提特征的訓練時間均高于IMF5~IMF11所提特征的訓練時間。可知無效的IMF分量所提特征不僅降低識別準確率且大幅度增加訓練時間。本文所提篩選的特征識別準確率較LFA1-14、LFA5-11、WEE1-14、WEE5-11以及MFCC 5種特征,至少提高了0.8%,且針對10類松動故障均有明顯提升。
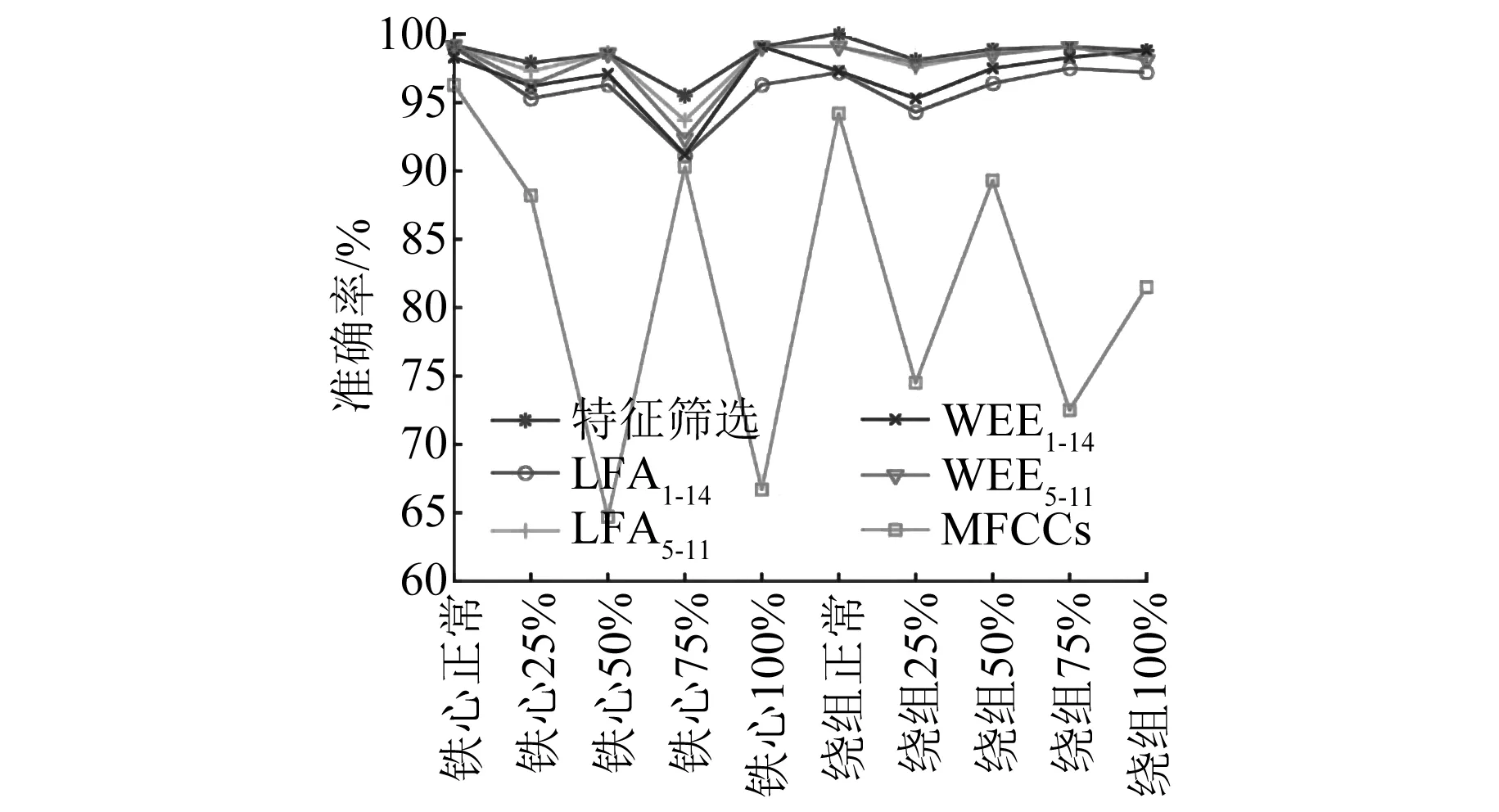
圖10 不同特征識別結果對比圖
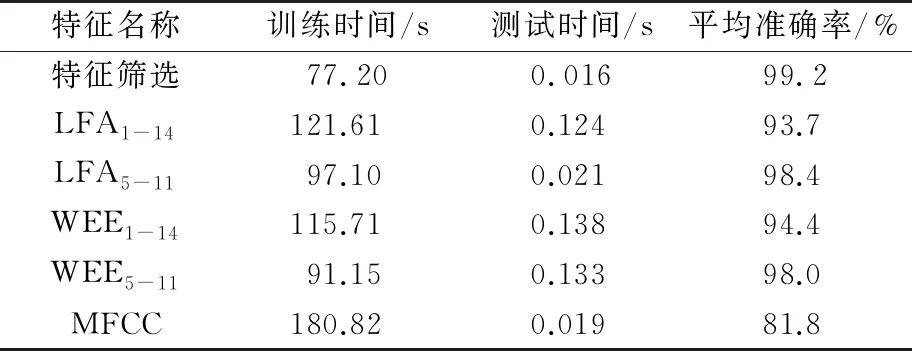
表2 各故障特征訓練時間和識別準確率
為驗證本文所提識別算法的優越性,將常見的機器學習算法如決策樹(DT)、樸素貝葉斯(NB)、隨機森林(RF)、K近鄰(KNN)、支持向量機(SVM)以及RUSBoost等與本文所提的改進深度森林模型進行對比。對1 100組樣本進行測試,測試結果如圖11所示。對比其他常見機器學習模型的平均識別準確率以及單一故障識別準確率,所提方法均有所提高。
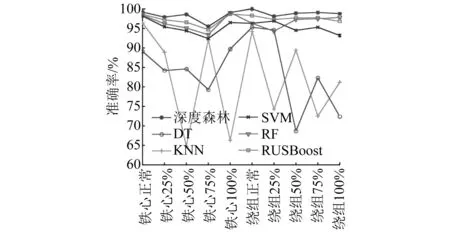
圖11 傳統機器學習算法識別結果對比圖
為驗證改進深度森林算法比深度學習算法擁有更強的泛化能力,與深度學習算法中的一維卷積神經網絡(ID-CNN)的訓練過程和識別結果進行對比,如圖12所示。CNN模型在訓練過程中能夠快速收斂,訓練集準確率最終穩定在100%。雖然改進的深度森林算法識別準確率存在一定程度的波動性,但卷積神經網絡測試集識別準確率僅為62.1%,改進深度森林測試集準確率達到99.2%,可知改進深度森林對變壓器機械狀態的識別具有更高的泛化能力。
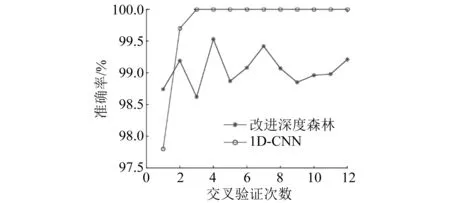
圖12 卷積神經網絡識別結果對比圖
5 結 語
變壓器運行過程中發出的聲音信號包含大量能夠反映設備內部機械狀態的有效信息。本文搭建變壓器聲紋信號采集平臺,對采集到的聲紋信號進行分析與處理,并對變壓器不同機械狀態的聲紋信號進行識別。在后續的研究中,會對現場實際運行的變壓器正常及故障數據進行收集處理,以進一步驗證本文所提方法的有效性。本文得到如下結論。
(1) 利用CEEMDAN對聲紋信號進行分解,通過頻譜分析和皮爾遜相關系數對IMF分量進行篩選,有效剔除無效的IMF分量,保留了包含變壓器本體聲紋信號的IMF分量。
(2) 通過對不同IMF分量在高低頻段上表征出的差異性,提取高頻段IMF分量的時頻能量和低頻段IMF分量的幅值特性作為特征指標,具有針對性的提取特征量,有效提高了特征向量的區分度,降低了特征向量的冗余,在一定程度上減少了識別模型復雜程度。
(3) 利用改進的深度森林算法對變壓器機械狀態進行識別,取得了較好的識別效果。
猜你喜歡
中學生數理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:08
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
通信電源技術(2018年3期)2018-06-26 06:33:30
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代工業經濟和信息化(2016年4期)2016-05-17 05:35:38
