基于長短期記憶神經網絡的太陽耀斑短期預報
2022-11-09 04:25:00何欣燃鐘秋珍崔延美劉四清石育榕閆曉輝王子思禹
空間科學學報 2022年5期
何欣燃 鐘秋珍 崔延美 劉四清 石育榕 閆曉輝 王子思禹
1(中國科學院國家空間科學中心 北京 100190)
2(中國科學院大學 北京 100049)
3(中國科學院空間環境態勢感知技術重點實驗室 北京 100190)
0 引言
太陽耀斑是一種劇烈的太陽爆發現象,是太陽質子事件和日冕物質拋射發生的先兆現象之一。與之伴隨發生的高能粒子流及其輻射對空間環境產生劇烈的沖擊,對空間飛行器或航天員造成潛在危害。當耀斑輻射來到地球附近時, 光致電離使得電離層D 層的電子密度增加,引起無線電通信中斷。太陽耀斑預報研究具有重要的實用價值和科學意義。一方面太陽耀斑預報為提前應對電離層突然擾動、太陽質子事件和地磁暴提供了重要的警報作用;另一方面,太陽耀斑預報對于理解太陽活動事件的原理具有重要的指導意義。
由于耀斑爆發對空間天氣的重要影響,研究提出了多種耀斑預報方法。考慮到太陽活動區與耀斑爆發之間的緊密聯系,耀斑預報方法大多采用活動區拓撲特征參數和光球磁場特征參數,根據當前觀測情況預測未來耀斑的發生。耀斑預報方法主要包括:基于專家系統的方法[1—4];利用觀測數據建模的方法,包括統計分析中的泊松統計[5]、多元線性回歸模型等[6—8],以及機器學習中的支持向量機[9—10]、神經網絡[11—15]、徑向基函數網絡[16]、線性判別分析[17]、隨機森林[18]、相關向量機[19]等。
目前普遍認為浮現磁通量區在耀斑產生中起重要作用[20],活動區的演化過程對于耀斑活動具有重要影響[21],活動區當前觀測以及之前的觀測共同影響了耀斑的發生。Huang 等[22]利用光球磁場作為預報因子,分別建立耀斑預報的神經網絡模型和決策樹模型,隨著預報因子時序信息的引入,兩種預報模型的預報精度得到不斷提高。
近年來, 機器學習中的深度學習方法取得了快速發展[23—24], 并成功應用于語音識別、自然語言處理、目標識別和分類等領域[25—26]。深度學習方法可以從原始觀測數據中自動學習特征參量并建立模型,Li等[27]和Huang 等[15]利用卷積神經網絡的自動圖像特征提取能力建立太陽耀斑預報模型。同時,深度學習方法中的循環神經網絡還可以學習到數據的時序特征,Liu 等[28]利用SHARP 數據和耀斑歷史特征,基于長短期記憶網絡(LSTM)方法,分別構建了未來24 h≥M5.0 級、≥M 級和≥C 級耀斑預報模型。
通常在空間天氣預報業務中,未來48 h 的耀斑預報是重要的內容之一。本文選取SHARP 活動區磁場參量,利用深度學習中的長短期記憶網絡,建立未來48 h≥M 級太陽耀斑預報模型。在建模過程中利用XGBoost[29]計算各磁場參量的特征重要性,篩選出6 個參量作為模型輸入,最后通過與其他機器學習方法的預報評估來分析模型對太陽耀斑的預報能力。
1 數據
太陽耀斑的觸發和能量釋放與磁場密不可分,當儲存的磁能在日冕中突然釋放時就發生了耀斑。由于日冕磁場還未能準確測量,因此在太陽耀斑預報建模過程中,通常采用活動區光球磁場作為預報輸入。本文太陽活動區數據采用SDO/HMI 的SHARP(Spaceweather HMI Active Region Patch)數據** http://jsoc.stanford.edu/doc/data/hmi/sharp.htm。該數據提供了活動區的相關特征參量。使用的數據集為2010 年5 月到2017 年5 月所有活動區樣本,樣本間隔為96 min,考慮了SHARP 數據中提供的10 個活動區物理參量,包括總無符號電流螺度、總光球磁自由能密度、總無符號垂直電流、凈電流螺度絕對值、正負極凈電流絕對值、總無符號磁通量、活動區強磁場面積、平均光球磁自由能、中性線磁通量以及剪切角大于45°的像素比例。太陽耀斑數據來源于美國國家地球物理數據中心(National Geophysical Data Center, NGDC)整理的數據列表**ftp://ftp.ngdc.noaa.gov/STP/space-weather/solar-data/solar-features/solar-flares/x-rays/goes/xrs/。太陽耀斑根據其軟X 射線峰值流量分為B,C,M,X 四級。
在構建數據集時,利用滑動窗方法[30—33]將光球磁場觀測的序列信息引入耀斑預報系統,即引入活動區演化信息。滑動窗方法的原理如圖1 所示,其中t為當前時刻的觀測量,隨著時間的推移,t—WΔt到t之間的觀測隨時間滑動,稱為滑動窗,這里W為滑動窗尺寸。在實際應用中,序列需要在初始位置增補W個點(一般情況下,序列的初始值被重復W次),使得滑動窗可以從原始序列的初始位置處運行。
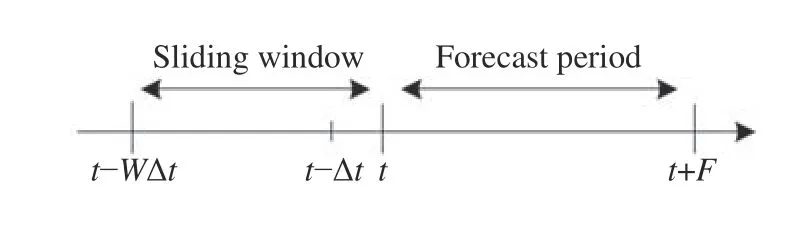
圖1 滑動窗口原理Fig. 1 Sliding window principle
滑動窗方法的關鍵問題是如何確定窗口大小。根據Huang 等[22]互信息函數的計算結果,建議滑動窗的總時間長度不超過三天,因此這里選取W=15,時間間隔Δt=96 min,滑動窗口總長度為24 h(15×96 min),預報時段F=48 h。將16 條(W+1)數據作為一個樣本,用于預測未來48 h 內該活動區的耀斑發生情況。
在建立耀斑樣本時,規定若是滑動窗口最后時刻(t)的未來48 h 內發生了≥M 級的耀斑事件(t+F時間范圍內),即標注為正樣本,若未發生則標注為負樣本。為了使訓練集和測試集都包含每個活動區的數據,在劃分數據集時,按照9∶1 的比例對每個活動區的數據進行隨機抽取,并分別放入訓練集和測試集,保證訓練集和測試集包含所有活動區的數據。經過 這 樣 的 處 理 后,2010 年5 月 至2017 年5 月的SHARP 數據集中,訓練集正樣本2098 個,負樣本41809 個,測試集正樣151 個,負樣本13953 個,總計58011 個樣本。
2 耀斑模型
2.1 長短期記憶神經網絡
考慮到本文樣本所使用的滑動窗口時長較長,選擇使用深度學習中的長短期記憶神經網絡(LSTM)作為模型主體。長短期記憶神經網絡(LSTM)作為循環神經網絡(RNN)的改進,引入了門控機制,讓模型在學習的過程中自行學習需要“記憶”和“遺忘”的內容,對于長時間序列的處理具有很大優勢。
LSTM 主要結構為遺忘門、輸入門和輸出門。遺忘門(Forget Gate)的任務是接受上一個單元模塊傳過來的輸出,并決定要保留和遺忘該記憶單元的部分。輸入門(Input Gate)的作用是確定當前細胞需要記憶多少上個細胞的狀態,針對遺忘門中丟棄的屬性信息,在本單元模塊找到相應的新屬性信息,添加進去,以補充丟棄的屬性信息。輸出門(Output Gate)用于確定細胞狀態部分需要的輸出,然后對細胞狀態進行處理,由遺忘門和記憶門給輸入賦予權重,得到最終需要輸出的信息。在圖2 顯示的重復模塊結構中,加藍底的圓圈表示4 個神經網絡層,其以一種復雜而高效的特殊方式進行交互。圖2 中各符號意義的說明見表1。

表1 圖2 中各符號含義的說明Table 1 Implication of some symbols in Figure 2
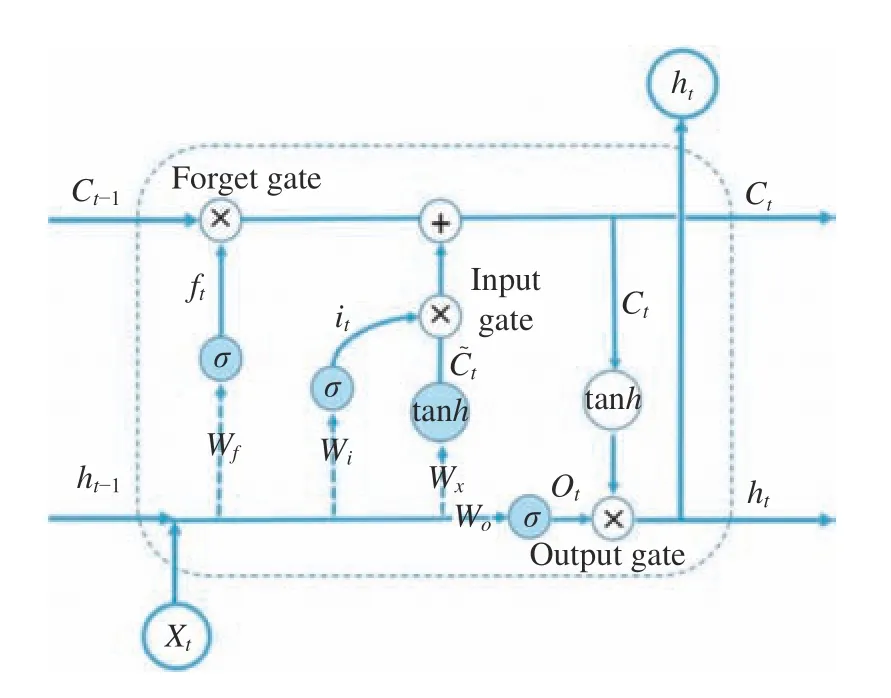
圖2 LSTM 中隱含層重復模塊結構Fig. 2 Architecture of repeat module in the hidden layer of LSTM
LSTM 的關鍵是細胞狀態(例如Ct和Ct-1),其類似于一條傳送帶,直接在整個鏈上運行,只有少量的線性交互,這樣信息在上面流動就很容易保持不變。圖2 給出了LSTM 記憶單元的工作流程。輸入由三部分組成,第一是當前時刻的輸入xt,第二是上一時刻的隱藏層輸出ht-1,第三是細胞中存儲的上一狀態Ct-1。具體步驟如下。
第一步 確定哪些信息需要經過遺忘門被丟棄掉,輸入經過一次非線性變換得到遺忘門函數,即
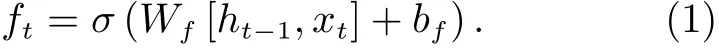
第二步 確定哪些新的信息將被存儲,經過兩次非線性變換,可以分別得到輸入門函數和單元候選狀態為
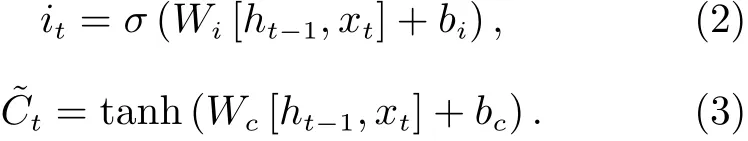
第三步 對當前時刻的單元狀態進行更新,此時需要通過遺忘門和輸入門對當前和歷史信息進行控制,有
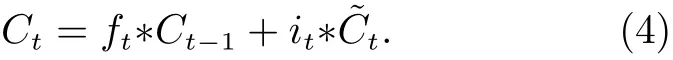
第四步 當單元狀態被更新后,需要確定哪些信息即將被輸出,這里不僅要通過對輸入進行非線性變換得到輸出門函數,同時還要對已更新的單元狀態信息進行輸出控制,得到當前時刻神經元的輸出,即
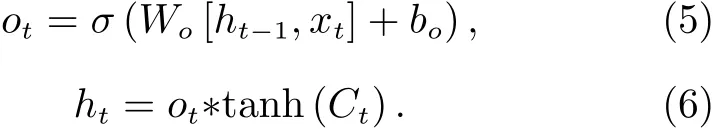
上述過程中用到的兩個激活函數分別是sigmoid 函數和tanh 函數, 即
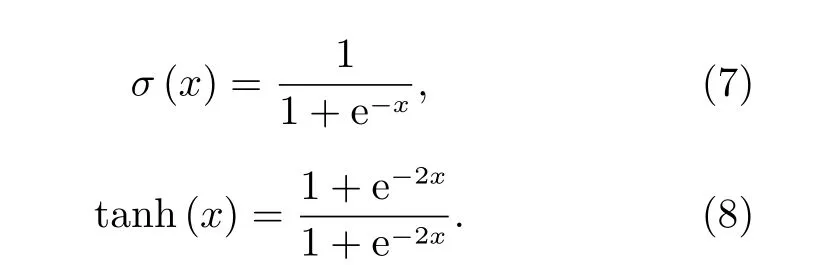
上述Wf,Wi, Wc, Wo和bf, bi, bc, bo分別表示網絡結構中每一步的權重和偏置。
在建立太陽耀斑預報模型過程中,還采用了Dropout[34]技巧訓練深度神經網絡。在每個訓練批次中,通過忽略一部分神經元(讓這部分隱層節點的權重為0),可以明顯減少過擬合現象。
2.2 特征參數選擇
在使用LSTM 模型進行訓練之前,首先利用極端梯度提升器(eXtreme Gradient Boosting, XGBoost)[29]對SHARP 數據中各物理參量進行特征重要性分析,根據重要程度選擇特定的物理參量,用于構建最終的訓練集和測試集。
XGBoost 是機器學習集成學習中的Boosting[35]方法之一,Boosting 方法中將弱學習器通過串聯的方式進行疊加,每個弱學習器都擬合前一個弱學習器的殘差,合成一個強學習器。XGBoost 的默認弱學習器為CART 樹[36],樹模型有著良好的特征選擇能力。選取特征主要有三種模式,分別是權重(weight)、信息增益(gain)、覆蓋率(cover)。由于每個決策樹都不會生長完全,因此每個特征所使用的次數均不相同,其中Weight 模式計算每個特征在分裂節點時被使用的平均次數,使用次數越多,特征越重要。信息熵用于描述一個系統信息的不確定性程度,而信息增益代表在一定條件下(使用某個特征分類),系統信息熵(不確定性)減少的程度。Gain 模式為計算在每個特征作為分裂節點的特征時,其平均信息增益,CART 樹在進行分裂時,選擇信息增益最大的特征進行優先分裂,因此Gain 模式下的得分反映了特征對分類的優先級。由于不是每個樣本都需要所有特征進行分類,在Cover 模式為所有CART樹中,以每個特征作為分裂節點的特征時,所有CART 樹中所覆蓋的樣本平均數量,因此Cover 模式的得分體現了特征的普適性。
利用XGBoost 分別計算了選取的SHARP 數據集中10 個物理參量的特征權重、增益率、覆蓋率(見圖3~5)。從圖3 可以看出,活動區強磁場面積、剪切角大于45°的像素比例以及總無符號電流螺度在所有基分類器中使用次數更多,通常使用越多的特征也會對分類起到更多的作用。從圖4 可以看出,中性線磁通量具有最多的平均信息增益,這說明在使用特征中性線磁通量進行分裂節點時,對整個系統具有最大的信息增益。從圖5 可以看出,中性線磁通量、正負極凈電流絕對值、總無符號電流螺度具有較高的覆蓋率,這說明多數樣本都使用了上述特征。同時為了不移除掉過多特征導致模型效果下降,增加了在三種特征重要性計算中得分都不低的凈電流螺度絕對值。綜合考慮,選取總無符號電流螺度、正負極凈電流絕對值、凈電流螺度絕對值、活動區強磁場面積、中性線磁通量、剪切角大于45°的像素比例這6 個物理參量作為模型輸入參數,分別記為L1,L2,L3,L4,L5,L6。 經過特征參數選擇后,t預報時刻的樣 本 數 據 集 為[[L1(t—15*96),L1(t—14*96),···,L1(t)],[L2(t—15*96),L2(t—14*96),···,L2(t)], [L3(t—15*96),L3(t—14*96),···,L3(t)], [L4(t—15*96),L4(t—14*96), ··· ,L4(t)], [L5(t—15*96),L5(t—14*96),···,L5(t)], [L6(t—15*96),L6(t—14*96),···,L6(t)]],共計96 個數據。
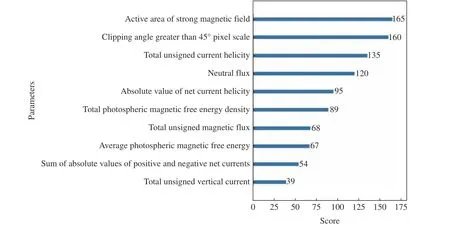
圖3 10 個物理參量在所有弱學習器中的權重Fig. 3 Weights of ten parameters in all weak learners
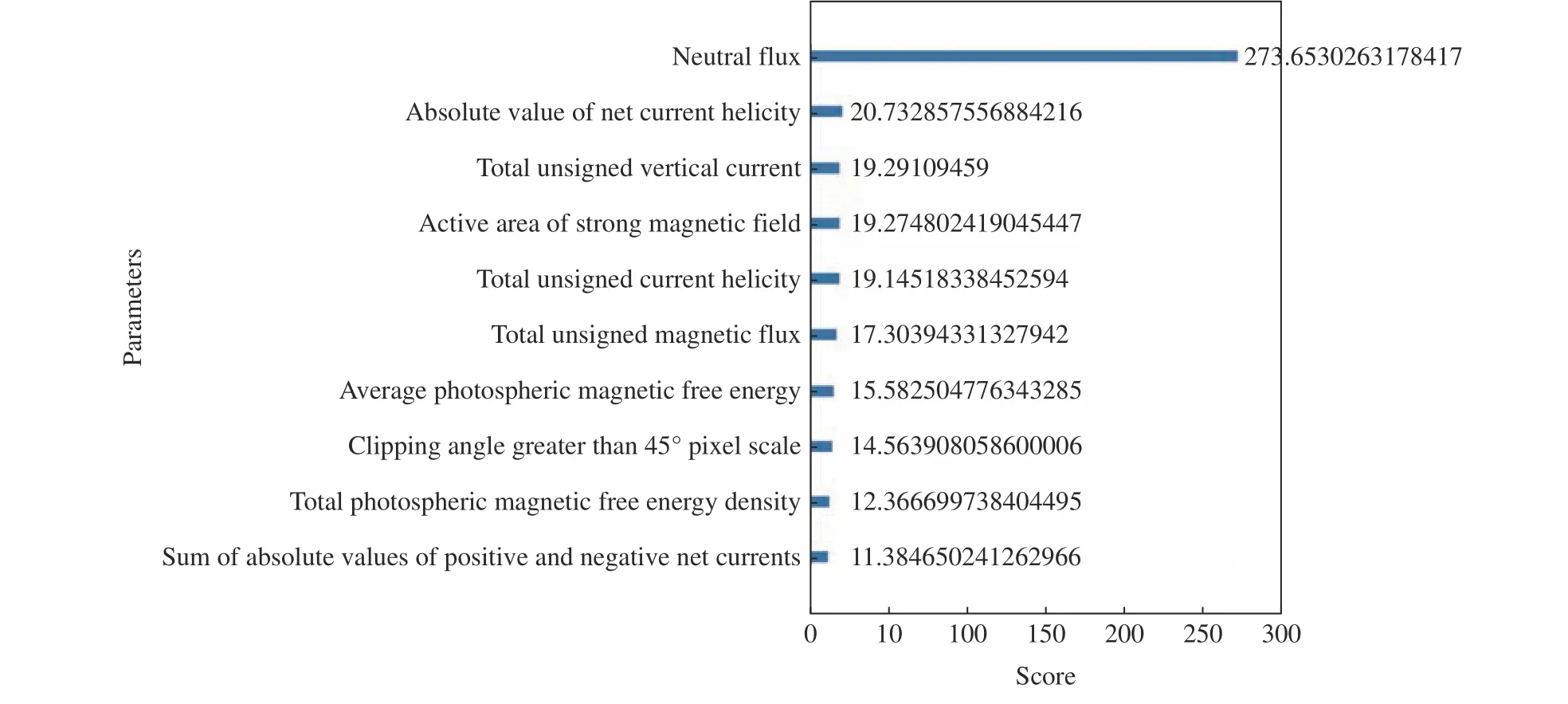
圖4 10 個物理參量在所有弱學習器中的增益率Fig. 4 Gain rate of ten parameters in all weak learners
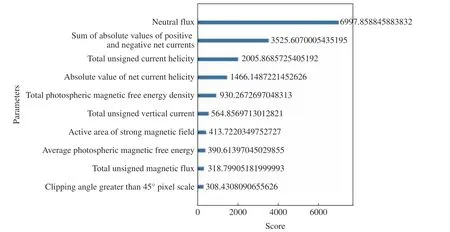
圖5 10 個物理參量在所有弱學習中的覆蓋率Fig. 5 Cover rate of ten parameters in all weak learners
2.3 模型建立
采用2015 年Fran?ois Chollet 為ONEIROS 項目開發的深度學習框架keras 構建耀斑預報模型,模型結構如圖6 所示,分別為輸入層、LSTM 層1、Dropout 層1、LSTM 層2、Dropout 層2 以及全連接層(分類層)。其中輸入層的輸入維度為樣本個數×時間步長×特征維度,由于時間步長=滑動窗口長度+1,因此輸入維度為44022×16×6。LSTM 層1 的神經元個數為128 個,因此其輸出維度為44022×16×128。Dropout 層1 的神經元保留概率為0.5,且不改變輸出維度。LSTM 層2 的神經元個數為128 個,在LSTM 層2 需要返回到分類層,因此數據維度輸出為44022×128。分類層的損失函數為二分類交叉熵損失,神經元個數為1,最終輸出結果為0~1 之間的數值。
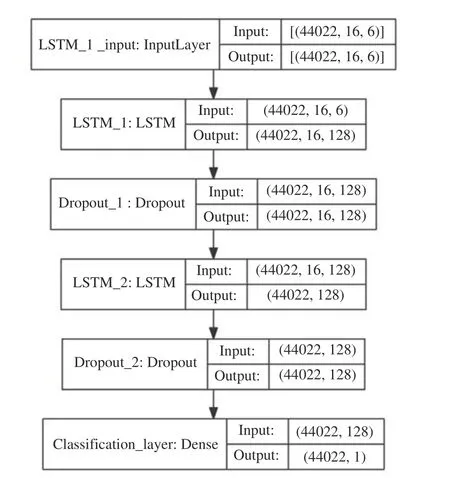
圖6 LSTM 耀斑預報模型結構Fig. 6 LSTM flare prediction model structure
所使用的樣本數據集存在較大數據不均衡問題,即正樣本的個數遠少于負樣本,若是按照傳統機器學習任務的做法,應該是補充正樣本的數量,但是考慮到耀斑事件的發生頻率很低,正負樣本的不均衡反映了耀斑事件發生頻率的客觀事實,因此選擇保留這樣的數量差異。為了解決數據不均衡對模型效果的影響,對分類所使用的交叉熵損失函數進行修改,在正樣本上增加了分類權重,增加的分類權重等于正負樣本比例(1∶25),在模型訓練時會讓模型更側重正樣本進行訓練,解決樣本不均衡問題。
為了選取合適的閾值確定是否發生耀斑事件,這里通過不斷調整閾值大小,計算出不同閾值下的報準率(TPR,定義符號RTP)和虛報率(FPR,定義符號RFP),即
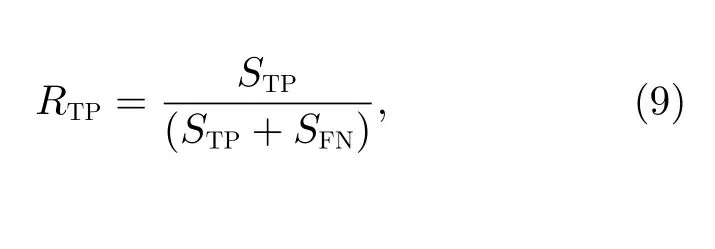
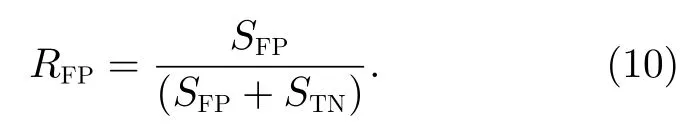
符號定義如下。
STP(True Positive, TP):原本屬于正樣本,被分類成正樣本,記為真實的正樣本。
SFN(False Negative, FN):原本屬于正樣本,分類成負樣本,為耀斑事件被遺漏的樣本,記為虛假的負樣本。
SFP(False Positive, FP):原本屬于負樣本,分類成正樣本,無耀斑發生的活動區被虛報的樣本記為虛假的正樣本。
STN(True Negative, TN):原本屬于負樣本,被分類成負樣本,無耀斑發生的活動區被正確預報的樣本記為真實的負樣本(TN)。
繪制模型輸出結果的ROC(Receive Operating Characteristic)曲線[37],如圖7 所示。由于ROC 曲線越接近點(0,1),模型整體效果越好,因此篩選出到點(0,1)距離較小的部分點用于實驗,實驗結果表明當閾值為0.7334 時耀斑預測效果最好,選擇0.7334作為分類的輸出閾值,輸出值大于分類閾值判定為正樣本,反之為負樣本。

圖7 LSTM 耀斑預報模型ROC 曲線,圖中紅點為該模型的最佳閾值所對應的TPR 和FPRFig. 7 ROC curve of the LSTM flare prediction model. The red dots in the figure are the TPR and FPR corresponding to the optimal threshold of the model
3 結果與分析
使用二分類混淆矩陣評估模型的訓練結果,選用報準率(RTP)、虛報率(RFP)、準確率(Accuracy,Rac-curacy)和真實技巧統計值(True Skill Statistics, TSS,ITSS, 臨界成功指數)作為模型的評判標準。通過式(9)和式(10)可以看出,報準率越高,虛報率越低,說明模型的預報能力越強。通過如下公式可計算耀斑預報模型對于事件的預報準確率(Raccuracy)和真實技巧統計值(ITSS):
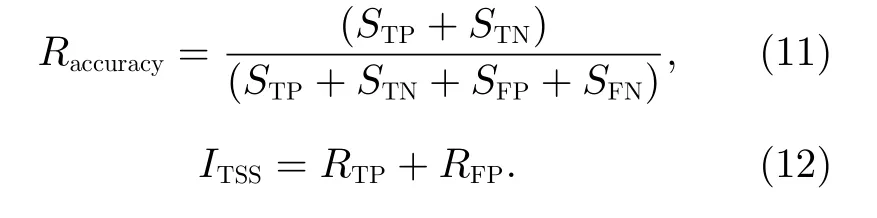
為了評估模型的預報結果,采用同樣的數據集,利用機器學習中的支持向量機(SVM)、決策樹C4.5、集成學習方法XGBoost、集成學習方法隨機森林(RandomForest)、邏輯回歸(Logistic Regression)等方法進行對比。支持向量機、隨機森林、邏輯回歸等是良好的分類器,但是缺乏對于太陽活動區時序信息的捕捉。
表2 和表3 給出了LSTM、 SVM、 XGBoost、RandomForest、 C4.5、邏輯回歸等模型對未來48 h 太陽耀斑的預報評估結果。可以看出所提出的LSTM 模型報準率為0.7483,高于其他模型;虛報率與SVM 相當,略低于邏輯回歸模型;準確率包含了對正負樣本預報結果的評估,由于負樣本比例較大,因此負樣本的預報效果決定了預報的準確性,這些模型的預報準確性基本相當;TSS 評價指標綜合考慮了報準率與虛報率的影響,LSTM 模型的TSS 評分為0.7402,高于其他幾個模型。模型總體預報性能優于傳統機器學習模型。
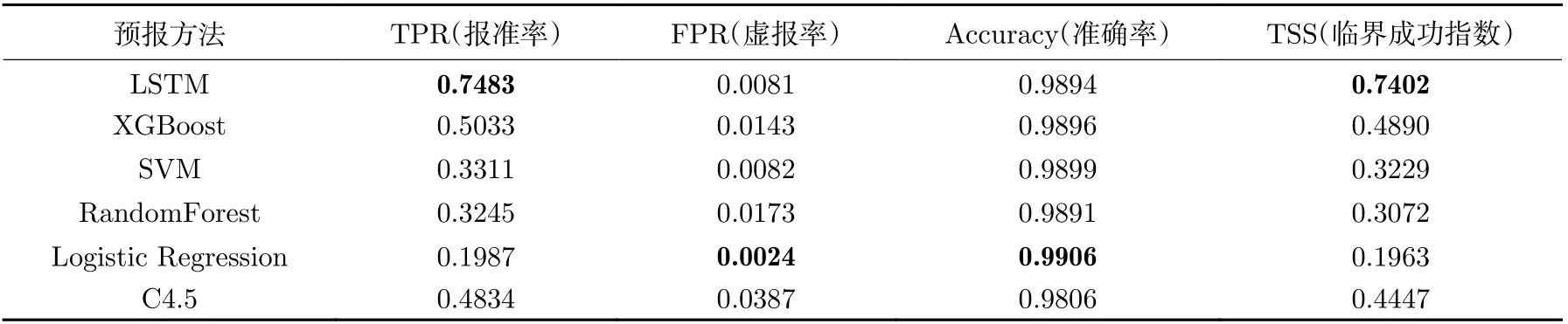
表2 不同模型預報結果評估(1)Table 2 Evaluation of forecast results of different models (1)

表3 不同模型預報結果評估(2)Table 3 Evaluation of forecast results of different models (2)
Li 等[27]利用SOHO 衛星MDI 載荷拍攝的磁圖數據作為數據集,使用卷積神經網絡(CNN)建立了太陽耀斑預報模型,Huang 等[28]利用SOHO/MDI 和SDO/HMI 拍攝的磁圖,同樣使用卷積神經網絡(CNN)構建了多預報時段太陽耀斑預報模型,選取其對于未來48 h 的M 級及以上耀斑模型進行對比(見表4 和表5),相比使用磁圖數據的CNN 模型,LSTM 預報模型的報準率略低于CNN 預報模型,而準確率、虛報率和臨界成功指數等優于CNN 模型,并且從表5 可知,LSTM 預報模型的數據樣本少于CNN 預報模型,如果增加LSTM 預報模型的數據樣本數量,還可以有所提升。

表4 CNN 與LSTM 模型預報結果評估(1)Table 4 Evaluation of forecast results of CNN and LSTM models (1)

表5 LSTM 與CNN 模型預報結果評估(2)Table 5 Evaluation of forecast results of LSTM and CNN models (2)
建立未來48 h≥M 級太陽耀斑預報模型時,采用了SHARP 數據的時序物理參量作為輸入參數。圖8 和圖9 分別給出了正樣本和負樣本中6 個物理參量和未來48 h 太陽X 射線的流量變化。可以看到正樣本各參數在滑動窗口內變化較大,之后的48 h 內 發 生 了M8.4 級 耀 斑(2012 年3 月10 日17:44:00 UT);而負樣本各參數在滑動窗口內較平穩,未來48 h 無≥M 級耀斑發生。
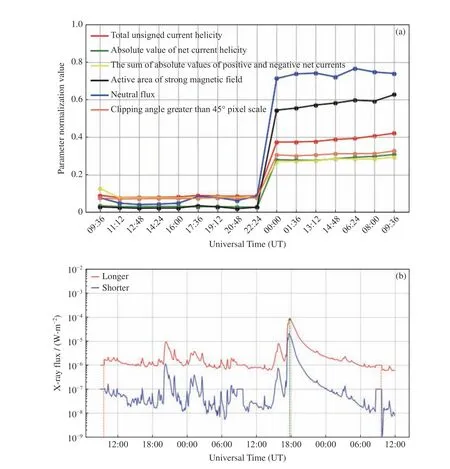
圖8 正樣本(2012 年3 月8 日09:36 UT 至9 日09:36 UT)各特征參數的變化(a)和GOES 衛星測量(2012 年3 月9 日00:00 至12 日00:00 UT)在該樣本未來48 h 的X 射線通量變化(b)。橙色垂直虛線為模型預測范圍,綠色虛線為耀斑事件(2012 年3 月10 日17:44 UT)Fig. 8 Positive sample (from 09:36 UT on 8 March 2012 to 09:36 UT on 9 March 2012) characteristic parameter change (a) and the GOES satellite measurement (from 00:00 UT on 9 March 2012 to 00:00 UT on 12 March, 2012) of the X-ray flux change of the sample in the next 48 h (b). Orange dashed line is the model prediction range, and the green dashed line is the flare event (17:44 UT on 10 March 2012)
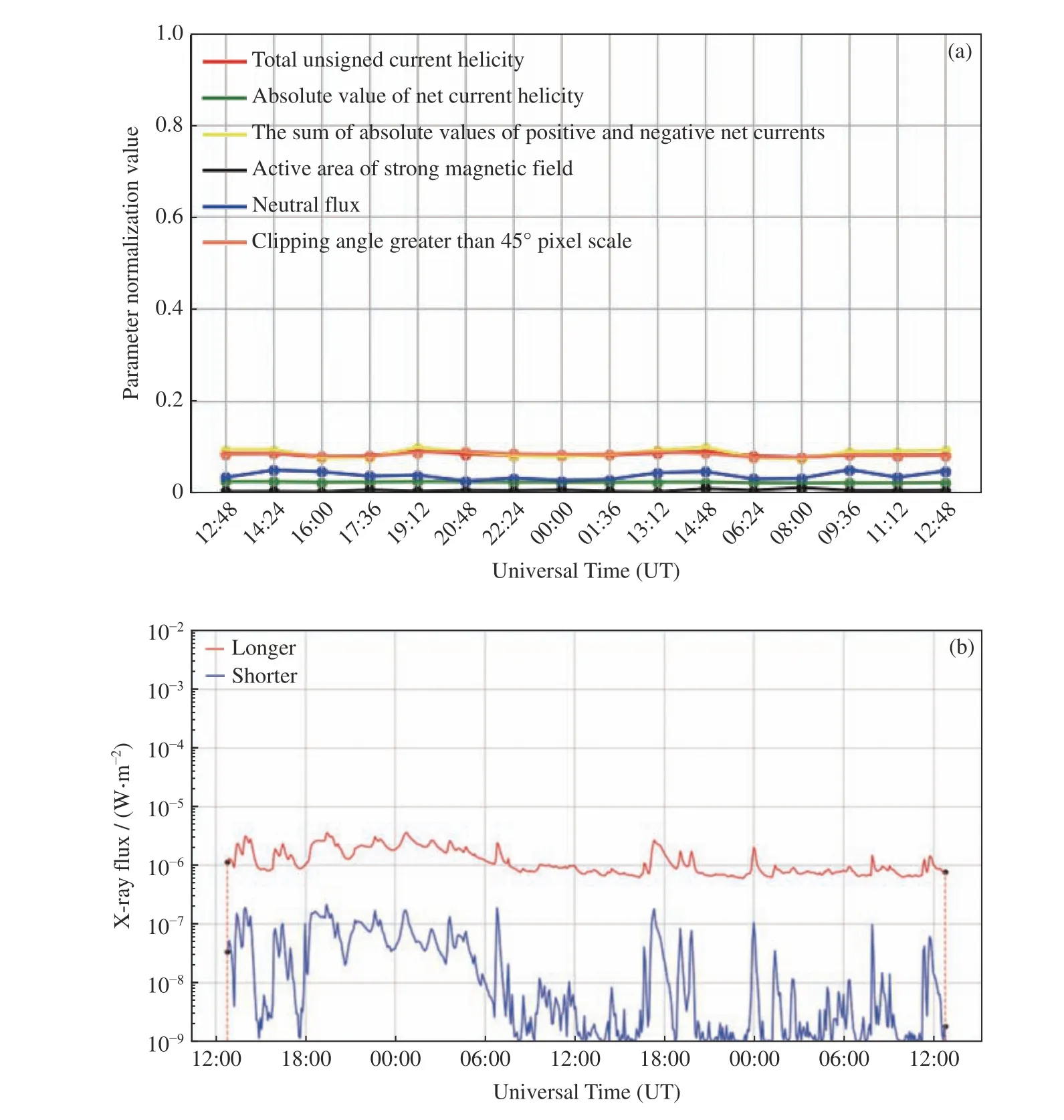
圖9 負樣本(2011 年11 月16 日12:48 UT 至17 日12:48 UT)各特征參數變化(a)與GOES 衛星測量(2011 年11 月17 日00:00 UT 至20 日00:00 UT)該樣本未來48 h 的X 射線通量變化(b),橙色虛線為模型預測范圍,顯示該樣本未來48 h 內無≥M 級耀斑發生Fig. 9 Negative sample (from 12:48 UT on 16 November 2011 to 12:48 UT on 17 November 2011) characteristic parameter change (a) and the GOES satellite measurement (from 00:00 UT on 17 November 2011 to 00:00 on 20 November 2011) of the X-ray flux change of the sample in the next 48 h (b). Orange dashed line is the model prediction range, and shows that there is no ≥M class flares occurrance in the next 48 h for this sample
本文提出的模型在準確率上并不具備優勢,由于在訓練過程中為了解決數據的不平衡問題,在模型訓練過程中修改了損失函數的權重,使模型對正樣本的識別更加側重,導致對負樣本的識別率降低,會在一定程度上影響模型虛報率和對負樣本的識別。
4 結論
提出了基于長短期記憶神經網絡的太陽耀斑預報模型,通過XGBoost 方法對SHARP 數據中各物理參量進行特征重要性分析,最終選取特征總無符號電流螺度、正負極凈電流絕對值、凈電流螺度絕對值、活動區強磁場面積、中性線磁通量、剪切角大于45°的像素比例這6 個物理參量作為模型輸入參數。利用活動區這6 個參數連續24 h 的數據作為輸入,建立未來48 h 的太陽耀斑預報模型。
與傳統機器學習模型及經驗模型相比,本文提出的模型對太陽活動區的時間變化特征進行建模,運用了太陽活動區磁場的時間演化信息,得到優于傳統機器學習模型的預報效果。基于LSTM 模型的報準率和臨界成功指數分別為0.7483 和0.7402,均高于傳統機器學習模型,模型在準確率和虛報率上與傳統模型相近,總體性能優于傳統機器學習模型。預報結果與對耀斑產生物理機制的認識一致,即活動區的演化過程對于耀斑產生具有重要影響。
構建數據樣本的規則是通過判斷未來48 h 內是否發生>M 級別太陽耀斑事件,因此模型能分辨兩種情況,分別為未來48 h 內發生≥M 級以上的耀斑事件和未來48 h 內發生<M 級耀斑或不發生耀斑事件。在構建模型時只用到活動區的參數特征,未用到圖像特征,而圖像的演化信息同樣可以使用長短期記憶神經網絡進行分析,建立耀斑預報模型。利用太陽觀測圖像信息進行分析和建模研究,并對不同耀斑級別的預報進行更細致的劃分將是未來研究的重要方向。
致謝 耀斑數據由SDO 衛星提供。SDO 衛星為NASA 啟動的“與星共棲”計劃(LWS)的第一個任務,該計劃旨在了解太陽變化的原因及其對地球的影響。太陽活動區耀斑爆發數據集由中國科學院國家空間科學中心空間環境人工智能預警創新工坊整理提供。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
