基于數據增強視覺Transformer 的細粒度圖像分類
2022-11-11 11:31:52胡曉斌彭太樂
西華大學學報(自然科學版) 2022年6期
胡曉斌,彭太樂
(淮北師范大學計算機科學與技術學院,安徽 淮北 235000)
與傳統的圖像分類不同,細粒度圖像分類(fine-grained vision classification,FGVC)是指將下級類別分類到基本類別下,例如鳥和狗的種類、飛機和汽車的型號等。由于類內差異較大以及低類間方差,屬于同一類別的物體經常呈現出完全不同的形態,不同類別的物體之間也可能非常相似。其次,由于訓練數據的局限性,對細粒度類別進行標記通常需要大量的專業知識,因此細粒度圖像識別被認為是一項更具挑戰性的任務。
大多數先前的工作[1-4]是使用卷積神經網絡(convolutional neural network,CNN)作為主干網絡來提取圖像中的細微特征。但是此類方法隨著網絡層數的加深,計算復雜程度增大,在提取深層的特征時容易受到非特征區域噪聲的干擾。近年來,Transformer 在一般圖像分類[5]、圖像檢索[6]和語義分割[7]方面都展現出了優越的性能。視覺Transformer(ViT)[5]通過其固有注意力機制能夠自動識別出圖像中有判別性的特征區域,在圖像分類領域證明了自身巨大的潛力。然而,ViT 無法直接在FGVC 上發揮其優勢,例如,ViT的感受無法有效擴展,其像素塊標記的長度不會隨著編碼器層數的增加而改變。此外,ViT 輸入固定大小的像素塊不利于網絡捕獲關鍵性的區域注意力信息。
本文提出一種新穎的數據增強視覺 Transformer(DAVT)用于細粒度圖像分類。它能夠匯聚各個層級有判別性的特征信息并進行分類,其層級注意力選擇HAS 通過在各個層級之間篩選關鍵標記并融合,以補償局部和層級之間缺失的信息。其次,本文還使用注意力引導的圖像裁剪來減少固定大小像素塊帶來的部分噪聲干擾,增強圖像表達關鍵特征的能力。
1 相關工作
1.1 細粒度圖像分類
目前主流細粒度分類的方法有基于定位的方法[2-4,8]和特征編碼方法[9-11]。前者利用注意力機制、聚類等手段來發現區別性區域。后者則是通過計算高階信息來捕獲更多區域細微的特征。
強監督定位的方法需要昂貴的人工標注,而弱監督定位的方法不需要部件標注,僅通過分類標簽即可完成訓練;因此,弱監督定位的方法受到了更多的關注。注意力機制的誕生進一步提升了弱監督圖像分類的性能,主流的分類模型更加聚焦于多樣的注意力引導的方法。CAL[2]利用反事實干預促使網絡學習更多的注意力區域。特征增強和抑制方法[3]則通過對關鍵部分和局部區域進行增強或抑制,以迫使網絡挖掘潛在的信息。基于特征編碼的方法專注于捕獲細微的局部特征,以提高分類精度。構建對比輸入批次的方法[9]通過計算不同特征之間的線索,從而加強特征包含判別信息的能力。而跨層雙線性池化[12]則通過捕獲層間局部特征關系,以提高多個跨層雙線性特征的表示能力。本文將基于注意力機制的圖像增強方法擴展到Transformer 中,利用數據裁剪擦除無關的圖像噪聲,達到特征增強的效果。
1.2 Transformer
隨著Transformer 在計算機視覺領域取得突破性進展[5,13-14],圖像識別也在Transformer 的基礎上迎來了新的熱潮。ViT 是第一個采用純Transformer結構的圖像分類模型。它包含嵌入層和編碼器,編碼器由多頭自我注意力機制(MSA)和多層感知模塊(multi-layer perceptron,MLP)組成。訓練時,嵌入層將圖像分割成固定大小的像素塊,并將其輸入Transformer 的編碼器進行分類,像素塊依次通過MSA 和MLP 進行訓練和分類。最終,ViT 利用最后一個編碼器層的第一個標記作為全局特征的表示,并將其轉發給MLP 模塊的分類器頭以獲得最終分類結果,而不考慮存儲在其余層標記中的潛在信息。為解決ViT 潛在的問題,AFTrans[15]通過自適應注意力多尺度融合Transformer 來捕獲區域注意力。文獻[16]提出了一種峰值抑制模塊懲罰最具判別性的區域來學習不同的細粒度表示。TransFG[17]和FFVT[18]分別將ViT 擴展到大規模和小規模FGVC 數據集。然而,這些工作忽略了層級之間的部分局部特征和固定大小的像素塊帶來的噪聲影響。受到FFVT 模型的啟發,本文將關鍵標記篩選延伸到ViT 模型的各個層級,使用層級交叉相乘的方法逐層提取局部特征,更加強調各個層級之間的標記關聯性。
2 數據增強Transformer 的分類方法
由于ViT 網絡模型深層的輸入標記難以關注圖像局部的細微特征,也很難聚集各層級之間的重要標記信息。針對這一問題,本文提出層級注意力選擇和數據增強的方法強制網絡選擇判別性的標記信息以彌補各個層級之間缺失的特征信息。將增強后的圖像從新輸入網絡進行循環,促使網絡生成多尺度特征對判別區域進行學習。DAVT 總體結構如圖1 所示。
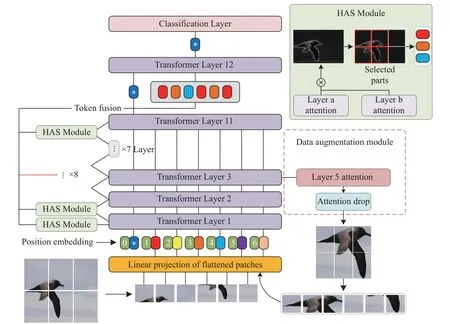
圖1 DAVT 網絡框架圖
2.1 層級注意力選擇機制
原始ViT 中經過嵌入層的標記信息判別性較弱,由于固定大小的像素塊引發的噪聲影響,高層次的輸入標記不一定能保留原始標記相對重要的特征信息。為此,本文提出了層級注意力選擇機制,將層級間的注意力權重融合并對標記進行篩選。DAVT 網絡模型中前幾層的注意力權重表示為:

式中:K表示模型中多頭自我注意力機制中自我注意力頭的數量,l表示模型的層數,但僅依靠自我注意力頭部和尾部在各個層級內部提取標記信息,容易造成層級間的部分局部信息的遺漏,為了充分利用各個層級間的標記信息,通過如下方式整合層級間的注意力權重:
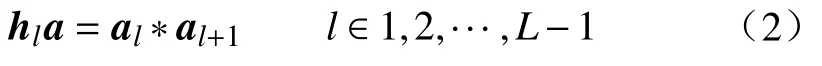
式中:hla代表第l層融合后的注意力權重。將此方法應用于除去最后一層的所有Transformer 層。具體來說,通過將第l層和第l+1 層的注意力權重通過矩陣乘法進行融合,其中l∈(0,L-1)。隨后利用Max()函數選取K個不同注意力頭的最大值指標A1,A2,···,AK,這些位置被用作模型的索引,以提取層級之間判別性的標記。使用HAS 方法選擇的關鍵標記表示為
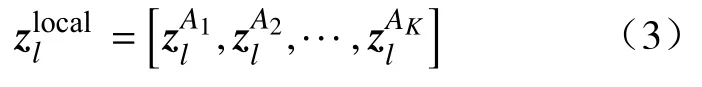
式中:AK表示注意力權重選定特征的數量。最后,將分類標記連接到各層篩選后的判別性標記,融合后輸入最后一個Transformer 層進行分類,此過程可表示為
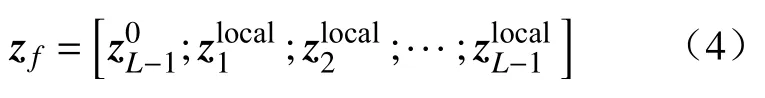
層級注意力選擇方法直接聚合各層級之間判別性標記,并將分類標記和融合后的標記作為輸入連接到最后一個Transformer 層,不僅保留了各個層級間的本地信息,還充分利用層級間的注意力權重,捕獲丟失在深層的局部信息。
2.2 注意力引導的數據增強
在訓練過程中,ViT 將原始圖像分割成固定大小的像素塊,隨著數據量的增加,像素塊帶來的圖像噪聲也會增加。例如:某一個像素塊中,沒有鳥的頭部、翅膀、頸部等關鍵信息,只有天空、云等環境背景信息。注意力引導的數據增強能削弱圖像噪聲帶來的影響,并增加訓練部分的數據量。
訓練過程中,通過ViT 中多頭自我注意力機制生成的第 ξ層的注意力圖aξ來指導數組增強的過程,并將其歸一化為,使其更具有代表性。歸一化過程如下:


目的是尋找能覆蓋整個Ck選定的Mask(元素值為1)區域的最小邊界框,用該邊界框裁剪原圖,并放大到原始圖像大小作為增強后的輸入數據。由于對象部分的比例增加,因此模型能更好地定位對象位置,方便提取更具有判別性的特征。
由于引入了數據增強后的新圖像,因此,在訓練階段,損失函數由多個部分組成。其表示為
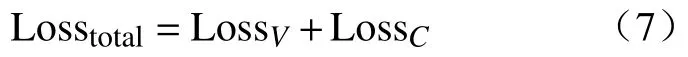
式中:LossV、LossC分別表示原始圖像的交叉熵損失以及注意力裁剪后的交叉熵損失。這兩種損失在反向傳播過程中共同作用,從而優化模型的性能。
3 實驗
本文在CUB-200-2011[19]、Stanford Dogs[20]數據集上對模型進行評估。CUB-200-2011 是一個關于鳥類的數據集,它包含11 788 張鳥類圖片,其中訓練集、測試集分別包含5 994 張和5 794 張圖片,共計200 個鳥類類別。Stanford Dogs 包含來自世界各地的120 種狗類的圖片,其中訓練集、測試集分別包含12 000、8 580 張圖片。兩個數據集不僅包含圖像標簽,還包含邊界框和零件注釋。實驗中使用Top-1%表示細粒度圖像的分類的準確率,利用損失函數的變化率來測試訓練過程是否發生過擬合。
3.1 實驗細節
在所有實驗中加載官方在ImageNet21k 上進行預訓練的ViT-B_16 模型的權重對網絡進行訓練,將原始圖像大小調整為448×448 并對圖像進行分割,使其變為16×16 的像素塊。每個數據集的訓練周期設置為10 000。實驗采用隨機水平翻轉對圖像進行數據擴充。在訓練階段,使用隨機梯度下降(SGD)以0.9 的動量值來優化網絡,初始學習率設置為0.02,使用余弦退火對學習率進行有序調整。批處理大小設置為6。超參數K的值設置為12,超參數ζ設置為5。使用Pytorch 框架作為實驗平臺,通過APEX工具包以FP16 的數據格式加速訓練。本文使用單張NVIDIA TESLA T4 顯卡進行實驗。
3.2 實驗結果及對比分析
本文在CUB-200-2011 和Stanford Dogs 數據集上對DAVT 進行了消融研究,以分析所提出的方法對細粒度分類精度的影響。如表1 所示,通過使用層級注意力選擇(HAS),使模型在兩個數據集上的性能分別得到了1.1%和0.7%的提升,因為HAS 以各個層級之間的注意力權重作為引導,篩選出有判別性的標記并丟棄一些不重要的標記,迫使網絡從重要部分進行學習。通過引入數據增強模塊,使得模型再次提升了0.3%和0.5%的準確率,這是因為注意力裁剪后的圖像去除了部分背景噪聲。數據增強的方法在提高分類精度的同時引入了新的增強圖像,因此在訓練過程中隨著訓練數據的增加,參數量和分類時間都會不同程度地增大。

表1 CUB-200-2011 和Stanford Dogs 數據集下的消融研究
表2 展示了不同Transformer 層注意力圖引導的數據增強在CUB-200-2011 數據集上的效果。ζ表示以第幾個Transformer 層的注意力圖作為引導。由表2 可知,選擇第5 層注意力圖作為引導時效果最佳,隨著層數逐漸降低或升高效果均變差,因為層數偏低或偏高時,容易造成選擇的特征停留在低級或偏高級的局部區域。因此,選擇中間部分的Transformer 層提取注意力圖,以獲得較為均衡的特征信息。
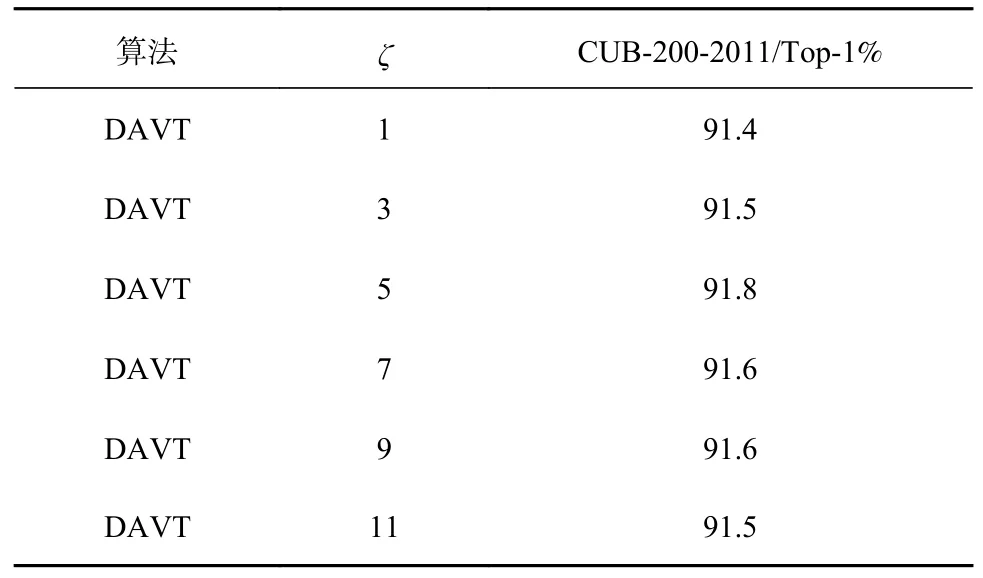
表2 CUB-200-2011 數據集下注意力提取層ζ 的消融實驗
如表3 所示,本文的方法在CUB-200-2011和Stanford Dogs 數據集上的性能優于所有以ViT和卷積神經網絡為底層網絡的方法。在CUB-200-2011 數據集上與迄今為止最佳算法相比,DAVT在Top-1%指標上實現了0.2%的提升,與原始框架ViT[5]相比,提高了1.4%。在Stanford Dogs 數據集上與迄今為止最佳結果相比,DAVT在Top-1%指標上實現了0.4%的提升,與原始框架ViT 相比,提高了1.6%。與其他主流的CNN 相比,DAVT在兩個數據集上的性能也有大幅提升。此外,為了探究不同類別樣本特征表示之間的距離對模型性能的影響,本文對比了模型在不同損失函數下的性能,如圖2 所示。
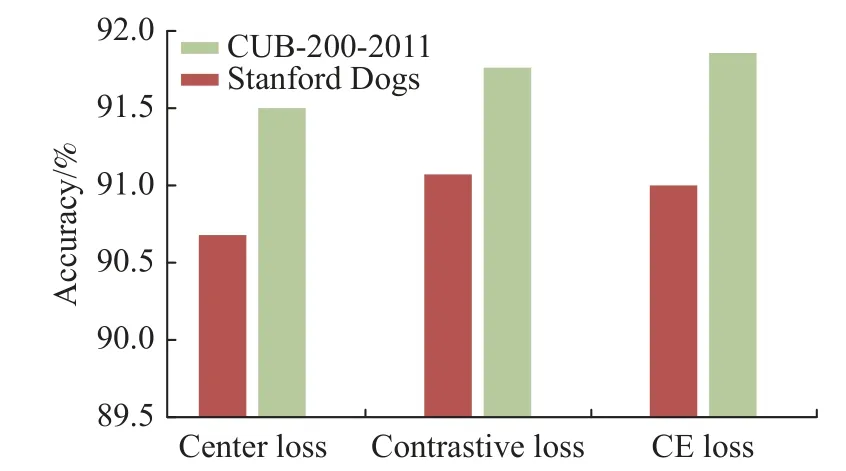
圖2 損失函數對比圖
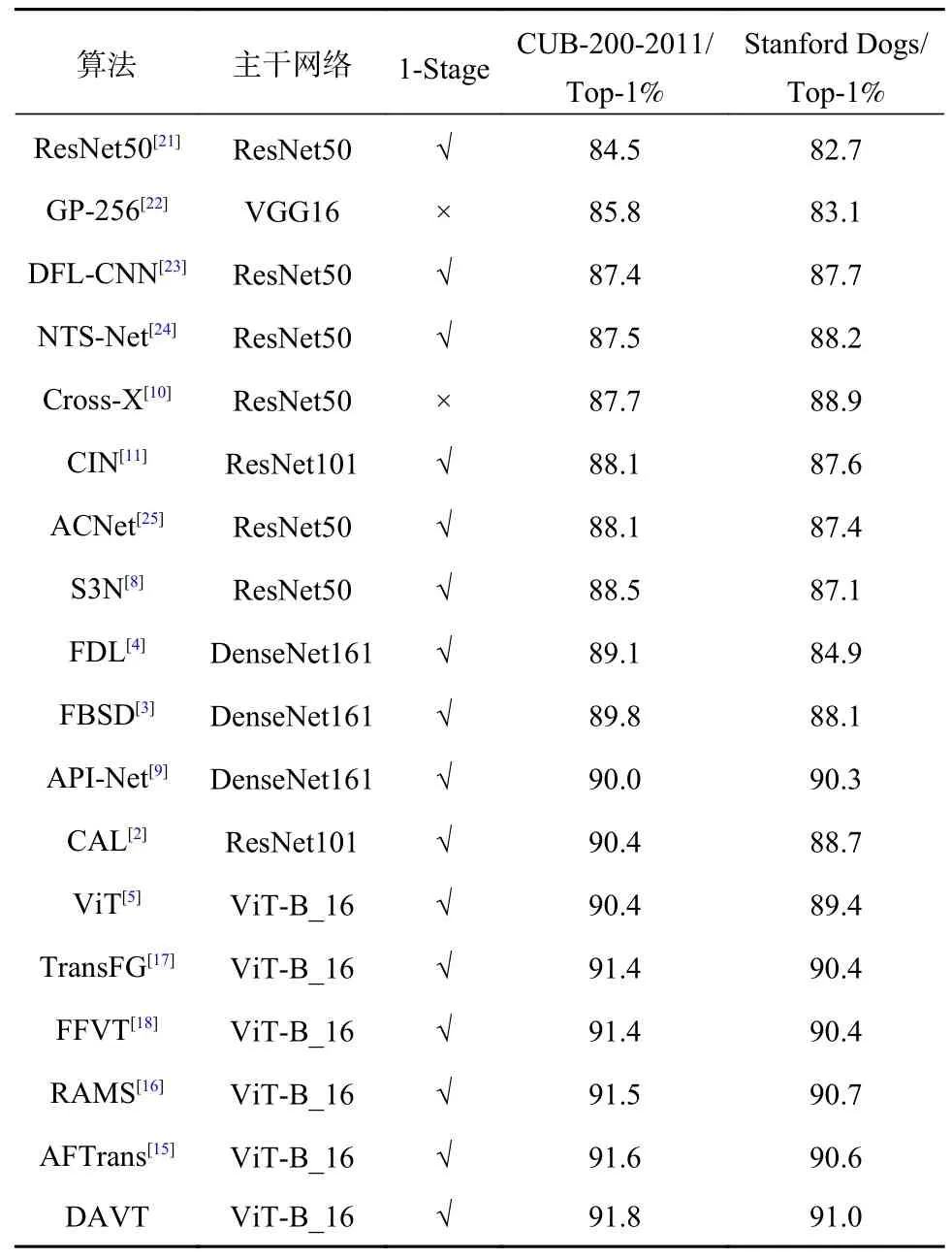
表3 CUB-200-2011 和Stanford Dogs 數據集下不同算法的比較
通過在兩個常見的FGVC 數據集上對模型進行評估,將本文方法與現有的Transformer 分類方法相比,DAVT 的性能優于現有的以ViT 模型為底層網絡的方法,如圖3 所示。
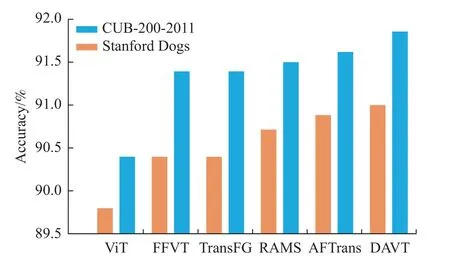
圖3 最先進算法的性能對比
圖4 為損失和準確率的變化曲線。橙色曲線表示損失和準確率的變化趨勢。曲線由Tensorboard生成,淺色部分代表真實數據的曲線。本文通過改變平滑系數獲得一條深色曲線,以更好地展示準確率和損失的變化。如圖4(a)和圖4(b)所示,所提方法在兩個數據集上的訓練損失都能穩步降低。由于使用預訓練ViT-B_16 模型的權重訓練網絡,測試精度在前2 000 個周期得到了快速的改善,如圖4(c)和圖4(d)所示。同時,測試精度曲線無下降趨勢,證明沒有擬合現象發生。
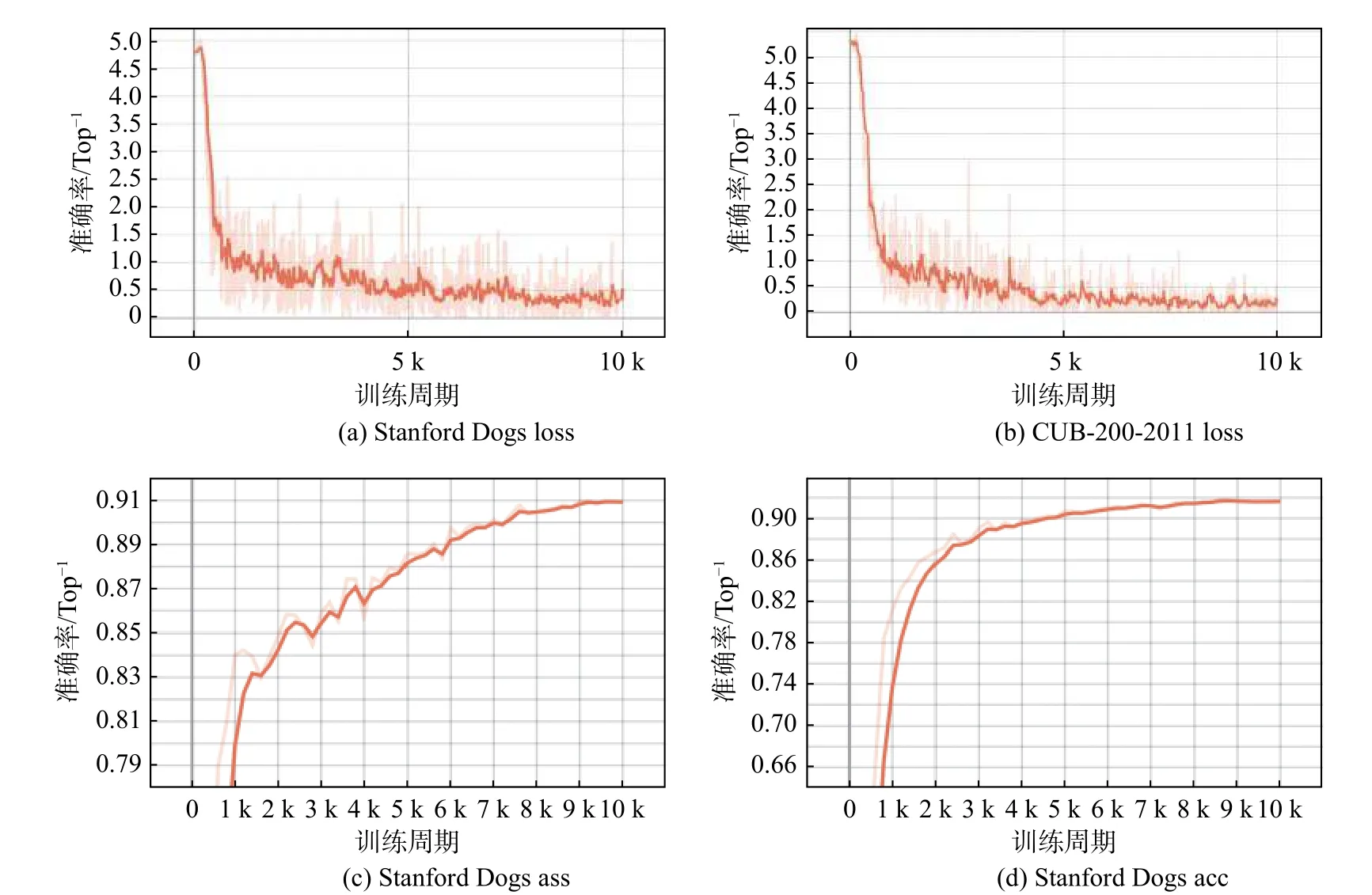
圖4 CUB-200-2011 和Stanford Dogs 數據集下的訓練損失和測試準確率
圖5 顯示了模型在兩個數據集上的可視化結果。具體來說,圖5 的第1 行展示了數據集的原始圖像。第2 行顯示了圖像的注意力圖,圖中重要區域的顏色通過淺色表示。圖5 的第3 行和第4 行顯示了數據增強后圖像。第4 行深色區域表示注意力裁剪的背景噪聲,如圖5 所示,注意力引導的圖像裁剪能夠去除絕大部分背景噪聲。第3 行顯示了裁剪后的圖像,并對物體的關鍵區域進行了放大,促使網絡提取更細微的局部特征。圖5 的第5 行顯示了模型定位的關鍵標記的位置,其中紅色方框代表注意力強調的特征區域,它由Visualizer可視化工具生成。如圖5 所示,在復雜的環境下DAVT 模型成功地捕捉到了物體的關鍵區域,即鳥類的頭部、翅膀和尾巴和狗的耳朵、眼睛、腿。

圖5 注意力可視化及數據增強的結果
4 結論
針對原始ViT 模型中輸入的像素塊引發背景噪聲和無法有效地提取層級間細微特征的問題。本文提出了層級注意力選擇和注意力引導的數據增強方法,減少了背景噪聲對網絡的干擾,迫使網絡學習層級間判別性的特征信息。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
