顯著性時空特征融合的多視角步態識別算法
2022-11-25 04:38:38楊凱文李雙群胡星
現代計算機 2022年17期
楊凱文,李雙群,胡星
(1.中電長城圣非凡信息系統有限公司,北京 102209;2.中國電子信息產業集團有限公司第六研究所,北京 100083)
0 引言
行人步態是非常重要的生物特征之一,它具有遠程識別行人身份的唯一性能力,與人臉、虹膜、指紋等其他生物特征相比,步態具有下列顯著優勢:①可以通過遠程、非接觸的方式獲取;②難以模仿或偽裝;③即使在低質視頻中,仍然可以有效地獲取行人步態。近幾年來,視頻監控系統中的步態識別引起了研究人員的廣泛關注,研究成果可以應用于智慧邊防、倉庫安全管理、智慧安防、智能刑偵、身份識別等領域,這些具有挑戰性的應用在很大程度上依賴于步態識別準確率。
然而,準確的步態識別仍然面臨以下主要挑戰:①不同視角的步態匹配非常困難,但對于步態識別應用非常重要;②精確檢測步態周期困難大,步態序列的周期性運動線索和時間特性無法被有效利用。上述因素導致行人步態具有模糊的類間差異和較大的類內差異,部分示例[1]如圖1所示。
針對上述挑戰,為提升步態識別性能,研究者們提出了兩種類型步態識別方法:基于模型的步態識別方法和基于外觀的步態識別方法。基于模型的步態識別方法通過對人體四肢的運動進行建模,并從步態圖像中提取人體結構。例如:Lombardi等[2]通過計算光流場對步態序列中的兩點數據進行統計,并對行人肢體運動進行編碼,稱為兩點步態;李昱等[3]融合視覺和觸覺特征建立全身步態模型,并使用支持向量機進行分類完成步態識別;Goffredo等[4]應用人體比例測量方法對人員下肢姿勢進行建模,是一種獨立于拍攝視角的步態識別方法。然而,在低質監控視頻中,很難精確估計行人步態的運動模型參數。
基于外觀的步態識別方法主要從獲取的步態圖像序列中提取步態特征,即使在低分辨率視頻中也可以完成步態識別任務。例如:Muramatsu等[5]提 出 了 一 種 任 意 視 角 轉 換 模 型(AVTM),用于在任意視角下準確匹配行人的步態特征;官洪運等[6]利用HSV顏色特征和局部細節特征進行步態匹配;Wang等[7]提取每個步態圖像的輪廓,然后使用多通道映射函數將步態輪廓映射到相同的步態序列中,形成步態時序模板完成步態識別。
最近,基于深度學習的步態識別方法取得良好的識別結果,Zhang等[8]使用成對的步態能量圖(GEI)作為輸入,構建了孿生神經網絡學習步態序列的時空特征,在一定程度上提高了步態識別精度。由于GEI在計算過程中會損失步態大量的動態信息,GEI僅僅能夠表示步態的少量動態信息。LSTM網絡采用學習有用新信息并遺忘無用舊信息機制,可以有效捕獲視頻中的運動信息,Donahue等[9]提出了一種新的循環神經網絡架構,采用LSTM對可變長度視頻的復雜動態特性進行建模,應用于大規模視頻的視覺描述。為了獲取豐富的行人運動信息,Mahasseni等[10]提出一種正則化LSTM網絡架構,并使用視頻中行人的3D人體骨架序列進行訓練,應用于大規模視頻的行人動作識別。陳京榮[11]提出了一種結合姿態估計與Bi-LSTM網絡的人體跌倒檢測算法,用于檢測老年人跌倒事件的發生。
受上述研究工作的啟發,為了解決步態識別的挑戰性問題,本文設計了一個自動融合步態序列的框架,其顯著的空間和時間特征用于完成步態識別任務。首先,為了獲得步態的判別性外觀特征,利用步態圖像對VGG16網絡進行微調,并使用微調后模型提取行人步態圖像的空間特征表示步態外觀信息;其次,為了準確地捕捉行人步態的顯著周期性運動特征,設計了時序總結孿生LSTM神經網絡來自動學習步態序列的顯著周期性運動特征,其中LSTM單元用于對步態序列的周期性運動進行建模、時序加權總結模塊捕捉顯著的時序信息、孿生網絡架構解決步態識別中類別數量巨大而每個類別樣本數量很少的問題;最后,在OULP-C1V1-A步態數據集上對本文方法進行了實驗驗證,實驗結果表明本文方法在相同視角和交叉視角下都取得了良好的步態識別性能。
綜上所述,本文主要貢獻總結為:①設計了一種網絡架構,同時利用步態圖像序列的顯著性空間特征和時間特征進行相同視角和交叉視角下的步態識別;②提出了一種時序總結孿生LSTM神經網絡,自動學習步態圖像序列的顯著周期性運動特征;③探索了LSTM的層數、隱藏單元數量與步態識別準確率之間的關系,在OULP-C1V1-A步態數據集上綜合評價了本文方法在相同視角內和交叉視角間取得的良好識別性能。
1 時序總結孿生LSTM網絡
1.1 算法框架
圖2展示了本文提出的時序總結孿生LSTM網絡模型框架。首先,以步態圖像序列對作為輸入,步態圖像序列通過微調的VGG16網絡提取每個圖像的空間特征;接著,將步態圖像的空間特征輸入LSTM單元,學習步態序列中與時序相關的特征集;最后,提出了一個時序總結層,用于為不同的時間步輸出分配不同的權重,生成步態序列周期性運動線索的序列級特征,用于完成步態識別任務。
1.2 步態空間特征提取
本文選擇VGG16網絡學習步態圖像的空間特征,由于預訓練的VGG16模型采用ImageNet作為訓練數據,不能直接應用于步態識別。因此,將預訓練VGG16模型在步態數據集上進行微調,將其遷移到步態圖像領域。微調解決方案:將fc8層的輸出參數設置為步態圖像類別數目,微調預訓練VGG16模型中的所有層參數。微調后VGG16模型能夠捕捉到步態圖像更為豐富的空間特征。給定一個步態序列處理單元S={s1,…,st,…sT},其中st是時間步t的步態圖像、T為步態序列處理單元S的長度,利用微調后VGG16模型提取步態序列處理單元S的空間特征向量集X={x1,…,xt,…xT}。
1.3 步態周期特征提取
LSTM是一種特殊的循環神經網絡,通過記憶單元模塊調節特定的相關信息與其周圍環境信息之間的相互作用,有目的地保留特定相關信息,可以捕捉視頻序列中的長期時間動態信息,增強序列時序信息的判別能力。行人步態周期是區分不同行人的重要特征,因此本文采用LSTM神經網絡對行人步態的周期性運動進行建模,并提取更具判別特性的周期性運動特征表示步態周期,提高行人步態識別性能。
LSTM記憶單元由四個主要部分組成:一個輸入門、一個具有自循環連接的神經元、一個遺忘門和一個輸出門。輸入門根據輸入數據更新記憶單元的狀態或阻塞更新,自循環連接確保記憶單元的狀態具有1個時間步延遲的反饋,遺忘門允許記憶單元通過調整其自循環連接來記住或忘記其先前的狀態,輸出門允許記憶單元的狀態對其他神經元產生影響或阻止影響。總之,LSTM記憶單元允許神經網絡學習何時忘記先前的隱藏狀態以及何時更新隱藏狀態以保留新的相關信息。
接下來,將步態序列處理單元S的空間特征向量集X輸入LSTM模塊,學習步態序列的周期性時序信息。對于時間步t,xt和ht分別為輸入向量,Wx為輸入權重矩陣,Wh為循環權重矩陣,b為偏置向量。Sigmoid函數是一個元素級非線性激活函數,它將實數輸入映射到(0,1)范圍內。雙曲正切函數?(x)=也是一個元素級非線性激活函數,它將輸入映射到(-1,1)范圍內。運算符⊙表示元素級相乘運算。給定輸入xt,ht-1和ct-1,LSTM單元時間步t的更新方程可表示為:
從公式(1)~(6)可以看出,每個時間步都會得到一個隱藏單元ht∈?N。一個LSTM單元由輸入門it∈?N、遺忘門ft∈?N、輸出門ot∈?N、輸入調節門gt∈?N和記憶單元ct∈?N組成。記憶單元ct是ct-1記憶部分和被調節后it的總和。LSTM單元中的ft和gt被視為選擇性地忘記其先前記憶和考慮當前輸入的旋鈕,ot用于學習記憶單元中的哪些信息需要轉移到隱藏單元中。最后,得到步態序列處理單元S的隱藏狀態集H={h1,…,ht,…hT},它表示步態序列S長期的時序信息,即周期性運動信息。
1.4 步態時序信息加權總結
盡管LSTM能夠捕獲到步態序列的時序信息,但它更偏重于使用后面時間步的輸出信息,這會降低步態識別性能,因為前面時間步的輸出也會包含一些有用的時序信息。為了解決這個問題,本文設計了一個時序信息加權總結(WTS)模塊,提供了一種加權解決方案來聚合總結所有時間步的信息,從而捕捉到具有強區分能力的時序特征。WTS模塊生成的步態特征向量V可形式化為:
其中T表示步態序列的時間步數(長度)、ht是LSTM在時間步t的輸出。
1.5 孿生LSTM網絡
在步態識別領域,樣本數據具有以下特點:類別數量非常多且模型訓練階段無法確定,而每個類別的樣本數量非常少。孿生架構網絡可以從訓練數據中應用判別學習技術來學習相似度度量模型,不需要特定的樣本類別信息,它包含兩個結構相同且權重共享的子網,將輸入對象映射到低維目標空間中進行相似性度量。因此,孿生架構網絡適合解決步態識別問題,本文設計了一個孿生LSTM網絡用于學習步態序列的周期性運動特征,如圖2所示。由于孿生LSTM網絡目標空間的維數較低,能夠從每個類別的少量樣本中學習不同步態序列之間的強區分性特征。
1.5.1 網絡輸入
孿生LSTM網絡以步態序列對作為輸入,將每個步態序列映射為一個特征向量,然后進行相似性度量。對于訓練集中的所有步態序列,本文隨機選擇兩個屬于同一類別的步態序列構成正訓練對、隨機選擇兩個屬于不同類別的序列構成負訓練對。給定一個步態序列訓練對(Si,Sj),Y∈[ 0,1]為訓練對的標簽,Y=1表示Si和Sj屬于同一個身份,Y=0表示它們屬于不同的身份。
如圖2所示,步態序列訓練對(Si,Sj)分別輸入微調后VGG16模型提取步態序列的空間特征向量集Xi和Xj,接著它們分別被輸入兩個并行的LSTM子網絡學習得到兩個步態序列的隱藏狀態集Hi和Hj,最后根據公式(7)分別對Hi和Hj進行加權總結,得到兩個步態序列的特征向量Vi和Vj。
1.5.2 對比損失函數
對于步態識別任務,需要學習一個非線性函數將步態序列映射到低維空間中的點,使正訓練對盡可能接近、而負訓練對盡可能遠離,且至少大于一個最小距離間隔。因此,本文采用對比損失層連接兩個LSTM子網絡。
對于步態序列的特征向量Vi和Vj,距離度量方法可表示為:
對比損失目標函數可形式化表示為:
其中正數m為不同類別步態序列之間的最小距離間隔。
1.5.3 網絡訓練
本文將步態識別視為一個二分類問題,訓練數據包括步態序列對和標簽。在訓練階段,采用權重共享機制同時優化兩個LSTM子網絡,成對的步態序列分別輸入兩個LSTM子網絡,通過對比損失層計算對比損失并反向傳播來訓練孿生LSTM網絡模型。
由于步態序列的正訓練對數量要遠遠少于負訓練對,可能會帶來數據不平衡和過擬合問題。為了避免這些問題,在訓練過程中隨機丟棄LSTM層的50%神經元輸出,LSTM層保留神經元的輸出傳遞到后續層,隨著對訓練數據的多輪迭代,模型被訓練達到收斂狀態,訓練結束。
1.5.4 網絡測試
在測試過程中,舍棄了孿生架構和對比損失函數,使用孿生LSTM網絡中的一條分支(即微調的VGG16模型和LSTM子網絡部分)作為特征提取器,提取參考集合和查詢集合中步態序列的外觀和周期性運動特征。在聯合步態序列的外觀和周期性運動特征時,先對它們執行歸一化操作再進行特征融合。
2 實驗結果與分析
2.1 數據集和評價準則
2.1.1 數據集
使用OULP-C1V1-A步態數據集評估本文方法的性能,它是一個規模大、覆蓋范圍廣的步態識別基準數據集,包含3836名行人對象、年齡覆蓋范圍為1歲到94歲。每個行人對象包括兩類步態序列:參考序列和查詢序列。步態序列由行人剪影圖像構成,這些圖像被歸一化為128×88個像素。參考集合和查詢集合中的行人對象分別根據觀察視角分為五個子集,即55°、65°、75°、85°和所有角度。在實驗中,使用參考集合進行訓練,查詢集合沒有參與訓練。
2.1.2 評價準則
由于OULP-C1V1-A步態數據集中的每個查詢序列都有對應的多個交叉視角參考序列,因此采用MAP來評價所提方法的性能。MAP用于計算所有查詢步態序列的識別精度,定義如下:
其中Q表示查詢集,mj表示查詢序列j對應的參考步態序列數量,Precision (Rjk)表示查詢序列j對應參考序列k的平均識別精度(AP)。
除此之外,本文還采用累積匹配曲線(CMC)來計算Rank-1和Rank-5,分別表示所有查詢正確的參考序列排名在第一和前五的百分比,它們也是廣泛應用于評估步態識別性能的方法。
2.2 實驗設置
為了客觀評價所提方法,基于訓練數據對損失函數的負訓練對最小距離間隔、LSTM隱藏單元數量、LSTM層數進行了調整。首先,調整孿生架構網絡中對比損失函數的負樣本最小距離間隔m。當m=1時,驗證性能最好;當m=0.5或m=1.5時,驗證性能沒有明顯變化;但是當m<0.5或m>1.5時,驗證性能明顯下降。因此,后續實驗評價過程中設置m為1。
其次,對LSTM隱藏單元數量進行了實驗嘗試,以揭示隱藏單元數量對LSTM學習能力的影響。由于數據集中行人類別數量大(3836個行人)和行人步態圖像差異性小,實驗中嘗試使用與之匹配的LSTM隱藏單元數量進行驗證,即分別使用了1024、2048、3096和5120隱藏單元數量。隨著LSTM隱藏單元數量的增大,步態識別準確率也得到了持續的提升,當隱藏單元大小達到5120時,識別準確率無法獲得進一步的提升。因此,后續實驗評價過程中LSTM隱藏單元數量設置為5120。
最后,對LSTM層數進行了實驗驗證嘗試,分別嘗試了1、2和4層LSTM網絡結構,驗證結果表明1層LSTM在OULP-C1V1-A步態數據集上識別性能最好。因此,后續實驗評價過程中LSTM層數設置為1。
2.3 時序加權總結性能驗證與分析
實驗過程中,需要將步態序列的LSTM所有時間步輸出融合為單個特征向量完成步態識別,除了使用所提出的步態時序信息加權總結(WTS)融合方法之外,還使用了平均池化(Mean-pooling)和最大池化(Max-pooling)來融合LSTM所有時間步的輸出。具體地說,平均池化方法認為LSTM所有時間步輸出同等重要,而最大池化方法使用LSTM所有時間步輸出的最大激活值作為特征向量。在OULP-C1V1-A步態數據集上,基于本文設計的孿生LSTM網絡結構使用時序加權總結、平均池化、最大池化分別進行了訓練和測試,對比分析了它們各自的步態識別性能。如表1和表2所示,WTS比Meanpooling和Max-pooling方法取得了更好的步態識別性能,驗證結果表明WTS方法可以更好地捕捉到步態序列的周期性運動線索。
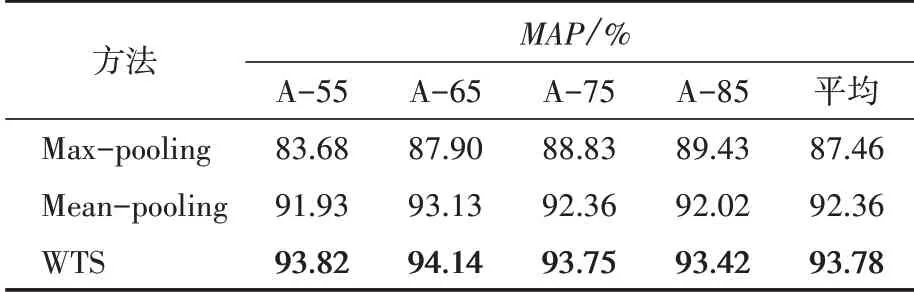
表1 不同融合方法基于MAP評價準則的識別性能比較
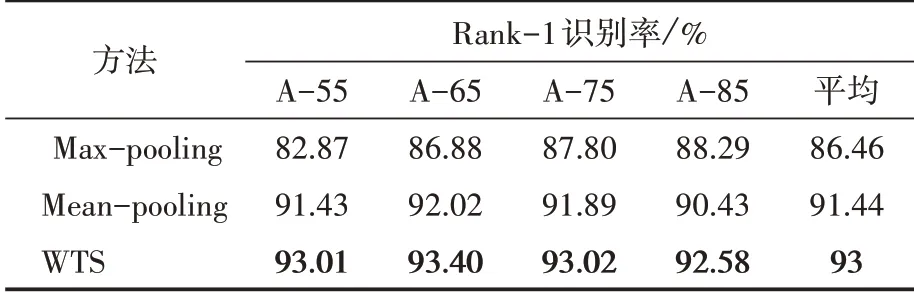
表2 不同融合方法基于Rank-1識別率評價準則的識別性能比較
2.4 相同視角下的步態識別性能評價分析
首先,在相同視圖下評價本文方法,與GEI[1]、FDF[1]、woVTM[5]、CNN[8]、SiaNet[8]等方法的識別性能進行比較,性能對比結果如表3所示。本文方法在55°、65°、75°、85°視角下的識別性能優于其他對比方法,獲得了最好的步態識別準確率。與現有傳統方法(即GEI、FDF、woVTM)相比,本文方法能夠捕獲到步態圖像的區分性外觀特征和更加豐富的行人運動信息,而大多數傳統方法使用GEI表示行人步態的運動信息,會導致大量有用運動信息丟失,本文方法步態識別性能獲得了顯著的提高。與現有基于深度學習的方法(即CNN和SiaNet)相比,本文方法通過使用孿生LSTM架構學習步態序列的顯著周期性運動信息,而現有基于深度學習的方法使用GEI作為訓練數據,只能捕捉到少量運動信息,本文方法獲得了最好的步態識別性能。
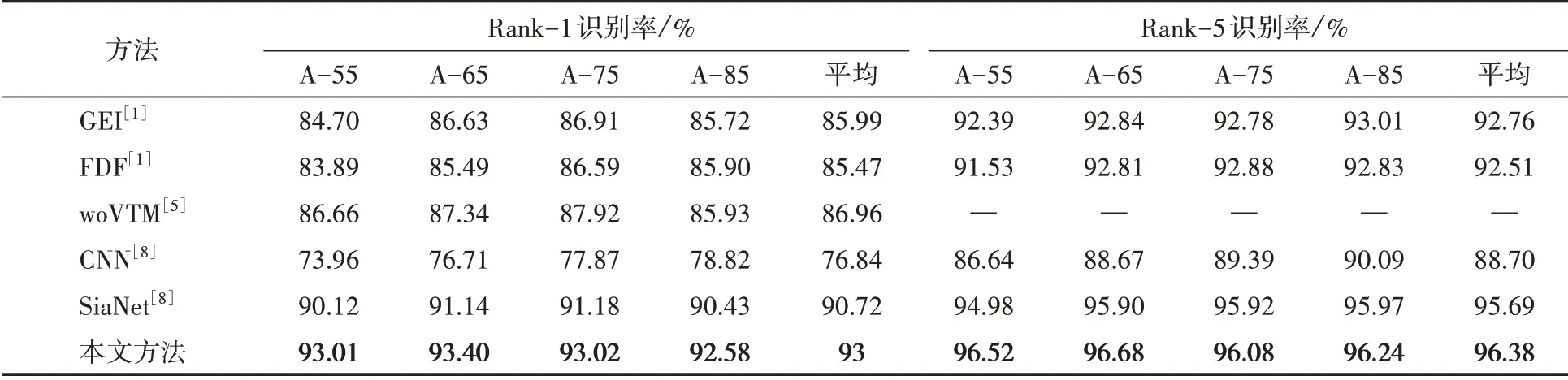
表3 不同步態識別方法在相同視角下的Rank-1和Rank-5識別率對比結果
2.5 交叉視角下的步態識別性能評價分析
實際應用場景的步態序列經常受到攝像機拍攝視角變化的影響,因此在交叉視角下對本文方法的識別性能進行評價,與woVTM[5]、AVTM[5]、AVTM_PdVS[5]、SiaNet[8]等方法進行對比分析,性能對比結果如表4所示。前三種方法通過構建3D步態序列專門用于跨視角步態匹配,SiaNet方法使用孿生神經網絡捕捉步態序列的外觀特征。本文方法同時考慮步態外觀的視角差異和顯著周期性運動信息,獲得了最好的步態識別性能。當視角差異較大時,本文方法的識別性能也會略有下降。
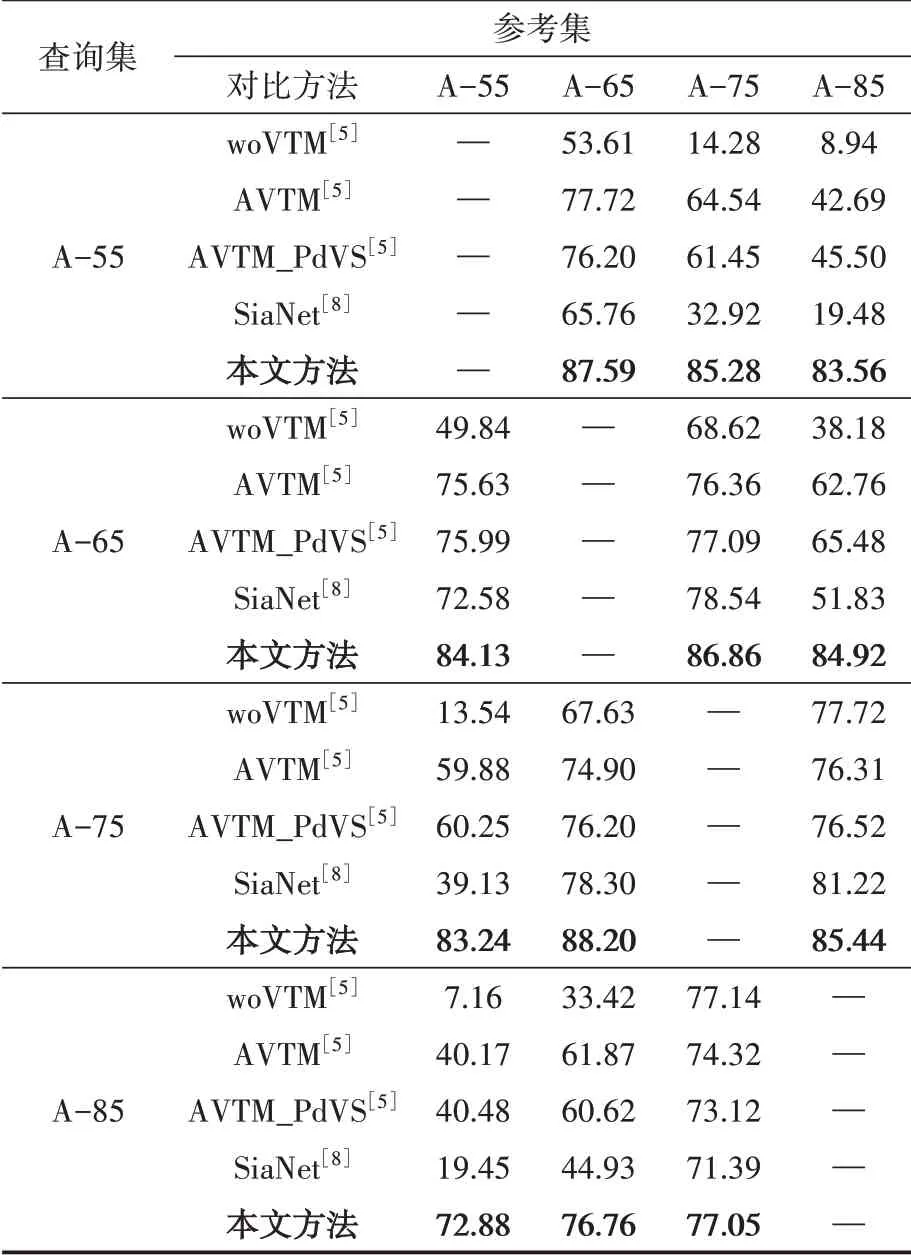
表4 不同步態識別方法在交叉視角下的Rank-1識別率對比結果
3 結語
本文設計了一個孿生LSTM神經網絡架構,自動學習多視角步態序列的周期性運動特征,設計了步態時序信息加權總結模塊提取步態序列的顯著性時序信息,最后融合多視角步態序列的區分性外觀特征和顯著周期性運動特征,完成步態識別任務。實驗結果表明,本文方法在相同視角和交叉視角步態識別方面都取得了良好的識別性能。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
