基于異常識別與有損壓縮的無線AP數倉構建方法
2022-10-19 13:02:08李明春劉世超
光通信研究 2022年5期
關鍵詞:設備
李 明,李明春,劉世超
(烽火通信科技股份有限公司,武漢 430074)
0 引 言
近年來,隨著第五代移動通信技術(5th Generation Mobile Communication Technology,5G)的普及以及網絡帶寬的不斷發展,無線訪問接入點[1](Access Point,AP)設備產生的物聯網[2](Internet of Things,IoT)數據呈現驚人的增長趨勢,而傳統的IoT管理平臺數據分析模塊面對如此大量的接入數據,相應數據分析時長的增加,成了當前必須要解決的首要任務,引入大數據[3]流式計算和離線計算后很好地解決了數據處理時數據量過大的難題,但是面對較高頻率的上送數據持久化存儲成本以及相關數據倉庫[4]的建設成本也亟需解決。
IoT數據的一大特性就是數據重復,比如100萬臺設備5 min上送一次數據,每天即可產生幾百Gbit的數據,而這些數據中包含了大量的重復數據,數據的全部收錄將會增加企業的網絡傳輸成本以及數據倉庫構建成本,如果將所有數據收錄至數據倉庫,再構建不同層次的數倉,數據量又會呈現出翻倍增長的情況,龐大的數據量對于數據分析和異常識別[5]等造成計算資源的浪費以及數據處理時效性的降低。
基于原有IoT平臺對于無線AP的設備接入、設備管理、數據流轉以及數據分析,本文提出了基于異常識別與有損壓縮的無線AP數倉構建方法,使用了一種有損壓縮[6-7]方法,對于無線AP傳輸的IoT數據可以通過流式計算以及基于K-means聚類算法[8-9]的異常識別方式進行有損數據壓縮,主要處理設備運行中存在的較多重復數據且數據存儲精度要求不高,比如信號強度和帶寬等。通過以信號強度為例的具體實驗驗證了本文所提方法的可行性,彌補了現有無線AP數據構建數倉解決方案中的數據量過大的問題。
1 AP數據接入處理數倉構建
IoT技術目前在各行各業已經逐漸落地實踐,其產生的社會經濟效益也越來越明顯,IoT平臺是一個集成了設備管理、數據安全通信和消息訂閱等能力的一體化平臺。向下支持連接海量設備。基于AP設備的IoT平臺實現了對AP設備的管理、連接管理和數據分析等一系列功能,同時在大數據的支持下實現對海量數據的采集、處理、挖掘和展示。
數據倉庫主要功能是將組織透過資訊系統之聯機事務處理(On-Line Transaction Processing,OLTP)經年累月所累積的大量資料,透過數據倉庫理論所特有的資料儲存架構,系統地分析整理,以利于進行各種分析如聯機分析處理(On-Line Analytical Processing,OLAP)和數據挖掘(Data Mining),幫助決策者能快速有效地從大量資料中分析出有價值的資訊,以利決策擬定及快速回應外在環境變動。
為充分有效利用無線AP數據,本文在IoT設備連接的基礎上設計了數據采集[10]、數據處理和數倉實現數據整體架構,如圖1所示,主要由消息中間件、HDFS、實時計算和離線計算等組件構成。本文中實現的無線AP數據數倉分層主要分為:數據緩存層、數據近源層、公共明細層、公共匯總層和數據應用層。無線AP IoT數據經由IoT平臺的設備連接至消息隊列,集成至緩存層進行數據壓縮后進入操作數據 (Operation Data Store,ODS)層;明細數據 (Data Warehouse Details,DWD)層負責轉碼/清洗,異常&缺失值處理,計算加工邏輯,按業務過程分表;業務數據 (Data Warehouse Service,DWS)基于業務需求的原始粒度明細事實的整合匯總,采用一致性維度建模;應用數據服務 (Application Data Service,ADS)層面向業務需求的應用模型,基于應用進行數據組裝,定制化,提供數據應用。
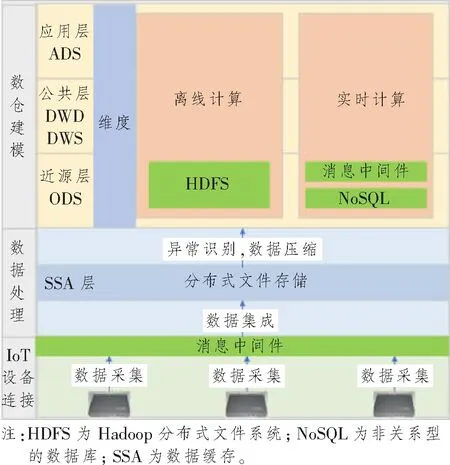
圖1 數據采集處理和數倉實現整體架構圖Figure 1 The overall architecture diagram of data acquisition and processing and data warehouse realization
2 數據處理策略
為提高處理AP設備上送數據的實時性,本文設計了基于flume的數據集成方式,采用Spark Streaming的window以及Spark Ml來實現數據的異常識別以及正常數據基于窗口數據均值的有損壓縮技術,該過程主要包括數據集成、數據異常識別、數據壓縮和持久化存儲模塊。
2.1 數據壓縮
本方案在SSA中實現網絡設備數據壓縮;基于K-means算法與先驗知識結合的方式, 基于數據是否異常制定數據下發方案。正常數據時,采集的設備數據處于平穩變化,取當前窗口平均值下發;異常數據時,異常數據點前后1 min數據根據媒體存取控制(Media Access Control,MAC)和時間字段去重后下發;該方案主要處理設備運行中存在較多重復數據的指標,且該指標數據存儲精度要求不高,本文以信號強度數據為例。具體的實現過程如圖2所示。
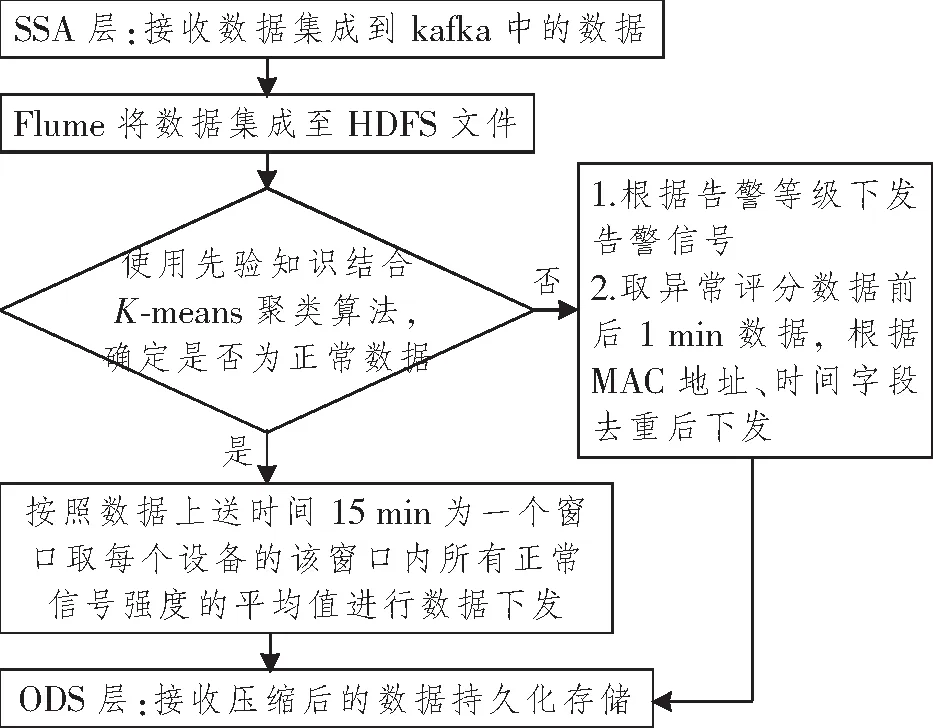
圖2 信號強度RSSI數據處理過程Figure 2 The scheme of signal strength RSSI data processing
數據壓縮過程主要包含4部分內容:
(1) 數據集成:在緩存層將終端設備上送數據集成至HDFS中,用于構建模型以及異常識別測試。數據集成使用flume組件實時采集kafka消息隊列中的接收信號強度指示(Received Signal Strength Indicator,RSSI),同步至HDFS中。
(2) 異常數據識別:基于先驗知識以及專家知識庫中獲得異常數據樣本取樣,使用Spark ML構建K-means模型對上送數據進行聚類分析,結合取樣異常數據進行綜合判斷。
(3) 有損壓縮:數據識別為異常后,取異常評分數據前后1 min的數據,根據MAC地址和時間字段去重后進行下發,同時將異常數據告警信號下發;正常數據取15 min窗口中每個設備正常值的平均值下發。
(4) 持久化存儲:有損壓縮后的數據持久化存儲至近源層中,為后面的數據分析提供數據源。
2.2 先驗知識結合K-means聚類算法識別異常
經由flume同步至HDFS中的數據,需要經過有損壓縮后進入ODS層進行數據持久化存儲以及數據規范管理。本文在異常識別中,為了使識別結果更加準確,通過參考異常生成器結合K-means聚類算法的方式構建了異常識別算法。上送信號強度RSSI字段經歸一化處理后形成特征字段,K-means聚類算法將特征字段聚類后取異常數據在redis中進行緩存,通過與參考異常生成器數據進行比對,若異常數據超過參考異常生成器數據中的異常值,則認定該數據為異常,根據異常數據數值范圍發送相應告警信號,截取數據前后1 min數據進行數據下發;若數據值不超過參考異常生成器中的最低異常值,則認定聚類中無異常數據,從redis中將該數據刪除,同時取窗口數據平均值進行下發。
參考異常生成器:為了增加異常數據識別的準確度以及增加丟包判斷標準,使用該模塊生成參考異常值。設μR為參考異常,定義為l個正常樣本異常分數{r1,r2,…,rl}的均值,采用先驗方式獲取此值:
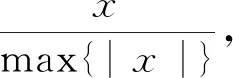
K-means異常識別模型:K-means算法的思想如下:對于給定的樣本集,按照樣本之間的距離大小,將樣本集劃分為K個簇。讓簇內的點盡量緊密地連在一起,而讓簇間距離盡量大。K-means算法使用距離來描述兩個數據對象之間的相似度。距離函數有明式距離、歐氏距離、馬式距離和蘭氏距離,最常用的是歐氏距離。K-means算法是當準則函數達到最優或者達到最大的迭代次數時即可終止。當采用歐氏距離時,如果用數據表達式表示,假設簇劃分為(c1,c2,…,ck),則我們的目標是最小化平方誤差E,
式中:k為簇的個數;ci為第i個簇的中心點;dist(ci,x)為x到ci的距離。
3 實 驗
3.1 實驗環境與評價指標
實驗用通用路由器一臺,通用智能手機一部,實驗代碼在Spark集群中運行,集群配置為3臺Intel(R) Xeon(R) Gold 5120 CPU @ 2.20 GHzcpu,16 G內存服務器,操作系統為CentOS7.9。對于K-means聚類算法,K值選取采用誤差平方和 (Sum of Squares due to Error,SSE)評價指標進行評價。采用壓縮后的文件大小與原文件大小比值的形式來進行壓縮率的評價。
3.2 實驗數據集
為驗證本文算法的有效性,將連接有一臺終端設備的無線AP接入IoT平臺進行實際驗證,終端上送數據為每秒1條,通過IoT平臺收集終端上送數據,其中正常樣本為設備在無線AP附近獲取,通過移動設備增加設備與無線AP的距離,實現異常樣本的采集。采集3 h數據,每小時數據為一組,將數據分為3組進行實驗,每組數據樣本總數均為3 600條,保證每小時數據中都包含了異常數據以及正常上送數據。如表1所示,其中第1小時數據異常樣本數為23條,正常樣本數為3 577條;第2小時數據異常樣本數為106條,正常樣本數為3 494條;第3小時(訓練數據集)異常樣本數為129條,正常樣本數為3 471條。

表1 終端上送數據集
3.3 K值實驗
在Spark集群中對訓練數據進行歸一化處理后運行K-means聚類程序,對K值采用實驗的方式獲取,通過不斷調整K值大小,得到在不同K值下的最小化平方誤差E,E越小說明聚類效果越好,實驗結果如圖3所示。
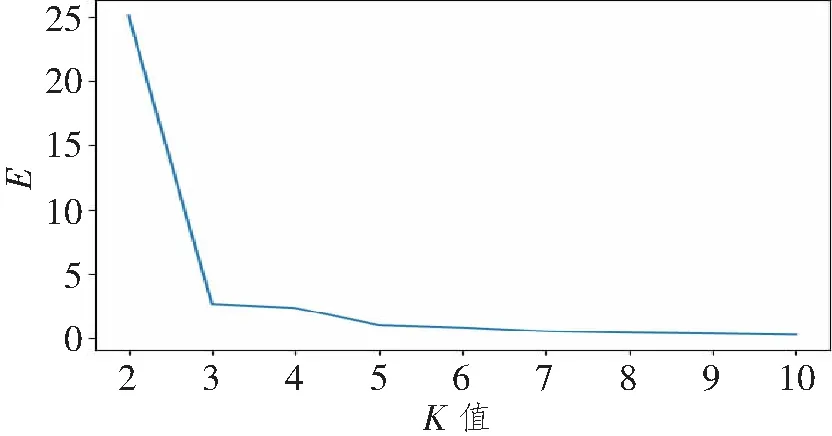
圖3 K值大小與E的趨勢圖Figure 3 The value of K and the trend chart of E
結果表明,K=3時,E逐漸平滑,根據拐點法確認K=3時,可以作為聚類時的參數,聚類中心的選擇使用“K-means||”方式。
3.4 綜合判斷
經參考異常生成器獲得差信號強度為-80 dBm,很差信號強度為-90 dBm。基于聚類結果與參考異常生成器綜合判斷邏輯如圖4所示。經過K-means模型與參考異常生成器綜合判斷訓練數據集中的異常檢測結果如表2所示。
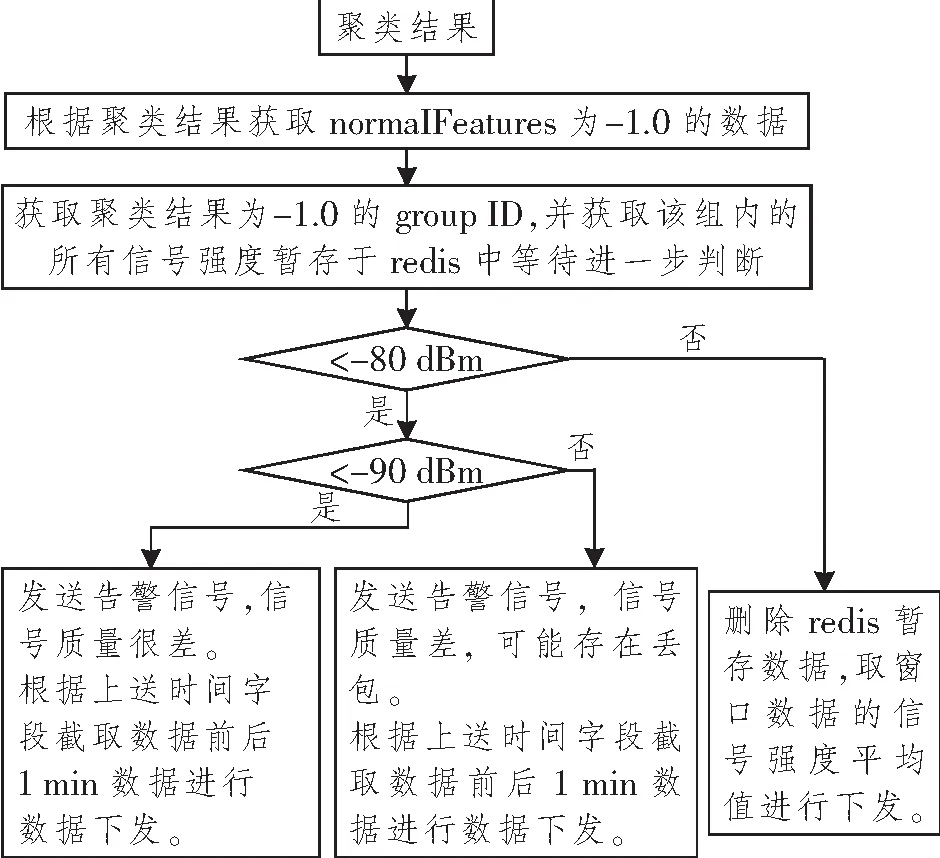
圖4 基于聚類結果與參考異常生成器綜合判斷邏輯Figure 4 Comprehensive judgment logic based on clustering results and reference exception generator

表2 異常檢測結果
其中劃分為異常數據組,但是不滿足信號強度≤-80 dBm的數據有6條,基于K=3的K-means聚類算法實現的判斷準確率為95.6%。同樣對另外兩個測試數據集進行相同處理,異常檢測結果如表3所示。

表3 異常檢測結果
在測試數據集中,兩個數據集的識別率分別為99%和85%。根據綜合判斷,將該異常識別錯誤的數據從redis中剔除,在本窗口中,根據綜合判斷的異常數據取時間字段,對異常數據前后1 min的數據進行抽取,同時根據MAC以及時間字段去重后下發。
3.5 數據壓縮率
實驗測試過程中,測試數據集1的數據時間區間為2022-02-20 15∶33∶00~ 2022-02-20 16∶32∶59,測試數據集2的數據時間區間為2022-02-20 16∶33∶00~ 2022-02-20 17∶32∶59。其中測試數據集1的異常數據起始點為2022-02-20 16∶05∶02~ 2022-02-20 16∶06∶47,測試數據集2的異常數據起始點為2022-02-20 17∶23∶37~ 2022-02-20 17∶23∶59。程序基于圖4的一場判別有損壓縮邏輯,最終取得測試數據集1和測試數據集2的有損壓縮數據總條數分別為229和149條。詳細數據比對如表4所示。
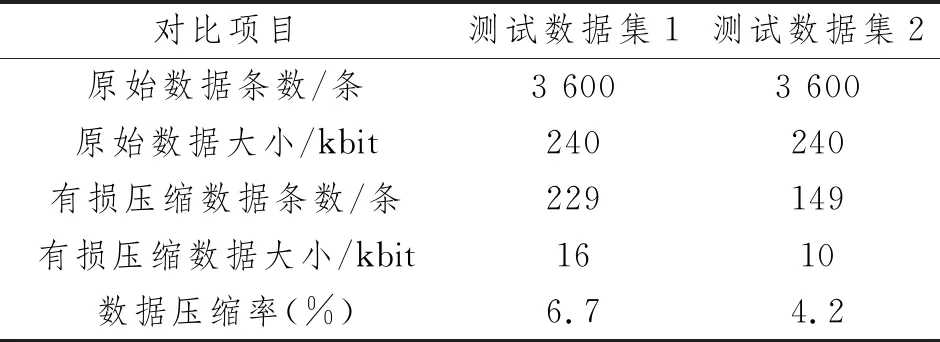
表4 數據壓縮對比
通過兩組測試數據與原始數據的對比,表明本文方案可以在保證識別異常數據、保留異常數據細節動作的同時,很好地降低無線AP重復性上送數據的存儲占用空間,可以大大降低用戶的存儲成本。
4 結束語
為了降低無線AP數據的數倉實現成本,本文提出了基于緩存層實現網絡設備數據壓縮的方法,設計了結合流式計算和異常識別決策數據下發框架,根據無線AP上送數據的特點,結合機器學習和流式計算,通過對信號強度的實際實驗,驗證了本文方法的可行性以及經濟性。本文所提方法同樣可以用于其他IoT領域,如電力終端、智慧家庭和智慧工業等領域,以降低IoT設備的數倉構建和數據存儲成本,同時對于異常數據的識別提供了一種很好的辦法。當然,對于方法中單一特征值也可以進行相應的擴充,比如信號強度字段與丟包率和網速結合形成多特征的聚類能夠更好地識別異常。
猜你喜歡
中國特種設備安全(2022年6期)2022-09-20 02:52:28
當代工人(2020年13期)2020-09-27 23:04:20
經濟技術協作信息(2018年22期)2019-01-19 03:00:18
電子制作(2018年11期)2018-08-04 03:26:08
電子制作(2018年10期)2018-08-04 03:24:48
家庭影院技術(2017年11期)2017-12-20 08:10:57
工業設計(2016年12期)2016-04-16 02:52:00
IT時代周刊(2015年8期)2015-11-11 05:50:37
汽車維修與保養(2015年1期)2015-04-17 03:25:28
設備管理與維修(2015年12期)2015-04-09 06:57:00
