基于秘密共享的本地多節點聯邦學習算法
2022-10-09 00:53:24王捍貧范耀榕
廣州大學學報(自然科學版) 2022年3期
關鍵詞:模型
王捍貧, 范耀榕
(廣州大學 計算機科學與網絡工程學院, 廣東 廣州 510006)
目前,深度學習技術在各個領域發展迅速,這離不開數據和算力的爆發。深度學習模型的準確度依賴于數據量,由于隱私問題不斷出現,人們逐漸重視數據的隱私安全,與此同時,政府也頒布隱私保護法律法規(如:GDPR[1]、《中華人民共和國網絡安全法》[2]等)進一步保護用戶數據安全,導致數據不斷分散出現“數據孤島”現象,從而無法聚集數據來訓練高精度模型。
對此,Google 于2016年提出聯邦學習(Federated Learning, FL)理論[3]。在FL系統中,參與者通過在自己的私有本地數據上執行本地訓練算法,并僅與中心服務器共享模型參數,此中心服務器用作中央聚合器,以適當方式聚合本地參數更新后與每個參與者共享聚合的更新。然而參與者與中心服務器之間存在高頻通信及長傳輸延遲,這導致FL不得不面對通信效率問題[4]。
根據應用場景的不同,聯邦學習可分為跨設備聯邦學習(Cross-device federated learning)和跨數據庫聯邦學習(Cross-silo federated learning)[5]。聯邦學習的通信拓撲圖一般為星形拓撲,對于跨設備聯邦學習而言,參與訓練的客戶端為數量龐大的IoT設備或者移動設備,并且具有本地數據量少、通信不穩定和客戶端間不互信的特性,這往往會對中心服務器的通信造成巨大的壓力。對此,最近的研究提出了分層聯邦學習框架(Hierarchical Federated Learning, HFL)[6-7],在客戶端-中心服務器的結構中加入邊緣服務器,形成客戶端-邊緣服務器-中心服務器結構,在訓練過程中相鄰的客戶端將模型發送到近端邊緣服務器進行聚合,然后由邊緣服務器發送局部聚合模型到中心服務器進行最終聚合,從而減少中心服務器的通信壓力。目前的HFL主要是利用物理層的中間設備充當邊緣服務器,如Mehdi等[8]利用物理層面的小型蜂窩基站(Small-cell Base Station, SBS)來充當邊緣服務器,大型基站(Macro-cell Base Station, MBS)作為中心服務器,構建分層聯邦學習訓練架構,移動用戶將與最近的SBS進行通信形成局部交流結構,SBS聚合模型后再與MBS通信從而減少MBS的通信量。而在跨數據庫聯邦學習的場景中,其客戶端數量通常在100個以內,每個客戶端具有數據量大、通信可靠、計算資源豐富和客戶端間不互信等特性,并且都參與每個輪次的訓練。以往的HFL在該場景下反而可能會由于額外增加的邊緣服務器聚合操作造成通信效率下降[6-8]。
本文關注在跨數據庫聯邦學習環境下客戶端與服務器之間的通信效率問題。在該場景下,客戶端內部通常擁有多個本地計算資源,如高性能計算機,且本地的內部通信相對于外部網絡WAN而言具有速度更快、更可靠和可信任的優點。傳統的聯邦學習框架在該場景下,客戶端上僅利用部分計算能力訓練模型,并不能夠充分地利用其計算資源訓練模型。而HFL的結構則根據跨數據庫聯邦學習內部通信的特性與優點,可以很好地利用客戶端本地的計算資源,通過客戶端將本地的多個計算資源生成多個節點參與到全局聯邦學習的訓練中,形成本地節點-客戶端-中心服務器的多級分層聯邦學習結構,有效地利用跨數據庫聯邦學習的計算資源來加快訓練速度,從而提高通信效率。
此外,雖然FL允許參與者將其原始數據保存在本地,為客戶端的數據隱私提供了保護,但最近的工作表明,它不足以保護本地訓練數據的隱私免受成員推理攻擊[9]、屬性推理攻擊[10],訓練過程中交換的模型參數與梯度更新仍然是重點攻擊目標[10-11]。Gei等[11]通過余弦相似性和對抗攻擊策略從梯度信息中恢復訓練時輸入一批圖像,并證明從梯度中重建輸入圖像與模型的深度架構無關。
與傳統架構一樣,HFL架構中傳輸的模型參數或梯度仍面臨著潛在的隱私泄露風險,不足以保護訓練數據的隱私免受推理攻擊及數據重構攻擊。為保護FL系統免受這些隱私攻擊,目前已有學者提出解決方案,如Abadi等[12]在神經網絡模型訓練過程中添加差分隱私噪聲來消除訓練數據的隱私,后續的工作在此基礎上進行適應改造,將該方法移植到聯邦學習系統中,如Truex等[13]提出LDP-Fed,用于實現客戶端能自主定義本地差分隱私預算,在客戶端上傳模型時添加隱私噪聲,實現相對于中心式差分隱私更為優秀的隱私保護功能。Lu等[14]提出了一種在HFL場景中應用差分隱私的隱私保護方案HFL-DP,在客戶端上傳模型時,添加滿足局部差分隱私的噪聲進行擾動,并且采用Abadi的時刻記賬方式來跟蹤累計的隱私損失。又如Moreau等[15]將Abadi的方法應用至跨數據庫聯邦學習中,并提出了一種混合策略,即客戶端根據本地數據量選擇固定或自適應的隱私預算策略。然而差分隱私方案會帶來噪聲,隨著噪聲變大模型精度也逐漸降低,從而導致模型難以收斂[4]。另外一個方向為采用安全多方計算來進行隱私保護,Bonawitz等[16]提出了一種FL的安全聚合方法,通過使用偽隨機數、Shamir的秘密共享[17]和對稱加密來禁止服務器直接訪問客戶端模型。然而該方法需要可信服務器,并且需要較高的通信代價。更進一步,David等[18]基于Bonawitz等人的工作,將差分隱私與安全多方計算結合,用于聯邦學習的安全訓練過程,即客戶端向訓練好的模型參數添加差分隱私噪聲以及基于加密原語生成的隨機數,在中心服務器進行聚合操作時,對加密模型進行聚合,即可將隨機數消除得到聚合模型。但是該方法依舊向模型添加了額外的差分隱私噪聲。Duan等[19]提出了一種采用秘密共享策略的深度模型隱私保護方法,各個客戶端將本地模型的梯度更新進行秘密共享,由中心服務器聚合秘密,從而得到梯度聚合結果。然而,該方案并未處理客戶端掉線問題。目前的隱私保護方案中,采用安全多方計算的方案并不會在訓練過程中額外添加噪聲,相比于差分隱私方案其能夠得到準確的模型,但是也存在相應的缺點,如需要較高的通信代價,需要依賴可信服務器與沒有處理客戶端掉線情況等。因此,設計一種高效且保護隱私的FL方案,以防止數據的隱私泄露至關重要。
在對模型精度要求更高的需求下,安全多方計算方案能更好地發揮數據的價值。秘密共享作為安全多方計算中應用場景較為廣泛的方法,相比于其他安全多方計算方法而言算法實現更為簡單,且在聯邦學習系統中產生的代價相對較小[20],故而本文采用秘密共享方法進行保護跨數據庫聯邦學習中的數據隱私安全,通過優化加密過程來減少秘密共享所產生的通信代價。
因此,針對跨數據庫聯邦學習的通信效率問題,以及目前聯邦學習隱私保護方案中存在的問題,本文提出了一種基于秘密共享的本地多節點聯邦學習算法Mask-FL。本文假設用戶數據分布在不同的客戶端上,例如電商平臺、銀行或金融機構,它們擁有大量不同的用戶數據。每個客戶端將生成多個本地節點,然后將用戶數據劃分成多份分布在本地節點上,每個客戶端進行本地訓練時,由本地節點采用劃分的數據訓練模型。在訓練過程中通過秘密共享方式解決模型上行傳輸的隱私泄露問題。實驗結果表明,該算法在保護隱私的同時具有較高的通信效率。本文的主要工作如下:
(1)提出本地多節點跨數據庫聯邦學習框架。在客戶端-服務器的結構上加入本地多節點結構,每個客戶端根據自身的計算資源能力生成多個本地節點,并將本地數據進行切分后設置在各個本地節點上,每個本地節點并行參與到全局聯邦訓練。針對節點的數據量分配問題,設計了一種基于計算能力的數據切分算法,客戶端根據各節點計算能力進行數據切分,以減小數據量不平衡帶來的影響。
(2)提出基于秘密共享的自適應掩碼加密協議。在本地多節點跨數據庫聯邦學習框架的基礎中,通過秘密共享的方式得到可復用的安全自適應參數掩碼,客戶端通過對模型添加掩碼以保護模型參數安全后,再發送至服務器進行聚合。在誠實且好奇的安全設置下,證明了本協議能夠對抗來自客戶端與服務器的威脅。
(3)將Mask-FL算法用于訓練卷積神經網絡模型過程,通過對Mask-FL的各個參數進行獨立實驗,以及對比3種不同聯邦學習算法,證明了本文提出的Mask-FL在保護隱私的前提下能保持相對較高的準確率,并且減少了全局通信輪次,有效地提高了聯邦學習模型訓練速度。
1 背景知識
1.1 聯邦學習
聯邦學習提供了使用分布式數據訓練機器學習模型的能力,參與實體之間無需共享原始數據。假設(D1,D2,…,Dn)是分布式數據集,分別分布在n個用戶(O1,O2,…,On)上,在聯邦學習中,每一個用戶都獨立擁有一個數據集,并且僅使用本地的數據獨立訓練一個ML模型,而不對外部公開本地數據。每個用戶通過本地訓練得到的模型參數被收集到服務器(一個中心實體/機構)中,該服務器聚合所有收集到的模型參數以生成全局模型。全局模型的精度Afed應非常接近在服務器上使用所有數據集訓練得到的模型精度Actr,這種關系可用公式(1)表示,其中,δ是一個非負實數[20]。
|Afed-Actr|<δ
(1)
標準的FL訓練算法在多輪訓練中進行,典型的聯邦學習步驟如下:
(1)服務器初始模型,下發到各個客戶端;
(2)每個客戶端根據各自的數據訓練本地模型;
(3)每個客戶端將其模型權重發送到受信服務器;
(4)服務器計算模型平均權重得到共享模型;
(5)服務器將共享模型返回給所有客戶端;
(6)客戶端從共享模型開始,重新訓練本地模型。
在提供高度準確推斷的同時,保護敏感用戶信息非常重要。例如輸入法提供商可以使用聯邦學習來提高客戶輸入推薦詞的精確度。各提供商不必采集客戶設備上的隱私輸入詞來訓練自己的推薦算法,而是結合其模型創建共享的高頻詞推薦機制,無需共享其個別客戶的隱私輸入詞。然而,惡意方仍然有可能通過從訓練模型的權重或參數中推斷出訓練數據集的細節來潛在地損害個人用戶的隱私[9-11]。
1.2 安全多方計算
安全多方計算理論是姚期智先生為解決一組互不信任的參與方在保護隱私信息,以及沒有可信第三方的前提下,協同計算問題而提出的理論框架。目前,主要通過3種不同的框架來實現:不經意傳輸、秘密共享和閾值同態加密。不經意傳輸協議和閾值同態加密方法都使用了秘密共享的思想[20]。
秘密共享(Secret Share, SS)是指通過將秘密值分割為隨機多份,并將其分發到不同方來隱藏秘密值的一種概念。每一方只能擁有一個通過共享得到的值,即秘密值的一小部分。根據不同場景,需要所有或者一定數量共享值才能重新構造原始的秘密值[17]。圖1給出了如何使用秘密共享的簡單示例。
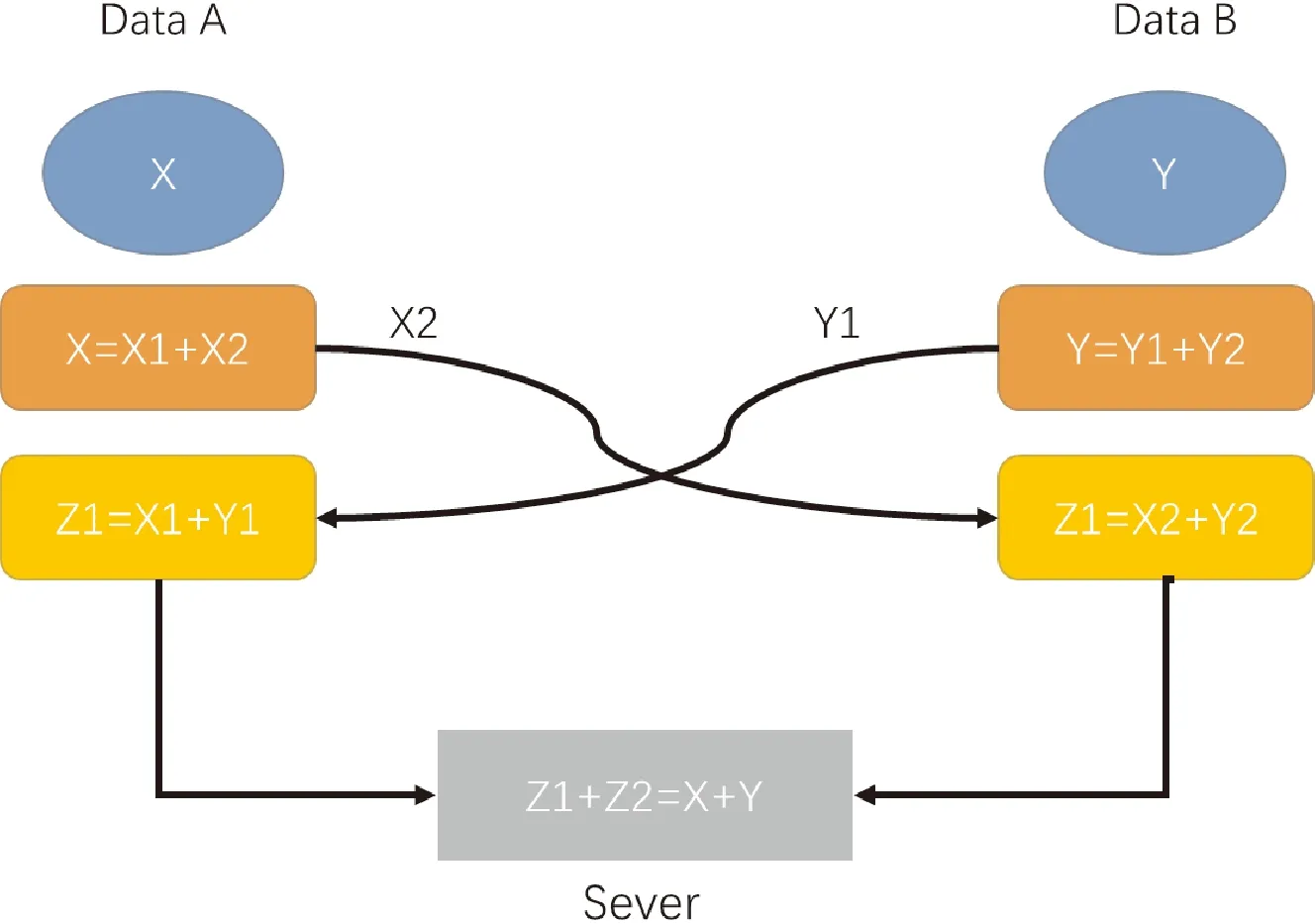
圖1 秘密共享的簡單示例
由圖1所知,2個數據源分別擁有數字X和Y,服務器想要知道X+Y之和,但對X和Y一無所知。該過程可以描述如下:首先,將原始數據分解為2個子部分,一個子部分在雙方之間交換,然后計算剩余子部分與另一方部分的和。最后,對計算結果進行匯總,得到原問題的解。在這個過程中,原始數據不會被公開,因此,可以在保護數據隱私的前提下完成求和運算。
2 基于秘密共享的本地多節點聯邦學習算法
本章介紹本文提出的聯邦學習算法Mask-FL,主要分為3個部分,第一部分為本地多節點跨數據庫聯邦學習訓練框架,第二部分為基于秘密共享的自適應掩碼加密協議,第三部分為聯邦學習算法Mask-FL,將掩碼加密協議嵌入本地多節點跨數據庫聯邦學習訓練框架,并進行更為詳細全面的設計。
2.1 本地多節點跨數據庫聯邦學習訓練框架
跨數據庫FL自然適合企業對企業(B2B)場景,其中每個數據庫可以是公司或組織,而跨設備FL對應于企業對客戶(B2C)模式。跨設備FL通常涉及大量用戶,故通信成本可能是一個瓶頸,而跨數據庫FL只有幾個參與方(通常少于10個),因此,對于通信要求相對不大。本文基于跨數據庫設置FL,在這種情況下應該考慮計算成本,因為作為企業的每一方都擁有比個人設備更為龐大的數據,并且計算能力也比單一設備要強,然而當前的聯邦學習框架在數據庫節點上僅僅訓練單一的模型,并不能夠充分地利用計算資源。雖然有分布式機器學習方法的輔助,但是在聯邦學習中仍存在缺陷,即不能夠直接進行快速的訓練,因此,本節主要為了解決在FL中充分利用客戶端的計算能力問題,設計了新型的訓練結構框架LocalNodes-FL,以將數據和算力利用起來,加快聯邦學習模型的訓練,進而減少訓練過程中的通信開銷。
考慮在FedAvg聯邦學習的框架上,通過改變其結構來有效提高資源利用效率和通信效率。框架如圖2所示,結構采用本地節點-客戶端-中心服務器的方式。通信過程存在于客戶端內部、客戶端與客戶端、中心服務器與客戶端。本地節點由于是處于同一個數據庫客戶端環境下,網絡傳輸的延遲影響較小,其中的通信開銷可忽略不計。而主要的通信開銷產生于中心服務器與各個客戶端之間。

圖2 本地多節點跨數據庫聯邦學習示例
考慮n個客戶端參與訓練的聯邦學習,本地數據集設為(D1,D2, …,Dn),各客戶端根據本地的m個計算資源能力生成m個本地節點,將本地數據劃分成m份并放置在本地節點上,有
(2)
在本地節點訓練模型過程中,各個對等節點的訓練是同步進行的,那么在客戶端等待收集各個節點訓練完成時,最長等待時間為本地節點中訓練時間最長的節點。而模型訓練時間跟數據集大小成正比關系,跟節點計算能力成反比關系,因此,在數據劃分時,為了能夠減少客戶端等待時間,本文設計了數據集切分算法——DataSplit,以讓本地各個節點訓練時間相近,從而能夠提高整體的訓練速度。偽代碼如算法1。
首先,客戶端確認本地擁有的計算資源節點數量m,從中心服務器獲取初始化模型后,從本地數據集中采樣m個batch大小為B的樣本數據分配到各個節點上,每個節點采用該batch進行訓練,記錄節點訓練所需時間tj。所有節點訓練完成后,得到各個節點訓練所耗時間序列。計算節點計算能力系數
(3)
客戶端根據每個節點的計算能力系數進行劃分數據集
|Dj|=cj|D|
(4)
在進行數據集劃分時,各個節點所分配的數量為|Dj|,但是劃分的數據是從客戶端數據集中隨機采樣的,并且每個節點內的樣本都不重復。

算法1 基于計算能力的數據切分算法———DataSplit輸入: 客戶端數據集D,計算資源節點集M,服務器下發模型w0輸出:節點數據集|Dj|1:Client executes:2: sample m batches from the dataset and dis-tribute them to each node3: for each node j∈M in parallel do4: w1←ClientUpdate(j,w0)5: Statistic time tj ∥統計訓練時間6: End for7: calculate dataset rate of nodes:8: cj←t1tj*∑mk=1t1tk9: for each node j∈M do:10: |Dj|=cj|D|11: End for
2.2 基于秘密共享的自適應掩碼加密協議
在聯邦學習訓練過程中,按照參與訓練的主體劃分,存在著來自非誠實服務器以及其他參與訓練方的威脅,所以為了解決來自這些主體的威脅,本節在LocalNodes-FL框架上設計基于秘密共享的自適應掩碼加密協議,加入了聯邦加權平均算法的思想。該協議用于一組固定的客戶端(P1,P2, …,Pn),還有一臺服務器S的深度神經網絡交互訓練。
安全假設:①假設所有客戶端與服務器都采用安全的通道進行通信,如TLS/SSL;②所有客戶端和中心服務器都是誠實且好奇的[21],誠實且好奇的定義如下:誠實且好奇的客戶端和中心服務器會根據協議執行相應步驟,但是,它們也會嘗試推斷出其他客戶端的隱私數據;③每個客戶端至少生成m(m≥2) 個節點參與聯邦學習過程。
為了向服務器隱藏每個客戶端的模型權重,協議采用安全多方計算技術中的秘密共享技術,在該協議中,客戶端協同工作,以加密的方式向服務器發送各自的模型參數或者模型更新梯度。在模型從中心服務器下發到客戶端后,每個客戶端生成一個與模型參數形狀相等的掩碼Mask,例如對于一個具有10 M個參數的模型,那么也相應生成一個10 M個參數的掩碼,即
shape(Mask)=shape(w)
(5)
由于模型參數與掩碼值可能相差過大,進而會出現一種危機:服務端接收到本地掩碼模型后,通過比對原始模型,判斷掩碼模型參數是否出現異常值,那么將異常值去掉突出部分得到原始模型參數,某種程度上也會反映出本地真實模型,因此,本文提出自適應的掩碼生成方案,將生成的掩碼值界限設置為[min(w), max(w)],使得模型值與掩碼值在同一范圍區間內,進而消除掩碼與模型參數之間的差距,從而更好地防止服務器從客戶模型中推斷私人數據。模型掩碼采用偽隨機數發生器進行生成:
Mask=PRG(a)z
(6)
其中,z代表PRG(·)的輸出維度(在本協議中,其維度等于模型的參數數量),PRG(·)是偽隨機數生成器,輸出空間限定為[min(w), max(w)],a為模型參數值。
協議如圖3所示,該圖為3個客戶端參與的掩碼交換過程。
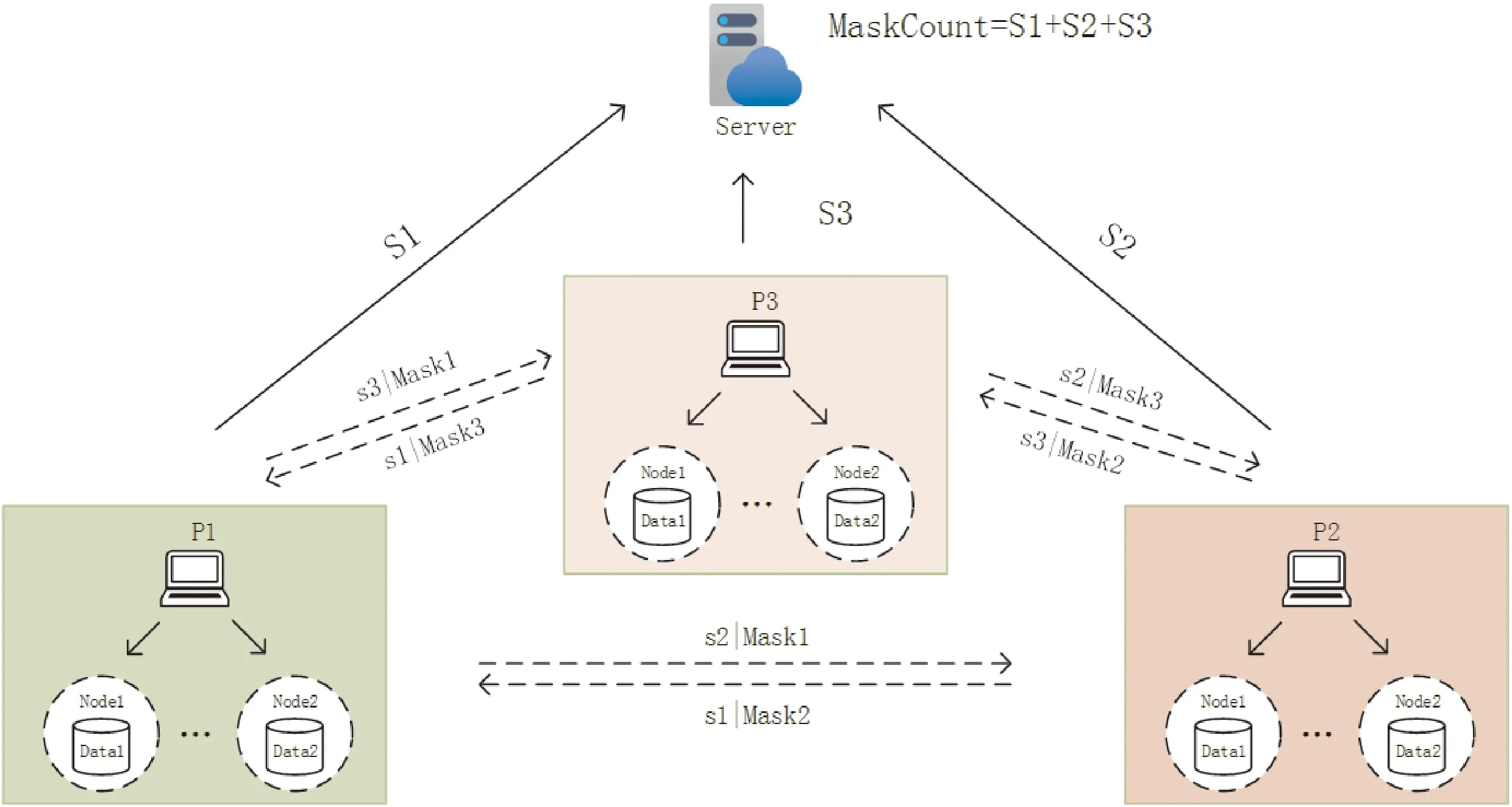
圖3 三方參與掩碼加密協議過程
協議具體流程如下:
(1)節點生成掩碼
自適應掩碼加密的目標是保護單個客戶端的模型參數,每個參與訓練的節點按照式(6)生成本地掩碼。
(2)進行秘密共享求和
每個客戶端的各個本地節點都生成本地掩碼后,進行求和,即
(7)
得到客戶端掩碼和,每個客戶端對掩碼和執行秘密共享協議,將Maski分別拆成n份Maski= {si,1,si,2, …,si,n},分發給n個客戶端。客戶端收到各個客戶端發來的部分秘密后,對部分秘密進行求和,即
(8)
得到部分秘密和,接著將其發送到中心服務器。
(3)服務器計算掩碼和
中心服務器接收來自各個客戶端發送的部分秘密和之后,計算掩碼和
(9)
(4)模型添加掩碼
節點在本地訓練完模型后,向模型添加權值|Di,j|,其代表客戶端劃分到本地節點的數據集大小,再向模型w添加自適應掩碼。即對模型參數w做如下處理:
(10)
然后客戶端將本地掩碼模型聚合:
(11)
將本地掩碼模型發送至中心服務器,|Di,j|為局部節點劃分到的數據集大小,并且客戶端發送|Di|至中心服務器。通過對模型參數添加自適應掩碼,從而保護客戶端的訓練模型參數在交互過程中不被泄露。
(5)模型解碼
中心服務器收到每個客戶端發來的掩碼模型和數據集值,然后執行模型解碼:
(12)
(13)
(14)
(15)
(16)
得到聚合模型。
本文協議能夠讓客戶端在每次模型迭代中重用掩碼,因此,客戶端在協議開始時只需要與服務器和其他客戶端進行一次通信。在隨后的迭代中,每個客戶端只需與服務器通信,當然,隨著訓練的輪次增大,模型參數的最值區間改變,那么相應的,掩碼值也應更新,并且掩碼值定期更新能為系統帶來更高的安全性。
協議安全性分析:
本節證明了在誠實且好奇的客戶端和中心服務器參與攻擊下,本協議是安全的。
定理1(抵御服務器攻擊) 服務器不能推斷出節點的模型參數。
證明在上述聯邦學習訓練過程中,服務器可以獲得客戶端上傳的加權聚合掩碼模型。假設服務器可以推斷出wi,j,那么服務器需要推斷出節點的參數掩碼和權值。首先,推斷出基于a的偽隨機數生成的掩碼Maski,j,a是節點的參數,服務器需要與節點進行相互串謀才能獲取a,這與該攻擊方式相矛盾。故而服務器無法推斷出節點的模型掩碼Maski,j;其次,服務器破解權值|Di,j|,由于假設③,|Di,j|≠|Di|,則需要推斷出客戶端給該節點分配的數據量,而客戶端在本地內進行切分的方法是根據節點的計算能力進行分配的,服務器需要與客戶端進行合謀才能破解,節點是屬于客戶端的,這與該攻擊方式相矛盾,因此,服務器無法推斷出節點的權值|Di,j|。
綜上所述,在中心服務器攻擊中,服務器無法推斷出節點的模型參數。
定理2(抵御節點攻擊) 惡意客戶端不能推斷出節點的模型參數。
證明假設惡意客戶端在每次訓練迭代過程中,根據聚合模型結果推斷出其他客戶端的本地節點模型參數,但是在協議中,模型聚合結果是由每個客戶端本地節點的模型加權聚合平均得到的,那么惡意客戶端需要推斷其他客戶端生成的本地節點個數mi及劃分到本地節點的權值|Di,j|。首先,推斷所有其他客戶端生成的本地節點個數mi,m是每個客戶端根據本身計算資源生成的節點,其他客戶端并不知曉,惡意客戶端需要與所有客戶端相互勾結才能獲取mi,這與該類攻擊方式不相符,故惡意客戶端無法推斷出其他客戶端生成的本地節點個數mi;其次,惡意客戶端推斷本地節點的權值|Di,j|,|Di,j|是每個客戶端的隱私數據集大小,只有其本身知曉,惡意客戶端需要所有客戶端相互勾結才能獲取,與該類攻擊方式不符,因此,惡意客戶端無法推斷出其他客戶端的本地節點權值|Di,j|。綜上所述,無法從聚合結果推斷出其他客戶端本地節點的模型參數。
定理3(抵御h≤n-1個客戶端和服務器的共謀攻擊) 服務器和客戶端不能推斷出其他客戶端本地節點的模型參數。
證明首先從服務器角度證明。假設中心服務器可以推斷出其他客戶端本地節點的模型參數wi,j。服務器收到來自客戶端發送的加權聚合掩碼模型,服務器需要推斷出本地節點添加的掩碼Maski,j和權值|Di,j|,服務器要求與之勾結的h個客戶端上傳各個節點的掩碼值,服務器擁有MaskCount,當h=n-1時,則僅能推斷出客戶端內所有本地節點的模型掩碼和,無法獲得本地節點的單一模型掩碼。通過消除加權聚合掩碼模型的掩碼,得到客戶端的加權聚合模型,而服務器要破解本地節點的權值|Di,j|,需要與客戶端進行合謀,與攻擊方式不符。當h 其次,從客戶端角度證明。①客戶端可以從聚合結果進行推斷。假設h個客戶端相互合謀,從聚合結果推斷出其他節點的模型參數。h個客戶端需要推斷其他客戶端生成的本地節點個數mi以及劃分到本地節點的權值|Di,j|。與服務器合謀獲知其他客戶端發送的客戶端總權值|Di|,然而h個客戶端仍需與所有客戶端進行勾結才能獲取|Di|和mi,與該攻擊不符,故客戶端不能從聚合結果中推斷出節點的模型參數。②客戶端可以從加權聚合掩碼模型中進行推斷。與上述服務器角度證明相同,故客戶端不能推斷出其他客戶端本地節點的模型參數。綜上所述,誠實且好奇的客戶端無論從聚合結果進行推斷還是從客戶端上傳的結果進行推斷,都不能推斷出其他客戶端的節點模型參數。 總之,服務器和客戶端不能推斷出其他客戶端本地節點的模型參數。以上3個定理證明了基于秘密共享的自適應掩碼加密協議能夠有效地抵御服務器攻擊、客戶端攻擊以及服務器與客戶端相互合謀的共謀攻擊。因此,本文提出的結合自適應掩碼加密的本地多節點聯邦學習隱私保護方案是安全的。該方案能夠保證誠實且好奇的服務器和客戶端都不能獲取其他誠實客戶端的隱私數據。 集成本地多節點訓練框架和自適應掩碼加密協議,考慮客戶端掉線問題與全聯邦學習訓練流程,在本節給出完整的Mask-FL聯邦學習算法。訓練分為2個階段,第一階段為初始化階段,第二階段為聯邦學習訓練階段。具體如算法2所示。 算法2 Mask-FL輸入:客戶端{P1,…,Pn},服務器S,初始模型參數w0,全局訓練輪次R,掩碼更新閾值T,本地訓練迭代次數E,客戶端數據集{D1,D2,…,Dn},客戶端本地節點集{m1,m2,…,mn} 輸出:結果模型w1:S initialization model w0 and deliver the model to each client.2:Mask-FL.Setup:3: for each client i∈Pn do:4: {Di,j},{wi,j}←DataSplit(Di,w0) ∥詳見算法15: Maski,j←PRG(wi,j) ∥采用偽隨機數生成器生成與模型相同的模型掩碼6: Maski←∑mj=1Maski,j7: Split {si,1,si,2,…,si,n}←Maski8: Send share si,n to Pn9: receive share and merge them:10: Si←∑nj=1sj,i11: Send Si, Di to server12: End for13: Server do:14: MaskCount←∑ni=1Si15:Mask-FL.Train:16: While r≤R do:17: for each client i∈Pn in parallel do:18: for each node j∈mi in parallel do:19: wjr+1←ClientUpdate(j,wr), do it for E time20: wjr+1 ←|Di,j|*wjr+1+Maski,j21: End for22: wir+1 =∑mj=1wjr+1 and send to server23: End for24: Server do:25: wr+1 ←∑ni=1wir+1 26: wr+1←1∑ni=1|Di|(wr+1 -MaskCount)27: Send wr+1 to all clients28: r++29: if r % T == 0 or client dropout: 30: Run Mask-FL.Setup (wr+1)31: End while32:ClientUpdate(k, w): ∥ Executed on client k33: for each local epoch i from 1 to E do:34: batches←(data D split into batches of size B) 一個完整的訓練周期如下: (1)初始化模型參數。中心服務器初始化模型,并且生成模型初始化參數,分別為客戶端本地節點的訓練迭代次數、全局通信輪次以及學習率,并且將模型和這些參數發送至所有參與訓練的客戶端,客戶端根據本地計算資源能力將本地數據集進行隨機劃分,每一個計算資源生成一個節點并擁有一個劃分后的數據集。 (2)節點采用一個batch的隱私數據集進行單次訓練,每個節點根據模型參數生成模型掩碼,采用秘密共享機制與其他節點分享模型掩碼秘密,各節點再將獲得的掩碼秘密求和后發送到服務器,服務器結合各部分掩碼秘密和獲得總掩碼。 (3)節點采用隱私數據集進行本地訓練,獲得模型參數后加權,并且添加本地掩碼得到掩碼模型,發送至客戶端,客戶端聚合后再上傳至中心服務器并且發送客戶端本地參與訓練的數據集數量。 (4)中心服務器檢測是否有離線客戶端,①沒有離線客戶端,直接將所有客戶端上傳的掩碼模型相加并采用總掩碼和解密后進行平均得到全局模型;②存在離線客戶端,則其他客戶端重啟步驟2~步驟5,然后計算全局模型,下發全局模型至各個客戶端。當全局迭代次數達到掩碼更新閾值時,各個客戶端按照步驟2更新掩碼。 如果訓練過程中,有客戶端中途退出,則采用步驟2重新生成新的掩碼并將其保存下來,若在下一次迭代掉線客戶端重新上線,則可啟用上一次掩碼值而不用重新運行步驟2。反復迭代,直到模型收斂或達到最大訓練輪數。 在本章中對Mask-FL進行實驗以評估其性能指標,同時設置對照實驗組:聯邦平均算法(FedAvg)[3]、結合差分隱私的聯邦學習(DP-FL)[12]、結合秘密共享方案的聯邦學習(SS-FL)[19]。為了進行相同背景的對比,3個對照實驗組的超參數、模型及數據集都設置成與Mask-FL一致。 本文在分布式數據集上使用深度神經網絡AletNet進行訓練來模擬,模型參數數量為3.87 M。實驗數據集采用MNIST手寫圖像數據集,該數據集由28*28像素的60 000張訓練圖片和10 000張測試圖片組成,一共10個數字類,其中,每類各有6 000張訓練集和1 000張測試集。實驗運行環境為一臺配有Tesla P100 PCIe 16GB GPU的PC,內存為32 GB。各節點訓練模型使用SGD作優化器。 在實驗中默認訓練數據集batch為64,測試集batch為1 000,學習率為0.01,全局訓練輪次round為100。對于Mask-FL中客戶端的本地節點進行本地迭代訓練次數epoch設置為1,其他框架的客戶端本地訓練次數epoch為1。在本文DP-FL對照實驗中,設置隱私預算松弛度δ=1e-5,訓練抽樣集比例q=0.01,clip=8,由于抽樣集比例為0.01,為能與其他算法在同等情況下進行比較,控制其模型訓練的樣本數與其他算法相等,因此,設置DP-FL的本地訓練輪次epoch=100。 Mask-FL、FedAvg、SS-FL和DP-FL均采用1個中心服務器、3個客戶端的結構進行訓練。對60 000張圖片的MNIST訓練集進行打亂后隨機采樣切分成3個訓練集[20 000,20 000,20 000],每個客戶端擁有一個訓練集參與聯邦學習訓練。測試集只放置在中心服務器,在一個輪次訓練結束后,中心服務器使用測試集進行測試以觀察聚合模型的效果。 本文分別從協議通信成本、訓練時間、模型訓練精度等角度對Mask-FL進行評估與分析。 通過實驗來評估協議,可以構建一個精確的過程,以確定在實際場景中運行協議需要多長時間。為了實現這一點,本文統計了Mask-FL各個節點及服務器交流過程中協議各個步驟的計時結果,包括節點上的掩碼初始化平均時間、掩碼交換時間、加密平均時間、訓練平均時間,服務器上的模型聚合平均用時、解碼平均用時、模型下發平均用時,并且統計了FedAvg算法各個訓練過程的平均耗時。雖然實驗是單線程的,但它確實跟蹤每個節點每個動作的獨立時間,并確保實驗不允許在同一時間內執行多個活動。因此,可以斷言這些時間應該是對協議完整、分布式實現的合理估計。 實驗采集了100個通訊輪次FedAvg和Mask-FL的各階段平均用時,如圖4所示。對于Mask-FL算法,基于秘密共享的自適應掩碼協議的掩碼初始化過程耗時為11.027 9 ms,在訓練過程中,模型在本地訓練的耗時為1 056.182 6 ms,相比之下,本協議對模型的加解密過程所耗費的時間僅為2.771 4 ms,說明本協議加密過程所產生的耗時并未對FL系統產生明顯的時間開銷。并且通過2.2節中對協議進行的安全性證明分析,說明基于秘密共享的自適應掩碼協議消耗的時間不僅極小,而且能夠有效地保護客戶端數據隱私安全。除此之外,從圖中可以看出,Mask-FL客戶端的模型訓練時間大大縮小,證明本文提出的本地多節點結構設計能夠有效地減小客戶端模型訓練的時間。 圖4 Mask-FL和FedAvg訓練中各階段耗時 由于本次實驗是在單機上運行的,所以并未對客戶端-客戶端、客戶端-服務器的上下行傳輸時間進行模擬,并且在實際應用中,各種設備的通信帶寬、數據傳輸效率和網絡狀態各不相同,所以在聯邦學習上下行過程中,考慮的評價指標為通信數據量。本文對各種聯邦學習安全協議的訓練過程進行了數據傳輸量的比較。 表1比較了4種聯邦學習協議全局訓練過程中的通信成本,|w|為傳輸的模型大小,n為參與訓練的客戶端,k為服務器聚合模型次數。相比于其他協議,Mask-FL協議需要在訓練開始進行初始化設置,在該過程中所有客戶端間需傳輸固定數據量(n-1)*n*|w|,客戶端與服務器需傳輸3|w|數據量。在整個訓練流程中,初始化產生的時間損耗僅發生一次,而在訓練中掩碼的更新頻率T小于全局訓練次數k,其數據量相對于整個訓練過程的數據量僅占少部分,考慮協議安全性與時間損耗,Mask-FL仍具有很大的優勢。 表1 不同聯邦學習算法之間的通信成本比較 構造1個中心服務器、3個客戶端及每個客戶端3個節點的結構,每個客戶端擁有20 000張數據,由于在相同的機器上訓練,因此,按照Datasplit數據切分算法劃分,得到每個客戶端節點中的數據為[6 666,6 666,6 666]。按照以上采用默認參數設置,每個節點本地迭代訓練1epoch,全局通信輪次為100,進行Mask-FL訓練,訓練結果如圖5所示。 圖5 Mask-FL的模型訓練精度 由于采用的是平均聚合方式,所以在模型下發各個節點后,再次進行本地訓練導致訓練精度突然改變,從而出現了圖5(a)中的毛刺,9個參與訓練的節點的訓練效果各有差異,但是在聯邦學習的平均聚合效果下,最終都能達到整體的最優精度,在圖5(b)中,隨著全局迭代的不斷增加,模型逐漸收斂,最大準確率達98.69%,即Mask-FL充分地利用各個節點數據達到訓練目標。 由于Mask-FL客戶端的訓練速度提高,那么在相同的通信輪次內,本地節點可進行更多本地迭代訓練的次數,根據上述實驗,Mask-FL客戶端訓練時間約為FedAvg客戶端訓練時間的1/3,因此,設置節點本地迭代次數為FedAvg的3倍以進行相同條件的對比。訓練結果如圖6所示。 圖6中,在相同的訓練時間條件下,Mask-FL訓練模型的收斂速度比FedAvg顯著提高。達到相同的98%準確度條件下,Mask-FL需要進行14次通信,FedAvg需要進行20次通信,相比之下本方案所需的通信輪次更低,提高訓練效率比為30%。Mask-FL最大收斂準確率為98.85%,FedAvg為98.83%,2種方案訓練的模型均收斂。 圖6 Mask-FL本地節點訓練3 epoch與FedAvg訓練模型精度比較 在默認參數設置下,針對Mask-FL不同的本地迭代訓練次數進行實驗,將epoch設為1、3、5、10分別進行訓練,研究節點本地迭代訓練次數對訓練結果的影響,見圖7。 圖7 Mask-FL中不同epoch對訓練的影響 圖7為訓練模型達到98%精度,Mask-FL在本地迭代1epoch方式需要進行通信47 round,3 epoch方式需要進行通信14 round, 5 epoch方式需要進行通信12 round,10 epoch方式需要進行通信8 round。1 epoch方式達到最大精度為98.69%,3 epoch方式最大精度為98.85%,5 epoch方式最大精度為98.85%,10 epoch方式最大精度為98.86%。隨著本地節點迭代次數的增加,模型能更快地收斂,從而聯邦學習訓練收斂時所需的通信輪次更少。 采用默認參數設置,針對Mask-FL每個客戶端生成的節點數分別為1、2、3、5進行實驗,分析客戶端節點數對模型訓練的影響,結果見圖8及表2。 如圖8所示,在這次實驗中Mask-FL節點數為1時,等價于FedAvg方法,但是不符合Mask-FL的安全性假設。隨著客戶端節點數的增加,模型收斂時所需的通信輪次增多,訓練時間如表2所示,訓練耗時大大降低,并且能夠達到收斂精度。考慮上述實驗圖6的結果,可在提高客戶端節點數的同時,提高節點本地迭代次數,以此來提高訓練效果。 圖8 Mask-FL客戶端生成不同節點數對訓練的影響 表2 Mask-FL客戶端多節點訓練100 round耗時和精度 采用默認參數設置,根據前面實驗的結論節點數與訓練耗時成反比,考慮在相同的時間內比較Mask-FL的訓練效果,即客戶端生成2節點的實驗進行本地迭代2 epoch,客戶端生成3節點的實驗進行本地迭代3 epoch,客戶端生成5節點的實驗進行本地迭代5 epoch。實驗結果如圖9及表3。 圖9 Mask-FL多節點多epoch對訓練的影響 表3 Mask-FL多節點多epoch訓練100 round耗時和精度 如圖9所示,實驗①達到98%精度時,所需通信輪次為17,實驗②達到98%精度時,所需通信輪次為14,實驗③達到98%精度時,所需通信輪次為9,實驗④達到98%精度時,所需通信輪次為10。各個實驗的模型通過100輪次的訓練最終達到收斂。根據表3所示,得出實驗結論:在近似的時間內,投入的計算資源越多,則模型訓練速度越快,但是計算資源投入越多所獲得的收益呈下降趨勢。 采用默認設置,Mask-FL的每個客戶端生成3個節點,節點本地迭代訓練3 epoch,與其他3個框架進行100個通信輪次對比實驗,比較模型準確度,結果見圖10及表4。 圖10 多種框架訓練模型100 round的準確度 表4 各個框架訓練100 round耗時和精度 如圖10所示,在Mask-FL、SS-FL及FedAvg訓練中,模型均獲得較高精度,在DP-FL中,其結果模型準確度隨著差分隱私預算減小而減小,即添加的擾動過大,導致模型精度下降,模型效果變差,并且表4顯示,由于在訓練過程中需要進行小批次采樣訓練和梯度切割而導致訓練時間極大增加。Mask-FL訓練所需耗時與SS-FL及FedAvg相近,但實驗平均精度均比其他框架高,說明Mask-FL所訓練的模型收斂更快。實驗證明了Mask-FL訓練過程中,在保證多方安全計算的前提下沒有引入新的噪聲,因此,得出Mask-FL能夠在深度神經網絡訓練過程中不會造成精度的損失,并且能夠更快地收斂模型的結論。 針對聯邦學習目前面臨著成員推理、重構攻擊等隱私推斷攻擊,以及跨數據庫聯邦學習各節點訓練時間長的問題,本文將分層聯邦學習和基于安全多方計算的隱私保護機制相結合,提出了一種新型聯邦學習訓練算法Mask-FL,通過安全性分析證明,客戶端的模型參數能不被服務器和其他客戶端所獲取。實驗結果證明,相比于結合秘密共享的聯邦學習,Mask-FL的通信成本較少;相比于添加差分隱私噪聲的聯邦學習訓練方式,Mask-FL的訓練準確度更高;相比于FedAvg算法,Mask-FL更安全且訓練速度更快。本算法在保證數據隱私安全的前提下,擁有較高的模型準確度,以及具備優秀的模型訓練速度。2.3 Mask-FL

3 實 驗
3.1 協議時間消耗分析
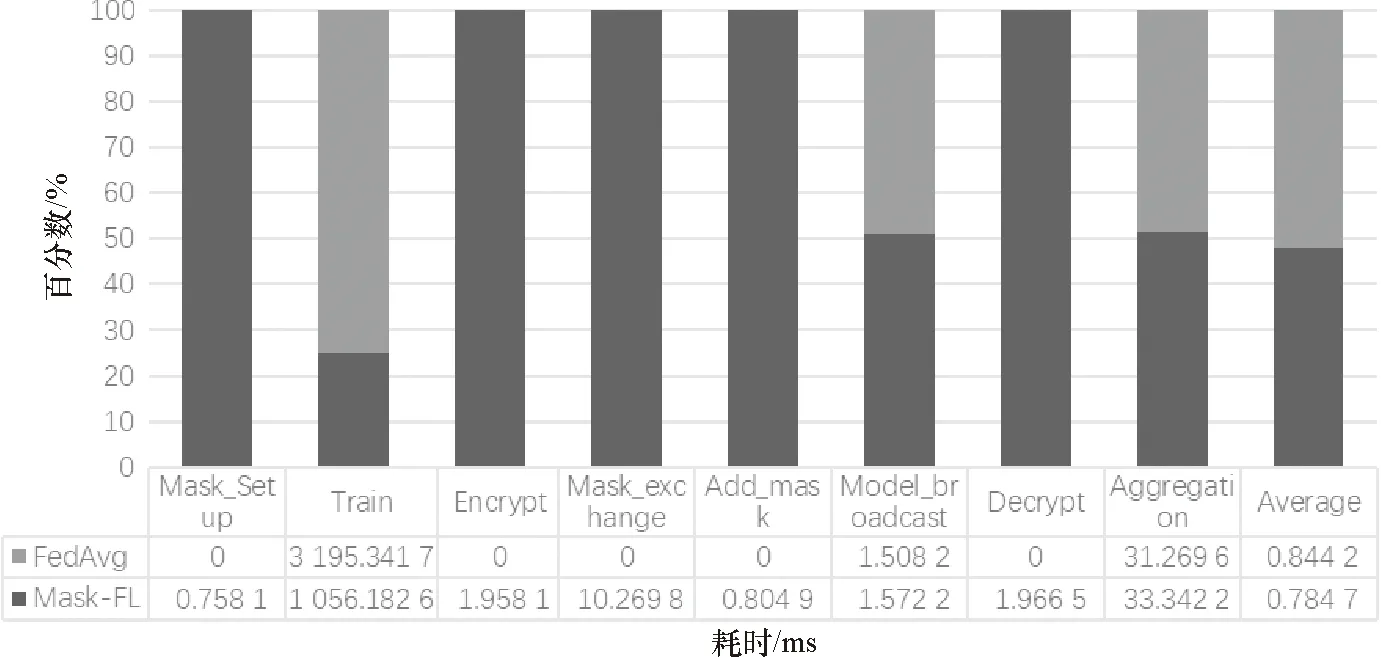
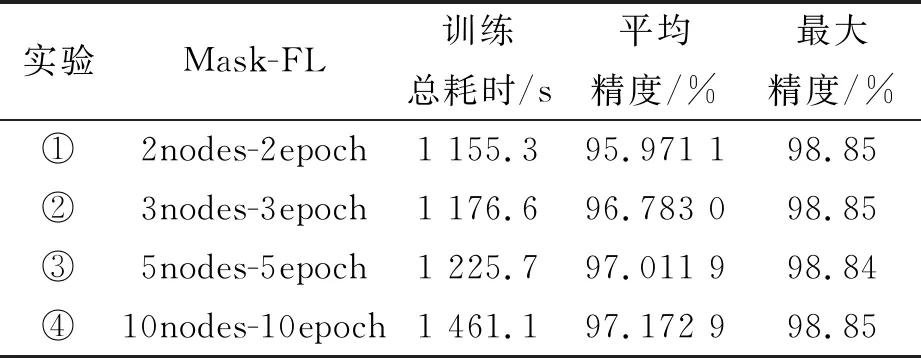
3.2 通信成本評估

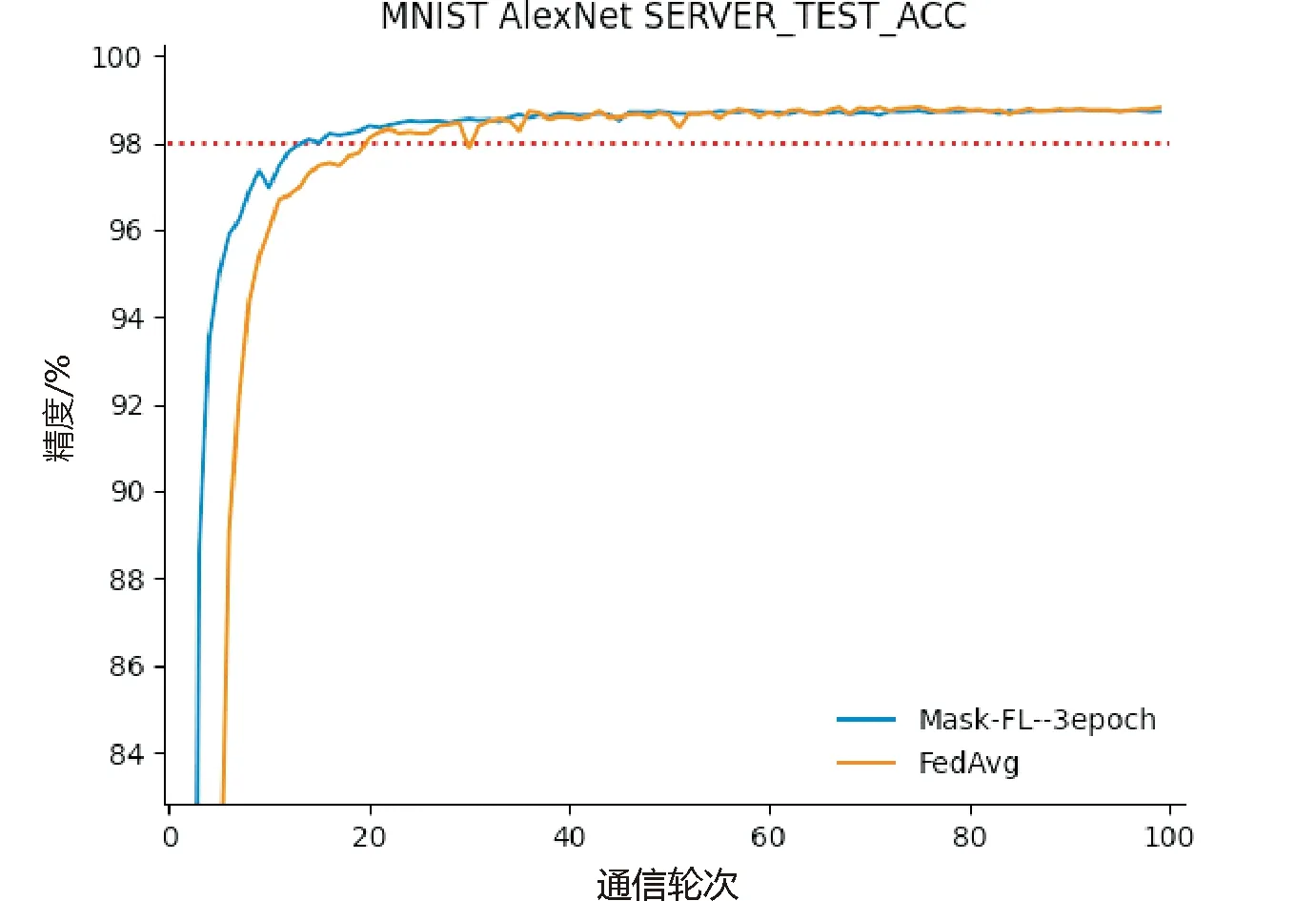
3.3 模型準確性分析

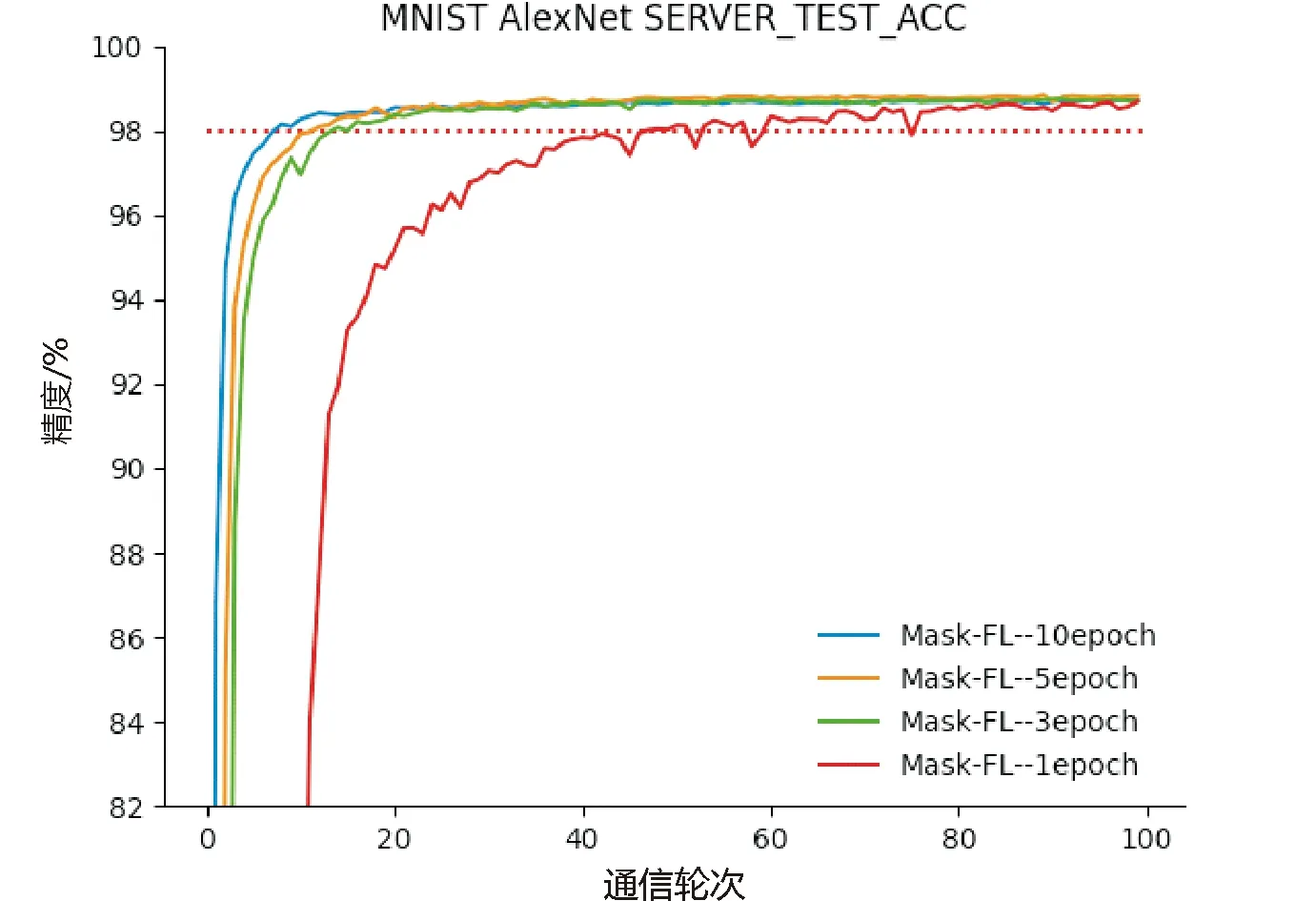



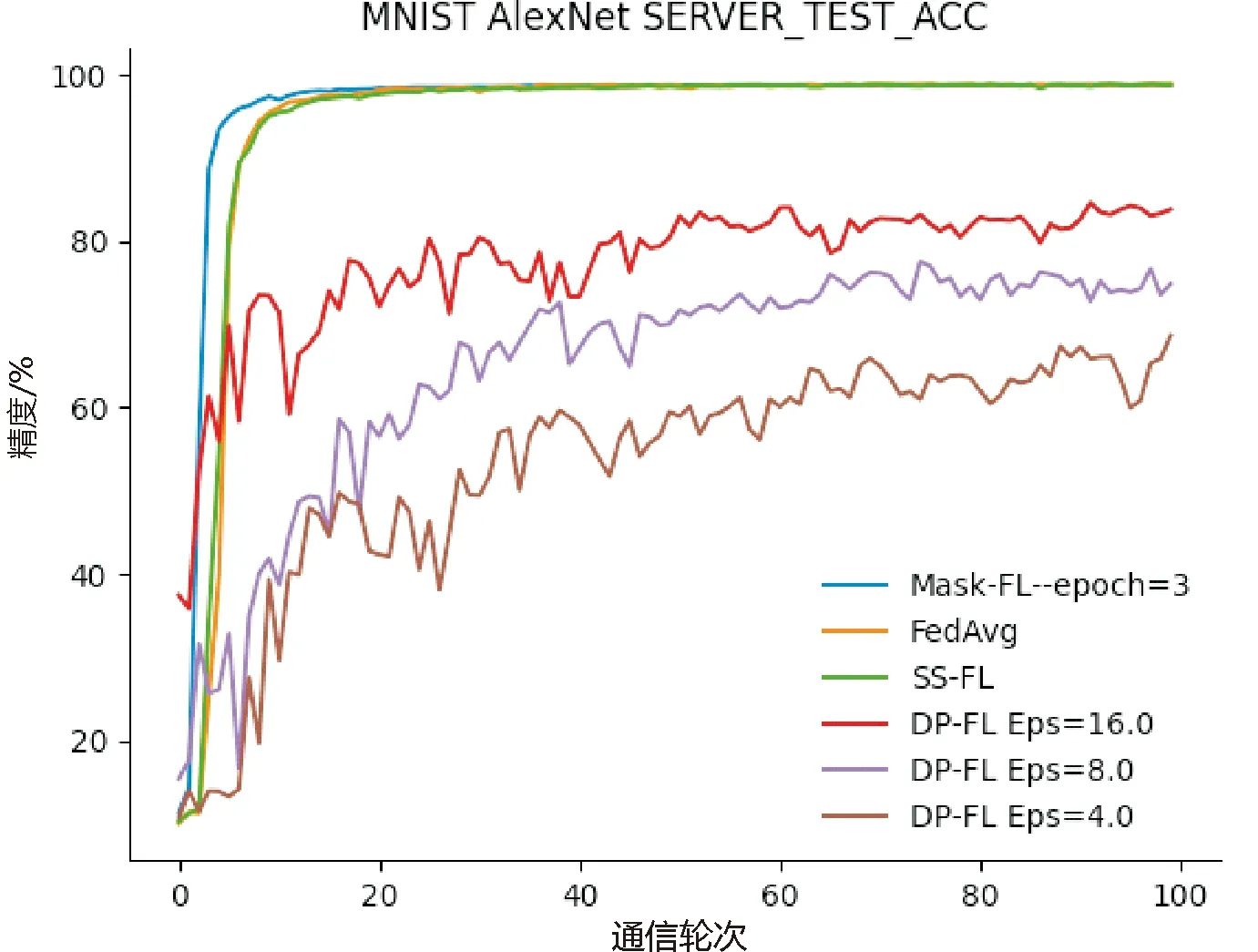

4 總 結
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19

- 廣州大學學報(自然科學版)的其它文章
- 廣州大學《大學體育》課程“課內外一體化”教學模式的設計與實施研究
- Modified spin wave theory applied to the low-temperature properties of ferromagnetic long-range interacting spin chain with the antiferromagnetic nearest-neighbor interaction
- 布爾環及其譜的一些性質
- The cyclotomic numbers of order k=2m-1
- 基于分離邏輯的云存儲系統并發正確性驗證
- 廣東省2035年土地利用空間分布的模擬預測