RFC-Net:基于殘差結(jié)構(gòu)的動(dòng)作質(zhì)量評(píng)估網(wǎng)絡(luò)
2022-11-25 02:56:10周嫻瑋陳瑋濤李振豐余松森
計(jì)算機(jī)技術(shù)與發(fā)展 2022年11期
周嫻瑋,賴 堅(jiān),陳瑋濤,阮 樂(lè),李振豐,余松森
(華南師范大學(xué) 軟件學(xué)院,廣東 佛山 528010)
0 引 言
人類運(yùn)動(dòng)動(dòng)作質(zhì)量評(píng)估(Action Quality Assessment,AQA)指的是評(píng)估一個(gè)特定動(dòng)作的執(zhí)行情況,為該動(dòng)作進(jìn)行打分。動(dòng)作質(zhì)量評(píng)估在現(xiàn)實(shí)中具有巨大的應(yīng)用價(jià)值,如運(yùn)用在體育視頻分析[1-6]、外科醫(yī)生手術(shù)訓(xùn)練[7-8],以及其他的一些技能評(píng)估中[9-10]。
動(dòng)作質(zhì)量評(píng)估相較于人類動(dòng)作識(shí)別(Human Action Recognition,HAR)更具有挑戰(zhàn)性,因?yàn)镠AR是識(shí)別不同類別的動(dòng)作,其動(dòng)作之間差別較大,然而在AQA領(lǐng)域中,處理對(duì)象基本上都是同一類別下的動(dòng)作,其動(dòng)作間的差別較為細(xì)微,難以區(qū)別。目前絕大部分的運(yùn)動(dòng),其中運(yùn)動(dòng)員比賽的評(píng)分(如跳水[11]、滑冰[12]等),都是由相關(guān)領(lǐng)域的專家評(píng)委根據(jù)運(yùn)動(dòng)員的表現(xiàn)給出相應(yīng)的分?jǐn)?shù)。在現(xiàn)實(shí)生活中,一名合格的專家評(píng)委是非常稀少的,因?yàn)樗麄儽仨毥?jīng)過(guò)長(zhǎng)期的訓(xùn)練才能熟悉所有特定的動(dòng)作,因此用自動(dòng)評(píng)分系統(tǒng)取代教練評(píng)分是未來(lái)的一種趨勢(shì),另一方面,自動(dòng)評(píng)分系統(tǒng)某種程度來(lái)說(shuō)比較公平公正能夠避免評(píng)分丑聞。
近幾年里在AQA領(lǐng)域提出了許多方法[13-15]試圖解決分?jǐn)?shù)預(yù)測(cè)問(wèn)題,文獻(xiàn)[16]通過(guò)對(duì)視頻中的運(yùn)動(dòng)員進(jìn)行追蹤,只提取視頻中運(yùn)動(dòng)員有關(guān)的特征。這種方法雖然一定程度上降低了背景因素的干擾,但是對(duì)于跳水運(yùn)動(dòng)而言,水花濺起的大小和高度,也是決定最后分?jǐn)?shù)的關(guān)鍵因素,因此不根據(jù)運(yùn)動(dòng)特性而去除背景因素是不太合理的。文獻(xiàn)[17]通過(guò)對(duì)比學(xué)習(xí)進(jìn)行分?jǐn)?shù)預(yù)測(cè),在數(shù)據(jù)集中挑選部分視頻作為范例視頻,然后通過(guò)學(xué)習(xí)范例視頻與輸入視頻之間的相似性來(lái)預(yù)測(cè)輸入視頻最終的評(píng)分。這類方法學(xué)習(xí)的相似度,通常會(huì)存在較大的誤差,并且需要人工選擇范例視頻,這在某種程度上增加了預(yù)測(cè)的復(fù)雜度。文獻(xiàn)[11,18-20]中的方法都是通過(guò)端到端之間的模型進(jìn)行分?jǐn)?shù)預(yù)測(cè)。在此類方法中,文獻(xiàn)[11]通過(guò)增加卷積層的數(shù)量加強(qiáng)特征提取的效果,但是卷積層數(shù)的增加,會(huì)導(dǎo)致網(wǎng)絡(luò)出現(xiàn)了退化,有效特征丟失。文獻(xiàn)[21]使用LSTM作為特征聚合器,LSTM在卷積的頂層只能獲取高層次的動(dòng)作而不能獲取關(guān)鍵的低層次動(dòng)作,作為特征聚合器不能起到一個(gè)很好的效果。
現(xiàn)有的方法不能有效地執(zhí)行特征聚合,在AQA任務(wù)中需要一種簡(jiǎn)單、有效的特征聚合機(jī)制。為解決上述問(wèn)題,該文提出了一種端到端的RFC-Net(Residual Full Connection Network)模型用于預(yù)測(cè)視頻的分?jǐn)?shù)。AQA模型由特征提取器和特征聚合器兩個(gè)部分組成,特征提取器是用于視頻特征提取的網(wǎng)絡(luò),特征聚合器是用于特征聚合以進(jìn)行分?jǐn)?shù)回歸的網(wǎng)絡(luò)。3D Convolutional Networks (C3D)[22]因?yàn)槟芴崛〕鲆曨l中物體信息、場(chǎng)景信息和動(dòng)作信息的特征,不需要根據(jù)特定任務(wù)進(jìn)行微調(diào)都可以取得不錯(cuò)的效果,被廣泛用于動(dòng)作質(zhì)量評(píng)估領(lǐng)域。C3D看似更適合做視頻處理,但存在維度問(wèn)題,經(jīng)過(guò)8層卷積層到最后全連接層有4 096個(gè)輸出單元,這樣就會(huì)更難訓(xùn)練,并且不能有效地將2D網(wǎng)絡(luò)的預(yù)訓(xùn)練權(quán)重遷移到3D網(wǎng)絡(luò)。所以該文的特征提取器采用Two-Stream Inflated 3D ConvNets (I3D)[23],I3D主要依據(jù)最優(yōu)的圖像網(wǎng)絡(luò)架構(gòu)實(shí)現(xiàn),對(duì)它們的卷積和池化核從2D擴(kuò)展到3D,并選擇使用它們的參數(shù),最終得到了非常深的時(shí)空分類網(wǎng)絡(luò),并且分別采用了不同幀組成的Clip。該文的特征聚合器由平均池化層和RFC Block組成,其中RFC Block參照殘差網(wǎng)絡(luò)(Residual Networks)的設(shè)計(jì),卷積操作的接受域范圍有限,導(dǎo)致了長(zhǎng)期依賴關(guān)系的損失,所以使用全連接層作為權(quán)重層,每層的全連接層之間加入激活函數(shù),最后再恒等映射(identity mapping)聚合所有特征進(jìn)行輸出。
為進(jìn)一步驗(yàn)證模型在不同背景下、動(dòng)作差異較大時(shí)的泛化能力,該文制作了一類羽毛球運(yùn)動(dòng)的數(shù)據(jù)集簡(jiǎn)稱(BS dataset),其中大部分是從視頻媒體共享平臺(tái)收集而來(lái)的羽毛球運(yùn)動(dòng)的訓(xùn)練視頻。把所收集到的視頻交由專業(yè)的羽毛球教練根據(jù)不同難度的動(dòng)作標(biāo)準(zhǔn)進(jìn)行評(píng)分,最后參照MTL-AQA數(shù)據(jù)集的格式對(duì)其進(jìn)行標(biāo)簽化操作。與現(xiàn)有的數(shù)據(jù)集相比,該數(shù)據(jù)集有著其他的一些特性。首先視頻是教學(xué)的視頻而不是比賽的視頻,在教學(xué)中動(dòng)作會(huì)較為緩慢,能更清楚識(shí)別出動(dòng)作;其次羽毛球運(yùn)動(dòng)是人使用長(zhǎng)柄網(wǎng)狀球拍擊打羽毛球的體育項(xiàng)目,不僅僅是要考慮人的動(dòng)作是否標(biāo)準(zhǔn),球拍的位置和握拍的方式也會(huì)影響動(dòng)作的分?jǐn)?shù);最后該數(shù)據(jù)集包括了不同背景下(不僅僅有羽毛球球場(chǎng)背景,還有居家背景)的教練或?qū)W員打羽毛球的視頻,增加了背景因素的影響,加大了預(yù)測(cè)分?jǐn)?shù)的難度。
RFC-Net方法在MTL-AQA數(shù)據(jù)集以及BS-AQA數(shù)據(jù)集上進(jìn)行了測(cè)試。實(shí)驗(yàn)結(jié)果驗(yàn)證了該模型能夠提高視頻中的動(dòng)作分?jǐn)?shù)預(yù)測(cè)效果。該文的主要貢獻(xiàn)可以總結(jié)如下:
(1)針對(duì)動(dòng)作質(zhì)量評(píng)估中預(yù)測(cè)的分?jǐn)?shù)誤差較大問(wèn)題進(jìn)行改進(jìn)。
(2)提出了RFC Block用于視頻的特征聚合,消融實(shí)驗(yàn)表明該模塊能夠提高特征聚合的效果。
(3)提出了一種基于殘差結(jié)構(gòu)的RFC-Net模型,該模型由特征提取器和特征聚合器組成,模型在MTL-AQA數(shù)據(jù)集以及BS-AQA數(shù)據(jù)集中取得了較好的結(jié)果。
1 相關(guān)工作
動(dòng)作質(zhì)量評(píng)估領(lǐng)域與動(dòng)作識(shí)別領(lǐng)域方法相類似,這個(gè)領(lǐng)域幾乎所有的工作都將視頻中人類動(dòng)作表現(xiàn)分?jǐn)?shù)的問(wèn)題作為一個(gè)回歸問(wèn)題。文獻(xiàn)[24-25]對(duì)方法做了一個(gè)概括,該文按照不同的視頻處理對(duì)該領(lǐng)域的方法進(jìn)行劃分,分為基于視頻的方法以及基于人體骨架的方法。
1.1 基于人體骨架的動(dòng)作質(zhì)量評(píng)估
基于人體骨架的方法表現(xiàn)為,使用姿態(tài)估計(jì)算法對(duì)視頻中的人體骨架進(jìn)行識(shí)別,通過(guò)對(duì)姿態(tài)的識(shí)別得到人體骨骼各個(gè)關(guān)鍵點(diǎn)的信息。因?yàn)槭菑囊曨l中識(shí)別而來(lái)的數(shù)據(jù),所以這些關(guān)鍵點(diǎn)的信息是一個(gè)個(gè)二維坐標(biāo),所得到的2D人體骨架信息大多數(shù)使用圖卷積神經(jīng)網(wǎng)絡(luò)提取特征來(lái)訓(xùn)練回歸器。
文獻(xiàn)[26]提出了一種新的時(shí)空金字塔圖卷積網(wǎng)絡(luò)(ST-PGN),用于人體動(dòng)作質(zhì)量評(píng)估和姿態(tài)估計(jì),此方法能夠使用來(lái)自骨架特征層次的所有特征。作者的另外一篇文獻(xiàn)在此基礎(chǔ)上又提出了一種新的多任務(wù)框架,該框架利用圖卷積網(wǎng)絡(luò)主干把人類骨架關(guān)節(jié)之間的互聯(lián)特性嵌入到所提取的特征中,然后根據(jù)不同的任務(wù)需要進(jìn)行不同的處理[27]。文獻(xiàn)[28]建立了可訓(xùn)練的骨架關(guān)節(jié)關(guān)系圖,并分析了其中的關(guān)節(jié)運(yùn)動(dòng),提出了兩個(gè)新的模塊,聯(lián)合共性模塊和聯(lián)合差異模塊,用于關(guān)節(jié)運(yùn)動(dòng)學(xué)習(xí),此外還有文獻(xiàn)[29-31]也屬于這類方法。
雖然骨骼數(shù)據(jù)相比視頻數(shù)據(jù),可以去除視頻中背景因素的影響,專注于人體的動(dòng)作姿態(tài),能夠針對(duì)于不同環(huán)境下的動(dòng)作進(jìn)行質(zhì)量評(píng)估。但是一個(gè)動(dòng)作往往和物品或環(huán)境有著交互的關(guān)系,對(duì)只關(guān)注于動(dòng)作本身的骨架信息而言難以分辨出這其中的聯(lián)系。
1.2 基于視頻的動(dòng)作質(zhì)量評(píng)估
基于視頻的方法表現(xiàn)為,直接把RGB視頻流作為輸入,使用特征提取網(wǎng)絡(luò)來(lái)提取視頻中的特征,這種特征包含人體的動(dòng)作信息以及視頻中的環(huán)境信息。這也可以概括為使用模型來(lái)學(xué)習(xí)視頻和動(dòng)作分?jǐn)?shù)之間的直接映射,然后采用這種映射關(guān)系用于預(yù)測(cè)新的視頻中的動(dòng)作分?jǐn)?shù)。這些工作大多數(shù)使用三維卷積神經(jīng)網(wǎng)絡(luò)來(lái)提取視頻特征,然后使用回歸方法來(lái)獲得預(yù)測(cè)分?jǐn)?shù),不同的論文在分?jǐn)?shù)回歸階段的處理方法也不盡相同。
隨著視頻分析領(lǐng)域的進(jìn)展,動(dòng)作質(zhì)量評(píng)估領(lǐng)域采取更深層次的特征提取網(wǎng)絡(luò)對(duì)視頻中的特征進(jìn)行提取,同時(shí)還用不同的方法進(jìn)行分?jǐn)?shù)的回歸。文獻(xiàn)[18]中把動(dòng)作識(shí)別中的框架引入到動(dòng)作質(zhì)量評(píng)估中,使用C3D以及C3D-LSTM的方法對(duì)特征進(jìn)行提取,最后使用SVM回歸預(yù)測(cè)分?jǐn)?shù),效果相較于之前論文中的單獨(dú)C3D卷積有了一定的提高。此外,在文獻(xiàn)[13]中還發(fā)布了一個(gè)全新的多任務(wù)動(dòng)作質(zhì)量評(píng)估(MTL-AQA)數(shù)據(jù)集,使用了兩種不同的模型C3D-AVG,MSCADC驗(yàn)證多任務(wù)對(duì)動(dòng)作質(zhì)量評(píng)估的影響。文獻(xiàn)[21]使用C3D提取特征序列,然后用多尺度卷積跳躍LSTM(M-LSTM)和自注意LSTM(S-LSTM)這兩個(gè)獨(dú)立模塊進(jìn)行處理,對(duì)特征進(jìn)行聚合,用于預(yù)測(cè)分?jǐn)?shù)。文獻(xiàn)[32]引入了LDL(標(biāo)簽分布學(xué)習(xí))方法。在分?jǐn)?shù)回歸階段設(shè)計(jì)了一種不確定性感知分?jǐn)?shù)分布學(xué)習(xí)(USDL)方法來(lái)探索一個(gè)分?jǐn)?shù)的組成,通過(guò)將給定的單個(gè)分?jǐn)?shù)標(biāo)簽轉(zhuǎn)移到高斯分布分?jǐn)?shù)中進(jìn)行學(xué)習(xí),從而直接估計(jì)動(dòng)作視頻的得分分布。文獻(xiàn)[33]中對(duì)其進(jìn)行改進(jìn),解決了USDL不適用于具有連續(xù)標(biāo)簽的數(shù)據(jù)集以及在訓(xùn)練中需要固定的方差的問(wèn)題,進(jìn)一步開發(fā)了分布式自動(dòng)編碼器(DAE),DAE同時(shí)具有回歸算法和標(biāo)簽分布學(xué)習(xí)(LDL)的優(yōu)點(diǎn)。
除了直接進(jìn)行分?jǐn)?shù)回歸外,一些學(xué)者也把目光轉(zhuǎn)向了另一種解決方案:文獻(xiàn)[16]使用孿生網(wǎng)絡(luò)在給定的動(dòng)作視頻與參考視頻之間進(jìn)行比較,計(jì)算視頻之間的相似度,從而根據(jù)參考視頻的分?jǐn)?shù)評(píng)估出給定視頻的分?jǐn)?shù)。盡管對(duì)比回歸框架可以預(yù)測(cè)相對(duì)分?jǐn)?shù),但是相對(duì)分?jǐn)?shù)通常取值范圍很廣,因此文獻(xiàn)[34]提出一個(gè)群意識(shí)(group-aware)回歸樹將對(duì)比學(xué)習(xí)得到的相對(duì)分?jǐn)?shù)做了更為細(xì)致的回歸,該方法是目前AQA領(lǐng)域的SOTA。
2 基于殘差結(jié)構(gòu)的動(dòng)作質(zhì)量評(píng)估方法
該文使用特征提取器進(jìn)行視頻的特征提取,一個(gè)完整的視頻幀數(shù)量太多,不能夠一次輸入到特征提取器中,首先對(duì)視頻進(jìn)行分割處理,然后把分割完的視頻片段分別輸入特征提取器,特征提取器提取的特征向量作為特征聚合器的輸入。為了使預(yù)測(cè)的結(jié)果更加接近真實(shí)評(píng)分,該文提出了一種由RFC Block和平均池化層構(gòu)成的特征聚合器,聚合的結(jié)果將作為預(yù)測(cè)的分?jǐn)?shù)結(jié)果。
在本章節(jié)將會(huì)對(duì)RCF-Net模型進(jìn)行詳細(xì)的描述,其中內(nèi)容包括RFC-Net網(wǎng)絡(luò)結(jié)構(gòu),如何對(duì)視頻特征進(jìn)行提取以及RFC結(jié)構(gòu)如何聚合視頻特征。
2.1 特征提取器
在進(jìn)行特征聚合之前必須得對(duì)視頻的特征進(jìn)行提取,對(duì)于特征提取網(wǎng)絡(luò)的選擇,之前大部分論文都是采取C3D作為特征提取器,但是一般3D網(wǎng)絡(luò)的深度較淺和參數(shù)過(guò)多,這樣影響了模型的表達(dá)能力和加大了訓(xùn)練的難度。而I3D作為較為優(yōu)秀的一種特征提取架構(gòu)被廣泛用于動(dòng)作識(shí)別以及動(dòng)作質(zhì)量評(píng)估中。它以最新的圖片分類模型為基礎(chǔ)結(jié)構(gòu),將kernels膨脹(inflate)結(jié)合到3D Conv。可以從視頻中學(xué)習(xí)到時(shí)空特征,同時(shí)成功把ImageNet中的預(yù)訓(xùn)練權(quán)重?cái)U(kuò)展到視頻行為識(shí)別中,因此RCF-Net模型選取I3D網(wǎng)絡(luò)作為視頻的特征提取網(wǎng)絡(luò)。
該文所采用的I3D架構(gòu)(見圖2)采用了4個(gè)卷積層、5個(gè)池化層以及Inception 模塊,除最后一個(gè)卷積層之外,在每一個(gè)卷積后面都加入了Batch Normalization層和激活層(ReLU)。
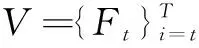
(1)
F(x)為視頻通過(guò)I3D網(wǎng)絡(luò)所提取的特征,輸出是一個(gè)1 024維的特征向量,隨后把F(x)作為特征聚合器的輸入。
2.2 特征聚合器
在動(dòng)作質(zhì)量評(píng)估中,一個(gè)視頻中包含的動(dòng)作的視頻幀數(shù)較少,一些模型試圖使用擴(kuò)展更多的卷積進(jìn)行更深層次特征提取。在一定程度上,網(wǎng)絡(luò)越深越大表達(dá)能力就越強(qiáng),提取的不同層次的信息便越多。但是隨著特征提取網(wǎng)絡(luò)層數(shù)的增加,會(huì)帶來(lái)許多問(wèn)題,網(wǎng)絡(luò)出現(xiàn)了退化,有效特征丟失,這便導(dǎo)致網(wǎng)絡(luò)的效果逐漸降低。在經(jīng)過(guò)前面若干次卷積、激勵(lì)、池化后,模型會(huì)得到一個(gè)高質(zhì)量的全連接層,因此該文不再增加卷積用于特征的提取,而是把提取到的特征進(jìn)行有效的聚合以提高分?jǐn)?shù)的預(yù)測(cè)效果。RFC Block網(wǎng)絡(luò)結(jié)構(gòu)如圖3所示。
在接受特征提取器輸入的特征F(x)后,F(xiàn)(x)分別輸入到平均池化層以及RFC Block中。該文所提出的RFC Block,參照殘差網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)而成,由于卷積操作的接受域范圍有限,導(dǎo)致了長(zhǎng)期依賴關(guān)系的損失,因此隱藏層由四層的全連接層組成,每層全連接層的特征值個(gè)數(shù)分別為{512,256,256,512},并且在每層之間加入激活函數(shù)GELU。由于隱藏層全部使用全連接層,會(huì)導(dǎo)致特征值數(shù)目過(guò)大,因此需要隨機(jī)刪除全連接中的部分特征值以減少參數(shù)量。Dropout通過(guò)將一些激活數(shù)乘于0來(lái)規(guī)范化模型,ReLu作為激活函數(shù)引入非線性,強(qiáng)化網(wǎng)絡(luò)的學(xué)習(xí)能力,而GELU可以看作Dropout和ReLu的結(jié)合,在后續(xù)的實(shí)驗(yàn)部分RFC Block分別使用了這兩類激活函數(shù),驗(yàn)證這兩類激活函數(shù)在本模型中的效果。GELU激活函數(shù)公式如下:
GELU(x)=xP(X≤x)=xφ(x),x~N(0,1)
(2)
其中,x是輸入值,X是具有零均值和單位方差的高斯隨機(jī)變量。P(X≤x)是X小于或等于給定值x的概率,φ(x)是指高斯正態(tài)分布的累積分布。全連接層是一維列向量,經(jīng)過(guò)了隱藏層和激活后得到的特征可以與一開始輸入的特征進(jìn)行聚合,RCF Block可以表示為:
FRFC(x)=F(x)⊙F(xl|wl)
(3)
其中,F(xiàn)(xl|wl)表示殘差塊中隱藏層中的輸出特征,xl為輸入隱藏層之前的特征,wl為隱藏層學(xué)習(xí)到的權(quán)重,其中l(wèi)為隱藏層的層數(shù)l?[1,4],RFC Block的輸出FRFC(x)為兩個(gè)通道數(shù)的合并,使得描述圖像的特征維度增加,而每一維度特征下的信息量不變,F(xiàn)(x)經(jīng)過(guò)平均池化層得到的Favg特征值數(shù)為512。故整個(gè)特征聚合模塊的輸出為:
FV=FRFC⊕Favg
(4)
FV為RFC Block與平均池化層聚合的特征,采取對(duì)應(yīng)元素位置相加的聚合方式,在維度不變的情況下使描述圖像的特征每一維下的信息量增多,顯然對(duì)最終的圖像的分類是有益的。最后FV進(jìn)行回歸得到該視頻動(dòng)作的預(yù)測(cè)分?jǐn)?shù)。
2.3 損失函數(shù)
損失函數(shù)用來(lái)評(píng)價(jià)模型的預(yù)測(cè)值和真實(shí)值不一樣的程度,不同的模型用的損失函數(shù)一般也不一樣。該文需要預(yù)測(cè)視頻中的動(dòng)作質(zhì)量分?jǐn)?shù),這可以看作一個(gè)分?jǐn)?shù)回歸的任務(wù),給定帶有動(dòng)作質(zhì)量標(biāo)簽的輸入視頻,基于輸入視頻預(yù)測(cè)動(dòng)作質(zhì)量:
(5)
(6)
該文采用MSE作為損失函數(shù),用于評(píng)估模型的效果,訓(xùn)練過(guò)程中均方誤差越小則預(yù)測(cè)分?jǐn)?shù)越接近真實(shí)得分。
3 實(shí) 驗(yàn)
3.1 數(shù)據(jù)集
3.1.1 MTL-AQA dataset
這是一個(gè)于2018年發(fā)布的AQA領(lǐng)域數(shù)據(jù)集。它包含了1 412個(gè)視頻樣本,是迄今為止該領(lǐng)域最大的AQA數(shù)據(jù)集。這個(gè)數(shù)據(jù)集關(guān)注跳水運(yùn)動(dòng),所有的樣本都是來(lái)自于不同國(guó)際比賽中的跳水運(yùn)動(dòng)。這些視頻包含了103幀。它們有不同的視角和相機(jī)角度。該數(shù)據(jù)集包含男女運(yùn)動(dòng)員的樣本,個(gè)人和同步跳水、3米跳臺(tái)和10米跳臺(tái)跳水、奧運(yùn)裁判的最終動(dòng)作質(zhì)量成績(jī)、任務(wù)難度水平、賽事的評(píng)論,以及細(xì)粒度的動(dòng)作標(biāo)簽。
3.1.2 BS-AQA dataset
為進(jìn)一步驗(yàn)證模型在不同背景下、動(dòng)作差異較大時(shí)的泛化能力,該文制作了羽毛球視頻數(shù)據(jù)集,目前已經(jīng)提出了一些AQA數(shù)據(jù)集,如AQA-7[35]、MTL-AQA[11]以及FD-10[12]數(shù)據(jù)集主要包含體操、跳水、滑冰的動(dòng)作。由于球類運(yùn)動(dòng)的特殊性,與體操、跳水、滑冰等運(yùn)動(dòng)不一樣。在羽毛球等球類競(jìng)技比賽中,對(duì)動(dòng)作是否標(biāo)準(zhǔn)并無(wú)要求,只要擊敗對(duì)手即可,因此該文采用羽毛球運(yùn)動(dòng)訓(xùn)練階段的視頻來(lái)進(jìn)行動(dòng)作質(zhì)量評(píng)估。
視頻主要來(lái)源于各個(gè)視頻網(wǎng)站中的羽毛球訓(xùn)練視頻,為每個(gè)視頻進(jìn)行編號(hào),并請(qǐng)羽毛球教練為每個(gè)視頻進(jìn)行評(píng)分。BS-AQA數(shù)據(jù)集分?jǐn)?shù)分布如圖4所示。
關(guān)于羽毛球運(yùn)動(dòng)數(shù)據(jù)集評(píng)分:
在羽毛球教練的建議下,把羽毛球運(yùn)動(dòng)分為四個(gè)階段,不同的階段在整個(gè)運(yùn)動(dòng)中所占的權(quán)重不一致。不同階段動(dòng)作的評(píng)分進(jìn)行加權(quán)求和從而得到總體的評(píng)分,這無(wú)疑比直接通過(guò)整個(gè)視頻的直接評(píng)分更加合理。并且為了降低教練評(píng)分的主觀性,邀請(qǐng)多位教練分階段對(duì)視頻進(jìn)行評(píng)分,最后所得的分?jǐn)?shù)為多位教練的評(píng)分取均值。用Stagei,i∈[1,4]表示教練對(duì)i階段的評(píng)分,各個(gè)階段的評(píng)分系數(shù)由教練根據(jù)經(jīng)驗(yàn)得出。
Scoreoverall=Stage1*0.4+Stage2*0.2+
Stage3*0.3+Stage4*0.1
(7)
3.2 評(píng)價(jià)指標(biāo)
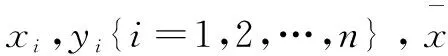
(8)
3.3 實(shí)驗(yàn)細(xì)節(jié)
在整個(gè)實(shí)驗(yàn)中該文使用的是Pytorch框架,并采用在Kinetics Dataset上進(jìn)行預(yù)訓(xùn)練的I3D模型作為特征提取器,I3D中采用ReLU作為激活函數(shù),使用MSE損失函數(shù)以及Adam優(yōu)化器,學(xué)習(xí)率設(shè)置為1e-4。把每個(gè)視頻提取包含完整動(dòng)作的96幀用作訓(xùn)練模型,96幀被分為6個(gè)Clip 16個(gè)幀剪輯或3個(gè)Clip 32個(gè)幀剪輯。視頻幀較大直接輸入網(wǎng)絡(luò)會(huì)導(dǎo)致訓(xùn)練速度過(guò)慢等問(wèn)題,原始的視頻幀的大小被調(diào)整到171×128,隨后裁剪后的視頻幀大小為112*112。并且通過(guò)隨機(jī)水平翻轉(zhuǎn)來(lái)進(jìn)行數(shù)據(jù)增強(qiáng),最后將RGB圖像三通道的數(shù)值進(jìn)行均值化、歸一化處理,3個(gè)通道中的數(shù)據(jù)整理理到[-1,1]區(qū)間,得到frames*112*112*3的輸入。通過(guò)上述步驟的處理,進(jìn)一步降低了網(wǎng)絡(luò)訓(xùn)練難度。
在RFC-Net中,該文設(shè)置了消融實(shí)驗(yàn)用于驗(yàn)證RFC Block的有效性,并且比較了不同的幀數(shù)的Clip對(duì)輸出結(jié)果的影響。
3.4 實(shí)驗(yàn)結(jié)果
3.4.1 MTL-AQA實(shí)驗(yàn)結(jié)果
(1)與其他公開模型的結(jié)果對(duì)比。
由于MTL-AQA數(shù)據(jù)集包含動(dòng)作的難度,裁判將它們的分?jǐn)?shù)與難度相乘得到最終分?jǐn)?shù),該文選擇將最后輸出的分?jǐn)?shù)與動(dòng)作難度相乘。在MTL-AQA數(shù)據(jù)集中,把近兩年(2020-2021)文獻(xiàn)[19]、文獻(xiàn)[32]和文獻(xiàn)[34]所提出的四種模型(ResNet34_(2+1),MUSDL,USDL,CoRe)與該文提出的模型進(jìn)行對(duì)比,結(jié)果如圖5所示。
(2)與SOTA(CoRe+GART模型)對(duì)比。
從表1中結(jié)果可知,除了文獻(xiàn)[34]中模型外,文中模型優(yōu)于之前的所有模型,在文獻(xiàn)[34]中把對(duì)比學(xué)習(xí)用于動(dòng)作質(zhì)量評(píng)估,通過(guò)比較兩個(gè)不同分?jǐn)?shù)的視頻,學(xué)習(xí)視頻之間的差異,最后使用群感知回歸樹來(lái)回歸預(yù)測(cè)最終得分。該模型至今為止是MTL-AQA數(shù)據(jù)集中的SOTA。文中模型對(duì)比于SOTA模型,Spearman's rank correlation比文獻(xiàn)[34]較低,但是文獻(xiàn)[34]采用的是對(duì)比學(xué)習(xí)方法,預(yù)測(cè)視頻所需要對(duì)比的范例視頻需要手動(dòng)進(jìn)行選擇,這使得模型變得更加復(fù)雜并且降低了模型預(yù)測(cè)的效率。在結(jié)果相差不是很大的情況下,相比于對(duì)文獻(xiàn)[34]的方法,通過(guò)改進(jìn)特征提取或特征聚合的方法進(jìn)行端到端的學(xué)習(xí)更加簡(jiǎn)便以及更加貼合應(yīng)用場(chǎng)景。
在RFC-Net中,設(shè)置了消融實(shí)驗(yàn)用于驗(yàn)證RFC Block的有效性,并且比較了不同幀數(shù)的Clip 對(duì)輸出結(jié)果的影響。
(3)消融實(shí)驗(yàn)結(jié)果對(duì)比。
為了進(jìn)一步探究RFC模塊是否能提升特征的聚合結(jié)果,設(shè)置了消融實(shí)驗(yàn),即不加入RFC Block聚合特征而是直接對(duì)特征提取器提取的特征進(jìn)行分?jǐn)?shù)回歸。此外參照文獻(xiàn)[19]中的方法,在MTL-AQA數(shù)據(jù)集上測(cè)試了不同幀數(shù)的Clip對(duì)結(jié)果的影響,把Clip中的幀數(shù)分別設(shè)置為16與32,對(duì)比了Clip中不同幀數(shù)對(duì)實(shí)驗(yàn)結(jié)果的影響。Spearman's rank correlation對(duì)比如圖6所示,可以看到在參數(shù)不變的情況下32幀比16幀的Clip效果相對(duì)較好一些。
RFC-Net消融實(shí)驗(yàn)結(jié)果如表2所示。當(dāng)Clip為16幀的時(shí)候,加入RFC Block的結(jié)果優(yōu)于沒(méi)有RFC Block的結(jié)果,這驗(yàn)證了RFC Block能夠提升特征聚合的結(jié)果。文中模型在Clip為32幀的時(shí)候得到最優(yōu)的結(jié)果。
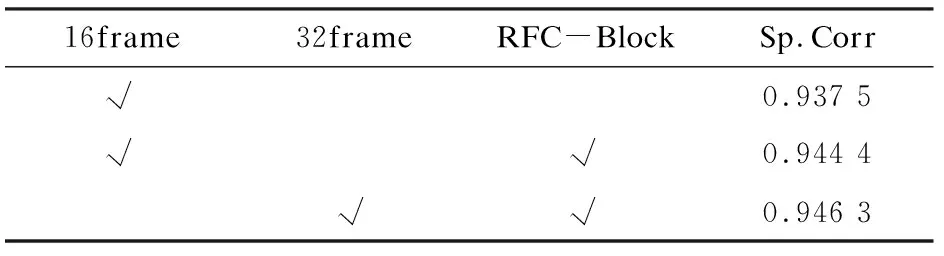
表2 RFC-Net消融實(shí)驗(yàn)
3.4.2 BS-AQA數(shù)據(jù)集結(jié)果
為驗(yàn)證模型在不同背景下、動(dòng)作差異較大時(shí)模型的泛化能力,制作了羽毛球視頻數(shù)據(jù)集,挑選了文獻(xiàn)[11]和文獻(xiàn)[19]中的三種采用端到端的分?jǐn)?shù)回歸方法模型(MSCADC,C3D-AVG,RestNet-34(2+1))與該文提出的RFC-Net方法進(jìn)行對(duì)比。因?yàn)镃oRe+GART模型需要人工挑選范例視頻,而范例視頻的挑選對(duì)實(shí)驗(yàn)結(jié)果影響較大,故在BS-AQA數(shù)據(jù)集中沒(méi)有選擇當(dāng)前的SOTA模型進(jìn)行對(duì)比。
四種模型在測(cè)試集上的結(jié)果如圖7所示。散點(diǎn)為當(dāng)前Epoch下的Spearman's rank correlation,數(shù)據(jù)集中的視頻背景復(fù)雜,動(dòng)作差異較大,因此點(diǎn)的分布較為分散,為了找到一條線段來(lái)盡可能貼近地描述這些散點(diǎn)。該文使用非線性Gaussian函數(shù)對(duì)散點(diǎn)進(jìn)行擬合,其中Gaussian函數(shù)有8種類型,選取其中基礎(chǔ)類型,其函數(shù)表達(dá)式為:
a*exp(c-((x-b)/c)2)
(9)
最后得到一條擬合線用于表示Spearman's rank correlation的回歸結(jié)果。可以看到在BS-AQA數(shù)據(jù)集中RFC-Net的Spearman's rank correlation普遍高于其他三種模型。
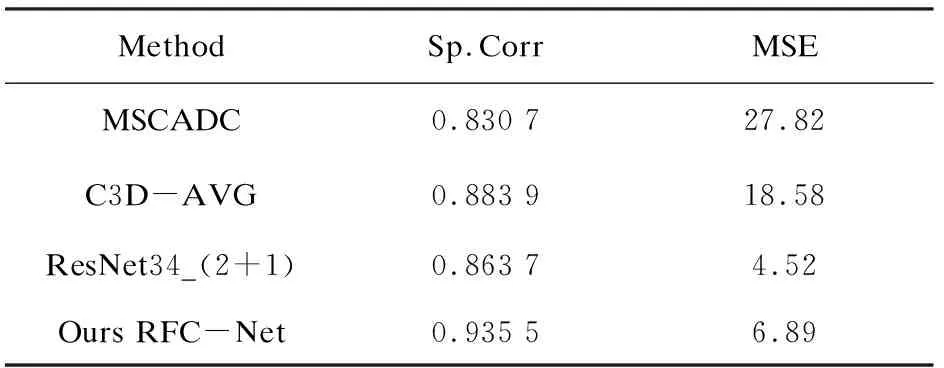
表3 BS-AQA數(shù)據(jù)集性能比較
表3給出了四種模型在BS-AQA數(shù)據(jù)集上的具體性能比較,比較結(jié)果顯示在主要的評(píng)價(jià)指標(biāo)Spearman's rank correlation中。RFC-Net在四類模型中效果最優(yōu),而MSE略低于RestNet_34(2+1),這表明RFC-Net模型在不同的動(dòng)作類別中仍然具備較好的結(jié)果,模型的泛化能力較強(qiáng)。
4 結(jié)束語(yǔ)
為了提高動(dòng)作質(zhì)量評(píng)分的準(zhǔn)確性,提出了一種基于殘差結(jié)構(gòu)的動(dòng)作質(zhì)量評(píng)估網(wǎng)絡(luò)模型。RFC-Net由特征提取器和特征聚合器組成,在特征聚合器中采用了RFC Block和平均池化層進(jìn)行特征聚合,通過(guò)消融實(shí)驗(yàn)表明,RFC Block能夠?qū)μ崛〉囊曨l特征進(jìn)行有效的特征聚合,更加準(zhǔn)確地預(yù)測(cè)動(dòng)作的得分,RFC-Net模型在MTL-AQA數(shù)據(jù)集上取得了僅次于SOTA的結(jié)果。此外為了探究該模型的泛化能力而制作了BS-AQA數(shù)據(jù)集,實(shí)驗(yàn)結(jié)果表明在羽毛球運(yùn)動(dòng)動(dòng)作質(zhì)量評(píng)估中,與其他端到端的模型相比,該模型仍然表現(xiàn)出了具備競(jìng)爭(zhēng)力的結(jié)果。
該方法仍具備改進(jìn)的空間,未來(lái)將在以下兩個(gè)方向進(jìn)行研究:
(1)在特征提取器中進(jìn)行改進(jìn),特征提取是提取視頻中所有的特征,但是和動(dòng)作質(zhì)量評(píng)估相關(guān)的特征在整個(gè)視頻特征中占據(jù)較小的部分,如何精確提取運(yùn)動(dòng)員的運(yùn)動(dòng)特征是未來(lái)的一個(gè)研究方向;
(2)如何在減少參數(shù)量的情況下提升其聚合效果也是未來(lái)的一個(gè)研究方向。
猜你喜歡
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
小學(xué)生作文(低年級(jí)適用)(2018年3期)2018-04-17 00:58:35
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
少年博覽·小學(xué)低年級(jí)(2017年4期)2017-06-09 16:22:28
作文評(píng)點(diǎn)報(bào)·低幼版(2017年7期)2017-03-11 20:49:41
中國(guó)生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
少兒科學(xué)周刊·少年版(2015年4期)2015-07-07 20:56:37
噪聲與振動(dòng)控制(2015年4期)2015-01-01 07:08:21
