基于深度語義分割的無人機遙感影像水體提取研究
2022-10-11 03:00:54江沛原
現(xiàn)代計算機 2022年15期
江沛原
(西南民族大學電子信息學院,成都 610041)
0 引言
語義分割任務(wù)也可以看作是特殊的分類任務(wù),密集像素級分類任務(wù)。深度學習方法在場景復(fù)雜的遙感影像中,能夠自適應(yīng)地提取淺層的低級特征和深層的高級特征,經(jīng)過特征融合高效挖掘豐富的語義信息。并且無人機遙感具有機動性好、環(huán)境影響小、空間分辨率高等優(yōu)點。因此,高分辨率的遙感影像與深度學習技術(shù)的結(jié)合在遙感影像語義分割領(lǐng)域具有重要的現(xiàn)實意義,為無人機遙感影像的水體提取提供了新手段。地球表面由各種復(fù)雜類型的水和非水地貌組成,具體而言,地表水類型包括河流、湖泊、水庫和海洋,它們具有不同的形狀和光譜;非水類型包括陰影、柏油路和建筑物,它們具有相似的光譜和空間特征,容易與地表水混淆。因此,地表水測繪通常在精度上受到限制。通過地表水面積的大小和水的深淺程度可以監(jiān)測遙感影像中的水體信息,為了充分地了解水體的變化情況,最行之有效的方法是對遙感影像中的水體信息進行提取。與提取遙感影像中的森林植被、城市道路、建筑物等其他類型地物相比,從遙感影像上提取水體的研究更為常見。隨著空間探測技術(shù)的發(fā)展,基于遙感衛(wèi)星的對地觀測遙感數(shù)據(jù)為大范圍水體提取提供了新的數(shù)據(jù)基礎(chǔ),同時也對現(xiàn)有的遙感數(shù)據(jù)分析方法提出了極大的挑戰(zhàn)。
隨著深度學習在圖像分類、目標檢測、語義分割等圖像處理任務(wù)中展現(xiàn)出來的優(yōu)異性能,近些年,使用深度學習方法進行水體提取的研究 越 來 越 多。Yang等利 用 傳 統(tǒng) 的NDWI、NDVI、NDBI等指數(shù)人工構(gòu)建特征作為網(wǎng)絡(luò)的輸入,然后使用稀疏自動編碼器進行水體檢測,能夠在有限標簽樣本的情況下學習水體特征;Isikdogan等采用基于深度學習的方法,提出了從數(shù)據(jù)中學習水體特征的Deep Water Map模型,可有效區(qū)分水與土地、雪、冰、云和及陰影區(qū)。Li等利用FCN從高分辨率遙感影像中提取城市水體,并對比分析了輸入特征、訓(xùn)練數(shù)據(jù)、遷移學習和數(shù)據(jù)增廣四個因素對實驗結(jié)果的影響,利用最優(yōu)模型獲得了較高的提取準確率。Wang等將深度學習方法應(yīng)用到高分辨率遙感影像的水體識別與提取中,通過構(gòu)建深度神經(jīng)網(wǎng)絡(luò)模型來提高遙感影像水體識別的精度,研究結(jié)果表明,所選用的深度卷積神經(jīng)網(wǎng)絡(luò)模型的識別效果都顯著優(yōu)于傳統(tǒng)的水體指數(shù)法,驗證了神經(jīng)網(wǎng)絡(luò)應(yīng)用于遙感影像水體提取的可行性。Li等提出了一種基于無人機高分辨率遙感影像的復(fù)雜環(huán)境下水體識別的快速準確方法。與現(xiàn)有方法相比,該方法在準確率上取得了顯著提高,可獲得城市區(qū)域內(nèi)明顯的水邊界,為城市水矢量制圖提供數(shù)據(jù)。
針對水體提取的研究,如何減少遙感影像的噪聲干擾仍是水體信息提取的難點,且水體流動反光,建筑物和陰影的遮蓋等因素也會增加提取的難度。另外,現(xiàn)有研究多是針對衛(wèi)星遙感影像的水體提取,識別精度較低。衛(wèi)星遙感觀測的信息不但宏觀、綜合,還可以長期連續(xù)觀測,形成時序信息。由于無人機近地面的緣故,總體上分辨率高、時效性好,數(shù)據(jù)處理也比衛(wèi)星遙感復(fù)雜。因此,本研究構(gòu)建無人機遙感影像數(shù)據(jù)集,旨在提高其水體識別精度,采用基于OCRNet語義分割模型結(jié)合HRNet的方法進行水體提取。實驗結(jié)果表明,該網(wǎng)絡(luò)在分割準確率上效果較優(yōu),得到不錯的結(jié)果,驗證了該方法的可靠性。
1 無人機遙感影像數(shù)據(jù)集
1.1 數(shù)據(jù)集介紹
無人駕駛飛機(UAV)通常被稱為無人機,無人機平臺可搭載多種微傳感器來獲取不同質(zhì)量的無人機遙感影像,從而構(gòu)成無人機遙感系統(tǒng)。無人機遙感由遙感探測技術(shù)、導(dǎo)航定位技術(shù)、無線通信技術(shù)及飛行技術(shù)于一體,是一個系統(tǒng)而復(fù)雜的工程,在管理地理空間信息方面高效且方便。在深度學習的神經(jīng)網(wǎng)絡(luò)語義分割任務(wù)中,數(shù)據(jù)集由訓(xùn)練數(shù)據(jù)集(train dataset)、驗證數(shù)據(jù)集(validation dataset)和測試數(shù)據(jù)集(test dataset)三部分組成。其中,訓(xùn)練集用于模型構(gòu)建,計算訓(xùn)練誤差的梯度和更新訓(xùn)練的權(quán)重參數(shù);驗證集用于調(diào)整模型的超參數(shù)和避免訓(xùn)練過程出現(xiàn)過擬合現(xiàn)象,用于輔助模型構(gòu)建;測試集用于提高模型訓(xùn)練的準確度和最終模型的泛化能力,用于評估模型的準確率。
圖1所示為初始無人機影像分布(共200張,像素6000×4000,格式為.JPG),通過ENVI 5.3軟件對數(shù)據(jù)進行預(yù)處理裁剪,制作得到水體提取數(shù)據(jù)集(共4800張,像素512×512,格式為.PNG)。UAV_DATASET數(shù)據(jù)集包含三個文件夾:Annotation、JPEGImages和val_big_img。其中,Annotations文件夾保存的是各原圖的像素級別的二值圖真值信息;JPEGImages文件夾包含無人機影像的原圖,命名方式相同;val_big_img文件夾包含隨機選取的二十張大圖,用于放入驗證集中,此外還包含兩個文本:val_list和train_list,分別記錄訓(xùn)練數(shù)據(jù)集(3888張,占81%,格式為.PNG)和驗證數(shù)據(jù)集(912張,占19%,格式為.PNG)。val_list文本存儲的信息是val_big_img中的大圖圖片名構(gòu)成驗證集,而train_list則是剩下的圖片構(gòu)成訓(xùn)練集。
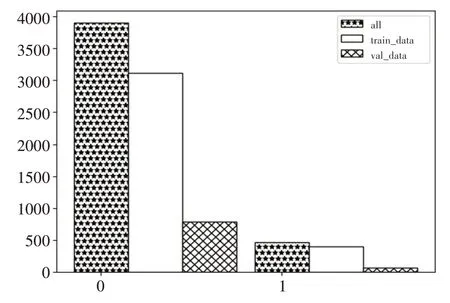
圖1 數(shù)據(jù)集類別分布圖
數(shù)據(jù)集的部分樣本原圖如圖2所示,考慮到構(gòu)建數(shù)據(jù)集的多樣性,分別選取了無水體原圖、不規(guī)則形狀水體原圖、包含水體范圍較廣等具有代表性的圖片,增加了數(shù)據(jù)集的魯棒性。在構(gòu)建數(shù)據(jù)集的過程中,由于無人機影像原圖為三通道RGB圖像,而輸入到Annotations文件夾內(nèi),只需要原圖對應(yīng)的二值圖,因此還需要將RGB圖像灰度化的操作,使之位深度由24降為8。

圖2 數(shù)據(jù)集的部分樣本原圖
與圖2對應(yīng)的數(shù)據(jù)集的部分樣本真值如圖3所示,數(shù)據(jù)預(yù)處理后得到的二值圖呈黑白圖像,包含非水體(0)與水體(1),非水體表現(xiàn)為黑色,水體表現(xiàn)為白色。類別數(shù)為2,因此無人機影像的水體提取任務(wù)可以看作是一個二分類問題。

圖3 數(shù)據(jù)集的部分樣本真值
1.2 數(shù)據(jù)集圖像裁剪制作
將遙感影像根據(jù)感興趣區(qū)域(region of interest,ROI)范圍大小對被裁剪影像進行裁剪,采用ROI方法裁剪無人機遙感影像得到數(shù)據(jù)集。數(shù)據(jù)集制作技術(shù)方案如圖4所示,包括以下三個主要步驟:
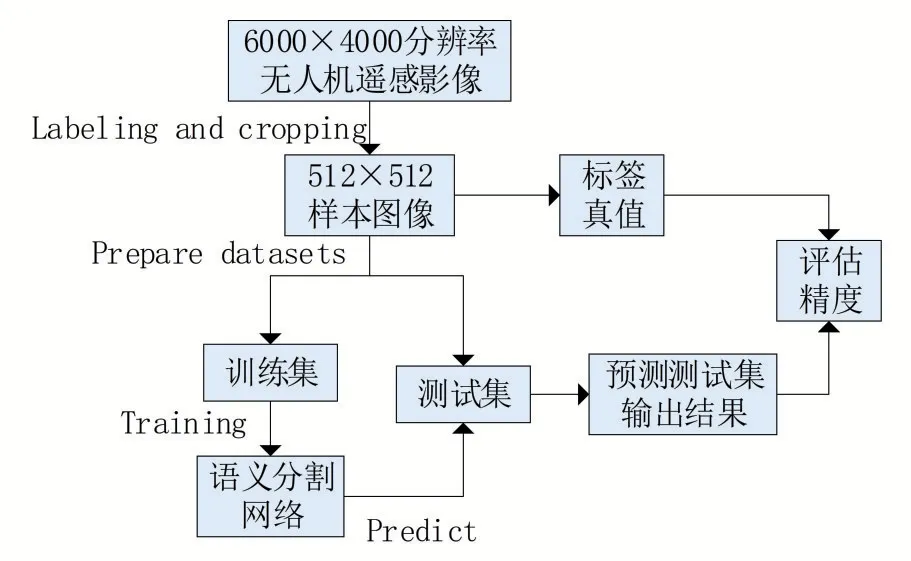
圖4 數(shù)據(jù)集制作技術(shù)方案圖
(1)收集研究區(qū)無人機遙感影像,標記(水體與非水體)和裁剪無人機影像以獲得512×512像素的樣本圖像,用于生成訓(xùn)練數(shù)據(jù)集和驗證數(shù)據(jù)集;
(2)構(gòu)建語義分割網(wǎng)絡(luò),并使用訓(xùn)練數(shù)據(jù)集訓(xùn)練網(wǎng)絡(luò);
(3)最后通過使用測試區(qū)域的真實標簽和分類結(jié)果來評估分割結(jié)果,分類結(jié)果由測試數(shù)據(jù)集的預(yù)測結(jié)果拼接而成,評估模型精度。
數(shù)據(jù)集的裁剪采用滑動窗口預(yù)測方法,并將關(guān)聯(lián)預(yù)測結(jié)果拼接,確定漁網(wǎng)(256×256)左上角和右下角中心像素坐標,據(jù)此確定需要填充的四至距離,預(yù)測圖在填充圖坐標系下的位置,并摳取需要預(yù)測的小圖,將預(yù)測圖有效區(qū)域添加到全0填充圖上。
2 實驗方法
2.1 語義分割模型OCRNet
語義分割是一項密集像素預(yù)測任務(wù),研究重點在于解決逐漸衰減的特征圖尺寸和需要原圖尺寸的預(yù)測之間的矛盾,因此圖像中每個像素的上下文信息是極其重要的。物體的上下文信息旨在顯式增強物體信息,通過計算一組物體的區(qū)域特征表示,并根據(jù)物體區(qū)域特征表示與像素特征表示之間的相似度將這些物體區(qū)域特征表示傳播給每一個像素。將像素的標簽看作是像素所在物體的標簽,通過對應(yīng)的物體區(qū)域來表示以此加強像素的表征,于是OCRNet語義分割模型被提出,其主要思想是像素的類別標簽由其所在目標決定,使用目標區(qū)域表示來增強其像素表示。
2.2 骨干網(wǎng)HRNet
HRNet能夠全程保持高分辨率的特征圖,得到更為精準的空間信息,其多尺度融合策略可以得到更為豐富的高分辨率表征,使預(yù)測的熱點圖(heatmap)更為準確。HRNet總體結(jié)構(gòu)按照順序可分為三部分:stem net、HRNet stages和segment head。stem net從圖像到1/4大小的feature map,得到此尺寸的特征圖后HRNet始終保持此尺寸的圖片;HRNet stages是由HighResolutionModule組成的模型,其中,每個藍色底色為1個階段,每個stage產(chǎn)生的multiscale特征圖的具體配置見表1(以hrnet_48為例)。stage的連接處有transition結(jié)構(gòu),用于不同stage之間的連接,完成channels及feature map大小對應(yīng);segment head將stages輸出的4種scale特 征concat到 一 起,加 上num_channels到num_classes層,得到分割結(jié)果。

表1 多尺度特征圖的具體配置
HRNet的head頭多樣化,支持不同的輸出模式,對應(yīng)V1,V2,V3三種版本,如圖5所示,分別為a,b,c三種形式。
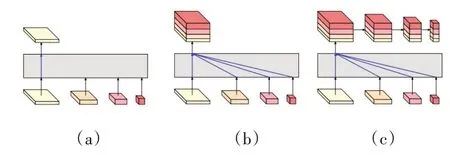
圖5 HRNet的head輸出形式
(a)輸出內(nèi)容僅包含最后輸出的高分辨率特征;
(b)輸出內(nèi)容在最后也進行了跨分辨率融合,再輸出高分辨率特征;
(c)語義信息較豐富,先進行融合后輸出高分辨的特征,再進行下采樣得到多個sacle的輸出,并且(b)和(c)的特征融合是通過沿通道方向拼接的方式拼接融合的。
2.3 語義分割網(wǎng)絡(luò)OCRNet結(jié)合HRNet骨干網(wǎng)
來自于NVIDIA的研究團隊采用OCRNet+HRNet作為主干網(wǎng)絡(luò)結(jié)構(gòu)并且設(shè)計了一種更高效的多尺度融合方法,取得了更好的精度效果。本文結(jié)合OCRNet模型設(shè)置三種不同輪次、兩種不同實驗方法:HRNet_w18和HRNet_w48分別在10 epoch、30 epoch、60 epoch運行。其中,HRNet_w18方法中的18代表模型最后三級高分辨率子網(wǎng)絡(luò)的寬度。OCRNet利用物體信息增強像素的上下文信息,HRNet保持主干網(wǎng)的高分辨率并且提供強語義信息與精準位置信息,它們的組合具有有效性,能夠較好地對無人機影像中的水體信息進行提取。
2.4 網(wǎng)絡(luò)模型的參數(shù)設(shè)置
常規(guī)優(yōu)化器是單一的,在本研究的訓(xùn)練過程中,在優(yōu)化器的基礎(chǔ)上添加動量,使用隨機梯度下降(stochastic gradient descent,SGD)算法進行優(yōu)化,SGD算法的動量參數(shù)(momentum)和權(quán)重衰減參數(shù)(weight_decay)分別設(shè)置為0.9和4.0e-05,使用權(quán)重衰減的目的是防止過擬合。根據(jù)GPU的計算能力、顯存大小、圖像像素大小和樣本數(shù),將實驗數(shù)據(jù)批量大小設(shè)置為8,batch_size的值為迭代一次送入網(wǎng)絡(luò)的圖片數(shù)量,一般顯卡顯存越大,批量值就可以越大。學習率是指模型訓(xùn)練的權(quán)重參數(shù)在逆梯度方向上調(diào)節(jié)的步長,為了保證訓(xùn)練過程順利進行,采用了變化學習率策略,通過多項式衰減的策略將學習率值從初始設(shè)置為0.01的learning_rate,逐步衰減到end_lr為0的最終學習率,power即衰減率這一參數(shù)設(shè)置為0.9,類型為PolynomialDecay。
水體像素級別分類任務(wù)通過Softmax函數(shù)將每一個像素點值映射為一個概率值,來確定每一個像素值是否屬于水體類,達到像素級別的預(yù)測損失函數(shù)的選擇也是非常關(guān)鍵的,它是BP算法的核心部分,用來衡量預(yù)測值和標簽值之間的差異。損失函數(shù)包括常規(guī)損失函數(shù)和多損失函數(shù),前者單一且固定,本文采用的是通過coef連接CrossEntropyLoss和LovasSoftmaxLoss的多損失函數(shù),該混合損失函數(shù)可用來監(jiān)督像素和對象級別的訓(xùn)練過程。其中,Lovasz-Softmax loss是一種針對mIoU優(yōu)化功能的損失,它基于子模損失的凸Lovasz擴展。在圖像分割任務(wù)中,經(jīng)常出現(xiàn)類別分布不均勻的情況,因此本文引入LSLoss以提高OCRNet中對象區(qū)域表示的準確性,并在對象級別優(yōu)化最終分割結(jié)果。語義分割只關(guān)注像素級分類,缺乏對象級分類的優(yōu)化。通過計算誤差,將得到的誤差進行反向傳播。網(wǎng)絡(luò)模型在訓(xùn)練過程中使用交叉熵作為損失函數(shù),它可有效地對模型進行預(yù)測。
3 實驗結(jié)果與分析
3.1 實驗環(huán)境
本研究基于Ubuntu 18.04操作系統(tǒng),使用的開發(fā)環(huán)境、編程語言和深度學習框架依次為Anaconda3、Python3.7.4和Pytorch,編 譯 器 為PyCharm。模型訓(xùn)練、驗證和測試均在一個NVIDIA GTX 1080Ti GPU上進行。
3.2 評價指標
評價指標用來評估不同算法在某一方面的效果是否最佳,可對算法進行不同程度的優(yōu)化。為定量分析圖像語義分割精度,在圖像分割領(lǐng)域中,評估模型質(zhì)量主要是通過準確率(Acc)、Kappa系數(shù)以及語義分割評價指標均交并比(mean intersection over union,mIOU)這三個指標對4800幅影像的水體提取模型進行評定。
準確率是最常見的評價指標,表示被正確分類的數(shù)量在所有預(yù)測該類的數(shù)量中的占比,準確率越高表明模型質(zhì)量越高。準確率由該類所有被正確分類的樣本數(shù)除以模型預(yù)測中屬于該類的總數(shù)得到。準確率的計算如式(1)所示:
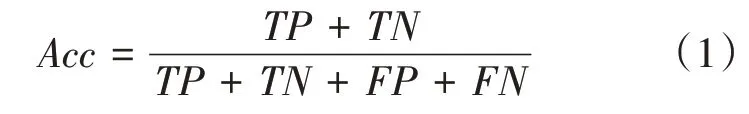
式中:表示的是預(yù)測結(jié)果為正例,標簽為正例的像素數(shù)量;表示的是預(yù)測的結(jié)果為負例,標簽的結(jié)果為負例的像素數(shù)量;表示的是預(yù)測結(jié)果為正例,標簽為負例的像素數(shù)量;表示的是預(yù)測結(jié)果為負例,標簽為正例的像素數(shù)量。
Kappa系數(shù)是用于一致性檢驗的指標,可用來衡量分類的結(jié)果。取值范圍是[-1,1],通常大于0,將其分為五組來表示不同級別的一致性:0.0~0.2極低的一致性(slight);0.21~0.40一般的一致性(fair);0.41~0.60中等的一致性(moderate);0.61~0.80高度的一致性(substantial);0.81~1幾乎完全一致(almost perfect)。基于混淆矩陣的Kappa系數(shù)計算如式(2)所示:
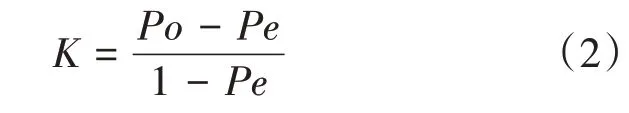
式中:代表每一類中正確分類像元素,即;代表所有類別對應(yīng)的實際與預(yù)測數(shù)量的成績的總和除以樣本總數(shù)的平方,如式(3)所示:
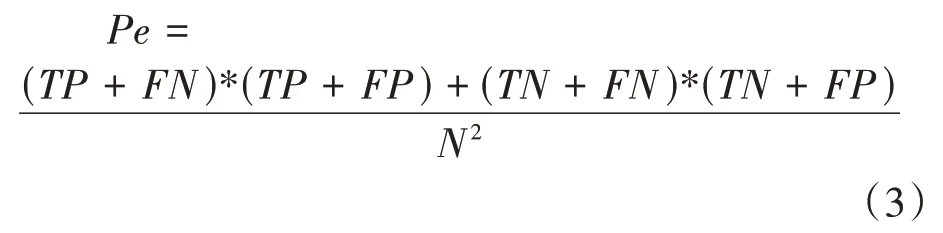
mIOU為語義分割的標準度量對每個類別數(shù)據(jù)集單獨進行推理計算,計算出的預(yù)測區(qū)域和實際區(qū)域交集除以預(yù)測區(qū)域和實際區(qū)域的并集,然后將所有類別得到的結(jié)果取平均。在圖像分割中,就是真實值(ground truth)和預(yù)測值兩個集合。先計算每個類別的交并比,然后計算均值,如式(4)所示:
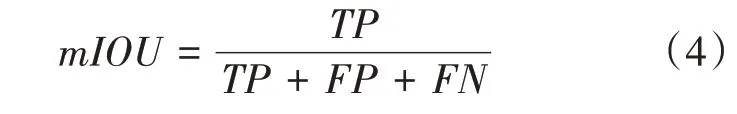
3.3 結(jié)果分析
表2列出了OCRNet網(wǎng)絡(luò)結(jié)合HRNet_w18骨干網(wǎng)在不同輪次下在訓(xùn)練集上的評價指標。從實驗分析可得,10 epoch和60 epoch訓(xùn)練輪次數(shù)下的各評價指標效果不及30 epoch訓(xùn)練輪次,后者的評價效果最佳:Acc可達99.30%,Kappa系數(shù)(KC)為0.9231,mIoU為0.9281。此時最佳驗證迭代數(shù)為13122。
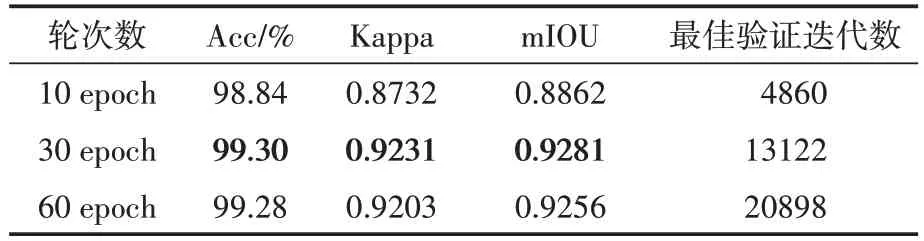
表2 OCRNet+HRNet_w18不同輪次的評價指標
表3列出了OCRNet網(wǎng)絡(luò)結(jié)合HRNet_w48骨干網(wǎng)在不同輪次下在訓(xùn)練集上的評價指標,從實驗分析可得,隨著訓(xùn)練輪次的增加,各項評價指標也有一定的提高,在60 epoch時達到最佳:Acc可達99.24%,Kappa系數(shù)(KC)為0.9136,mIoU為0.9199。此時最佳驗證迭代數(shù)為23814。
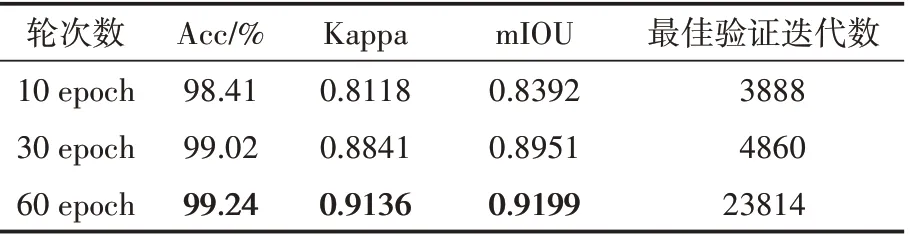
表3 OCRNet+HRNet_w48不同輪次的評價指標
值得一提的是,當OCRNet網(wǎng)絡(luò)結(jié)合HRNet_w18骨干網(wǎng)的輪次達到60 epoch時,各精度卻有一定程度的下降,可見并不是訓(xùn)練輪次越多精度越高。迭代輪數(shù)過少可能欠擬合,而過多則可能過擬合,需要在訓(xùn)練中不斷摸索找到大致合適的范圍,或者可采用提前終止策略等。總體來看,語義分割模型OCRNet結(jié)合HRNet_w18骨干網(wǎng)在30 epoch輪次時,效果最好。
3.4 預(yù)測效果
在語義分割模型中輸入6000×4000分辨率的遙感影像(水平分辨率和垂直分辨率均為350 dpi),預(yù)測其水體提取效果。如圖6所示,左側(cè)為原圖,右側(cè)為偽彩色預(yù)測結(jié)果圖片,可直接查看各個類別的預(yù)測效果。對無人機遙感影像水體提取這一任務(wù)來說,總體精度較高,但對于圖中誤檢測以及由于陰影遮擋等原因未識別到的水體部分,后續(xù)的工作仍需調(diào)整超參數(shù)來改進模型。

圖6 水體的預(yù)測效果圖
4 結(jié)語
語義分割任務(wù)旨在獲取輸入圖像中每個像素的類標簽,而無人機遙感影像水體提取任務(wù)旨在獲取輸入圖像中的每個像素,這兩個任務(wù)概念上有一定的一致性,因此可以將遙感影像提取任務(wù)轉(zhuǎn)化為語義分割任務(wù)。本研究根據(jù)無人機遙感影像在復(fù)雜環(huán)境下采用OCRNet語義分割模型結(jié)合HRNet骨干網(wǎng)進行水體提取,擴充后的數(shù)據(jù)集涵蓋水體信息更為豐富,也進一步提高了其魯棒性,通過設(shè)置不同的實驗,選取最優(yōu)模型的神經(jīng)網(wǎng)絡(luò)完成水體數(shù)據(jù)集的提取。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
