用于齒輪箱復(fù)合故障診斷的三階段混合式特征選擇方法研究*
2022-10-11 06:13:48章翔峰
制造技術(shù)與機(jī)床 2022年10期
章翔峰 劉 迪 姜 宏
(新疆大學(xué)機(jī)械工程學(xué)院,新疆烏魯木齊 830046)
旋轉(zhuǎn)機(jī)械在工業(yè)應(yīng)用中扮演著極其重要的角色,而齒輪箱幾乎是所有旋轉(zhuǎn)機(jī)械中必不可少的組成部分[1]。因此,對齒輪箱進(jìn)行故障診斷是維護(hù)旋轉(zhuǎn)機(jī)械設(shè)備正常運(yùn)行的必要手段。
目前,對齒輪箱中單部件和單故障類型的研究已經(jīng)比較深入,周建民等[2]提取時域特征和能量熵特征,基于相關(guān)性、單調(diào)性和魯棒性3種指標(biāo)從中選擇最佳的軸承退化特征;Zhang K等[3]結(jié)合了多種特征選擇模型,提出了一種混合式特征選擇算法,應(yīng)用于選擇軸承和定子繞組的特征頻率。而對復(fù)合故障診斷的研究往往側(cè)重于同一部件,如齒輪或軸承,胡愛軍等[4]以最大相關(guān)峭度為依據(jù)優(yōu)化變分模態(tài)分解(variational mode decomposition, VMD)參數(shù),結(jié)合1.5維譜用以分離滾動軸承復(fù)合故障特征;張振海等[5]提取齒輪振動信號的小波包能量譜特征,通過多分類支持向量機(jī)(multi-class support vector machine,MSVM)進(jìn)行診斷。然而,齒輪箱中往往存在不同部件故障同時發(fā)生,這種復(fù)合故障卻很少被研究。
因此,研究不同部件故障同時發(fā)生的復(fù)合故障診斷方法成為故障診斷領(lǐng)域相關(guān)研究人員的一項(xiàng)重要任務(wù)。軸承和齒輪作為齒輪箱中最重要的部件,因受多元激勵共同作用等惡劣環(huán)境影響,極易發(fā)生故障,且當(dāng)軸承出現(xiàn)故障后,會影響齒輪的振動特性,反之亦然[6],加之復(fù)合故障特征之間發(fā)生耦合,使得齒輪-軸承復(fù)合故障的診斷變得極為困難。故障診斷通常由特征提取和模式識別兩部分組成,獲得一個優(yōu)質(zhì)的特征集是實(shí)現(xiàn)故障診斷的關(guān)鍵,然而,由于故障信息分散在多個域中且特征間相互耦合等影響,構(gòu)造的特征集中往往存在著大量冗余和無關(guān)的特征。這些特征對分類器提供的信息有限,甚至?xí)斐筛蓴_[7],且特征集維數(shù)過大會導(dǎo)致分類器需要更長的訓(xùn)練時間。
為了克服上述問題,國內(nèi)外學(xué)者通過特征選擇技術(shù)從原始高維特征集中篩選出敏感特征,在提升分類準(zhǔn)確率的同時盡可能減少特征集的維數(shù)。李帥位等[8]提出了一種利用Grassmann流形的多聚類特征選擇方法,應(yīng)用于滾動軸承故障數(shù)據(jù)集。Zhang X L等[9]提出了一種混合式算法應(yīng)用于滾動軸承故障和轉(zhuǎn)子故障,該方法可以在獲得最優(yōu)特征子集的同時優(yōu)化支持向量機(jī)(support vector machine,SVM)的參數(shù)。Buchaiah S等[10]使用了一種嵌入式特征選擇方法-隨機(jī)森林來確定軸承故障特征集的最優(yōu)子集,并在進(jìn)一步使用降維技術(shù)進(jìn)行融合后通過SVM進(jìn)行分類,這些方法取得了較好的應(yīng)用表現(xiàn),但存在計(jì)算復(fù)雜,多個關(guān)鍵參數(shù)需要人為設(shè)定等問題。
特征選擇算法已在故障診斷領(lǐng)域中得到廣泛應(yīng)用,但在復(fù)合故障診斷中的應(yīng)用仍較為少見,基于以上分析,本文結(jié)合了多篇前人在故障診斷中開展的應(yīng)用,提出了一種綜合多種特征選擇模型的三階段混合式特征選擇方法,用于齒輪箱中的齒輪-軸承復(fù)合故障診斷。首先通過從時域、頻域及特征值域中提取故障特征以獲取更全面的故障信息,然后在特征排序階段中利用4種過濾式模型從3個測度對特征進(jìn)行評價,接著在加權(quán)排序階段中通過模型的評價結(jié)果在徑向基(radial basisfunction,RBF)網(wǎng)絡(luò)中表現(xiàn)出的分類精度,以加權(quán)的方式綜合不同評價結(jié)果,對特征重新進(jìn)行排序,然后在特征篩選階段中使用RBF網(wǎng)絡(luò)結(jié)合3種啟發(fā)式搜索方法,按照排序結(jié)果迭代篩選出最優(yōu)特征子集,最后通過RBF網(wǎng)絡(luò)實(shí)現(xiàn)故障分類。
1 理論基礎(chǔ)
1.1 特征選擇模型
依照評價標(biāo)準(zhǔn)的不同,可將特征選擇算法分為過濾式(filter)、封裝式(wrapper)、嵌入式(embedded)和混合式(hybrid)算法[11]。其中過濾式算法依據(jù)評價準(zhǔn)則對特征進(jìn)行排序,計(jì)算效率高,但評估結(jié)果與后續(xù)分類器的性能偏差較大;而封裝式算法依據(jù)識別準(zhǔn)確率篩選特征,偏差小,但計(jì)算量大,不適合高維數(shù)據(jù)集;因此先使用過濾式算法對特征進(jìn)行評價,再使用封裝式算法按照評價結(jié)果精細(xì)篩選的混合式算法得到了廣泛應(yīng)用。
由于僅使用單一評價準(zhǔn)則會造成選擇后的子集中存在無關(guān)或冗余特征,且無法保證子集是最優(yōu)的而非次優(yōu)的,因此本文使用多種特征選擇模型綜合考慮不同評價準(zhǔn)則,首先使用4種過濾式算法分別通過距離、信息和相關(guān)性測度對特征進(jìn)行評價。
1.1.1 費(fèi)舍爾分值法
在費(fèi)舍爾分值(Fisher score,FS)法中,每個特征都是根據(jù)其Fisher標(biāo)準(zhǔn)分?jǐn)?shù)獨(dú)立選擇的,F(xiàn)isher得分越大,該特征的辨別力就越強(qiáng)。給定特征x,F(xiàn)S的計(jì)算公式如下[12]
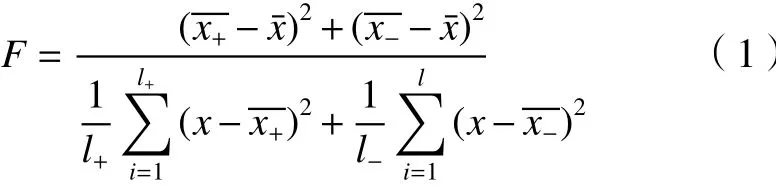
其中:x+、x-分別表示正樣本和負(fù)樣本,l+、l-分別表 示正樣本和負(fù)樣本的個數(shù),-表示均值。
1.1.2 距離評估技術(shù)
距 離 評 估 技 術(shù)(distance evaluation technique,DET)與FS同為基于距離測度對特征進(jìn)行評價,文獻(xiàn)[13]提出了一種改進(jìn)DET算法,通過計(jì)算類間距離和類內(nèi)距離的比值作為距離評估因子,得分越大,相應(yīng)的特征越易于區(qū)分不同類。
1.1.3 信息增益
信息增益(information gain,IG)基于信息測度對特征進(jìn)行評價,是對特征的先驗(yàn)不確定性和預(yù)期的后驗(yàn)不確定性之間差異的度量,特征的信息增益越大,判別能力越好。給定特征x和其對應(yīng)的標(biāo)簽y,IG的計(jì)算公式如下:
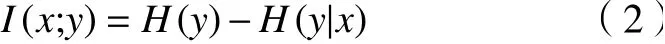
其中:H() 表示信息熵,H(|)表示條件熵。
1.1.4 皮爾遜相關(guān)系數(shù)
皮爾遜相關(guān)系數(shù)(Pearson correlation coefficient,PCC)基于相關(guān)性測度對特征進(jìn)行評價,它可以用來衡量特征和類之間的相關(guān)性。得分越高,特征區(qū)分不同類的能力越好。給定特征x和其對應(yīng)的標(biāo)簽y,PCC的計(jì)算公式如下

其中:-表示均值。
然后在封裝式算法中將采用3種隨機(jī)搜索策略來調(diào)整子集以獲得近似的最優(yōu)子集。
1.1.5 二分查找
二分查找(binary search,BS)將候選特征集分為兩部分:左子集和右子集。如果左子集的分類錯誤率低于閾值,則保留左子集以進(jìn)行進(jìn)一步搜索,并刪除右子集,反之亦然。當(dāng)下一個左子集和右子集的錯誤率都高于閾值時,迭代過程停止。
1.1.6 序列向前查找
序列向前查找(sequential forward search,SFS)的過程是在開始子集中一次增加1個特征。當(dāng)分類精度沒有隨著特征的增加而提高時,迭代過程停止。
1.1.7 序列向后查找
序列向后查找(sequential backward search, SBS)的過程與SFS相反,在開始子集中一次減少1個特征。當(dāng)分類精度沒有隨著特征的減少而提高時,迭代過程停止。
1.2 徑向基網(wǎng)絡(luò)
RBF網(wǎng)絡(luò)是一種具有3層結(jié)構(gòu)的前饋網(wǎng)絡(luò)模型[14],憑借結(jié)構(gòu)簡單,收斂速度快等優(yōu)點(diǎn)被廣泛應(yīng)用于故障診斷領(lǐng)域中,其基本結(jié)構(gòu)如圖1所示。本文中使用高斯函數(shù)作為RBF網(wǎng)絡(luò)的激活函數(shù),并通過最小化均方誤差來訓(xùn)練網(wǎng)絡(luò),當(dāng)誤差達(dá)到目標(biāo)或隱藏層神經(jīng)元個數(shù)達(dá)到最大時結(jié)束訓(xùn)練。
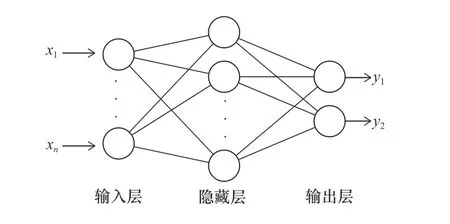
圖1 RBF網(wǎng)絡(luò)結(jié)構(gòu)
2 故障診斷流程
2.1 構(gòu)造故障特征集
齒輪箱的振動信號中包含了豐富的故障信息,由于從單一尺度中提取故障特征很容易造成故障信息的丟失。因此為了更精細(xì)地捕捉隱藏在振動信號中的故障信息,本文首先使用經(jīng)驗(yàn)?zāi)B(tài)分解(empirical mode decomposition,EMD)算法對原始振動信號進(jìn)行分解,然后選取包含有用信息的前8個固有模態(tài)分量(intrinsic mode function,IMF),最后分別從原始振動信號和前8個IMF中提取時域、頻域特征以及特征值域特征。特征值域特征[15]是通過將振動信號轉(zhuǎn)化為圖信號并變換到特征值域,從中提取的特征信息,它能夠表征振動信號的變化特征。
最終構(gòu)造的故障特征集中包括11個時域特征,13個頻域特征[13]以及6個特征值域特征,共提取(11+13+6)×9=270個特征構(gòu)造原始特征集。特征集中時域特征編號為1~99,頻域特征編號為100~216,特征值域特征編號為217~270,特征參數(shù)的具體計(jì)算公式見表1。
表1中,時域特征參數(shù)T1和T3~T5反映時域振動幅值和能量大小,T2和T6~T11反映時域信號的時間序列分布情況;頻域特征參數(shù)F1反映頻域振動能量的大小,F(xiàn)2~F4,F(xiàn)6和F10~F13反映頻譜的分散或集中程度,F(xiàn)5和F7~F9反映主頻帶位置的變化;特征值域特征參數(shù)P1~P6反映圖信號在特征值域的幅值和能量以及波動情況的變化。

表1 特征參數(shù)
此外,為了消除奇異樣本數(shù)據(jù)導(dǎo)致的不良影響,對特征集使用式(4)進(jìn)行歸一化處理。
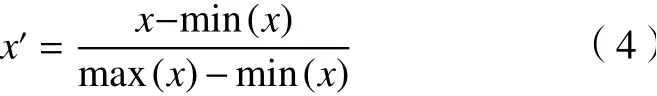
其中:x表示原始數(shù)據(jù),x′表示經(jīng)歸一化處理后的數(shù)據(jù)。
2.2 特征選擇算法
本文提出的特征選擇方法由3個階段組成,分別為特征排序階段、加權(quán)排序階段以及特征篩選階段,具體流程圖如圖2所示。
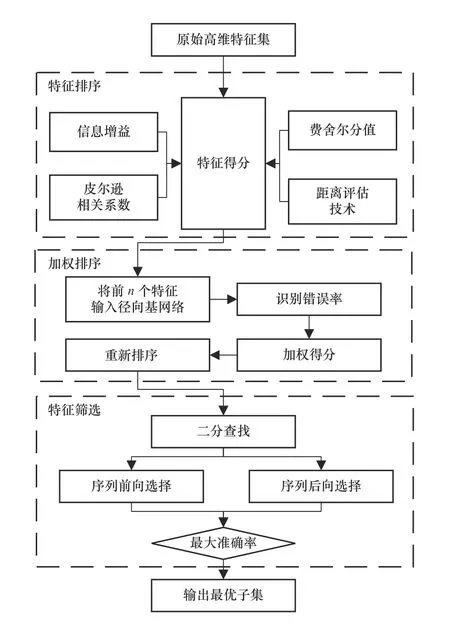
圖2 特征選擇流程圖
特征排序階段中,使用FS、DET、MI和Person相關(guān)系數(shù)這4種過濾式模型分別從距離測度、信息測度和相關(guān)性測度對故障特征進(jìn)行評價,得到4組特征得分。
加權(quán)排序階段中,首先按照特征得分對特征進(jìn)行排序,選取排名最高的前n個特征輸入RBF網(wǎng)絡(luò)進(jìn)行分類。然后將識別錯誤率作為權(quán)值,與每個特征排名的乘積作為對應(yīng)特征的新得分。對4組特征得分重復(fù)上述操作后,每個特征均得到4個新得分,將新得分求和即為該特征的加權(quán)得分結(jié)果,加權(quán)機(jī)制如式(5)所示,最后按照由小到大的順序重新排序。

其中:SNew表示某個特征的加權(quán)得分,EFS和RFS分別表示FS等模型的識別錯誤率和在對應(yīng)模型的評價結(jié)果中該特征的排名。
重新排序后的特征,充分考慮了特征在不同評價準(zhǔn)則中的表征能力,將冗余、無關(guān)特征和敏感特征以排名劃分開。新的排序結(jié)果中,敏感特征排名靠前,而冗余和無關(guān)特征排名靠后,因此僅選擇前幾個特征便可以替代原始高維數(shù)據(jù)集,使特征集達(dá)到最高的識別準(zhǔn)確率。
特征篩選階段中,首先通過BS快速篩除排名靠后的冗余和無關(guān)特征,大致確定最優(yōu)子集,然后以BS獲得的子集為起點(diǎn),分別使用SFS和SBS選擇最優(yōu)子集,最后比較兩個子集,以其中識別準(zhǔn)確率最高的一個為最優(yōu)子集。
2.3 故障診斷流程
本文提出的齒輪箱復(fù)合故障診斷方法主要分為3個步驟:
(1)將樣本集隨機(jī)劃分為測試樣本和訓(xùn)練樣本,然后從訓(xùn)練樣本的原始振動信號中提取故障特征,構(gòu)造高維故障特征集。
(2)對原始高維特征集使用本文提出的特征選擇方法,得到最優(yōu)特征子集,然后對測試樣本僅提取篩選后的最優(yōu)特征。
(3)使用訓(xùn)練樣本的最優(yōu)特征子集對RBF分類器進(jìn)行訓(xùn)練,然后使用訓(xùn)練好的分類器對測試樣本進(jìn)行故障分類。
3 實(shí)驗(yàn)驗(yàn)證
為了驗(yàn)證本文方法的有效性,使用SQI公司的風(fēng)電機(jī)組驅(qū)動系統(tǒng)故障診斷試驗(yàn)臺,采集齒輪箱不同運(yùn)行狀態(tài)下的振動信號。試驗(yàn)臺如圖3所示,故障齒輪與故障軸承均安裝在平行軸齒輪箱輸入軸上,齒輪與軸承故障均通過人為加工,故障類型包括齒輪的磨損故障、裂紋故障、斷齒故障以及軸承的內(nèi)圈故障、外圈故障和滾動體故障。采集的樣本類型包括正常狀態(tài)、6種單故障狀態(tài)和4種齒輪-軸承復(fù)合故障狀態(tài),詳細(xì)描述如表2所示。
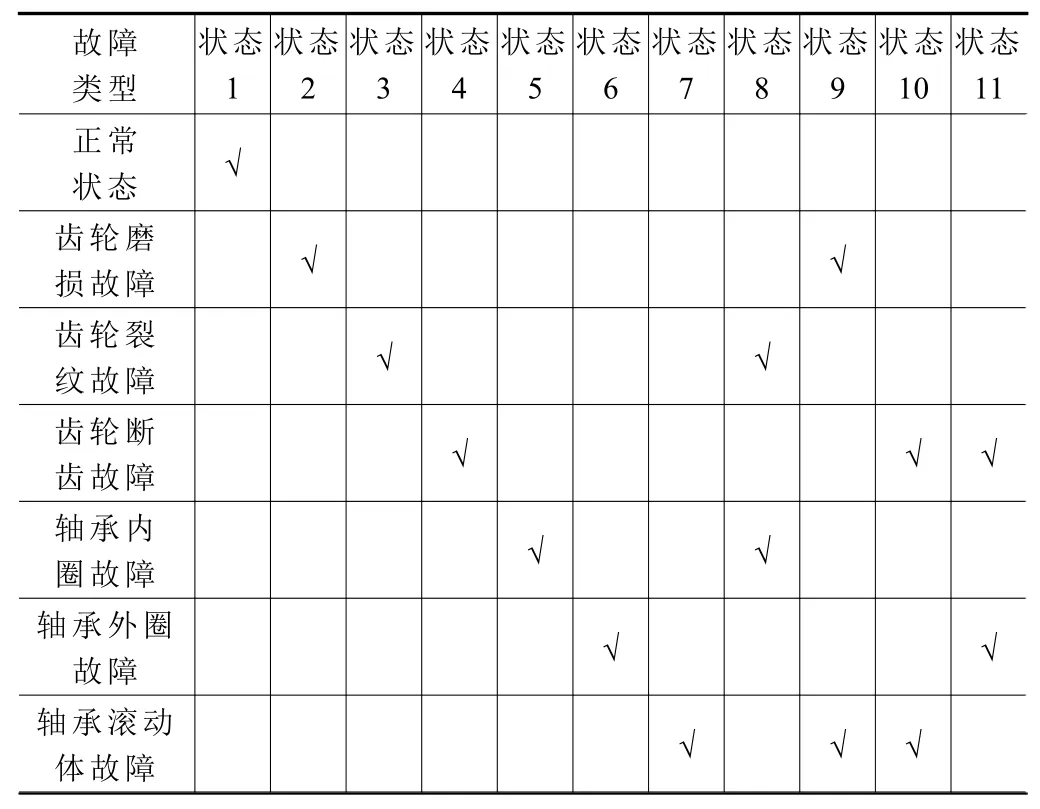
表2 樣本類型
采集過程中,輸入軸轉(zhuǎn)速約為1 000 r/min,采樣頻率設(shè)置為20 480 Hz,對每種狀態(tài)類型各采集200個樣本,其中4種復(fù)合故障的時域圖如圖4所示,可以明顯看出不同齒輪-軸承復(fù)合故障間的時域差異較小,難以直接區(qū)分。將故障樣本集按照1∶3的比例劃分為測試集和訓(xùn)練集,然后按照本文提出的診斷方法進(jìn)行實(shí)驗(yàn)。
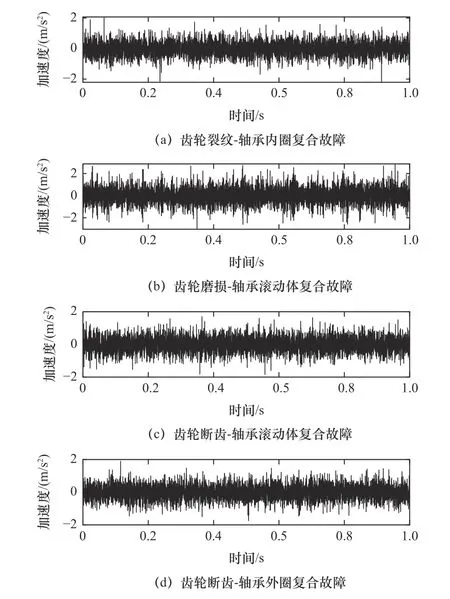
圖4 不同齒輪-軸承復(fù)合故障的時域波形
首先將訓(xùn)練集中的270個特征分別通過4種過濾式模型按照判別能力由高到低排序,然后分別按照排序結(jié)果選取前20個特征輸入RBF網(wǎng)絡(luò),當(dāng)均方誤差小于10-10或神經(jīng)元達(dá)到200個時,訓(xùn)練停止。訓(xùn)練重復(fù)10次,取平均值作為4組次優(yōu)子集的識別錯誤率,F(xiàn)S、DET、IG、PCC的識別錯誤率依次為2.18%、3.09%、6.82%和9.64%。將識別錯誤率作為權(quán)值,按照式(5)計(jì)算特征的新得分,以加權(quán)排序后排名最高的前兩個特征為例:
第2個特征:24×0.021 8+58×0.030 9+5×0.068 2+14×0.096 4=4.006
第15個特征:25×0.021 8+63×0.030 9+4×0.068 2+15×0.096 4=4.210
將新得分之和按從低到高重新排序即為最終的加權(quán)排序結(jié)果,4種過濾式模型和加權(quán)排序的部分結(jié)果如表3所示。從表3中可以看出傳統(tǒng)的時域、頻域特征在信息和相關(guān)性測度中的表現(xiàn)要差于特征值域特征,但在距離測度中的表現(xiàn)更優(yōu),因此加權(quán)排序結(jié)果中排名靠前的特征中,時域、頻域特征的占比要高于特征值域特征。
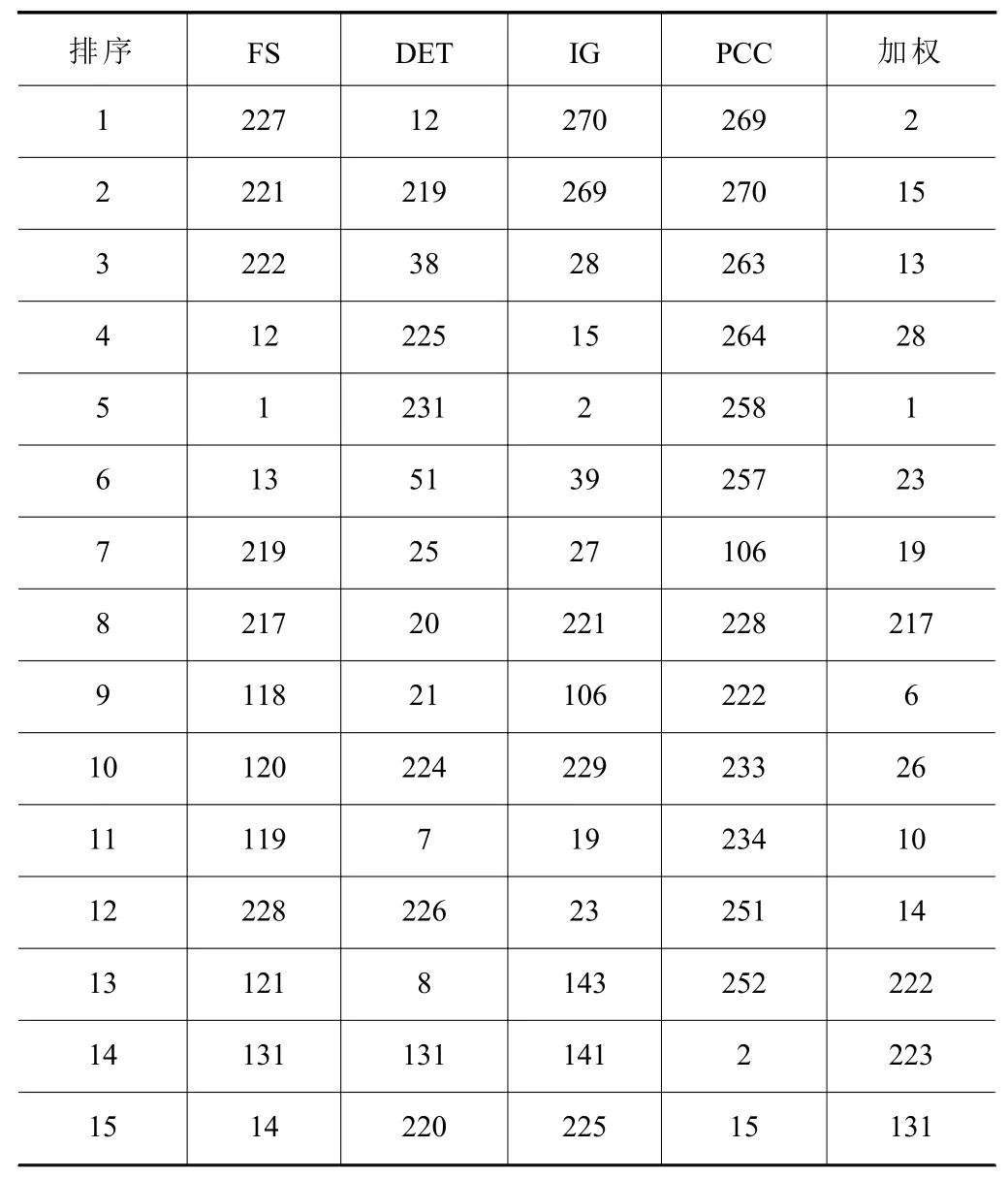
表3 排序結(jié)果
然后以經(jīng)過加權(quán)排序后的新特征集為起點(diǎn),首先使用BS將特征集均分為左子集和右子集,取其中識別準(zhǔn)確率最高的一個為新起點(diǎn),當(dāng)新的左右子集的識別準(zhǔn)確率均低于起點(diǎn)時停止迭代,此時由BS獲取的最優(yōu)子集包含17個特征。接著以這17個特征為起點(diǎn),分別使用SBS和SFS各獲取一個最優(yōu)子集,分別包含17和18個特征,然后比較兩個子集的識別準(zhǔn)確率,取二者中最高的一個作為最優(yōu)子集,本例中即是由SFS獲取的包含18個特征的子集,具體篩選過程如圖5所示,圖中方框內(nèi)為子集包含的特征,括號內(nèi)為子集的識別準(zhǔn)確率,并在括號前標(biāo)注了子集內(nèi)特征的個數(shù)。

圖5 特征篩選階段
最終測試集中僅提取經(jīng)特征選擇后的18個特征,使用經(jīng)訓(xùn)練集訓(xùn)練后的RBF網(wǎng)絡(luò)分類,得到的混淆矩陣如圖6所示,11種故障狀態(tài)均取得了較好的診斷結(jié)果,測試集的平均準(zhǔn)確率達(dá)到了94.42%,然而狀態(tài)9-齒輪磨損-軸承滾動體復(fù)合故障的識別準(zhǔn)確率僅為85.33%,其誤分類幾乎都出現(xiàn)在狀態(tài)7-軸承滾動體故障中,從圖6中可以看出誤分類大都發(fā)生在不同部件故障間以及復(fù)合故障和組成復(fù)合故障的單故障間,證明復(fù)合故障和單故障的特征相似度較高,因而降低了分類精度。

圖6 測試集的混淆矩陣
為了驗(yàn)證本文提出的特征選擇方法的優(yōu)越性,設(shè)置了3組對照實(shí)驗(yàn),從經(jīng)加權(quán)排序階段重新排序后的特征集中挑選特征子集,分別為:實(shí)驗(yàn)1,使用排名前20個特征;實(shí)驗(yàn)2,隨機(jī)使用20個特征;實(shí)驗(yàn)3,使用排名后20個特征。3組實(shí)驗(yàn)均使用RBF網(wǎng)絡(luò)作為分類器,網(wǎng)絡(luò)參數(shù)保持一致,每組實(shí)驗(yàn)重復(fù)10次,取效果最優(yōu)的1次作為結(jié)果,實(shí)驗(yàn)對比結(jié)果如表4所示。
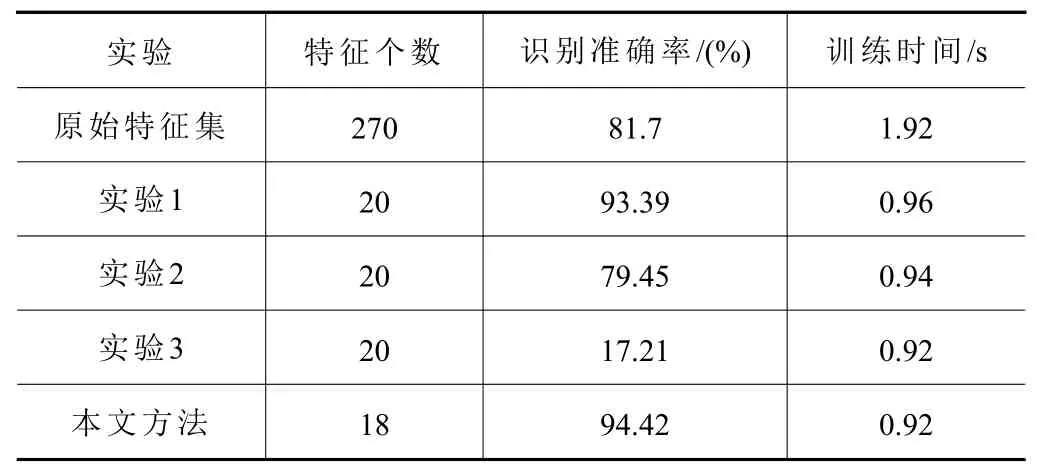
表4 實(shí)驗(yàn)對比結(jié)果
相比于直接使用原始高維特征集,實(shí)驗(yàn)1的識別準(zhǔn)確率提升了11.69%,實(shí)驗(yàn)2和實(shí)驗(yàn)3的識別準(zhǔn)確率則分別降低了2.25%和64.49%。充分說明經(jīng)加權(quán)排序階段重新排序后,排名靠前的特征對不同故障類別的區(qū)分能力更好,而排名靠后的特征表征能力較差,無益于故障分類任務(wù),甚至?xí)绊懱卣骷姆诸惸芰Α4送猓?dāng)僅使用一種過濾式模型,將排序后的前18個特征作為最優(yōu)子集時,同樣將實(shí)驗(yàn)重復(fù)10次,取效果最優(yōu)的1次作為結(jié)果,得到僅使用FS、DET、IG和PCC的測試集識別準(zhǔn)確率,依次為:92.48%、92.42%、91.27%和87.45%,均低于本文方法,說明不同測度對于特征的評價能力不同,且單一測度獲得的排序結(jié)果中存在冗余特征,而本文方法則篩除了冗余特征,在同樣的特征維數(shù)下,取得了最高的識別準(zhǔn)確率。
與直接使用原始高維特征集進(jìn)行故障分類相比,可以發(fā)現(xiàn)在應(yīng)用本文提出的特征選擇方法后,在特征個數(shù)減少了93.3%,分類器訓(xùn)練時間縮短了52%的同時,提高了12.72%的識別準(zhǔn)確率。證明本文方法可以篩除對故障類別不敏感的特征,僅保留判別能力最好的特征,可以在降低特征維數(shù)、縮短訓(xùn)練時間的同時,顯著提高故障分類的準(zhǔn)確率。
4 結(jié)語
本文針對齒輪箱中齒輪-軸承復(fù)合故障存在故障特征耦合,特征信息分散等問題,提出了一種綜合多種特征選擇模型的三階段混合式特征選擇方法。經(jīng)由包含單故障和復(fù)合故障的試驗(yàn)樣本集進(jìn)行驗(yàn)證,試驗(yàn)結(jié)果表明本方法可以有效降低故障特征集的維數(shù)并提升分類能力。
(1)本文提出的特征選擇算法綜合了多種評價標(biāo)準(zhǔn)的優(yōu)勢,有效篩除了原始特征集中的冗余特征和無關(guān)特征,并通過啟發(fā)式搜索策略迭代搜索獲取最優(yōu)特征子集。
(2)本文提出的特征選擇方法能夠從高維特征集中自動確定最優(yōu)特征子集,從而在成功降低特征維數(shù)的同時取得最高的識別準(zhǔn)確率。
(3)與直接使用原始高維特征集相比,應(yīng)用本文提出的特征選擇方法減少了93.3%的特征個數(shù)并提升了12.72%的識別準(zhǔn)確率,同時也縮短了測試集故障特征的提取時間和分類器的訓(xùn)練時間。
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2022年11期)2022-02-14 07:14:12
科普童話·學(xué)霸日記(2020年1期)2020-05-08 16:45:11
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
小天使·一年級語數(shù)英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
重慶工商大學(xué)學(xué)報(自然科學(xué)版)(2015年10期)2015-12-28 07:43:58
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機(jī)械與電子(2014年1期)2014-02-28 02:07:31
