基于CEEMDAN-ABC-LSTM組合模型的短時交通流預測
2022-11-15 11:16:06沈富鑫邴其春張偉健胡嫣然
青島理工大學學報 2022年5期
沈富鑫,邴其春,*,張偉健,胡嫣然,高 鵬
(1.青島理工大學 機械與汽車工程學院,青島 266525;2. 青島市交通運輸公共服務中心,青島 266100)
隨著汽車保有量的增加以及人們對交通要求的不斷提高,交通擁堵、交通污染等問題正在嚴重影響著城市居民日常生活品質和出行時間。精準的短時交通流預測信息不僅可以幫助人們選擇合適的交通工具、縮短出行時間,而且也是實現主動交通管制的關鍵。國內外專家、學者經過近幾十年的研究構建出了一些預測模型,主要包括時間序列模型、卡爾曼濾波模型、支持向量回歸模型和組合模型[1-4]。
近年來,由于科學技術和計算機技術的進步,以數據驅動和深度學習的短時交通流預測方法受到了廣泛關注。數據處理方法通常用數據分解方法來提取交通流的特征,然后用神經網絡模型進行預測。例如,WEI等[5]在研究中將經驗模態分解(Empirical Mode Decomposition,EMD)和BP神經網絡原理結合,并證實了方法的有效性。譚滿春等[6]首先運用小波變換降低原始交通流數據中心的噪聲,然后構建了基于去噪數據集和混合交通流預測模型。張陽等[7]提出了小波包分析和LSTM神經網絡組合的交通流預測方法。YANG等[8]提出了一種基于EMD和疊加自動編碼模型的混合交通流多步預測方法,并證實了預測的可靠性。陸文琦等[9]將原始速度序列利用集成經驗模態分解算法進行分解,然后對分解后的序列進行處理,構建了行駛車輛速度預測模型。LI等[10]提出了集成經驗模態分解和隨機向量函數連接網絡的行程時間預測模型,該模型在多項誤差衡量指標方面均優于其他模型。谷遠利等[11]利用基于信息熵的灰色關聯分析提取空間特征變量,并用LSTM神經網絡和門限遞歸單元神經網絡組合預測不同時段車道的速度;王祥雪等[12]對深度學習理論進行研究,構建了LSTM-RNN的城市快速路交通預測模型,經過驗證該預測算法的精確性、實用性和擴展性均有提高。RUI等[13]將LSTM和GRU組合模型運用到交通流預測領域并證實了其預測性能。POLSON等[14]提出了一種深度學習結構來預測交通流,并證明了深度學習結構能夠捕捉非線性時空效應。朱永強等[15]將交通時間序列數據用互補集成經驗模態分解(CEEMD)進行多尺度分解,構建了CEEMD-LSSVM組合預測模型,該模型的平均誤差較小。
綜上算法雖然在交通流預測方面取得了較好的預測效果,但仍有許多方面需改進完善。如在交通流數據分解方面,存在模態混疊、適應性和穩定性較差等缺點。為了能夠獲取更加穩定的交通流分解數據,減少交通流原始數據對預測結果產生的干擾,獲取最佳模型參數值,本文提出了CEEMDAN-ABC-LSTM組合模型的短時交通流預測方法。
1 CEEMDAN理論
1.1 集成經驗分解
經驗模態分解(Empirical Mode Decomposition,EMD)由HUANG等[16]于1998年提出,它是一種自適應的分解方法,主要通過多次重復減去包絡的均值來消除震蕩。對于信號x(t),其經驗模態分解算法由以下步驟組成:
1) 使用三次樣條連接連續的局部最大值(各自的最小值)以導出上(或者下)包絡線。
2) 通過對上下包絡線求平均值,取得包絡中值m(t)。
3) 從原始序列中減去上述已求得包絡線的均值m(t)用以提取臨時本地震蕩h(t),得到h(t)=x(t)-m(t)。
4) 將得到的臨時本地震蕩h(t)多次重復計算步驟1)至3),直到滿足算法條件要求,如此形成的h(t)就為分解后得到的一個固有模態函數(Intrinsic Mode Functions, IMF),記為c(t)。
5) 計算殘余:r(t)=x(t)-c(t)。
6) 重復步驟1)至5)生成下一個IMF和殘差。
因此,可以通過一個公式對原始信號x(t)進行重建:
(1)
式中:ci(t)與IMF一致(即本地震蕩);rn(t)與第n個殘差一致。
1.2 CEEMDAN算法
自適應噪聲完全集成經驗模態分解(Complete Ensemble Empirical Mode Decomposition with Adaptive Noise,CEEMDAN)是以EMD理論為基礎,經過改進形成的一種新型自適應分解算法[17]。經過不斷創新,它不但克服了EMD算法產生的模態混疊現象,還通過添加自適應白噪聲對EEMD算法[18]進行改進,讓重構后的信號誤差降到最低。CEEMDAN算法實現步驟如下[19]:
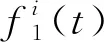
(2)
式中:ε0為在交通流序列中第一次添加白噪聲幅度值的系數;ωi(t)為在交通流序列中添加的白噪聲;N為交通流序列的長度。
2)可以得到第一個殘余信號:
(3)
3)將殘余信號r1(t)添加白噪聲ε1E1ωi(t)繼續分解,得到第二階的IMF分量,記為
(4)
4)按照以上計算模式,可以得到第j個殘余信號:
(5)
5)則第j+1階的IMF分量為
(6)
6)對步驟4)和5)進行多次重復運算直到分解結束以獲取最終的殘余分量:
(7)
2 模型構建
2.1 LSTM原理
長短時記憶(Long Short-Term Memory,LSTM)神經網絡,是由HOCHREITER等[20]首次提出的一種經過改進后的循環式神經網絡,可以有效地緩解循環式神經網絡所存在的梯度爆炸或者階段性梯度消失的缺陷。LSTM主要由神經網絡的輸入層、隱含層、輸出層三部分組成。與其他傳統循環式神經網絡不同的是,長短時記憶神經網絡通過在隱含層結構上增加記憶模塊,使信息達到較長一段時間的儲存和遺傳,結構如圖1所示。
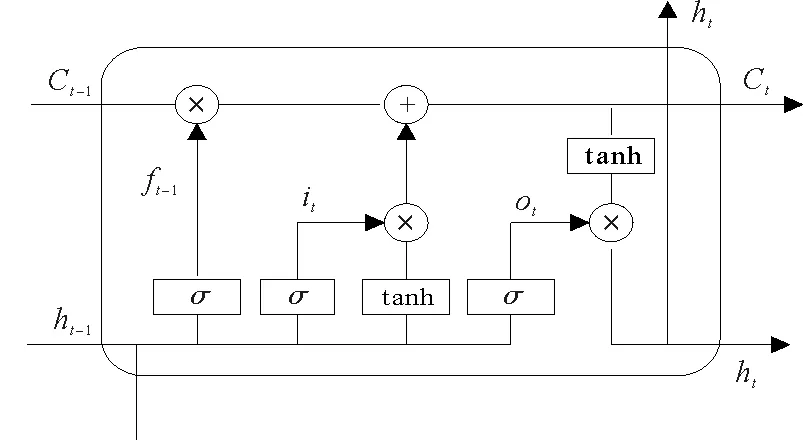
圖1 長短時記憶網絡結構
LSTM結構主要由遺忘門、輸入門、輸出門和記憶單元4部分構成,它也是一種鏈式結構,它們之間以一種特定的相互作用關系對信息進行過濾和保存。神經網絡中的遺忘門主要對來自上一時刻單元狀態的信息進行判斷,決定哪些信息應該被保留,哪些信息應該被遺棄。由前一隱藏神經元節點ht-1和當前t時刻輸入的信息xt經激活函數σ激活后,輸出門限層ft,其過程可表示為
ft=σ(Wfxt+UfCt-1+bf)
(8)
輸入門分別由sigmoid和tanh兩個激活函數,準備更新接下來的記憶單元狀態,其結構可表示為
it=σ(Wiht-1+Uixt+bi)
(9)
(10)
記憶單元狀態更新中的Ct由過去長期狀態和現在狀態決定。其中過去長時間的刻畫是由上一時刻單元狀態Ct-1元素與遺忘門輸出結果相乘體現,則Ct可表示為
(11)
輸出門主要由短期記憶結合當前輸入信息得到的信息ot和結合長期記憶最終輸出的ht兩部分構成,兩者表示為
ot=σ(Woht-1+Uoxt+bo)
(12)
ht=ot*tanh(Ct)
(13)
式(8)—(13)中:σ為sigmoid函數;*為兩個向量的乘積;Wf,Wi,Wo,Wc,Uf,Ui,Uo,Uc為訓練過程中得到的權重矩陣;bf,bi,bo,bc為訓練得到的偏移量。
2.2 基于人工蜂群算法的參數優化
在LSTM模型中,為了獲取最佳隱含層神經元數量、分塊尺寸、最大訓練周期以及學習率,采用人工蜂群算法對模型參數進行優化。人工蜂群算法(Artificial Bee Colony,ABC)[21]主要是根據自然界中蜜蜂日常采蜜行為提出來的一種仿生和優化算法。它也是目前比較新穎的一種全局優化算法,其優化步驟如下:
步驟1:初始化模型參數,設定雇傭蜂數量SN,食物源的最大循環次數LM,最大迭代次數MC,以及LSTM模型的隱含層神經元數量nHU、分塊尺寸mBS、最大訓練周期mE和學習率LR,然后隨機生成一個具有SN數量的初始種群。
步驟2:將均方根誤差(RMSE)作為適應度函數對前SN個食物源的適應度進行訓練。
步驟3:執行雇傭蜂和觀察蜂階段,限制參數尋優的范圍。
步驟4:偵察蜂階段,將相對較差的食物源丟棄獲取一個新的食物源。
步驟5: 對給定的結束條件進行判斷,如滿足該算法的結束終止條件,則可以輸出模型參數為最優解;反之,返回步驟3直到滿足條件。
人工蜂群算法優化流程如圖2所示。
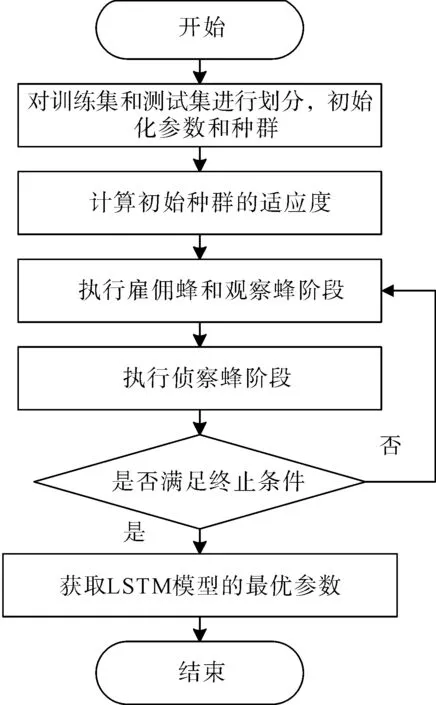
圖2 人工蜂群算法參數尋優流程
2.3 CEEMDAN-ABC-LSTM模型構建
在交通流預測建模過程中,首先利用CEEMDAN算法將交通流時間序列分解成若干個不同尺度的IMF分量和一個殘余分量,然后將分解數據輸入到用ABC優化完成的LSTM神經網絡中進行預測,具體流程如下:
步驟1:收集、整理實際獲取到的交通流時間序列數據。
步驟2:將處理好的原始交通流數據用CEEMDAN算法進行分解,得到若干不同的模態分量IMF和一個殘余分量R。
步驟3:對LSTM用人工蜂群算法進行參數優化,然后將分解后的模態分量和殘余分量分別建立LSTM預測模型。
步驟4:將各分量數據進行訓練預測,輸出各分量的預測值。
步驟5:疊加每個模態分量的預測值,輸出最終預測結果。
構建模型流程如圖3所示。
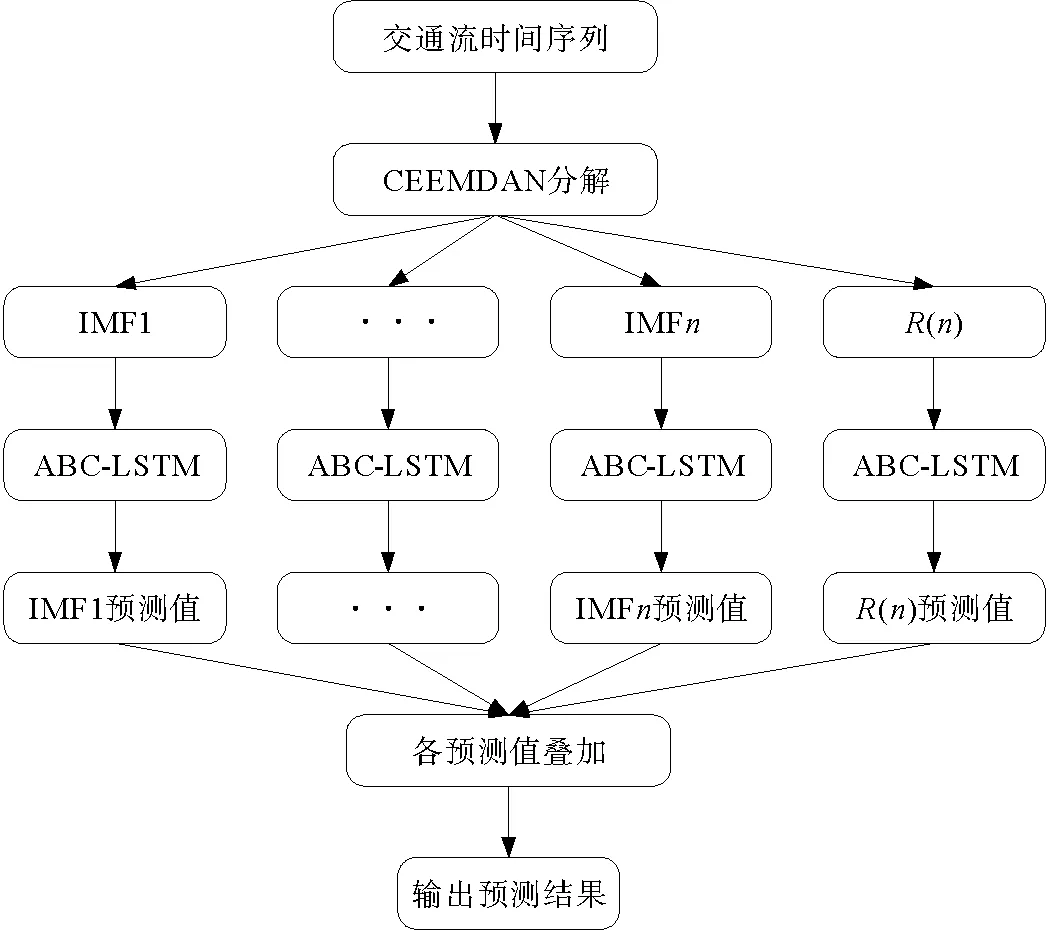
圖3 CEEMDAN-ABC-LSTM模型預測流程
將模型的輸入維數設置為6,數據訓練和輸出如圖4所示。
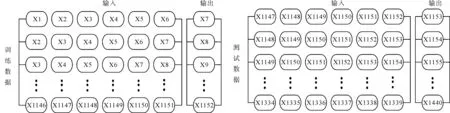
圖4 數據的輸入和輸出格式
3 實例驗證
3.1 數據來源
本文采集的數據來源于上海市南北高架路段感應線圈實測的交通流數據,數據采集的時間為2018年8月27日—8月31日。以每5 min一次的數據采集周期,共獲取1440個實際交通流數據。交通流量隨時間變化的折線如圖5所示。
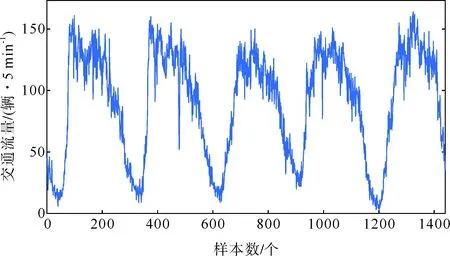
圖5 連續5天交通流量數據
3.2 CEEMDAN算法分解
運用CEEMDAN算法對原始交通流時間序列數據進行分解。白噪聲幅度值系數k設定為0.2,集成次數M設為500,根據算法的自適應分解性能,分解出10組不同尺度的IMF分量和1組殘余分量,如圖6所示。
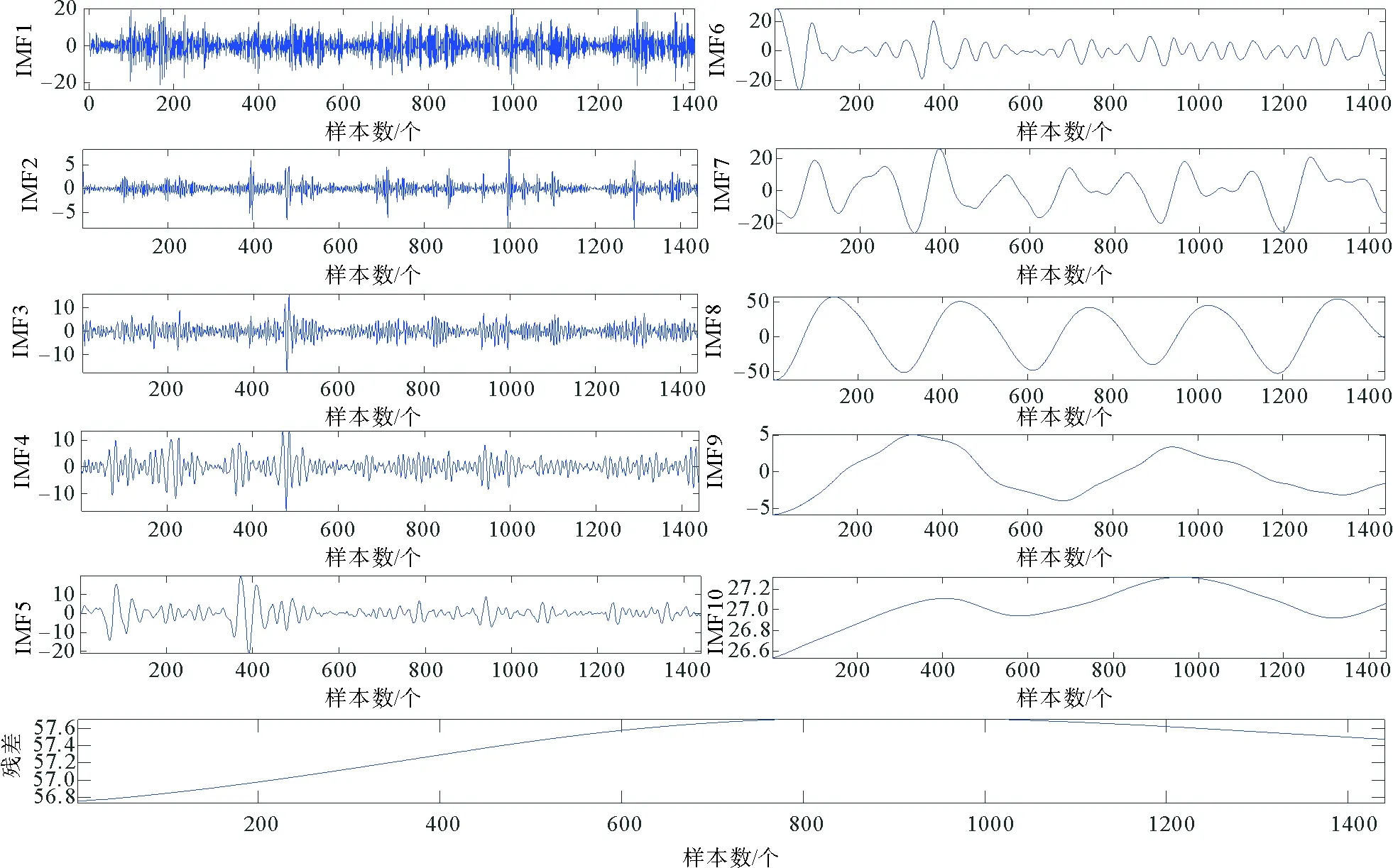
圖6 CEEMDAN交通流時間序列分解
3.3 人工蜂群算法參數優化
采用人工蜂群算法(ABC)對LSTM的參數進行二次尋優。
ABC參數設定如下:雇傭蜂數量SN設定為50,食物源最大循環次數LM設定為100,最大迭代次數MC設定為200;將前4天的數據作為訓練樣本訓練LSTM神經網絡,為了方便表示,用RMSE表示人工蜂群算法參數尋優的過程。
建立模型的最優參數如下:LSTM隱含層神經元數量nHU為240,分塊尺寸mBS為50,最大訓練周期mE為250,學習率LR為0.005。尋優結果如圖7所示。
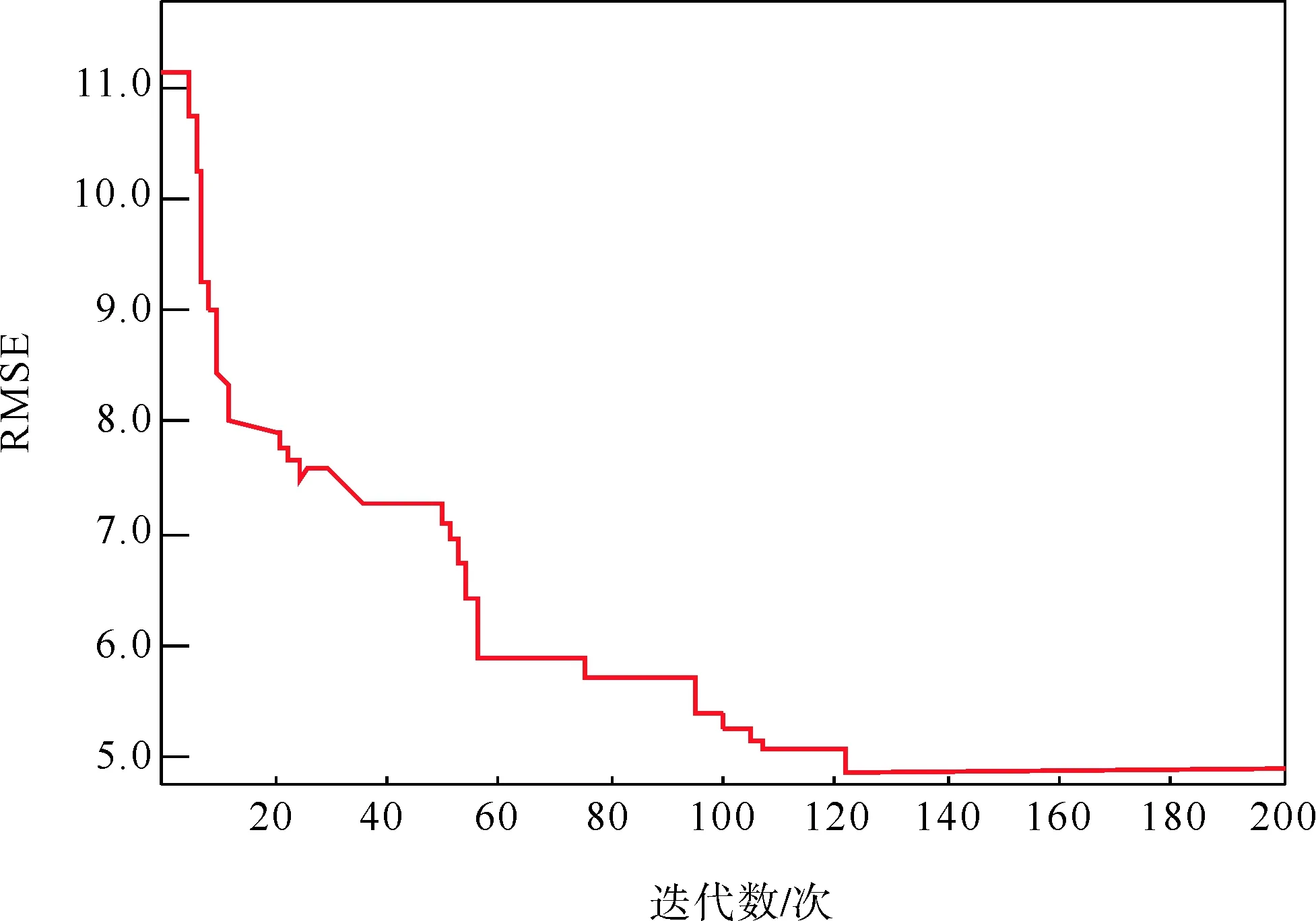
圖7 人工蜂群算法參數尋優的過程
3.4 實驗結果
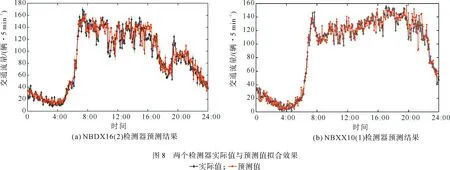
為了驗證所構建模型在短時交通流預測方面的精度,將NBDX16(2)和NBXX10(1)檢測器前4天采集的數據作為前期訓練樣本,用第5天實測數據作為測試樣本進行對比分析,其中NBDX,NBXX分別為南北高架東線、南北高架西線;16,10為檢測斷面編號;2,1為車道編號。實驗訓練所用的電腦配置為i7-9750HQ處理器,運行內存16 G。圖8為實測值與預測值的擬合效果,從圖中可以看出,本文構建的組合模型預測結果與實測數據相比具有較高的擬合度,證實了本文方法的有效性。
3.5 結果分析
選取LSTM,ABC-SVM,ABC-BPNN預測模型作為對比,模型參數設定如下:BPNN模型的隱層數為1,隱層神經元的個數為50,激勵函數為Sigmoid函數; SVM模型的懲罰因子λ=32,核函數參數γ=0.5。采用平均絕對誤差(MAE)、平均絕對百分比誤差(MAPE)和均方根誤差(RMSE)三個指標進行分析評價。
(14)
(15)
(16)
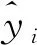
由表1、表2可以看出,本文方法的三個指標評價通過兩個檢測器驗證都有較好的效果。MAE值分別為5.92和5.63,MAPE值分別為7.85%和7.57%,RMSE值分別為6.34和6.25,較其他三種方法的平均預測精度分別提升了19.8%,25.6%和38.7%,說明本文構建的CEEMDAN-ABC-LSTM模型具有一定的自適應能力和較高的穩定性,再次證實了本文所建模型的優越性。
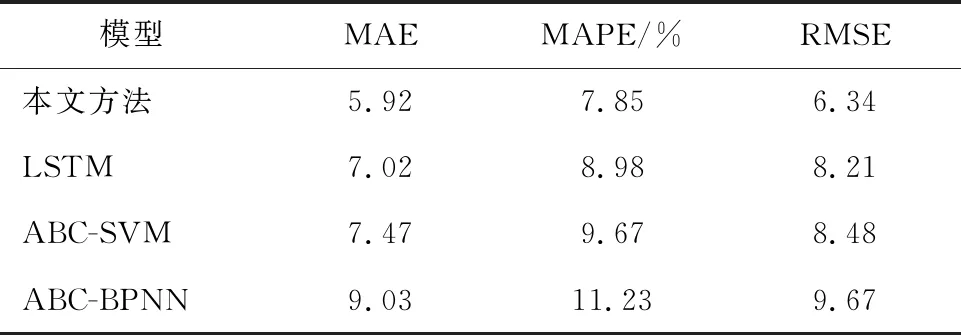
表1 NBDX16(2)檢測器4種模型預測誤差對比

表2 NBXX10(1)檢測器4種模型預測誤差對比
4 結論
為了進一步提高短時交通流預測的精度,本文將非平穩、非線性交通流時間序列運用CEEMDAN算法分解為相對平穩的若干個不同模態分量,構建了CEEMDAN-ABC-LSTM組合交通流預測模型。通過實測數據驗證,該模型表現出較好的預測性能,可以為以后交通流預測研究提供借鑒。但因現實交通系統較為復雜,受多種因素的干擾和影響,出行者也更加需要獲取在出行時間范圍內交通流的動態信息,因此單步的預測遠不能滿足人們出行要求,后續在本文基礎上,對不同時間尺度下交通流的多步預測進行更深層次的研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
廣西科技大學學報(2016年1期)2016-06-22 13:10:37
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
核科學與工程(2015年4期)2015-09-26 11:59:03
航空學報(2015年4期)2015-05-07 06:43:35
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
