面向計算流體力學的圖形處理器資源管理*
2022-10-04 12:46:04張獻偉盧宇彤
國防科技大學學報 2022年5期
翁 躍,張獻偉,張 曦,盧宇彤
(中山大學 計算機學院, 廣東 廣州 510006)
計算流體力學(computational fluid dynamics, CFD)是流體力學的一個分支,它利用數值分析和數據結構來分析和解決與流體流動有關的問題,可以廣泛應用于各種工程實踐,如空氣動力學和航空航天分析,自然科學和環境工程,工業系統設計和分析等。借助計算機的計算能力,CFD 可以模擬流體的自由流動以及流體與邊界面的相互作用,實現對物理過程的仿真。如今已經有一些優秀的數值模擬軟件用于求解 CFD 問題,例如擁有多種求解器可以解決可壓縮、不可壓縮流體模擬 OpenFOAM[1]、應用在航空航天領域的 FUN3D[2]、適合多物理場耦合的 Fludity[3]、結構和非結構網格耦合的計算框架 NNW-PHengLEI(風雷)[4]等。
隨著任務規模的不斷擴大,求解問題愈加復雜, 傳統的中央處理器(central processing unit, CPU)處理器已經難以提供足夠的算力支持, 這給 CFD 的應用和發展帶來了嚴峻挑戰。近些年來,隨著通用圖形處理器(general purpose graphics processing unit, GPGPU)的快速發展,其高并發、低功耗的特性受到高性能計算領域的青睞,被應用到CFD和其他諸多科學應用。 如何充分利用圖形處理器(graphics processing unit, GPU)的計算能力,提高CFD的計算性能和并行效率,是當前推動CFD發展的重要課題之一。
GPU的設計遵循單指令多線程(single instruction multiple threads,SIMT)的模式,即在同一時刻大量線程并行執行同一條指令。GPU 高并行優勢的發揮依賴于計算所需數據在合理時延范圍內的快速返回。然而,非結構網格(unstructured grid)的流體問題求解面臨嚴重的訪存瓶頸。原因在于網格的不規則數據存儲需要通過幾何拓撲結構間接索引數據,這將導致頻繁的不規則內存訪問和緩存替換,顯著增加數據的訪問延遲,極大地限制了 GPU 的指令執行,造成計算流水資源的浪費[5]。
針對以上問題,一種可行的解決方案是同時運行多個任務實現 GPU 共享使用和資源的差異化使用,從而提高整體利用率。每個任務程序都會具有各自的特性,不同的任務組合將會帶來不同的性能影響。當互補型的任務(如計算密集型和訪存密集型任務)共同執行時,由于需求的主要硬件資源不同,任務間的競爭被弱化,可以在保證任務的執行效率的同時,使資源使用更加均衡。反之,相同特性的任務一起運行將會給資源競爭帶來負面影響,很容易造成執行效率的不升反降[6-7]。因此,設計一個合理的混合任務調度機制對于 GPU 資源使用顯得尤為重要。本文將基于 CFD 對 GPU 進行資源管理設計, 通過搭配多任務共享 GPU 來提升整體的資源利用率。對于每個任務,將借助調優工具 (profiling tool)進行性能分析,得到程序的執行特性,并結合收集的 GPU 資源使用情況來動態調度任務的執行時間和核函數大小。
1 研究背景
1.1 計算流體力學
計算流體力學是流體力學中一種重要的技術,通過對納維-斯托克斯方程的求解,來預測流體流動時的狀態和變化,用于科學問題的研究或者機械設計的工程實現。在過去的30多年里,CFD 被廣泛地應用到多個領域,例如:在生物工程中,模擬心臟跳動、血液通過動脈和靜脈流動、細胞流體等[8];在機械工程中,模擬熱量傳遞過程,渦輪機械仿真,葉輪機械設計,預測機翼的空氣動力學等[9-11];在食品制造行業中,模擬滅菌和制冷的過程等[12]。
圖1展示了 CFD 在運輸機模型外流場氣動模擬中的應用。隨著應用領域的拓展以及應用規模的增大,CFD 對計算資源的需求也在不斷提升。因此,許多 CFD 模擬[13]必須在集群或者超級計算機上的高性能計算(high performance computing,HPC)系統中執行。隨著計算技術的發展,GPU 由于其低能耗和高并發的特性,在 HPC 系統中發揮了越來越重要的作用,許多 CFD 的應用也開始在 GPU 上進行移植加速和優化設計[14]。
圖1 運輸機模型外流場氣動模擬計算網格Fig.1 Aerodynamic simulation grid of transport plane model
1.2 GPU架構
圖2展示了基于 NVIDIA 設計的通用圖形處理器架構。一個 GPU 的組成包括多個流式處理器(streaming multiprocessors,SMs)、共享二級緩存(L2 cache)、全局內存(global memory)等,其中最核心的部分是 SMs。作為最基礎的計算單元,每個 SM 上有多個計算核心,如 INT32、FP32、FP64 和 tensor 用于滿足不同的計算精度需求。在內存上,每個 SM 包含 L0 和 L1 緩存,分別支持指令和數據的緩存。共享內存(shared memory)和 L1 共享同一個內存區域,用于減少合作線程之間的對全局內存的訪問次數。其他廠商的 GPU,如 AMD 等,也采用相似的 GPU 設計,只不過用了不同的描述術語。編程人員利用并行編程框架,如 CUDA[15]、OpenCL[16]、HIP[17]等編寫并行程序。核函數(kernel function)包含大量的線程,并且可以被進一步劃分為 blocks 和 grids,它們將通過設備的驅動和運行在 GPU 上執行。每個核函數的線程將被劃分為多個 warp,warp 是 GPU 任務調度的基本單元。以 CUDA 為例,每個 warp 包含 32 個線程(threads),這 32 個線程遵循 SIMT 的執行模式,通過 SM 上的 warp 調度器被分發到相應的計算單元 (CUDA core) 上執行計算。
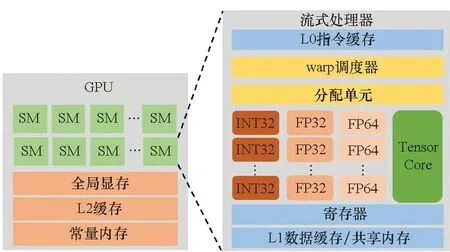
圖2 GPGPU 抽象架構Fig.2 Abstract architecture of GPGPU
1.3 GPU 程序性能分析
為了更好地剖析 GPU 程序的性能瓶頸,研究人員設計了多種 GPU 性能分析工具,從實現上來講可以分為:
基于硬件層面的實現,如 nvprof[18]和 rocprof[19],基于硬件計數器來記錄組件中發生的指定操作,如緩存請求和運行周期等。通過將原始計數器的結果轉換為高級的度量(如轉化為采樣時間內的內核執行效率、內存利用率等),用戶能夠清晰地度量和理解低級的硬件活動,進而分析核函數的執行情況,調試和優化程序。在本文中,將采用 nvprof 來剖析程序進而獲得執行特點。
在軟件層面的實現上,二進制插樁框架(binary instrumentation frameworks)(如 GT-Pin[20]和 NVBit[21])被廣泛地應用。二進制插樁是指在二進制程序動態執行時注入插樁代碼,從而實現程序分析。由于插入了額外的分析代碼,這種方式有可能會改變原程序的運行邏輯,并且帶來負面的影響[22]。除此之外,還可以通過改變編譯行為來實現程序分析,例如 DARSIE[23]和 CUDAAdvisor[24]。 這些工具在編譯期間添加更多輔助指令,以監視指令的有效性和內存訪問。分析工具提供的信息有助于全面了解程序的特點,進一步了解程序運行過程中各種 GPU 硬件資源的使用情況,可用于指導混合調度的設計。
2 相關工作
2.1 非結構網格求解
近年來,由于非結構網格對于復雜外形的模擬具有更好的適應性,逐漸成為工程應用上的主流建模選擇,也衍生出了不同精度的求解方式。基于二階精度的有限體積方法[25-27]具有較好的魯棒性和可靠性,可以應用于對精度要求較低的應用場景。但低階的格式存在數值耗散與色散問題,難以解決如湍流、非線性作用等復雜場景的問題,對此需要采用高階的格式[28]。基于非結構高階的計算方法也有著迅速的發展,主要包括:kexact 有限體積方法[29]、間斷 Galerkin 方法[30]、譜體積方法[31]、譜差分方法[32]以及混合多種求解方法的重構修正(correction procedure via reconstruction, CPR)方法[33]。本文中使用的是有限體積方法[34]。有限體積方法可以利用有限元素構建不規則網格,并將守恒態的微分方程離散化。同時,有限體積方法的計算速度和有限差分法接近,但相比有限元素法更加快速,可以極大減少計算量[35]。非結構網格有限體積方法在航空航天、海洋環境等許多科學計算領域得到廣泛的應用,形成了一些優秀的數值模擬軟件,例如OpenFOAM[1]、FUN3D[2]、Fludity[3]、NNW-PHengLEI(風雷)[4]等。
2.2 GPU資源管理
GPU 的計算核心是流多處理器(streaming multiprocessor, SM),圍繞 SM 資源的分配問題,Adriaens 等[36]介紹了三種管理方式——協作式多任務執行(cooperative multitasking)方式、搶占式多任務執行(preemptive multitasking)方式和空間多任務執行(spatial multitasking)方式。協作式執行方式允許任務在一段時間內獨占 GPU,由于一個任務往往無法充分利用所有的 GPU 資源,所以存在閑置資源。對于搶占式執行方式,多個任務以時間片的形式輪流使用 GPU,這可以緩解任務的過長等待時間,但也會帶來多次上下文切換的開銷[37-38]。空間多任務執行方式允許多個任務同時分享 GPU 資源,每個任務都只會占用一部分 SM[39],但對于局部而言,單個 SM 的使用率仍存在提升空間[40]。并且,對于SM的控制和warp放置往往需要深入驅動層面的修改或者硬件的輔助支持,所以往往通過模擬器來實現方法和設計。而本文提出的方法可以直接應用在實際的GPU上面,不需要額外的硬件支持。也有學者把核函數的執行作為切入點,Pai 等[41]提出了不同核函數靜態融合的方式來提高 GPU 資源利用率,還有學者致力于尋找最優的核函數執行對[6-7],以使得兩個核函數能以較低的性能損失來換取 GPU 資源利用率的提高。這種方法考慮了不同核函數之間的差異和共性,能夠更全面地利用不同類型的資源。但是缺點在于需要進行大量的代碼修改和核函數的調整,不利于實際的應用。本文的方法只需要很少的代碼微調,更加方便可行。
NVIDIA提供了多種技術以實現多個任務共同執行,包括流(stream)[42]、Hyper-Q[43]、多進程服務[44](multi-process service,MPS)和多實例GPU[45](multi-instance GPU,MIG)。借助流技術,開發人員可以將核函數執行和數據復制放到不同的流序列中,實現異步執行。Fermi 架構之后,Hyper-Q 作為一種硬件支持,可以實現多個 CPU 進程或線程共享 GPU。MPS 進一步發揮 Hyper-Q 的性能,支持協同多進程應用,尤其是 MPI 類型的任務。在最新的 Ampere 架構中, MIG 允許 GPU 資源被劃分為 7 個 GPU 實例,可以用于運行不同的應用,每個實例之間互不影響。這些方法可以實現 GPU 資源共享或劃分,但是在提高資源利用率方面仍然存在一定的局限性。例如在 MIG 中,每個實例內部依舊需要關心資源利用率的問題。本文提出的方法和以上的技術是正交的,可以很好地與這些技術結合,進一步發揮 GPU 的性能。并且不需要額外的硬件支持或者驅動修改,只需要微調部分代碼便可以支持本文的設計,并帶來實際的性能提升。
3 研究動機和方法設計
3.1 研究動機
3.1.1 訪存延遲導致指令執行低效
在移植和優化風雷軟件(NNW-PHengLEI)[4]過程中發現移植后的 GPU 風雷程序在求解非結構網格問題時并無法充分利用硬件資源,其中的熱點函數需要被更細致地分析。
表1列出了風雷程序中計算時間占比最大的前 8 個核函數名全稱及其縮寫,這 8 個核函數合計執行時間約占任務整體時間的 72%。圖3展示了這些核函數每個時鐘周期完成的指令條數(instructions per cycle,ipc)。ipc表示每個采樣周期指令的吞吐數目,可以用于衡量程序對于處理器性能的利用率,其理論峰值是 4.0[18]。然而這些熱點函數的平均ipc值只有 0.21,最大值也僅有 0.43,這表明風雷程序無法充分利用 GPU 的計算能力。
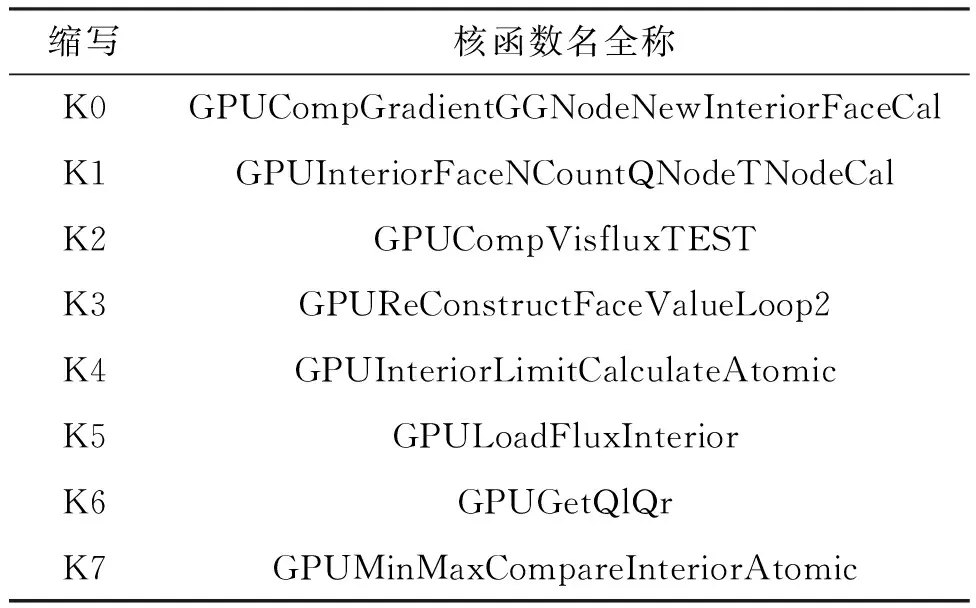
表1 風雷GPU程序前8個熱點核函數名全稱及其縮寫Tab.1 Full names and abbreviations of the top 8 hot kernel functions of the PHengLEI GPU program
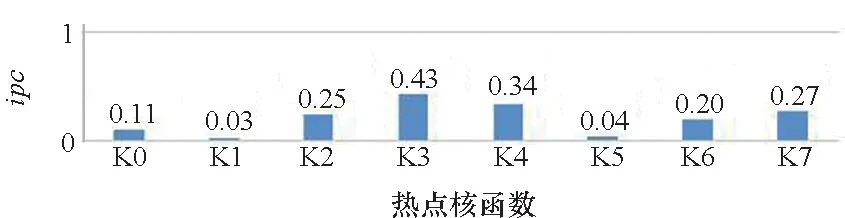
圖3 風雷GPU程序前8個熱點核函數每個時鐘周期完成的指令條數Fig.3 Instructions per cycle of the first 8 hot kernel functions of the PHengLEI GPU program
圖4展示了影響這些熱點函數的原因。可以發現最重要的兩個原因是stall_memory_dependency和stall_memory_throttle。stall_memory_dependency表示因為所需資源沒有可用或沒有充分利用,或者由于給定類型的請求太多而導致內存操作無法執行,從而導致的停頓百分比。而stall_memory_throttle是由于內存節流而發生指令延遲的百分比。這兩項延遲原因是程序延遲的最主要原因,由此可以推斷風雷程序的瓶頸在于訪存等待。進一步深入分析發現,該訪存問題是由非結構網格數據存放特點導致的。在非結構網格中,相鄰數據結構(如點、面、體)之間的數據存放是非連續的,需要根據拓撲結構間接索引數據,這導致了緩存的失效,需要從全局內存中讀取數據,這將帶來極大的延遲,導致 GPU 計算資源的閑置和浪費。這種訪存延遲型的任務在科學計算中并不少見[46-47]。對此,可以嘗試讓計算型任務和這類訪存延遲型任務共享 GPU 資源,在訪存型任務等待數據讀取返回的同時,計算型任務可以使用計算單元,這將一定程度上提高 GPU 資源的整體利用率,并且保障任務的執行性能。
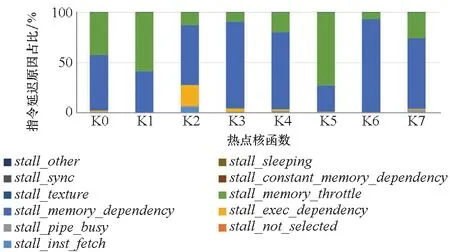
圖4 風雷GPU程序前8個熱點核函數的指令延遲原因Fig.4 Stall reason of the first 8 hot kernel functions of the PHengLEI GPU program
3.1.2 拆分函數可以帶來性能提升
在以往的經驗中,研究人員會嘗試將多個小的核函數合并為一個大的核函數,以提高函數的執行效率[48],但這種方法并不適用于所有情況。嘗試對 K6 進行拆分,這個函數主要負責數據的索引和讀取。將原先函數中的大循環拆分為 5 個小循環并串行執行,在拆分之后,總體的平均執行時間減少了 5%,其他指標的分析如圖 5所示。其結果進行了正則化處理,將拆分前的各項指標和結果設為 1。從圖5中可以看出,對 SM 的占用率achieved_occupancy也下降了 6%。這是因為核函數變得更小,能更快被執行完畢,所以采樣期間的占用率下降。值得一提的是,ipc和準備好可以被執行的 warp 數目eligble_warps_per_cycle出現了較大的提升, 相比拆分前分別提高了 57%和 85%。這是由于核函數規模變小,數據訪問的瓶頸現象有所緩和,stall_memory_dependency下降了 2%,stall_memory_throttle也下降了 10%。一旦小批量數據讀取完成便可以馬上被執行,計算性能被進一步得到利用。同理,拆分后的核函數所需的數據依賴量更小,更容易成為可以被執行的 warp。這將可以緩解大核函數的訪存瓶頸,使得 GPU 的資源被更好地利用。這啟發研究人員可以在某種硬件資源競爭情況嚴重(如頻繁訪存)的時候,適當減小核函數的規模大小,讓出部分資源(如對 SM 的占用),在減輕資源競爭的同時,維持甚至提升核函數的執行效率,也讓其他任務有更多的資源可以被使用。因此,可以嘗試在資源不足時,動態縮小核函數的規模,讓出部分資源,可以被其他準備好的任務使用,從而提升GPU的整體資源利用率。
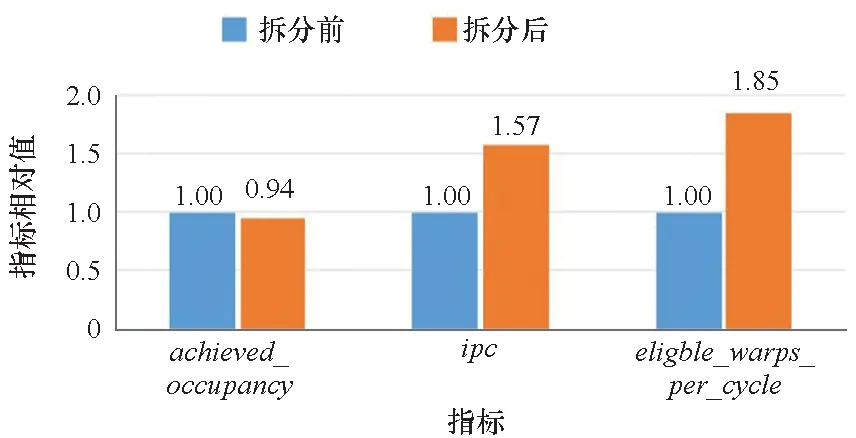
圖5 K6 拆分前后的性能指標對比Fig.5 Comparison of performance metrics before and after K6 separation
3.2 GPU資源管理設計
3.2.1 應用性能分析
風雷程序具有龐大的任務結構,為了更好地進行方法設計,本文不失一般性地選擇了來自 Rodinia 的 CFD Solver[47]。這個任務同樣是面向非結構網格的求解,具有相同的任務屬性且程序結構更加簡短。在未來工作中將對風雷軟件進一步解耦,拆分為更小的kernel,適合多個stream并行。 本文結合 CUDA Toolkit[15],一共選取了 8 個不同的任務。表 2展示了這些任務的基本信息,詳細的介紹將在 4.1節中給出。
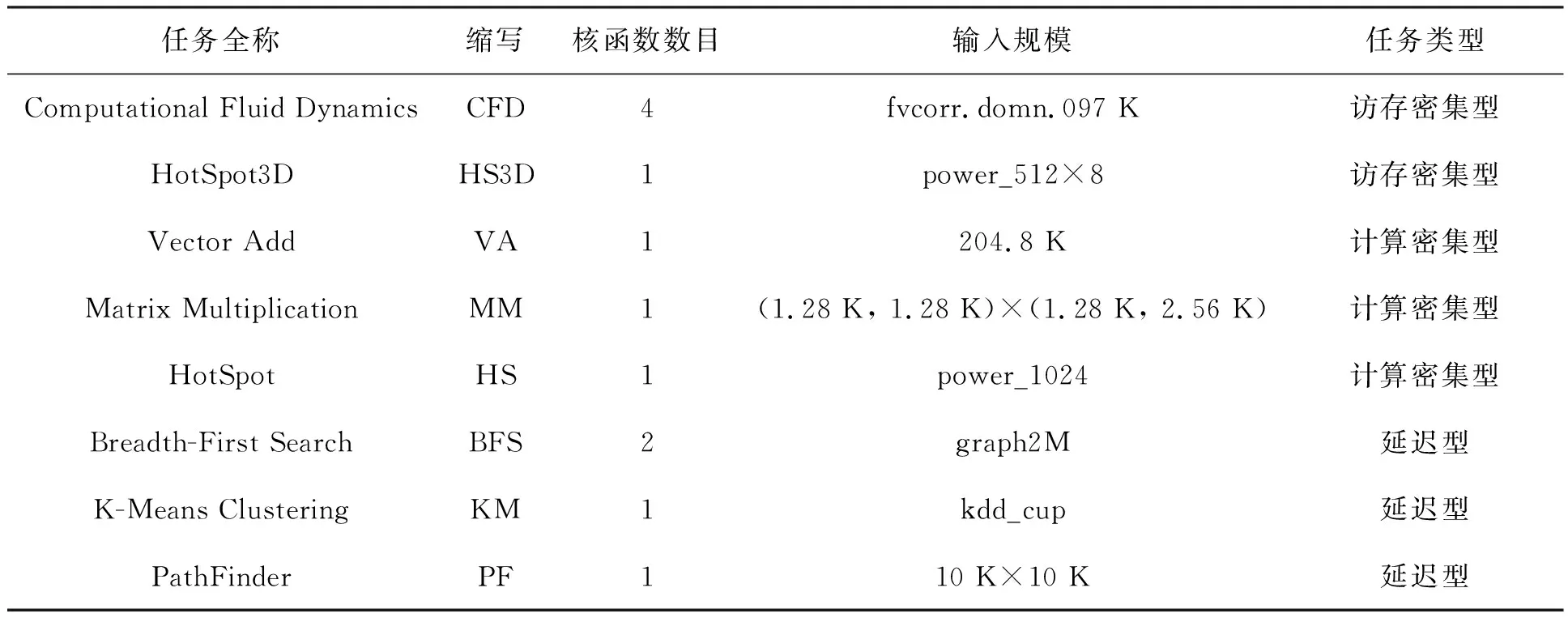
表2 任務介紹
基于 nvprof[18]對這些程序進行分析,在圖 6中展示了這些任務單獨運行時的4個重要的指標,包括衡量指令執行效率的ipc, 衡量 warp 在 SM 上的執行情況的achieved_occupancy和sm_efficiency,以及衡量內存資源使用情況的dram_utilization。不同指標的量綱將被統一映射到 0~10 之間。 nvprof 以核函數為基本單位給出每個核函數的指標,為了對任務有一個整體的衡量,對于有多個核函數的任務,把每個核函數的執行時間占比作為權重,對同個任務內的不同核函數指標進行加權求和。從圖6中可以發現,不同任務之間的性能存在較大的差異。根據不同任務的執行特征,將任務分為3類,分別為計算密集型、訪存密集型和延遲型。CFD 和 HS3D 屬于訪存密集型,因為這兩類任務的dram_utilization指標很高,而ipc較低。VA、MM 和 HS 屬于計算密集型,這類任務的特點是計算占用了程序的大部分時間,訪存相對較少,且具有較高的ipc。HS、BFS 和 KM 屬于延遲型,這類任務對于計算和內存資源的需求都不突出,程序往往是在等待指令或者數據返回。對任務進行分類為后續的混合調度提供了指引。
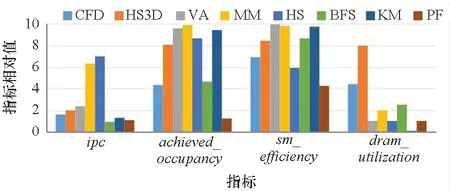
圖6 任務單獨運行時的性能剖析結果Fig.6 Tasks profiling results when run exclusively
3.2.2 GPU 資源使用情況收集
NVIDIA提供了一個基于 NVML[49]的系統管理接口 nvidia-smi 用于設備的管理和監控[50],然而這個管理工具只能得到比較粗略的 GPU 使用率、內存利用率等,無法實現更加精細的監控。 CPUTI[51]可以實現運行過程中的程序分析,但是這會帶來極大的開銷。
對此進行了折中處理,利用任務單獨運行時的 profiling 信息來近似估計任務啟動時GPU 資源的利用情況。例如dram_utilization被劃分為 0~10 之間 10 個等級,那么可以將 GPU 總的 DRAM 可用量設定為gloabl_dram_utilization=10,當啟動一個dram_utilization=3 的任務時,將更新GPU 的資源剩余情況,得到global_dram_utilization=7。可以選擇多種類型的指標來全方面地對 GPU 資 源進行管理。使用了 13 個指標,包括 5 個衡量全局信息的指標(achieved_occupancy,sm_efficiency,ipc,issue_slot_utilization,cf_fu_utilization),2 個衡量計算單元使用情況的(single_precision_fu_utilization,double_precision_fu_utilization),以及 6 個和設備內存利用率相關的指標(sysmem_read_utilization,sysmem_write_utilization,dram_utilization,ldst_fu_utilization,shared_utilization,tex_utilization)。這些指標可以全面地描述一個任務的特性,并且對后續的調度帶來一定的指導意義。對于全局資源的指標,由于單獨運行和多個任務共同執行之間存在較大的差距,通過一個縮放因子γ進行適當的放縮以更好地指導調度。在每個任務啟動之后,將消耗相應的 GPU 全局資源,在任務完成之后,這些資源將被歸還。作為一種近似的收集方式,可以避免帶來過多的統計開銷,又可以從多個層面相對細粒度地分析當前 GPU 資源的使用情況,用于指導調度機制的設計。
3.2.3 混合任務調度
基于任務的性能分析信息和 GPU 資源使用情況收集,設計了一個混合任務的調度方式,其算法流程如圖7所示。
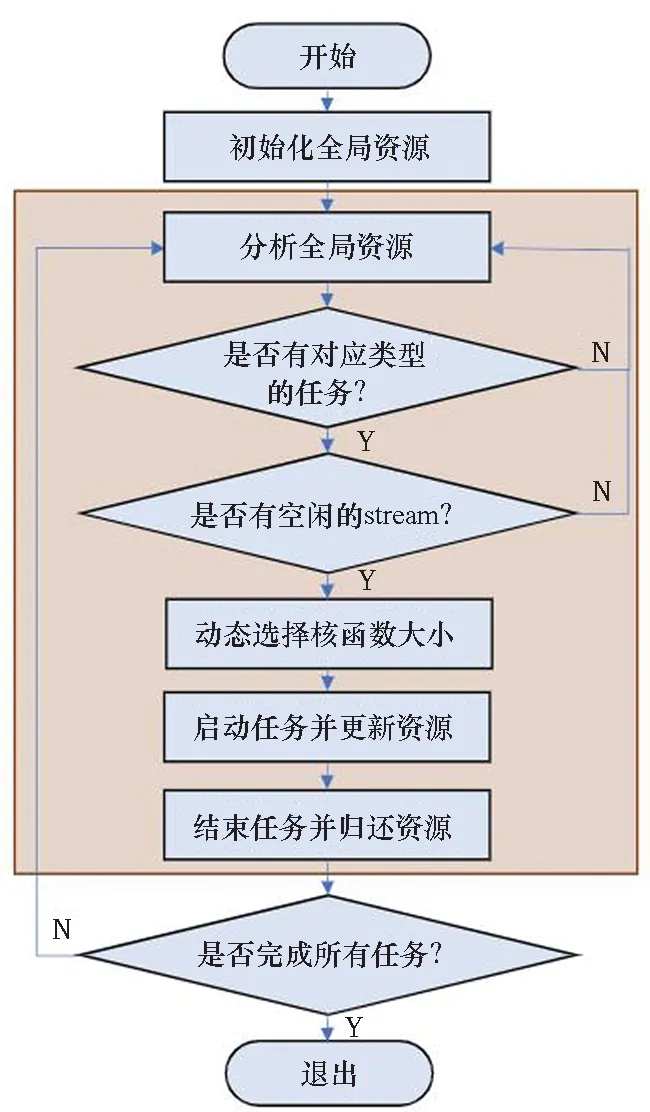
圖7 混合調度流程Fig.7 Flow chart of hybrid scheduling
首先會初始化全局資源, 將 13 個指標所對應的全局資源全部設置為空閑。接著分析全局資源:將對計算相關的指標求均值得到avgcom,同理計算與內存相關的指標avgmem。①當avgcom和avgmem之間的差小于一個閾值α, 那么此時可以啟動任何類型的任務,優先選擇延遲型任務。如果延遲型任務已經都執行完,將會依次選擇計算密集型和訪存密集型任務。②如果avgcom
接著會判斷是否有對應類型的任務,如果沒有,將會持續等待,直到檢測到資源歸還的信號量,那么會重新分析全局資源。
為了實現多任務共同執行,使用 CUDA 提供的流技術(stream)來實現多任務共享 GPU 資源。創建Nstream個 stream,每個 stream 每次會被一個啟動的任務占有,直到任務執行結束。所以如果有合適的任務可以執行,還需要判斷是否有空閑的 stream;如果沒有,將等待現有任務完成釋放 stream。如果有空閑的 stream,那么可以根據當前資源剩余情況選擇核函數的啟動大小。這些核函數的大小是提前設定的,在任務輸入數據固定的情況下,不同的核函數大小將會影響執行的時間和效率。有時候更小的核函數反而可以充分利用 SM 上的碎片資源,使得任務被更快地執行完畢。在輸入不變的情況下,根據資源使用情況動態選擇不同大小的核函數。接著啟動任務,并消耗全局資源。在任務結束之后,歸還全局資源,并判斷是否還有任務未完成,重復循環迭代。
流程圖中的灰色區域將會由Nthread個線程并行執行,涉及線程間的資源鎖和信號量的更新。除了核函數執行部分將在 GPU 上執行,其他部分將在 CPU 上進行計算,這種設計可以充分發揮異構計算的性能,降低調度開銷。
4 實驗分析
4.1 實驗設置
實驗環境:如表3和表4所示,實驗環境是基于 Ubuntu 18.04 LTS。所使用的硬件配置是一張 NVIDIA Volta 100。計算資源上共有 80 個流式處理器,每個流式處理器包括 64 個 FP32、32 個 FP64 和 8 個 Tensor 計算核心。 內存資源上,顯存的大小是 16 GB,并配備 6 144 KB 的 L2 級緩存,每個 SM 上包含 256 KB 的寄存器以及一塊 128 KB 的 L1 和共享內存區域,其中共享內存最多可以擴展為 96 KB。使用的編程架構是 CUDA 10.1,GCC的版本是 7.5.0。
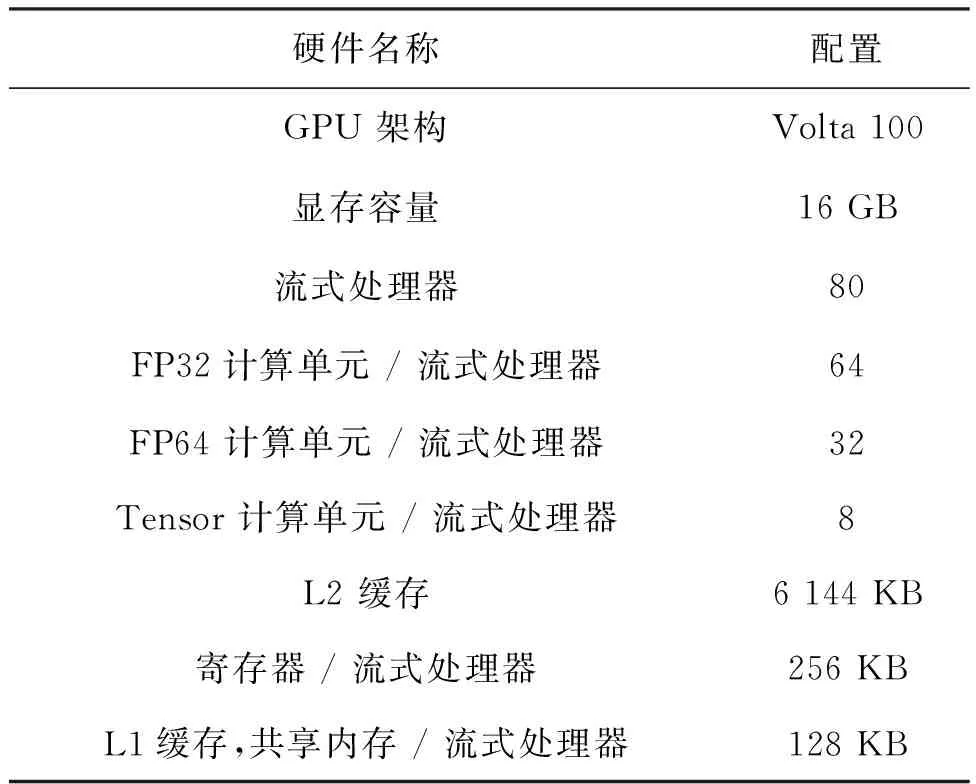
表3 實驗硬件環境

表4 實驗軟件環境
設計實現:為了實現本文的設計,需要微調部分的任務代碼。具體包括以下兩個部分:①由于所有的任務都是使用默認的流來運行,所以需要更靈活地控制增加對流。將原先和內存分配相關應用程序編程接口(如malloc(), free(), cudaMemcpy())以及核函數啟動(kernel <<
任務集選擇:從 CUDA Toolkit[15]和 Rodinia[47]中選擇了 8 個具有代表性的任務,如表2所示。這些任務涵蓋科學計算、機器學習、網絡等方面,每個應用的輸入規模都是固定的,采用了 Rodinia所提供的輸入數據集。對于無須讀取外部輸入的任務,如 Vector Add 和 Matrix Multiplication,采用隨機初始化的方式對輸入進行賦值。 根據每個任務單獨運行時的程序特性,將這些任務分為3類,分別是:訪存密集型、計算密集型和延遲型。由于是面向 CFD 的 GPU 資源管理,所以將 CFD 作為最核心的任務,CFD 任務執行時間是整體運行時間的主要成分。
多任務共享 GPU:借助流技術和 CPU 線程來實現多任務共享 GPU,每個任務會獨占一個 CPU 線程,并且獨占一個流,在任務結束之后,流將被釋放,被其他任務使用。一共有Nstream個流和Nthreads個線程。
參數設置:對于每個任務,將重復執行Nr次。考慮到任務并行的數量過大將會增大資源競爭的可能性,所以將Nstream的數目設置為 3,即同時最多可以有 3 個任務一起共享 GPU 資源。將線程的數目Nthreads設置為 6,以便當所有 stream 都被不同任務占用時,CPU 端可以分析和選擇下一個可以啟動的任務,充分發揮異構的計算能力。縮放因子γ=0.3,閾值α=0.5。縮放因子的作用在于平衡指標的范圍以近似實際資源使用情況,如果不進行縮放,會導致任務之間的共同執行變得更為苛刻。縮放一些指標如achieved_occupancy和sm_efficiency,這些指標在任務單獨運行時具有很高的占用率,縮放這些指標能更好地讓多任務共享GPU,同時更好地近似多任務共享時這些資源的使用情況。α被設置為0.5,表示只有當計算資源avgcom或者訪存資源avgmem的消耗明顯大于另一種資源,占據了超過一半的全局資源時,不宜再啟動相同類型的任務。
基線方法:由于現有GPU資源管理工作大都基于模擬器進行設計和實現[37, 39-40],無法進行公平地對比。不失一般性地,本文參考在現實中廣泛使用的隨機調度方式作為基線方法。使用同樣的多線程和多流方式實現任務之間的并行。基線方法在選擇啟動任務時將采用隨機選取的方式,不會考慮任務的特性和當前 GPU 的資源使用情況,模擬缺乏調度下的 GPU 共享方式。
效果指標:使用執行完所有任務的時間作為最重要的衡量指標,并將給出不同方法在運行過程中的多個指標分析。
4.2 實驗結果及其分析
按照以上的實驗設置,改變Nr的數目進行實驗。當Nr=2 時,每個任務會執行 2 次,由于一共有 8 個任務,所以任務規模是 16,同理當Nr是 3 和 4 時,任務規模分別是 24 和 32。 這些任務可以看成是一個任務池,任務是同時到來的,但是正式被運行和處理取決于調度決策。對于同一種設定,重復執行 3 次,并取結果平均值。這3種設定的實驗結果如圖 8所示,對比了完成批量任務所需時間的加速比。從實驗結果可以發現,當任務數量分別為 16 和 24 時,本文提出的 GPU 資源管理方法可以達到 1.89 和 1.78 的加速比,可以很好地緩解資源競爭問題,提高 GPU 資源的利用率。當任務數量增大時,調度空間變得更加復雜,需要考慮的因素變多,此時加速效果有所下降,但相比基線任務,依舊有 1.24 的加速。總體來看,本文方法在不同任務規模下的平均加速比為可以達到 1.64。
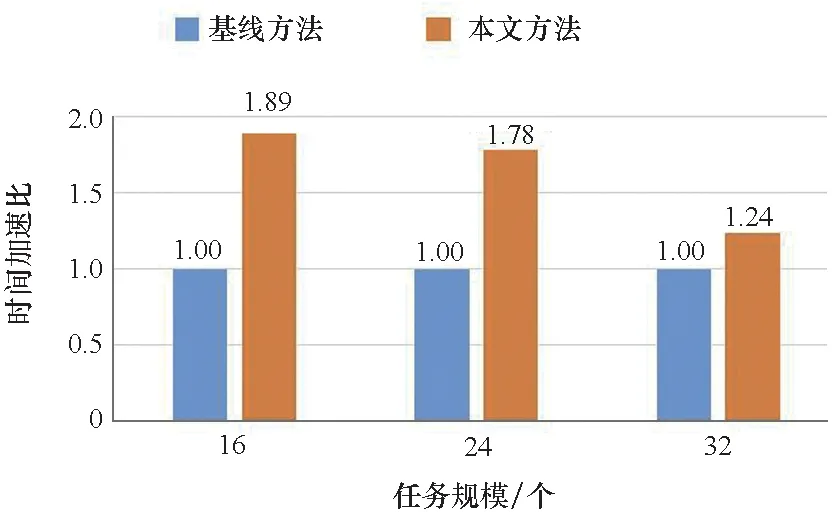
圖8 在不同任務規模下本文所提方法同基線方法在時間上的加速比Fig.8 Time acceleration ratio under different task scale
圖9給出了不同方法運行過程中的性能指標分析,將不同核函數的運行時間占比作為權重,對所有指標進行加權求和,得到最終的結果。 由于不同的指標的量綱并不相同,所以將基線方法的值設為 1,用于正則化。不同于前面提到的13個用于描述任務單獨使用GPU時的資源占用情況和指導調度的指標,在這里使用其中具有代表性的指標用于衡量多任務情況下GPU全局資源的使用情況。從圖9中可以發現,本文提出的資源管理方法在ipc,sm_efficiency和dram_utilization指標上有了一定的提升。ipc的提高表明本文方法可以更好地利用 GPU 的計算資源,sm_efficiency的提升表明本文方法讓更多的 warp 去充分利用SM 的資源,至少一個warp使用SM 的時間有所提高。dram_utilization的提升證明本文方法可以提高內存資源的利用率,這將有利于訪存型任務的執行。achieved_occupancy有所下降,這是由于調度策略發現全局資源使用緊張時,會等待占用資源的釋放后再啟動新的任務。所以每個周期活動的 warp 數目有所下降, 這也使得 GPU 資源競爭的情況有所緩解,間接帶來計算效率的提升。
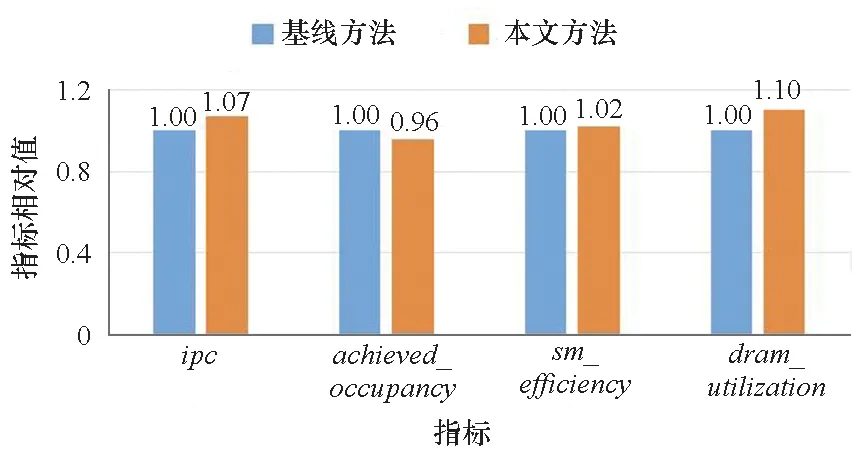
圖9 資源使用率對比Fig.9 Resource utilization comparison
5 結論
GPU的運用提高了 CFD 問題的求解速度,極大地推動了 CFD 的研究和發展,而在求解過程中如何對 GPU 資源有更高效的管理也是一個富有挑戰性的問題。本文提出了一種面向 CFD 的 GPU 資源管理方法,通過分析搭配不同任務的程序特性,設計合理的 GPU 資源收集方法和調度策略,在提高硬件利用率的同時,加速了程序的執行效率。
在未來工作中,更加全面的 GPU 資源收集方法將會被考慮,包括對程序執行過程中的硬件需求有更細致的考慮。還將設計糾錯機制,對近似的信息做進一步的更正。對于程序特性信息的收集,還會考慮更多的指標,包括延遲原因的加入。同時將增大任務數量和規模,設計更具彈性的核函數規模調整方法,可以根據實時的資源使用情況進行動態調整,提高方法的魯棒性和可拓展性。
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
人大建設(2019年12期)2019-05-21 02:55:44
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
資源再生(2017年3期)2017-06-01 12:20:59
環球時報(2017-03-30)2017-03-30 06:44:45
Coco薇(2016年2期)2016-03-22 02:42:52
中國衛生(2015年3期)2015-11-19 02:53:32
Coco薇(2015年1期)2015-08-13 02:47:34
