基于自動編碼器的內部威脅檢測技術
2022-10-17 13:53:04孫小雙
計算機工程與設計 2022年10期
孫小雙,王 宇
(1.航天工程大學 研究生院,北京 101416;2.航天工程大學 航天信息學院,北京 101416)
0 引 言
相比于外部威脅,內部威脅具有隱蔽性、多樣性及高危性。內部威脅活動通常分布在大量正常行為中,而且內部威脅需要處理和分析大量不同類型的數據,從網絡流量、文件訪問日志、電子郵件記錄,到員工信息等,如何從海量數據中挖掘關聯信息、識別內部威脅依然是內部威脅檢測技術面臨的難題。
基于行為特征的內部威脅檢測主要是從數據中提取行為特征向量或者對行為序列建模,在此基礎上進行異常檢測。由于異常行為和異常用戶具有未知性,異常檢測方法通常采用無監督學習方法。而傳統的無監督機器學習方法受到特征維度限制,本文提出基于自動編碼器的內部威脅檢測方法,旨在通過深度學習模型從廣泛的審計數據中學習非線性相關性,檢測異常行為。
1 相關研究
內部威脅檢測相關研究較為豐富。文獻[1-3]從不同視角梳理了內部威脅的發展歷程、技術研究和挑戰等。內部威脅檢測技術發展過程中運用的主要方法包括基于規則的方法、統計分析法、圖算法、機器學習等。統計分析法運用數學方式建立模型,不需要與領域相關的先驗知識,對異常事件較為敏感,但是由于主觀確定閾值存在有限性和靜態性。基于規則的方法利用專家庫生成規則識別內部惡意人員,在結果固定且類別較少的分類中是很有意義的,但是它嚴重依賴領域知識,需要不斷對規則庫進行更新以應對新威脅。圖算法通過數據間的關聯關系構建圖結構,根據圖結構的變化識別惡意行為。例如,Gamachchi等[4]提出了一個基于圖形化和異常檢測技術的惡意用戶隔離框架。該架構主要由圖形處理單元(GPU)和異常檢測單元(ADU)兩部分組成,將多維數據源的數據格式化并送入GPU,GPU生成網絡信息資產關系圖,并為每個用戶計算圖參數。然后將計算圖和時變數據輸入ADU,執行隔離森林算法,輸出每個用戶的異常分數作為判斷標準。文獻[5-9]采用淺層機器學習的方法,例如K-means、Support Vector Machine(SVM)、Isolation Forest等,機器學習是在統計學的理論基礎上發展起來的,相比于統計分析法,機器學習會犧牲可解釋性獲得強大的預測能力,在實際應用中具有更高的準確度;而相比基于規則的算法,機器學習可以不斷學習新的規則,不需要人工更新規則庫。但是面對體量龐大且結構日益復雜的審計數據,傳統機器學習方法受到特征維度等因素的限制,研究者又將目光轉向深度學習。
目前,應用于內部威脅檢測的深度學習模型[10-14]包括卷積神經網絡模型(CNN)、長短期記憶神經網絡模型(LSTM)、自動編碼器神經網絡模型(auto-encoder)等及其改進或組合模型。文獻[10]使用卷積層從輸入樣本中捕獲局部特征,然后使用LSTM層考慮這些給定特征的順序。文獻[14]利用集成的深度自編碼器對重構誤差進行學習實現異常檢測。文獻[14]采用LSTM模型和多頭注意力機制來檢測異常網絡行為模式,并利用Dempster條件規則對信念進行更新,用于融合證據,實現增強預測。與傳統機器學習相比,深度學習不需要復雜的特征工程,算法適應性強;而且隨著數據量的增大,深度學習在學習能力和檢測指標上有著更好的表現。
2 基于自動編碼器的內部威脅檢測模型
基于自動編碼器的內部威脅檢測模型采用樹結構分析方法,從大量審計日志中分析并構建基于樹結構的用戶行為特征圖,并將樹節點表示為用戶特征向量。采用自動編碼器模型對特征向量進行學習,將輸入和輸出之間的重建誤差作為異常分數,利用Z-score方法判斷異常等級。其整體工作流程如圖1所示。
2.1 基于樹結構分析的特征向量生成
由于審計數據體量大、數據類型多樣、結構復雜,本文采用樹結構方法[15]分析用戶審計數據。通過層層屬性分析,形成樹形結構,建立的樹節點可以用特征向量表示。其優勢在于分析速度快,具有良好的擴展性,而且為所有用戶提供了行為特征的一致性表示。
如圖2所示,先按照時間域和行為域對每條行為記錄分類。時間域從工作時間與非工作時間上進行劃分,工作時間和非工作時間是通過學習用戶日常上下班時間得到的。行為域包括用戶的登錄行為、網站訪問、郵件收發、文件操作、設備使用等,不同行為域的活動變化反映了用戶不同的意圖。可以根據實際情況對行為域進行擴展,從而更全面地刻畫用戶行為特征。
在行為域下,行為記錄接著按照設備-活動-屬性的樹結構進行分析。設備是指用戶登錄的設備型號;活動是指用戶在某行為域下的具體操作,例如文件的復制、粘貼、刪除等;屬性指操作行為附帶的特征,例如收發郵件的附件大小、數量等。
通過樹結構分析,如果得到的節點在原樹結構中存在,則節點的計數值增加,如果不存在,則插入該新節點,最后得到用戶在一段時間內的基于樹結構的行為特征圖。行為特征圖可以編碼為特征向量,長度取決于樹結構分析中的節點數目。由于不同節點間存在時間或行為的關聯關系,可以通過對不同節點進行組合獲取新的特征向量,例如非工作時間的活動頻率為不同行為域下非工作時間活動頻率的總和。
2.2 基于自動編碼器的異常檢測
2.2.1 模型原理及算法
內部威脅檢測屬于異常檢測的一類,通常采用無監督學習方法,而傳統的機器學習方法受特征維度限制,隨著維度數升高,檢測性能受到影響。本文選擇基于自動編碼器的異常檢測方法,它是一種基于神經網絡的無監督學習算法,是PCA類型的模型的非線性擴展,適用于高維數據。通過訓練正常數據,自動編碼器學習到正常數據的有效特征和內在聯系,在對異常數據進行重構時會產生較大誤差,有利于檢測未知攻擊。
設D維樣本x(n)∈RD, 1≤n≤N, 自動編碼器將數據映射到特征空間,得到樣本的編碼z(n)∈RM, 1≤n≤N, 并通過這組編碼重構原來的樣本。最簡單的自動編碼器是兩層神經網絡。其中,輸入層到隱藏層用來編碼,隱藏層到輸出層用來解碼,層與層之間是全連接關系,自動編碼器的網絡結構如圖3所示。編解碼過程中,隱藏層的活性值z為x的編碼,x′為自動編碼器的輸出重構數據,即
z=f(W(1)x+b(1))
(1)
x′=g(W(2)x+b(2))
(2)
其中,W(1)、W(2)為權重矩陣,b(1)、b(2)為偏置,f、g為激活函數。令W(1)=W(2)T, 通過捆綁權重的方式減少自動編碼器的參數,易于學習,并在一定程度上起到正則化的作用。
當特征向量輸入到自動編碼器中,編碼器通過學習將數據有效壓縮至低維空間,解碼器將有效特征重構出與輸入特征相近的擬合數據,擬合數據與輸入數據的差值為重構誤差(reconstruction error)。自動編碼器正是通過最小化重構誤差來有效學習網絡參數的,即重構數據趨近于真實數據。異常檢測中把重構誤差作為異常分數來識別異常用戶。其計算方法如下所示
(3)
基于自動編碼器的異常檢測算法步驟如下:
輸入:按時間順序依次輸入某用戶第i天的行為特征向量xi=[xi,1,xi,2,…,xi,m],m為特征向量的長度。
步驟1 初始化函數。
步驟2 對特征向量進行歸一化處理。
步驟3 輸入訓練數據,通過反向傳播學習確定參數W、b。
步驟4 輸入測試數據,計算重構誤差。
輸出:按時間順序依次輸出某用戶第i天的行為特征向量的重構誤差。
2.2.2 模型體系結構及參數
自動編碼器體系結構的設計對自動編碼器的性能有重要影響。主要需要考慮以下幾個方面:
(1)神經網絡深度。神經網絡深度加深能增強特征的抽象程度和網絡的表達能力,但同時網絡中的超參數會增多,從而提高計算復雜度和訓練難度。本文通過實驗對比不同網絡結構的自動編碼器,既可以得到良好的特征表達,又能降低計算復雜度;
(2)損失函數。為了最大化正常和異常用戶行為之間的可分性,選擇損失函數來懲罰結構差異。因此,與熵相關的損失函數,如交叉熵損失函數(cross-entropy loss function)等,可能優于傳統的距離度量指標,如均方誤差(mean squared error)等。而且,交叉熵損失函數在誤差大時權重更新快,誤差小時權重更新慢,可以解決均方誤差損失函數權重更新過慢的問題;
(3)dropout rate。在輸入層和隱藏層后分別加入dropout層,使輸入數據和隱藏層神經單元按一定概率隨機從網絡中暫時丟棄,相當于減少中間特征的數量,增加每層特征之間的正交性,防止模型的過擬合,增強模型的泛化能力。
2.3 基于Z-score方法的異常等級分類
Z-score是一種低維特征空間中的參數異常檢測方法。它假定數據服從于高斯分布,異常值通常是分布尾部的數據點,遠離數據的平均值。距離的遠近取決標準差分數zi和設定閾值zth間的關系
(4)
其中,μ為原始數據的均值,σ為原始數據的標準差,zi表示了給定數據距離其均值的相差的標準差個數。這種方式將數據歸一化,提高了數據的可比性。
內部威脅行為類別多樣,異常分數與正常行為的分數差值也大小不一。部分異常行為隱藏在大量正常行為中,其經過異常檢測所得的異常分數與正常行為差較小,如果閾值設置過高可能會忽略這部分異常行為,而閾值設置過低則會導致誤判率升高,所以本文中的zth選取了1、2、3這3個不同的閾值,對用戶異常行為進行了等級劃分,根據不同異常等級的行為出現的頻次綜合判定用戶是否異常。
3 實驗分析
3.1 實驗準備
3.1.1 實驗設計
通過相關理論研究,本文對autoencoder的神經網結構和各項參數進行實驗設計,并將結果進行對比。另外,分別對PCA、isolation forest、autoencoder等異常檢測方法進行實驗設計,并將結果進行對比。通過準確率、精確率、召回率、ROC曲線和PR曲線對以上方法進行評估。
3.1.2 環境配置
實驗環境信息描述如下:系統環境為Windows操作系統;硬件配置為Inter(R)Core(TM)i7-7700H CPU@2.7 GHz,NVIDIA GeForce GTX1060,16 G內存IT硬盤;實驗框架為TensorFlow 2.1深度學習框架;開發語言為Python。
3.1.3 數據集選取
內部威脅數據在檢測算法的研究中至關重要,沒有可靠合適的數據,任何檢測技術都很難達到預期的效果。本文采用卡耐基梅隆大學CERT項目的內部威脅數據集進行實驗。
該數據集數據類型豐富,包括了主機日志、網絡日志、員工心理評價以及人力資源信息等,包含了1000名用戶502天時間里的320 770 727條行為記錄,是一個比較全面的內部威脅檢測數據集,其具體內容見表1。

表1 CERT-IT數據集
CERT-r4.2數據集從真實企業環境中采集,并加入了人工制造的攻擊行為,例如數據泄露、系統破壞等。其所包含的攻擊場景概括如下:
(1)用戶開始在非工作時間登錄賬戶,使用可移動存儲設備,并向某些網站上傳數據,存在數據泄露的風險;
(2)用戶頻繁瀏覽求職網站,并頻繁使用可移動存儲設備拷貝數據,存在竊取數據并跳槽的風險;
(3)用戶下載一個鍵盤記錄程序,然后用可移動存儲設備把它傳送到他上司的設備上。根據收集到的鍵盤日志,以上司的身份登錄賬戶,并群發郵件,在組織中引起恐慌。
3.2 評價標準
本文采用準確率(accuracy)、精確率(precision)、召回率(recall/TPR)、ROC曲線和PR曲線作為評測指標。準確率、精準率和召回率是根據混淆矩陣中的TP(true positives)、FP(false positives)、TN(true negatives)、FN(false negatives) 等計算得到的,見表2。
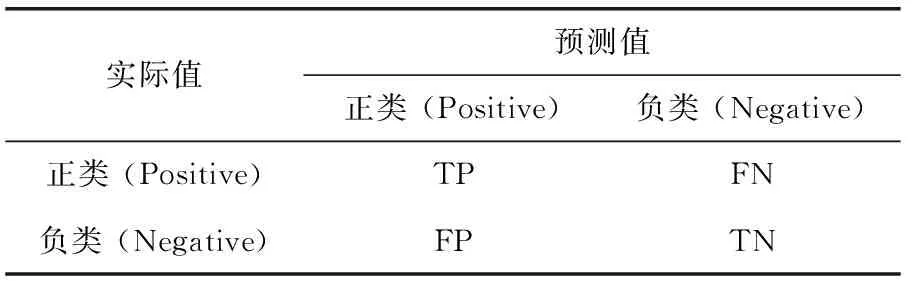
表2 混淆矩陣
準確率表示預測正確的樣本在總樣本中的比例,精確率表示真陽性樣本占預測為正樣本的比例,召回率表示真陽性樣本占實際為正的樣本的比例,計算公式如下
(5)
(6)
(7)
(8)
ROC曲線是分類問題的一種性能度量,AUC則是曲線下的面積,表示分離度,AUC值越大,模型的分類效果越好。但是,當數據樣本不平衡時,ROC曲線不能很好地反映模型性能,而PR曲線能解決這個問題。PR曲線展示的是以精確率為橫坐標、以召回率為縱坐標的曲線,PR曲線與ROC曲線的相同點是都采用了TPR,都可以用AUC來衡量分類器的效果。不同點是ROC曲線使用了FPR,而PR曲線使用了精確率,因此PR曲線的兩個指標都聚焦于正例。由于數據不平衡問題中主要關心正例,所以在此情況下,PR曲線被廣泛認為優于ROC曲線。
3.3 實驗結果及分析
通過對用戶數據的樹結構分析生成了用戶每日的特征向量,對特征向量求和即得該用戶當日的活動頻率。如圖4所示,左圖展示了用戶CCL0068在268天時間中的活動頻率變化(為方便觀察,數據中不包含周六、周日的活動),從圖中可以觀察到用戶大致在第250天左右的活動頻率增加,表明該用戶可能存在異常行為。
將特征向量按時間順序輸入自動編碼器中,得到用戶每日的異常分數,異常分數越高表示用戶行為異常的可能性越大。右圖展示了用戶CCL0068的異常分數變化情況。從圖中可以觀察到第250天左右的異常分數明顯偏高,說明該用戶存在異常行為,其異常行為的具體時間域需要進一步分析。
但是,由于內部人員具有合法身份,內部攻擊行為可能只有幾個細微的異常動作,并隱藏在大量正常行為中,難以發現;而且內部人員熟悉系統的安全防護機制,可以有效規避安全防護檢測。如圖5所示,左圖展示了用戶BSS0369在219天時間中的活動頻率變化,幾乎很難從活動頻率的變化中發現異常情況,但在右圖展示的該用戶的異常分數變化中,可以明顯看出該用戶某幾天的行為中存在異常,需要進一步對其各項活動進行分析。
為了驗證基于自動編碼器的異常檢測方法的有效性,本文將自動編碼器與PCA方法[15]進行了對比,其中PCA中的n_components值為3,自動編碼器的具體參數見表3。前期,對特征向量進行歸一化處理,使兩種方法具有相同的輸入值,比較兩種方法的ROC曲線和PR曲線及其覆蓋面積大小。
兩種方法的ROC曲線和PR曲線對比如圖6、圖7所示,曲線覆蓋面積對比見表4,從面積覆蓋值中可以看出,自動編碼器的檢測效果要好于PCA方法。
由于內部威脅行為類別多樣,異常分數的判別閾值也不是固定的。從實驗中可以發現固定判別閾值,如果閾值設置過高可能會忽略部分異常行為,而閾值設置過低則會導致誤判率升高,所以本文采用Z-score方法,其中Zth選取了1、2、3這3個不同的閾值,對用戶異常行為進行了等級劃分,1、2、3分別表示了低、中、高3個異常等級,結合其出現的頻率判斷異常用戶。
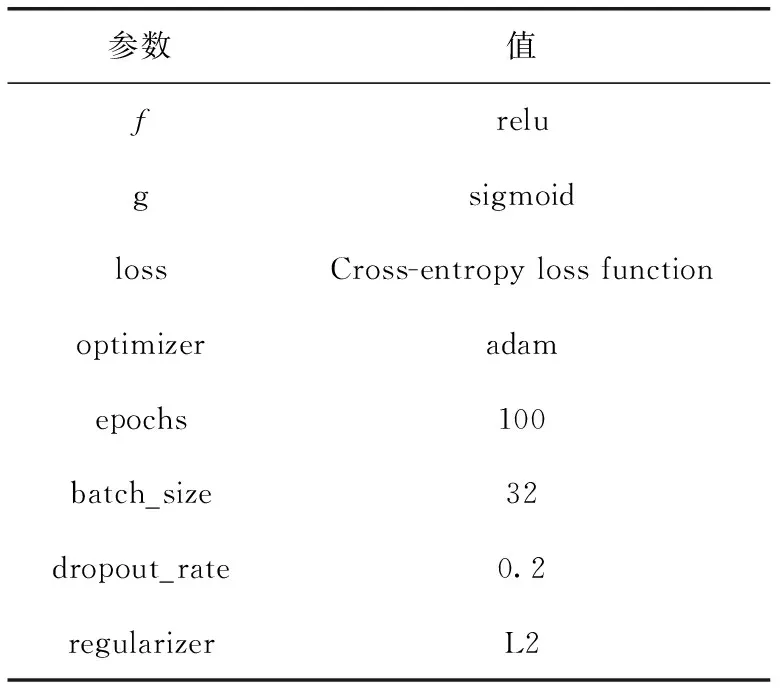
表3 實驗參數設置
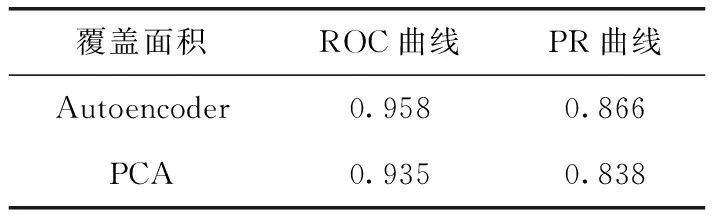
表4 曲線覆蓋面積對比
實驗中,將70名異常用戶和剩余正常用戶中隨機挑選的70名用戶混合進行測試,結果如圖8所示。其中,正常用戶與異常用戶均判斷正確,7名疑似用戶需要進一步結合其它數據進行分析。
4 結束語
本文采用基于自動編碼器的內部威脅檢測方法,首先對用戶數據進行樹結構分析,對于大量多源異構數據的處理速度快且可擴展性高。樹結構分析得到的特征向量輸入異常檢測模型中,異常檢測模型將自動編碼器和Z-score方法相結合,通過自動編碼器得到異常分數,采用Z-score方法對異常分數分級后判斷異常用戶。自動編碼器能學習到正常數據的有效特征和內在聯系,且隨著特征擴展,也適用于高維數據。實驗結果表明,該方法是一種有效的檢測方法。
下一步工作將擴展內部威脅檢測中的行為特征,對上述實驗中的疑似用戶進行進一步判斷,提高準確率并降低誤判率;進一步研究用戶行為特征間的關聯關系,對用戶的攻擊行為和攻擊意圖進行全面分析,結合用戶畫像技術對用戶的攻擊行為建立畫像模型。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
