深度學習驅動的跨模態視覺數據搜索研究綜述*
2022-10-24 08:01:12朱維喬廣州航海學院廣州510725
高校圖書館工作 2022年5期
●朱維喬 (廣州航海學院 廣州 510725)
隨著人工智能技術發展的一日千里,以及移動終端與社交網絡的日益普及,互聯網上的多媒體數據呈現指數級激增。包括圖像、文本、音視頻等不同類型的數據通常用于描述同一事物[1],這些不同種類的數據稱作多模態數據,其在形式上表現出底層特征(如文本關鍵詞、視頻的幀、圖像顏色等)的異構性和高層語義的關聯性[2]。相互關聯的多模態海量數據使用戶跨模態檢索的需求與日俱增。如圖1所示,左圖通過文本搜索出相關圖像,右圖通過圖像搜索出相關文本,表達同一事物的圖像和文本屬于不同模態數據,此類跨模態數據間的互檢索方式即為跨模態檢索[2]。移動視覺搜索屬于跨模態數據搜索,指通過移動智能終端攝像頭獲取現實對象的圖像、視頻、3D模型以及音頻等視聽覺數據,在互聯網檢索上述多模態數據的關聯信息,并在智能終端顯示出來的一種信息獲取方式。其難點在于對文本、視頻等跨模態數據的時序信息的理解,以及構建跨模態數據之間匹配關系的方法[3]。跨模態數據搜索的實現過程,是提取不同模態的數據特征并對特征之間的關聯表示建立模型;通過模型與相關算法獲取檢索結果并進行排序。其中的主要問題在于如何度量表示相同語義主題卻處于不同特征空間的跨模態數據之間的相似性,并在它們之間建立語義關聯,即難點是語義鴻溝的跨越[4]。
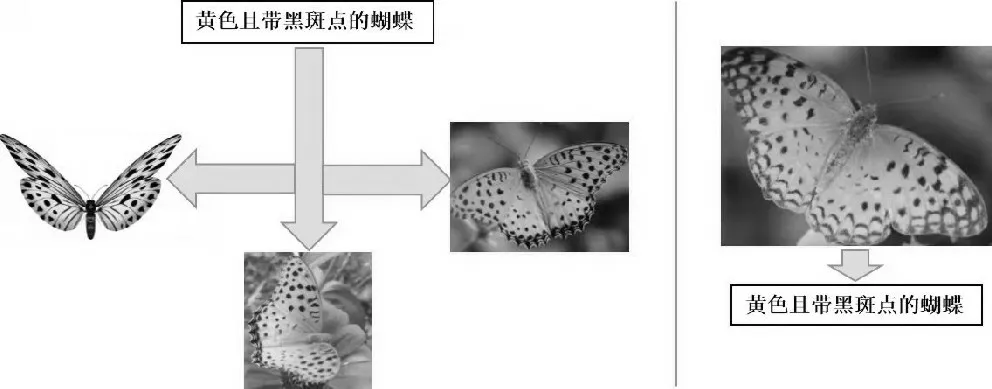
圖1 跨模態數據搜索示意圖
深度學習作為人工智能領域最熱門的技術之一,近年來在語音分析、自然語言處理與計算機視覺等領域的推廣運用都取得了突出的成效。其卓越的特征學習與特征表達能力為跨模態數據融合問題的解決提供了新途徑,成為多模態數據語義理解與移動視覺搜索領域的重要工具,對異質鴻溝問題的解決和跨模態檢索性能的提升提供了一種有前景的方案[5],能利用數據的本質特征解決各種問題[6],有利于實現跨模態搜索結果的精確度和可靠性[7]。
1 跨模態視覺數據搜索問題定義
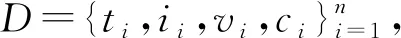
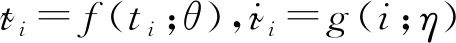
最終,跨模態數據搜索達成的目的是在給定任意模態數據時,能夠檢索出語義相似的其他某類或某幾類模態的數據。
2 基于深度學習的跨模態視覺數據搜索研究現狀
不同種類的跨模態視覺數據具備相似的語義信息,這種潛在相關性使搭建公共空間并將跨模態數據映射至此,進而生成統一的特征表征方式并進行相關性度量匹配具有可行性[8]。如圖2所示,跨模態視覺數據搜索的過程架構,是在抽取多模態數據特征的基礎上學習其公共表征,并實現跨模態匹配和排序。由此可見,圖像、文本以及視頻等跨模態視覺數據能夠在公共語義空間中互相接近[9]。
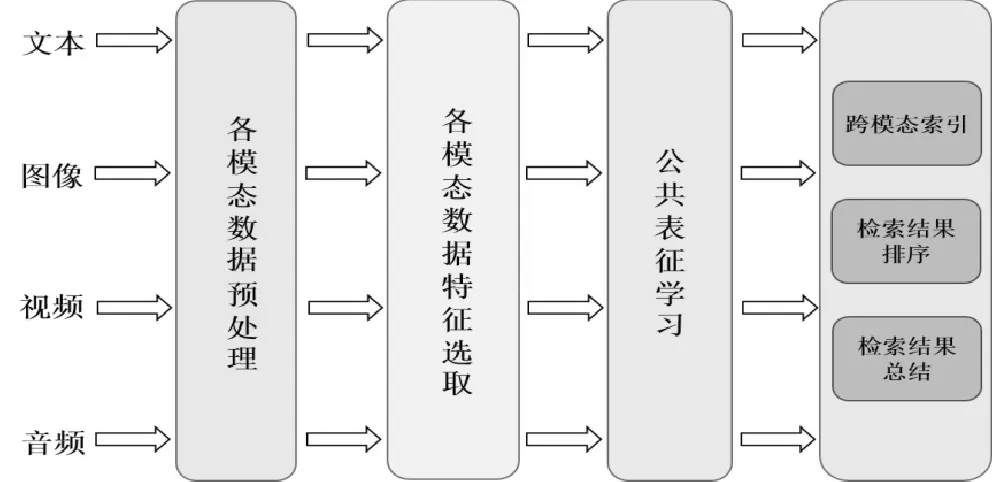
圖2 跨模態視覺數據搜索過程架構
深度學習技術驅動的跨模態數據搜索研究獲得了較大突破,檢索準確性得以明顯提升。下文以深度學習技術應用為切入點進行綜述,將跨模態數據搜索研究劃分為基于卷積/循環神經網絡的方法、基于圖網絡表示的方法、基于生成對抗的方法以及基于深度哈希編碼的方法。其中,前三種方法側重于應用深度學習技術提升跨模態檢索的準確性,而基于深度哈希編碼的方法融合了深度學習技術與哈希算法,側重于檢索效率與精確度的同步提升。
2.1 基于卷積/循環神經網絡的方法
神經網絡結構包括卷積神經網絡(Convolutional Neural Network,CNN)與循環神經網絡(Recursive Neural Network,RNN)。其中,前者主要用于抽取圖像數據特征[10],后者主要用于抽取文本數據特征及挖掘其語義。而對于視頻數據特征,通常使用三維CNN進行抽取;對于音頻數據特征,需要首先進行數據信號的降噪處理,再使用CNN抽取數據特征。
在應用深度學習技術實現數據特征抽取時,研究者們根據不同目標提出相應的改進組合方法。由于文本數據和圖像數據之間語義鴻溝的存在,使用文本對所需圖像進行精準描述存在著較大難度,Vo N等提出了TIRG(Text Image Residual Gating)模型,該方法通過查詢文本數據特征修改圖像數據特征,運用剩余連接對文本與圖像特征進行重組,形成全新的數據查詢特征[11]。例如,將文本或圖像數據作為輸入,通過文本對圖像數據特征進行修正調整,使其與預測的輸出結果相符。如圖3所示,輸入為一組圖像和文本,最終輸出結果是圖像。TIRG模型以輸入圖像為基礎,通過改變某些特征,使語義鴻溝問題得以有效緩解[9]。
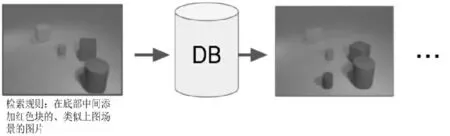
圖3 TIRG模型效果示例[11]
對于視頻數據的特征抽取,二維CNN的局限性體現在抽取視覺空間特征而遺漏時間特征,應用三維CNN則可以使視頻數據的時間特征得以保留。因此,Yamaguchi M等使用二維CNN和三維CNN相結合的方式抽取視頻數據特征[12]。對于音頻數據的特征抽取,Google公司通過實驗發現CNN架構不但擅于處理圖像數據,而且在音頻數據分類任務方面也卓有成效[9]。此外,Guo M等提出文本和音頻數據之間跨模態檢索架構,運用語音特征參數MFCCs抽取音頻數據特征[13]。
排序加權機制在跨模態數據搜索領域的應用近年來得以推廣,促進了檢索性能的提升。其運行機理是根據不同的數據搜索任務,通過權重排序的方式對關鍵數據進行抽取,使不同模態數據特征的重要性得以平衡。該機制在特征抽取階段發揮了顯著的作用,有效保存了關鍵數據的特征信息[9]。如Li S等提出采用遞歸神經網絡算法RNN模型進行數據特征抽取,輸入信息包括人物圖像數據及其描述語句,輸出的是二者之間的匹配度[14],該算法對公共場所密集人群的安全監控具有較高的應用價值。Dey S等提出使用長短期記憶網絡LSTM(Long Short-Term Memory)為圖像數據計算注意力圖,將其映射至公共子空間同其他模態數據的查詢特征相比較,并進行權重排序以及相關性度量[15]。
2.2 基于圖網絡表示的方法
深度神經網絡具備強大的視覺關系學習與推理功能,在數據內容相關性匹配過程中發揮著重要作用。圖像數據的語義信息包括圖像中的對象、屬性以及相互關系,對語義信息的識別與表示有利于加強對數據內容的理解。圖網絡表示模型在視覺數據搜索中顯示出卓越的性能,使圖像數據中對象之間的關系得以更清晰地呈現和表達,具有更強的魯棒性,并有效填補了語義鴻溝。為了解決同一場景內對象之間關系的復雜性問題,Johnson J等構建了面向視覺場景的條件隨機域模型CRF(Conditional Random Field),用場景圖代替文本對圖像數據進行檢索并獲取詳細語義信息[16]。Yang J W等提出了graph RCNN模型,采用圖網絡建模的同時度量對象之間的相似性[17]。對于視頻時刻檢索問題的處理方法,Liu B B等提出時序模塊網絡模型(Temporal Modular Networks),通過查詢的底層語言結構對相應的神經網絡模塊進行動態組裝,進而組合推理視頻數據,輸出查詢與視頻數據之間的對應關系[18]。
2.3 基于生成對抗的方法
生成對抗模型作為深度學習研究方向的聚焦點,自被提出以來一直熱度不減。Peng Y X等發現的跨模態GAN結構[19]和Wang B K等研究的對抗性跨模態數據檢索[20]極為相似,二者均以跨模態數據的聯合分布為對象構建模型。不同模態數據間的相關性在生成模型中進行匹配,同一模態內的數據內容相關性通過判別模型進行探索,通過對抗博弈促進跨模態數據的相關性學習。其中,生成模型的構成選取卷積自動編碼器,以實現跨模態數據相關性與重構信息的有效利用[21]。
Wang H等提出的對抗性跨模態數據嵌入法,是運用對抗性學習方法進行模態對齊,進而學習不同模態之間的公共映射特征空間[22]。此外,Gu J X等也將跨模態特征嵌入與生成過程相結合,實現局部基礎特征與整體抽象特征的同步學習[23]。
綜上所述,生成對抗模型通過文本生成圖像的方式來檢索圖像數據,使跨模態差異得以有效降低。其中,生成模型用于記錄樣本數據分布,判別模型驗證生成數據的真實性。二者通過互相對抗博弈,使模型最終達到平衡。
2.4 基于深度哈希編碼的方法
跨模態多媒體數據的爆發式激增使檢索系統的存儲空間面臨著巨大壓力,為了擺脫這一困境,研究人員以哈希算法作為解決問題的工具,將跨模態數據轉換為二進制哈希編碼后投影至公共空間,實現檢索速度的提升與存儲空間的壓縮。然而手工特征的哈希算法雖使檢索速度與存儲性能得以改善,但在一定程度上損失了檢索精度。為了實現平衡檢索效率與精確性的目標,近年來有學者將深度學習技術與哈希算法相結合,即應用深度哈希編碼方法[24]。 Salakhutdinov R等學者最早提出了語義哈希方法,使用基于深度學習的受限玻爾茲曼機模型學習哈希編碼以實現可視化數據搜索[25]。Xia R K等[26]和Liong V E等[27]提出包括數據特征學習與哈希編碼生成的二階段深度哈希方法,采用深度神經網絡學習多模態數據中的非線性表征轉換,實行統一的二進制哈希編碼并以其為依據對隱變量進行建模。董震等設計了深度異構哈希網絡用于檢索跨模態人臉數據,使人臉圖像與視頻這兩種位于異構空間的跨模態數據可以映射至同一公共空間,進而生成二值哈希編碼表示[28]。此模型提供了深度哈希方法的通用架構,適用于多種跨模態數據的搜索任務。
深度哈希方法的訓練需要多模態海量數據的支撐,當新數據出現時需要重新訓練卷積神經網絡模型生成哈希碼。為了解決這一增量學習難題,Wu D Y等設計了深度增量哈希網絡模型,在原有圖像哈希碼表示不變的基礎上,以增量方式對哈希編碼進行學習,在無須重新訓練模型的條件下,使新數據能夠直接進行哈希編碼,并且保持訓練數據間的相似性,進而學習查詢數據集的深度哈希算法,既減少了訓練時間又保證了檢索精準度[29]。
3 跨模態視覺數據搜索常用數據集
在跨模態視覺數據搜索方法研究與評價的過程中,數據集有助于實現評估檢索性能的目標,具有舉足輕重的作用,下文對常用數據集進行重點介紹。
Wikipedia數據集。該數據集來源于Wiki維基百科,包含兩種模態特征,在跨模態數據搜索研究過程中使用較為廣泛。其包括兩千余個語義互為關聯的文本/圖像數據對,每一個文本/圖像數據對標注相應的語義類別[5]。
Flickr數據集。該數據集來源于雅虎的相冊網站Flickr,內容涉及各項人類日常活動的相關場景和事件。其中Flickr8k數據集與Flickr30k數據集分別包含8 000張、31 783張來源于Flickr網站的圖像,每張圖像有對應的五個獨立文本注釋語句進行描述,描述語句由網站用戶進行編輯[30]。
MS COCO(Microsoft Common Objects in Context)數據集。該數據集由微軟公司收集構建,與Flickr數據集相比較,該數據集包含更多數量的日常生活場景圖像與文本標簽數據,并提供了數據的視覺描述特征,其中有123 287 張用于訓練與驗證的圖像,每張圖像有對應的五個注釋語句進行描述[31]。
PKU XMedia Net數據集。該數據集來源于YouTube、Wikipedia、Flickr等,由北京大學多媒體信息處理研究室通過網絡爬蟲抓取采集,是當前數據量最大、模態種類最多的跨模態檢索數據集。其中包括二十個語義類標注,每一類包括圖像、文本、語音、視頻以及3D 模型等五種不同類型的跨模態數據,數量分別為250、250、50、25、25[32]。可將上述語義類標注作為查詢進行數據搜索,并截取與標注內容相符合的片段。
4 深度跨模態數據搜索研究展望
近年來,研究者設計出一系列基于深度學習的跨模態數據搜索算法并取得了較為卓越的性能,然而,算法應用效果仍與用戶期待之間存在差距。因此,跨模態數據搜索的研究工作仍有待向縱深方向開展。
(1)搜集海量多模態數據集。研究人員構建的復雜深度學習算法亟須跨模態基準數據集驗證支撐,然而當前的如NUS-WIDE與Wiki僅包含兩種模態數據且體量有限,難以精準描述模態特征。為此,亟須搜集海量數據集以提升跨模態數據搜索的性能[5]。
(2)充分利用語義標注有限且含有噪聲的多模態數據。在互聯網技術飛速發展的大數據環境下,YouTube、微信微博等社交媒體產生的海量多模態數據是以松散組織的方式分布在互聯網中,數據標注有限且包含龐雜噪聲,無法對全部數據進行標注。因而怎樣充分利用標注有限且包含噪聲的多模態數據進行檢索有待研究者繼續深入探索。
(3)設計高效輕量級跨模態數據搜索算法。海量多模態數據的劇增使用戶對跨模態數據搜索的需求日益提升,對搜索算法的要求也愈加苛刻。研究者設計的復雜性較高的算法在提升檢索性能的同時,卻無法保證數據搜索的效率[5]。故而,設計輕量級高性能的跨模態數據搜索算法是極具挑戰性的研究課題。
(4)跨模態數據的細粒度相關性建模。基于深度神經網絡的一般算法是在跨模態數據共同表示學習時,將不同模態數據進行非線性映射至共同表示空間后進行相關性度量。然而此類方法在建模時欠缺精細度,導致跨模態數據之間的一致性部分難以深入發掘。為了解決這一難題,研究者近年來提出了細粒度相關性的一系列建模方法[8],以深入挖掘文本數據和圖像數據之間片段級的對應關系,并取得了較為理想的相關性建模效果。由此可見,針對不同模態類型數據的片段級表征進行提取,并進行復雜性更高的細粒度關系建模將成為未來的研究方向。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
開放教育研究(2020年2期)2020-03-31 01:54:14
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
現代語文(2016年21期)2016-05-25 13:13:44
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
大連民族大學學報(2015年2期)2015-02-27 08:28:11
計算物理(2014年2期)2014-03-11 17:01:39
