基于深度學習的耙吸挖泥船裝艙產量預測研究*
2022-11-09 02:35:26朱大鵬俞孟蕻
計算機與數字工程 2022年9期
朱大鵬 俞孟蕻 蘇 貞
(1.江蘇科技大學電子信息學院 鎮江 212100)(2.江蘇科技大學海洋裝備研究院 鎮江 212003)
1 引言
在形式各異的疏浚工程船舶中,耙吸挖泥船由于具有獨立工作能力和很強的環境適應能力而在挖泥船中占有重要地位,是全球疏浚領域的主力軍[1~5]。預測耙吸挖泥船的產量對于提升挖泥船的疏浚效率具有明顯的幫助,通過耙吸挖泥船產量的預測,可以在施工過程中選擇挖泥船的最優施工參數,從而提升挖泥船的疏浚效率和工程效益。
耙吸挖泥船的產量受到船舶航行速度、耙頭對地角度、泥泵吸入真空、溢流堰高度、船艙參數、砂土特性等因素的影響,因此耙吸挖泥船的生產過程是一個復雜的、高難度的過程。Wangli[6]則通過把裝艙過程分為無溢流階段、恒體積階段和恒載重階段對裝艙指標進行評估分析。王培勝[7]從疏浚機理出發,對挖泥船的裝艙過程進行動態建模,對溢流密度與溢流流量進行了預測。王湘[8]通過使用遺傳算法優化疏浚模型,表明改變施工參數可以有效提高挖泥船的疏浚效率。孫健[9]通過使用遺傳算法對BP神經網絡進行優化,以此來預測干土方生產率。
耙吸挖泥船的施工數據是基于時間序列的數據,數據之間存在時間滯后的問題,而這些方法大多沒有考慮時間序列之間的滯后、依賴問題,且并未涉及未來時刻的目標參數的預測。因此采用了基于時間序列的循環神經網絡進行產量預測模型的建立。與傳統的機器學習相比,循環神經網絡引入了“記憶”的概念,從內部結構上建立了輸入變量隨時間的變化關系,對于數據滯后、長期依賴、多步預測的情況有較好的預測效果。
2 GRU神經網絡
循環神經網絡對于時間序列的數據具有很好的處理能力,對非線性、多步預測問題可以取得很好的預測效果,因此采用循環神經網絡對耙吸挖泥船進行產量預測模型的構建[10]。GRU神經網絡是循環神經網絡的一個變種,它通過使用同一個門控單元——更新門來同時進行信息的遺忘和記憶,從而使計算更加便捷,提高訓練效率[11]。
GRU神經網絡引入了兩個門函數,分別是更新門和重置門,其結構如圖1所示[12]。
由圖1可知,GRU網絡的前向傳播公式如下所示:
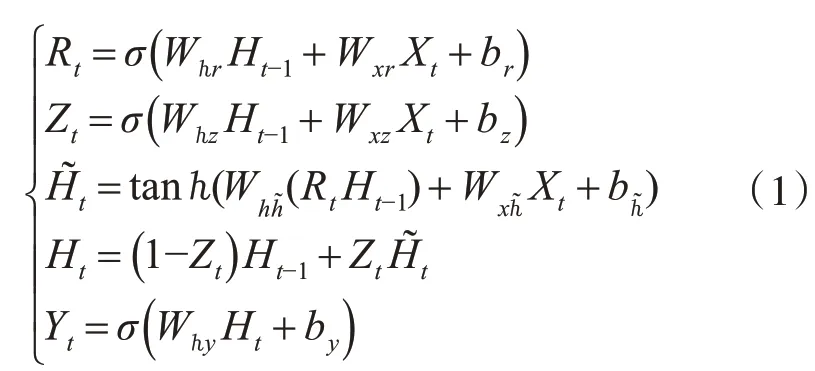
在上述公式中,Xt、Ht分別為隱含層的輸入和輸出,Yt為輸出層的輸出,而Rt、Zt和H~t則分別是隱含層結構中重置門輸出、更新門輸出和候選記憶單元輸出[13]。在對GRU網絡結構的學習中,首先通過上一個時刻的輸出Ht-1和當前時刻的輸入Xt來獲取兩個門控狀態——重置門Rt和更新門Zt,兩者均輸出一個值域為[0,1]的值。參數W?r、Wxr、W?z、Wxz、W??~、Wx?~、W?y、br、bz、b?~的學習更新過程是一個誤差反向傳播的過程,其中t-1時刻隱含層的輸出的偏導是由t時刻各個門的輸入的偏導所組成:
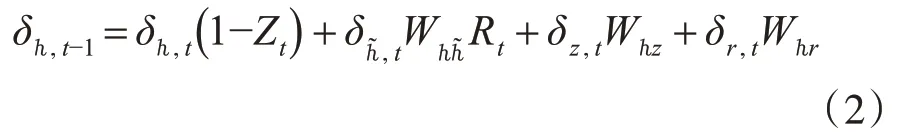
式中δ?,t、δ?~,t、δz,t、δr,t分別為t時刻網絡的隱含層、候選記憶單元、更新門和重置門的偏導。
3 改進GRU神經網絡研究
3.1 時間序列數據處理
在進行預測模型搭建之前需要先對施工數據進行處理。首先通過填補、消噪等方法對數據進行預處理,消除數據采集過程中因設備原因而產生的疏漏與噪聲,并通過歸一化的方式消除不同數據間的量綱影響。然后通過滑動窗口的方式將n行輸入數據轉化為一行輸入數據,其轉換方式如圖2所示。
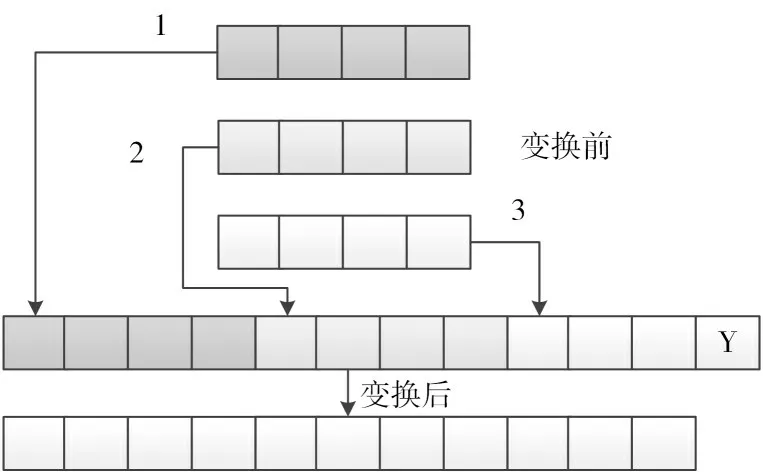
圖2 數據轉換方式
當n=3時,將每3行數據合并轉化為新的行數據,在新的行數據中末端數據為預測輸出值Y。
3.2 注意力機制
近幾年來,注意力機制在深度學習領域有著廣泛的應用,常被用來進行圖像處理、自然語言處理、目標檢測、語音識別等任務[14]。注意力機制沒有嚴格的數學定義,它根據目標任務的不同,進行方向和加權模型的調整,從而加強對重要信息的關注和對不重要信息的弱化[15~16]。自注意力機制是注意力機制的改進,它減少了對外部信息的依賴,更擅長捕捉數據或特征的內部相關性,對輸出結果貢獻大的數據賦予較大的權重,使其對輸出的影響加強。
3.3 自注意力機制優化的GRU神經網絡
自注意力機制優化的GRU神經網絡(Self-attention GRU,SGRU)其結構如圖3所示,該網絡結構由四部分構成:第一部分為輸入層,第二部分為堆疊式GRU層,第三部分為自注意力層,第四部分為輸出層。
由圖3可知,數據由輸入層輸入后先經過GRU層處理得到輸出Ht,然后由GRU層輸出Ht轉置后作為自注意力層的輸入進行自注意力系數s的計算。
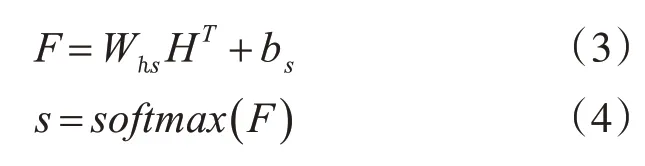
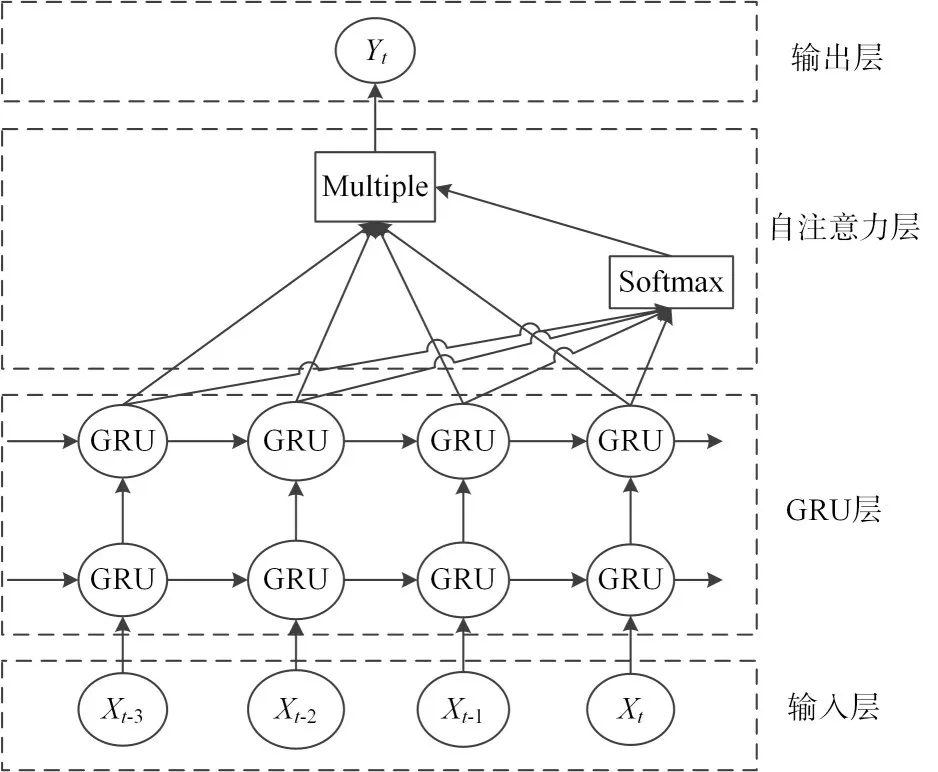
圖3 自注意力GRU結構圖
然后將GRU層的輸出Ht與自注意力系數s一一對應后進行相乘得出自注意力層的輸出Z。

最后自注意力層的輸出Z經過輸出層的激勵函數得到整個網絡的最終輸出Y。
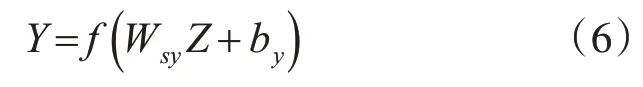
式中,Wsy和by分別為輸出層的權值和閾值。
4 實驗結果與分析
耙吸挖泥船產量預測模型的數據來自于2016年4月“新海虎8”號耙吸挖泥船在廈門港進行作業時的施工數據。施工數據包括挖泥船航速、耙頭對地角度、泥泵吸入真空、泥泵流速、波浪補償器壓力、溢流堰高度、裝艙體積以及裝艙質量這些參數數據,并按照4∶1的比例將數據集劃分為訓練集和測試集。
模型通過對過去10個時刻樣本數據的學習來對當前時刻以及未來2個時刻的挖泥船裝艙質量與裝艙體積進行預測,并與未優化的GRU神經網絡預測模型進行比較。
圖4、圖5分別是當前t時刻、t+1時刻、t+2時刻的裝艙質量與裝艙體積的兩個模型預測曲線與真實值曲線對比圖。圖6、圖7分別是三個時刻的裝艙質量與裝艙體積的兩個模型預測值與真實值之間的絕對值誤差曲線圖。由圖中可看出經過自注意力機制優化的GRU預測模型與未優化的GRU預測模型相比其預測結果更接近真實值。
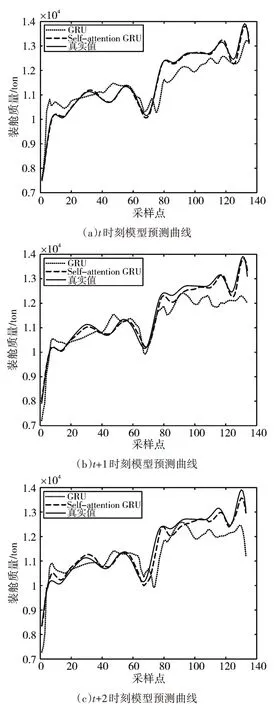
圖4 裝艙質量預測圖

圖5 裝艙體積預測圖
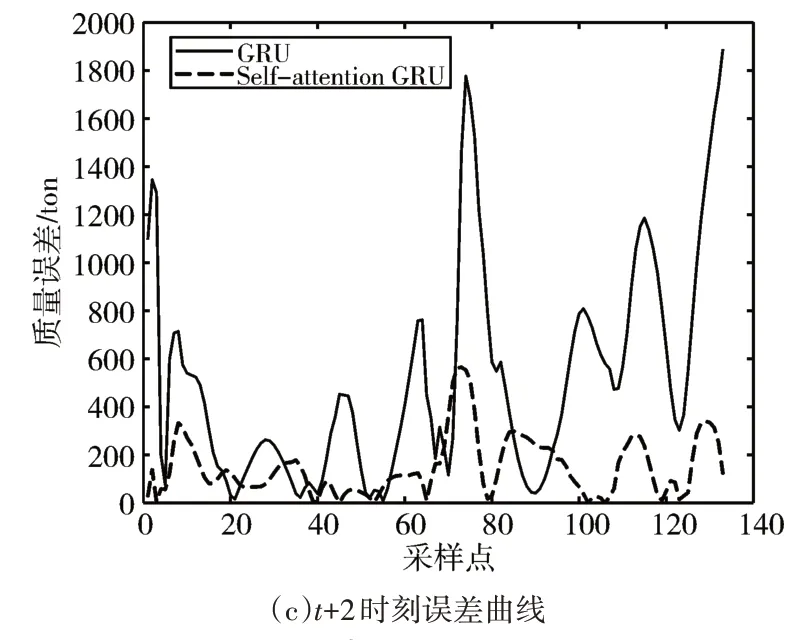
圖6 裝艙質量誤差圖
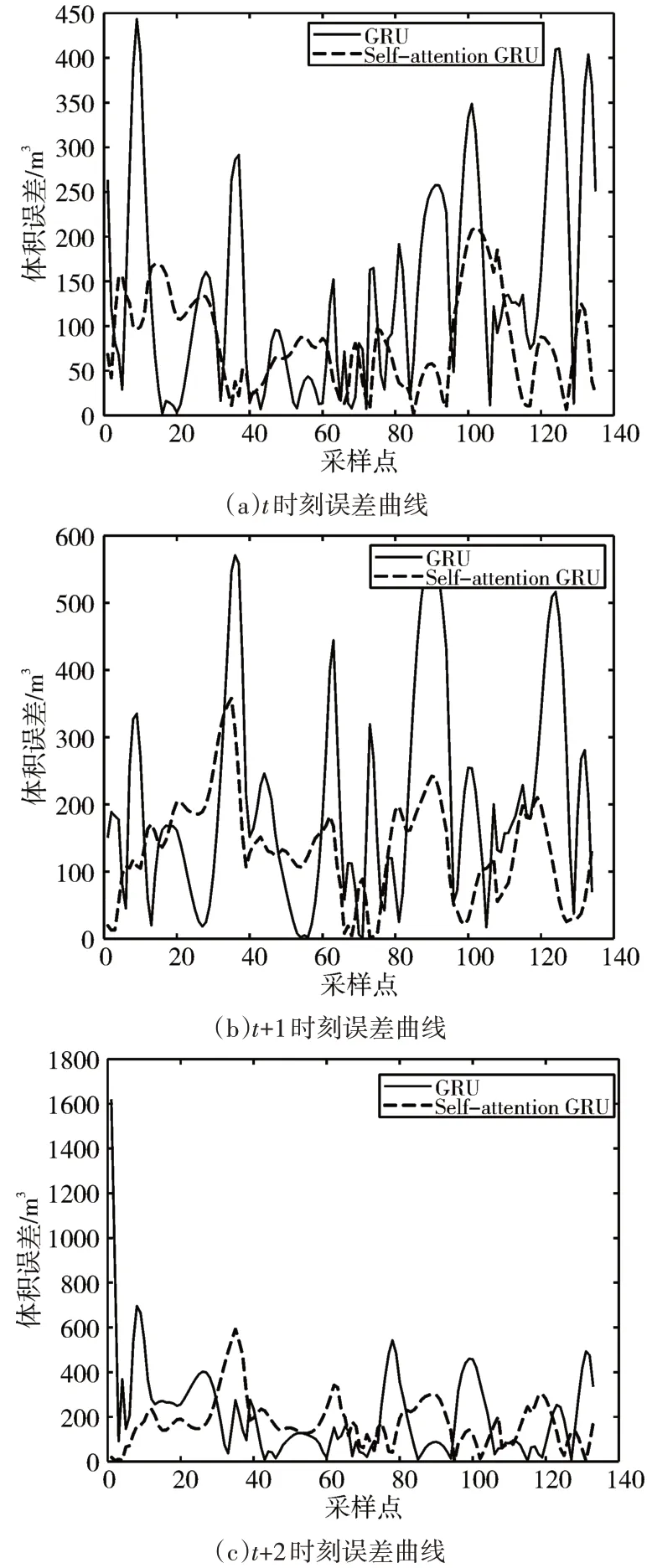
圖7 裝艙體積誤差圖
為進一步驗證SGRU預測模型的優越性,文章采用均方根誤差(RMSE)和平均百分比誤差(MAPE)作為指標來進行模型之間的比較,RMSE與MAPE的值越大表明預測效果越差。
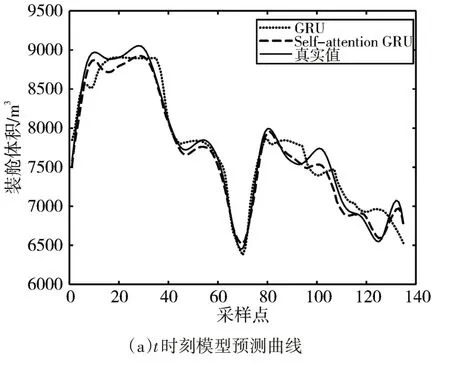
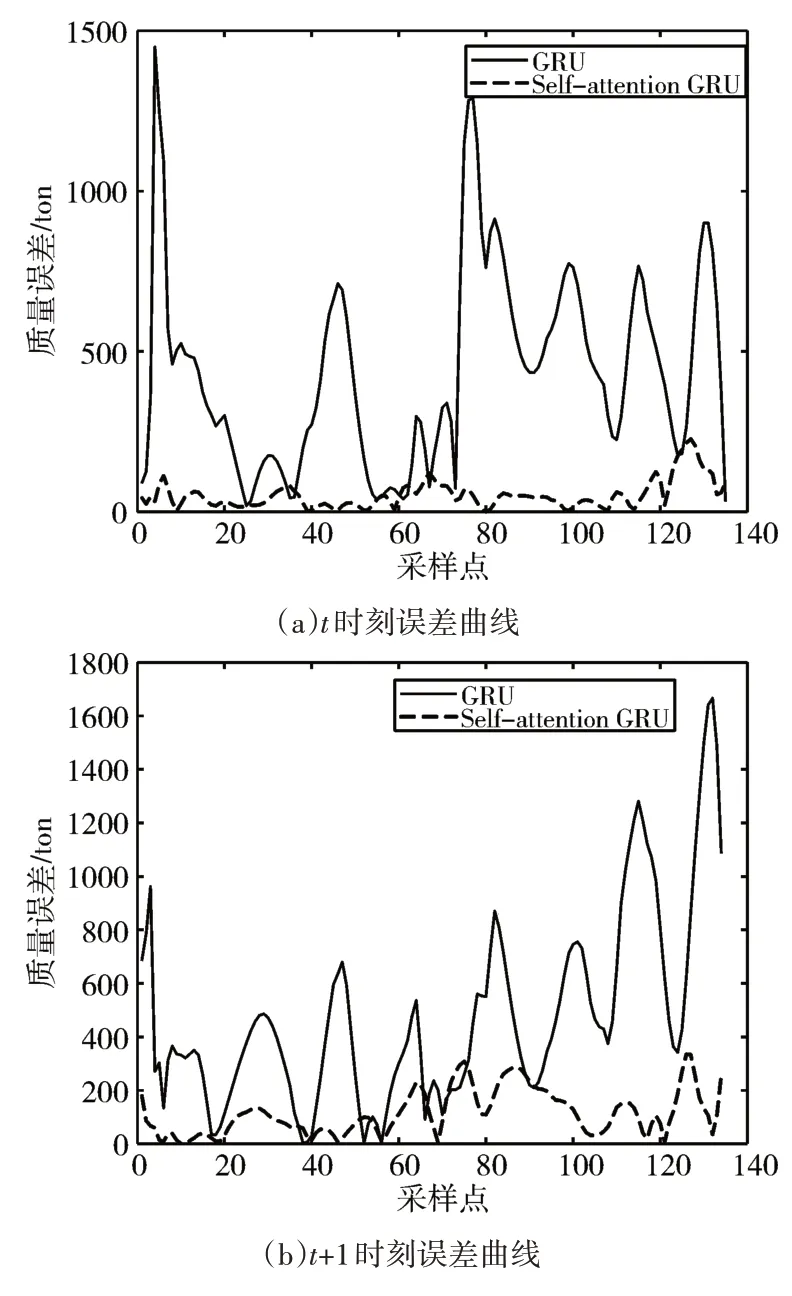
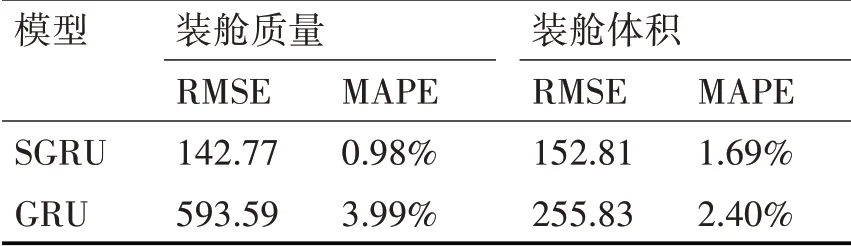
表2 t+1時刻挖泥船產量預測誤差
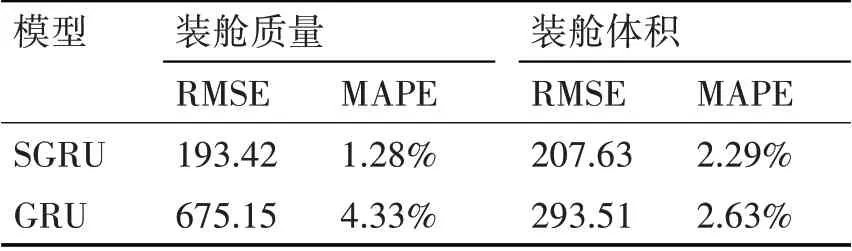
表3 t+2時刻挖泥船產量預測誤差
表1、2、3通過比較兩種模型之間的均方根誤差和平均百分比誤差可以清晰地看出經過SGRU預測模型的誤差更小,預測效果更為精確。
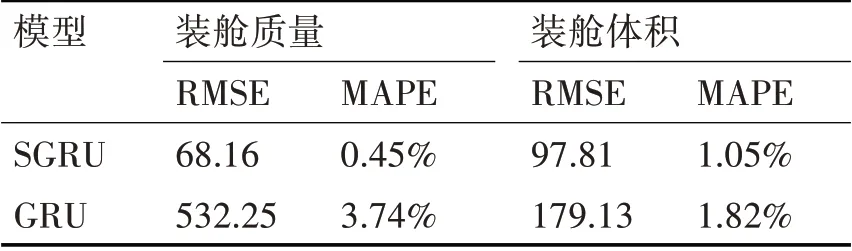
表1 t時刻挖泥船產量預測誤差
5 結語
實驗表明,使用自注意力機制對GRU模型進行優化可以有效地降低模型的預測誤差,較好的對耙吸挖泥船的產量進行預測。預測模型通過對過去數據的分析與學習,成功預測了耙吸挖泥船的當前時刻以及未來時刻產量,更好地構建了挖泥船裝艙產量預測模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
礦山安全信息(2022年40期)2022-04-07 02:16:52
今日農業(2021年14期)2021-11-25 23:57:29
石油與天然氣地質(2021年1期)2021-02-22 14:14:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
今日農業(2020年20期)2020-11-26 06:09:10
數學物理學報(2020年2期)2020-06-02 11:29:24
中國果業信息(2019年10期)2019-11-13 01:21:34
聚氯乙烯(2018年9期)2018-02-18 01:11:34
光學精密工程(2016年6期)2016-11-07 09:07:19
