基于深度學習的園林植物病蟲害智能識別系統
2022-10-11 03:01:08何懷文蔡顯華楊毅紅
現代計算機 2022年15期
何懷文,蔡顯華,楊毅紅
(1.電子科技大學中山學院,中山 528400;2.中山花木城園林有限公司,中山 528421)
0 引言
園林環境作為社會主義生態文明建設的重要組成部分,越來越受到廣大民眾的喜愛和關注。園林植物是城市綠化中提升生態環境質量的重要環節。但是目前由于生態污染問題嚴重,園林植物生長過程中經常會遭受病蟲害侵擾,導致其發病部位組織器官損壞,如出現落葉、腐爛、壞死斑等,大大降低了植物的觀賞價值,嚴重制約了園林業的發展。例如,松樹在感染松材線蟲后,一個月左右會死亡。而目前國內防治專家與植物養護員之間往往存在“信息孤島”現象,從而導致在植物病蟲害出現時無法正確識別和及時對癥下藥。
近年來,隨著機器學習技術的蓬勃發展,利用人工智能方法準確識別和預測病蟲害的發生,從而進行精準防治,受到廣大研究者的廣泛關注。文獻[6]提出了一種基于深度學習的病蟲害識別方法,通過提取灰度圖像的PCANet特性,再使用支持向量機進行識別;文獻[7]基于VGG16網絡模型,研發了一個農作物病蟲害智能識別的APP系統,提供移動端的病蟲害識別和診斷方法;文獻[8]基于Spring MVC框架,構建了病蟲害圖像識別和疫區防治的微信小程序;文獻[9]針對機器學習建模中的樣本采集問題,構建了大田作物的高質量農業病蟲害原始圖像數據。但是,上述研究在構建深度學習模型時僅針對固定數據集,無法根據應用場景來動態構建機器學習模型,缺乏一定的靈活性,給應用帶來了不便。
因此,本文針對園林植物病蟲害的智能識別問題,提出了一個能夠針對不同應用情景下動態構建機器學習模型的方法,為植物病蟲害診治提供數據支持和幫助。主要完成工作包括:①建立了常見園林植物的植物信息數據庫和病蟲害數據庫;②提供了自定義病蟲害識別數據集構建功能,允許用戶自定義病蟲害識別模型;③提供植物、病蟲害數據圖像采集和標注功能;④提供了基于深度學習園林植物病蟲害識別功能。
1 系統設計
本文圍繞園林植物養護過程的實際需求進行設計,系統從功能上分為七大模塊:新聞公告模塊、植物數據庫模塊、病蟲害數據庫模塊、盆景養護視頻模塊、數據采集和標準模塊、AI識別模型訓練模塊和系統管理模塊。系統功能模塊如圖1所示。
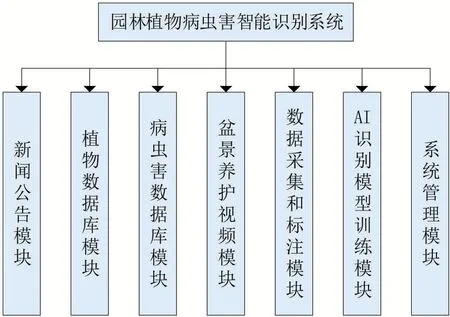
圖1 系統功能模塊圖
每個功能模塊的具體業務描述見表1。

表1 系統功能模塊描述
系統采用前后端分離的架構進行開發,其中前端采用了Vue3+ElementUI+TypeScript+Axios技術棧,有利于組件封裝和代碼重用。后端則基于主流的Java EE技術棧進行開發,采用了SpringBoot+JPA+QueryDsl+Sa-token技術棧,其中JPA+QueryDsl用于實現持久層操作,Sa-token則用于實現系統安全權限。深度學習模塊基于Python+Pytorch+Flask進行構建,其中Pytorch用于構建深度學習識別模型,Flask用于將訓練好的深度學習模型部署到Web服務器,并提供圖像識別接口。系統架構如圖2所示。
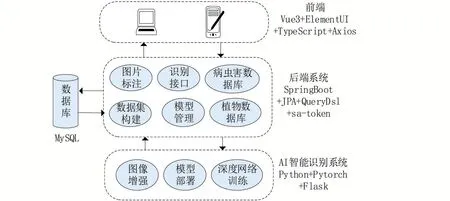
圖2 系統架構圖
2 主要模塊實現
系統主要分成以下三個部分:①植物病蟲害數據網站,提供植物、病蟲害數據展示和搜索功能;②數據管理系統,提供植物、病蟲害數據庫數據管理、深度學習模型管理功能;③深度學習模型訓練系統,用于構建病蟲害智能識別的深度學習模型和模型部署。
2.1 植物病蟲害數據網站
該部分是一個用于展示常見園林植物、病蟲害的網站系統,并提供病蟲害圖片識別接口,用戶無須登錄即可訪問,提供植物搜索功能、病蟲害的診斷功能、盆景養護視頻在線播放功能。頁面前端基于Vue3.0進行開發,采用Type-Script定義前端接口類型,使前端代碼整潔規范。前后端通信通過Axios實現,數據格式為JSON格式。在前端設計中,本文采用組件化思想,對界面相似組件進行抽離,封裝了Base-Table、BasicPage、BaseSearch等多個組件,提高了代碼的重用性。網站主頁如圖3所示。
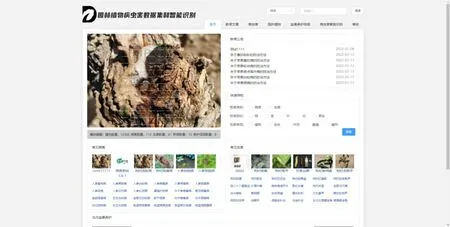
圖3 園林病蟲害數據庫網站
2.2 后端數據管理模塊
后端數據管理平臺主要用于植物數據庫、病蟲害數據、盆景養護視頻以及AI模型的管理。后端功能詳情如下:
對網站發布的新聞和公告進行管理,其中新聞文章具有不同的分類。
用于存儲常見的園林植物標準數據,包括植物基本信息(名稱、拉丁文名、科類、屬類和別名)和植物的詳細信息(生長習性、主要產地、形態特征、園林用途、管理護養和圖片集等)。植物數據庫的建立有助于形成統一標準的植物信息數據,養護員可以通過前端查詢或者智能圖片識別快速確定植物的類型,優化病蟲害診斷的及時性和準確性。
由于植物病害和蟲害對植物生長的損壞和防治屬于不同范疇,因此劃分為病害和蟲害兩部分。其中病害數據庫包括病害基本信息(病害名稱、危害部位、被害狀、屬類、分布和危害)和詳細信息(病原、發生規律、防治方法以及病害圖集)。而蟲害數據庫則包括蟲害基本信息(蟲害名稱、拉丁文、科屬、危害植物、危害部位、被害狀、分布與危害)和詳細信息(形態特征、發生規律、防治方法和蟲害圖集)。通過建立病蟲害數據庫,提供了一個基于數據庫的病蟲害的快速診斷功能,通過輸入植物的名稱、危害部位和被害狀態,可以快速定位到產生該危害的病害或者蟲害,并提供相應的防治措施,及時對癥下藥。
數據集是深度學習訓練的數據基礎,系統數據集分為病害數據集、蟲害數據集和植物數據集三大類。每一個主類別下再按照病蟲害和植物名稱進行細分。每個病蟲害大約包含類500~800張標注好的圖片。用戶可以往數據集中上傳新的圖片并進行標注,也可以對數據集中尚未標注的圖片進行標注。
數據集以文件形式存儲在深度學習服務上,有利于深度學習模型訓練時減少IO操作。每種病蟲害對應一個文件夾,文件夾名稱為病蟲害的數據表ID+病蟲害中文名稱,文件夾中包含該病蟲害對應的原始圖片JPG文件,文件名稱以拍攝時流水號命名。病蟲害的詳情和具體防治措施則存儲在Mysql數據庫中,將病蟲害數據和深度學習模型驅動數據分離,使系統的數據維護更為靈活和易于拓展。
為了方便用戶在不同應用場景的智能識別應用,本文設計了一個可以自定義深度學習模型構建方式,具體流程如圖4所示。
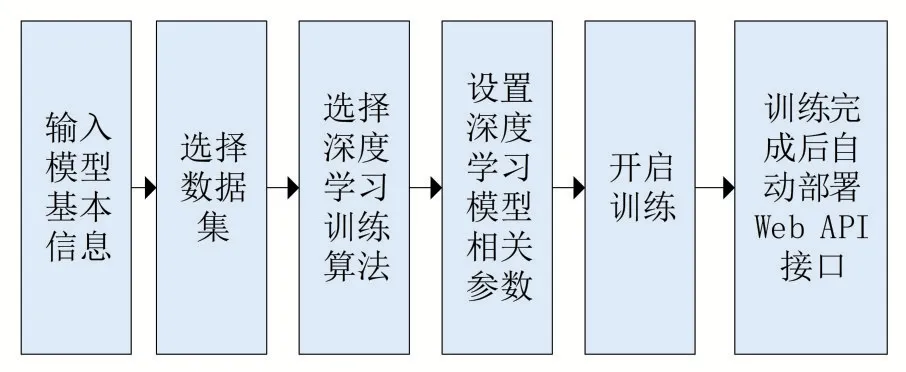
圖4 自定義機器學習模型構建過程
首先需要填寫模型的基本信息,包括:模型名稱、模型標識符、用途說明等。然后選擇需要識別的數據集,可以從病蟲害和植物數據庫中選擇全部類別,也可以選擇其中的某些種類。深度學習模塊會根據用戶選擇的數據類別讀取相應的圖像集進行訓練。接下來可以選擇深度學習網絡模型和算法,系統提供了RESNET-50和VGG16等常用網絡模型可供選擇。接著可以設置深度學習的相關參數,包括損失函數、優化器、迭代次數、批量大小等參數。模型構建完成后,可以開啟模型訓練。模型訓練完成后,會自動部署到服務器,并提供Web API接口進行圖像識別。其中數據集構建界面如圖5所示。
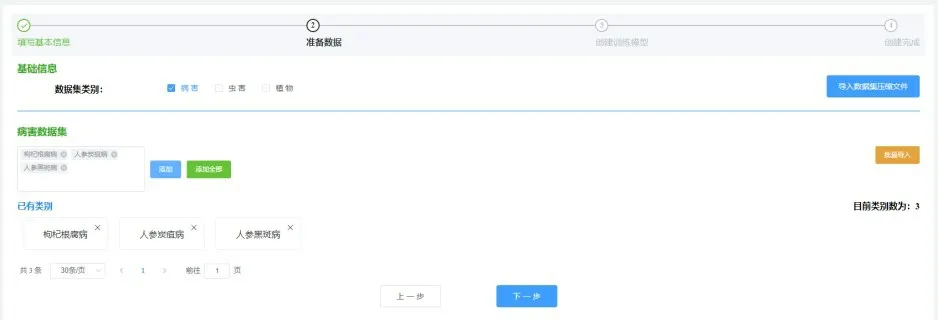
圖5 自定義數據集
2.3 基于深度學習的病蟲害識別
本文采用深度學習來構建病蟲害的智能識別模塊,該部分主要實現了深度網絡的訓練并將收斂穩定后的網絡模型部署到Web服務器,其主要流程如圖6所示。
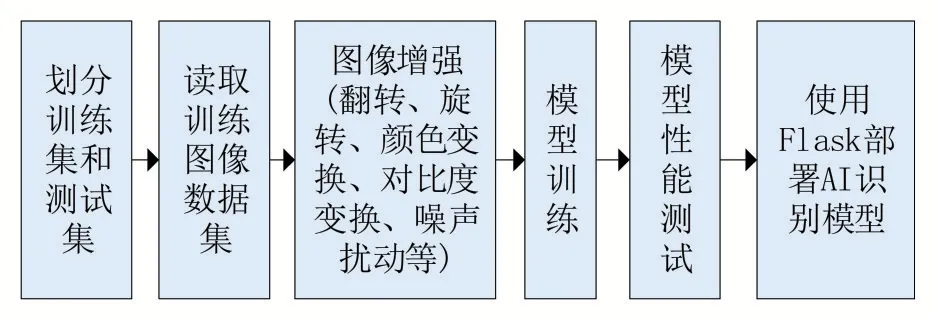
圖6 深度學習模型訓練流程
在深度學習模型訓練過程中,對要識別的每種病蟲害數據,使用70%的圖片作為訓練集,20%的圖片作為測試集,剩余的作為驗證集。首先讀取訓練集的圖像數據,并進行圖像增強,包括圖片翻轉、旋轉、顏色變化、對比度增強、噪聲擾動等。然后根據之前設置好的模型參數進行訓練,神經網絡模型收斂穩定后,進行模型性能測試。在多次調整相應的參數后,將最終識別效果較好的模型通過Flask部署到Web服務器,從而實現對前端提交圖像的智能識別。
在實際應用中,本文使用的深度學習服務器硬件環境如下:操作系統為Ubuntu 16.04.6 LTS;處理 器 為Intel(R)Xeon(R)Silver 4116 CPU@2.10GHz;內存為DDR4 128 G;顯卡為4×GeForce RTX2080Ti;開發環境為Anaconda3+Py-Torch+Pandas+Flask。
本系統對包含14種作物、26種病害的共54306張公開PlantVillage植物病害數據集進行了拓展,對其進行了補充,對包括穿孔病、白粉病、黑斑病、灰霉病、霜霉病、煤污病等15種常見病害進行識別,最好的識別準確率約92%,單張圖片識別平均耗時0.85秒,效果良好。
3 系統應用
本文構建了15種病害和30種蟲害的常見園林植物病蟲害數據庫,并利用深度學習進行模型訓練。其中幾種常見的病害和蟲害如圖7所示。

圖7 園林植物常見病蟲害數據集的部分樣本
系統提供了Web和APP兩種方式的智能識別界面,其中Web識別效果如圖8所示。
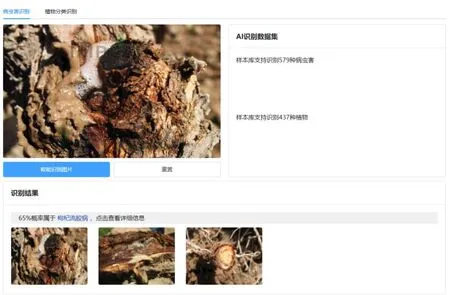
圖8 病蟲害識別界面
用戶上傳病蟲害圖片后,系統智能識別引擎會對圖片進行識別,并給出概率最大的病蟲害名稱,用戶可以點擊查看相應的病蟲害詳情并獲得防治方法。
4 結語
深度學習作為一種可方便實現圖像特征自動提取的技術,解決了傳統農林業中僅依靠經驗豐富的專家診斷模式所存在的問題,在園林種植減災和養護領域具有廣闊的前景。本文提出了一個基于深度學習的園林植物病蟲害識別系統,構建了常見的園林植物數據庫、病害和蟲害數據庫,同時還提供了一個允許用戶自定義構建病蟲害識別模型的方法,通過與深度神經網絡模型相結合,實現了對植物病蟲害快速、高效的識別。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
紅領巾·萌芽(2017年5期)2017-06-23 10:35:59
財經(2017年2期)2017-03-10 14:35:35
爆笑show(2016年7期)2017-02-09 09:36:13
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
