一種用于大數據內容安全監測的快速相似匹配并行算法
2022-11-25 04:38:42王曉霞孫德才
現代計算機 2022年17期
王曉霞,孫德才
(渤海大學信息科學與技術學院,錦州 121013)
0 引言
隨著互聯網的高速發展,人們可以利用各種新媒體工具在網絡上發表自己的觀點,由此也使一些話題迅速成為網絡焦點話題。面對數量龐大的網絡言論,網絡信息安全監測領域的研究需要引入海量大數據分析技術[1]。大數據信息安全是為適應大數據時代的輿情和服務而發展起來的,是專注于海量信息采集、監測和分析等技術的一個新的研究領域。
如何從巨大的數據集中快速找出滿足要求的信息,是信息安全監測研究中需要解決的一個基本問題。在大數據清洗中,為去除相似信息,常采用相似連接[2-6]技術。當前的相似連接算法主要有單機算法和并行算法。單機算法因單節點計算能力有限導致其橫向擴展能力不強,并行算法因其運行在分布式集群的多節點上,橫向擴展能力較強,漸漸成為一種主流技術。MapReduce框架是一種高效的分布式編程框架,基于MapReduce框架的相似連接并行算法[4-10]在大數據處理中被廣泛采用。它的主要研究內容包括V-SMART-Join[7]、PassJoinKMR[8]、Mass-Join[9]、SAX[10]和FS-Join[11]等。
大數據內容安全監測的快速相似匹配并行算法是大數據處理中的熱點問題,對應出現了很多先進的算法,MassJoin算法是一個支持多數據集的相似連接算法,能快速找出文本集間編輯距離[8]滿足要求的文本對,算法分為四個階段:統計階段、過濾階段、驗證階段1和驗證階段2。然而該算法在匹配速度上稍顯不足。
本文將改進MassJoin算法[9]中的過濾和匹配技術,并提出一種新的基于MapReduce框架的并行算法MQSM(MapReduce and Q-gram based Similarity Match),擬解決信息安全監測中的快速相似匹配問題。
1 內容相似匹配及新過濾方案
1.1 基于內容的相似匹配的問題定義
基于內容的相似匹配是從一個已知的文本集中找出與給定查詢集中匹配度達到要求的所有文本,匹配度定義如下:
定義1給定兩個文本s和d,稱s為查詢串,d為文本串,兩串間的q元匹配度定義為
式(1)中,simq(s,d)為兩串間的q元匹配度,|s|為串長,[s]q為文本s拆分得到的連續且重疊q-1個字符的q-gram[12]的總數目(q-gram是一個長度為q的子串),即[s]q=|s|-q+1,Sq(s,d)為文本s拆分得到的[s]q個q-gram在文本d中出現的個數,Cq(s,d)為s的[s]q個q-gram構 成 的 子串在d中匹配到的最長子串長度。當q=1時為字符級別的匹配度,當q>1時為多元匹配度。在該匹配度公式中,前半部分描述的是q-gram的覆蓋情況,后半部分描述的是q-gram的連續情況。如:s為“thirty”,d為“thirsty”和q=2,則|s|=6,[s]2=5,Sq(s,d)=4,Cq(s,d)=4(th,hi,ir三個連續且重疊q-gram構成的子串為最長匹配子串),最終sim(2“thirty”“,thirsty”)=0.73。這里的匹配度不同于編輯距離[7],編輯距離描述的是兩個串間的近似情況,而本文的匹配度描述的是一個串在另外一個串中匹配的情況。
在內容信息安全監測系統中,給定一個查詢集和一個大文本集,系統要在大文本集中快速發現與查詢集中匹配度達到要求的文本,這里查詢集通常是一個由關鍵詞(詞或句子)構成的集合。設某個查詢總共有N個關鍵詞,則此時公式(1)中
定義2基于內容的相似匹配問題:給定查詢集Q、大文本集D和q元匹配度參數τ,基于內容的相似匹配問題是在Q和D間找出所有滿足simq(si,dj)≥τ,si∈Q,dj∈D的所有匹配對。
如給定查詢集Q和文本集D如表1,在每個集合中“#”號前面的是查詢編號或文本編號,后 面 的 是 內 容。如τ=0.9,q=2,則sim2(s1,d1)=1≥0.9是 一 個 匹 配 對;而sim2(s2,d2)=0.85<0.9,則不是匹配對。

表1 查詢集和文本集例子
1.2 基于內容的相似匹配過濾方案
因給定的大文本集D中含有大量的文本串,查詢集Q中也有一定數量的查詢串,因此潛在串對是海量的。而計算所有可能串對的匹配度需要花費大量的時間,因此本文擬采用過濾器先過濾掉那些不滿足要求的串對,然后再對通過過濾的候選對進行計算。為實現快速過濾,新算法提出了一種基于分割子串的過濾方案。
定理1給定查詢串s、文本串d和q元匹配度參數τ。設串s中共有N個關鍵詞,把每個關鍵詞si都分割成||si-q+1個連續且重疊的長度為q的q-gram,設文本d中含有這[s]q個q-gram中 的Sq(s,d)個,此時如則一定有simq(s,d)<τ,即s,d一定不是匹配對。
證明:設因N≥1,q-1≥0則因文本d共享了Sq(s,d)個q-gram,則能構成的最長匹配子串長度和不超過Sq(s),d+N(q-1),即Cq(s,d)≤Sq(s,d)+N(q-1),則即
2 MQSM相似匹配算法
給定查詢集Q、大文本集D和匹配度參數τ,相似匹配算法需要快速找出滿足匹配度要求的查詢/文本對。本文提出的新算法MQSM采用MapReduce框架來實現相似匹配的并行計算,算法包括三個階段:配對階段、過濾階段和驗證階段。每個階段又包括Map過程、Shuffle過程和Reduce過程。其中Shuffle過程會將Map過程中生成的所有鍵/值對按鍵值進行混淆、排序,并把具有相同鍵的鍵/值對送到同一個Reduce節點,作為Reduce過程的輸入,以后各階段中的Shuffle過程因原理相同不再描述。MapReduce是一個分布式編程框,因此程序在集群中運行時各數據節點會開啟眾多的Map任務和Reduce任務進行并行計算。
2.1 配對階段
由1.2節可知,定理1是一個無關對過濾條件,使用定理1能拋棄那些共享q-gram數目達不到要求的查詢/文本對。為方便地使用定理1進行快速過濾,需要對輸入的查詢和文本進行字符串分隔,然后才能根據查詢串和文本串間共享子串的情況進行過濾。
2.1.1 Map過程
每個Map任務處理的數據是一個鍵/值對n,c,其中n是數據分片號(內容的偏移量),而數值c則是查詢集Q或文本集D中的一行內容。此時需根據內容來源不同進行分別處理。為進行相似匹配,新算法針對內容c生成索引子串或匹配子串,具體過程如下。
生成匹配子串:如分片來源于查詢集Q,從內容c中提取出查詢編號sid和查詢內容s(“#”分隔)。因為查詢s是一個關鍵詞(詞或句子)集合,首先提取出所有關鍵詞。為使每個關鍵詞都能在容忍一定量錯誤的情況下匹配到文本集中的文本,需把每個關鍵詞都拆分成連續且重疊q-1個字符的q-gram。設sji表示關鍵詞si第j個q-gram,0≤j<|si|-q+1,則輸出一個作為匹配子串的鍵/值對,即
生成索引子串:如分片來源于文本集D,則提取c中文本編號did和文本內容d。為使查詢中拆分得到的q-gram能夠匹配到該文本,新算法把d也拆分成連續且重疊的q-gram,設dk表示d的第k個q-gram,0≤k<|d|-q+1,則輸出一個索引子串的鍵/值對,即
2.1.2 Reduce過程
每個Reduce任務將處理Shuffle結果中的一個鍵/值對,即
2.2 過濾階段
配對階段的輸出結果是所有候選對的集合,由大量的鍵/值對
2.2.1 Map過程
因該階段的輸入來源是配對階段的輸出結果和文本集Q,這里根據來源分別進行處理。如鍵/值對
2.2.2 Reduce過程
每個Reduce過程的輸入是Shuffle過程輸出的一個鍵/值對,即其中sid鍵為查詢編號。新算法先遍歷值列表list(list(did)/(#s))內的所有項,如該項以‘#’開頭,則該項是查詢的內容,內容保存到s中;否則,該項是與該查詢候選的文本編號列表list(did),則循環list(did)中的每個did,并把各文本的q-gram命中數組H[did]增1,直到list(list(did)/(#s))處理完畢。此時發現如list(list(did)/(#s))中無文本did,則該查詢無匹配;否則,先拆分查詢內容s并統計關鍵詞總數tn、查詢總長tl,然后檢查命中數組中每個H[did]。
2.3 驗證階段
驗證階段的主要任務是計算每個候選對的真實匹配度,并輸出達到要求的真實匹配對。過濾階段結束后輸出了所有候選對,此時候選對已有查詢串內容但缺少文本串的內容。因此驗證階段除需要讀取過濾階段的輸出結果外,還需要讀取文本集D。
2.3.1 Map過程
每個map任務的輸入是鍵/值對
2.3.2 Reduce過程
每個Reduce任務處理的是一個鍵/值對,即
3 實驗分析
3.1 實驗配置及環境
本文采用Java語言在Hadoop平臺上實現了新算法MQSM。為對比集群分布式算法和單機算法的性能差別,實驗中還實現了一個單機多線程算法,記為MTSM。本實驗的數據來源于Sogou實驗室的Sogou新聞語料庫(http://www.sogou.com/labs/),處理后的文本集和查詢集詳情見表2。本次實驗中配置的Hadoop集群環境共包括5個節點,其中主節點1個;節點硬件條件為8 G內存+處理器i5 4590。MTSM算法設置線程數為4,運行在單一節點上。因中文的特殊性,一般單字不具含義,而兩字以上的詞才有意義,因此后面實驗中都設置q=2。
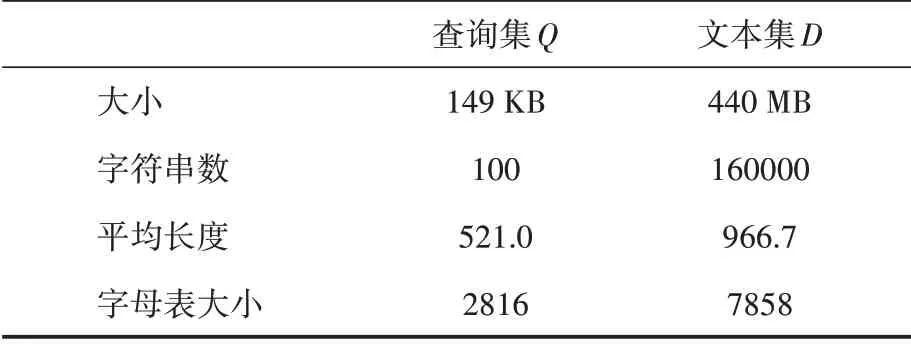
表2 實驗數據集信息
3.2 實驗結果分析
評價一個算法的優劣主要有兩方面指標,一是時間消耗,二是空間消耗,顯然在相似匹配算法中匹配速度更重要。給定不同大小的文本集,算法的匹配速度則不同。為衡量文本集大小對算法匹配速度的影響,本次實驗中使用參數配置q=2,τ=0.7,查詢集如表2所示,文本集中字符串數目分別為40000、80000、120000和160000。參與實驗的算法包括分布式集群算法MQSM和單節點多線程算法MTSM。實驗結果對比如圖1所示。
由圖1可知,MTSM算法在文本集較小時的匹配速度要快于MQSM算法。但隨著文本集的不斷增大,MQSM算法的并行優勢不斷提高,最后匹配速度超過了MTSM算法。這主要是因為MTSM算法是一個單機內存多線程算法,隨著文本集的增大處理能力逐漸不足,而新算法MQSM是一個基于MapReduce框架設計并運行在多節點集群上的并行算法,更適合大數據集的處理。從圖1中曲線的變化趨勢可知,MQSM算法和MTSM算法的匹配時間與測試文本集的大小總體上呈線性關系。
匹配度參數變化對算法性能的影響稱為算法的敏感度。為測得新算法MQSM對匹配度的敏感度,在文本集(160000條)上分別采用不同的匹配度參數(τ=0.7,0.8,0.9,1.0和q=2)進行了相關實驗,隨著匹配度參數的變化,新算法的性能表現如圖2所示。
由圖2可知,匹配度參數的變化對MQSM算法的影響不大。隨著匹配度的增大,算法的匹配速度稍有提高。這是因為算法的主要時間花費在配對階段和過濾階段,而匹配的驗證階段因結果較少而消耗時間較少。因MQSM算法中的配對階段和過濾階段受匹配度的影響較小,所以當匹配度增大,過濾條件變嚴,輸出候選對相對少些,只是稍微減少了一點驗證時間。因此,MQSM算法對匹配度的變化敏感度較小,較適合匹配度變化范圍較大的應用場景。
4 結語
本文研究的主要內容是用于大數據內容安全監測的相似匹配技術。文中先給出了相似匹配相關問題的定義。為能在算法中快速過濾掉那些一定不存在真實匹配的無關對,文中總結出了基于q-gram命中數特征的候選對過濾定理。最后提出并實現了一種用于大數據內容安全監測的快速相似匹配并行算法。文中通過實驗證明本文提出的新算法,利用字符串分割和過濾技術加快了相似匹配的速度。作者將繼續研究更加苛刻的過濾條件和非連續的q-gram拆分等技術,擬通過減少配對階段子串的輸出量來降低算法的配對時間和過濾時間。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
科學大眾(2022年11期)2022-06-21 09:20:52
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
臺聲(2016年2期)2016-09-16 01:06:53
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
