基于深度神經網絡優化網絡學習的社會創業研究
2022-11-25 04:38:42吳嘉鑫
現代計算機 2022年17期
吳嘉鑫
(新南威爾士大學創業創新系,澳洲 悉尼 2052)
0 引言
創業創新實踐因新興技術的驅動而產生了重大變化,越來越多的創業創新研究開始基于數字化的背景下[1]。但在中國情境下,對于現代計算機科學與創業創新實踐結合的研究還處于發展階段,尤其是對社會企業的研究,國內學者更多關注于數字化下的農民工返鄉創業、弱勢群體創業以及使命漂移等普遍社會問題[2],而忽略了對于學校內部信息化創新這一重要社會問題。然而學校對于培養人才,積蓄社會創業創新力量有著本質的影響,因此,更高效的師生網絡學習系統能更長遠地提高學生能力,對培養高質量創業創新人才有著重要意義[3]。基于此,本研究將利用深度神經網絡去提高師生網絡學習,從而實現對學校的社會貢獻。
近幾年,深度神經網絡在計算機視覺和自然語言處理等多個領域都表現出了最先進的性能。最新的研究表明[4],深度神經網絡可以深入處理數據,并且深度神經網絡可能具有更大的容量并實現更高的精度。然而,一個具有許多參數的深度網絡在訓練和測試時都需要大量的計算,由于對計算資源的要求很高,所以很難應用于實際場景。這個問題促使人們對神經網絡的壓縮進行研究。
Hinton等[5]首先提出了知識提煉(KD)這個概念,他們使用教師網絡的軟化輸出,將信息轉化為小型學生網絡。通過這種教學程序,小網絡可以學習大網絡如何以壓縮的形式研究給定任務。Romero等[6]介紹了FitNet,它不僅使用教師網絡的最終輸出,而且還使用教師網絡的中間隱藏層值來訓練學生網絡。通過使用這些中間層,可以改善學生網絡的性能。與Fit-Net不同的是,Zagoruyko等[7]提出了注意力遷移(Attention Transfer)的方法去轉移完整的注意力圖。最近,Yim等[8]使用FSP矩陣將知識從教師網絡轉移到學生網絡。FSP矩陣是由兩層的特征之間的內積計算出來的,包括如何“解決問題”的知識。
更值得關注的是,Zeiler等[9]介紹了一種可視化技術,讓人們了解中間特征層的功能。它揭示了這些特征遠遠不是隨機的、無法解釋的模式。相反,它們顯示了許多直觀的理想屬性,如構成性、增加的不變性和類別的區分。以前與特征相關的知識轉移工作只關注整個特征圖。例如,FitNet直接計算特征圖的二級損耗[6];AT轉移特征的摘要[7];不同層次的特征圖的內積得到轉移[8]。而所有這些方法都忽略了特征之間的關系。所以在Zeiler等[9]的啟發下,我們發現不應該只關注特征圖的值,而應該更加關注特征之間的關系。
因此,為了在這些特征之間傳遞知識,我們引入了流形學習。流形學習將數據集視為高維空間中非線性流形的嵌入。它的目的是將位于高維空間的非線性流形上的數據集進行低維參數化。流形學習已經成功地應用于許多領域,如人臉識別等。它包含幾種方法,如Isomap[10],
Locally Linear Embedding(LLE)[11],Laplacian Eigenmaps(LE)[12]和Local Preserving projection(LPP)[13]。局部保留投影(LPP)是一種流形學習方法,它保留了樣本的局部關系[13]。本文利用“局部保留投影”的思想,將教師網絡的知識轉移到學生網絡。
本文將深度網絡的輸入視為高維空間的流形,因為特征可以很好地表示輸入,并具有許多直觀的特性[9]。因此,我們認為從深度網絡中提取的隱藏層的特征是位于輸入流形上的重要點。對于同樣的輸入,利用“局部保留投影”的思想,從教師網絡和學生網絡中提取的特征應該位于相似的流形上,為此我們引入了一種新的LPP損失,以確保教師和學生網絡之間特征的局部相似性,并在此基礎上將教師網絡和學生網絡的特征之間的關系知識進行了轉移。
本論文的貢獻如下:①提供了一個關于知識轉移問題的新觀點,并提出了一種新的網絡壓縮方法;②通過實驗表明,本文方法在幾個數據集上提供了明顯的改進;③研究表明,本文方法可以與其他知識轉移方法相結合,并達到最佳性能。
1 理論基礎與文獻回顧
1.1 知識轉移
深度神經網絡在計算機視覺任務中表現良好。深度神經網絡的能力通常取決于網絡的深度和寬度。然而,一個具有許多參數的深度網絡很難在應用中使用,因為它需要大量的計算資源。學生網絡的參數很少,Hinton等[5]首創的知識轉移(Knowledge Transfer)旨在通過依賴從強大的教師網絡中借用的知識來改善學生網絡的訓練。它使用教師網絡最終輸出的軟化版本,稱為軟化目標,將信息傳授給一個小網絡。通過這個程序,學生網絡可以從教師網絡中學習并達到更好的準確性。Romero等[6]介紹了FitNet,將寬而淺的網絡壓縮為薄和深的網絡。
FitNet不僅使用軟化的輸出,還使用教師網絡的中間隱藏層值來訓練學生網絡。在第一階段,FitNet與教師網絡和學生網絡的隱藏層輸出相匹配;在第二階段,它使用軟化的輸出(知識提煉KD)來匹配最終輸出。通過匹配隱藏層,學生網絡可以從教師網絡學習額外的信息。Zagoruyko等[7]提出了注意力遷移(Attention Transfer,AT)。與FitNet不同的是,AT傳輸的是隱藏層的全部激活,而注意力圖則是全部激活的總結。Yim等[8]使用的FSP矩陣包含了網絡的解決過程的信息。通過匹配學生網絡和教師網絡之間的FSP矩陣,學生網絡可以從教師網絡學習如何“解決問題”。
1.2 流形學習
Isomap[10]是一種流形學習算法,它通過返回點之間的距離近似于最短路徑距離的嵌入,保留了輸入集的幾何特征。局部線性嵌入(LLE)[11]試圖通過將每個輸入點重建為其鄰居的加權組合來局部表示流形。拉普拉斯特征圖(LE)[12]建立了一個包含數據集的鄰域信息的圖。利用圖的拉普拉斯概念,LE計算出數據集的低維表示,在某種意義上最佳地保留了本地鄰域信息。局部保留投影(LPP)[13]則是通過解決一個變分問題來制作線性投影圖,該投影圖以最佳方式保留了數據集的鄰域結構。
2 研究方法
2.1 目標
本文方法旨在將教師網絡中的特征關系轉移到學生網絡中。對于一個輸入圖像x,教師網絡計算輸入并在中間層獲得特征。最后,網絡結合這些特征得到輸出。在其他學者的研究里,知識提煉(KD)[5]是通過匹配教師和學生網絡進行軟輸出;FitNet[6]是通過二級損失(L2 loss)直接匹配特征圖;AT[7]轉移注意力圖。然而所有這些方法都忽略了特征之間的關系。因此,本文認為特征是流形的重要點,它代表了輸入圖像。對于相同的輸入圖像,學生和教師網絡應該提取類似的特征。因此,他們的流形中的特征應該是相似的。本文方法使用局部保留損失(LPP loss)來衡量他們的特征圖之間的相似性。
2.2 局部保留投影(LPP)
LPP[13]是一種流形學習方法。它的目的是找到一個能最佳地保留數據集的鄰域結構的映射。假設給定一個集合{x1,x2,…,xm∈Rn},而y1,y2,…,ym是一個目標地圖集合,那么LPP的標準是選擇一個好的地圖,即最小化以下函數:
在合適的條件約束下,如果相鄰的點xi和xj被映射得很遠,那么選擇Wij的目標函數會產生嚴重的懲罰。因此,最小化可以確保當xi和xj接近時,那么yi和yj也是接近的。
2.3 局部保留損耗(LPP loss)
LPP[13]是一種保存樣本局部關系的流形學習方法。本文引入局部保留方法去保持教師網絡和學生網絡的流形相似性,具體來說,讓FS∈Rh×w×m表示由選定的匹配層生成的學生網絡的特征圖和{f1S,f2S,…,f mS∈Rh×w}表 示特征圖的特征,其中h,w和m代表高度、寬度 和 通 道 數。分 別 來 說,FT∈Rh'×w'×m和{f1T,f2T,…,f mT∈Rh'×w'}表示特征圖和教師網絡中選定層的特征。其基本思想是保留教師網絡中的特征與學生網絡中的特征一樣的局部關系。為了實現這一目標,本文定義了以下的局部保留損失:
其中,參數αi,j描述了由教師網絡的選定層產生的特征之間的局部關系。定義αi,j的方式如下:
N(i)表示第i個特征f iT的k個最近的鄰居特征與δ是標準化常數。WS表示學生網絡的權重,L(W,x)表示標準交叉熵損失。那么可以定義以下總損失:
2.4 局部保留損耗(LPP loss)的反向傳播
Llpp相對于f iS的梯度計算如下:
兩個網絡的權重是通過Llpp的導數反向傳播來微調的:
3 實驗與討論
在兩個數據集CIFAR-10和CIFAR-100[14]上評估本文方法。在所有的實驗設置中,使用Resnet-34[4]作為教師網絡,Resnet-18作為學生網絡。我們稍微修改了網絡的結構以適應數據集。CIFAR-10和CIFAR-100數據集包括50K訓練圖像和10K測試圖像,分別有10個和100個類別。對于數據增強,我們在訓練中從零填充的40×40圖像中隨機抽取32×32的裁剪或其翻轉一下。對于教師網絡,本文使用了在ImageNet LSVRC 2012中預訓練的模型[15],并采用隨機梯度下降法(SGD)對網絡進行優化,迷你批次大小為256。SGD的權重衰減為105,動量為0.9。對網絡進行了130次歷時訓練。初始學習率被設置為0.05,然后在10、60、90和105個歷時中分別除以10。將本文方法與KD[5]、FitNet[6]和AT[7]進行比較。將ResNet轉移的知識(KD)溫度提高到4,并按照Hinton的研究方法使用α=0.9。對于FitNet,在第一階段,我們訓練了90個歷時,學習率最初為1e-4;然后,在10和60個歷時中,它被改為1e-5。對于注意力遷移(AT),按照Zagoruyko的研究方法,將λ值設置為103除以注意力圖中的元素數和匹配層的批量大小。對于本文得LPP損失,我們將λ值設置為10除以特征圖中的元素數、匹配層的批處理量和通道數,并將k(近鄰數)的數量設置為5。對于以上所有的方法,本文對教師網絡和學生網絡的第二卷積組的輸出進行匹配。實驗結果見表1。包括KD、FitNet和LPP在內的所有的方法都比原始學生網絡的錯誤率低。KD[5]使用軟化標簽來提高學生網絡的準確性。Fitnet[6]不僅使用了像KD那樣的軟化輸出,還使用了教師網絡的中間隱藏層值來訓練學生網絡,并取得了比KD更高的準確性。本文方法,即LPP,在兩個數據集中與知識提煉(KD+LPP)相結合時,顯示出對學生網絡的明顯改善,并取得了比KD和FitNet更高的準確性。
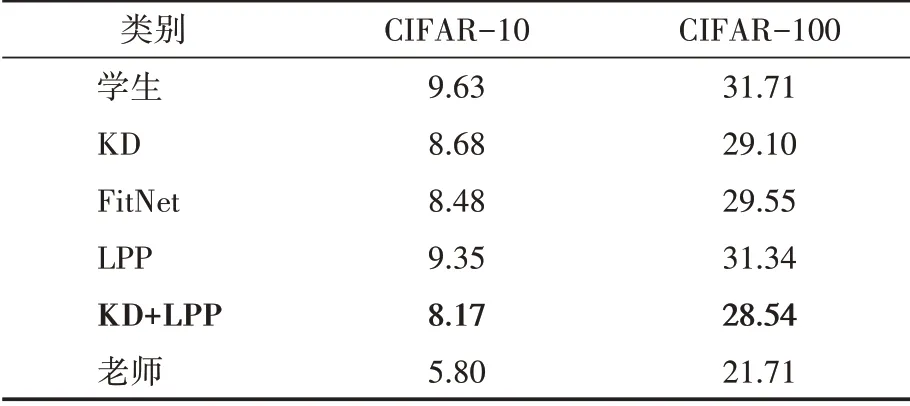
表1 不同轉移方法出錯率的CIFAR結果
注意力遷移(AT)是一種知識提煉方法,它取得了比KD和FitNet更高的準確性。表2顯示了本文方法和AT的結果。對于AT,按照Zagoruyko的規定,λ值被設定為103除以注意力圖中的元素數和匹配層的批處理大小。為了保證識別精度的公平比較,我們在教師網絡和學生網絡的第二卷積組之間轉移相同的AT和LPP的損失。當單獨使用AT損失和LPP損失時,LPP損失實現了更高的準確性。當把AT和LPP損失與KD結合起來時,AT損失實現了更高的準確性。在所有的方法中,AT+LPP+KD的組合達到了最好的性能。
如表2所示,本文的LPP方法在知識提煉方面有了顯著的改進。具體來說,提高了學生網絡的性能約1.46%和3.17%,并分別減少了15%和10%的相對誤差。在與AT相結合的情況下,學生網絡的性能提高了2.01%和3.72%,相對誤差分別降低了21%和12%。結果表明,本文方法成功地優化了教師網絡特征之間的關系。盡管FitNet[6]與完全激活的功能圖相比,AT[7]轉移了完整的注意力圖,但忽略了特征之間的關系。本文方法考慮了特征之間的關系,忽略了注意力圖的具體值。因此,我們將LPP損耗與AT損耗相結合,在所有方法中獲得了最高的精度。
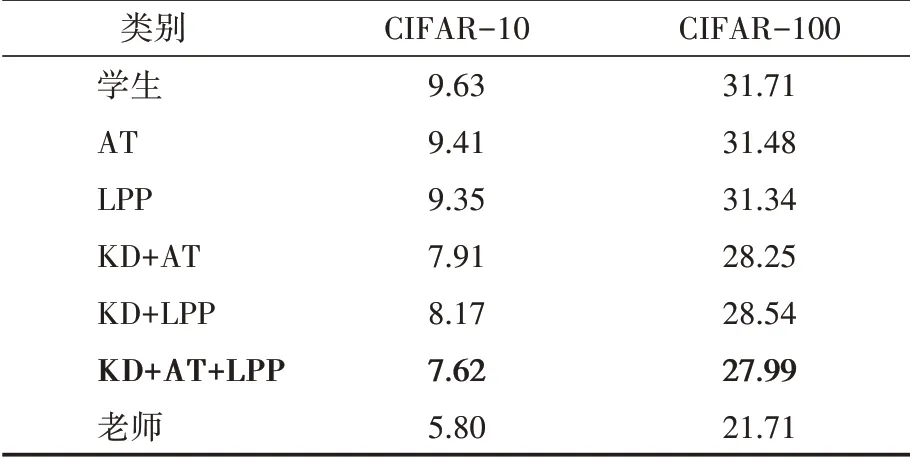
表2 LPP和AT的CIFAR結果
4 結語
本文提出了一種新的知識轉移損耗(LPP loss),將其作為一個流形學習問題。我們將深度神經網絡提取的特征視為流形中的導入點,可以代表輸入圖像,通過使用所提出的局部保留損失,學生網絡可以在教師網絡中學習特征的流形結構。本文在CIFAR-10和CIFAR-100中驗證了該方法的有效性。結果表明,本文方法在知識提煉方面有明顯的改進。通過將LPP損失與現有方法相結合,使得所提出的方法優于最先進的知識轉移方法。
本研究為現代計算機知識與管理學科創業創新研究的交叉融合做出了貢獻,拓寬了對于社會企業創業研究的邊界和方向,給出了社會企業去實現社會價值時不僅僅局限于慈善、社會企業責任等方面,還可以考慮為國家教育做出貢獻的新思路。同時,本研究也展現了現代計算機知識對于實現社會價值,提高教育效能的巨大潛力。未來的研究方向可以考慮嘗試通過新的網絡學習系統去減少管理學科收集問卷的復雜度,提高效率,從而實現進一步的社會價值。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
